
现在更多项目会把日志整理收集起来,方便客户或者开发查询日志。日志是项目中一个多而且杂的关键组织部分。
今天将演示的就是kafka+ELK【elasticSearch+logstash+kibana】组成的日志分析系统。其中kafka起到了异步的作用,最小程度减轻了应用本身的资源压力。
环境准备:
以下所有组件都是以tar.gz包的形式安装、配置。没有用到docker等容器。
1、Kafka
这边是通过网上下载的kafka安装包,其中内置了zookeeper。解压命令
tar -zxvf kafka_2.12-3.70.tgz -C 指定目录
这边解压完,如果不需要额外修改端口的话可以直接使用。进入到kafka_1.12目录下
先启动zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties
等启动好后,看到有create new log controller字样即可再去启动kafka
./bin/kafka-server-start.sh config/server.properties
这样kafka就启动好了,如果需要后台启动,自行下载 nohup,安装好后在命令前加上nohup,命令最后加上符号 & 即可,示例:
nohup ./bin/kafka-server-start.sh config/server.properties &
2、elasticSearch
我这边使用wget命令下载的,没有外网的可以去网上下载tar.gz传入Linux。
重点:这里ELK三件套版本问题,es、kibana最好一致,logstash不要相差太多。本人这里踩坑了。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.2-linux-x86_64.tar.gz
解压es,因为es启动不能用root账号启动。建议将解压文件放到/usr/local下
tar -zxvf elasticsearch-7.13.2-linux-x86_64.tar.gz -C /usr/local
**ES是这几个中间件中最难配的一个,需要修改JDK环境、JVM参数、线程数等**
jdk配置:
因为elasticsearch和jdk是强依赖关系,es由Java编写。所以下的安装包中也有一个JDK,而我们服务器可能已经安装过JDK就会出现冲突。这边需要修改es中bin目录下elasticsearch-env文件
vim elasticsearch-env 按 i 编辑 esc后 输入 wq 回车保存
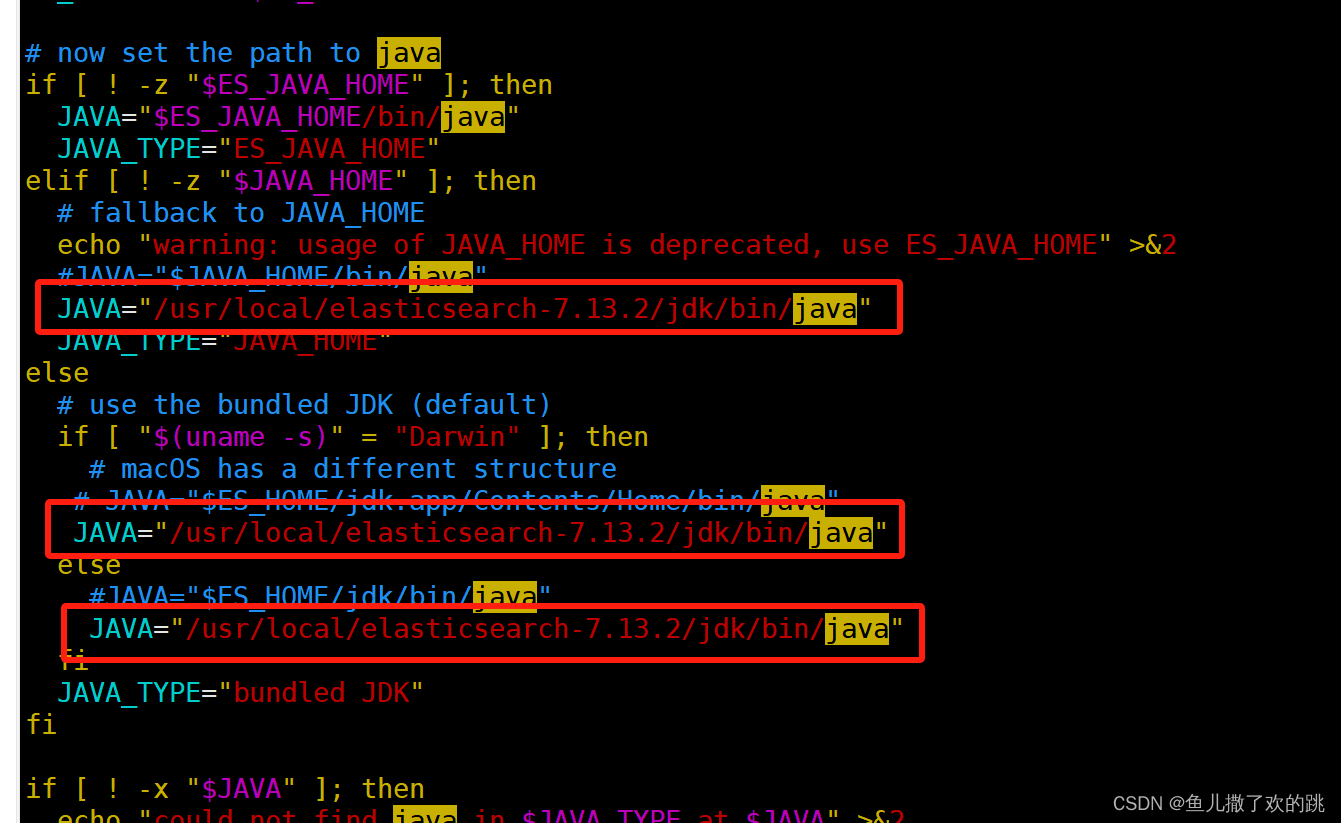
将使用的Java指定成我们es安装包中自带的。
JVM配置:
去修改es目录下 config目录下jvm.options 默认的jvm参数太高了,如果服务器性能好可以不做修改
vim jvm.options

YML配置:
配置host和端口,方便后期kibana、logstash访问。修改config目录下的elasticsearch.yml文件。
vim elasticsearch.yml
修改 network.host、http.port、cluster.name、node.name、cluster.initial_master_nodes参数,如图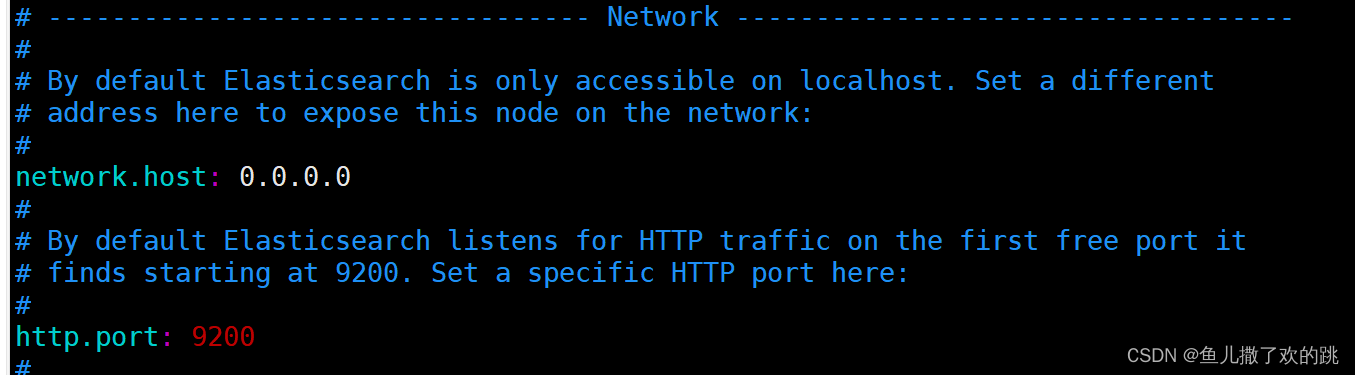
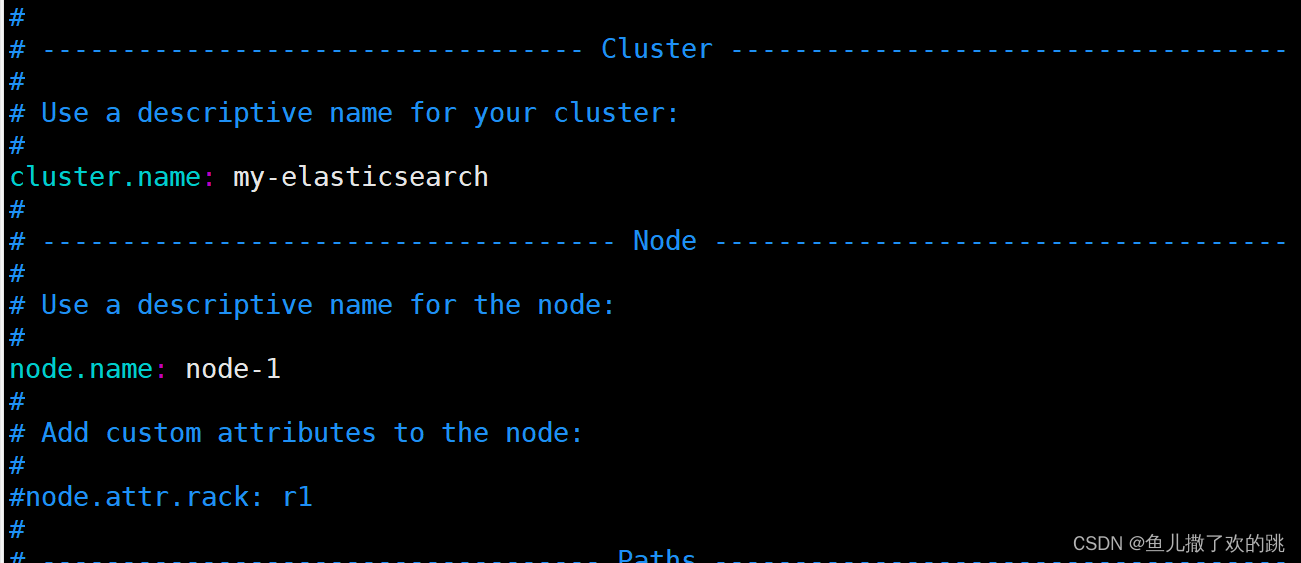
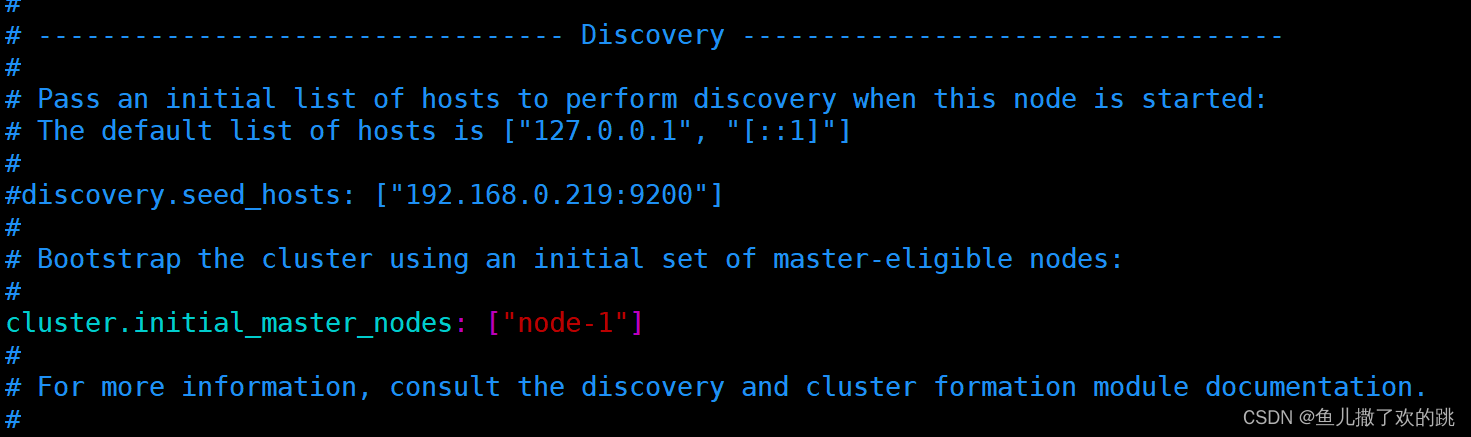
启动:
因为es不能直接用root用户启动,需要新建用户,且用root账户给新建账户授权
useradd user-es
passwd 123
接着输入自己的密码即可。接着授权chown -R user-es:123/usr/local/elasticsearch-7.13.2
然后切换到user-es账户下启动es
su user-es
#bin目录下
./elasticsearch
如果还未启动可能是线程数、堆大小问题。需要自行解决,这里就不过多赘述了。
3、kibana
我这儿使用的是wget指令下载的安装包,注意:需要和es版本一致
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.2-linux-x86_64.tar.gz
解压至 /usr/local目录下
tar -zxvf kibana-7.13.2-linux-x86_64.tar.gz -C /usr/local
YML配置:
修改config目录下的kibana.yml 配置IP+端口,并指定elasticsearch地址
vim kibana.yml
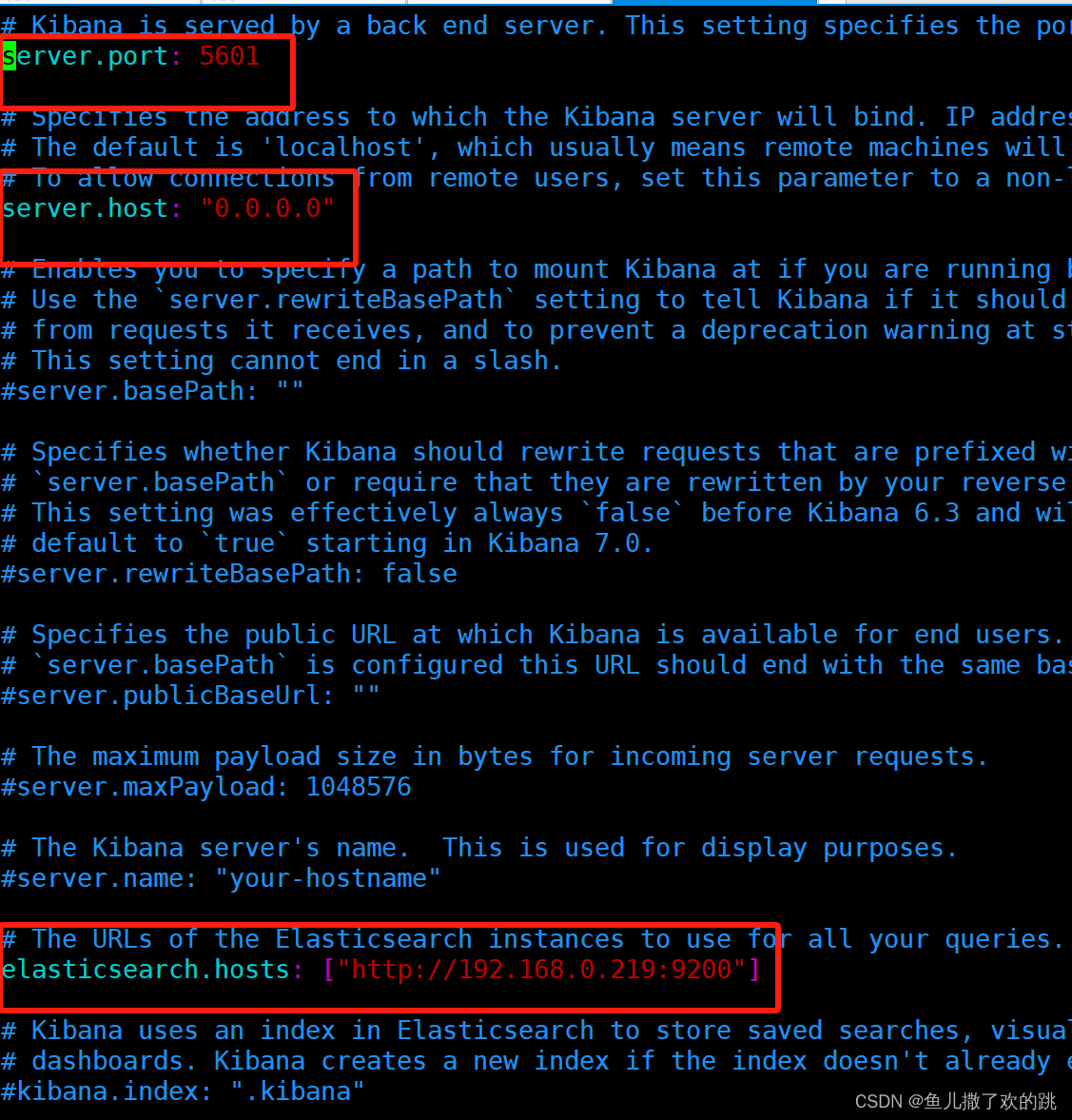 其中的server.host之所以填0.0.0.0是因为elasticsear和kibana需要连接,使用localhost会连接失败,所以我这边直接使用0.0.0.0放开了所有连接。
其中的server.host之所以填0.0.0.0是因为elasticsear和kibana需要连接,使用localhost会连接失败,所以我这边直接使用0.0.0.0放开了所有连接。
启动:
进入到bin目录下,也需要切换到 uesr-es账户下,切换前记得授权
./kibana
4、lostash
使用wget命令下载logstash安装包
wget https://artifacts.elastic.co/downloads/loagstash/logstash-7.5.1-linux-x86_64.tar.gz
解压至/usr/local目录下
tar -zxvf logstash-7.5.1.tar.gz -C /usr/local
CONF配置
在logstash conf目录下新建一个 logstash.conf 文件
编辑文件,输入如下内容
# 输入方式 通过监听kafka队列,读取数据
input {
#
kafka {
id => "my_plugin_id"
bootstrap_servers => "localhost:9092" #kafka地址
topics => ["zz-log-topic"] #队列名称,要于项目logback.xml文件中一致
auto_offset_reset => "latest"
}
}
# 输出 将监听的日志写入es中
output {
stdout { codec => rubydebug }
elasticsearch {
hosts =>["localhost:9200"] # es地址
}
}
保存,回到根目录下启动
./bin/logstash -f config/logstash.conf
spring项目配置
maven配置
添加maven依赖
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.2.0-RC2</version>
<scope>runtime</scope>
</dependency>
xml配置
在项目模块resource目录下新建logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
scan:当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。
scanPeriod:设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒当scan为true时,此属性生效。默认的时间间隔为1分钟。
debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。
-->
<configuration scan="false" scanPeriod="60 seconds" debug="false">
<shutdownHook class="ch.qos.logback.core.hook.DelayingShutdownHook"/>
<springProperty scope="context" name="logging.level" source="logging.level" defaultValue="info"/>
<!-- 定义日志的根目录 -->
<property name="LOG_HOME" value="./zzlogs/building" />
<!-- 定义日志文件名称 -->
<property name="LOG_NAME" value="building"></property>
<!-- 下面注释中 %traceid 为SkyWalking 中的traceid -->
<property name="LOG_PATTERN" value="[%-5level] [%d{yyyy-MM-dd HH:mm:ss}] [%thread] ==> [TxId: %X{PtxId},SpanId: %X{PspanId}]" />
<property name="LOG_PATTERN_EX" value="[%-5level] [%d{yyyy-MM-dd HH:mm:ss}] T:[%X{traceId}] S:[%X{sessionId}] U:[%X{userId}] [%thread] ==> [%tid] %msg%n" />
<appender name="kafka_log" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>${LOG_PATTERN_EX}</pattern>
</layout>
</encoder>
<topic>zz-log-topic</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<producerConfig>bootstrap.servers=localhost:9092</producerConfig>
</appender>
<!-- ch.qos.logback.core.ConsoleAppender 表示控制台输出 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<!--
日志输出格式:
%-5level:级别从左显示5个字符宽度
%d表示日期时间,
%thread表示线程名,
%msg:日志消息,
%n是换行符
-->
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>${LOG_PATTERN}</pattern>
</layout>
</encoder>
</appender>
<!-- 滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 -->
<appender name="file_log" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 这里为缺省log文件命名配置。注意,如果需要支持基于flume的日志搬运,为了防止文件名滚动过程中,
重复搬运数据,请将下面两行配置注释掉,从而保证每次生成的日志文件均包含日期信息且不会变化。-->
<file>${LOG_HOME}/${LOG_NAME}.log</file>
<append>true</append>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--
滚动时产生的文件的存放位置及文件名称 %d{yyyy-MM-dd}:按天进行日志滚动
%i:当文件大小超过maxFileSize时,按照i进行文件滚动
-->
<fileNamePattern>${LOG_HOME}/${LOG_NAME}-%d{yyyy-MM-dd}-%i.log</fileNamePattern>
<!--
可选节点,控制保留的归档文件的最大数量,超出数量就删除旧文件。假设设置每天滚动,
且maxHistory是365,则只保存最近365天的文件,删除之前的旧文件。注意,删除旧文件是,
那些为了归档而创建的目录也会被删除。
-->
<!-- 保存31天数据 -->
<MaxHistory>31</MaxHistory>
<!--
当日志文件超过maxFileSize指定的大小是,根据上面提到的%i进行日志文件滚动 注意此处配置SizeBasedTriggeringPolicy是无法实现按文件大小进行滚动的,必须配置timeBasedFileNamingAndTriggeringPolicy
-->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>20MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 日志输出格式: -->
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>${LOG_PATTERN_EX}</pattern>
</layout>
</encoder>
</appender>
<!-- 然后定义logger,只有定义了logger并引入的appender,appender才会生效 -->
<!-- 这里我们把输出到控制台appender的日志级别设置为DEBUG,便于调试。但是输出文件我们缺省为INFO,两者均可随时修改。-->
<root level="${logging.level}">
<appender-ref ref="console" />
</root>
<logger name="springfox.documentation" additivity="false" level="error">
<appender-ref ref="console" />
</logger>
<logger name="apelet" additivity="false" level="info">
<appender-ref ref="console" />
<appender-ref ref="kafka_log"/>
<appender-ref ref="file_log" />
</logger>
<!-- 这里将dao的日志级别设置为DEBUG,是为了SQL语句的输出 -->
<logger name="apelet.upmsservice.dao" additivity="false" level="debug">
<appender-ref ref="console" />
<appender-ref ref="kafka_log"/>
<appender-ref ref="file_log" />
</logger>
<logger name="apelet.common.log.dao" additivity="false" level="debug">
<appender-ref ref="console" />
<appender-ref ref="kafka_log"/>
<appender-ref ref="file_log" />
</logger>
<logger name="apelet.common.report.dao" additivity="false" level="debug">
<appender-ref ref="console" />
<appender-ref ref="kafka_log"/>
<appender-ref ref="file_log" />
</logger>
<logger name="apelet.common.online.dao" additivity="false" level="debug">
<appender-ref ref="console" />
<appender-ref ref="kafka_log"/>
<appender-ref ref="file_log" />
</logger>
<logger name="apelet.common.flow.dao" additivity="false" level="debug">
<appender-ref ref="console" />
<appender-ref ref="kafka_log"/>
<appender-ref ref="file_log" />
</logger>
<logger name="org.flowable" additivity="false" level="info">
<appender-ref ref="console" />
<appender-ref ref="kafka_log"/>
<appender-ref ref="file_log" />
</logger>
<statusListener class="ch.qos.logback.core.status.OnConsoleStatusListener"/>
</configuration>
xml详解:
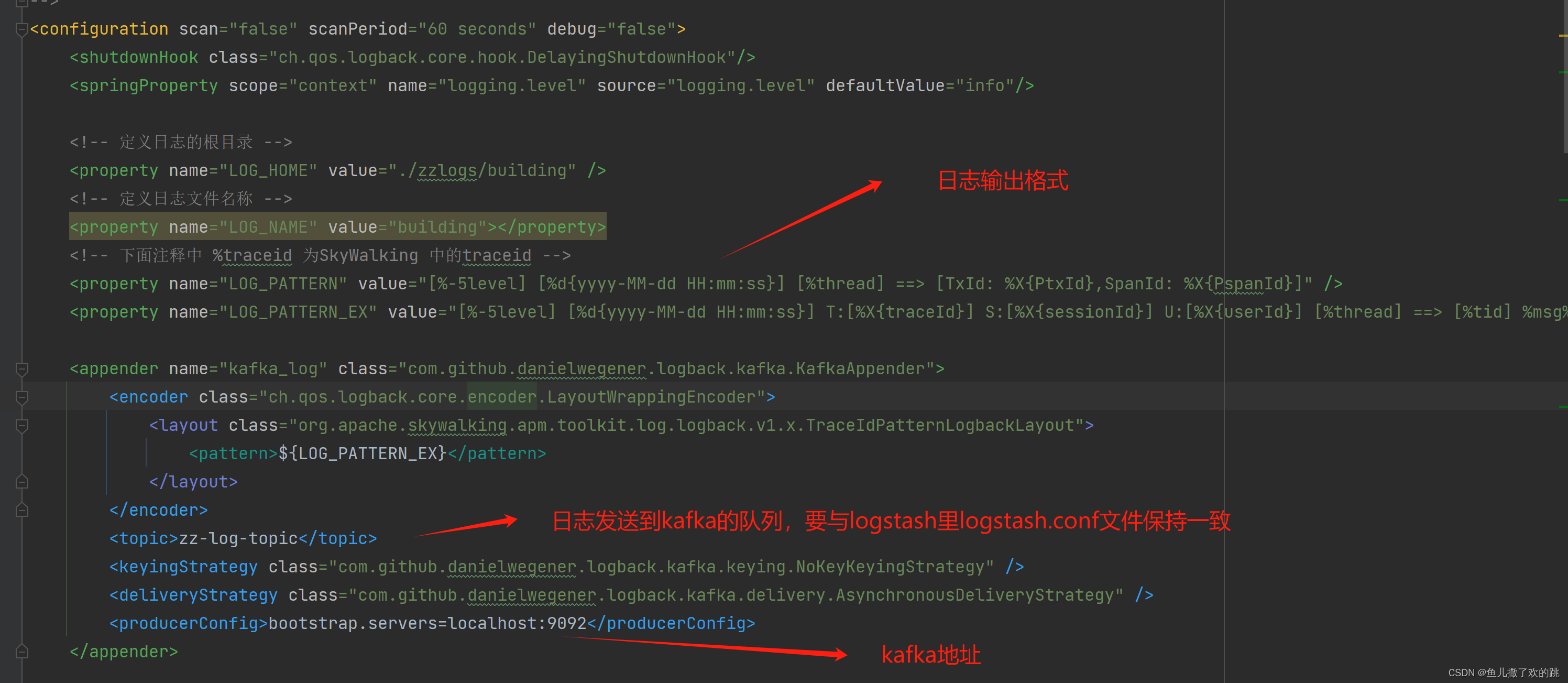
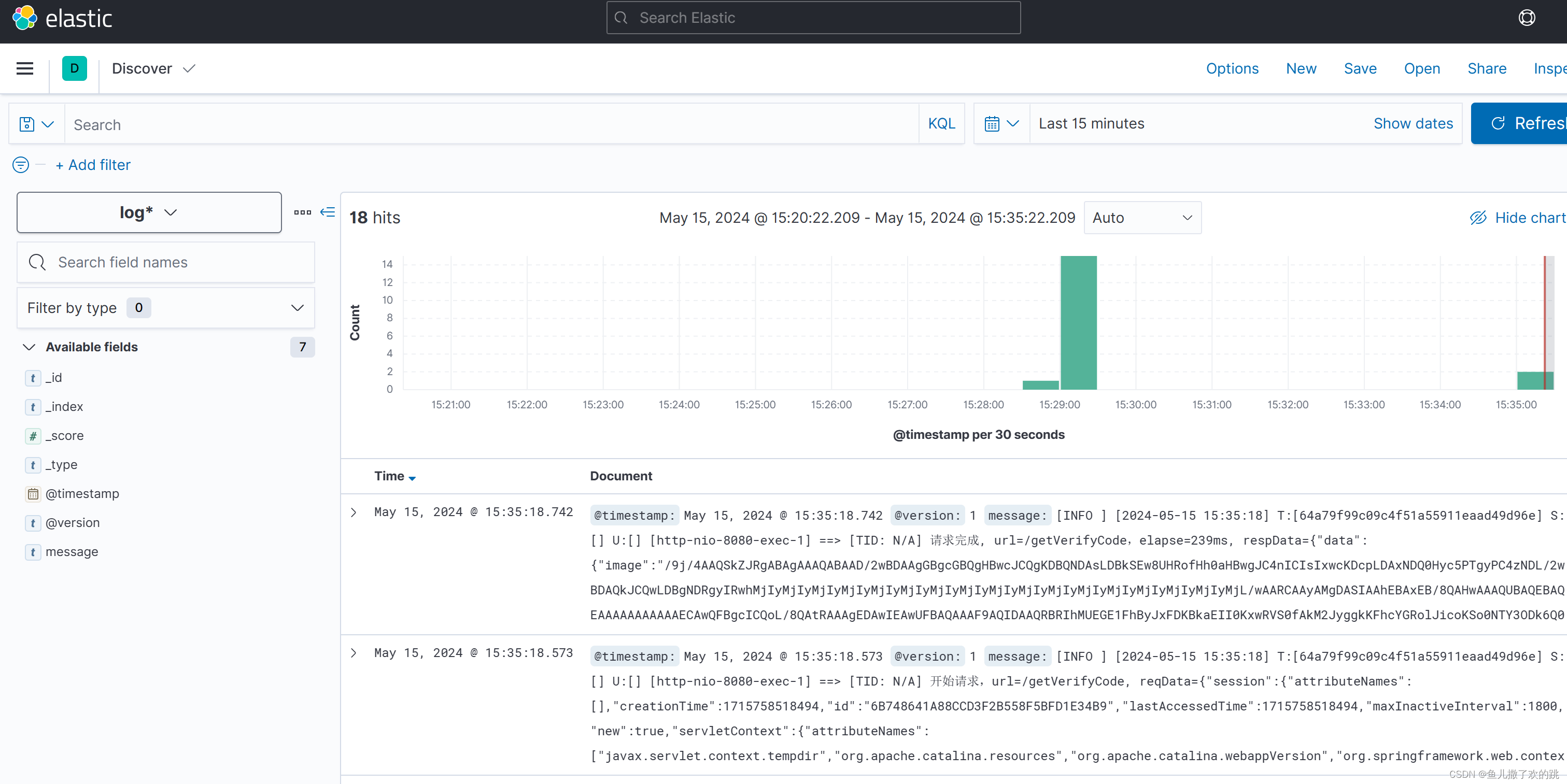
启动服务测试
访问kibana,看日志是否写入到了es
版权归原作者 鱼儿撒了欢的跳 所有, 如有侵权,请联系我们删除。