
文章目录
前言
Flink支持多种集群部署模式,以满足不同场景和需求。以下是Flink的主要集群部署模式:
- 会话模式(Session Mode):- 在会话模式下,用户首先启动一个长期运行的Flink集群,然后在这个会话中提交多个作业。- 集群资源在启动时就已经确定,提交的作业会竞争集群中的资源,直到作业运行完毕释放资源。- 会话模式适合执行大量规模小、执行时间短的作业。- 由于集群资源是共享的,因此可能存在资源争用的问题。
- 单作业模式(Per-Job Mode):- 在单作业模式下,每个作业都会启动一个独立的Flink集群,作业完成后集群也会关闭。- 这种模式为每个作业提供了资源隔离,避免了资源争用的问题。- 由于每个作业都需要启动和关闭集群,因此在处理大量作业时可能会产生额外的开销。- 单作业模式通常与第三方资源调度器(如YARN、Kubernetes等)结合使用,以便更有效地管理集群资源。
- 应用模式(Application Mode):- 应用模式与单作业模式类似,也是为每个作业启动一个独立的Flink集群。- 与单作业模式不同的是,在应用模式下,作业的main方法直接在JobManager上执行,而不是在客户端执行。- 这种模式简化了作业的提交过程,并减少了客户端与JobManager之间的通信开销。- 应用模式同样需要依赖第三方资源调度器来管理集群资源。
在选择Flink的集群部署模式时,需要根据实际的应用场景和需求进行权衡。例如,对于需要频繁提交大量小作业的场景,会话模式可能是一个合适的选择;而对于需要严格资源隔离和稳定性保障的场景,单作业模式或应用模式可能更为合适。同时,还需要考虑与现有资源调度器的集成和兼容性。
一、会话模式(Session Mode)
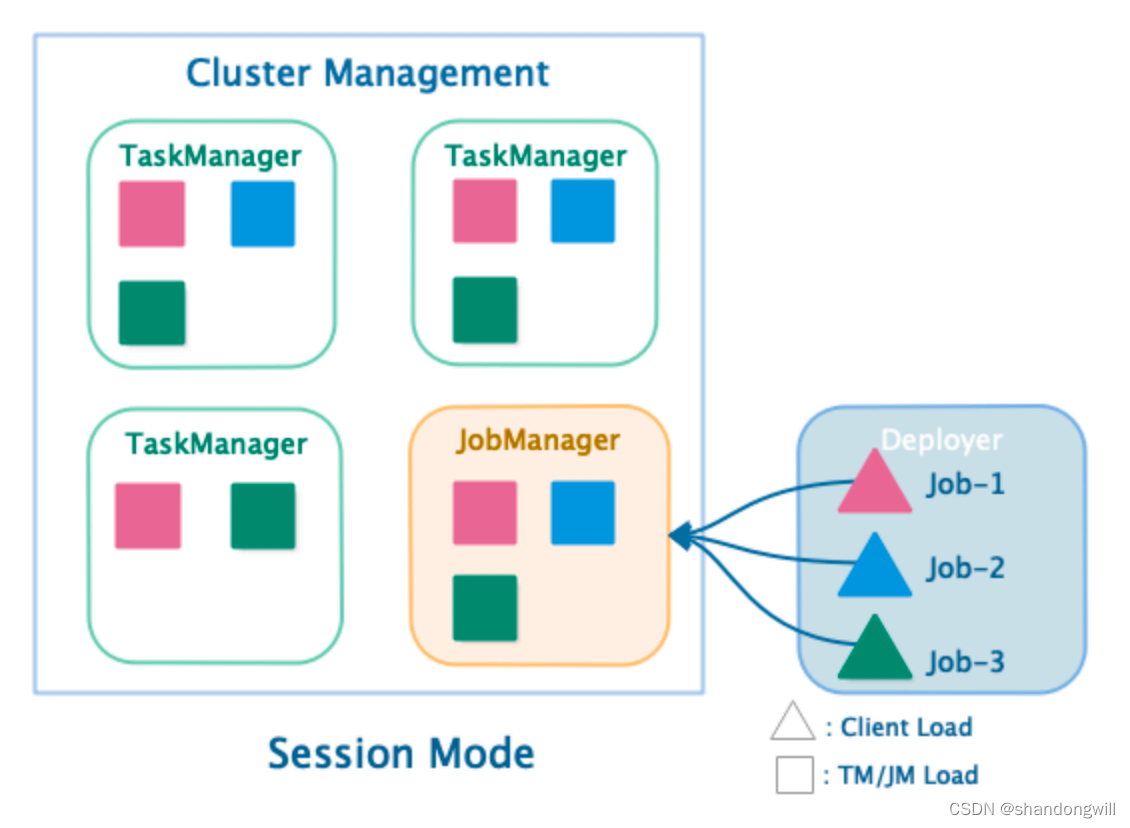
在 Apache Flink 的会话模式(Session mode)中,假设已经存在一个预先配置好的运行中的集群,该集群提供必要的资源来执行提交的应用程序。在这种模式下,多个应用程序共享同一个集群的资源,这意味着它们会竞争 CPU、内存和其他资源。
以下是会话模式的优势和劣势,供您在决策时考虑:
优势:
- 资源高效性: 对于每个提交的作业都启动一个完整的集群会消耗大量资源。在会话模式下,您避免了这种开销,因为可以重复使用已运行集群的资源。
- 简化管理: 有一个长期运行的集群意味着您不需要为每个作业频繁地启动和关闭集群。这简化了集群管理,减少了操作复杂性。
劣势:
- 资源竞争: 由于所有作业共享同一个集群的资源,它们会争夺 CPU、内存和网络带宽。这可能导致性能下降,如果某个作业消耗了不成比例的资源。
- 故障传播: 如果一个作业行为异常或导致 TaskManager 失败,它可能会影响在同一 TaskManager 上运行的其他作业。这可能导致故障级联和大规模的恢复过程,这个过程可能非常消耗资源且耗时。
- JobManager 负载增加: JobManager 负责管理和协调集群中运行的所有作业。多个作业同时运行时,JobManager 会面临增加的负载,这可能影响其性能和可伸缩性。
- 隔离性有限: 会话模式提供的作业之间的隔离性有限。一个作业的问题可能会潜在地影响在相同集群中运行的其他作业。
在考虑会话模式时,重要的是要评估您的具体用例和需求。如果您有一组稳定的作业,它们不需要严格的资源隔离,并且您希望最大化资源利用率,那么会话模式可能是一个不错的选择。然而,如果您需要更好的隔离性、容错性或对资源分配的更精细控制,您可能想考虑其他部署模式,如单作业模式(Per-Job)或应用模式(Application mode)。
此外,值得注意的是,Flink 提供了配置选项来减轻会话模式的一些劣势。例如,您可以配置资源配额或根据作业的重要性设置优先级,以确保公平的资源分配。您还可以使用外部监控和告警工具来快速检测和响应故障。
二、单作业模式(Per-Job Mode)
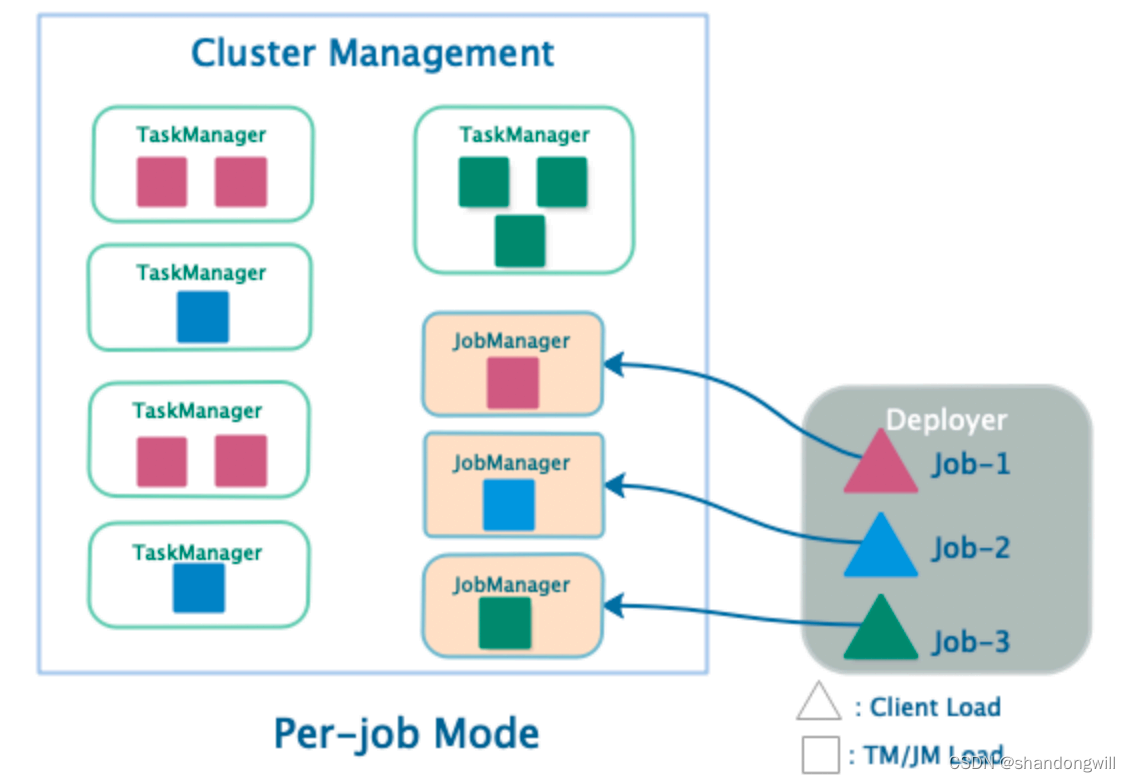
为了提供更好的资源隔离保证,单作业模式(Per-Job mode)使用可用的资源提供者框架(如YARN、Kubernetes)为每个提交的作业启动一个集群。这个集群仅对该作业可用。作业完成后,集群会被销毁,任何剩余的资源(如文件等)也会被清理。这提供了更好的资源隔离,因为行为异常的作业只能导致其自己的 TaskManager 崩溃。此外,由于每个作业都有一个 JobManager,因此它将记录工作的负载分散到了多个 JobManager 上。出于这些原因,单作业资源分配模型是许多生产环境首选的模式。
三、应用模式(Application Mode)
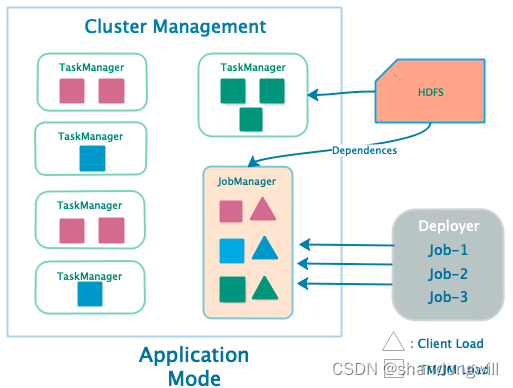
应用模式(Application Mode)#
在所有的其他模式中,应用程序的 main() 方法都是在客户端执行的。这个过程包括在本地下载应用程序的依赖项,执行 main() 来提取 Flink 运行时可以理解的应用程序表示(即 JobGraph),并将依赖项和 JobGraph 发送到集群。这使得客户端成为了一个大量消耗资源的实体,因为它可能需要大量的网络带宽来下载依赖项和向集群发送二进制文件,以及 CPU 周期来执行 main()。当客户端在多用户之间共享时,这个问题可能会更加明显。
基于这一观察,应用模式为每个提交的应用程序创建一个集群,但这次,应用程序的 main() 方法是在 JobManager 上执行的。为每个应用程序创建一个集群可以看作是创建一个会话集群,该集群仅由特定应用程序的作业共享,并在应用程序完成后销毁。通过这种架构,应用模式提供了与单作业模式相同的资源隔离和负载均衡保证,但粒度是整个应用程序。在 JobManager 上执行 main() 方法不仅节省了所需的 CPU 周期,还节省了本地下载依赖项所需的带宽。此外,由于每个应用程序都有一个 JobManager,它还允许在集群中更均衡地分配下载应用程序依赖项的网络负载。
在应用模式中,main() 是在集群上执行的,而不是在客户端上,如其他模式那样。这可能对您的代码产生影响,例如,您使用 registerCachedFile() 在环境中注册的任何路径都必须可由您的应用程序的 JobManager 访问。
与单作业模式相比,应用模式允许提交由多个作业组成的应用程序。作业的执行顺序不受部署模式的影响,而是由用来启动作业的调用方式决定。使用阻塞式的 execute() 方法会建立一个顺序,并导致“下一个”作业的执行被推迟,直到“当前”作业完成。而使用非阻塞式的 executeAsync() 方法会导致“下一个”作业在“当前”作业完成之前就开始执行。
应用模式支持多 execute() 应用程序,但在这种情况下不支持高可用性(High-Availability)。应用模式中的高可用性仅支持单 execute() 应用程序。
此外,在应用模式中,如果多个正在运行的作业中的任何一个(例如,使用 executeAsync() 提交的)被取消,所有作业都将停止,并且 JobManager 将关闭。正常的作业完成(由源关闭引起)是被支持的。
版权归原作者 shandongwill 所有, 如有侵权,请联系我们删除。