
类比一下,秒懂大数据模式
从传统单机开发模式思考
大数据这个架构,好像产品非常多,对于初学者来说似乎很不友好。于是大家觉得,好像和我们之前的开发很不一样。但实际上和之前的开发是一模一样的。为什么一模一样?
我们想一想,之前做开发的时候是怎么做的?
比方说我们之前,也是和Hive或者Spark SQL一样,去做数据仓库或者做数据库。这个时候我们在单机模式下是怎么完成的?
首先需要找一台单机服务器,然后在这个服务器上安装我们的OS(操作系统)。
安装好我们操作系统之后,我要做数据库开发,那就在操作系统上装一个MySQL,或者Oracle。
装好Mysql装好Oracle之后,我的业务就可以直接基于Mysql,基于Oracle去进行开发了。
大数据这一块,为什么要装这么多组件?我们来给大家铺垫一下。
传统单机服务,装在操作系统上,之前的传统服务是单机模式的,所以底层这个操作系统就为我们上层服务提供了哪些东西?
首先底层这个操作系统,它有没有提供一个文件系统?所以Mysql本质上,它的数据是不是存在操作系统里面的文件系统上。
当Mysql作业运行的时候,这些个SQL它是不是转成操作系统提供的一些个通用计算去运行了?比如说操作系统这一块,提供的c语言、汇编语言,甚至提供一些内核的指令集。
在运行的时候,操作系统有没有给运行这些个任务进行资源分配?有没有给它分配CPU、内存,然后进行作业管理的操作?是不是也有。
底层操作系统,本身就带了通用计算、资源管理还有数据存储这三层。这里,可以类比一下大数据模式了。
进入大数据模式后的转变
但是大数据这一块,和传统单机架构不太一样了。大数据这一块的产品,它要运行在分布式的集群上。
也就意味着,它底层的操作系统必须是分布式的。
因为单机的操作系统,存不了那么多数据,而且计算起来效率还很差。
那有没有一个操作系统,它运行起来以后就是分布式的,底层就是管理多个物理机集群的?
现阶段来说没有的,于是我们需要通过软件层面,帮我们把分布式的OS给构建出来。
你看我们软件层面去构建的时候,首先HDFS构建了一个分布式文件系统,YARN构建了一个分布式的资源调度,然后mapreduce和spark构建了一个通用计算。它本质上就是一个分布式的操作系统,该有的都有了。
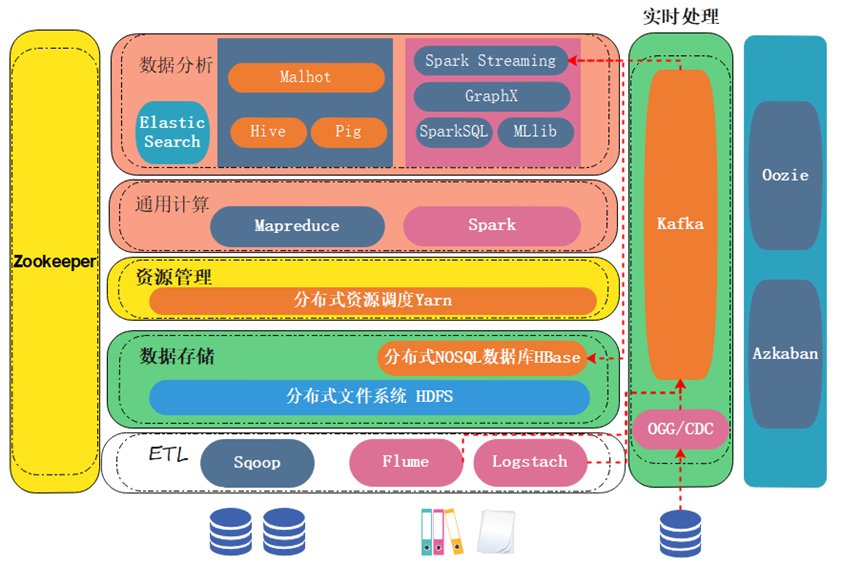
我们通过软件层面,把这个操作系统构建起来之后,我们在这个操作系统再去装满足业务需求的一些组件。
做数仓使用Hive,做机器学习使用Malhot,图计算GraphX,流计算Spark Streaming。
是不是和我们传统的一模一样?所以你不要把它想得很复杂,你觉得大数据这一块怎么这么多产品,有点复杂。实际上不是的,和我们传统的开发模式还是一模一样的。
只不过我们需要软件层面,把底层OS操作系统构建出来,然后再去装我们对应的组件,去完成相应的开发就ok了。
对于我们现在来说的话,大数据开发这里,使用通用计算这一层其实不是很多了。通用计算这一层的话,我们一般用它来做数据处理。
对抽取过来以后的数据存到HDFS里的数据,不管是通过Sqoop,还是通过flume、logstach,或者是通过ogg cdc这些个技术抽取到的数据,存到文件系统里面之后。我们会用MapReduce或者spark手动编写通用计算的任务,去对数据进行一个相应的处理。或者我们叫数据清洗。
这个怎么理解?和我们传统的架构也是一样的。我们想一下,在我们传统的架构里面,操作系统里面提供通用计算的,我们往低层说有汇编语言指令集,往高级点说,有高级语言,如c语言、c++,用的较多的Java、Python。这些编程语言,是不是在单机领域就处于通用计算这一层。
我们用这些编程语言,是不是也会对我们底层的一些个文件系统里存储的文件,进行一个处理。当把我们的底层文件系统的数据处理完、清洗完以后,就会导入到我们的开发平台,例如数据库里,之后的话我们就直接用mysql、oracle进行相应的一个开发就ok了。
在这儿实际上也是的,我们用mapreduce、spark把底层的数据处理完存到Hive、Spark SQL,或者MLlib里面之后,上层再基于这些干净的数据进行一个相应的开发。
这是大数据的整个架构,你发现开源开始的时候,建立出来的Hadoop底层,包含HDFS、Yarn、MapReduce这三个组件。它们为什么归到Hadoop里面呢,它不是没有道理的。这三个产品,其实就是一个分布式的操作系统。
在Hadoop之上再去装其他组件,不管是Hive,还是Malhot,按照不同的应用场景进行搭建就可以。
大数据发展的预测与延伸
之后我们大数据怎么去发展?如果之后大数据它的底层,有完全的一个分布式操作系统可以直接装在物理机上,装在我们硬件上,它的性能会更加出色。
现在的话是硬件服务器上去安装一个单机的操作系统,不管它是CentOS还是Ubuntu,安装起来之后再去部署我们的大数据的一个分布式操作系统,也就是Hadoop。
这样的话,因为中间隔了一层操作系统,所以的话它的性能并不是发挥到极致的。
如果之后有这样的一个趋势,就可以直接在裸机硬件上,直接安装分布式的操作系统;这三层直接以OS的形式,装在硬件上,折损就会更小一些。
OK,我们这一块的架构就给大家分享到这里,谢谢大家。B站配套传送门:类比一下,秒懂大数据模式
版权归原作者 桥路丶 所有, 如有侵权,请联系我们删除。