
文章目录
Load加载数据
- 在之前的建表之后,我们可以通过在hdfs中传入数据文档,实现数据加载的效果,但是这种方式并不是官方推荐的方式,Hive官方推荐的是Load加载数据到表中。
Load语法功能
- Load加载是指将数据文件移动到与Hive表对应的位置,移动时是纯复制、移动操作。纯复制、移动指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作。
- Load语法规则
LOADDATA[LOCAL] INPATH 'filepath'[OVERWRITE]INTOTABLE tablename;
Load语法规则讲解
- filepath表示待移动数据的路径。可以指向文件(在这种情况下,Hive将文件移动到表中),也可以指向目录(在这种情况下,Hive将把该目录中的所有文件移动到表中)。
- filepath文件路径支持下面三种形式,要结合LOCAL关键字一起考虑:- 相对路径- 绝对路径- 具有schema的完整URI
- Local是在本地文件系统中查找文件路劲,这个本地并不是客户端,而是hiveserver2服务所在机器的本地Linux系统。没有指定local的话如果filepath指向的是一个完整的uri,会直接使用这个URI,如果也没有schema,Hive会使用Hadoop配置文件中fs.default.name指定。
Load示例
- 建表
--建表student_local用于演示从本地加载数据CREATETABLE student_local(
num int,
name string,
sex string,
age int,
dept string)ROW FORMAT delimited fieldsterminatedBY',';--建表student_hdfs用于演示从HDFS加载数据CREATETABLE student_hdfs(
num int,
name string,
sex string,
age int,
dept string)ROW FORMAT delimited fieldsterminatedBY',';
- 加载数据
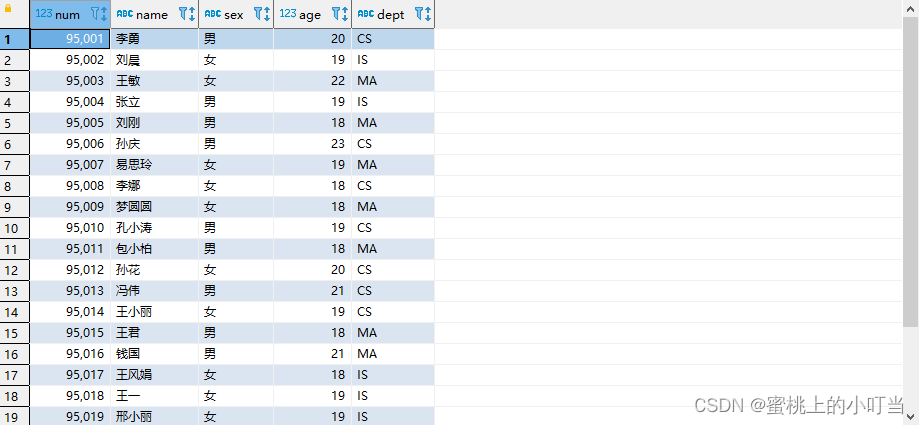
-- 从本地加载数据,数据位于Hiveserver2(node1)本地文件系统 本质是hadoop fs -put上传操作LOADDATALOCAL INPATH '/root/hivedata/students.txt'INTOTABLE student_local;SELECT*FROM student_local;
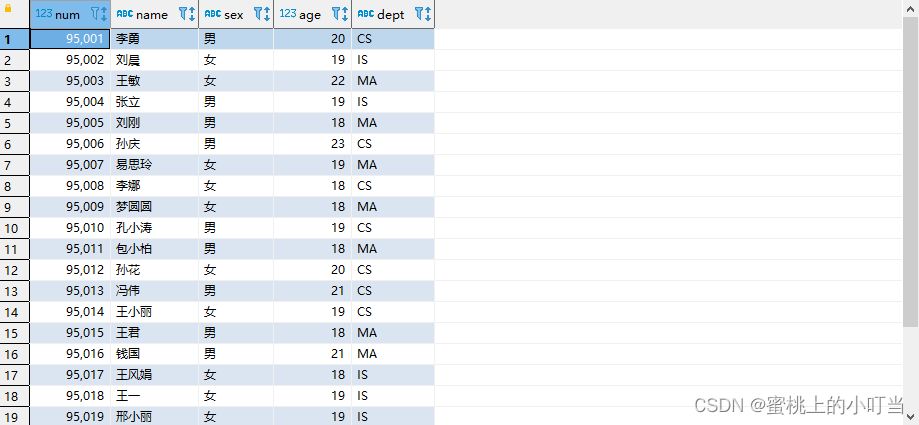

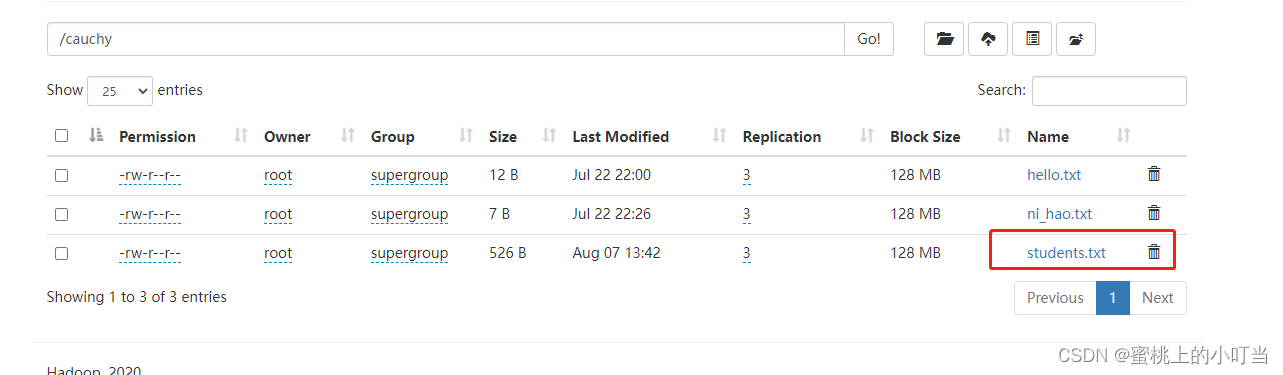
--从HDFS加载数据 数据位于HDFS文件系统根目录下 本质是hadoop fs -mv 移动操作--先把数据上传到HDFS上 hadoop fs -put /root/hivedata/students.txt /cauchy/LOADDATA INPATH '/cauchy/students.txt'INTOTABLE student_hdfs;
- 加载前数据还在cauchy文件夹中
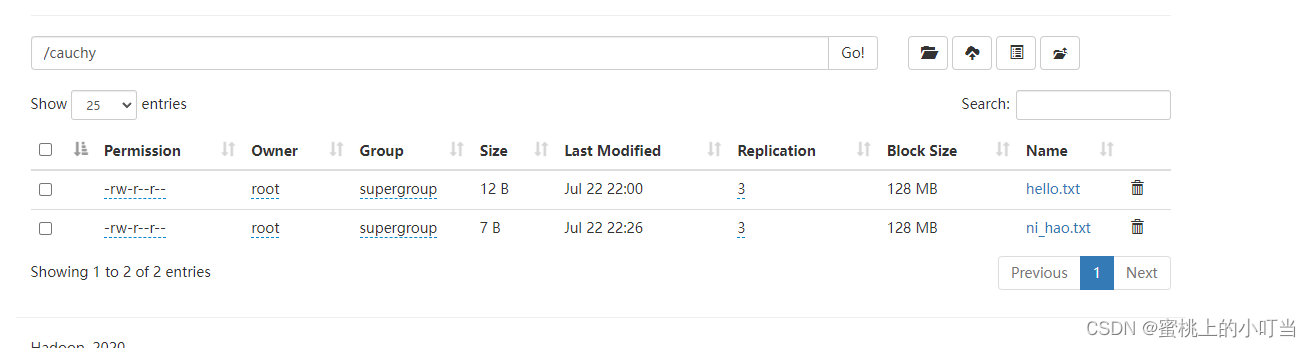
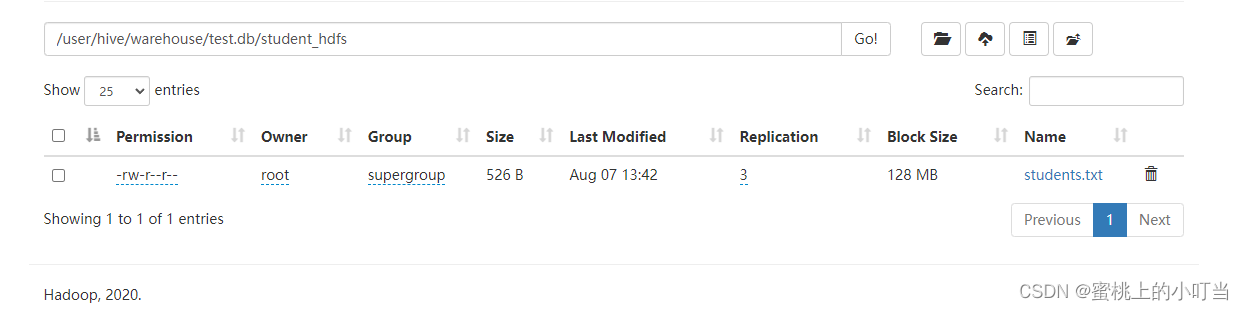
- 加载后数据文件移动到/user/hive/warehouse/test.db/student_hdfs中
- TIPS:如果再次load数据到表中默认是追加,如果使用overwrite into则表示覆盖之前的数据。
INSERT插入语句
- 如果是用标准SQL进行插入操作,则会导致过程及其缓慢,插入一条数据会执行Hadoop底层的MapReduce操作,如果使用insert进行数据插入可以使用insert语法把数据插入到指定的表中,最常用的配合是把查询返回的结果插入到另一张表中。
INSERT语法规则讲解
- INSERT+SELECT是将后面查询返回的结果作为内容插入到指定表中。
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致。
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL。
- INSERT+SELECT语法规则
INSERTINTOTABLE tablename select_statement1 FROM from_statement;
Insert+Select示例
- 创建一张student表
CREATETABLE student(
num int,
name string,
sex string,
age int,
dept string)ROW FORMAT delimited fieldsterminatedBY',';
- 加载数据
LOADDATALOCAL INPATH '/root/hivedata/students.txt'INTOTABLE student;
- 创建一张student_insert表
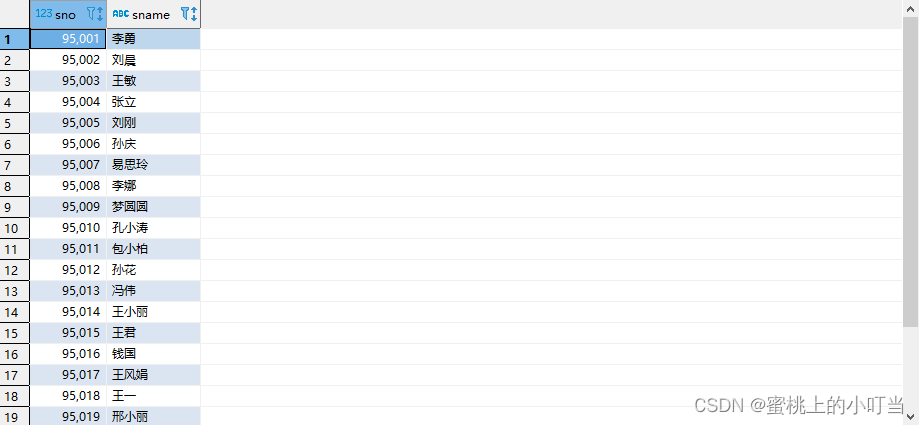
CREATETABLE student_insert(sno int, sname string);
- 使用insert+select插入数据到新表中
INSERTINTOTABLE student_insert SELECT num, name FROM student;
SELECT查询语句
- Select语法规则
SELECT[ALL|DISTINCT] select_expr, select_expr,...FROM table_reference
[WHERE where_condition][GROUPBY col_list][ORDERBY col_list][LIMIT[offset,]rows];
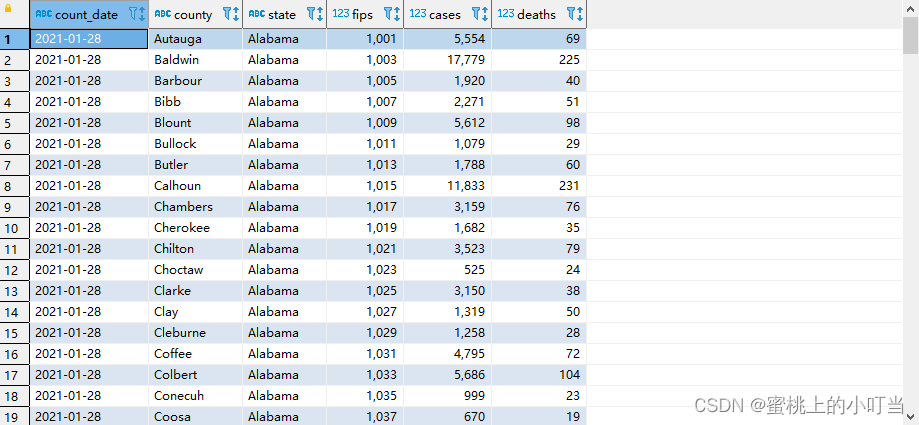
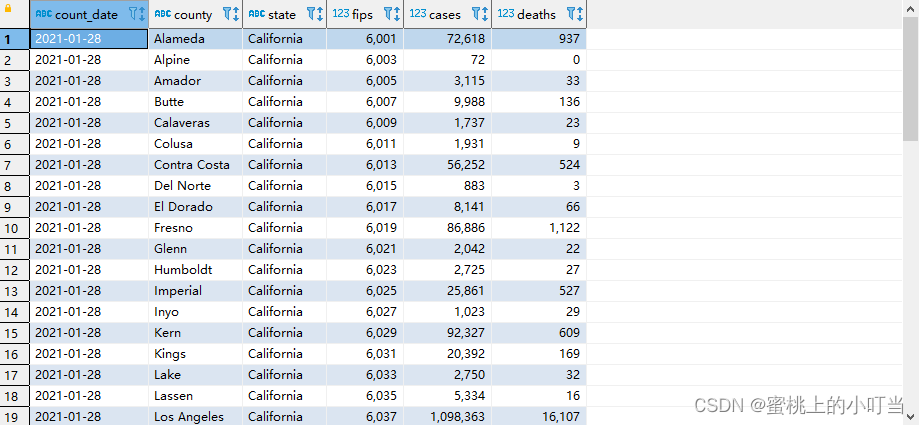
- 数据准备us-covid19数据集
--创建表t_usa_covid19CREATETABLE t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)row format delimited fieldsterminatedBY',';--将数据load加载到t_usa_covid19表对应的路径下LOADDATALOCAL INPATH '/root/hivedata/us-covid19-counties.dat'INTOTABLE t_usa_covid19;
简单的SELECT语句
- select_expr(column)表示检索查询返回的列,必须至少有一个select_expr。
--查询所有字段或者指定字段select*from t_usa_covid19;select county, cases, deaths from t_usa_covid19;--查询当前数据库select current_database();--省去from关键字
ALL DISTINCT(去重)语句
- 如果没有给出这些选项,则默认值为ALL(返回所有匹配的行)。
- DISTINCT指定从结果集中删除重复的行。
--返回所有匹配的行两者相同select state from t_usa_covid19;selectall state from t_usa_covid19;--返回所有匹配的行,去除重复的结果selectdistinct state from t_usa_covid19;--多个字段distinct是整体去重selectdistinct county,state from t_usa_covid19;
WHERE条件过滤
- WHERE后面是一个布尔表达式(结果要么为true,要么为false),用于查询过滤,当布尔表达式为true时,返回select后面expr表达式的结果,否则返回空。
- 在WHERE表达式中,可以使用Hive支持的任何函数和运算符,但聚合函数除外。
- 特殊条件(空值判断、between、in)与标准SQL语法用法相似。
--找出来自于California州的疫情数据select*from t_usa_covid19 where state ='California';--where条件中使用函数 找出州名字母长度超过10位的有哪些select*from t_usa_covid19 where length(state)>10;
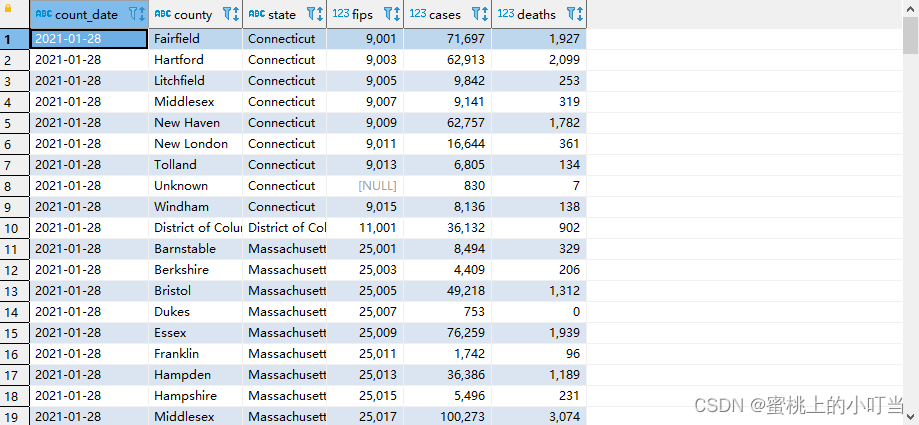
聚合操作
- SQL中拥有很多可用于计数和计算的内建函数,其使用的语法是:SELECT function(列) FROM 表。
- 常见聚合(Aggregate)操作函数有Count、Sum、Max、Min、Avg等函数。
- 聚合函数的最大特点是不管原始数据有多少行记录,经过聚合操作只返回一条数据,这一条数据就是聚合的结果。
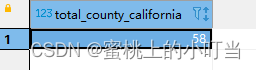
--统计美国总共有多少个县county--as给查询返回的结果起个别名selectcount(county)as county_cnts from t_usa_covid19;--去重distinctselectcount(distinct county)as county_cnts from t_usa_covid19;--统计美国加州有多少个县selectcount(county)as total_county_California from t_usa_covid19 where state ="California";
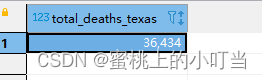
--统计德州总死亡病例数selectsum(deaths)as total_deaths_Texas from t_usa_covid19 where state ="Texas";
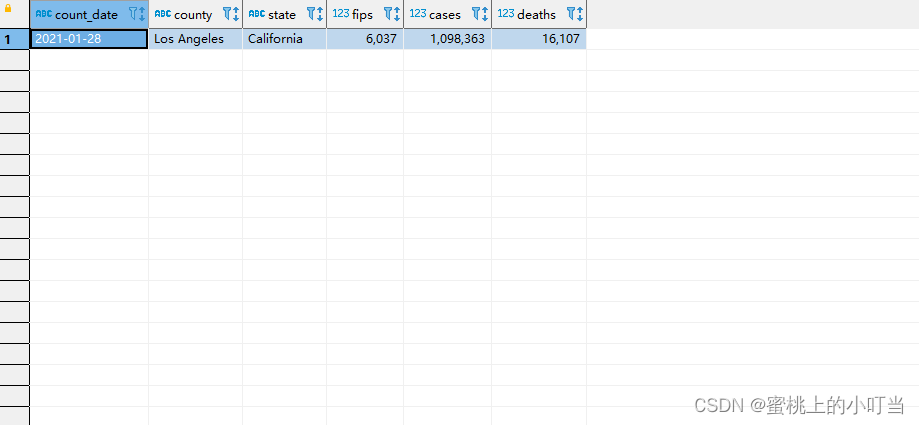
--统计出美国最高确诊病例数是哪个县selectmax(cases)as max_cases_county from t_usa_covid19;--这个比较高级了SELECT*FROM t_usa_covid19 where cases=(selectmax(cases)as max_cases_county from t_usa_covid19);
GROUP BY分组
- GROUP BY语句用于结合聚合函数,根据一个或多个列对结果集进行分组;
- GROUP BY语法限制 - 在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段。原因是避免出现一个字段多个值的歧义。- 分组字段出现select_expr中,一定没有歧义,因为就是基于该字段分组的,同一组中必相同。- 被聚合函数应用的字段,也没歧义,因为聚合函数的本质就是多进一出,最终返回一个结果。
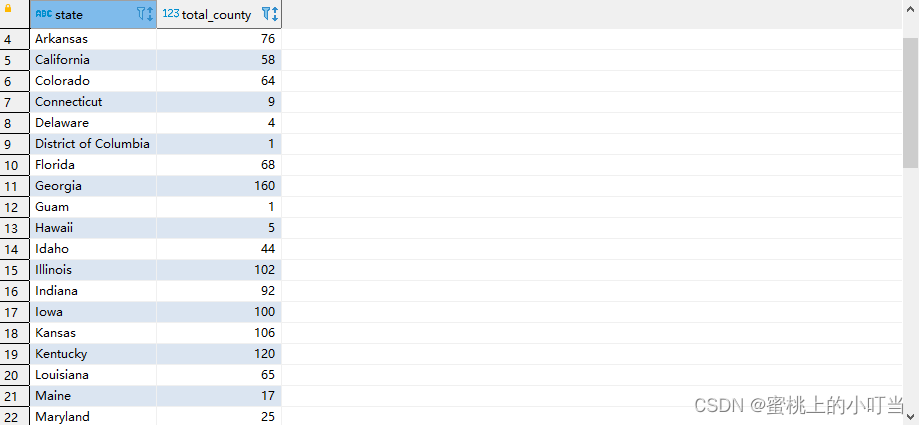
--根据state州进行分组 统计每个州有多少个县countyselect state,count(county)as total_county from t_usa_covid19 groupby state;
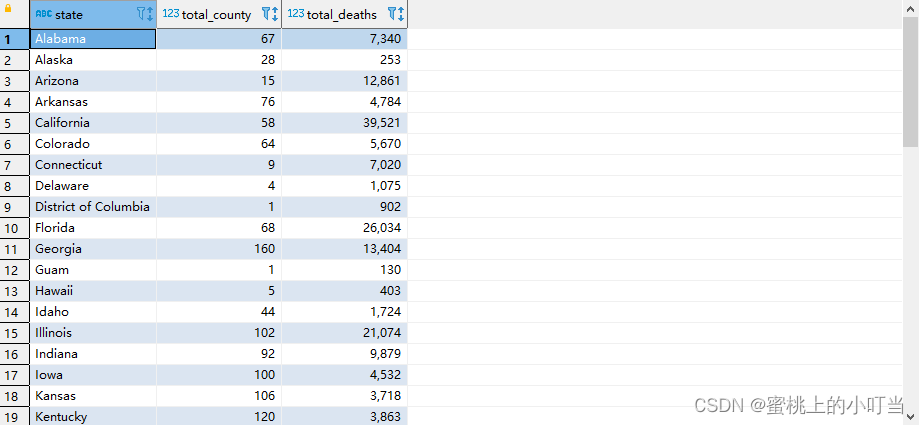
-- 根据state州进行分组 统计每个州有多少个县county并计算死亡人数总和select state,count(county)as total_county,sum(deaths)as total_deaths from t_usa_covid19 groupby state;
HAVING过滤语句
- 在SQL中增加HAVING子句原因是,WHERE关键字无法与聚合函数一起使用。
- HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where,group by已经执行结束,结果集已经确定
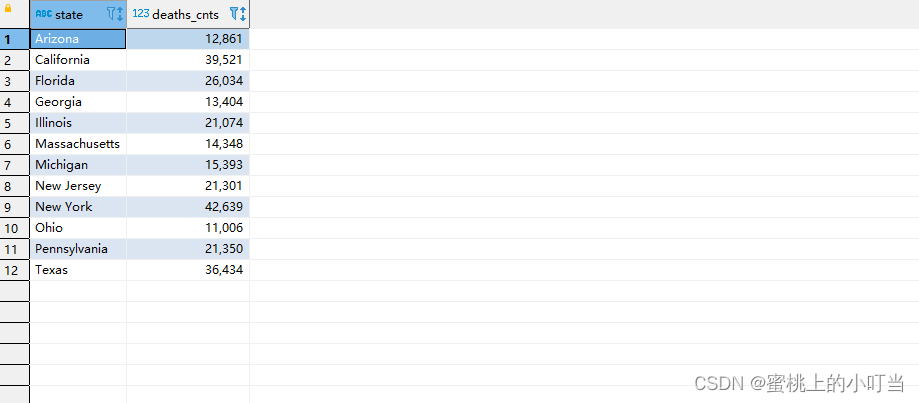
--统计2021-01-28死亡病例数大于10000的州--先where分组前过滤,再进行group by分组, 分组后每个分组结果集确定 再使用having过滤select state,sum(deaths)as deaths_cnts from t_usa_covid19 where count_date ="2021-01-28"groupby state havingsum(deaths)>10000;--这样写更好 即在group by的时候聚合函数已经作用得出结果 having直接引用结果过滤 不需要再单独计算一次了select state,sum(deaths)as deaths_cnts from t_usa_covid19 where count_date ="2021-01-28"groupby state having deaths_cnts>10000;
ORDER BY升降序语句
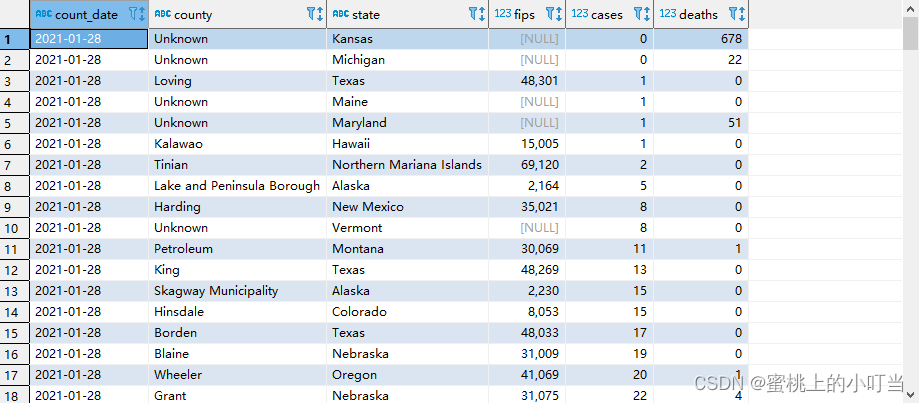
--根据确诊病例数升序排序 查询返回结果(默认就是asc升序)select*from t_usa_covid19 orderby cases;select*from t_usa_covid19 orderby cases asc;
--根据死亡病例数倒序排序 查询返回加州每个县的结果select*from t_usa_covid19 where state ="California"orderby cases desc;
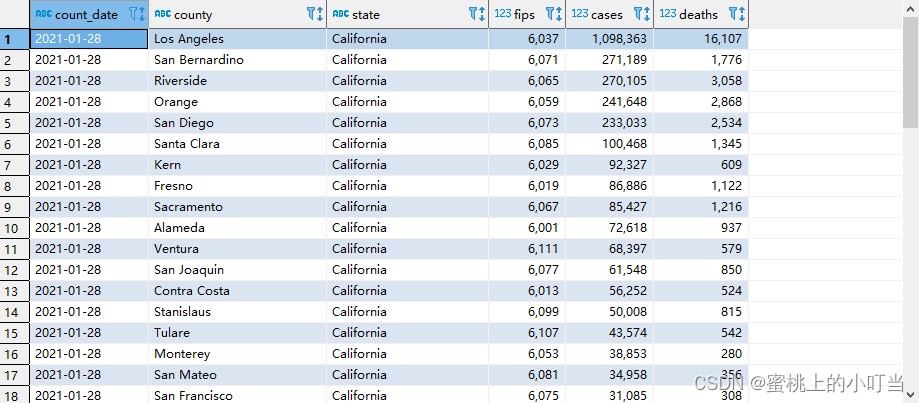
LIMIT限制语句
- LIMIT用于限制SELECT语句返回的行数。
- LIMIT接受一个或两个数字参数,这两个参数都必须是非负整数常量。
- 第一个参数指定要返回的第一行的偏移量(从 Hive 2.0.0开始),第二个参数指定要返回的最大行数。当给出单个参数时,它代表最大行数,并且偏移量默认为0。
--没有限制返回2021.1.28 加州的所有记录,返回结果集的前5条select*from t_usa_covid19 where count_date ="2021-01-28"and state ="California"limit5;
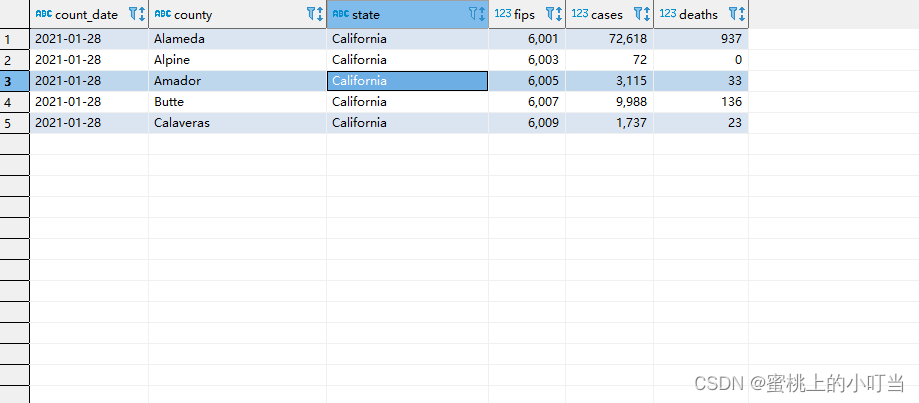
--返回结果集从第3行开始 共3行select*from t_usa_covid19 where count_date ="2021-01-28"and state ="California"limit2,3;
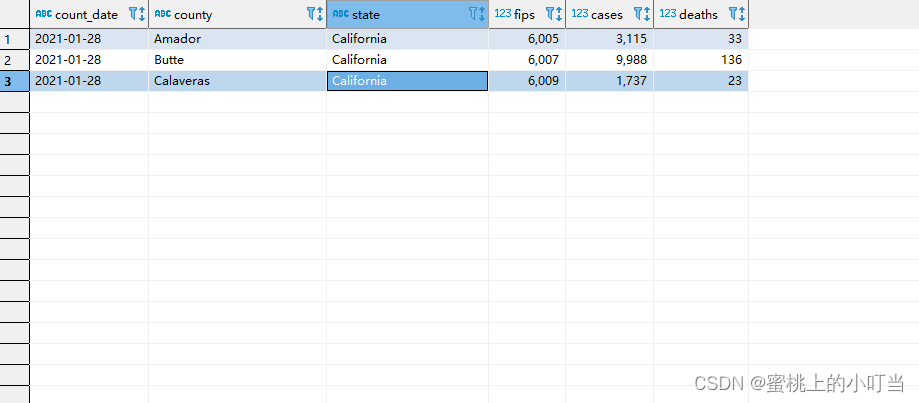
SELECT执行顺序
- 顺序:from > where > group(含聚合)> having >order > select。
本文转载自: https://blog.csdn.net/sinat_31854967/article/details/126208891
版权归原作者 蜜桃上的小叮当 所有, 如有侵权,请联系我们删除。
版权归原作者 蜜桃上的小叮当 所有, 如有侵权,请联系我们删除。