
三连支持 一起鼓励 一起进步
zookeeper
文章目录
一、概述
首先,在分布式架构中,任何的节点都不能以单点的方式存在,因此我们需要解决单点的问
题。常见的解决单点问题的方式就是集群
大家来思考一下,这个集群需要满足那些功能?
- 集群中要有主节点和从节点(也就是集群要有角色)
- 集群要能做到数据同步,当主节点出现故障时,从节点能够顶替主节点继续工作,但是继 续工作的前提是数据必须要主节点保持一直
- 主节点挂了以后,从节点如何接替成为主节点? 是人工干预?还是自动选举 所以基于这几个点,我们先来把 zookeeper 的集群节点画出来。
1.Leader 角色
Leader 服务器是整个 zookeeper 集群的核心,主要的工作任务有两项
- 事物请求的唯一调度和处理者,保证集群事物处理的顺序性
- 集群内部各服务器的调度者
2.Follower 角色
Follower 角色的主要职责
- 处理客户端非事物请求、转发事物请求给 leader 服务器
- 参与事物请求 Proposal 的投票(需要半数以上服务器通过才能通知 leader commit 数据; Leader 发起的提案,要求 Follower 投票)
- 参与 Leader 选举的投票
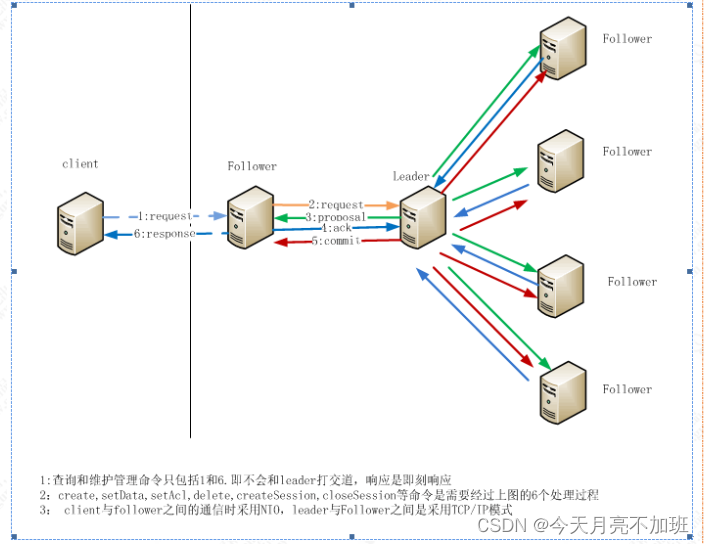
3.数据同步
leader 节点如何和其他节点保证数据一致性,并且要求是强一致的。在分布式系统中,每一
个机器节点虽然都能够明确知道自己进行的事务操作过程是成功和失败,但是却无法直接获
取其他分布式节点的操作结果。所以当一个事务操作涉及到跨节点的时候,就需要用到分布
式事务,分布式事务的数据一致性协议有 2PC 协议和 3PC 协议
4. 2PC提交
(Two Phase Commitment Protocol)当一个事务操作需要跨越多个分布式节点的时候,为
了保持事务处理的 ACID 特性,就需要引入一个“协调者”(TM)来统一调度所有分布式节点
的执行逻辑,这些被调度的分布式节点被称为 AP。TM 负责调度 AP 的行为,并最终决定这
些 AP 是否要把事务真正进行提交;因为整个事务是分为两个阶段提交,所以叫 2pc
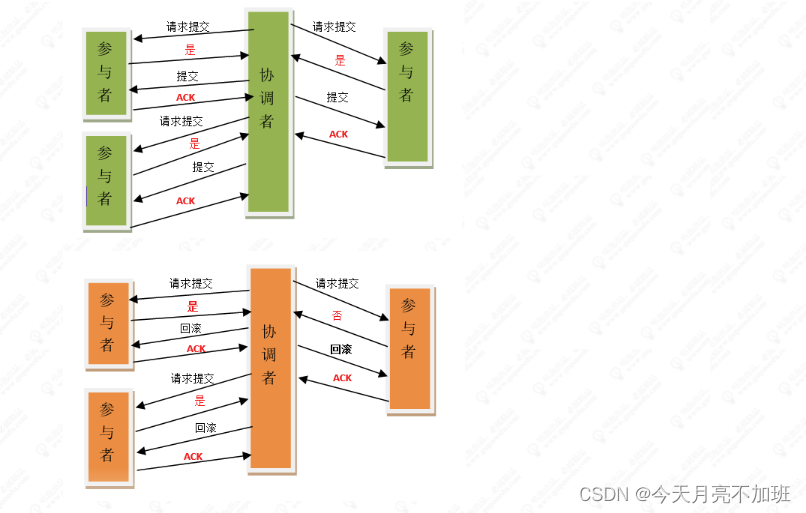
阶段一:提交事务请求(投票)
- 事务询问 协调者向所有的参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者的 响应
- 执行事务 各个参与者节点执行事务操作,并将 Undo 和 Redo 信息记录到事务日志中,尽量把提交过程中 所有消耗时间的操作和准备都提前完成确保后面 100%成功提交事务
- 各个参与者向协调者反馈事务询问的响应 如果各个参与者成功执行了事务操作,那么就反馈给参与者 yes 的响应,表示事务可以执行; 如果参与者没有成功执行事务,就反馈给协调者 no 的响应,表示事务不可以执行,上面这个阶 段有点类似协调者组织各个参与者对一次事务操作的投票表态过程,因此 2pc 协议的第一个阶 段称为“投票阶段”,即各参与者投票表名是否需要继续执行接下去的事务提交操作。
阶段二:执行事务提交
在这个阶段,协调者会根据各参与者的反馈情况来决定最终是否可以进行事务提交操作,正常情况
下包含两种可能:执行事务、中断事务
5. Observer 角色
Observer 是 zookeeper3.3 开始引入的一个全新的服务器角色,从字面来理解,该角色充当
了观察者的角色。
1.观察 zookeeper 集群中的最新状态变化并将这些状态变化同步到 observer 服务器上。
2.Observer 的工作原理与 follower 角色基本一致,而它和 follower 角色唯一的不同在于observer 不参与任何形式的投票,包括事物请求 Proposal 的投票和 leader 选举的投票。简单来说,observer 服务器只提供非事物请求服务,通常在于不影响集群事物处理能力的前提
下提升集群非事物处理的能力
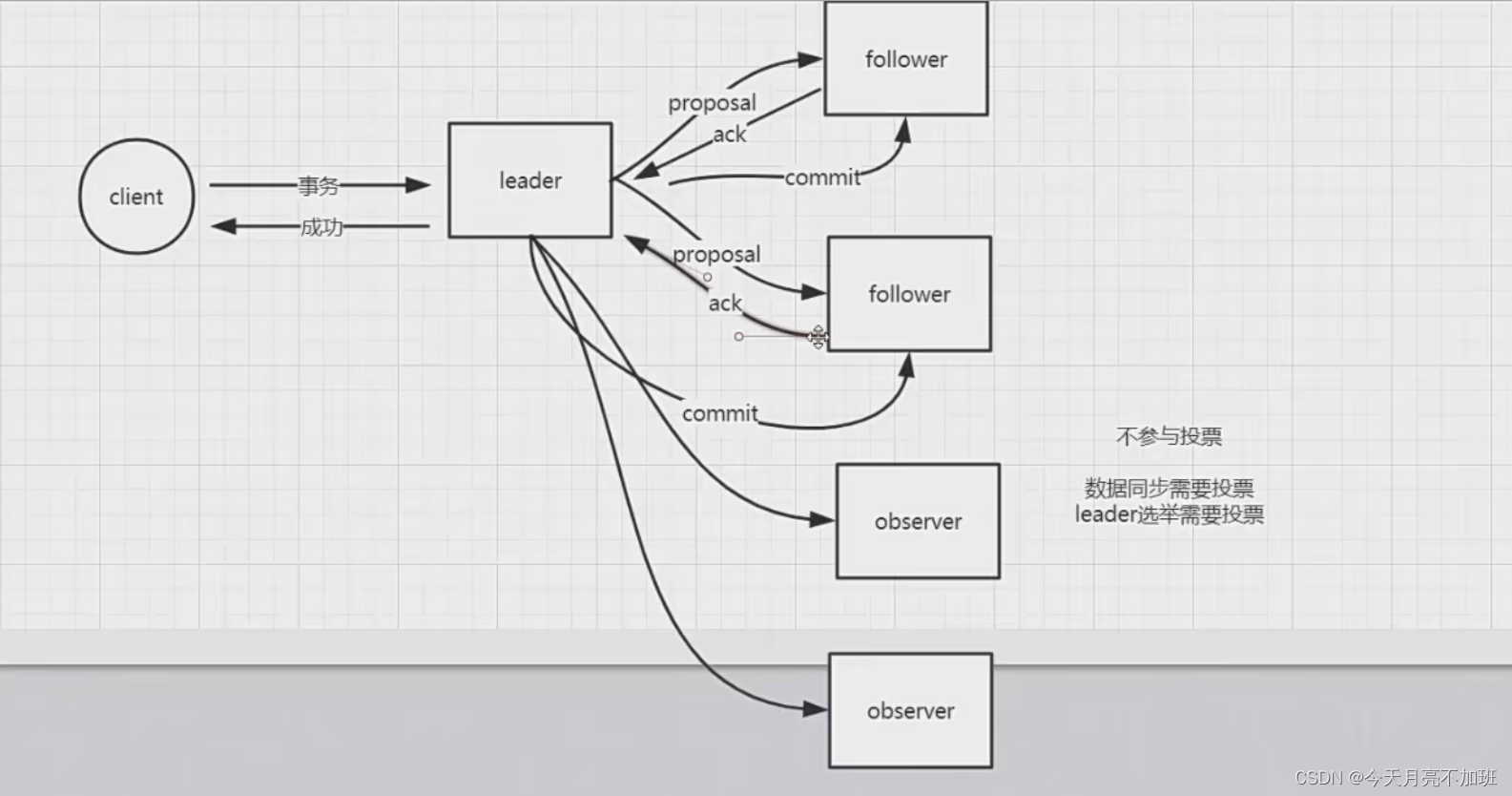
6. leader 选举
当 leader 挂了,需要从其他 follower 节点中选择一个新的节点进行处理,这个时候就需要涉及到 leader 选举从这个过程中,我们推导处了 zookeeper 的一些设计思想
7. 集群组成
1.通常 zookeeper 是由 2n+1 台 server 组成,每个 server 都知道彼此的存在。每个 server 都
维护的内存状态镜像以及持久化存储的事务日志和快照。对于 2n+1 台 server,只要有 n+1
台(大多数)server 可用,整个系统保持可用。我们已经了解到,一个 zookeeper 集群如果
要对外提供可用的服务,那么集群中必须要有过半的机器正常工作并且彼此之间能够正常通
信,基于这个特性,如果向搭建一个能够允许 F 台机器 down 掉的集群,那么就要部署 2*F+1
台服务器构成的 zookeeper 集群。因此 3 台机器构成的 zookeeper 集群,能够在挂掉一台
机器后依然正常工作。一个 5 台机器集群的服务,能够对 2 台机器怪调的情况下进行容灾。
如果一台由 6 台服务构成的集群,同样只能挂掉 2 台机器。因此,5 台和 6 台在容灾能力上
并没有明显优势,反而增加了网络通信负担。系统启动时,集群中的 server 会选举出一台
server 为 Leader,其它的就作为 follower(这里先不考虑 observer 角色)。
2.之所以要满足这样一个等式,是因为一个节点要成为集群中的 leader,需要有超过及群众过
半数的节点支持,这个涉及到 leader 选举算法。同时也涉及到事务请求的提交投票
6. 惊群效应

惊群效应推荐博文:https://blog.csdn.net/aazhzhu/article/details/89967346
二、Curator
Curator是Netflix公司开源的一套Zookeeper客户端框架。了解过Zookeeper原生API都会清楚其复杂度。Curator帮助我们在其基础上进行封装、实现一些开发细节,包括接连重连、反复注册Watcher和NodeExistsException等。目前已经作为Apache的顶级项目出现,是最流行的Zookeeper客户端之一。
三、应用场景
https://blog.csdn.net/qq_36679460/article/details/127234985
总结
版权归原作者 今天月亮不加班 所有, 如有侵权,请联系我们删除。