
一、概念
1.、有了HDFS为什么还需要HBase?
(1)HDFS和HBase都是Hadoop生态系统中的组件,但它们的设计目标和用途有所不同。
(2)HBase更注重操作。假如要对HDFS上存储的海量数据进行增删改查,要往里面删除里面某一行的数据,还要精确的查询某一行数据,这是hdfs做不到的,所以有了HBase。
2.Hhbase基础概况
(1)HBase是谷歌BigTable的开源实现,BigTable是一个分布式存储系统。
(2)单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]。
(3)时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引(就跟抽卡记录一样用时间做主键)。
(4)Hbase本质也是键值对(KV对),只不过其中的键是一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳]。
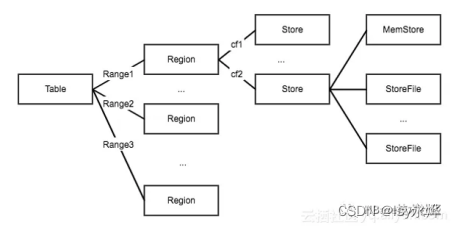
(5)Region是HBase中表数据分布和访问的基本单位。
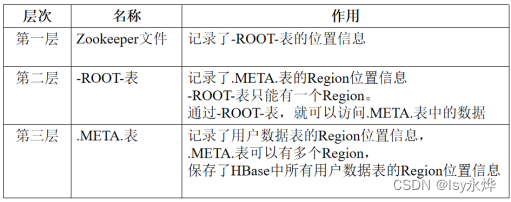
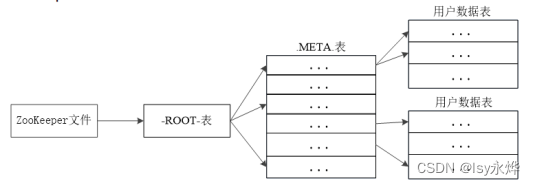
(6)HBase的三层结构(也可以由此知道Region的查询过程就是依次查询这三个表):
3.具体操作:
(1)存储数据:
首先将数据保存在内存中(称为MemStore)。好处是,当数据还在内存中时,读写操作都非常快。
一旦MemStore满了,HBase就会将这些数据“刷新”到HDFS上,形成一个叫做HFile的文件。确保了即使在数据量很大的情况下,HBase也能保持较高的写入性能。
(2)读取数据:
首先检查MemStore中是否有需要的数据。
有,就直接从内存中读取,非常快。没有,HBase就会去HDFS上的HFile中查找。
为了加速这个过程,使用了“布隆过滤器”的技术,可以快速判断一个数据是否可能存在于某个HFile中,从而避免不必要的磁盘IO操作。
(3)更新和删除数据:
由于HDFS不支持数据的直接修改,所以与传统不同,HBase实际上是通过在MemStore和HFile中记录新的数据版本来实现更新和删除的。
(4)数据索引和查询:
HBase使用“行键”索引机制来快速定位数据。
每个HBase表都有一个唯一的行键,类似传统数据库中的主键,因此可以迅速找到存储在HDFS上的对应数据。此外,HBase还支持通过列族和列限定符进行更细粒度的数据查询。
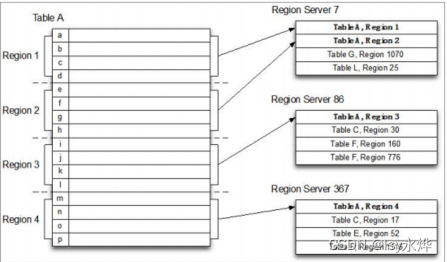
4.Region
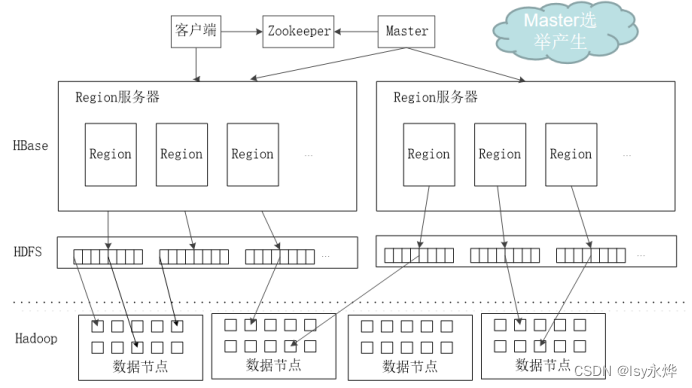
(1)主服务器Master负责管理和维护HBase表的分区信息,维护、分配Region服务器。
(2)Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求。
注意Region服务器和Region不是一个东西。
(3)客户端并不是直接从Master主服务器上读取数据,而是通过Zookeeper获得Region的存储位置信息后,直接从Region服务器上读取数据。
除此之外,Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时,Zookeeper会通知Master。
(4)一个表根据RowKey切分成HRegion分散存储在不同的HRS中,一个HRS中可以有多个不同的HRegion(可以是来自不同的表)
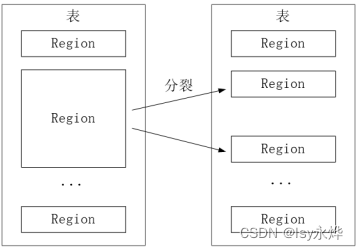
(5)开始只有一个Region,后来不断分裂
(6) Region服务器中配备了一个HLog文件,所有更新的数据都需要先计入此文件才能写入缓存。(7)和其他结构的关系:
5.系统架构:
二、HBase相关代码(重点)
1.create:创建表。
2.list:列出HBase中所有的表信息,就是把所有表列出来。
3.put:向表、行、列指定的单元格添加数据。
4.get:通过指定表名、行、列、时间戳、时间范围和版本号来获得相应单元格的值。
4.scan:查看表内的信息。
5.alter:修改列族模式(但是是添加列名,不是“修改列名”,当然也可以用于删除,需要用method指定为delete)。
三、习题
大题
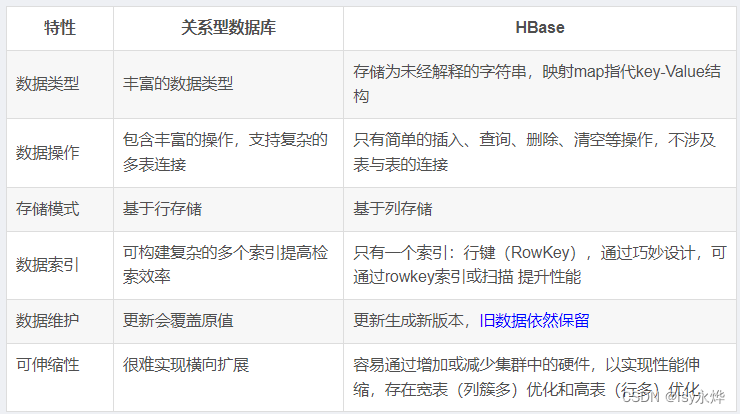
关系型数据库和HBase有什么区别?
答:
纵向扩展就是单个电脑变牛逼,横向就是能让更多弱小的电脑团结起来!
单选题
- HBase用来实现高可靠的底层存储的是()
A. HDFS B. MapReduce C. BigTable D. Hive
正确答案: A
- HBase中表的行是根据谁的值的字典序进行维护的?()
A. 行键 B. 列族 C. 列限定符 D. 单元格
正确答案: A
- 下列说法不正确的是()
A. Region是根据表中行的主键进行的分区
B. HBase查找用户Region时需要先去HMaster查找Root表地址
C. Region拆分操作非常快,接近瞬间,因为拆分之后的Region读取的仍然是原存储文件。
D. ZooKeeper为HBase集群中各进程提供分布式协作服务。各RegionServer将自己的信息注册到Zookeeper中,主用Master据此感知各个RegionServer的健康状态。
正确答案: B
- HBase用来处理HBase中海量数据的是()
A. Spark B. MapReduce C. BigTable D. Hive
正确答案: B
MapReduce就是HDFS的核心
- Region服务器中配备了一个()文件,所有更新的数据都需要先计入此文件才能写入缓存。
A. MemStore B. EditLog C. StoreFile D. HLog
正确答案: D
- HBase用来实现稳定服务和失败回复,作为协同服务的是()
A. Pig B. Hive C. Tez D. ZooKeeper
正确答案: D
- HBase中每个Region都有一个()来标识它的唯一性。
A. Region名 B. RegionID C. 表名 D. 开始主键
正确答案: B
- 用户读取数据时,需要先访问(),找不到数据时,才去磁盘上寻找。
A. MemStore B. EditLog C. StoreFile D. HLog
正确答案: A
- HBase是下列哪种类型的数据库?()
A. 键值 B. 关系 C. 列族 D. 文档
正确答案: C
- HBase是针对()的开源实现。
A. Spark B. MapReduce C. BigTable D. Hive
正确答案: C
多选题
1.下列各项中,HBase用来进行单元格定位需要的有()
A. 行键 B. 列族 C. 列限定符 D. 时间戳
正确答案: A, B, C, D
- 下列说法正确是()
A. 每个Region服务器只有一个HLog文件,所有Region对象共用一个HLog。
B. StoreFile文件过多时需要合并,文件过大时需要分裂。
C. HMaster负责表和Region的管理工作,负载很低。
D. RegionServer负责维护分配给自己的Region,并响应用户读写请求。
正确答案: A, B, C, D
9.下列各项中,属于三级寻址需要访问到的有()
A. ZooKeeper B. -ROOT-表 C. .META表 D. HMaster
正确答案: A, B, C
14.下列各项中,组成Region标识符的是()
A. 表名 B. 开始主键 C. RegionID D. 时间戳
正确答案: A, B, C
这个上面没说Region的构成,确实没找到,是漏掉的知识点。
- 下列属于正确的是()
A. Region中有多个Store,每个Store对应一个列族的存储
B. 每个Store中只有一个MemStore,作为内存中的缓存,保存最近更新的数据
C. 每个Store中有个StoreFile文件
D. MemStore中的数据会周期性地刷新到磁盘中形成StoreFile。
正确答案: A, B, C, D
大题
- **create 'student',{NAME=>'info'}**解释:在HBase中创建一个名为
student的表,并添加一个列族info。- **put 'student','2301001','info','Elle'**解释:在HBase表
student中,为行键2301001的行添加或更新列info的值为Elle。- **get 'student','2301001','info'**解释:从HBase表
student中获取行键2301001的行的info列族的值。- **scan 'student',{COLUMNS=>'info'}**解释:扫描HBase表
student并显示所有行中info列族的值。- **alter 'student',NAME=>'score'**解释:修改HBase表
student,添加一个新的列族score。注意NAME是属于关键字,表示列名的意思。
版权归原作者 lsy永烨 所有, 如有侵权,请联系我们删除。