
课题简介
网络电影平台拥有大量的影片库资源,每天数千万用户活跃在平台上,拥有数亿人次的用户点击试看、收藏等行为。在影视作品方面,更是拥有数万的影视作品形成作品库,如此庞大的数据资源库对于电影及电视剧流行趋势的把握有着极为重要的指引作用。通过设计和实现基于Hadoop的影视数据分析系统,可以为影视产业提供重要的数据支持和决策方向,帮助影视从业者更好地了解观众需求、优化内容创作、改进营销策略,提高影视作品的商业成功率和用户满意度。同时,该系统也为研究人员和学者提供了一个丰富的数据资源,用于对影视产业进行深入研究和分析。
过程要求
1、搭建Hadoop分布式系统环境。
2、爬取某网站电影名、评论数、评分、评论、国家、类型、年份等数据,存储到HDFS。
3、数据清洗,去掉缺失值、空值等,做必要的数据转换.
4、MapReduce数据分析,分析维度:所属国家、类型、评论量、评分、等多个维度统计分析。
5、通过数据可视化技术,将复杂的影视数据以直观的图像呈现,并展示流行趋势预测结果。
使用技术
Hadoop、MySQL、Python、Pandas、Java、SpringBoot、Html、JS、CSS、Echarts
使用软件
VMware Workstation、MobaXterm、Idea、DBeaver
1 搭建Hadoop分布式系统环境
这里我们使用Hadoop完全分布式,搭建过程不再描述,可以在网上搜索教程。
1.启动三台虚拟机
2.开启hadoop集群
用MobaXterm图形界面用户操作工具连接虚拟机,启动hadoop集群:
在配置了 NameNode 的节点(node1)启动 HDFS:
[root@node1 ~]# start-dfs.sh
在配置了 ResourceManager 的节点(node2)启动 YARN
[root@node2 ~]$ start-yarn.sh
(下图启动方式是设置了一键启动脚本)
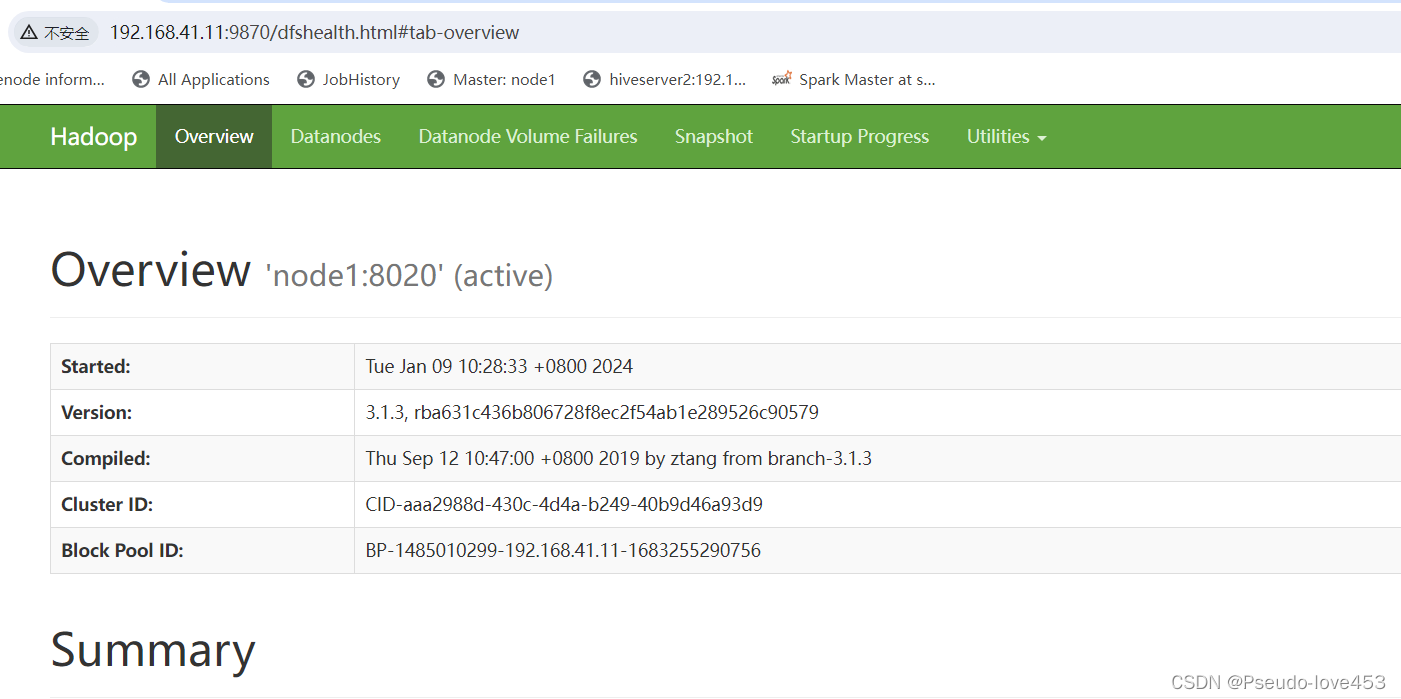
3.确认网页能打开
2 爬虫爬取数据集
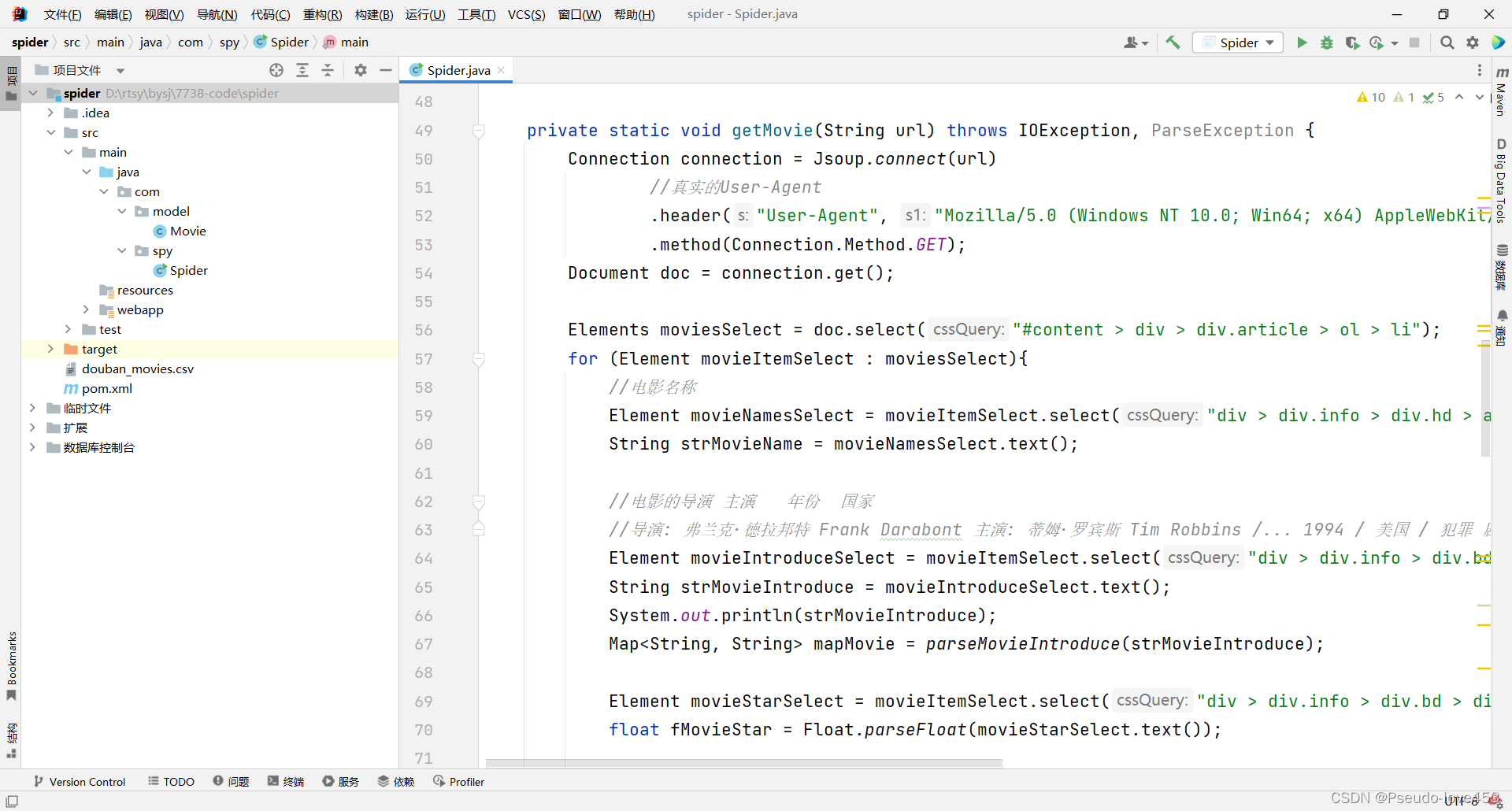
1.编写Java程序
这里我们使用Java代码爬取豆瓣评分前250名电影数据
目标网站:豆瓣电影 Top 250 (douban.com)
爬取字段:电影名字、国家、年份、简介、类型、评分、评论数量
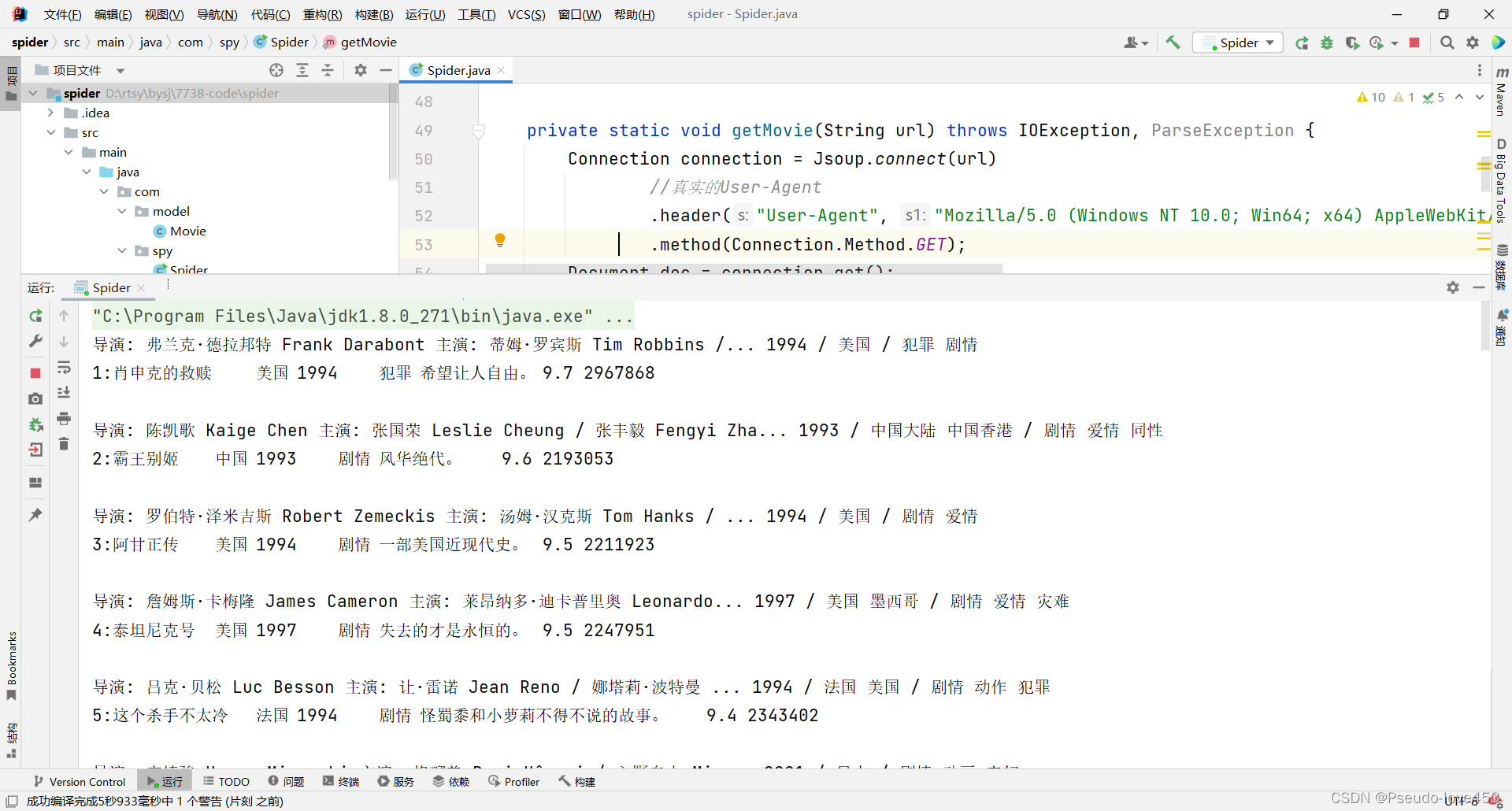
2.运行Java程序
爬虫已开始,等待程序爬完即可
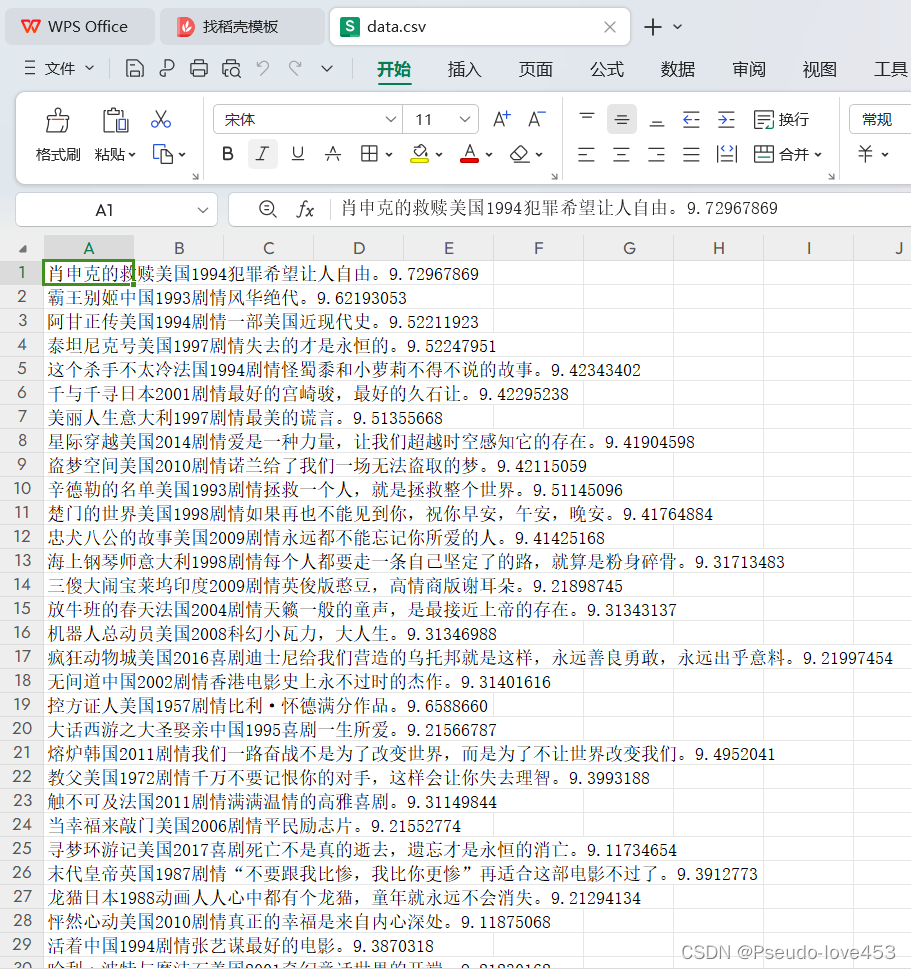
3.数据展示
爬完后保存为csv文件到本地
4.上传数据
再将该csv文件上传到HDFS,将本地文件上传到HDFS可以直接用鼠标拖拽到虚拟机里,然后再通过shell命令上传至HDFS,也可以通过Java代码直接连接HDFS将本地文件上传到HDFS
点击运行创建文件和上传文件Test
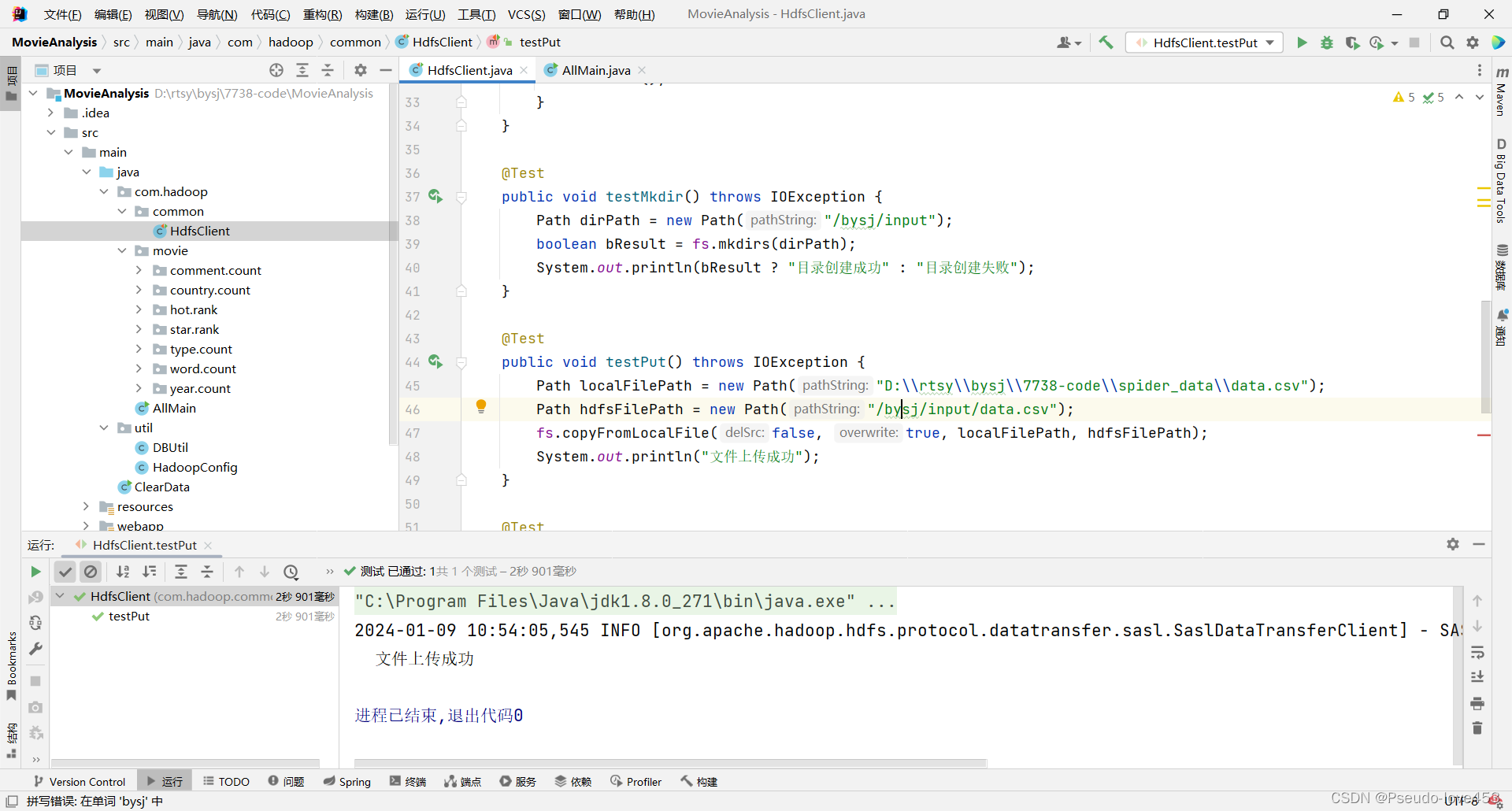
5.结果展示
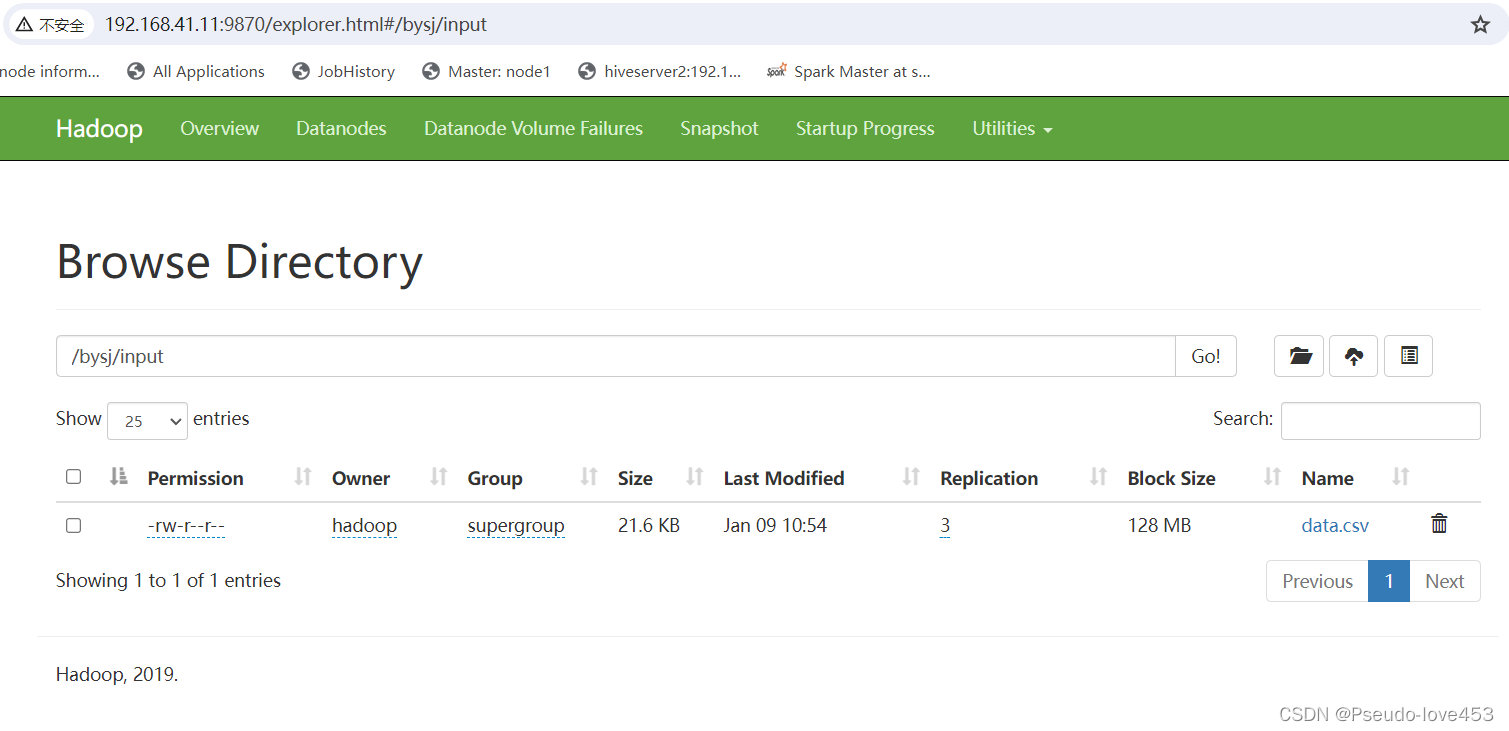
3 数据清洗
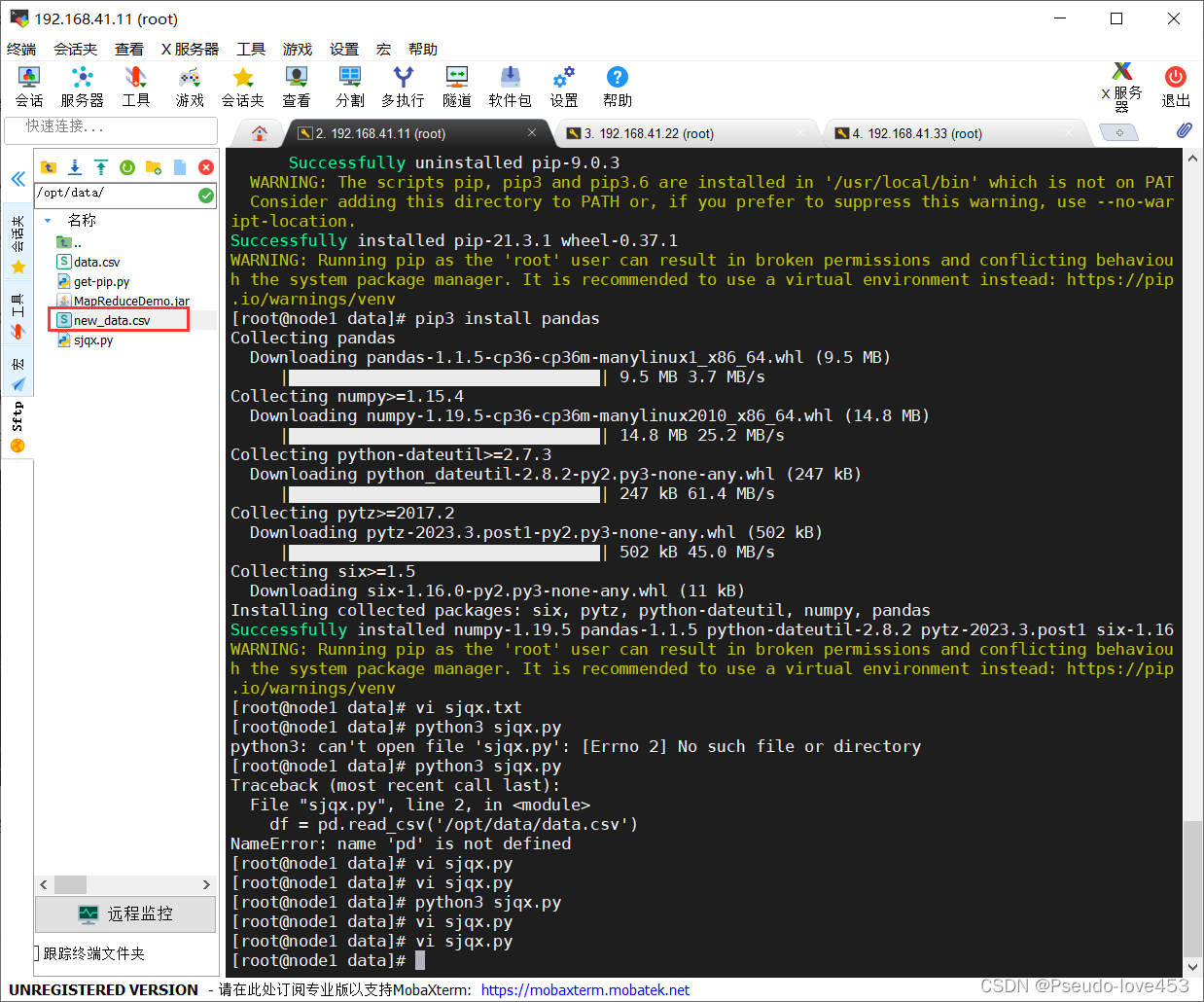
1.安装python3
具体步骤:
sudo yum install python3
wget https://bootstrap.pypa.io/pip/3.6/get-pip.py
sudo python3.6 get-pip.py
pip3 install pandas
其中第三步sudo python3.6 get-pip.py可能会报以下错误 :
ERROR: This script does not work on Python 3.6 The minimum supported Python version is 3.7. Please use https://bootstrap.pypa.io/pip/3.6/get-pip.py instead.
解决方法:
打开安装失败报错所给的网址:bootstrap.pypa.io/pip/3.6/get-pip.py
将网址所有内容ctrl+A、ctrl+C复制,在虚拟机创建get-pip.py文件并将内容ctrl+V进去后保存文件,再次执行sudo python3.6 get-pip.py即可成功安装

下载HDFS文件到虚拟机本地,也可直接从Windows本地拖拽到虚拟机,还可以使用shell命令从HDFS下载到虚拟机本地,代码如下:
hadoop fs -get /bysj/input/data.csv /opt/data/data.csv
以下是通过Java代码下载HDFS文件到虚拟机
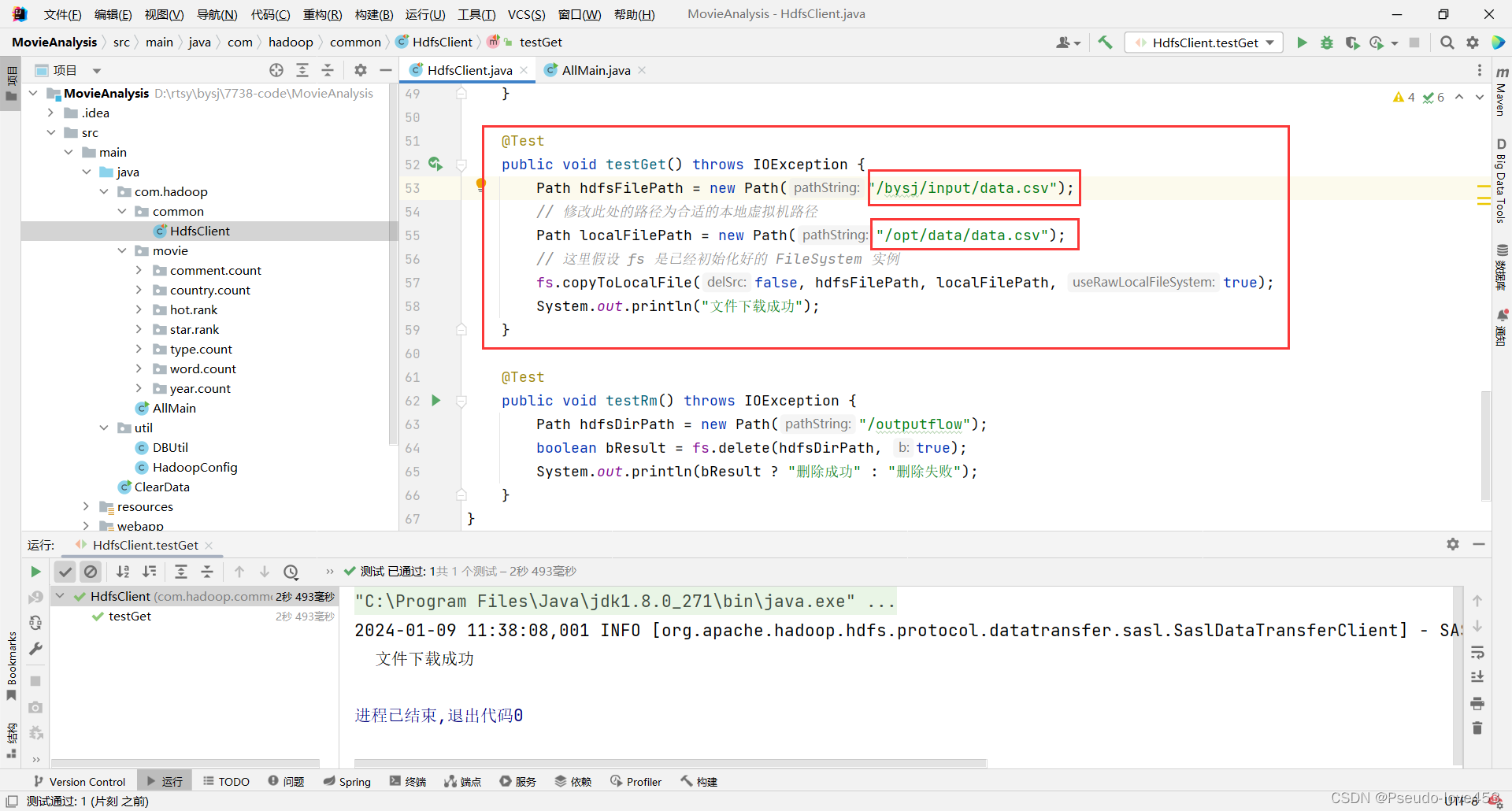
2.编写Python程序
vi sjqx.py 进去编辑一段简单的数据清洗python代码,并保存
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv('/opt/data/data.csv')
# 处理缺失值
df = df.dropna() # 删除包含缺失值的行
# 删除重复行
df = df.drop_duplicates()
# 保存为新的文件
cleaned_csv_path = '/opt/data/new_data.csv'
df.to_csv(cleaned_csv_path, index=False)
3.运行Python程序
在虚拟机输入 python3 sjqx.py 即可运行代码,刷新文件夹后得到新的数据集
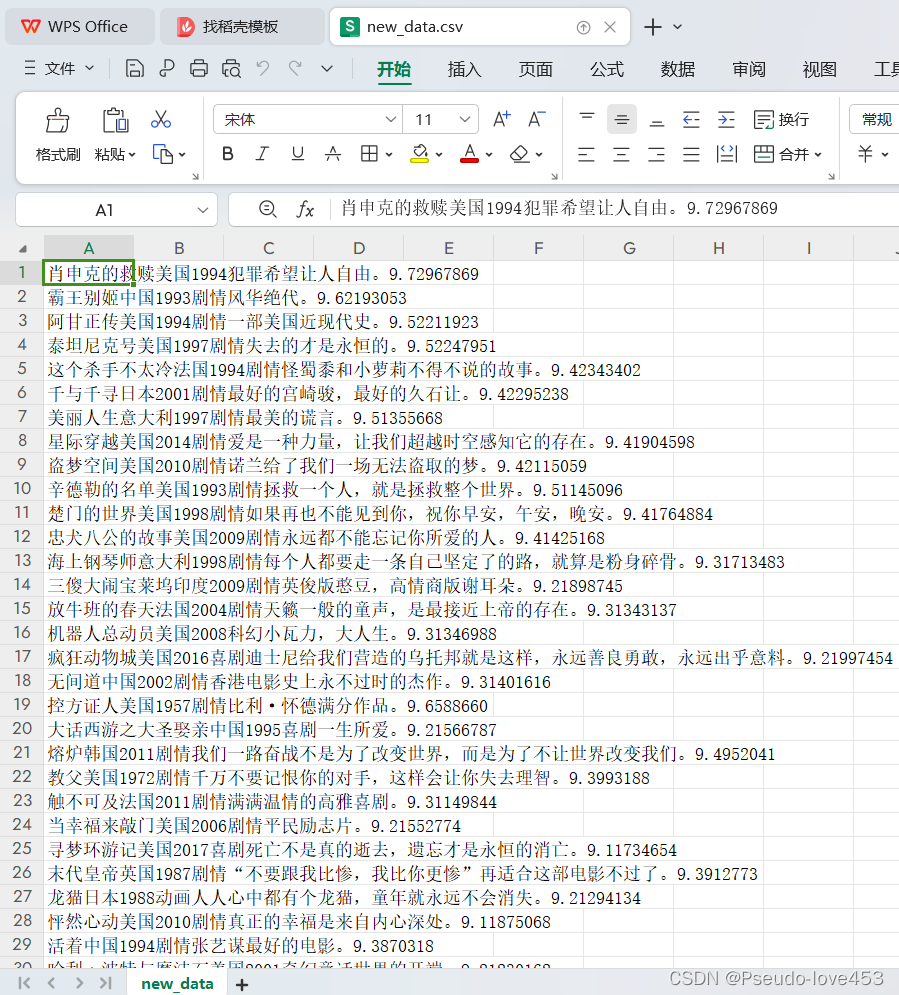
4.结果展示
4 数据分析
1.分析维度
这里我将对数据集进行七个方面维度的分析,分别是:
①每个类型电影总数
②电影简介中关键词出现次数总和
③每个国家上榜电影总数
④各个年份上映电影总数
⑤电影类型热度排行榜
⑥每部电影评论总数
⑦电影评分排行榜
2.编写Map Reduce代码
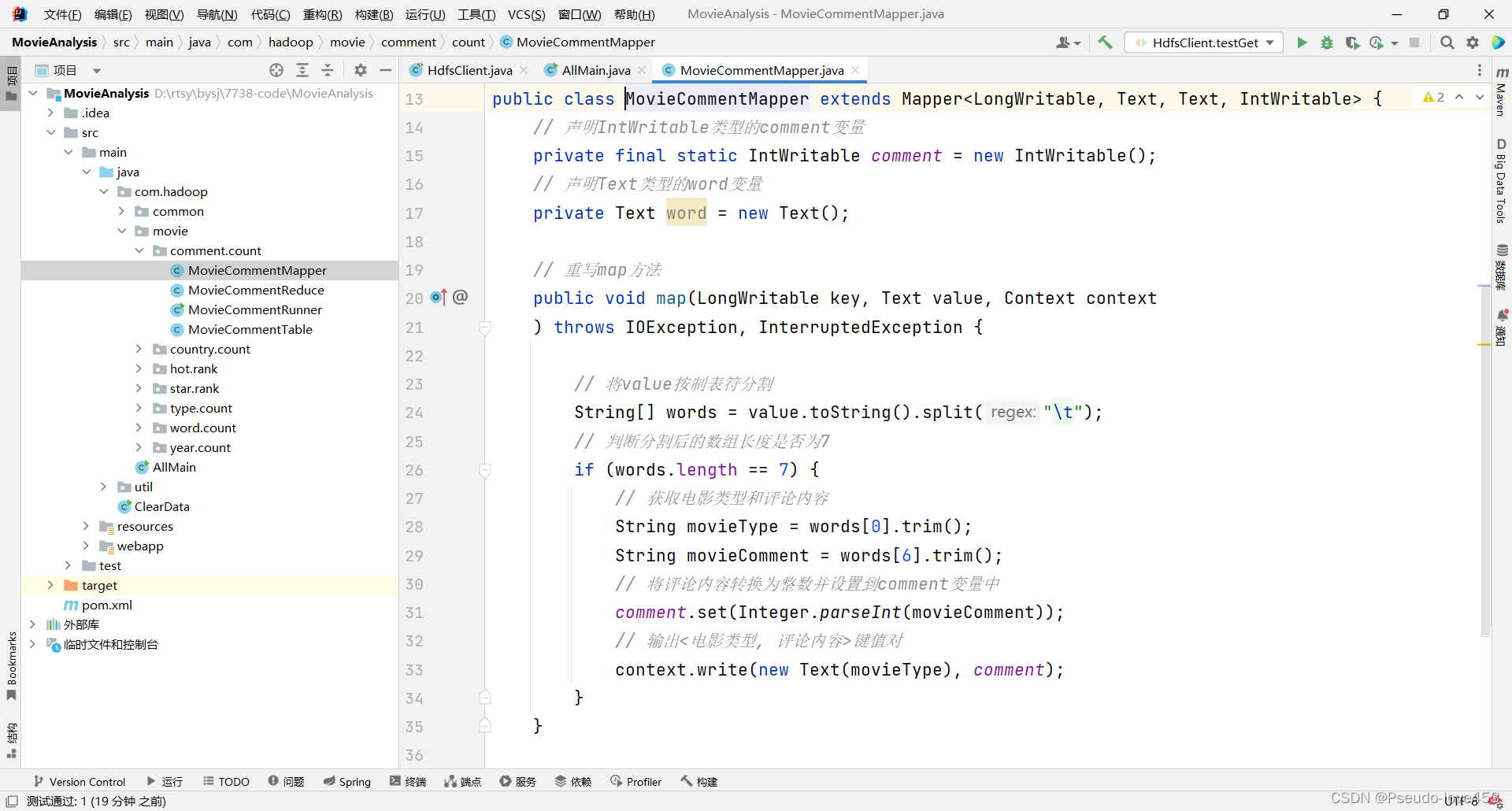
Ⅰ “ 每个类型电影总数 ” Mapper代码(mapper部分):
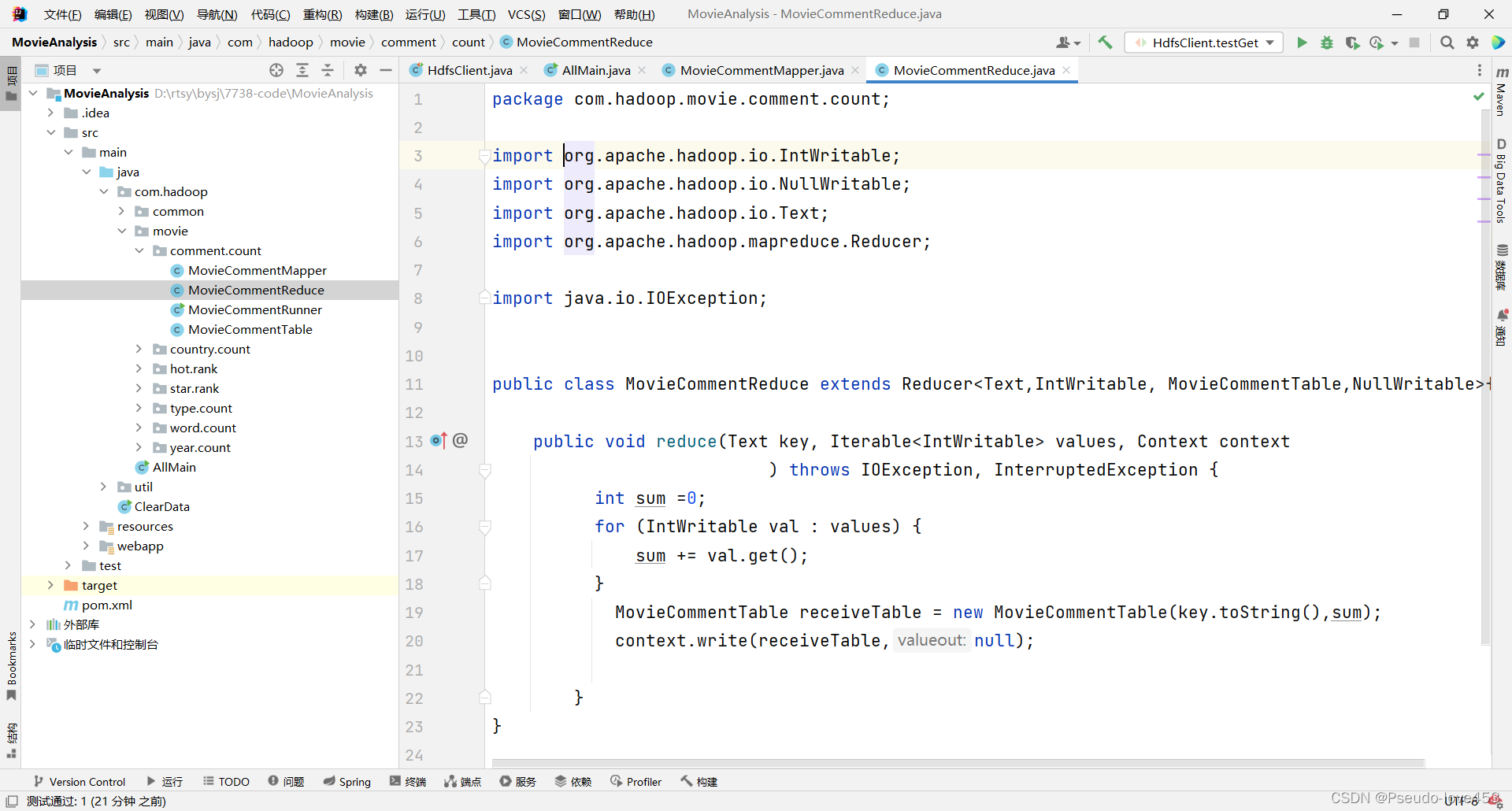
Ⅱ “ 每个类型电影总数 ” Reduce代码(reduce部分):
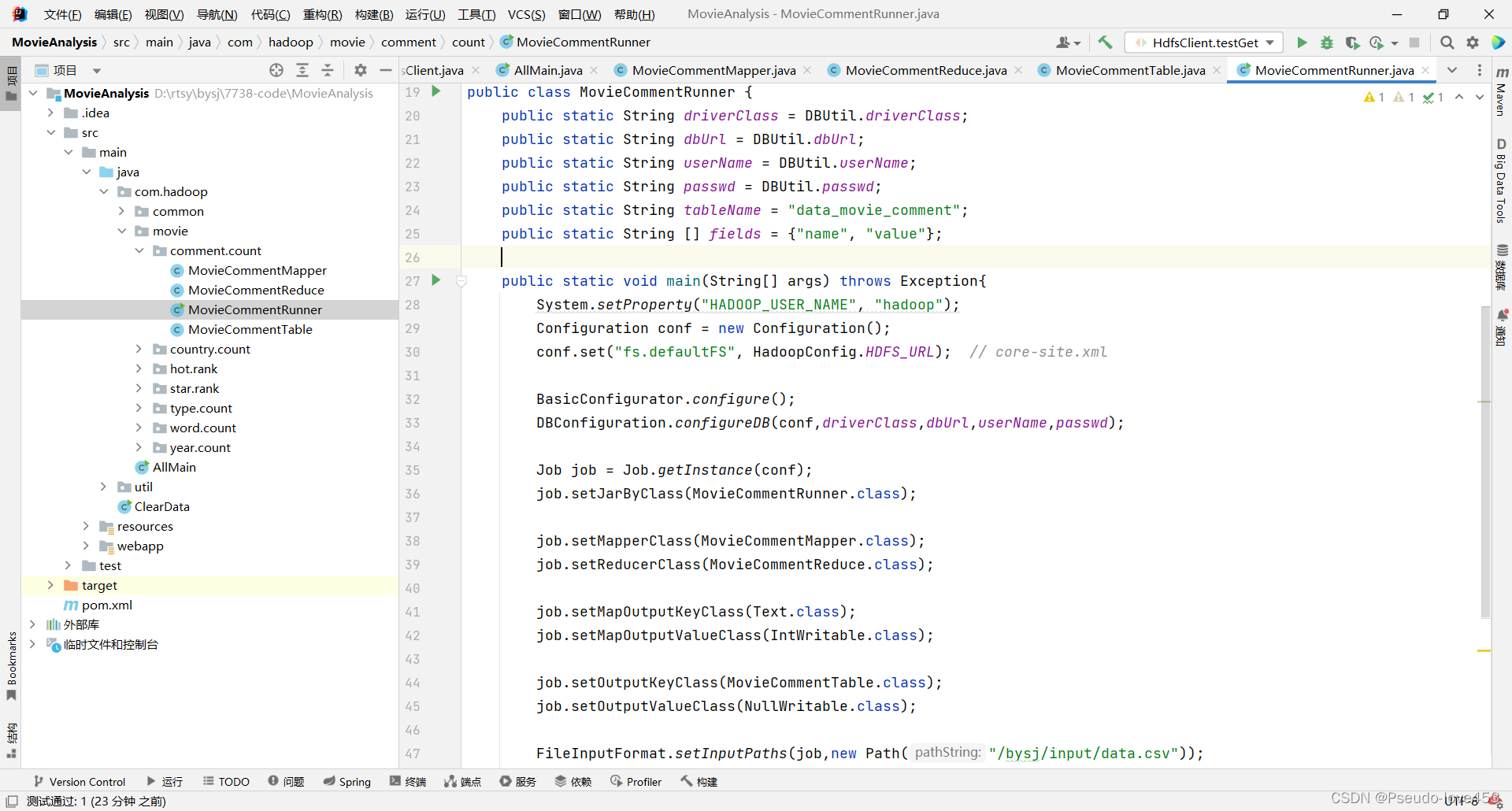
Ⅲ “ 每个类型电影总数 ” Runner代码(提交部分):
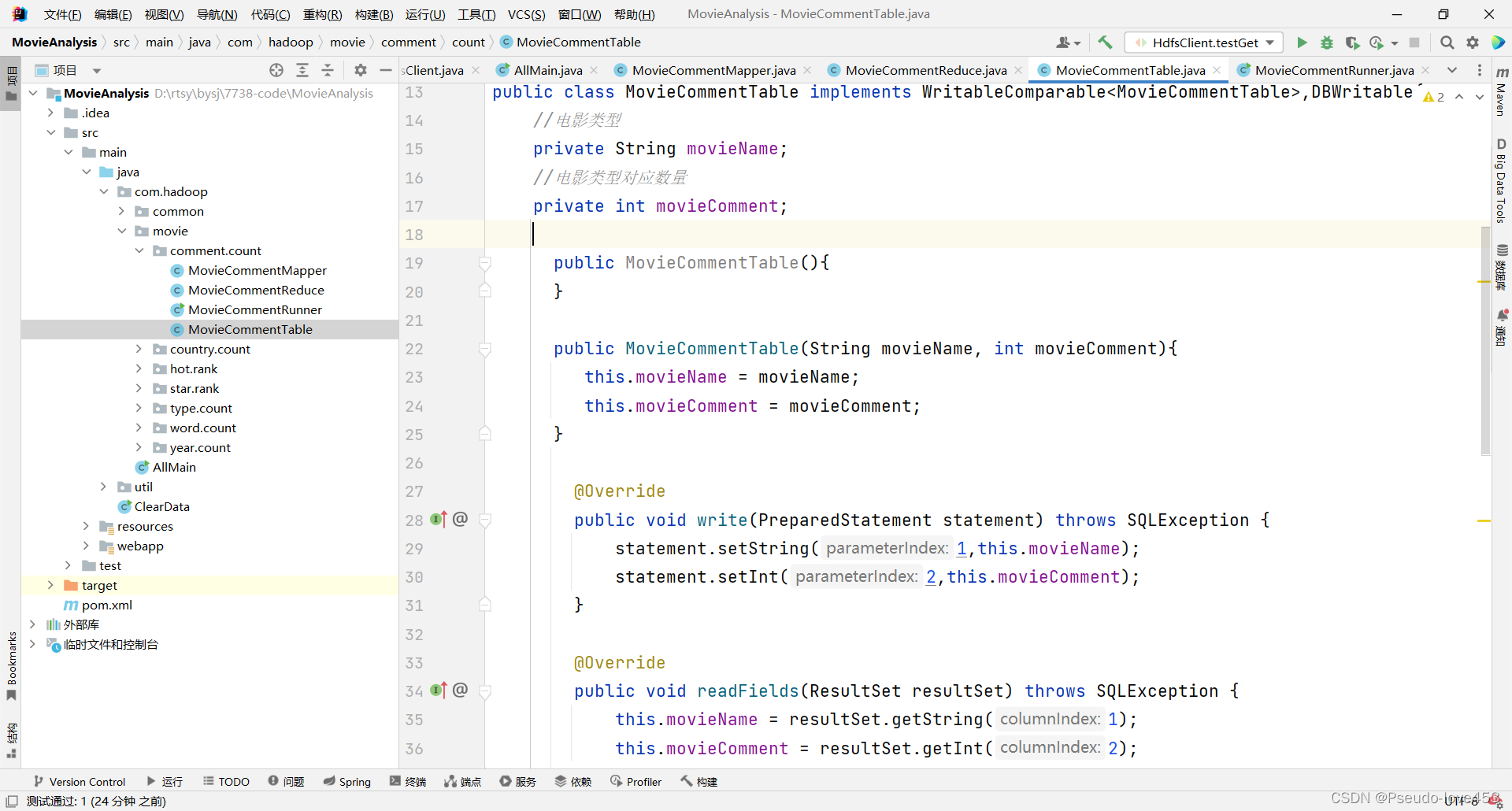
Ⅳ “ 每个类型电影总数 ” Table代码(上传数据库部分):
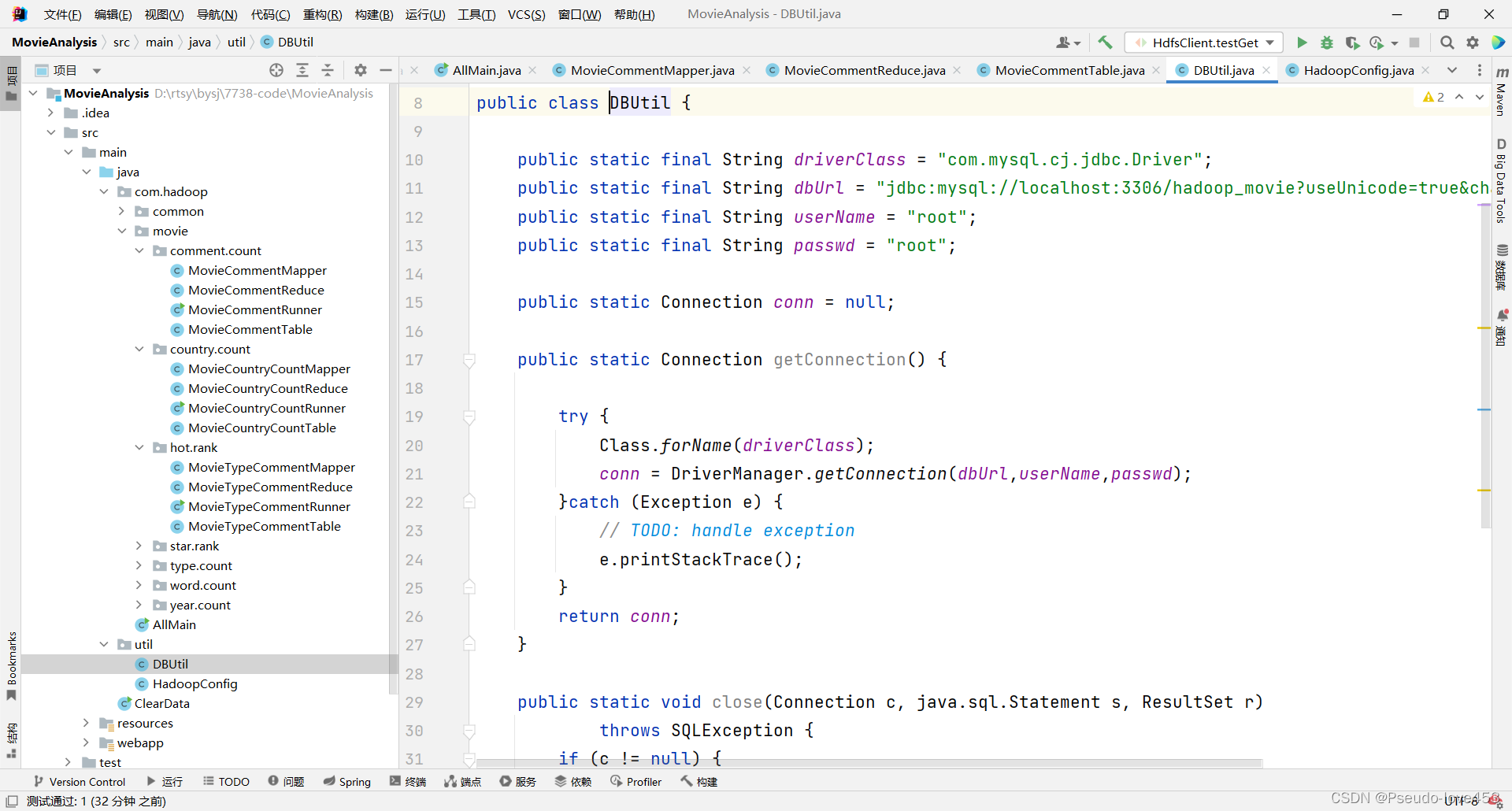
Ⅴ 数据库连接
Ⅵ hadoop连接
Ⅶ 最后将所有维度的mapreduce分析由“ AllMain ”启动项一起启动
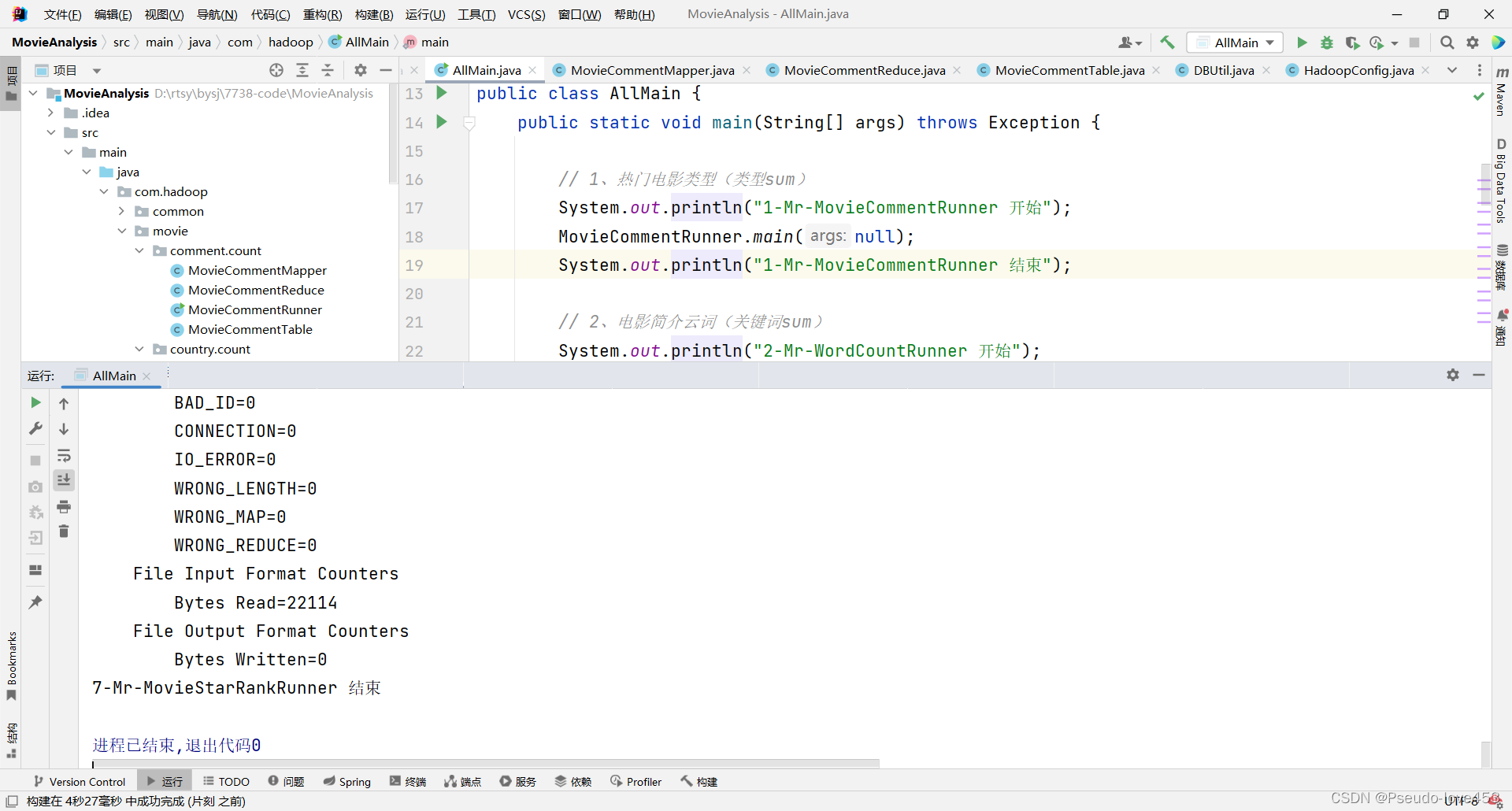
3.运行Map Reduce代码
在AllMain中右击运行
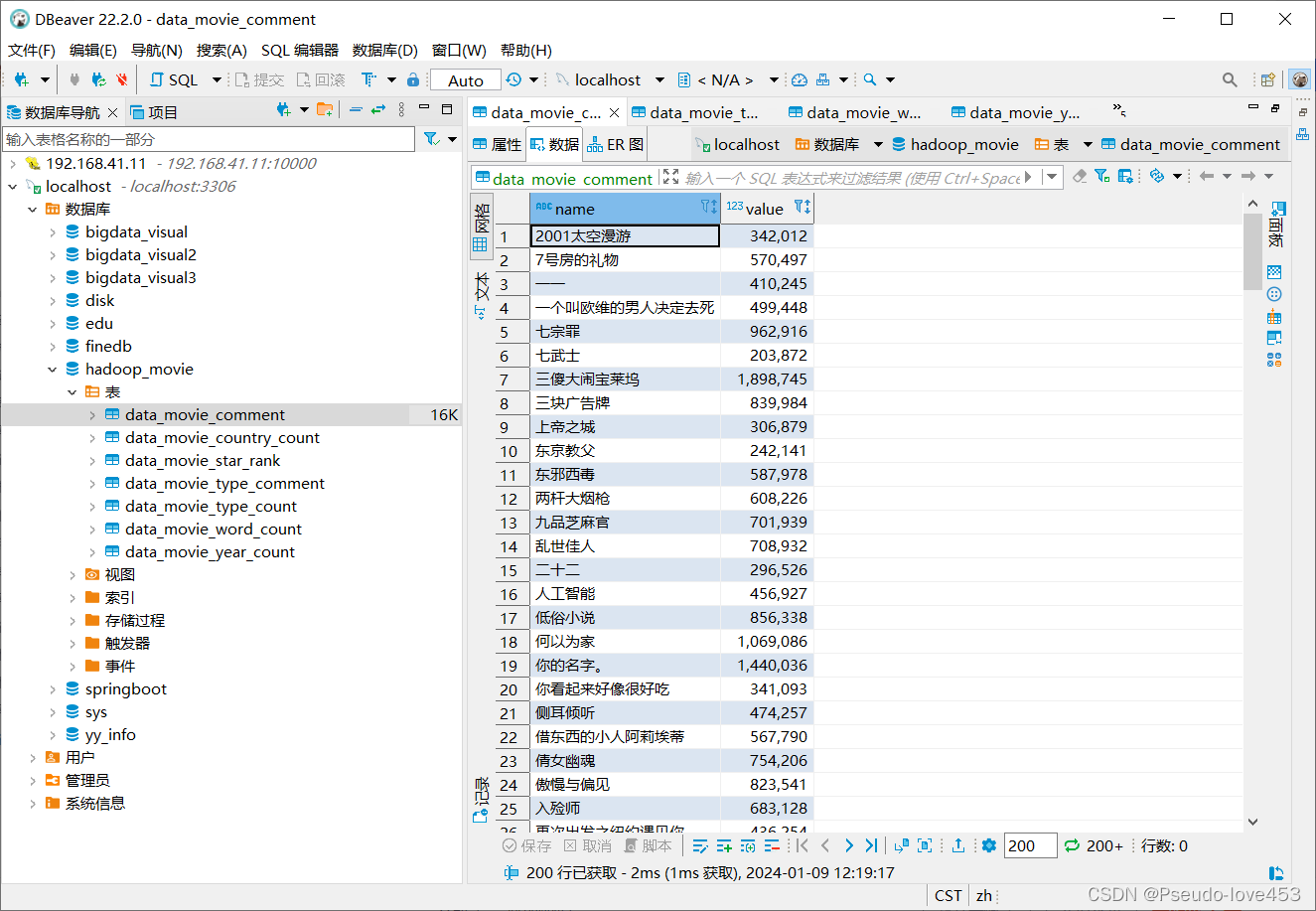
4.结果展示
5 数据可视化
数据可视化这里我们使用Spring Boot + Html + Js + Css + MySQL + Echarts实现
1.编写后端代码
①Controll层
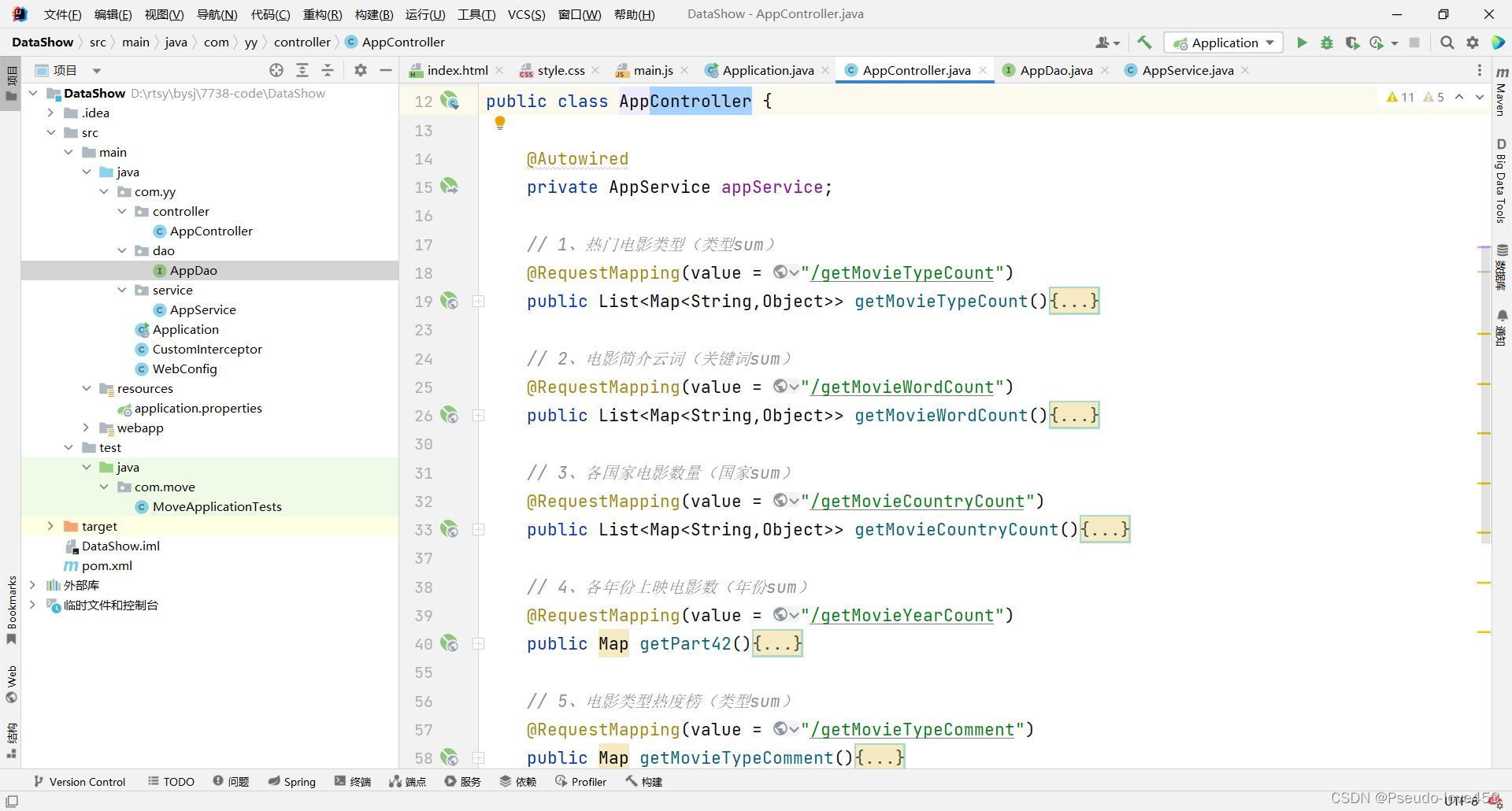
②Service层
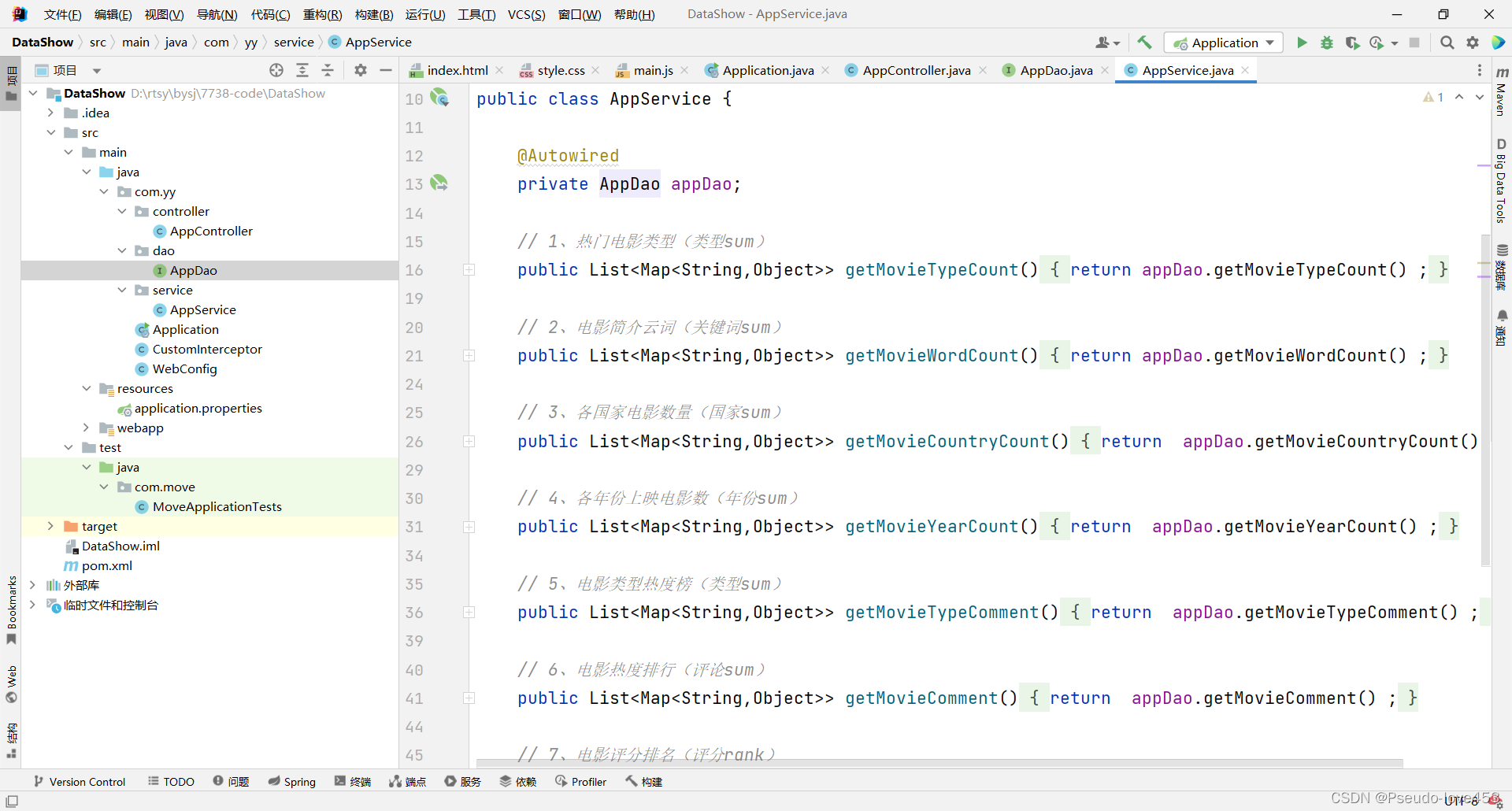
③Dao层
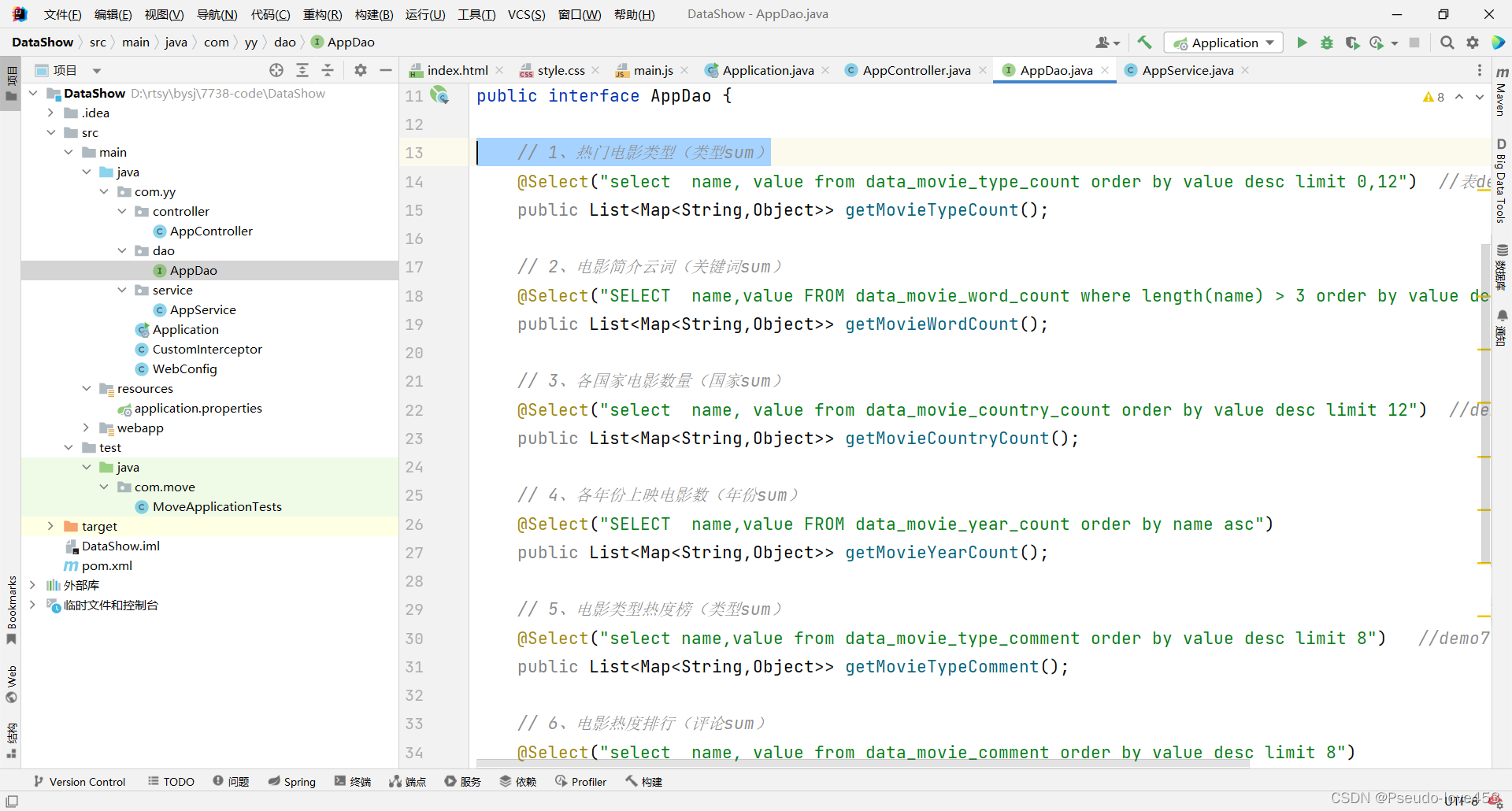
2.编写前端代码
①Html主页面代码
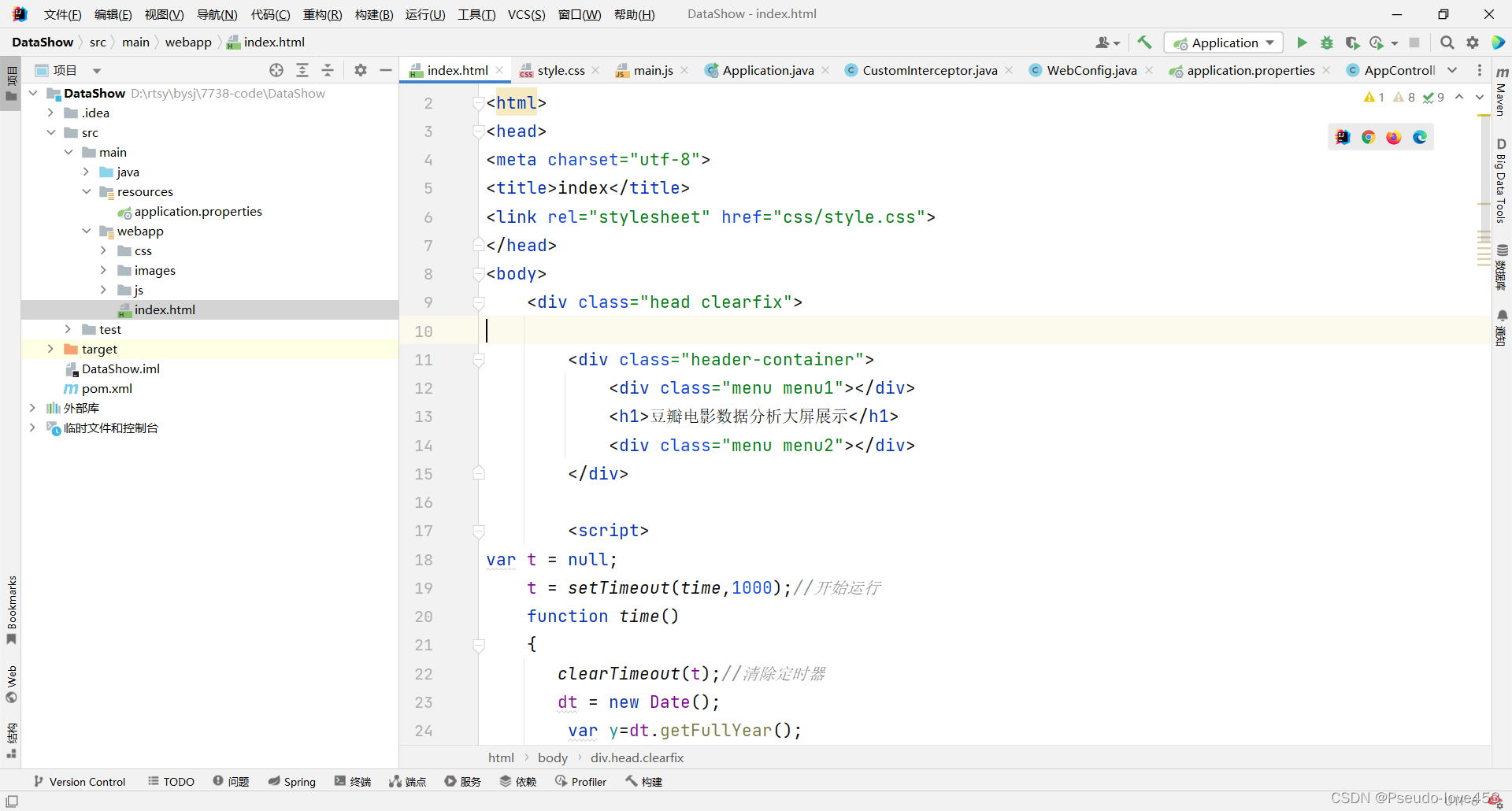
②Css渲染代码
③Js、Echarts图形代码
3.运行spring boot项目
右击Application运行即可
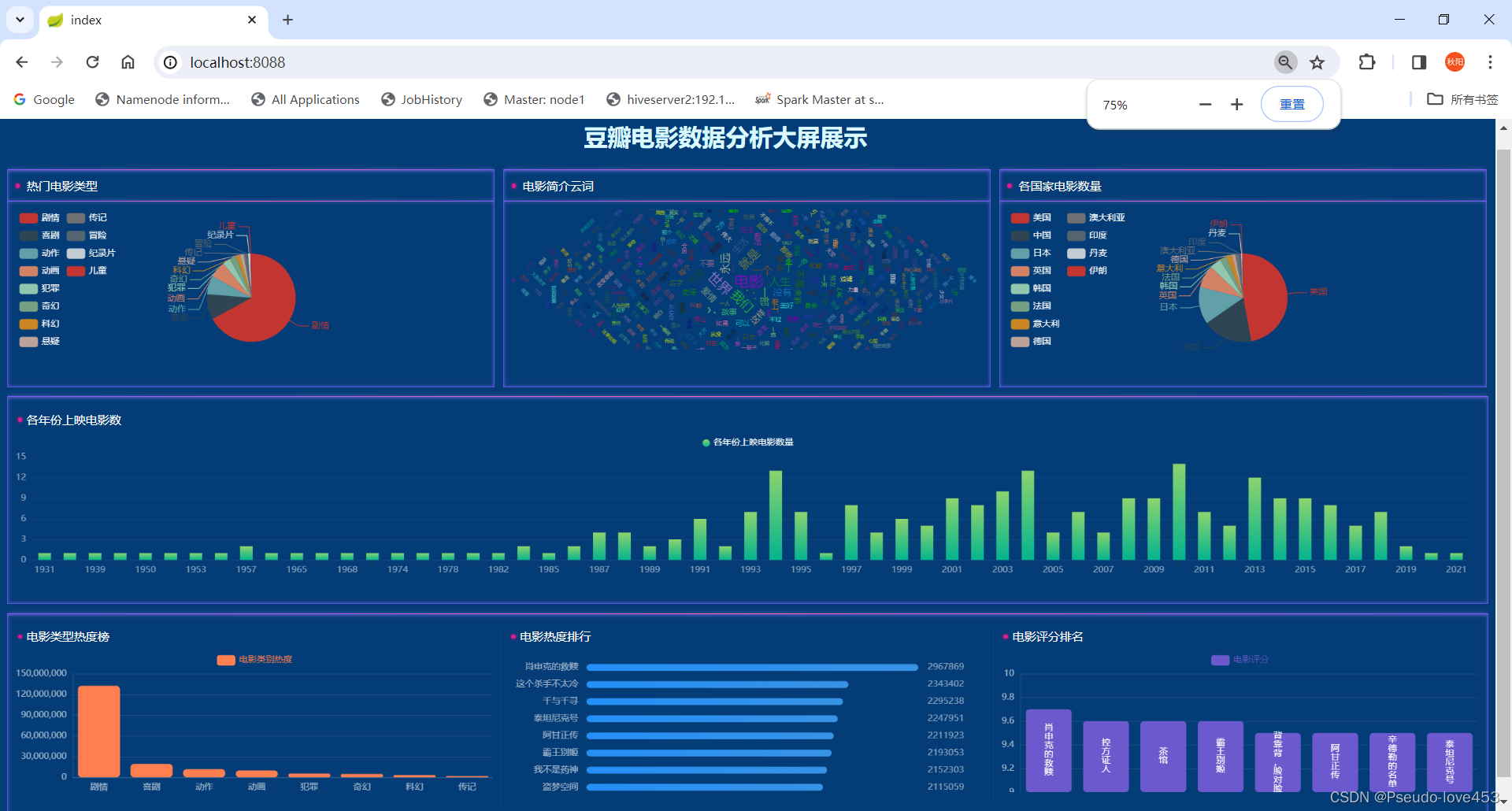
4.结果展示
打开浏览器,输入 “ http://localhost:8088/ ”
至此整个毕业设计完成!
版权归原作者 Pseudo-love453 所有, 如有侵权,请联系我们删除。