
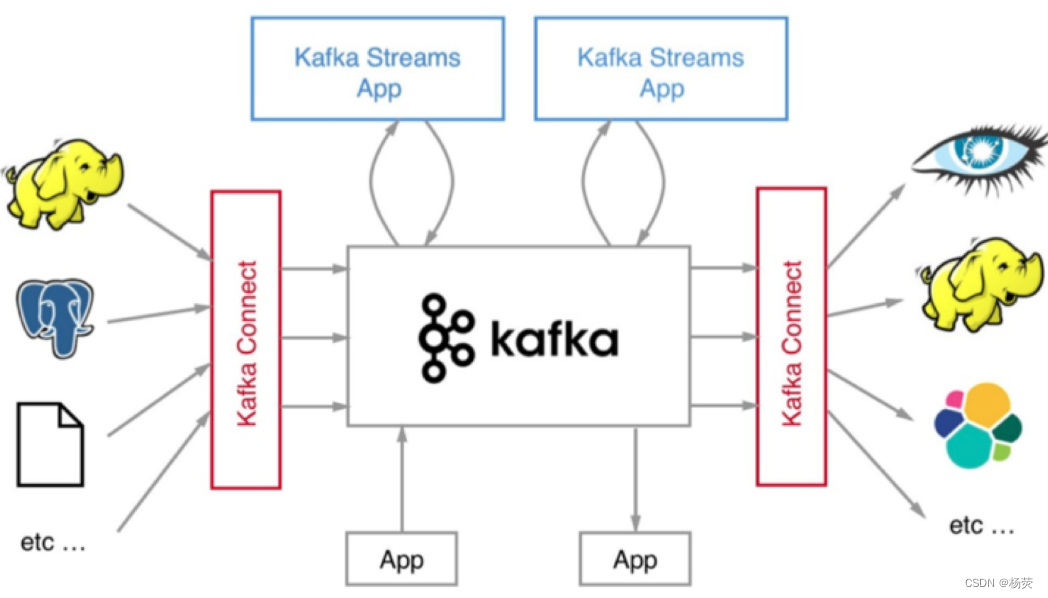
一、什么是分布式
分布式是指将计算任务分散到多个计算节点上进行并行处理的一种计算模型。在分布式系统中,多台计算机通过网络互联,共同协作完成任务。每个计算节点都可以独立运行,并且可以相互通和协调。这种分布式的架构可以提高计算能力和可靠性,充分利用集群资源,提高系统的扩展性和灵活性。常见的分布式系统包括分布式数据库、分布式文件系统、分布式计算等。分布式系统用于处理大规模的数据和复杂的计算任务,适用于各种领域,如互联网、云计算、大数据分析等。
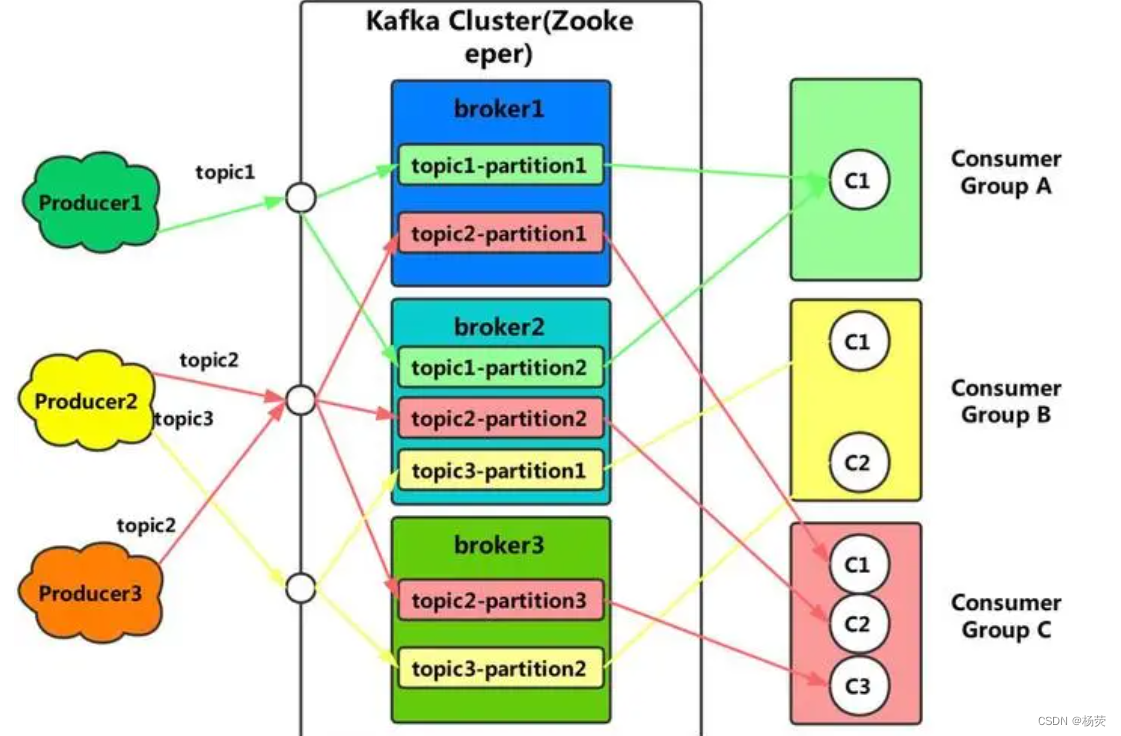
二、kafka介绍
Kafka是一种高性能、分布式的流式数据平台,由Apache基金会开发和维护。它的设计目标是实时、可持久地处理大规模的流式数据。
Kafka的核心概念是一个分布式的发布-订阅消息系统。它以可扩展性和持久性为重点,通过将数据分割成多个分区并存储在多个服务器上来实现高吞吐量和故障容忍性。
Kafka的架构主要由以下几个关键组件组成:
- Producer(生产者):负责向Kafka的Topic(主题)发布消息。生产者可以将消息发送到指定的Topic,并指定消息的键(key),Kafka将根据键将消息路由到对应的分区。
- Consumer(消费者):消费者可以订阅一个或多个Topic,并从分区中消费消息。Kafka允许多个消费者组(consumer group)共同消费一个Topic中的消息,实现高吞吐量和负载均衡。
- Broker(代理):Kafka集群中的每个服务器都被称为代理。代理负责存储和处理消息,生产者和消费者与代理进行通信。
- Topic(主题):消息在Kafka中通过主题进行分类和组织。一个主题可以有多个分区,每个分区可以在不同的代理上进行复制,以实现容错性。
- Partition(分区):主题可以被分割成多个分区,每个分区在磁盘上都有自己的存储空间。分区提供了消息的有序性和并行处理的能力。
Kafka具有高吞吐量、持久性、可扩展性和容错性的特点,广泛应用于数据处理、实时流处理、日志收集、事件驱动架构等场景。它可以处理海量的数据流,并保证数据的完整性和可靠性。同时,Kafka提供了一组强大的API和工具,使得开发者能够轻松地构建、部署和管理基于Kafka的应用程序。

三、消息的顺序消费
Kafka的消息顺序消费是指消费者按照消息的顺序逐条消费消息的过程。Kafka的分区(Partition)是消息的基本单位,每个分区中的消息按照顺序进行存储。在一个分区中,消息的顺序是有序的,这意味着先发送的消息会被存储在分区的前部,而后发送的消息会被追加到分区的末尾。
Kafka通过分区的方式实现消息的顺序性,消费者可以订阅一个或多个分区来消费消息。当消费者从分区中拉取消息时,Kafka会按照消息在分区中的顺序返回给消费者。这样就保证了消费者将按照消息的顺序进行消费。
需要注意的是,Kafka的多个分区是并行处理的,每个分区的消息可以独立进行消费。因此,在多个分区并行消费的情况下,消费者之间的消息顺序可能无法保证。但是,对于单个分区的消息消费,Kafka会确保按照消息的顺序进行消费。
为了实现消息的顺序消费,可以根据业务需求将相关消息发送到同一个分区,并且使用单个消费者实例来消费该分区的消息。这样就可以保证消息在整个分区中按照顺序进行处理。同时,Kafka还提供了分区器(Partitioner)机制,可以根据消息的键(key)来决定消息被发送到哪个分区,从而进一步控制消息的顺序消费。
四、如何保证消息的顺序消费
在Java中,可以使用Kafka的消费者API来实现消息的顺序消费。以下是几种可以考虑的方法:
- 单个分区消费:创建一个单独的消费者实例来消费一个分区的消息。这样可以确保在单个分区内的消息按顺序消费。但是需要注意,如果有多个分区,不同分区的消息仍可能以并发方式进行消费。
- 指定分区消费:通过指定消费者订阅的特定分区,可以确保只消费指定分区的消息。这样,可以通过将相关消息发送到同一个分区来保证消息的顺序消费。
- 按键分区:Kafka允许根据消息的键(key)来决定将消息发送到哪个分区。如果消息的键是相同的,Kafka会将它们发送到同一个分区。因此,可以根据消息的键来保证消息的顺序消费。
无论选择哪种方法,都应该注意以下几点:
- 设置消费者的
max.poll.records参数,确保每次拉取的消息数量合适,以避免因一次拉取的消息过多而导致处理速度过慢。 - 在消费者处理消息时,确保消息处理的逻辑是线程安全的。
- 监听消费者的
onPartitionsRevoked事件,以便在重新分配分区时进行必要的清理和准备工作。 - 使用
auto.offset.reset参数设置消费者的offset重置策略,以决定当消费者启动时从哪个offset开始消费。
通过上述方法,结合合适的配置和实现,可以在Java中实现Kafka消息的顺序消费。
版权归原作者 杨荧 所有, 如有侵权,请联系我们删除。