
一、消息中间件
1、简介
消息中间件也可以称消息队列
指用高效可靠的消息传递机制进行与平台无关的数据交流 基于数据通信来进行分布式系统的集成。 通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。 当下主流的消息中间件有RabbitMQ、Kafka、ActiveMQ、RocketMQ等。
2、作用
- 冗余(存储)
- 扩展性
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
3、两种模式
1、P2P模式
P2P模式包含三个角色: 消息队列(Queue)、发送者(Sender)、接收者(Receiver)。每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到它们被消费或超时。
P2P的特点:
- 每个消息只有一个消费者(Consumer),即一旦被消费,消息就不再在消息队列中
- 发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行它不会影响到消息被发送到队列
- 接收者在成功接收消息之后需向队列应答成功
- 如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式
2、Pub/Sub模式
Pub/Sub模式包含三个角色: 主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
Pub/Sub的特点:
- 每个消息可以有多个消费者
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息
- 为了消费消息,订阅者必须保持运行的状态
- 如果希望发送的消息可以不被做任何处理、或者只被一个消息者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型
4、常用中间件介绍与对比
1、Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
2、RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
3、RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
RabbitMQ和Kafka的区别
RabbitMQ比Kafka可靠,Kafka更适合IO高吞吐的处理,一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用,比如ELK日志收集。
二、RabbiMQ集群
RabbiMQ特点
- 可靠性
- 扩展性
- 高可用性
- 多种协议
- 多语言客户端
- 管理界面
- 插件机制
RabbitMQ模式⼤概分为以下三种:
(1)单⼀模式。 (2)普通模式(默认的集群模式)。 (3) 镜像模式(把需要的队列做成镜像队列,存在于多个节点,属于RabbiMQ的HA⽅案,在对业务可靠性要求较⾼的场合中⽐较适⽤)。要实现镜像模式,需要先搭建⼀个普通集群模式,在这个模式的基础上再配置镜像模式以实现⾼可⽤。
集群中的基本概念:
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。 一个rabbitmq集 群中可以共享 user,vhost,queue,exchange等,所有的数据和状态都是必须在所有节点上复制的。
ConnectionFactory(连接管理器):应用程序与Rabbit之间建立连接的管理器,程序代码中使用;
Channel(信道):消息推送使用的通道;
Exchange(交换器):用于接受、分配消息;
Queue(队列):用于存储生产者的消息;
RoutingKey(路由键):用于把生成者的数据分配到交换器上;
BindingKey(绑定键):用于把交换器的消息绑定到队列上;
Broker:简单来说就是消息队列服务器实体
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离.
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
user:用户
集群中的两种节点
1 内存节点:只保存状态到内存(一个例外的情况是:持久的queue的持久内容将被保存到disk) 2 磁盘节点:保存状态到内存和磁盘。推荐
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。集群中,只需要一个磁盘节点来保存状态 就足够了 如果集群中只有内存节点,那么不能停止它们,否则所有的状态,消息等都会丢失。
三、实例:RabbiMQ集群部署
1、准备环境
**注:这⾥三台服务器都联⽹,另外RabbitMQ集群节点必须在同⼀⽹段⾥,如果是跨⼴域⽹,效果会变差。关闭防火墙和selinux **
三台机器分别为:
10.12.153.133 rabbitmq-1 10.12.153.71 rabbitmq-2 10.12.153.72 rabbitmq-3
互相在/etc/hosts内做好域名解析
2、三个节点配置安装rabbitmq软件
注:所有机器都操作
erlang 版本选择
rabbitmq/erlang - Packages · packagecloud
1)安装依赖
# yum install -y epel-release gcc-c++ unixODBC unixODBC-devel openssl-devel ncurses-devel
2)安装erlang
# curl -s https://packagecloud.io/install/repositories/rabbitmq/erlang/script.rpm.sh | sudo bash
这里我们示例erlang-21.3.8.21-1.el7.x86_64版本
# yum install erlang-21.3.8.21-1.el7.x86_64
测试:
# erl
成功回显如下
3)安装rabbitmq
rabbitmq 版本选择
Tags · rabbitmq/rabbitmq-server · GitHub
这里我们选择rabbitmq-server-3.7.10-1.el7
下载源码包并安装

4)启动
方法一:
# systemctl daemon-reload
# systemctl start rabbitmq-server
# systemctl enable rabbitmq-server
方式二:
# /sbin/service rabbitmq-server status ---查看状态
# /sbin/service rabbitmq-server start ---启动
5)开启rabbitmq的web访问界面:
rabbitmq-plugins enable rabbitmq_management
3、创建用户
注意:在一台机器操作
添加用户和密码
# rabbitmqctl add_user ztn 123456

设置为管理员
# rabbitmqctl set_user_tags ztn administrator

查看用户
# rabbitmqctl list_users

设置权限
此处设置权限时注意'.'之间需要有空格 三个'.'分别代表了conf权限,read权限与write权限
例如:当没有给newrain设置这三个权限前是没有权限查询队列,在ui界面也看不见
# rabbitmqctl set_permissions -p "/" ztn ".*" ".*" ".*"

4、开启用户远程登录:
注:所有机器都操作
cd /etc/rabbitmq/
备份配置文件
cp /usr/share/doc/rabbitmq-server-3.7.10/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
vim rabbitmq.config
修改如下:

三台机器都操作后重启服务服务:
systemctl restart rabbitmq-server
5、查看端口
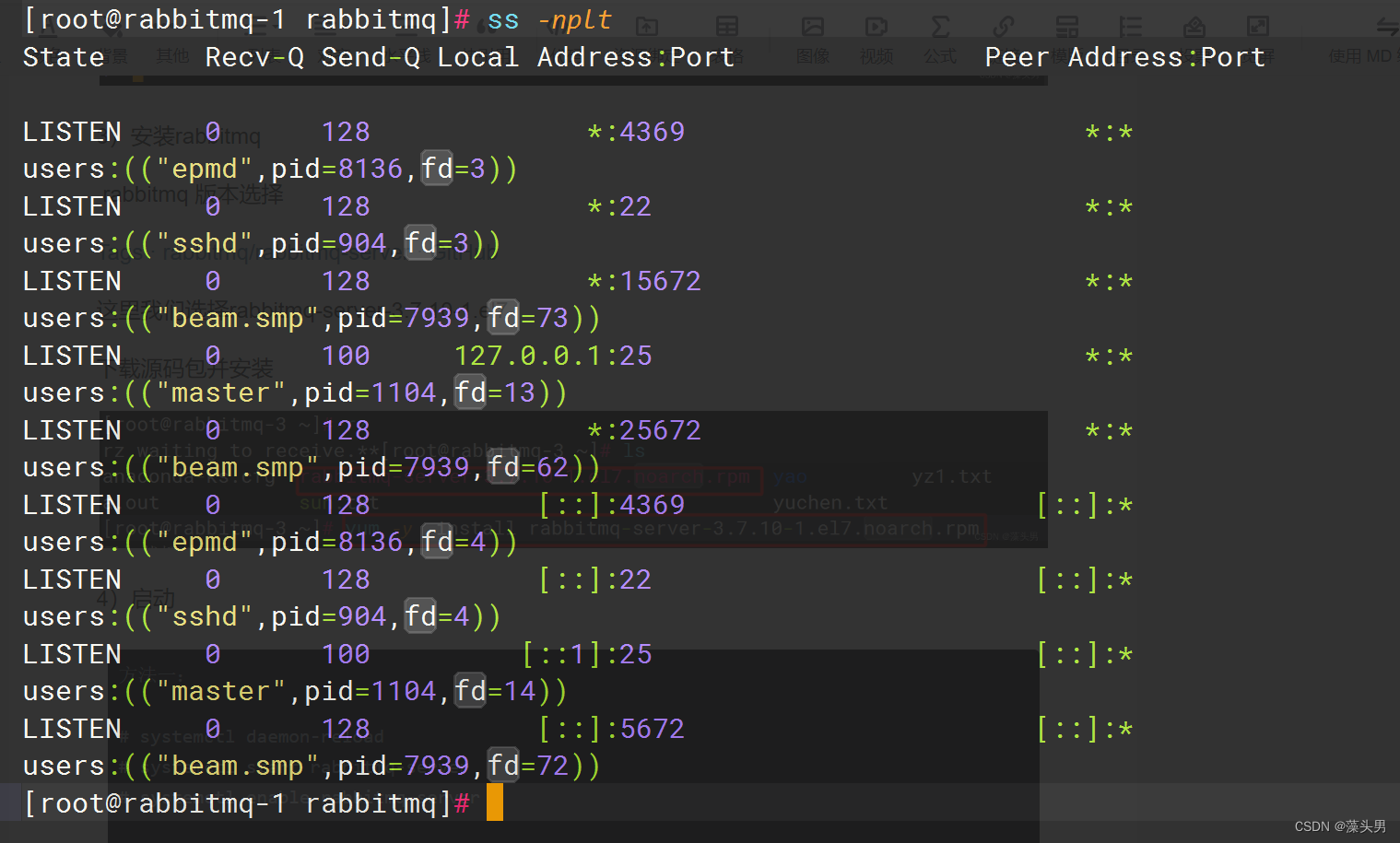
!注意如果是云服务器,切记添加安全组端口放行。
6、测试
浏览器访问
注意:
rabbitmq默认管理员用户:guest 密码:guest
我们刚才新添加的用户为:ztn 密码:123456

登录后页面


7、部署集群
注:三台机器都操作
1)首先创建好数据存放目录和日志存放目录
mkdir -p /data/rabbitmq/data
mkdir -p /data/rabbitmq/logs
chmod 777 -R /data/rabbitmq
chown rabbitmq.rabbitmq /data/ -R
创建配置文件:
vim /etc/rabbitmq/rabbitmq-env.conf
加入以下内容
RABBITMQ_MNESIA_BASE=/data/rabbitmq/data
RABBITMQ_LOG_BASE=/data/rabbitmq/logs
重启服务
systemctl restart rabbitmq-server
2)拷⻉erlang.cookie
Rabbitmq的集群是依附于erlang的集群来⼯作的,所以必须先构建起erlang的集群景象。Erlang的集群中
各节点是经由过程⼀个magic cookie来实现的,这个cookie存放在/var/lib/rabbitmq/.erlang.cookie中,⽂件是400的权限。所以**必须保证各节点cookie⼀致**,**不然节点之间就⽆法通信.**
** 文件位置:**
(官方在介绍集群的文档中提到过.erlang.cookie 一般会存在这两个地址:第一个是home/.erlang.cookie;第二个地方就是/var/lib/rabbitmq/.erlang.cookie。如果我们使用解压缩方式安装部署的rabbitmq,那么这个文件会在{home}目录下,也就是$home/.erlang.cookie。如果我们使用rpm等安装包方式进行安装的,那么这个文件会在/var/lib/rabbitmq目录下。)
cat /var/lib/rabbitmq/.erlang.cookie

⽤scp的⽅式将rabbitmq-1节点的.erlang.cookie的值复制到其他两个节点中
scp /var/lib/rabbitmq/.erlang.cookie [email protected]:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie [email protected]:/var/lib/rabbitmq/
3)将mq-2、mq-3作为内存节点加⼊mq-1节点集群中
在mq-2、mq-3执⾏如下命令:
mq-2:
systemctl restart rabbitmq-server
rabbitmqctl stop_app #停止节点
rabbitmqctl reset #如果有数据需要重置,没有则不用
rabbitmqctl join_cluster --ram root@rabbitmq-1 #添加到磁盘节点
Clustering node 'rabbit@rabbitmq-2' with 'rabbit@rabbitmq-1' ...
rabbitmqctl start_app #启动节点
Starting node 'rabbit@rabbitmq-2' ...
======================================================================
mq-3:
systemctl restart rabbitmq-server
rabbitmqctl stop_app
Stopping node 'rabbit@rabbitmq-3' ...
rabbitmqctl reset
Resetting node 'rabbit@rabbitmq-3' ...
rabbitmqctl join_cluster --ram rabbit@rabbitmq-1
Clustering node 'rabbit@rabbitmq-3' with 'rabbit@rabbitmq-1' ...
rabbitmqctl start_app
Starting node 'rabbit@rabbitmq-3' ...
(1)默认rabbitmq启动后是磁盘节点,在这个cluster命令下,mq-2和mq-3是内存节点,
mq-1是磁盘节点。
(2)如果要使mq-2、mq-3都是磁盘节点,去掉--ram参数即可。
(3)如果想要更改节点类型,可以使⽤命令rabbitmqctl change_cluster_node_type
disc(ram),前提是必须停掉rabbit应⽤
注:
#如果有需要使用磁盘节点加入集群
rabbitmqctl join_cluster rabbit@rabbitmq-1
rabbitmqctl join_cluster rabbit@rabbitmq-1
8)查看集群状态
在 RabbitMQ 集群任意节点上执行 rabbitmqctl cluster_status来查看是否集群配置成功。
在mq-1磁盘节点上面查看
rabbitmqctl cluster_status
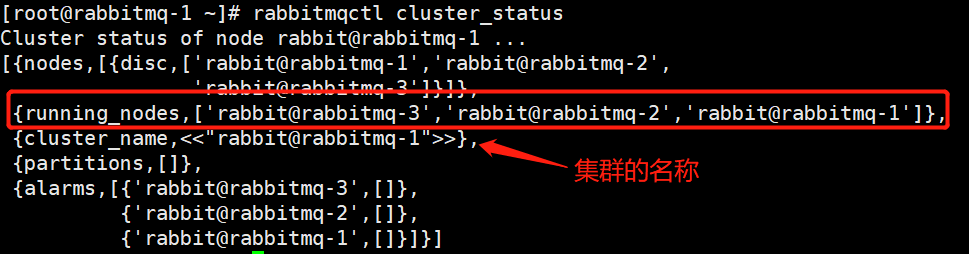
每台机器显示出三台节点,表示已经添加成功!
(1)默认rabbitmq启动后是磁盘节点,在这个cluster命令下,mq-2和mq-3是内存节点,mq-1是磁盘节点。
(2)如果要使mq-2、mq-3都是磁盘节点,去掉--ram参数即可。
(3)如果想要更改节点类型,可以使用命令rabbitmqctl change_cluster_node_type disc(ram),前提是必须停掉
rabbit应用
在RabbitMQ集群集群中,必须⾄少有⼀个磁盘节点,否则队列元数据⽆法写⼊到集群中,当磁盘节点宕掉时,集群将⽆法写⼊新的队列元数据信息。
希望能够帮助到大家!!

版权归原作者 藻头男 所有, 如有侵权,请联系我们删除。