
Hadoop:HDFS总结
HDFS架构
- NameNode(nn): 管理文件的元数据,如文件名、文件目录结构、文件属性等信息【NN运行时,元数据是存储在内存中,从而保证响应时间】元数据只保留在内存中是非常不可靠的,所以也需要持久化到磁盘。NN内部有两类文件用于持久化元数据:fsimage文件,以fsimage_为前缀,是序列化存储的元数据的整体快照;edits文件(又称edit log),以edits_为前缀,是顺序存储的元数据的增量修改(即客户端写入操作)日志。
- DataNode(dn): 存储数据块&存储块数据的校验和
- Secondary NameNode(2nn):NameNode的备份节点,隔段时间进行备份
YARN架构
Hadoop的资源管理器
- ResourceManager(RM):集群资源的总老大
- NodeManager(NM):单台服务器资源管理的老大
- ApplicationMaster(AM):单个任务管理的老大
- container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
任务运行时,ApplicationMaster 是存在在container中
MapReduce架构
Map & Reduce
- Map 阶段并行处理输入数据
- Reduce 阶段对 Map 结果进行汇总
集群架构

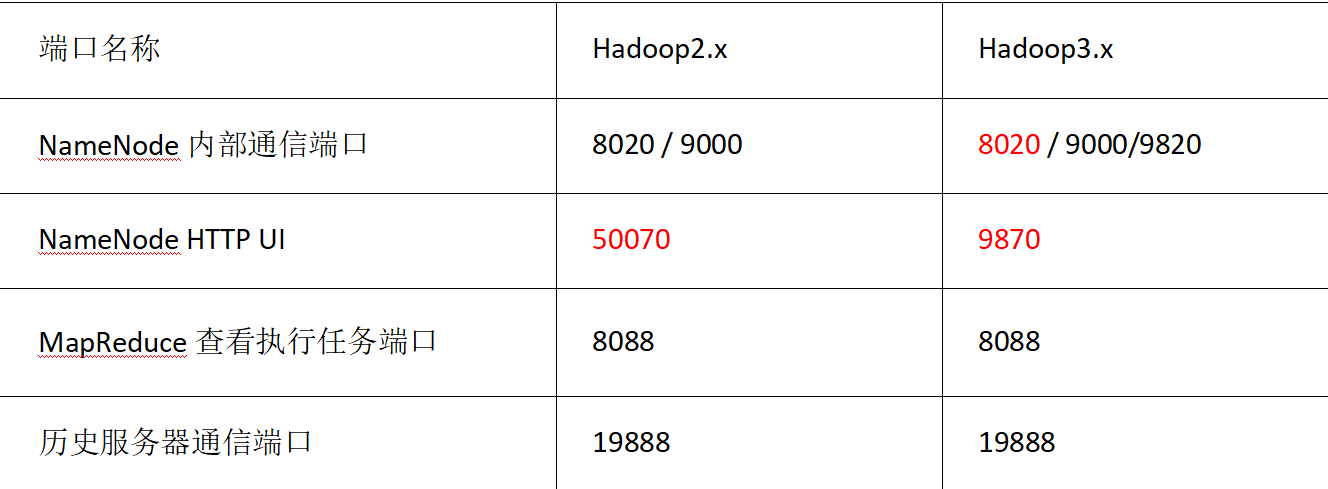
端口号
配置文件
core-site.xml
NameNode 的地址
Hadoop数据的存储目录
hdfs-site.xml
配置hdfs架构相关的设置,比如dfs.blocksize 块大小,hdfs的web访问页面等
yarn-site.xml
- 配置日志服务器
mapred-site.xml
HDFS文件块大小(重点)
关键点
①2.x 和 3.x 的默认块大小;②寻址时间:找到block的时间;③寻址时间&传输时间的最佳比例;
④磁盘传输速率;⑤设置块大小,=传输时间*磁盘传输速率
思考:为什么块的大小不能设置太小,也不能设置太大?
块大小,太小,块变多,查找某个block的时间变长
块大小,太大,块变少,Map任务数太少,作业执行速度变慢
总结:HDFS块大小的设置主要取决于,磁盘的传输速率
HDFS的Shell操作(重点)
hadoop fs <加下面的操作>
上传
hadoop fs -moveFromLocal <本地路径> <hdfs目标路径>
:剪切本地文件到HDFS
hadoop fs -copyFromLocal <本地路径> <hdfs目标路径>
:拷贝本地文件到HDFS
hadoop fs -put <本地路径> <hdfs目标路径>
:剪切本地文件到HDFS,等效moveFromLocal,生产环境用put更多,因为他短好吧
hadoop fs -appendToFile <本地路径> <hdfs目标路径>
:追加一个文件到已经存在的文件末尾
下载
hadoop fs -copyToLocal <hdfs路径> <本地路径>
:从HDFS拷贝数据到本地
hadoop fs -get <hdfs路径> <本地路径>
:从HDFS拷贝数据到本地,get更常用,因为他也很短好吧
HDFS直接操作
-ls: 显示目录信息
-cat:显示文件内容
-chgrp、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限
-mkdir:创建路径
-cp:从 HDFS 的一个路径拷贝到HDFS 的另一个路径
-mv:在 HDFS 目录中移动文件
-tail:显示一个文件的末尾 1kb 的数据
-rm:删除文件或文件夹
-rm -r:递归删除目录及目录里面内容
-du 统计文件夹的大小信息
-setrep:设置 HDFS 中文件的副本数量(备份的实际上线为DataNode的实际数量,因此写1000也没用,如果只有3个DataNode)
HDFS参数优先级

HDFS的写数据流程(重点)
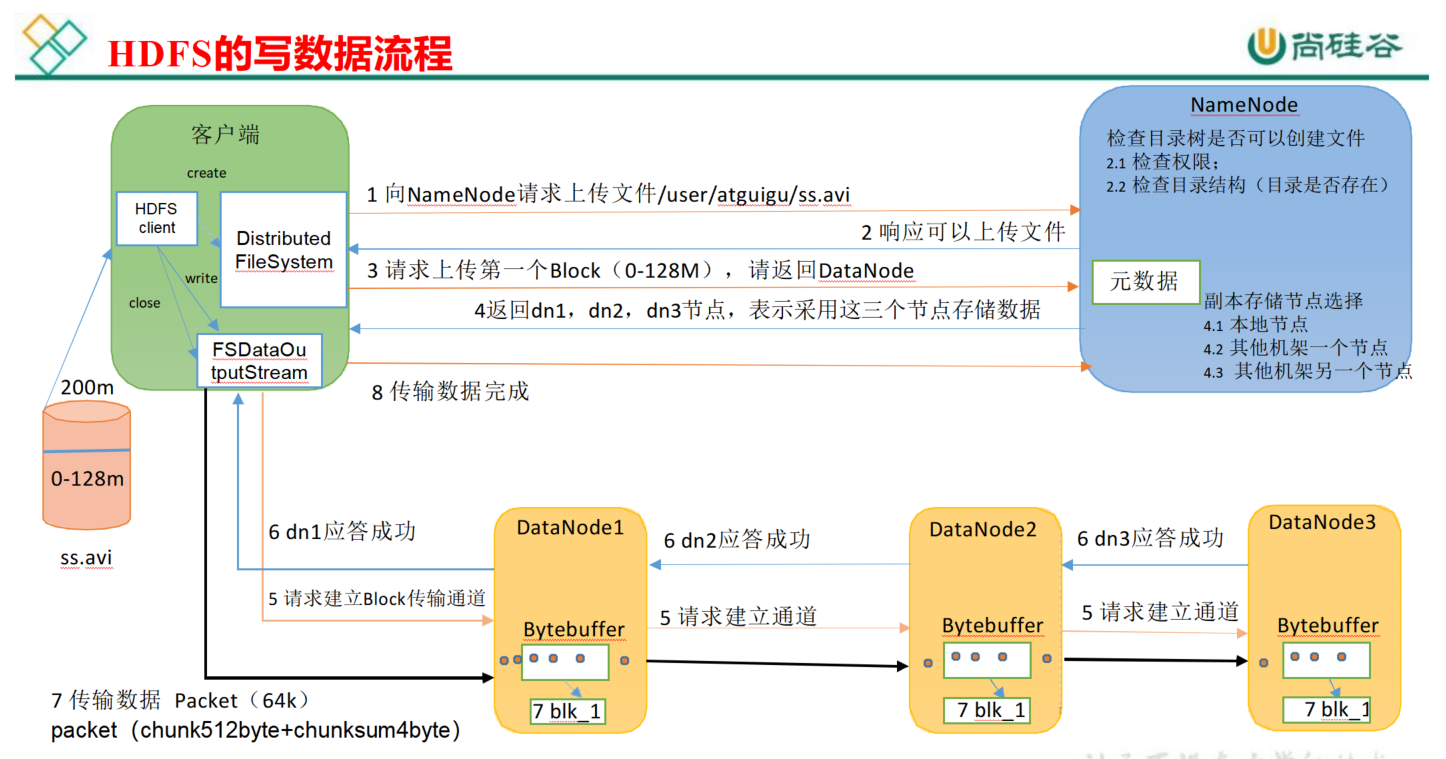
1.block
这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
2.packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
3.chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512),128M的packet要1M的chunk数据校验
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
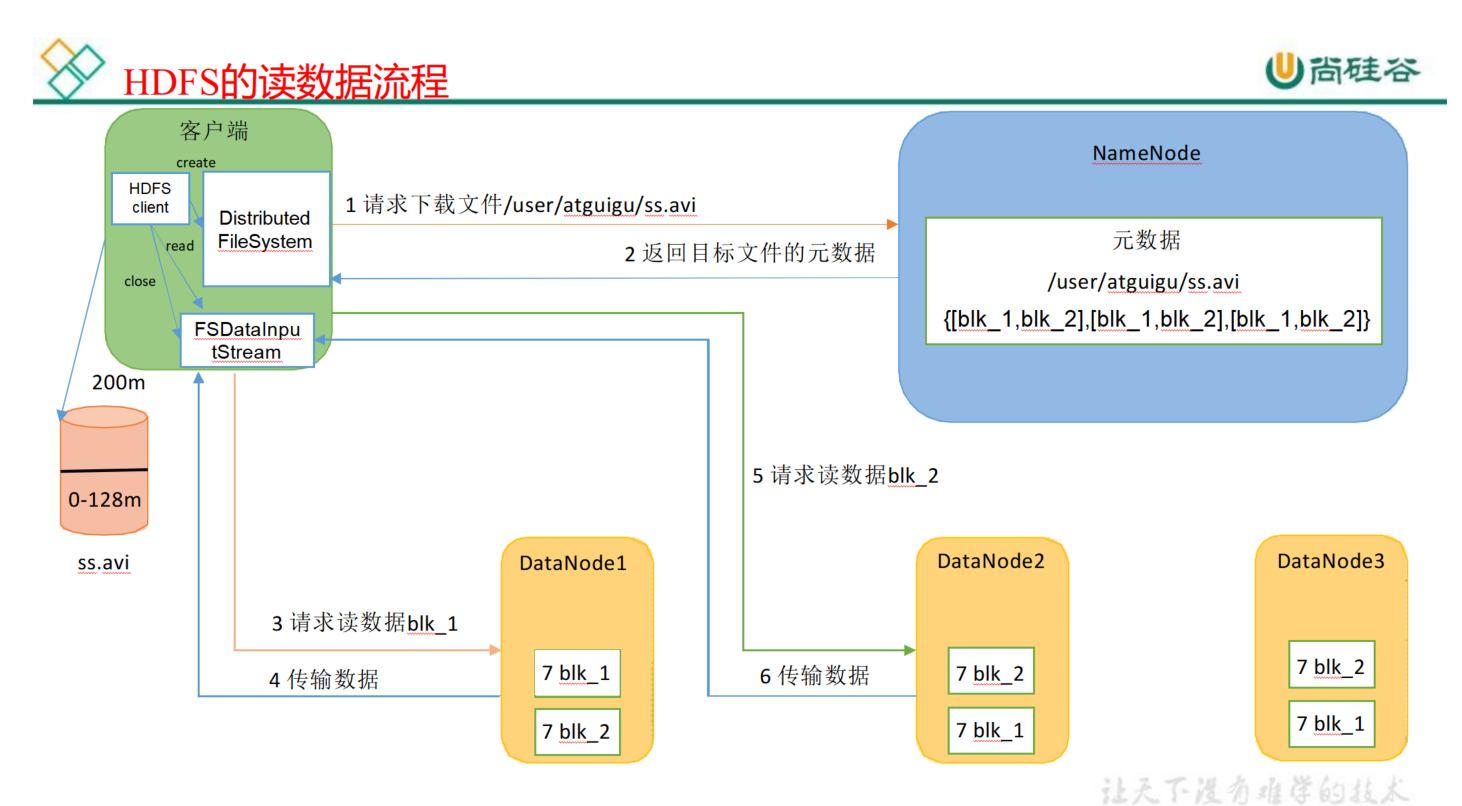
HDFS的读数据流程(重点)
NN和2NN工作机制【FsImage&Edits】(重点)
1. 原理图
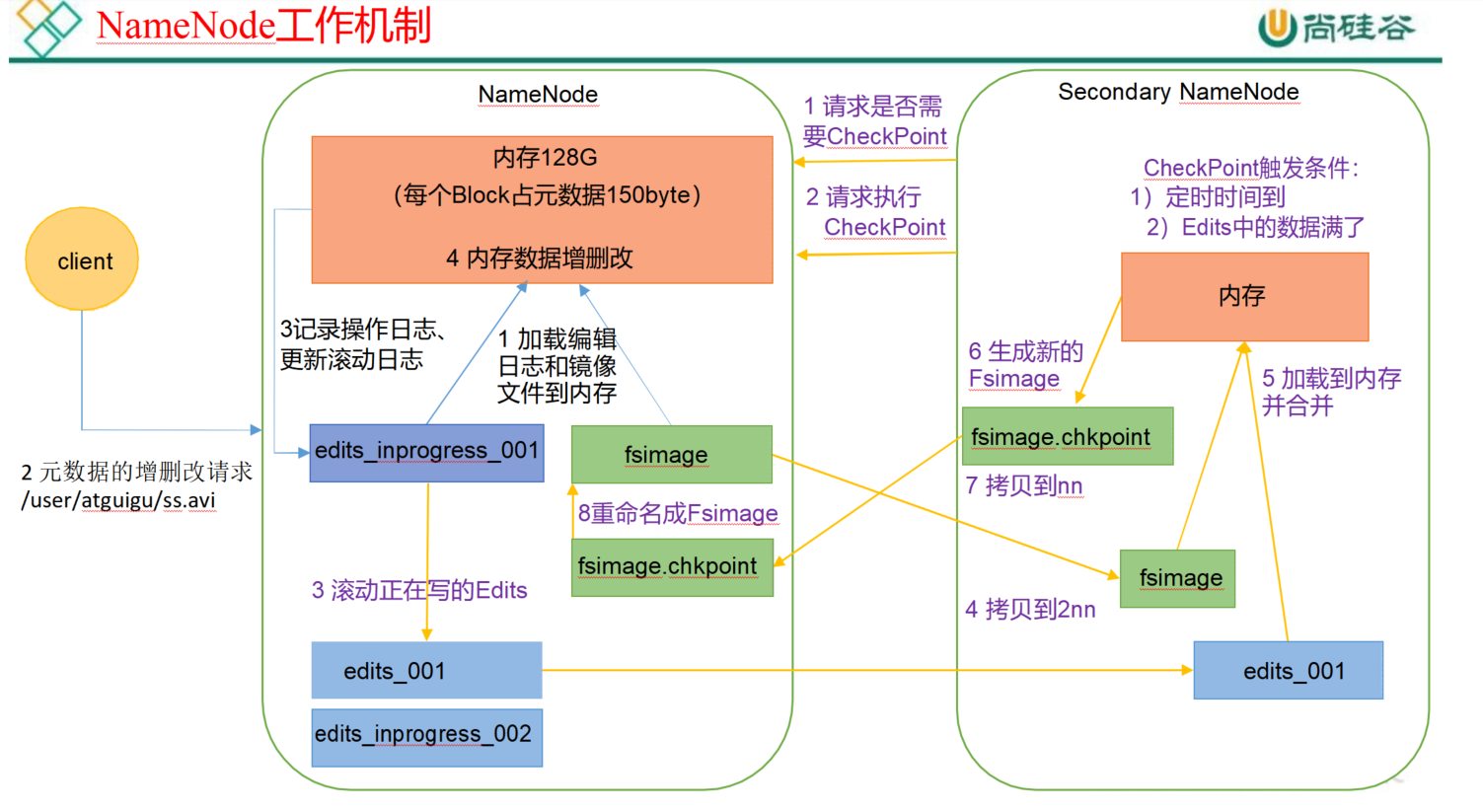
2. 基本概述
- namenode管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久
- 保存在本地磁盘上:命名空间镜像文件(fsimage)和编辑日志文件(edits)
- fsimage:nameNode中存的元数据信息进行序列化以后形成的文件(fsimage0000000001)
- edits:对nameNode中元数据更新是每一步操作
- SecondaryNameNode主要作用是合并nameNode磁盘中edits和fsimage文件形成最新的fsimage
FsImage和Edits文件都是经过序列化的,在NameNode启动的时候,他会将FsImage文件中的内容加载到内存中,之后再执行Edits文件中的各项操作,使得内存中的元数据和实际的 同步,存在内存中的元数据支持客户端的读操作。
FsImage是在磁盘中的存放,通过checkpoint功能备份内存的元数据。FsImage包含Hadoop文件系统中的所有目录和文件idnode的序列化信息,所以如果FsImage丢失或者损坏了,那么即使DataNode上有块的数据,但是我们没有文件到块的映射关系,我们也无法用DataNode上的数据!所以定期及时的备份fsimage和edits文件非常重要!
2.1 checkpoint设置
- 通常情况下,snn每隔一个小时执行一次
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
- 一分钟检查一次操作次数,当操作次数达到1百万时,snn执行一次
[hdfs-default.xml]
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value><description>操作动作次数</description></property><property><name>dfs.namenode.checkpoint.check.period</name><value>60s</value><description>1 分钟检查一次操作次数</description></property>
2.2 NameNode故障管理
namenode故障后,可以采取如下两种方法恢复数据:
NameNode故障后,可以通过下列两种方式进行恢复数据:
方法一(手动):将SecondaryNameNode文件下的数据复制到NameNode中
方法二(程序):使用-importCheckpoint选项启动NameNode的守护线程,
从而将SecondaryNameNode文件目录下的数据拷贝到NamenNode中
方法一:
模拟NameNode故障,并采用方法一,恢复NameNode的数据。
(1)kill -9 NameNode进程
(2)删除NameNode存储的数据($HADOOP_PATH/data/tmp/dfs/name)
$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
(3)拷贝SecondaryNameNode中的数据到原NameNode存储数据目录中
$ scp -r upuptop@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/
(4)重启NameNode
$ sbin/hadoop-daemon.sh start namenode
方法二:
(1)修改hdfs-site.xml文件
<property>
<name>dfs.namenode.checkpoint.period</name>
<description>原来默认是3600,修改为120</description>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
(2)模拟NameNode挂掉
kill -9 namenode进程
(3)删除namenode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
(4)如果SecondaryNameNode不和Namenode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到Namenode存储数据的平级目录,并删除in_use.lock文件。
scp -r : 基于 ssh 登陆进行安全的远程文件拷贝命令; -r 是连同文件夹及文件夹下的内容一起拷贝,要的话就是拷贝该文件夹下的所有文件
$ scp -r upuptop@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./
$ rm -rf in_use.lock
$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
$ ls
data name namesecondary
(4)导入检查点数据(等待一会ctrl+c结束掉)
$ bin/hdfs namenode -importCheckpoint
(5)启动NameNode
$ sbin/hadoop-daemon.sh start namenode
2.3 集群安全模式
NameNode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求,但是此刻,NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。
2.4 NameNode 多目录配置
1.NameNode的本地目录可以配置多个,且每个目录存放内容相同,增加了可靠性
2.具体配置
1)在hdfs-site.xml文件增加如下内容
<property><name>dfs.namenode.name.dir</name><value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value></property>
2)停止集群,删除data和logs中所有数据
[caimh@master-node hadoop-2.7.4]$ rm -rf data/ logs/ --master-node
[caimh@slave-node1 hadoop-2.7.4]$ rm -rf data/ logs/ --slave-node1
[caimh@slave-node2 hadoop-2.7.4]$ rm -rf data/ logs/ --slave-node2
3)格式化集群并启动
[caimh@master-node hadoop-2.7.4]$ hadoop namenode -format
[caimh@master-node hadoop-2.7.4]$ start-dfs.sh
[caimh@master-node hadoop-2.7.4]$ start-yarn.sh
3. 问题
NameNode 如何确定下次开机启动的时候合并哪些Edits?
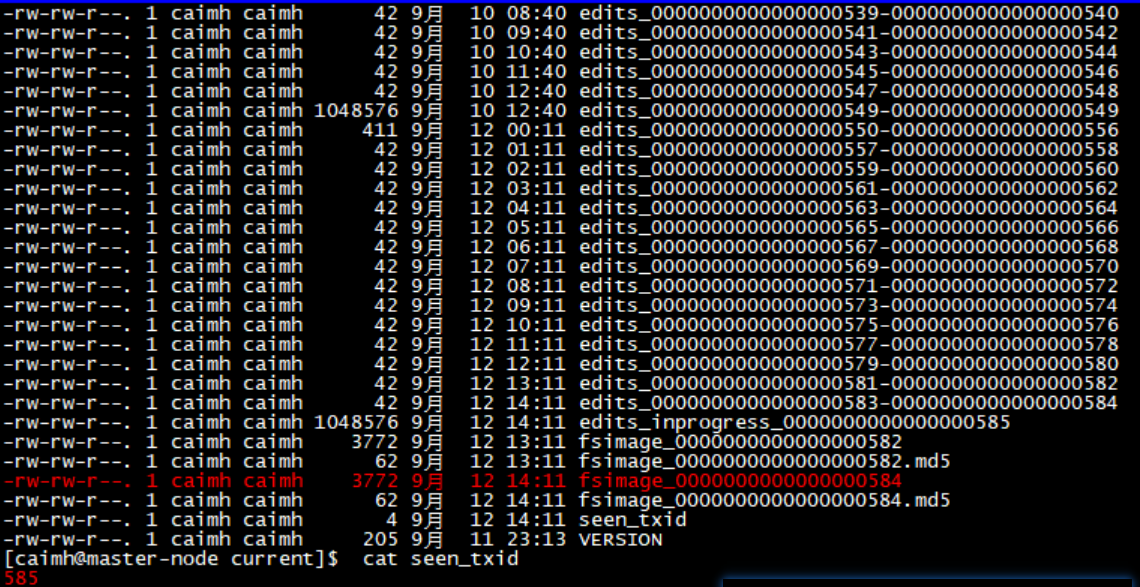
通过最新合并的fsimage_的序号(例如fsimage_0000000000000000584)和seen_txid存放的序号(如585)取它们中间的edits序号合并即可。下图中的例子是刚启动的,所以都是最新的。【fsimage可能是582,那么就有583、584要去合并】
DataNode的工作机制
1. 原理
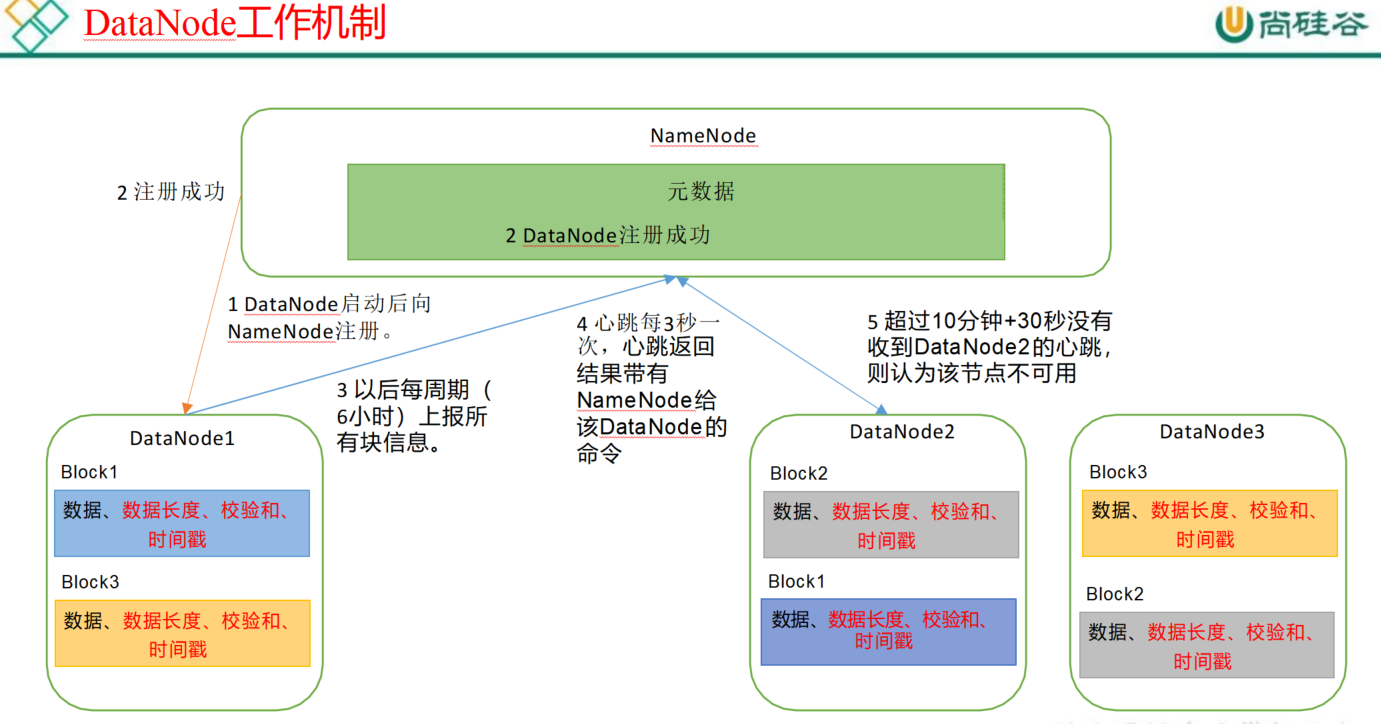
(1) 一个数据块在DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2) DataNode 启动后向NameNode 注册,通过后,周期性(6 小时)的向 NameNode 上报所有的块信息。
DN 向 NN 汇报当前解读信息的时间间隔,默认 6 小时
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
DN 扫描自己节点块信息列表的时间,默认 6 小时
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>21600s</value>
<description>Interval in seconds for Datanode to scan data</description>
</property>
(3) 心跳是每 3 秒一次,心跳返回结果带有NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个DataNode 的心跳, 则认为该节点不可用。
(4) 集群运行中可以安全加入和退出一些机器。
2. DateNode数据完整性
如下是 DataNode 节点保证数据完整性的方法。
(1) 当 DataNode 读取 Block 的时候,它会计算CheckSum。
(2) 如果计算后的 CheckSum,与Block 创建时值不一样,说明 Block 已经损坏。
(3) Client 读取其他DataNode 上的 Block。
(4)常见的校验算法 crc(32),md5(128),sha1(160)
(5)DataNode 在其文件创建后周期验证CheckSum。
3. 掉线时限参数设置
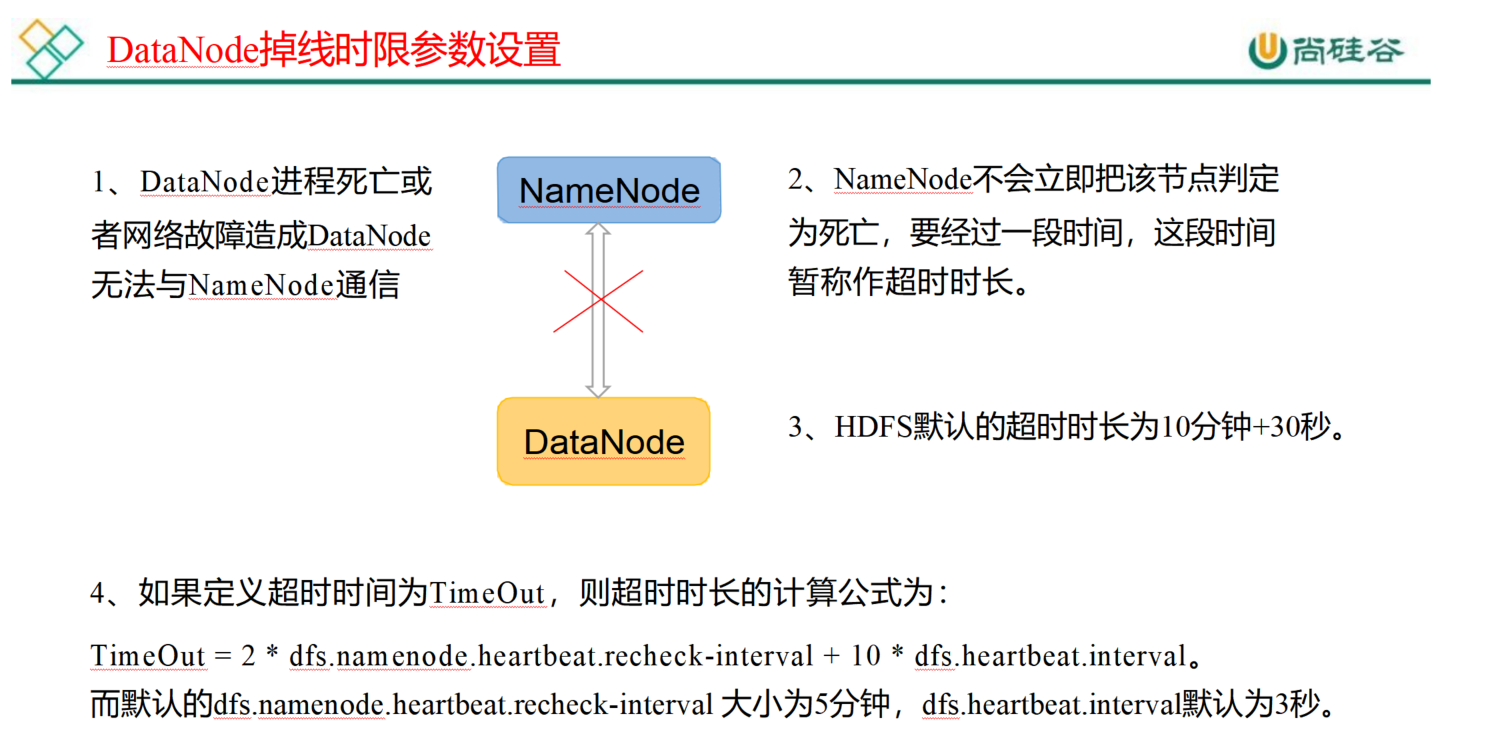
需要注意的是hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,
dfs.heartbeat.interval 的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
版权归原作者 YF_raaiiid 所有, 如有侵权,请联系我们删除。