
数据科学、数据分析、人工智能必备知识汇总-----Python爬虫-----持续更新:https://blog.csdn.net/grd_java/article/details/140574349
文章目录
一、安装和基本使用
什么是Selenium
- 一个用于Web应用程序测试的工具
- 测试直接运行在浏览器中,就像真正的用户在操作一样
- 支持通过各种driver驱动真实浏览器完成测试(例如FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)
- 支持无界面浏览器操作
特长
模拟浏览器功能,自动执行网页中js代码,实现动态加载
安装谷歌驱动
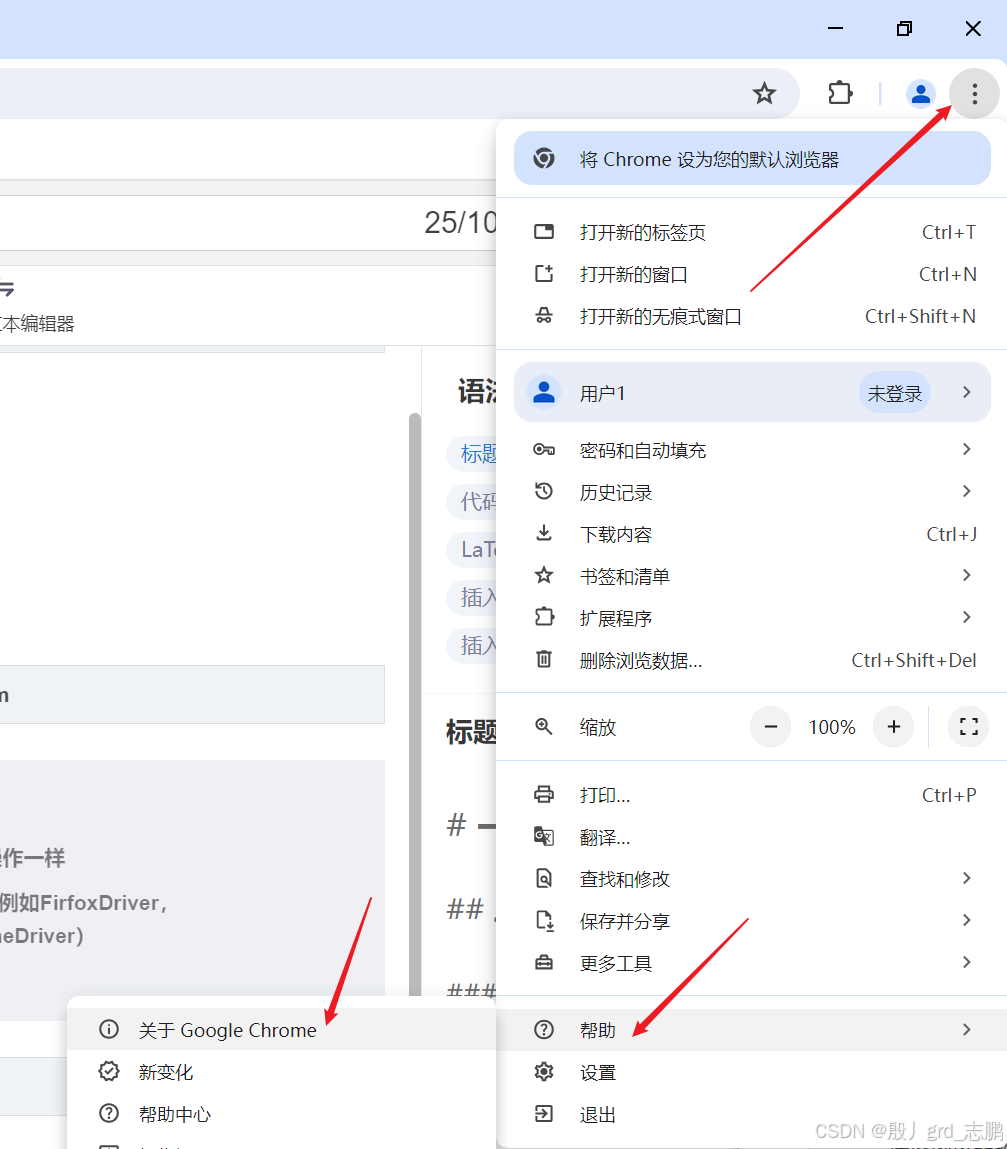
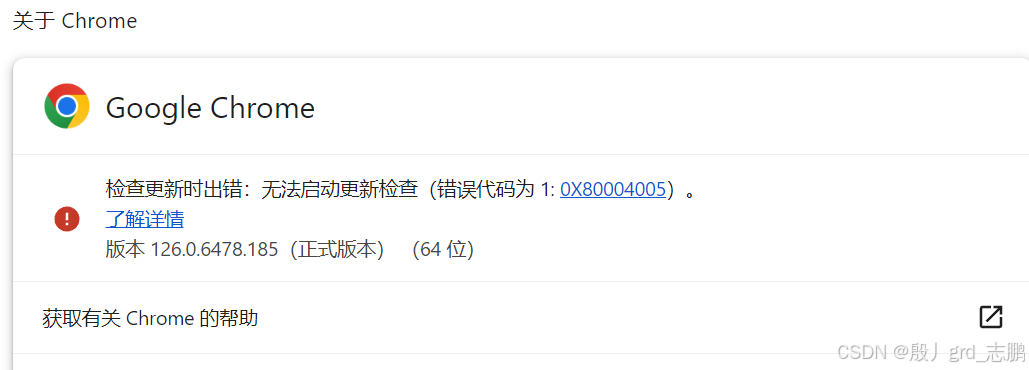
- 查看谷歌浏览器版本,只需要点击谷歌浏览器右上角的菜单按钮,然后选择帮助---->关于即可查看
- 操作谷歌浏览器的驱动下载地址(给出两个,第一个没有再去第二个):
- 选择对应版本和操作系统进行下载,上图中我的版本是126,但是这里只有127,所以可以选择额外下载127版本的chrome浏览器

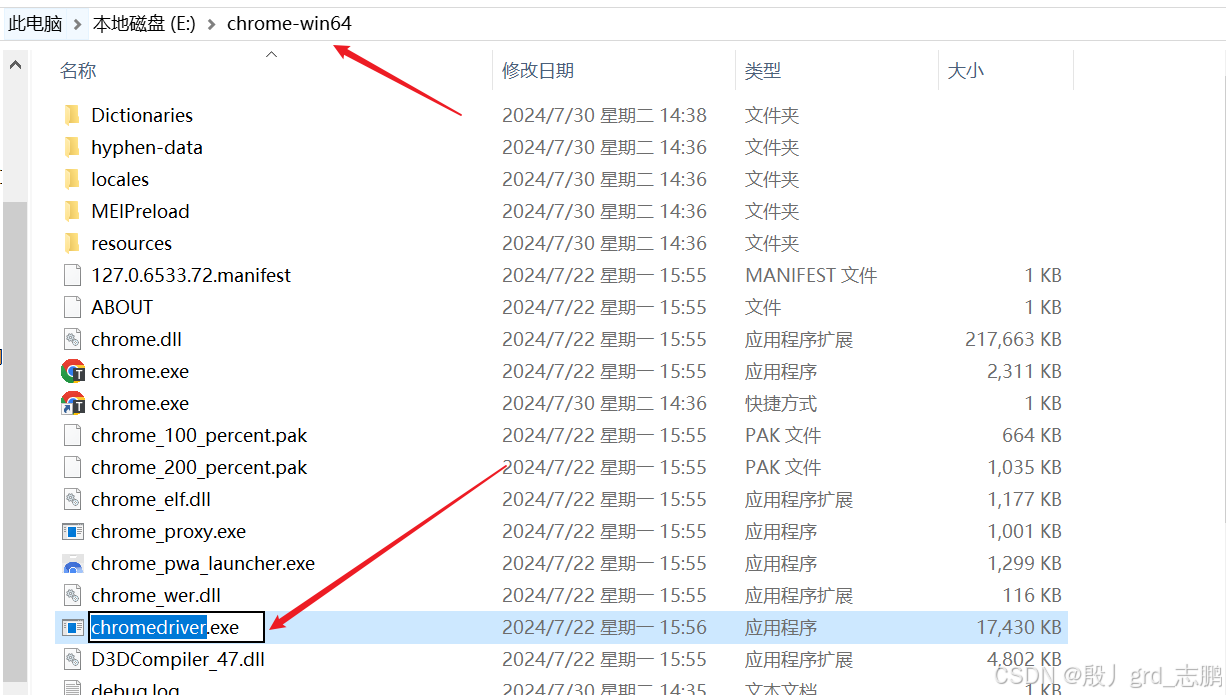
- 将下载好的压缩包解压,将驱动.exe文件拖入chrome浏览器文件夹下
python安装selenium
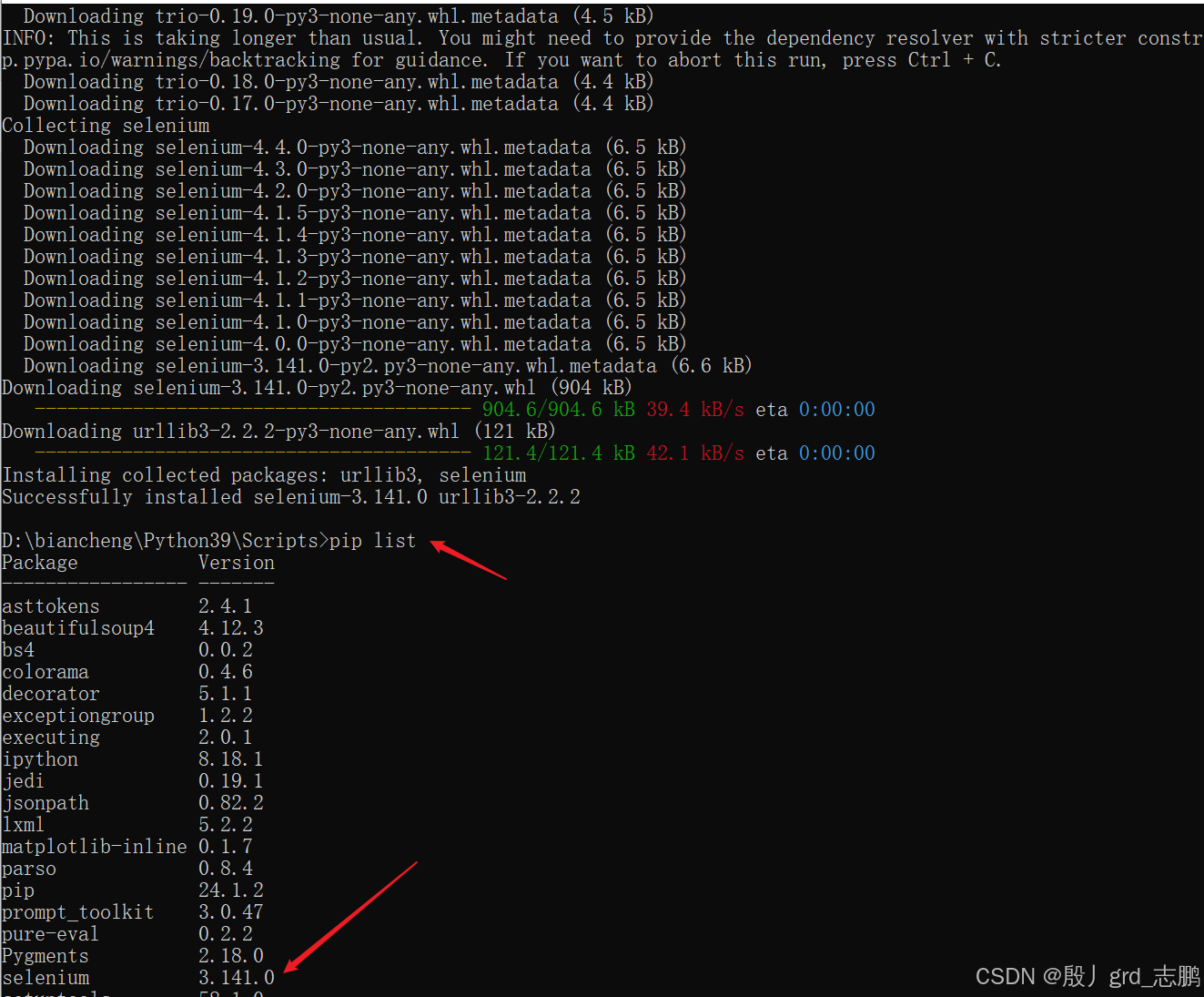
使用命令pip install selenium进行安装即可
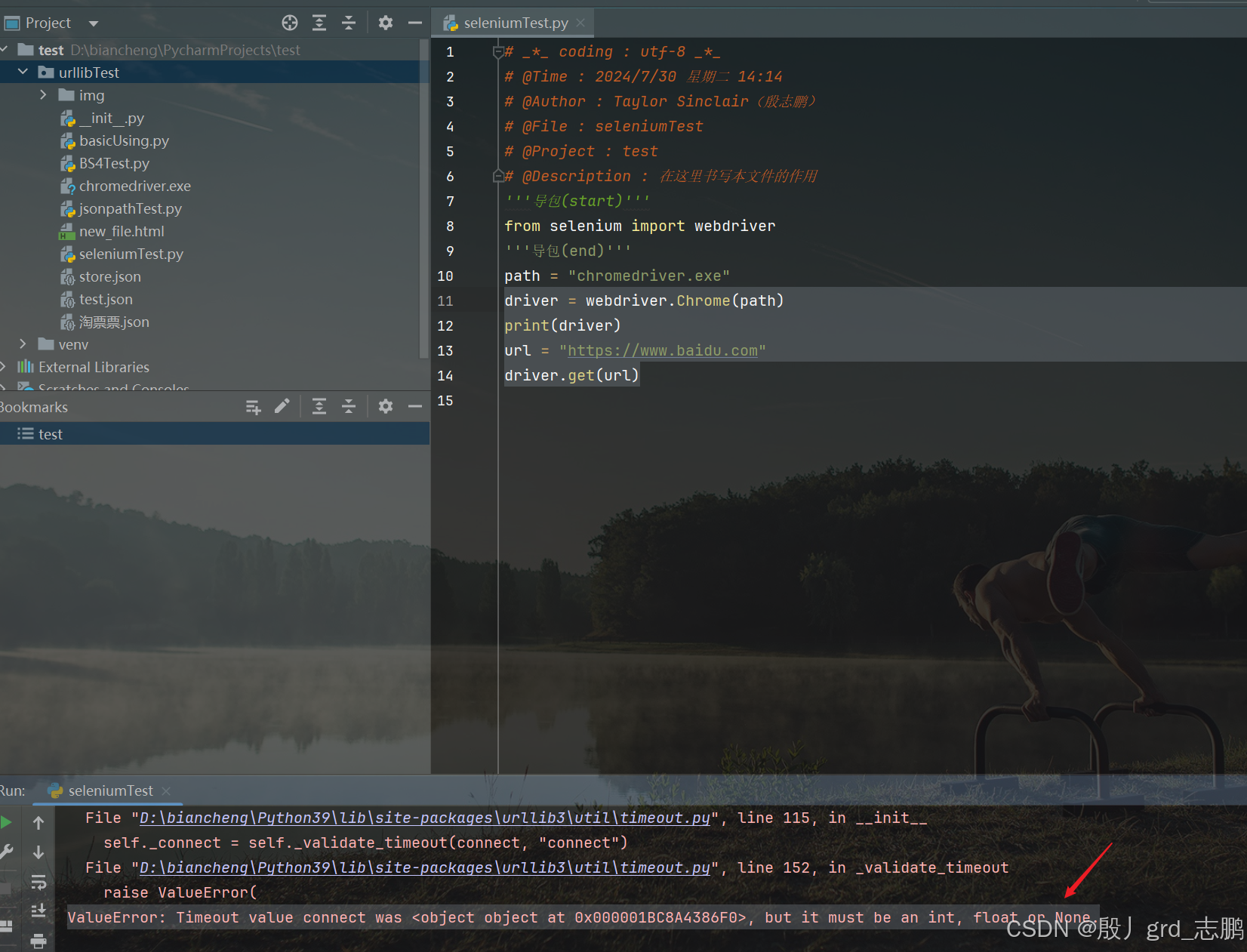
简单案例,解决常见报错
- 正常使用selenium访问百度首页,一般会报错ValueError: Timeout value connect was <object object at 0x000001BC8A4386F0>, but it must be an int, float or None.
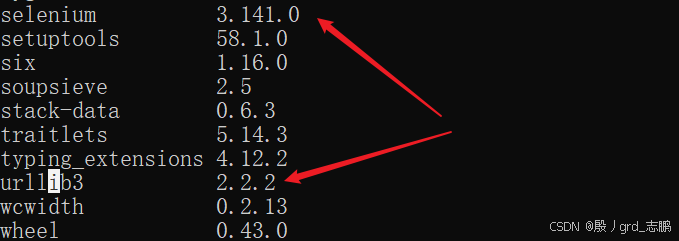
- 这是因为和urllib3的版本不兼容导致
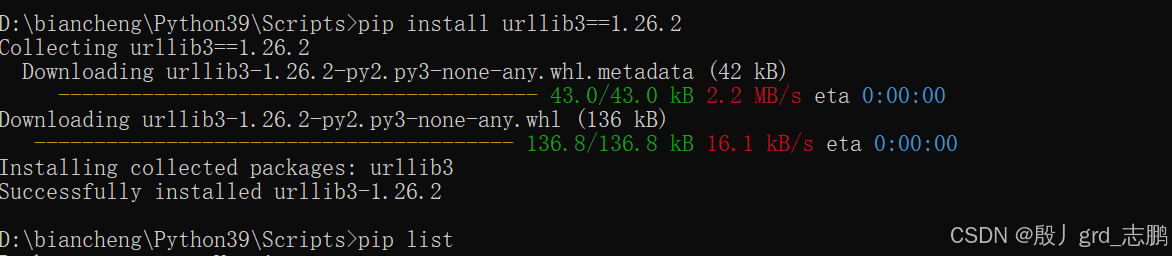
- 所以将urllib3降低到1.26.2版本,首先使用命令pip uninstall urllib3卸载,然后安装指定版本(pip install urllib3==1.26.2)
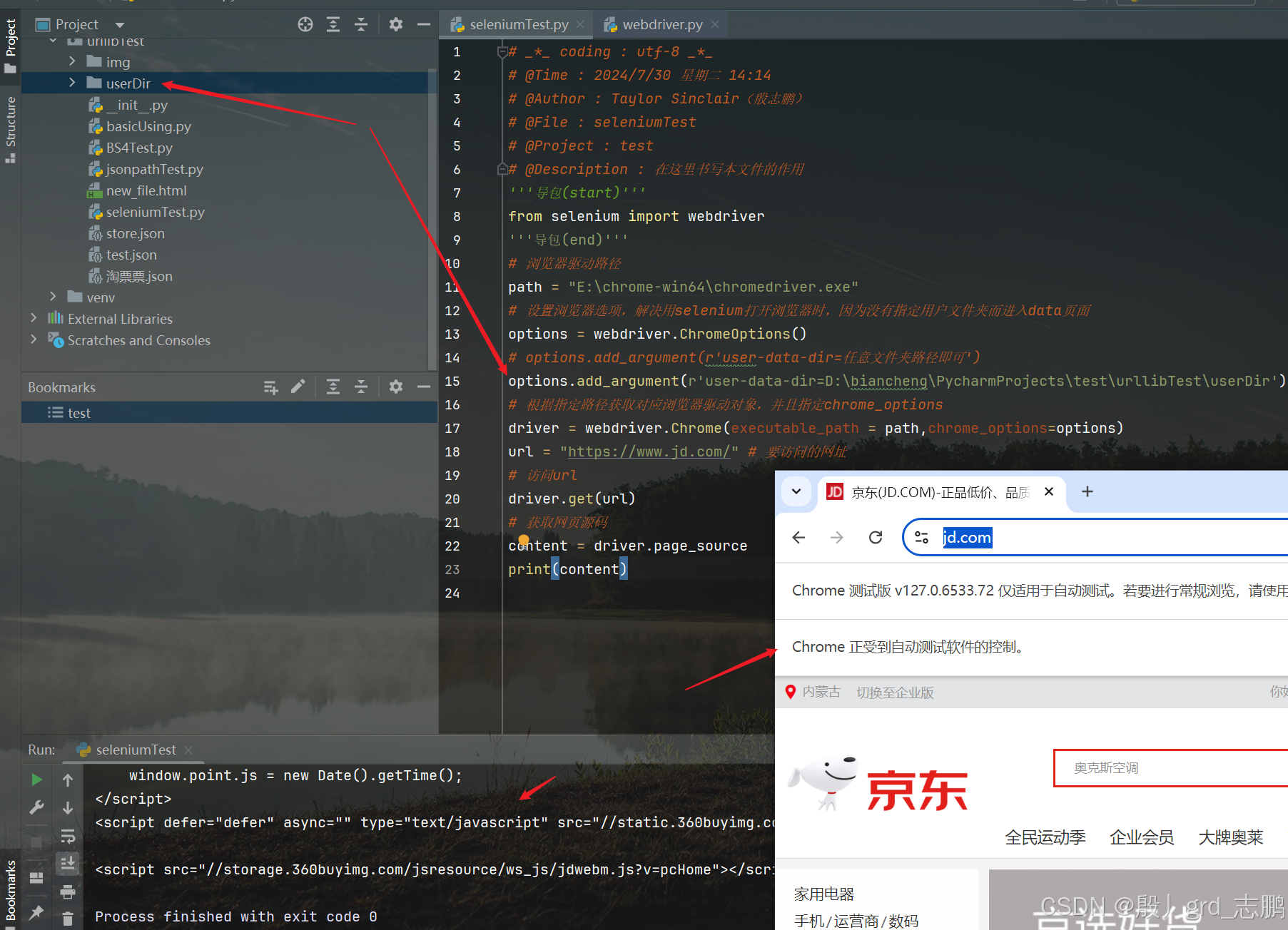
访问京东首页,让京东知道我们是真实的浏览器在访问,从而将所有数据交给我们,而不是隐藏部分数据
注意我们要指定一个谷歌浏览器的用户文件夹(随便一个即可),就可以正常访问了。但是访问后,浏览器会显示Chrome正受到自动测试软件的控制,这是接下来我们要解决的问题
'''导包(start)'''from selenium import webdriver
'''导包(end)'''# 浏览器驱动路径
path ="E:\chrome-win64\chromedriver.exe"# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url ="https://www.jd.com/"# 要访问的网址# 访问url
driver.get(url)# 获取网页源码
content = driver.page_source
print(content)
二、元素定位
元素定位:自动化要做的就是模拟鼠标和键盘操作来操作这些元素,点击、输入操作等等。首先要找到这些元素,WebDriver提供了很多定位元素的方法。
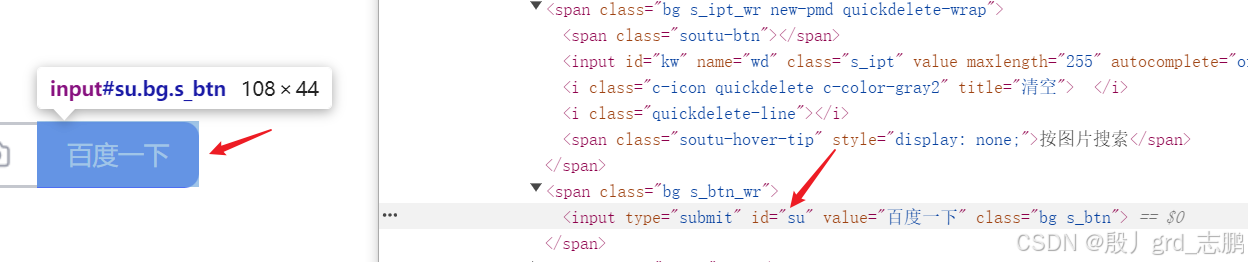
根据id定位百度一下按钮
- 可以发现按钮的id为su
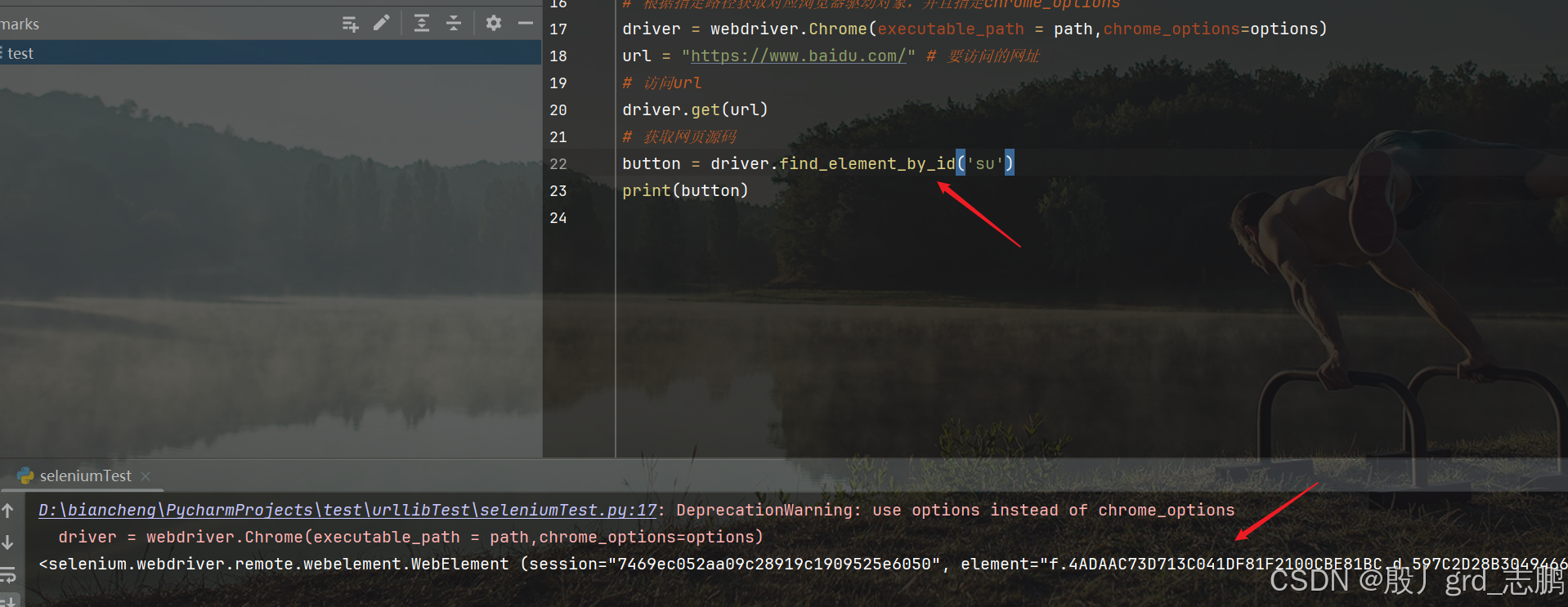
- 我们直接通过driver.find_element_by_id()来进行查找
'''导包(start)'''from selenium import webdriver
'''导包(end)'''# 浏览器驱动路径
path ="C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url ="https://www.baidu.com/"# 要访问的网址# 访问url
driver.get(url)# 获取网页源码input= driver.find_element_by_id('su')print(input)
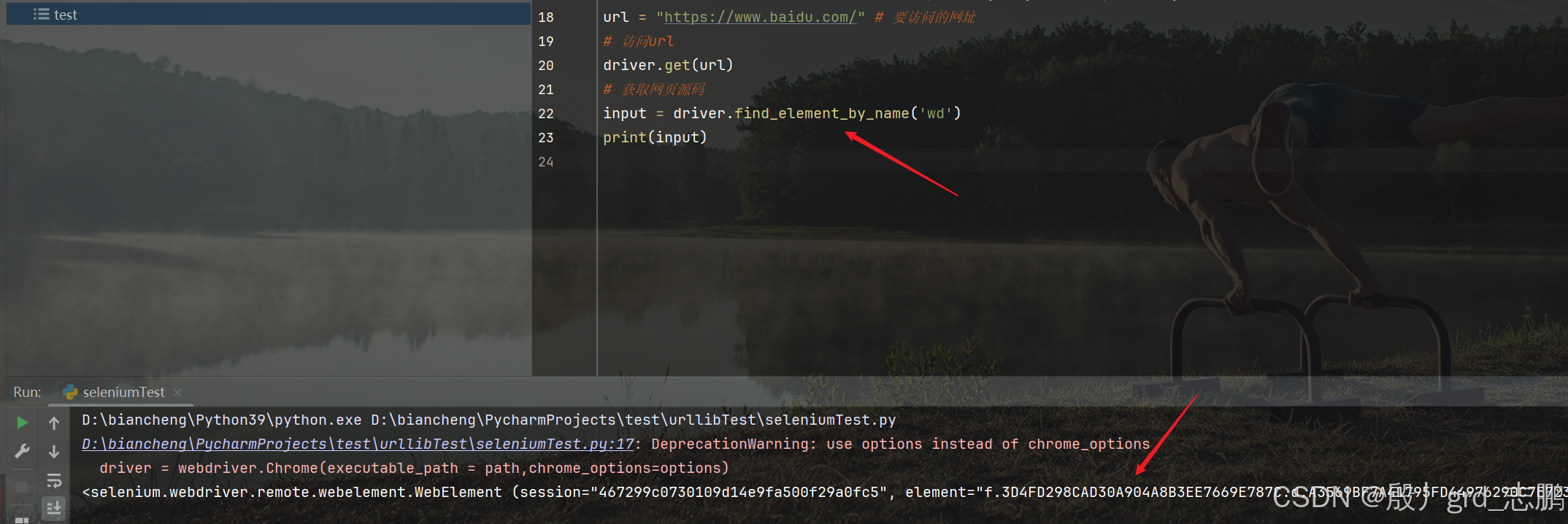
根据name属性定位input输入框
- 可以发现搜索框的name属性值为wd
- 我们直接通过driver.find_element_by_id()来进行查找

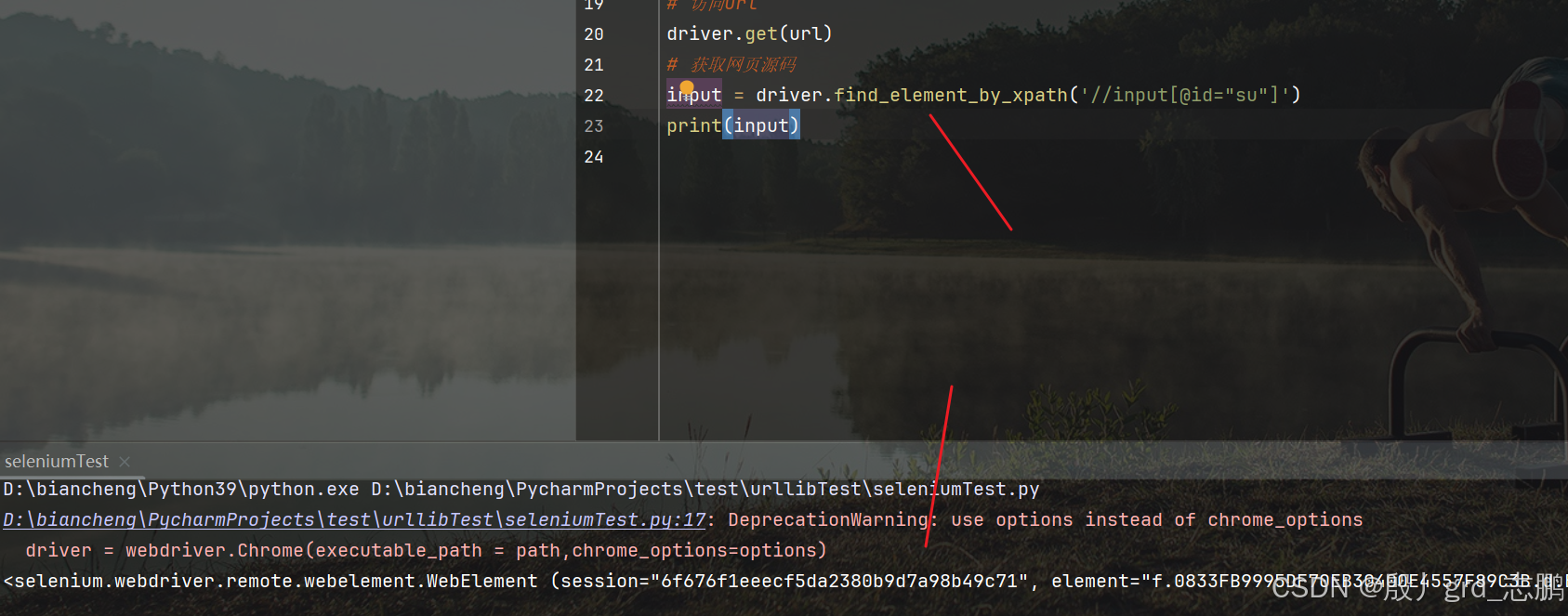
根据xpath路径找到百度一下按钮
- 先确定其xpath路径
- 通过driver.find_element_by_xpath(‘//input[@id=“su”]’)进行定位

根据标签名定位所有input
通过driver.find_elements_by_tag_name(‘input’),将所有input控件保存到list列表返回
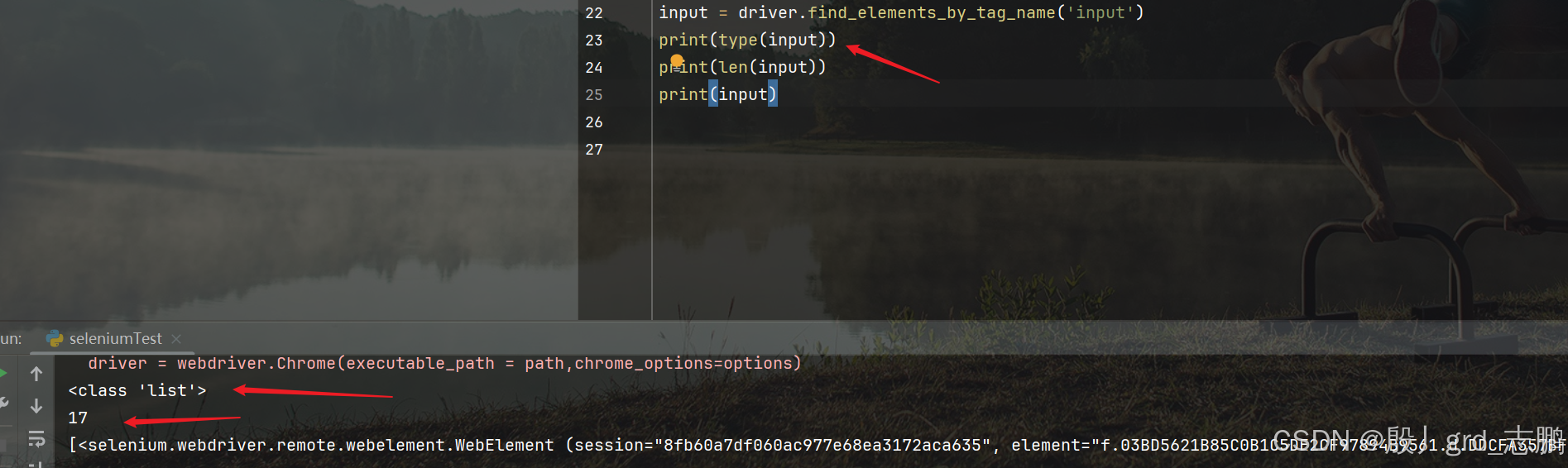
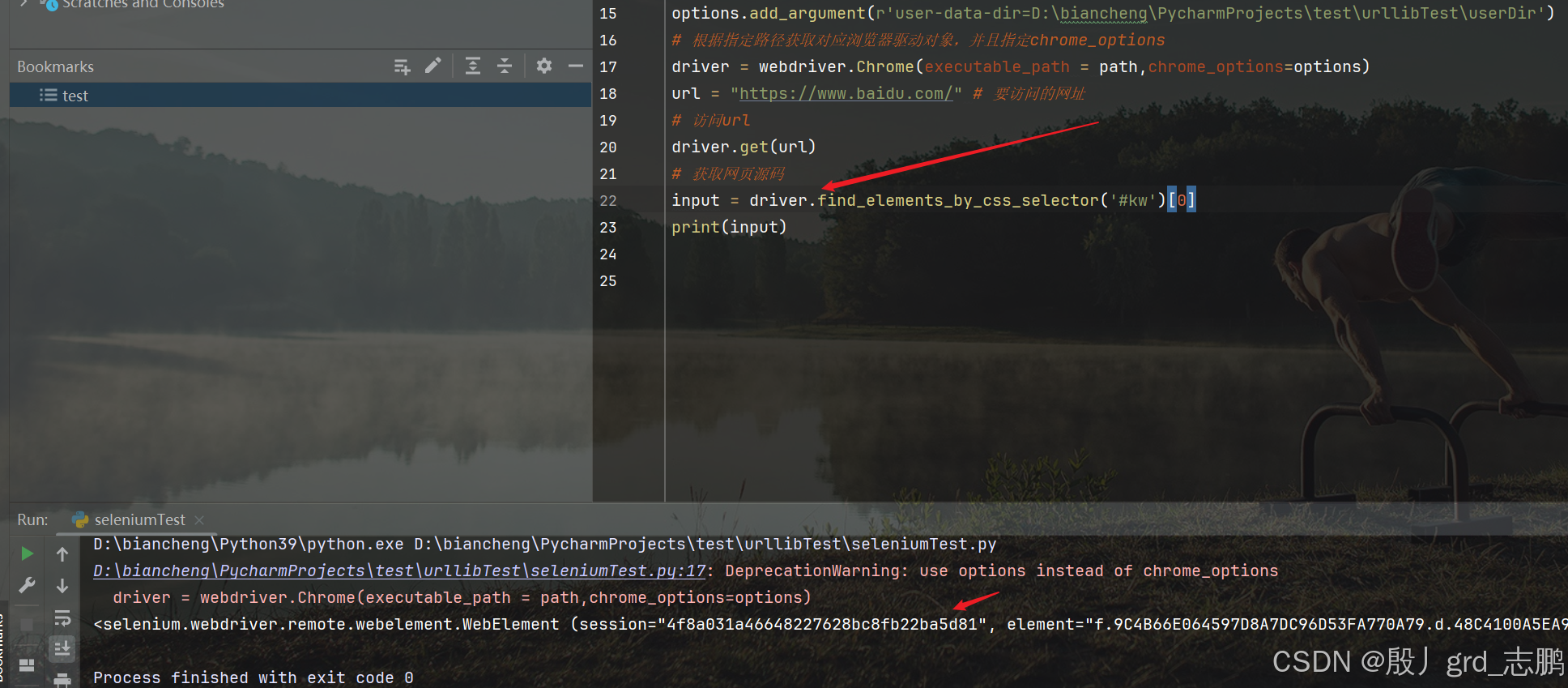
通过css选择器语法定位id为kw的元素
- 百度搜索框id为kw
- 通过driver.find_elements_by_css_selector(‘#kw’)[0]获取

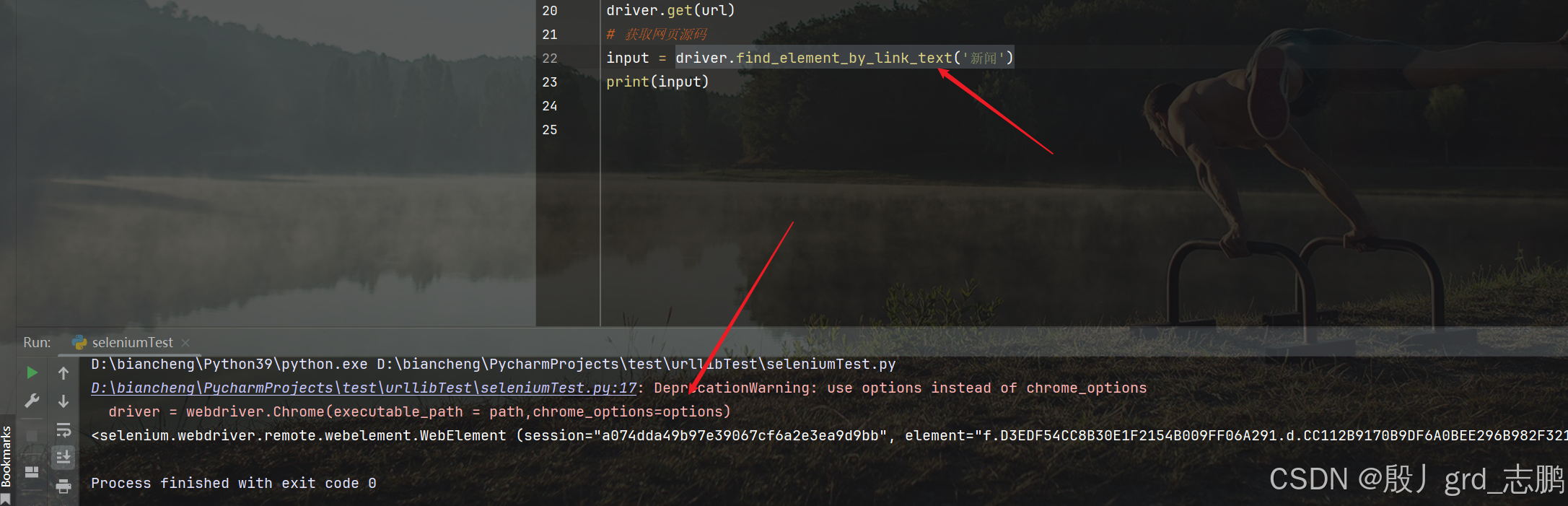
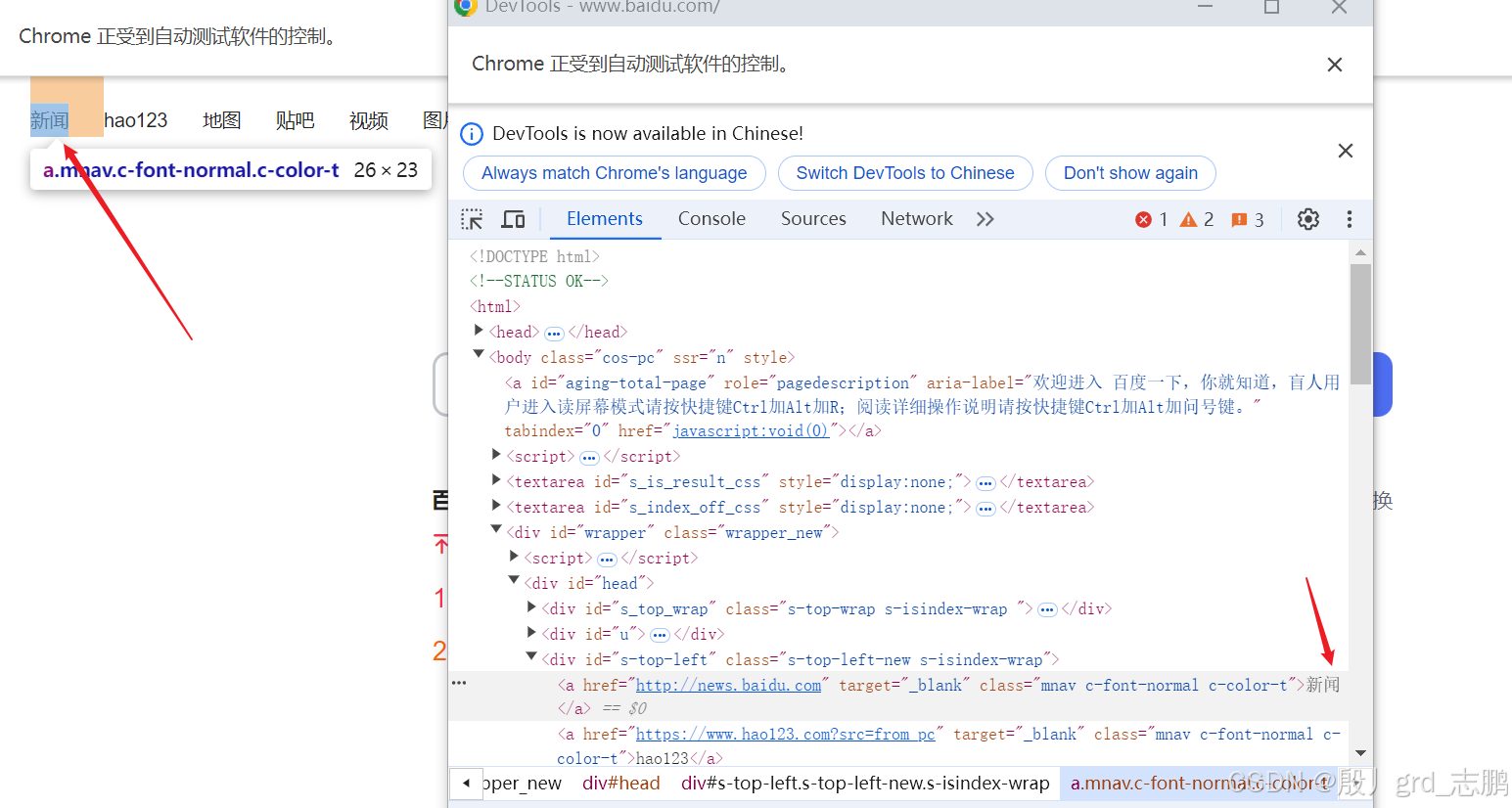
通过超链接定位
- 定位百度首页左上角第一个超链接"新闻"
- 通过driver.find_element_by_link_text(‘新闻’)获取即可

三、访问元素信息
上面讲解了如何找到元素,现在来介绍如何获取这些元素的信息
获取元素属性
- 获取新闻超链接的class属性
- 通过目标元素对象.get_attribute(“class”)获取即可

'''导包(start)'''from selenium import webdriver
'''导包(end)'''# 浏览器驱动路径
path ="C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url ="https://www.baidu.com/"# 要访问的网址# 访问url
driver.get(url)# 获取网页源码input= driver.find_element_by_link_text('新闻')print(input.get_attribute("class"))
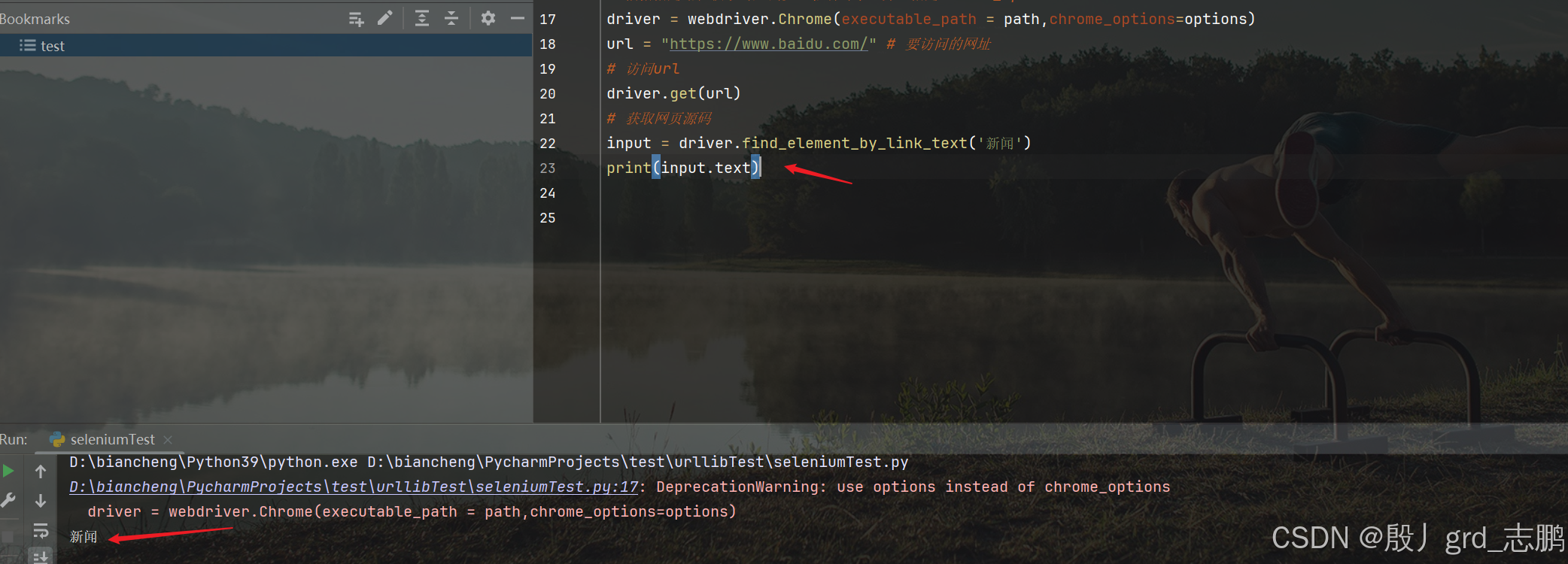
获取元素文本内容
- 获取新闻超链接的标签内容
- 通过目标元素对象.text来获取
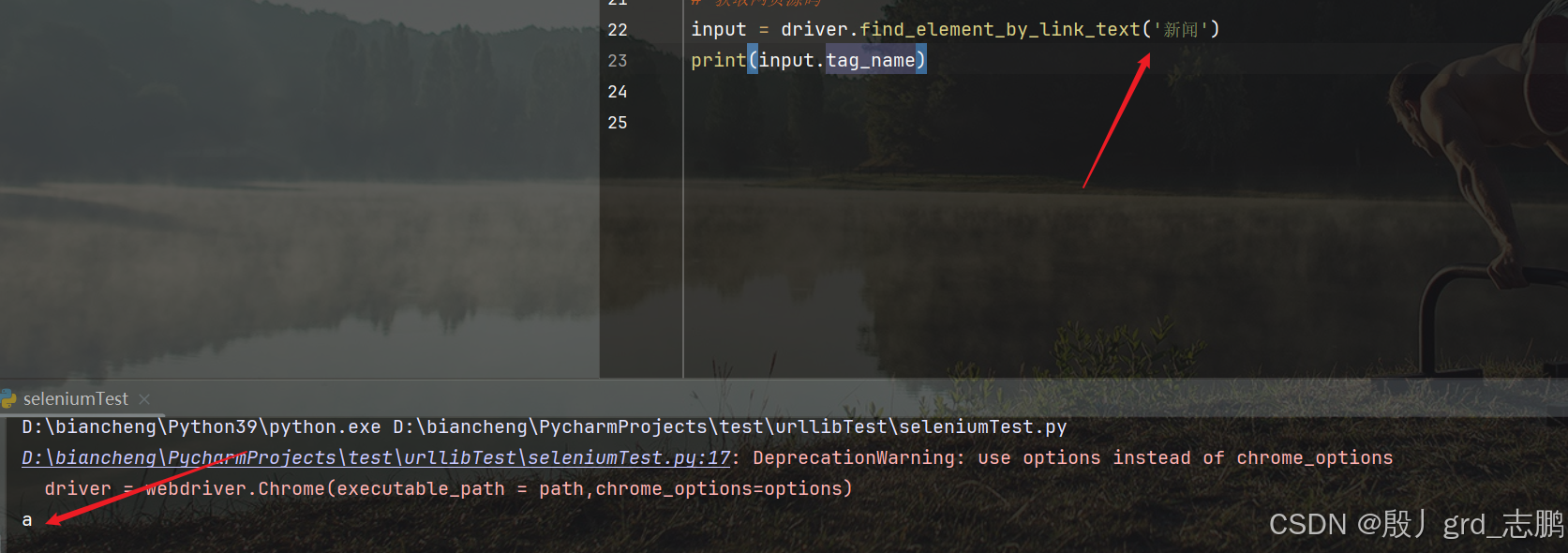
获取标签名
通过目标元素对象.tag_name来获取
四、自动化交互
找到元素后,不能只是获取内容,还要进行自动化交互,例如点击按钮等操作
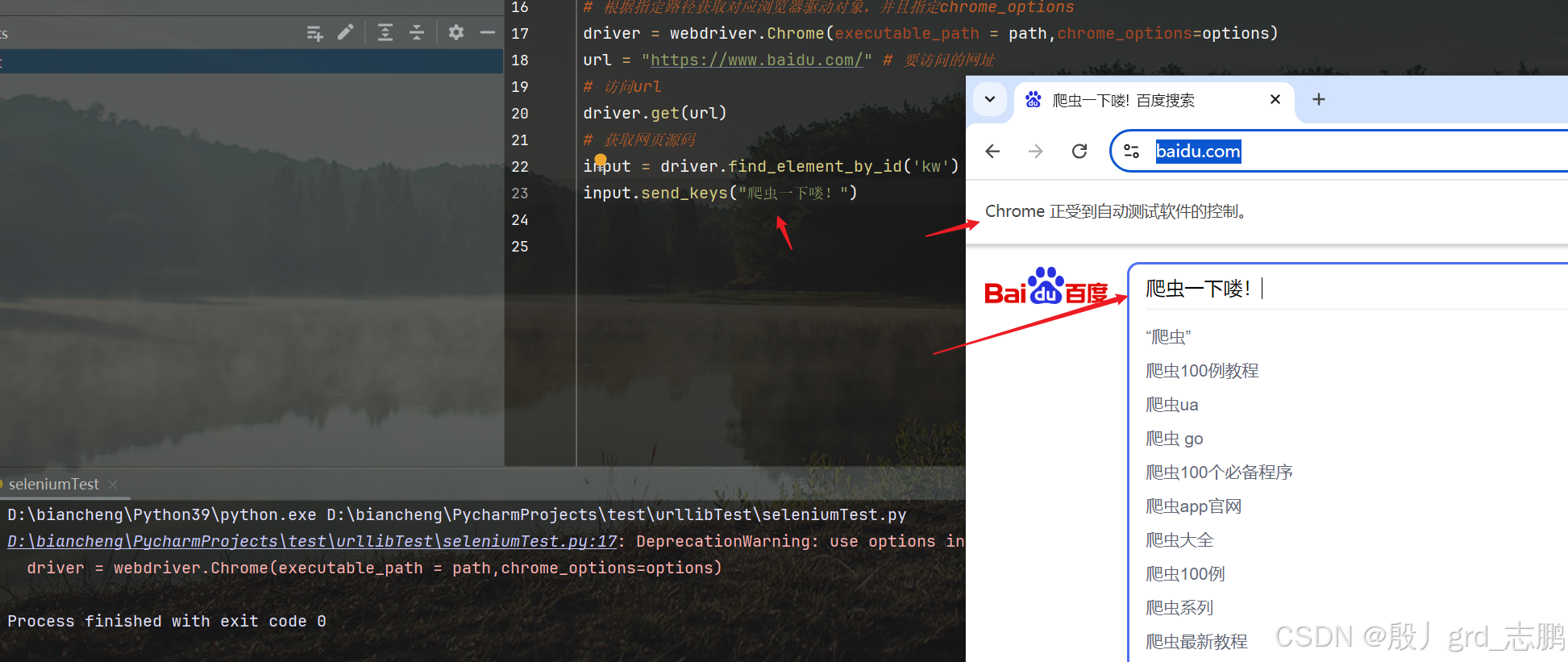
在百度一下搜索框输入文字
通过目标元素.send_keys(“爬虫一下喽!”),将"爬虫一下喽!"输入到搜索框
'''导包(start)'''from selenium import webdriver
'''导包(end)'''# 浏览器驱动路径
path ="C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url ="https://www.baidu.com/"# 要访问的网址# 访问url
driver.get(url)# 获取网页源码input= driver.find_element_by_id('kw')input.send_keys("爬虫一下喽!")
点击百度一下按钮

input= driver.find_element_by_id('kw')input.send_keys("爬虫一下喽!")
baiduButton = driver.find_element_by_id('su')
baiduButton.click()
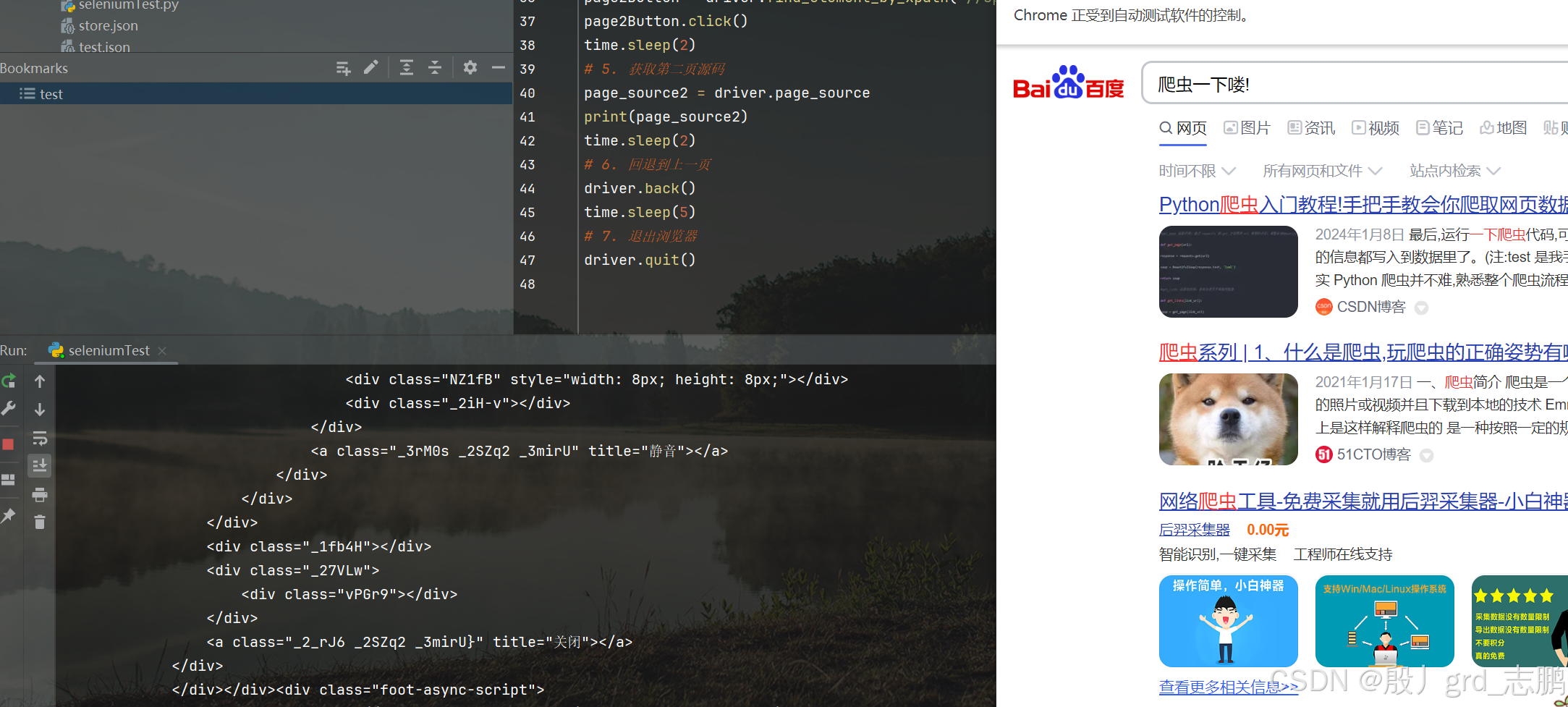
在上面的基础上,实现向下滑动到页面底部,点击第二页按钮,获取第二页源码,回退到上一级,然后在前进一级(回退的逆操作),然后关闭浏览器
- 获取第二页按钮的xpath语句为://span[@class = “page-item_M4MDr pc” and text()=2]
- 代码实现

'''导包(start)'''from selenium import webdriver
import time
'''导包(end)'''# 浏览器驱动路径
path ="C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"# 设置浏览器选项,解决用selenium打开浏览器时,因为没有指定用户文件夹而进入data页面
options = webdriver.ChromeOptions()# options.add_argument(r'user-data-dir=任意文件夹路径即可')
options.add_argument(r'user-data-dir=D:\biancheng\PycharmProjects\test\urllibTest\userDir')# 根据指定路径获取对应浏览器驱动对象,并且指定chrome_options
driver = webdriver.Chrome(executable_path = path,chrome_options=options)
url ="https://www.baidu.com/"# 要访问的网址# 访问url
driver.get(url)# 互动操作# 1. 获取搜索框,并输入爬虫一下喽!input= driver.find_element_by_id('kw')input.send_keys("爬虫一下喽!")
time.sleep(2)# 2. 获取百度一下按钮,并单击
baiduButton = driver.find_element_by_id('su')
baiduButton.click()
time.sleep(2)# 3. 执行js代码,定位到距离网页上端100000的位置,也就是类似于向下滑100000个像素
js ="document.documentElement.scrollTop=100000"
driver.execute_script(js)
time.sleep(2)# 4. 点击第二页按钮
page2Button = driver.find_element_by_xpath("//span[@class = 'page-item_M4MDr pc' and text()=2]")
page2Button.click()
time.sleep(2)# 5. 获取第二页源码
page_source2 = driver.page_source
print(page_source2)
time.sleep(2)# 6. 回退到上一页
driver.back()
time.sleep(2)# 7. 前进一级
driver.forward()
time.sleep(2)# 8. 退出浏览器
driver.quit()
五、PhantomJS
- 一个无界面浏览器,前面直接用selenium打开的浏览器,和我们人为打开是一样的,这样的操作对于程序来说有些太慢了
- 支持页面元素查找,js执行等等
- 由于不进行css和GUI渲染,运行效率要比真实浏览器快很多
但是因为这个团队已经散伙,所以这个已经不再更新了,老项目你依然会见到它,这里提一下就是让大家不要日后见到两眼懵
而现如今,Chrome headless用的更多一点
六、Chrome headless
Chrome-headless模式是Google在Chrome浏览器59版所新增的一种模式,可以让你在不打卡UI界面的情况下使用Chrome浏览器,运行效果与Chrome完美的保持了一致性
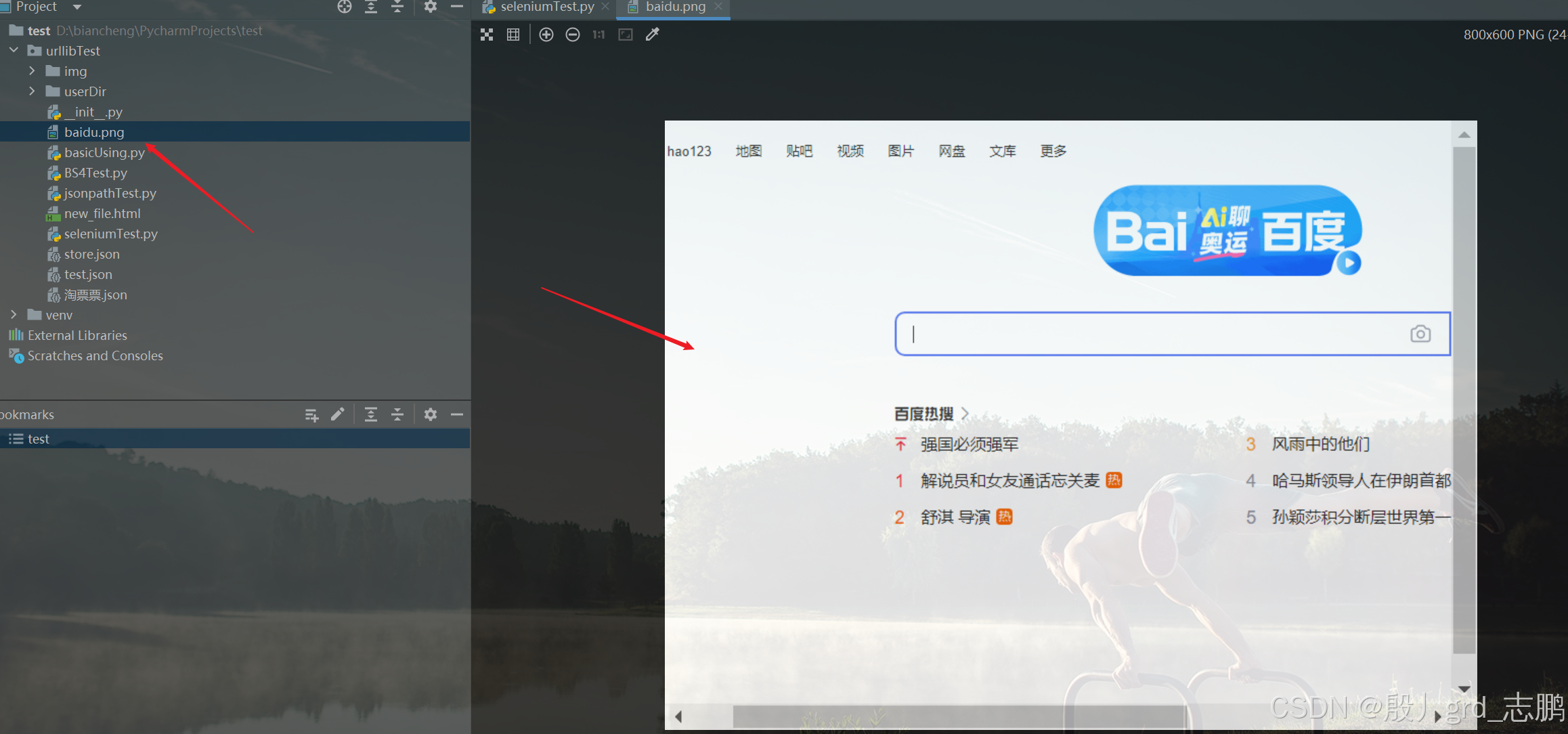
代码层面,除了需要一些固定代码创建Chrome headless对象以外,其余操作代码与上面直接用selenium打开浏览器是一样的。下面的代码是用Chrome headless模式打开百度首页,并且截屏
'''导包(start)'''from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
'''导包(end)'''# 固定写法,获取chrome headless对象defget_headless_browser(executable_path):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')# path是我们chrome浏览器的绝对路径
path =r'C:\Users\Administrator\AppData\Local\Google\Chrome\Bin\chrome.exe'
chrome_options.binary_location = path
brower = webdriver.Chrome(executable_path=executable_path, chrome_options=chrome_options)return brower
if __name__ =='__main__':# 驱动路径,如果配置到环境变量中,可以不进行这一步
executable_path ="C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Bin\\chromedriver.exe"# 获取chrome headless对象
brower = get_headless_browser(executable_path)# 其余使用方法和有界面是相同的
brower.get('https://www.baidu.com')# 截屏——当前操作界面
brower.save_screenshot('baidu.png')
版权归原作者 殷丿grd_志鹏 所有, 如有侵权,请联系我们删除。