
Kafka_04_Topic和日志
Topic/Partition
Topic/Partition: Kafka中消息管理的基础单位
- Topic和Partition并不实际存在(仅逻辑上的概念)
如: Topic和Partition关系
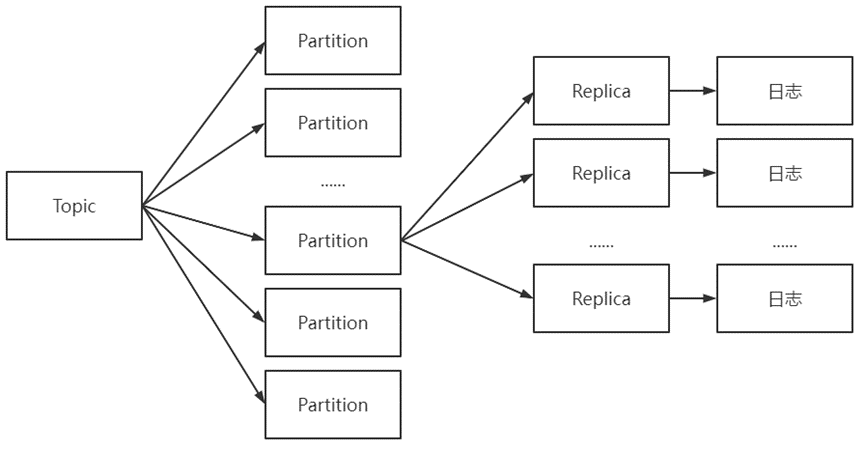
// 每个日志文件可对应多个日志分段, 其还可分为索引、日志存储和快照等
Topic
Topic(主题): Kafka中消息归类单位
- Topic管理本质: 管理Topic对应的日志存储(文件)
- 日志存储随机分步于各个Broker以提搞Topic容灾性
- 日志存储数量 = Partition数量 * Replica数量
- 存储文件格式:
Topic名-Partition名-序列号
// 可通过Kafka自带kafka-topics.sh脚本完成Topic相关管理
Topic名称组成: 大小写字母、数字、点号、连接线、下划线
- Topic名称必须含有点号或下划线(metrics命名时会将前者替换为后者)
- 不建议使用双下划线作为前缀(其常为内部Topic格式)
- 创建Topic的本质(交由控制器异步完成)
// ZooKeeper的
/brokers/topics/
和
/config/topics/
下创建子节点并写入Partition分配方案和配置信息
管理Topic须知:
- 创建Topic时Broker需统一是否配置机架信息, 否则会创建失败
- Topic创建后仅能增加Partition数量(Partition不能被删除)
- Partition数量变化会影响Key的计算(影响消息顺序)
Partition
Partition(分区): 组成Topic的单位(实际存储消息)
- Partition可有多个副本(leader和follower), 每个副本对应个日志文件
- leader提供读写服务, follower副本仅和leader进行数据同步
- leader恢复后重新加入, 则只能为新的follower
优先副本: AR集合中首个副本
- 理想情况下优先副本应是Partition的leader
- Kafka会确保所有Topic的优先副本在集群中均匀分布
- Partition平衡: 通过选举策略使优先副本选举为leader副本
// 优先副本选举的元数据存储于ZooKeeper的
/admin/preferred_replica_election
Partition重分配: Partition重新进行合理的分配
- 当Partition所处的Broker节点下线, Kafka不会自动进行故障转移
- Kafka集群中增加新Broker节点时, 该节仅能分配到新创建的Partition
- 本质:部分Partition增加新副本, 并从剩余Partition的副本中拷贝数据
- Partition重复配过程中需保证有足够的空间(完成后自动删除原有数据)
// 建议分为多个小批次执行Partition重分配, 并重启预下线的Broker
Partition数量与吞吐量关系:: 限定范围内增加Partition数量可增加吞吐量
- 若无休止增加Partition数量, 超出限定范围后吞吐量反而下降
- Partition数量有上限(过多会导致Kafka进程崩溃)
- Partition也是最小的并行操作单位
日志存储
日志(Log): Partition对应的物理存储
- 日志以目录方式存储多个LogSegment
- 日志的目录命名格式:
Topic名称-Partition名称 - 数据均以追加方式写入日志, 且以特定顺序进行追加
如: 日志存储关系
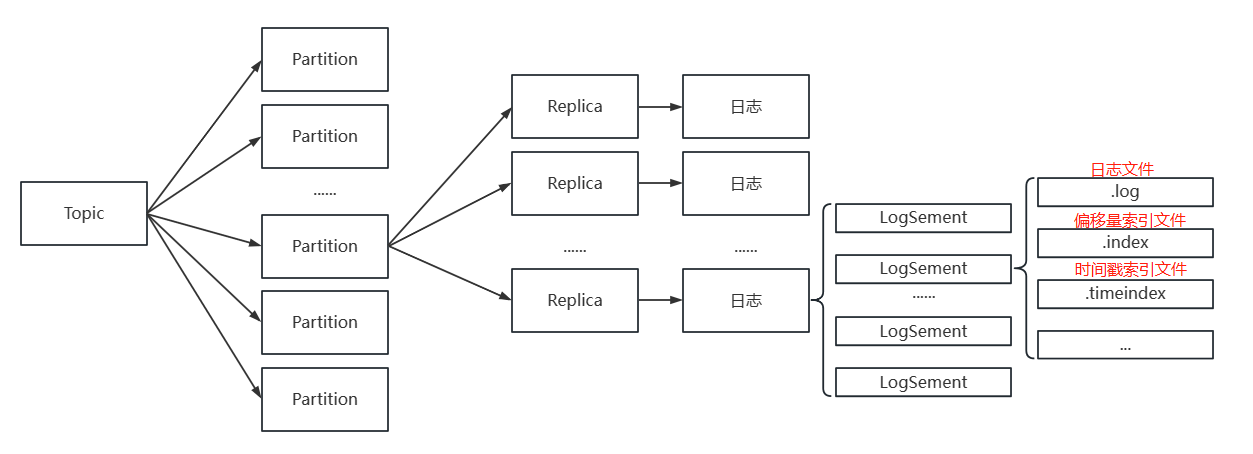
// LogSegment还包含
.deleted
、
.cleaned
、
.swap
等后缀文件
LogSegment(日志分段): 组成日志的基础单位
- 每个LogSement必须有个日志文件和两个索引文件
- 日志的最后个LogSegment才可执行写入, 其他仅存储数据
- BaseOffset(基准偏移量): 每个LogSegment中首个消息的偏移量
- 文件均以BaseOffset格式进行命名(固定为20位数字, 用0填充多余位)
// BaseOffset是64位长整型数据, 其可得知前个LogSegment的数据量
日志索引: 稀疏索引实现消息的快速检索
- 稀疏索引达到指定大小后才建立索引(不保证Record均有对应的索引项)
- 稀疏索引通过
MappedByteBuffer将索引文件映射到内层中 - 通过二分定位小于指定偏移量的最大偏移量
- 各索引均严格单调递增
存储格式
存储格式: 日志存储在硬盘的格式
- 日志的存储格式决定其占用空间大小和检索速率
- 日志的存储格式演进为3个版本: v0(0.10.0)、v1(0.11.0)、v2
如: 日志存储格式
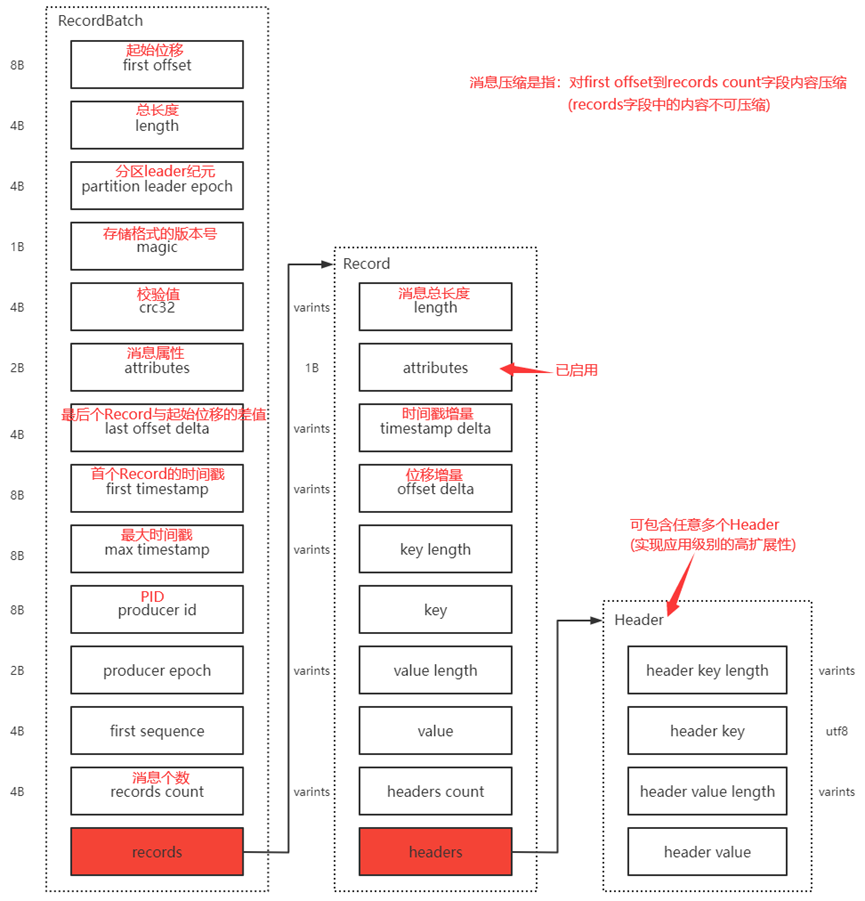
// Varints(变长整型): 使用任意多个字节序列化记录整数(特定范围减少空间)
消息压缩: 将RecordBatch压缩成单个Record
- 压缩生成的消息记为外层消息(反者为内层消息)
- 外层消息的key为null, 而value为内层消息(偏移量查找)
- 内层消息的偏移量均从0开始(使用时Broker会进行转换计算)
如: 外层消息和内层消息的偏移量
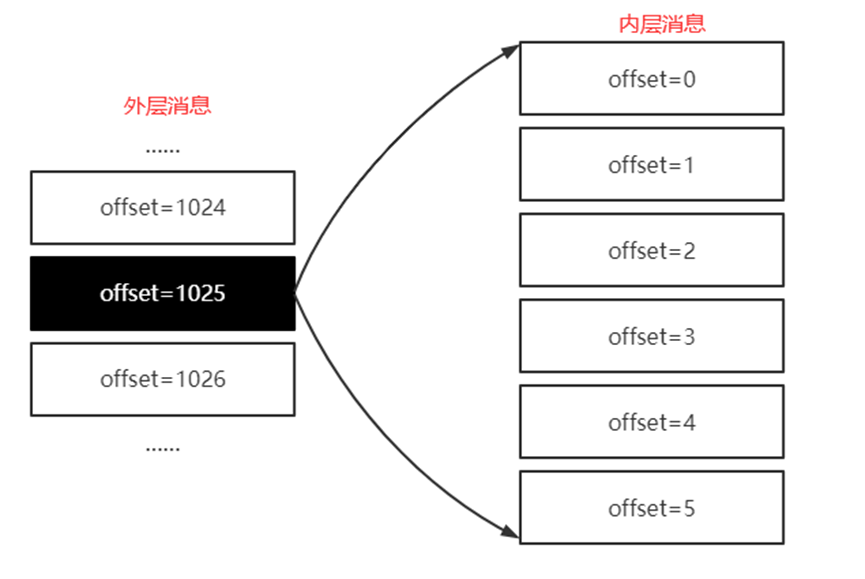
// 外层消息存储的是内层消息中最后条消息的绝对位移(相对于Partition而言)
日志清理
日志清理: Kafka对日志的维护
- 日志清理策略分为: 删除、压缩
- 日志清理的粒度最细可为Topic级别
- 可同时指定删除和压缩为日志清理的策略
删除
删除(Delete): 删除不符合特定条件的LogSegment
- 删除依据分为: 时间、文件大小、日志的起始偏移量
- Broker启动时会同时启动个线程周期性检测并删除特定LogSegment
- 删除线程会基于依据选择出可被删除的LogSegment(deletableSegment)
日志删除的大致流程:
- 从日志对象中所维护的LogSegment跳跃表中移除待删除的LogSegment
- 将所有待删除的文件添加
.deleted后缀(包括索引文件) - 统一交由延迟删除线程处理(默认1m)
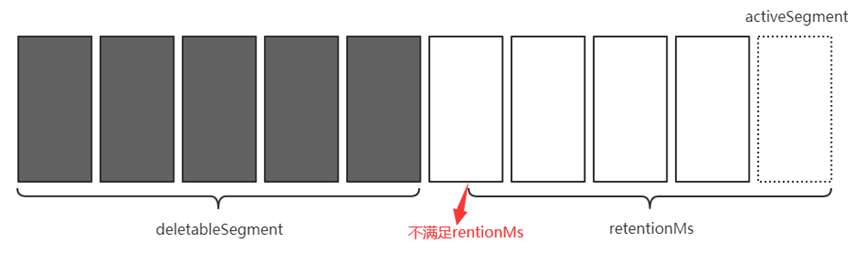
基于时间删除: 每个LogSegment拥有过期时间
- 根据LogSegment的最大时间戳(最后条消息)
- 若最后条消息的时间戳字段小于0, 则根据最近修改时间
- 若所有LogSegment均满足删除条件, 则在删除前创建activeSegment
如: 基于时间的日志删除(只要最大时间戳未过期就不会被删除)
基于文件大小: 每个LogSegment的限定大小
- 基于文件大小又可分为:日志大小、LogSegment大小
- 若基于日志大小, 则超出限定时默认从头开始删除LogSegment
如:基于大小的日志删除

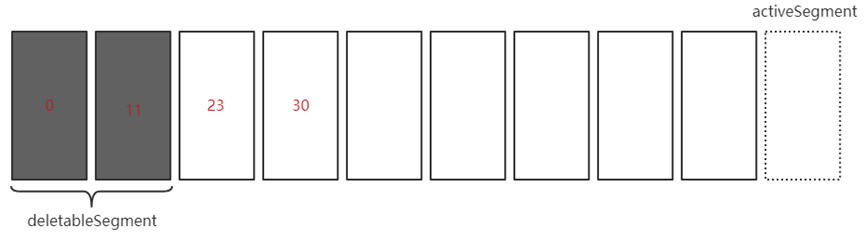
基于日志的起始偏移量: 下个LogSegment的BaseOffset是否小/等于起始偏移量
- 删除线程会逐个遍历LogSegment以判断BaseOffset是否满足
- 日志起始偏移量常为首个LogSegment的BaseOffset
如: 基于日志的起始偏移量(假设起始偏移量为25)
压缩
压缩(Compact): 将具有相同Key的消息仅保留最后个版本的Value
- 压缩后生成新的LogSegment, 消息的物理位置不会改变
- 压缩后的偏移量不再连续(不影响日志的检索)
- 压缩前后的消息可分为: clean和dirty
- activeLogSegment不参与压缩
如:日志压缩时其构成部分

// 日志的
cleaner-offset-checkpoint
文件记录每个Partition的已清理偏移量
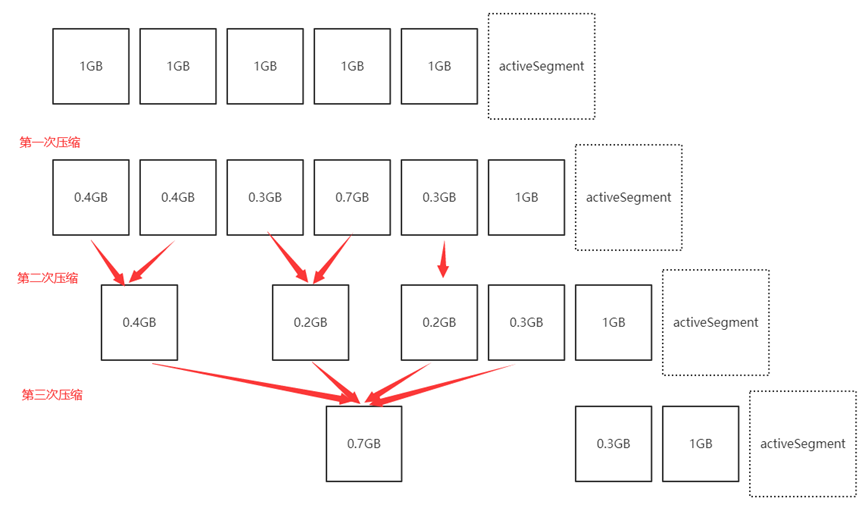
日志压缩时大致流程:
- 日志的污浊率触发压缩操作
- 压缩线程遍历两次日志(获取Key和判断)
- 对于压缩LogSegment的进行分组(防止过多小文件)
- 将LogSegment组中需保留消息存储于
.clean后缀的临时文件 - 对日志进行压缩, 在压缩完成后将
.clean临时文件后缀改为.swap - 删除被压缩的LogSegment, 并将
.swap后缀去除(变为可用LogSegment)
// LogSegment组的大小不可超过LogSegment的限定大小
如: 多次压缩的日志文件
// ActiveSegment(活跃的日志分段): 可执行写入操作的LogSegment
版权归原作者 爱喝可乐的w 所有, 如有侵权,请联系我们删除。