

Hadoop快速入门——入门考试(伪分布式60+编码25+执行jar15)
一、伪分布式搭建(60分)
1、创建1台Linux虚拟机,并打开对应的网络连接(VMnet8)(5分)
需要创建并启动成功图片,以及打开网络图片。
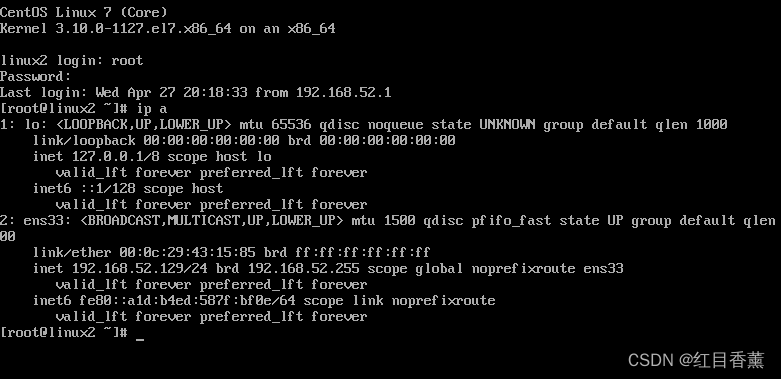

2、通过xshell正确连接Linux虚拟机(5分)
链接成功截图,即可得分。

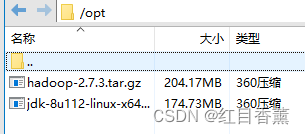
3、在【/opt/】文件夹下上传【java】以及【hadoop】压缩包(5分)
文件位置:C:\java\jar
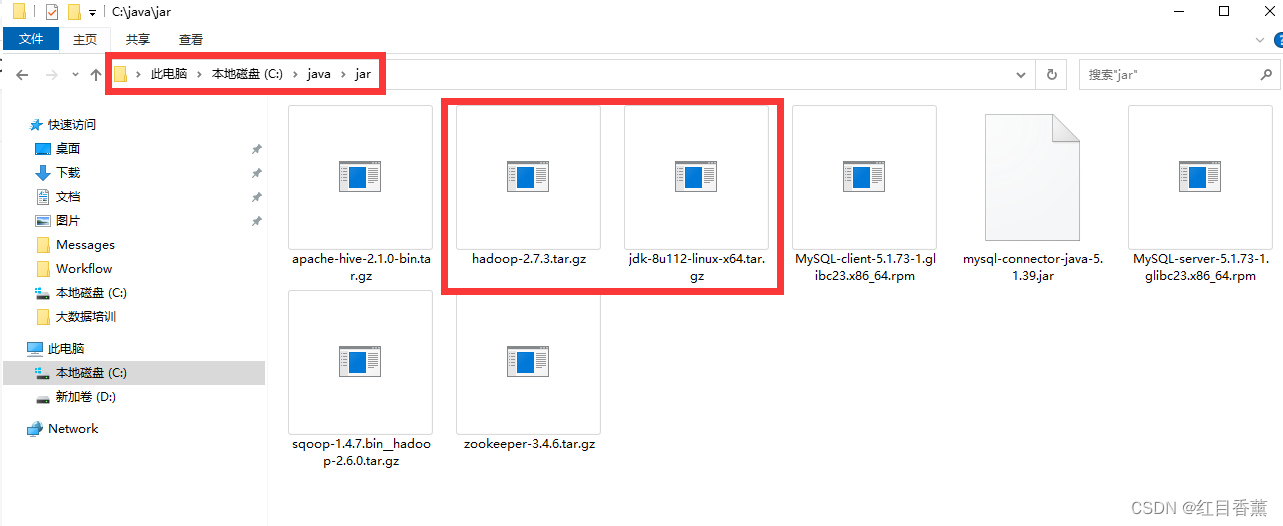
通过【xftp】上传到【/opt/】下
4、正确解压【java】以及【hadoop】的压缩文件(5分)
tar -zxvf jdk-8u112-linux-x64.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz
通过【ll】命令查询效果

5、修改【hadoop-2.7.3】以及【jdk1.8.0_112】文件夹名称为【hadoop】以及【jdk】(5分)
mv jdk1.8.0_112 jdk
mv hadoop-2.7.3 hadoop

6、在【/etc/profile.d/】编写【hadoop-eco.sh】脚本文件(5分)
vi /etc/profile.d/hadoop-eco.sh
JAVA_HOME=/opt/jdk
PATH=$JAVA_HOME/bin:$PATH
HADOOP_HOME=/opt/hadoop
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
通过【cat】 查询编辑结果:

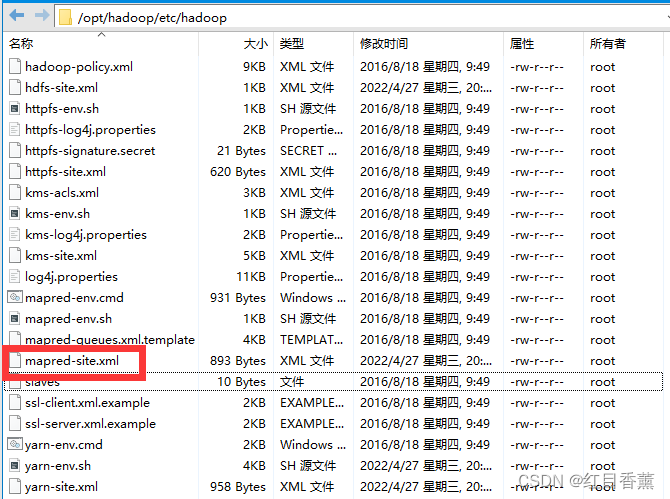
7、在正确的位置替换提供的【Hadoop】伪分布式的6个文件。(5分)

8、创建ssh免密登录(5分)
生成rsa的image
ssh-keygen -t rsa

拷贝到本地
ssh-copy-id -i root@localhost
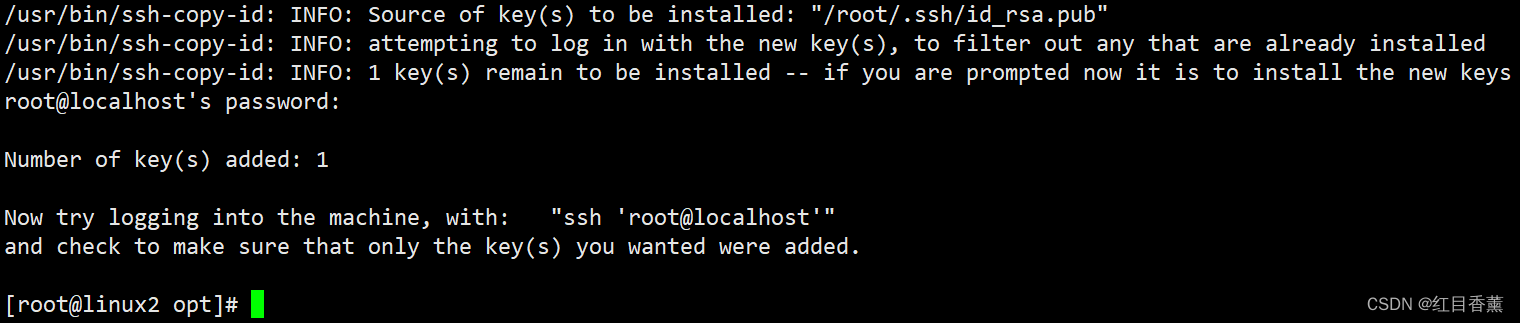
登录测试
ssh root@localhost

退出测试
exit

9、创建生成存储文件夹(5分)
创建【/opt/hadoop-record/】文件夹,并在【/opt/hadoop-record/】文件夹下创建【name】【secondary】【data】【tmp】四个文件夹。
mkdir -p /opt/hadoop-record/name
mkdir -p /opt/hadoop-record/secondary
mkdir -p /opt/hadoop-record/data
mkdir -p /opt/hadoop-record/tmp
ls /opt/hadoop-record/

10、执行【hadoop-eco.sh】脚本文件(5分)
source /etc/profile.d/hadoop-eco.sh
java -version
通过查看【java】版本以及【Hadoop】版本确认配置成功。

11、初始化并启动hdfs(5分)
hdfs namenode -format
start-all.sh
jps
初始化成功图片
启动并查询6个服务截图

12、关闭防火墙,并通过浏览器正确访问【ip:50070】
systemctl stop firewalld

二、编辑demo测试jar包(25分)
13、创建【idea】项目(5分)
选择【maven】项目,点击【next】
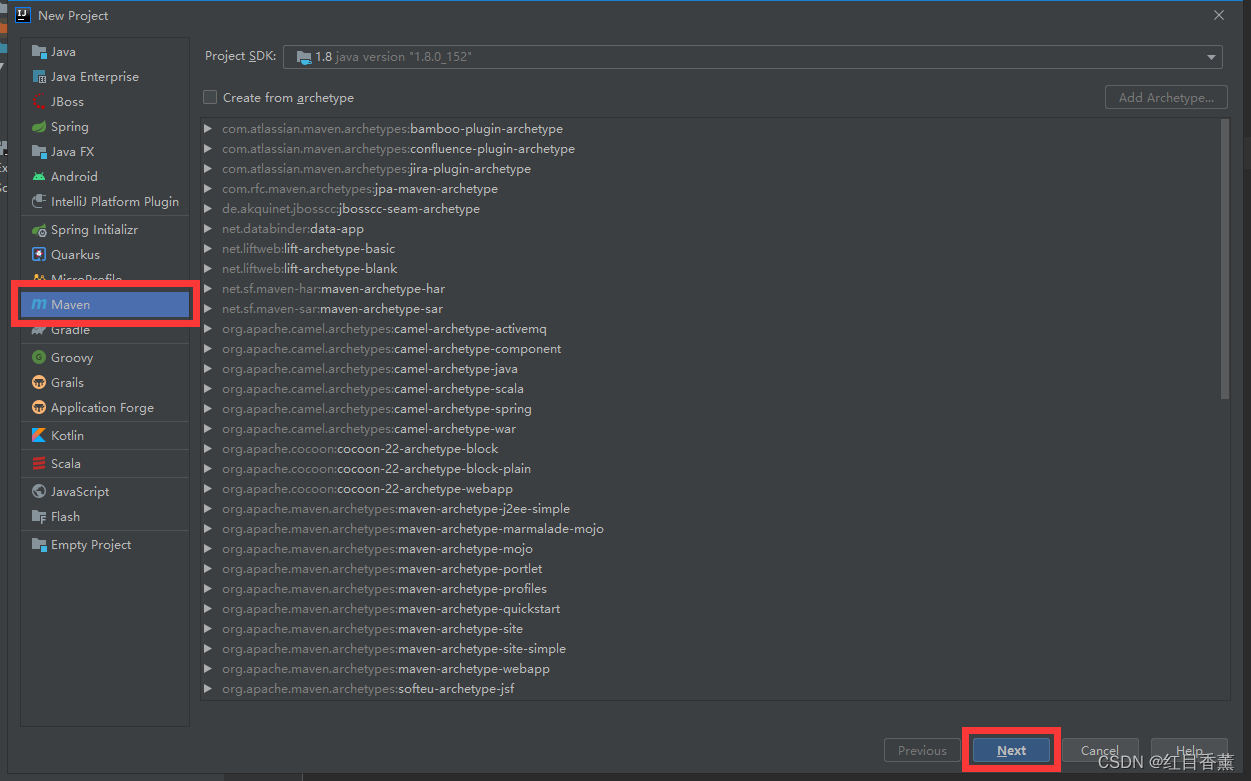
添加项目名称后,点击【finish】
14、修改maven配置路径以及maven库地址,并引入【hadoop】(5分)
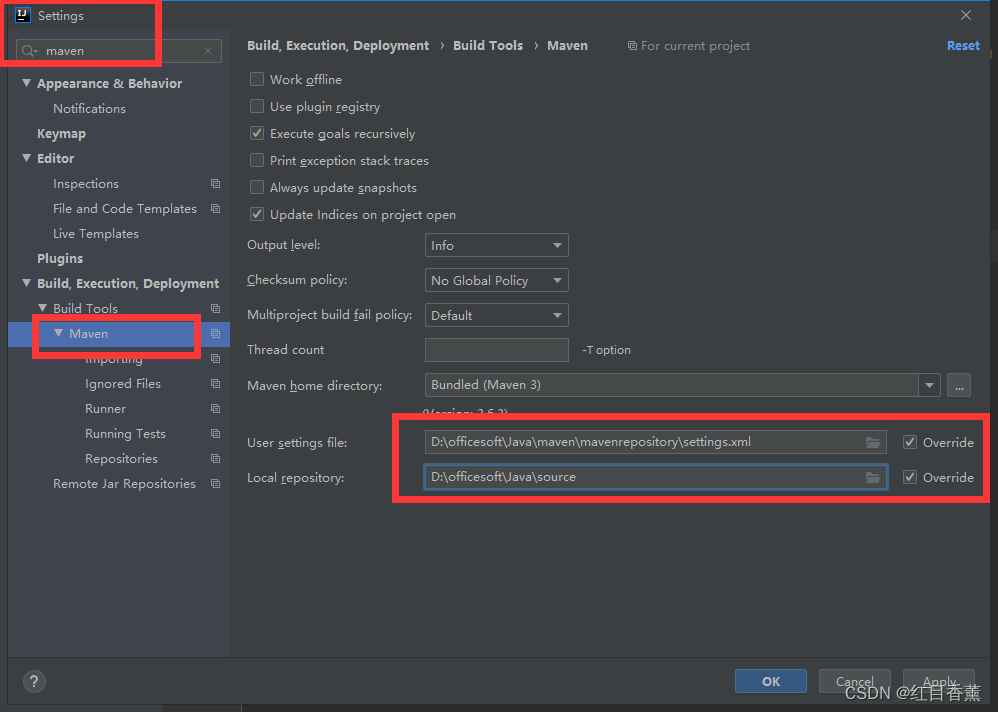
添加【hadoop-client】的【2.7.3】版本
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>

15、在【src的java】下创建【com.item.test】包,以及【MapAction】【ReduceAction】【Action】的类文件(5分)
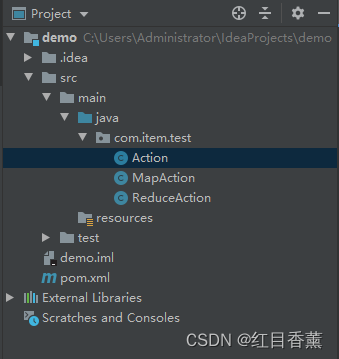
16、完成【MapAction】【ReduceAction】【Action】文件编码(5分)
【MapAction】
package com.item.test;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MapAction extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
char[] split = value.toString().toCharArray();
for (char s : split) {
context.write(new Text(s+""), new LongWritable(1));
}
}
}
【ReduceAction】
package com.item.test;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReduceAction extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
【Action】
package com.item.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Action {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Action.class);
job.setMapperClass(MapAction.class);
job.setReducerClass(ReduceAction.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path("/info/info.txt"));
FileOutputFormat.setOutputPath(job,new Path("/infos"));
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
17、导出jar包(5分)
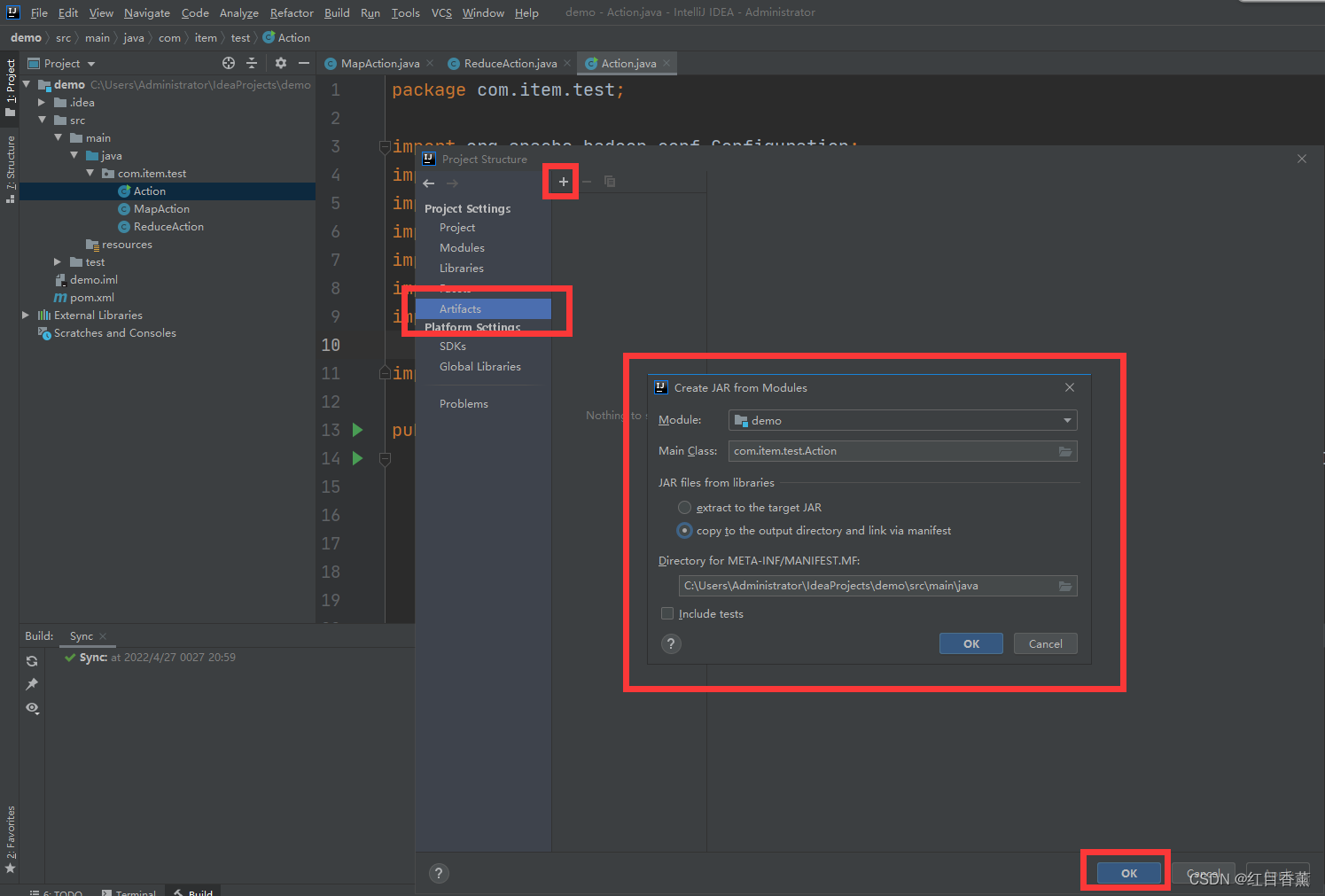
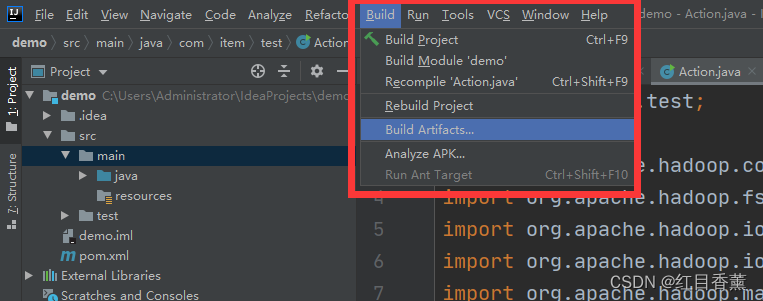
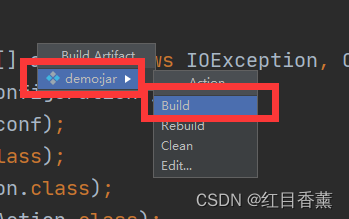

将【demo.jar】包复制出来,准备上传到服务器。
三、执行jar(15分)
18、进入到【/opt/hadoop/share/hadoop/mapreduce】文件夹下并引入【demo.jar】包(5分)
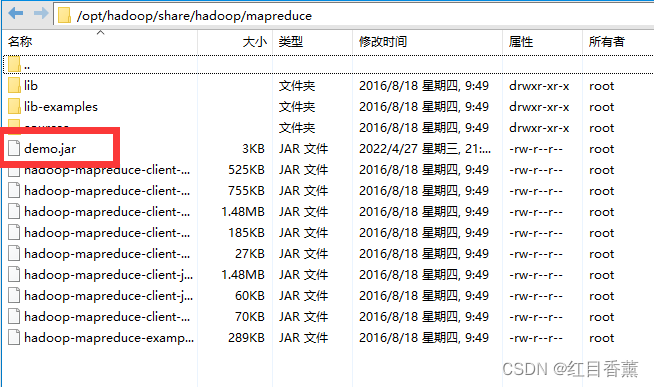
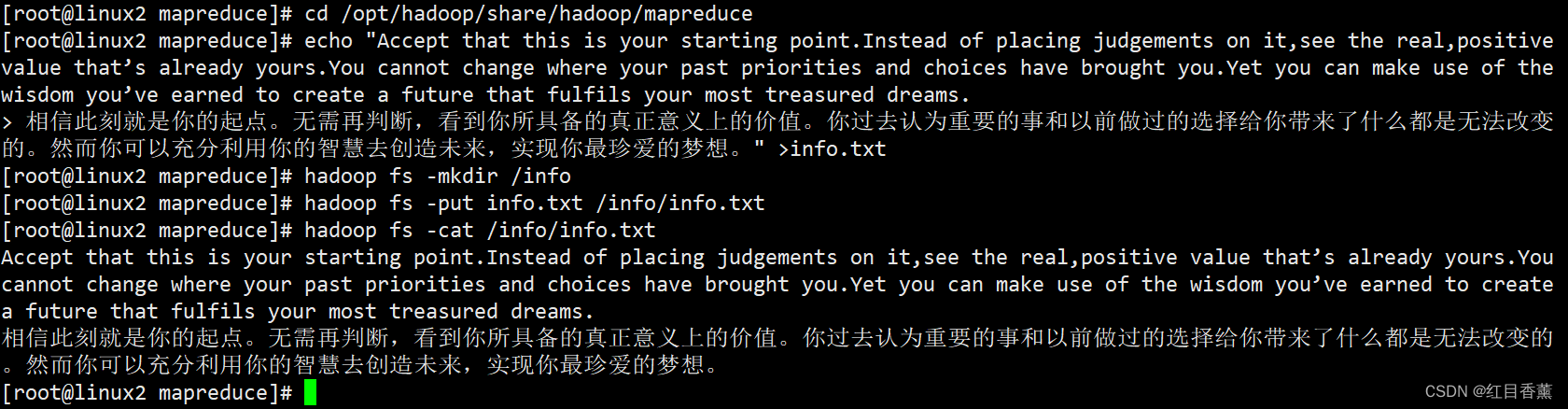
19、在服务器下创建【/info】文件夹,并添加测试文件【info.txt】(5分)
cd /opt/hadoop/share/hadoop/mapreduce
echo "Accept that this is your starting point.Instead of placing judgements on it,see the real,positive value that’s already yours.You cannot change where your past priorities and choices have brought you.Yet you can make use of the wisdom you’ve earned to create a future that fulfils your most treasured dreams.
> 相信此刻就是你的起点。无需再判断,看到你所具备的真正意义上的价值。你过去认为重要的事和以前做过的选择给你带来了什么都是无法改变 的。然而你可以充分利用你的智慧去创造未来,实现你最珍爱的梦想。" >info.txt
hadoop fs -mkdir /info
hadoop fs -put info.txt /info/info.txt
hadoop fs -cat /info/info.txt
20、执行并查看结果(5分)
hadoop jar demo.jar com/item/test/Action /info/info.txt /infos
hadoop fs -cat /infos/part-r-00000

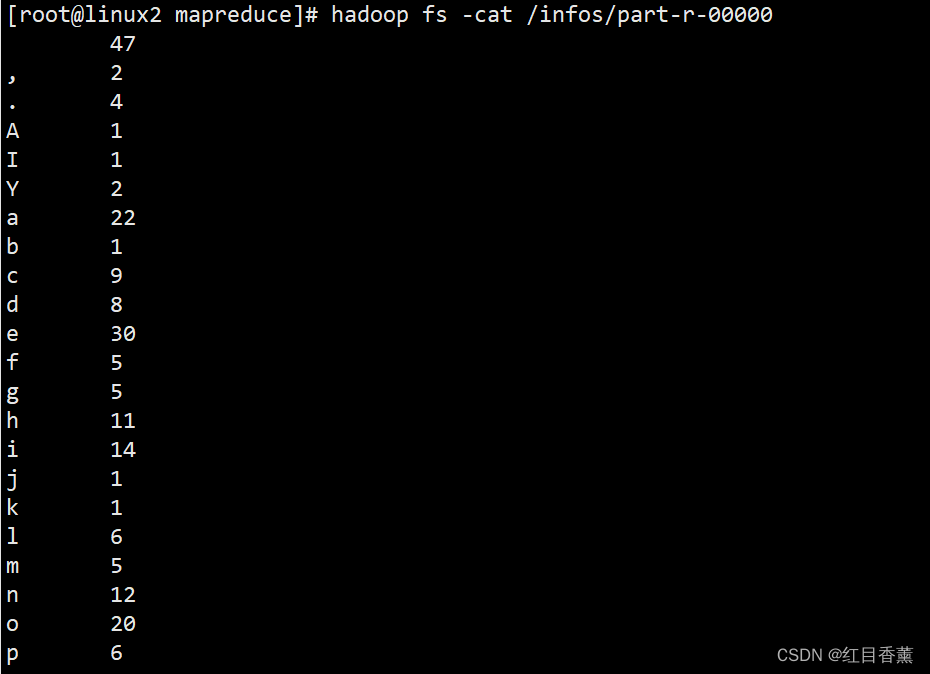
满分。
本文转载自: https://blog.csdn.net/feng8403000/article/details/124459413
版权归原作者 红目香薰 所有, 如有侵权,请联系我们删除。
版权归原作者 红目香薰 所有, 如有侵权,请联系我们删除。