
记 - flink sql upset-kafka sink 数据乱序排查与解决思路
数据乱序现状[left join]
前提
- flink 任务使用多并发跑
情况1:
- 以from表的主键作为sink表的主键
- 多表left join关联,更新、插入、删除left jion表的数据
数据乱序原理同情况2,下面仅以情况2来进行分析与解决
情况2:
- sink 表的联合主键组成:from 表的主键 + left join 表的关联字段拼接组成主键
- 多表left join关联,更新、插入、删除left jion表的数据
以上两种情况导致的现状
- 当业务系统更新、插入、删除任意字段和任意时间的数据时,下游数据可能会出现乱序【下游sink:pg和kafka】
数据乱序原因分析与解决
乱序sql如下
sink 主键描述:from 表的主键 + left join 表的join关联条件字段
insertinto sink_table
selectcasewhen event.pk_id isnotnullthen cast(event.pk_id asvarchar)else'-'end||casewhen B.id isnotnullthen cast(B.id asvarchar)else'-'end||casewhen B.dt_str isnotnullthen cast(B.dt_str asvarchar)else'-'endas pk_id,... 省略
event.extra_info
from event
leftjoin B on event.rect_id = B.id and B.dt_str = event.event_date
;
sql执行计划图

业务操作
当flink任务处于多并发跑时
- 若修改 B 表非关联字段数据
- 修改主表【event】的event_date的日期【基本都乱序】
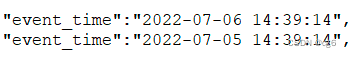
kafka乱序数据
sink to kafka 的数据如下图: 备注:若把数据写入数据库,pk_id - value【非null】 是基于pk_id进行数据更新 ; pk_id - null 是对pk_id 进行删除操作
备注:若把数据写入数据库,pk_id - value【非null】 是基于pk_id进行数据更新 ; pk_id - null 是对pk_id 进行删除操作
数据乱序结论:由图可知,数据分发在同一个kafka分区,消费kafka数据sink to pg 表,对应pk_id 的数据被删除;但此条数据是正常数据,因只做更新操作,不是删除操作,故数据已乱序而会导致pg数据漏数。
原因分析

- 由以上sql执行计划图看到,多表join时,不同表进行数据分发是根据表的join条件hash后分发计算
- 若修改主表【from 主表】的event_date, 由于sink的主键【pk_id】没有变化【无论的回撤还是修改的pk_id 都没有变化】,但event_date的日期发生改变 ,且event_date是join的条件之一,可能会使得hash分发发生改变,由于计算分区可能发生改变,处理线程也可能会不一样,导致不同线程存在处理数据顺序不一致而导致写入乱序。
解决
修改sink主键 = 主表主键 + 主表的join 条件
超过两个表的join时,主表主键是在逐步变化的,每join一次,表主键都会多一个主表字段;DAG图如下: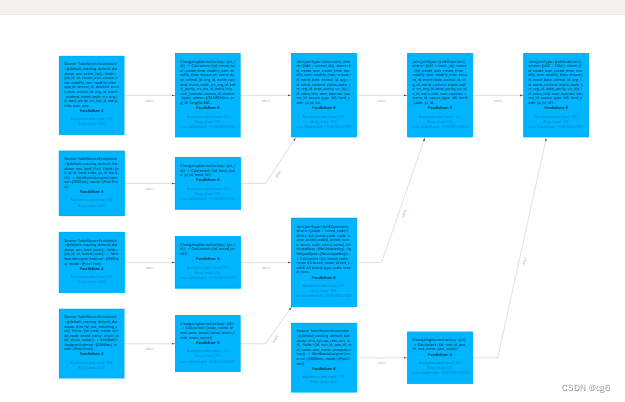
解决分析
由以上sql执行计划图可知,left join 是以join条件分发计算,且以主表数据sink到下游
- 若修改主表非join条件字段数据,pk_id 不变,数据分发不变,处理线程不变,数据写入顺序一致,不会导致数据乱序
- 若修改主表join条件字段数据,回撤与更新记录的分发可能发生改变,回撤记录的pk_id 不变,更新数据的pk_id【pk_id0】发生改变且与上一条记录的pk_id不同,回撤数据会删除pk_id的记录,而pk_id0的记录则 insert 到pg,则pg表数据不会乱序。
- 若修改left join 右边表的非join条件字段数据,因为sink的pk_id不变和右边表的数据分发不变,数据不会乱序
- 若修改left join 右边表的join条件字段数据,因为sink的pk_id不变,但右边表的数据分发发生改变,主表可能关联不上数据或数据出现更新,若主表关联不上右表数据,则主表会先回撤,再产生一条更新右表字段数据为null 记录或替换为新值的记录
验证
修改后的sql[替换sink主键] :
insertinto sink_table
selectcasewhen event.pk_id isnotnullthen cast(event.pk_id asvarchar)else'-'end||casewhen event.rect_id isnotnullthen cast(event.rect_id asvarchar)else'-'end||casewhen event.event_date isnotnullthen event.event_date asvarchar)else'-'endas pk_id,... 省略
event.extra_info
from event
leftjoin Bon event.rect_id = B.id and B.dt_str = event.event_date
;
重跑任务,修改event_date,消费kafka数据显示如下: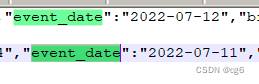

补充
多表right join 分析
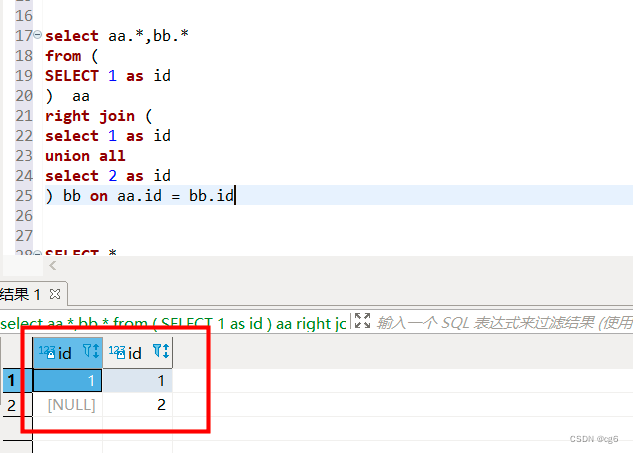
若多表right join , from aa表就不是主表了,而是right join bb表才是主表
多表join分析
inner join 多表,只需要使用单个表的主键作为sink表的主键即可,因为要么全部关联上, 要么全部关联不上,不会存在部分被关联上,部分被关联不上的问题
打印flink sql 执行计划
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();EnvironmentSettings settings =EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env, settings);
tableEnv.executeSql("EXPLAIN PLAN FOR **要打印执行计划的sql语句**").print();
数据乱序原因排查步骤
- 实时pg表数据与业务表数据对比【对数】,检查实时表没有但业务表正常存在的业务数据
- 消费实时数仓链路kafka topic 业务数据【实时数仓遗漏的】,验证是否是实时数仓计算导致的漏数
- 消费到漏数的数据,发现主键对应的业务数据,回撤数据在后面
- 分析实时flink sql 逻辑 , 打印sql执行计划,分析flink sql 执行计划
kafka上游数据比下游数据多【与数据乱序无关】
1、问题:Flink 任务分层,若修改数据,为什么kafka上游数据比下游多两条
原因分析:[flink 的 upset-Kafka 一致性保证]source 读入时,可以确保具有相同主键值下仅最后一条消息会生效,实现幂等写入。
上游kafka数据
下游kafka数据
flink 官网说明:https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/connectors/table/upsert-kafka/
2、问题:为什么修改维度表名称,下游会产生4条记录【两条null , 两条insert/update】
前提:维度表与事实表在修改数据前可以关联上,且sink的事实表的主键包含维度表字段
原因分析:
- 当修改维度表时,维度表会产生一条回撤数据【value :null】和一条update数据【value 非null 】
- 当事实表left join 维度表时,若维度表value为null , 则sink的事实表主键与历史主键不一致,会产生一条新主键的insert记录,同时会对上一个主键数据先发送value 为 null ,把历史数据回撤,保证数据一致性
- 当事实表left join 维度表时,若维度表value为update数据【value 非null 】, 则sink的事实表主键与历史主键不一致,会产生一条新主键的insert记录,同时会对上一个主键数据先发送value 为 null ,把历史数据回撤,保证数据一致性
综上所属,下游一共产生4条记录
版权归原作者 cg6 所有, 如有侵权,请联系我们删除。