
项目场景:
学习Hadoop时遇到的一个小问题。
问题描述
在集群两台节点都执行启动hadoop命令后,输入命令jps观察进程状态时,仅有jps,Hadoop启动失败,web端页面无法访问。
原因分析:
启动集群时出错,可能原因有以下几个:
1、hadoop的五个配置文件:core-site.xml yarn-site.xml hdfs-site.xml mapred-site.xml和workers文件配置错误。
2、IP主机映射未进行配置,导致web端无法访问。
3、集群进程ID错误,导致格式化时ID冲突,反复格式化。
解决方案:
1、修改hadoop的各个配置文件,具体配置如下:
①core-site.xml
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
②hdfs-site.xml
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
③yarn-site.xml
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
④mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
⑤workers:你自己各节点的主机名称
master
slave1
slave2
注意:在以上配置文件中,master,slave1,slave2都要替换成自己的主机名称,避免出错。
2、 配置IP映射
输入以下命令,按i进入编辑模式,将ip与主机名对应,设置完毕后“:wq”保存退出。
vi /etc/hosts
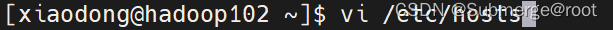

3、如果均不存在上述过程的错误,那么就需要考虑进程ID的错误了,我们可以在hadoop的日志中查看是否存启动报错。
输入命令:cd /opt/module/hadoop-3.2.1/logs/
cat查看日志信息
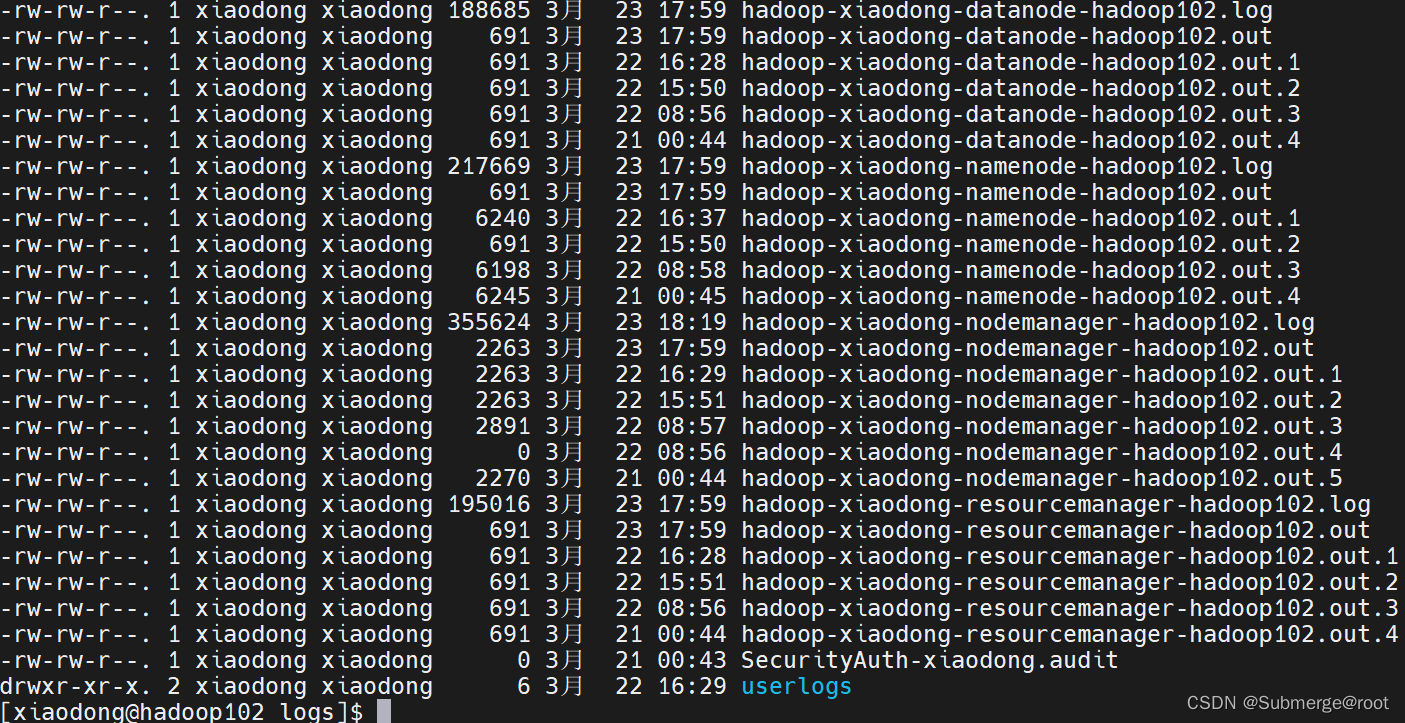
选择出问题的进程查看,例如查看hadoop-xiaodong-datanode-hadoop102.log

这里发现进程ID冲突了。
具体解决方法是:在每台节点上分别执行以下两条命令,删除data和log文件夹,删除tmp文件夹。
rm -rf data/ logs/
sudo rm -rf /tmp/*
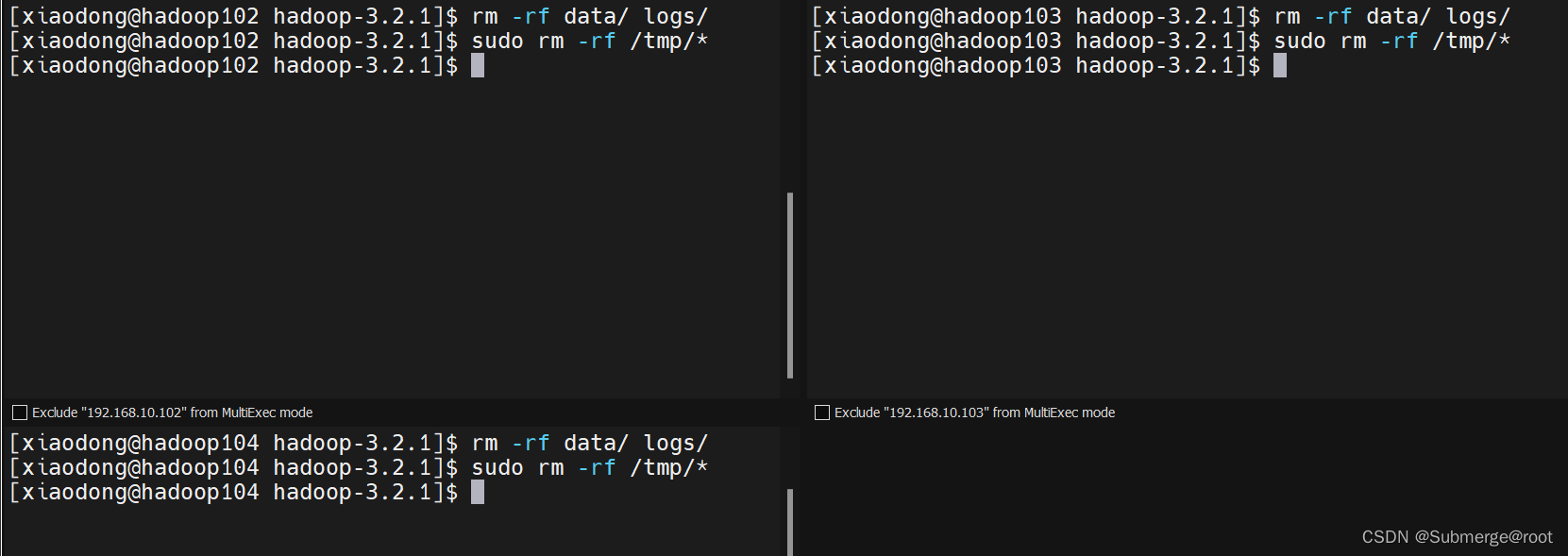
删除成功之后,重新进行hadoop集群格式化
hdfs namenode -format

重新格式化完毕后,再次启动集群,主节点上执行start-all.sh,在第二台节点上执行start-yarn.sh
start-all.sh

集群启动正常!!!问题解决!
访问web页面:

大数据学习萌新,如遇到问题,欢迎指正!
求关注呐!
版权归原作者 Submerge@root 所有, 如有侵权,请联系我们删除。