
Stages
stage页签展示了所有job下的所有的stage,如果是在执行中的作业,只展示已经启动的stage
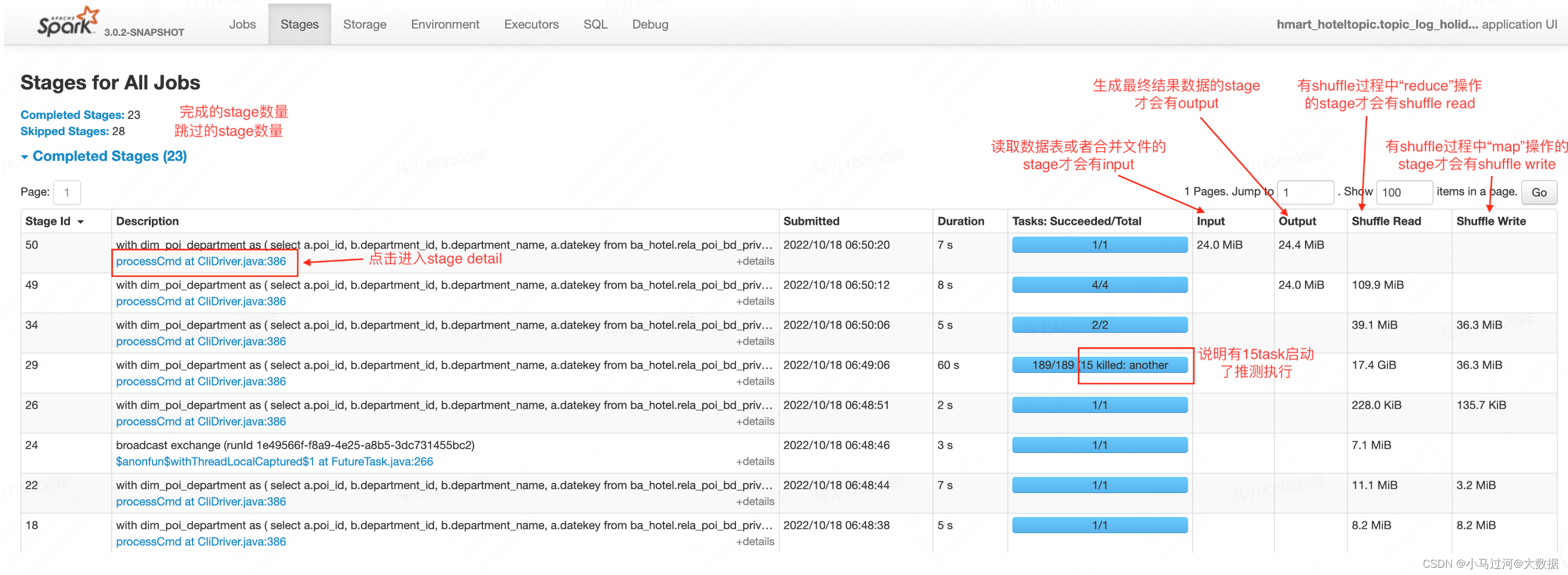
- Input****:指真正读取的文件大小,如果表是分区表,则代表读取的分区文件大小。如果数据表有10个字段,只select了3个字段并发生了列裁剪,则Input表明是3个字段的存储大小。
- Output****:输出到hdfs上的文件大小,如果结果数据是压缩的,则代表压缩后的大小。
- Shuffle Read****:shuffle阶段读取的数据大小,既包含executor本地的数据,也包含从远程executor读取的数据。
- Shuffle Write****:为了shuffle所准备的数据,未来会有其他的stage来读取,该部分数据会写到磁盘上。
有关stage列表页的自问自答
1.stage是如何划分的?
标准的回答是按照宽依赖划分stage
从实践中我总结的stage划分的原则是:有shuffle操作,且shuffle的key不相同(类型不相同也算)则新开stage,否则合并到前一个stage中
2.如何识别出stage的依赖关系
一般来说按照submitted进行排序,时间相同stage代表是并行执行的,相互之间没有依赖关系。时间相近且前一个stage的提交时间+执行时间>后一个stage的提交时间,两者也是没有依赖关系。
有依赖关系的stage往往有这样的特征:1.前一个stage的提交时间+执行时间=(或小于)后一个stage的提交时间,2.前一个stage的shuffle write数据量等于后一个stage的shuffle read数据量,或者后一个stage的read数据量=前两个stage的write数据量之和。
除了在列表页的推测判断外,还可以在sql页面看整个作业的DAG图

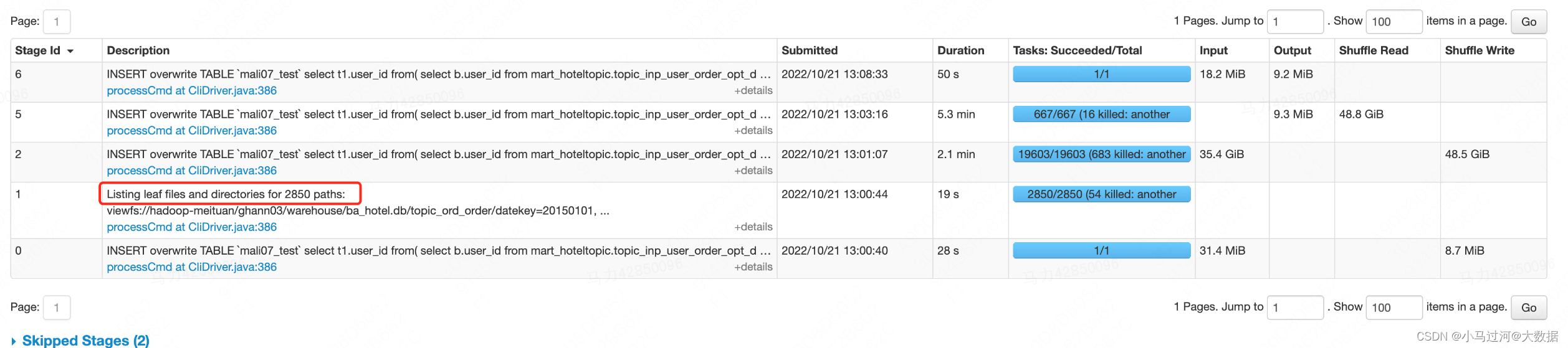
3.有的stage名叫Listing leaf files and directories for xxx paths是什么意思
spark 作业在启动前会从文件系统中查询数据的元数据并将其缓存到内存中,元数据包括一个 partition 的列表和文件的一些统计信息(路径,文件大小,是否为目录,备份数,块大小,定义时间,访问时间,数据块位置信息)。一旦数据缓存后,在后续的查询中,表的 partition 就可以在内存中进行下推,得以快速的查询。将元数据缓存在内存中虽然提供了很好的性能,但在 spark 加载所有表分区的元数据之前,会阻塞查询。对于大型分区表,递归的扫描文件系统以发现初始查询文件的元数据可能会花费数分钟。
后来,spark在读取数据时会先判断分区的数量,如果分区数量小于等于spark.sql.sources.parallelPartitionDiscovery.threshold (默认32),则使用 driver 循环读取文件元数据,如果分区数量大于该值,则会启动一个 spark job,并发的处理元数据信息(每个分区下的文件使用一个task进行处理)。分区数量很多意味着 Listing leaf files task 的任务会很多,分区里的文件数量多意味着每个 task 的负载高。
4.有些任务spark.sql.shuffle.partitions设置为2000,为什么有的stage的task数量是4000?
比如下面的任务设置spark.sql.shuffle.partitions=2000;但是却有一个stage做了shuffle操作,有4000个task
推测的原因是这个stage对应的是以下面的代码,上下两个shuffle的key相同又有一次union all,所以可以放在一个stage中,虽然task数量是4000,但是上面的shuffle数据是分在2000个task中,下面的是另一个2000task中,并不会两者合在一起hash到4000个task中。


5.有的stage会显示xxtask failed,代表什么意思呢,为什么task失败stage不会失败呢?
如上图,某些stage除了会显示总的task数,执行成功task数和killed task数,还会显示failed task数。failed task数量就代表该stage中执行失败的task数量。
为什么task失败而stage不会失败,是因为spark有一系列的重试机制来为分布式下大量任务的容错。
1)application层面的容错:spark.yarn.maxAppAttempts
代表一个app会最多执行几次,如果设置的是3就代表失败后会重试2次,公司当前设置的是1,即不会重试。(注意:spark框架下一个app不会多次重试,但是cantor会有两次重试机会)
2)stage层面的容错:spark.stage.maxConsecutiveAttempts
代表一个stage连续执行失败几次会被中止,社区版默认设置为4,公司的没有显式的指定
3)task层面的容错:spark.task.maxFailures
代表一个task连续执行失败几次会被中止,社区版默认设置为4,公司的没有显式的指定,印象中也是4。
4)某些动作层面的容错
比如spark.shuffle.io.maxRetries、spark.rpc.numRetries用来容错shuffle时的io异常和rpc通信的异常,类似的参数非常多,不一一列举,可以通过在spark参数中搜索attempt、failures、retries等看到

Stage detail
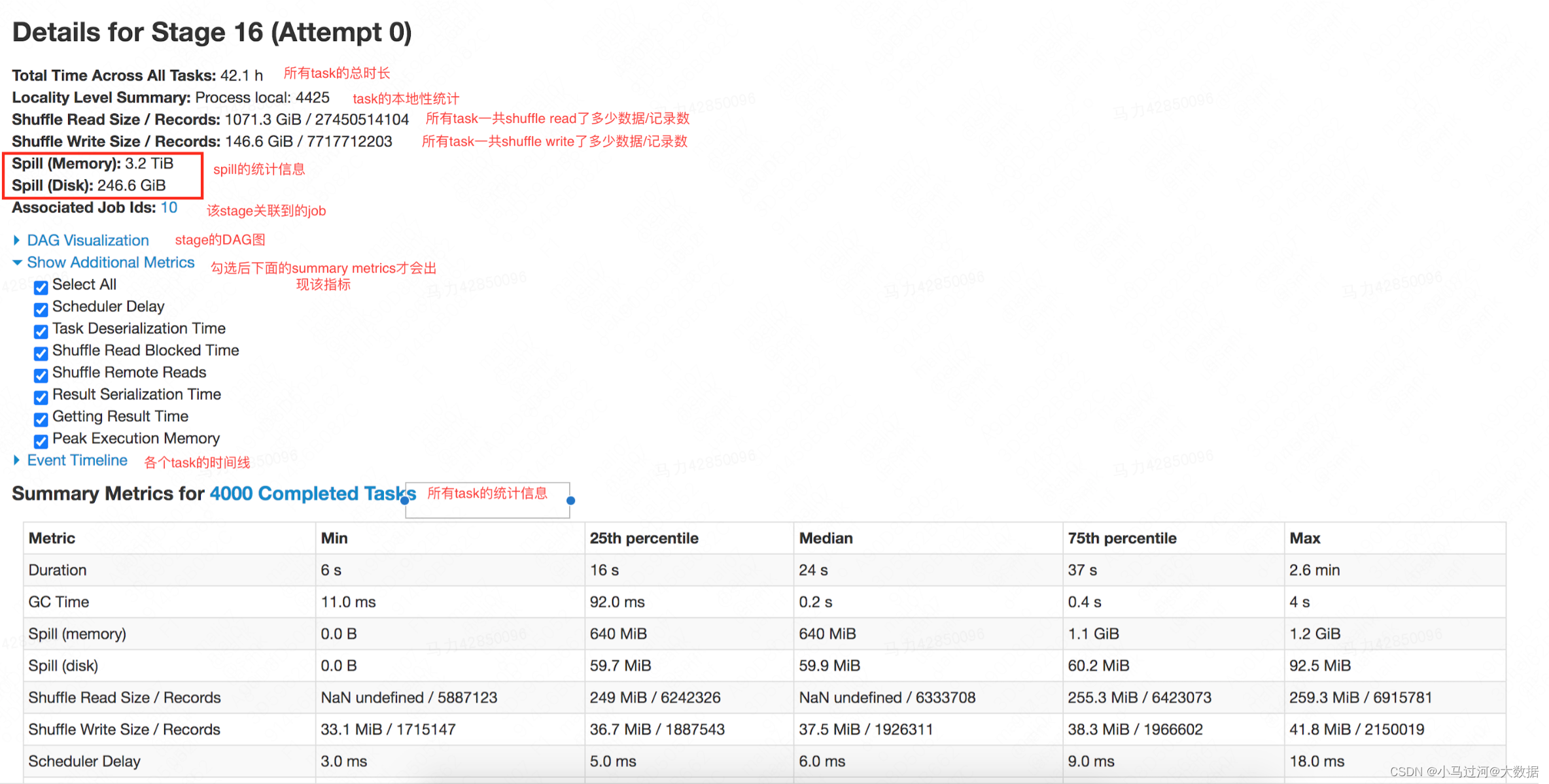
stage detail下展示了单个stage的信息,是排查有问题的stage时最重要的页面
Locality level
描述spark task的本地性级别。简单说计算越靠近数据本身,速度越快,所以通常情况下,会把代码发送到数据所在节点,而不是把数据拉取到代码所在节点。本地性有5个级别,分别是PROCESS_LOCAL(在相同进程中)、NODE_LOCAL(在相同节点)、NO_PREF(没有位置偏好,从哪里访问都一样快)、RACK_LOCAL(在相同的机架上)、ANY(在其他网络节点上),数据和计算的距离是越来越远,速度也越来越慢。对于数仓的同学而言,不用太关注这个统计,只需要了解其大致原理即可。
Locality level在spark官网上的描述
Data locality can have a major impact on the performance of Spark jobs. If data and the code that operates on it are together then computation tends to be fast. But if code and data are separated, one must move to the other. Typically it is faster to ship serialized code from place to place than a chunk of data because code size is much smaller than data. Spark builds its scheduling around this general principle of data locality.
Data locality is how close data is to the code processing it. There are several levels of locality based on the data’s current location. In order from closest to farthest:
- PROCESS_LOCAL data is in the same JVM as the running code. This is the best locality possible
- NODE_LOCAL data is on the same node. Examples might be in HDFS on the same node, or in another executor on the same node. This is a little slower than PROCESS_LOCAL because the data has to travel between processes
- NO_PREF data is accessed equally quickly from anywhere and has no locality preference
- RACK_LOCAL data is on the same rack of servers. Data is on a different server on the same rack so needs to be sent over the network, typically through a single switch
- ANY data is elsewhere on the network and not in the same rack
Spark prefers to schedule all tasks at the best locality level, but this is not always possible. In situations where there is no unprocessed data on any idle executor, Spark switches to lower locality levels. There are two options: a) wait until a busy CPU frees up to start a task on data on the same server, or b) immediately start a new task in a farther away place that requires moving data there.
What Spark typically does is wait a bit in the hopes that a busy CPU frees up. Once that timeout expires, it starts moving the data from far away to the free CPU. The wait timeout for fallback between each level can be configured individually or all together in one parameter; see the spark.locality parameters on the configuration page for details. You should increase these settings if your tasks are long and see poor locality, but the default usually works well.
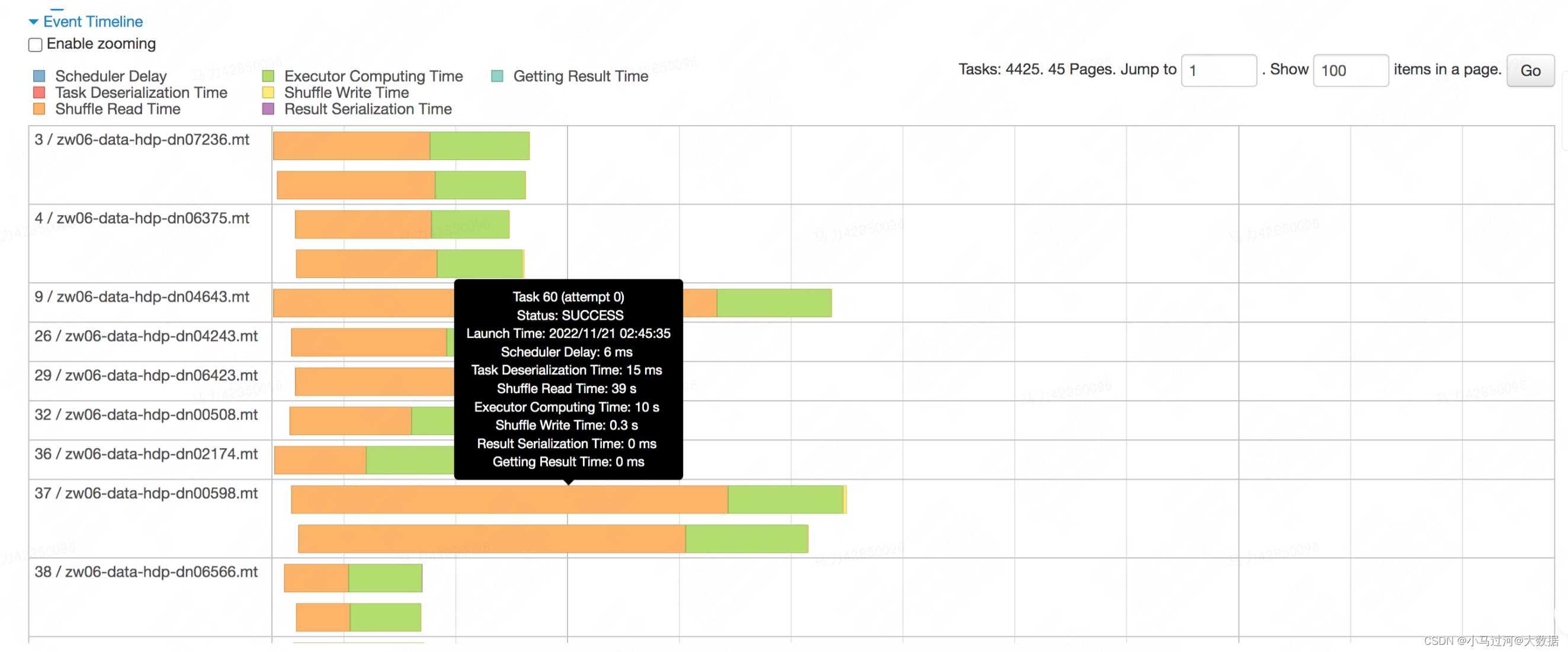
Event Timeline
task的时间线,以条形图+不同颜色的方式描述了各个task的不同动作下的耗时,鼠标浮动到某个条形图上,可以看到该task具体的各项时间。
spark官网对于界面上各个指标的简单介绍如下
- Getting result time is the time that the driver spends fetching task results from workers.(driver获取结果的时间,我们的ETL中几乎没有结果需要返回driver的情况,可以不关注)
- Scheduler delay is the time the task waits to be scheduled for execution.(调度延迟,sparkui上说如果调度延迟过长可以考虑减少task的大小或者结果的大小。具体原理不明)
- Executor Computing Time: 表示Task 执行时间,但不包含读取数据后的反序列化时间,和结果的序列化时间。
- Result serialization time is the time spent serializing the task result on a executor before sending it back to the driver.(结果序列化的时间)
- Task Deserialization Time****:Time spent deserializing the task closure on the executor, including the time to read the broadcasted task.(从远端或广播读取到的数据进行反序列化的时间)
- Shuffle Read Time :shuffle时从远端读取数据的时间
- Shuffle Write Time :shuffle前进行shuffle写的时间
鼠标浮动到“Show Additional Metrics”下的一些指标上,也可以看到相关信息,或更具体的说明。一个“健康”的task,时间应该绝大部分花在绿色的Executor Computing Time上。如果发现其他的时间占用过多,则需要考虑是否有性能问题。
**Summary Metrics **
此处是所有task的统计信息
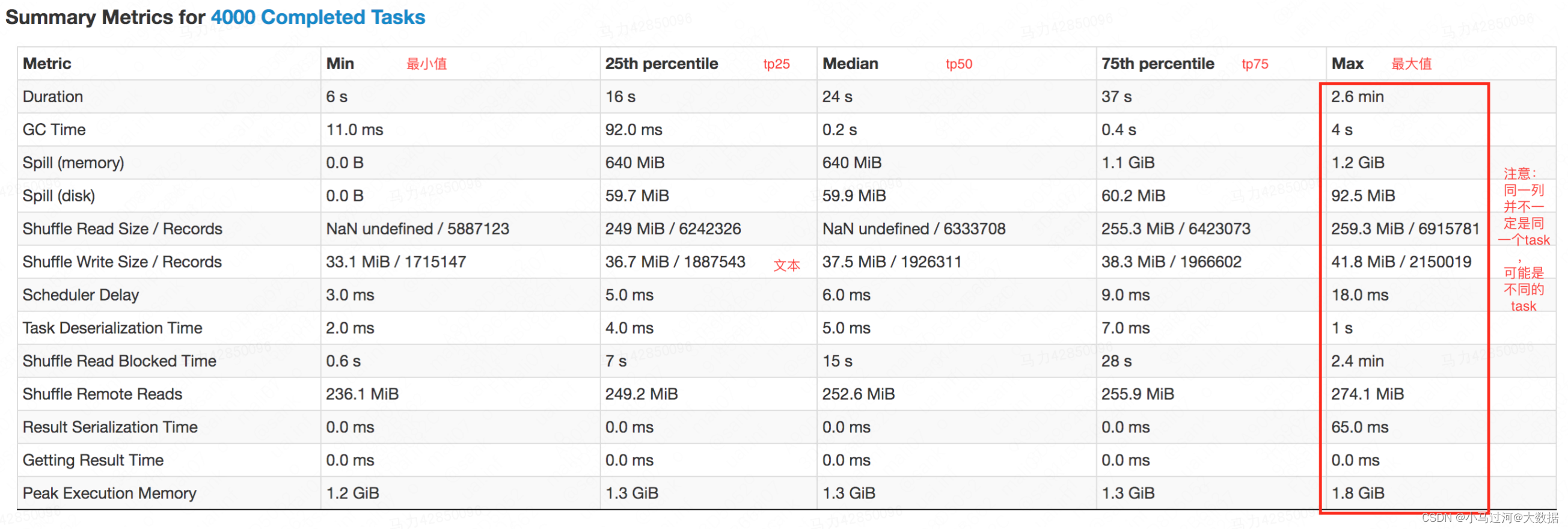
除了上面Timeline中出现的指标,其他指标的基本也是见名知意的,这里不再赘述。通常情况下排查数据倾斜或者某个task处理时间过长需要重点关注下面几个指标
- Duration****:task的执行时长,如果不同task之间的Duration差异过大,或者某个task的Duration过长,需要重点看看,可能是倾斜引起。
- Input Size / Records****:task的输入数据量,如果不同task之间的Input Size差异过大,考虑是否有输入的数据倾斜。
- Shuffle Read Size / Records****:task的shuffle read数据量,如果不同task之间的shuffle read差异过大,考虑是否有shuffle的输入数据倾斜
- Shuffle Write Size / Records****:task的shuffle write数据量,如果不同task之间的shuffle erite差异过大,考虑是否有shuffle的输出数据倾斜(数据膨胀)
- Shuffle Read Blocked Time****:task在读取数据是的阻塞时长,也是目前非rss任务经常出现的过长的问题,该时间过长可以考虑迁移到rss上
- **Spill (memory)/(disk)**:task 溢出的数量,memory指的是溢出前没有序列化的大小,disk指的是序列化为字节码的大小,也是占用磁盘的空间大小。最好是控制task不要产生溢出,大量溢出会消耗大量的时间
- GC Time****:task运行时垃圾回收的时间,越短越好,如果过大,考虑是不是task中处理了大对象比如复合类型的字段或者超长的string字段。
Aggregated Metrics by Executor
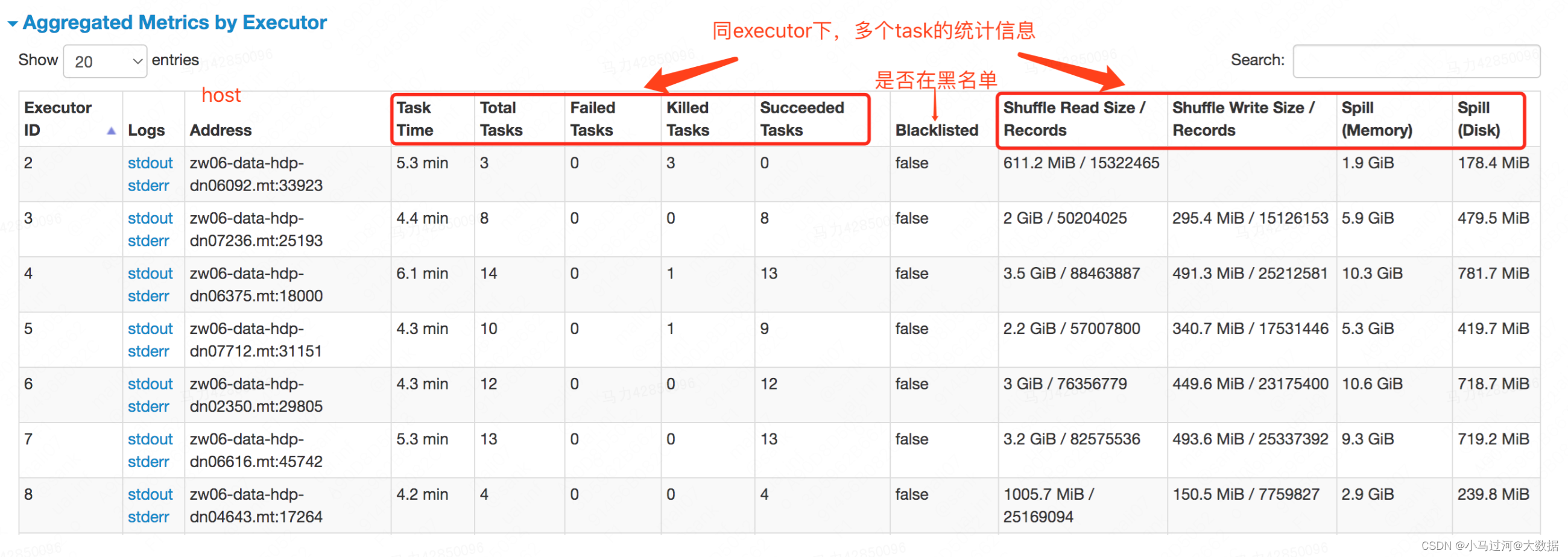
Tasks
每个task的明细信息,显示的指标受“Show Additional Metrics”中勾选的指标多少,在executor和task模块下都可以通过点击Logs来看executor的日志

有关stage detail的自问自答
1.为什么一般spill disk要小于spill memory
因为一个java的对象、字符串、集合类型在内存中为了更快的访问,都存储了超量的信息。比如一个对象需要存储,对象头存储信息,和对齐填充,一般来说即使是一个空对象,也需要占用对象头12-20字节。而序列化之后则不用存储这些内容。另外序列化也是一个重新的编码,也会起到“压缩”的效果
spark官网上的一些说明
By default, Java objects are fast to access, but can easily consume a factor of 2-5x more space than the “raw” data inside their fields. This is due to several reasons:
- Each distinct Java object has an “object header”, which is about 16 bytes and contains information such as a pointer to its class. For an object with very little data in it (say one Int field), this can be bigger than the data.
- Java Strings have about 40 bytes of overhead over the raw string data (since they store it in an array of Chars and keep extra data such as the length), and store each character as two bytes due to String’s internal usage of UTF-16 encoding. Thus a 10-character string can easily consume 60 bytes.
- Common collection classes, such as HashMap and LinkedList, use linked data structures, where there is a “wrapper” object for each entry (e.g. Map.Entry). This object not only has a header, but also pointers (typically 8 bytes each) to the next object in the list.
- Collections of primitive types often store them as “boxed” objects such as java.lang.Integer.
2.为什么要序列化
因为两个进程在进行远程通信时,都会以二进制序列的形式在网络上传送。无论是何种类型的数据,发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
3.为什么有的task只有spill memory没有spill disk,或者只有spill disk没有spill memory
个人推测是统计信息的采样丢失引起的,两者应该是同时存在或不存在
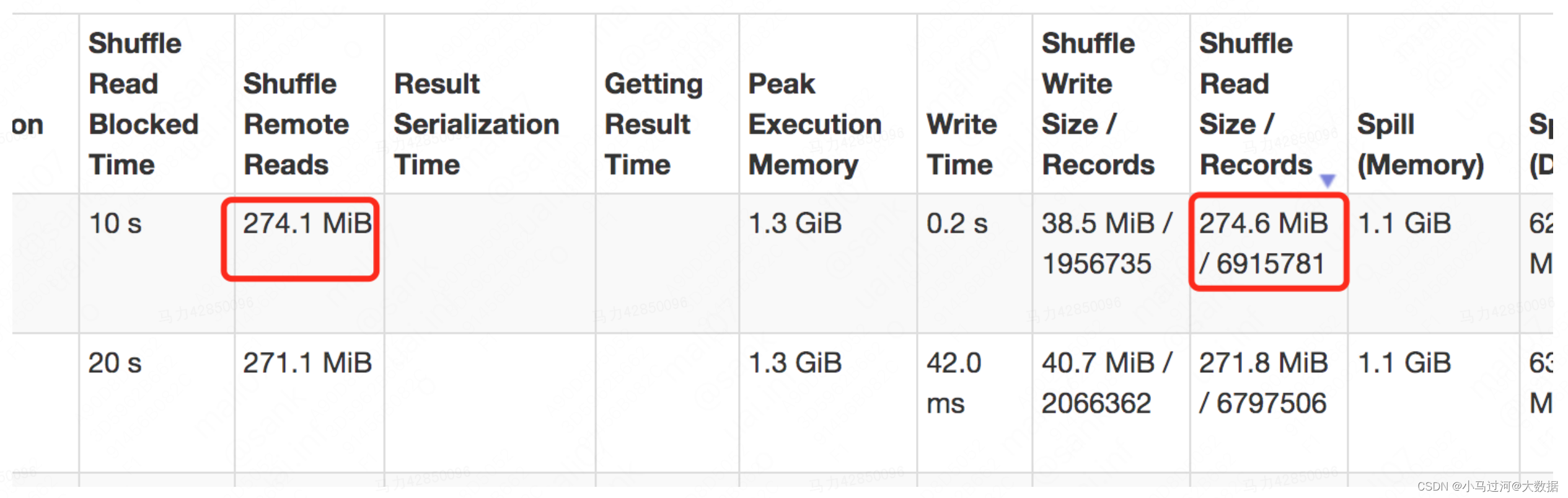
Shuffle Read Size和 Shuffle Remote Reads是什么关系,为什么有时前者会比后者小
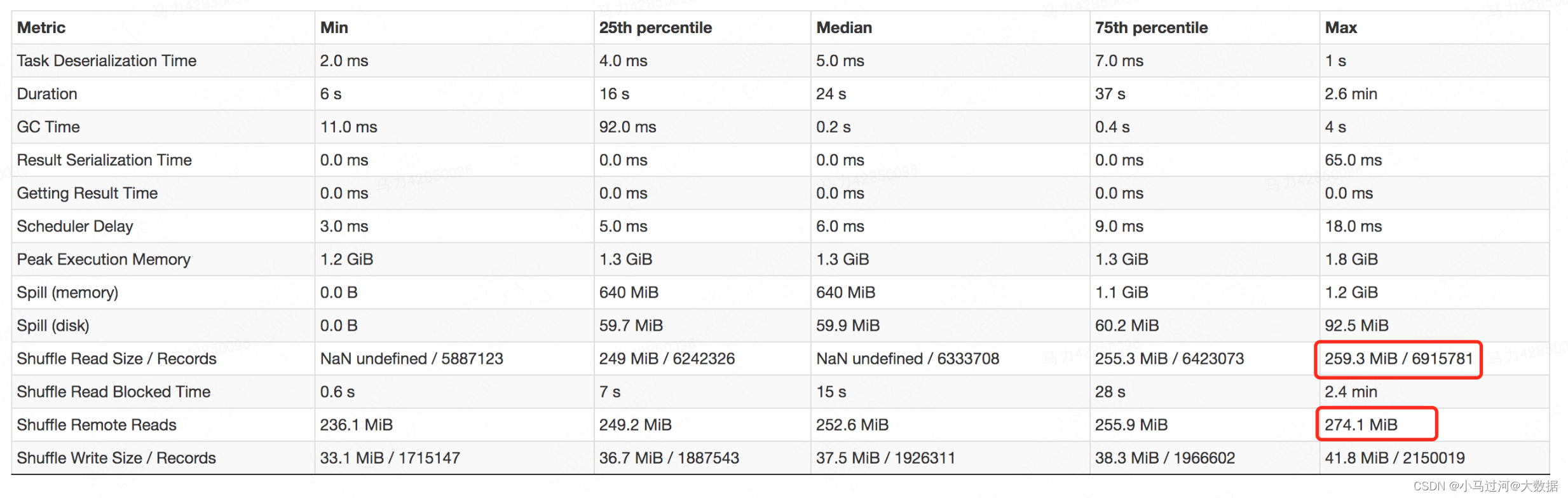 理论上说Shuffle Read Size包含了local read和remote read,所以Shuffle Read Size应该永远比Shuffle Remote Reads要大。个人推测在summary metrics中可能是统计信息丢失或者有误,会出现前者小于后者的情况,建议以task明细为准
理论上说Shuffle Read Size包含了local read和remote read,所以Shuffle Read Size应该永远比Shuffle Remote Reads要大。个人推测在summary metrics中可能是统计信息丢失或者有误,会出现前者小于后者的情况,建议以task明细为准
4.GC Time时间过长,有没有什么好办法
通常情况下gc时间不应该过长,如果出现gc过长首先应该找到gc耗时久的原因,对因下药解决。
也有一些对症下药的通用办法,比如增加executor的内存或者调整spark.memory.fraction参数增大执行内存,再或者可以更换垃圾回收器
版权归原作者 小马过河@大数据 所有, 如有侵权,请联系我们删除。