
文章目录
本文目录结构:
|___ 1. 前言
|___ 2. 数据源安装与配置
|______ 2.1 MySQL
|_________ 2.1.1 安装
|_________ 2.1.2 CDC 配置
|______ 2.2 Postgresql
|_________ 2.2.1 安装
|_________ 2.2.2 CDC 配置
|______ 2.3 Oracle
|_________2.3.1 安装
|_________2.3.2 CDC 配置
|_______2.4 SQLServer
|_________2.4.1 安装
|_________2.4.2 CDC 配置
|___ 3. 验证
|_______3.1 Flink版本与CDC版本的对应关系
|_______3.2 下载相关包
|_______3.3 添加cdc jar 至lib目录
|_______3.4 验证
1. 前言
关于如何使用和配置
flink cdc
功能,其实在官方文档(https://ververica.github.io/flink-cdc-connectors/master/)有相关的教程了,如下: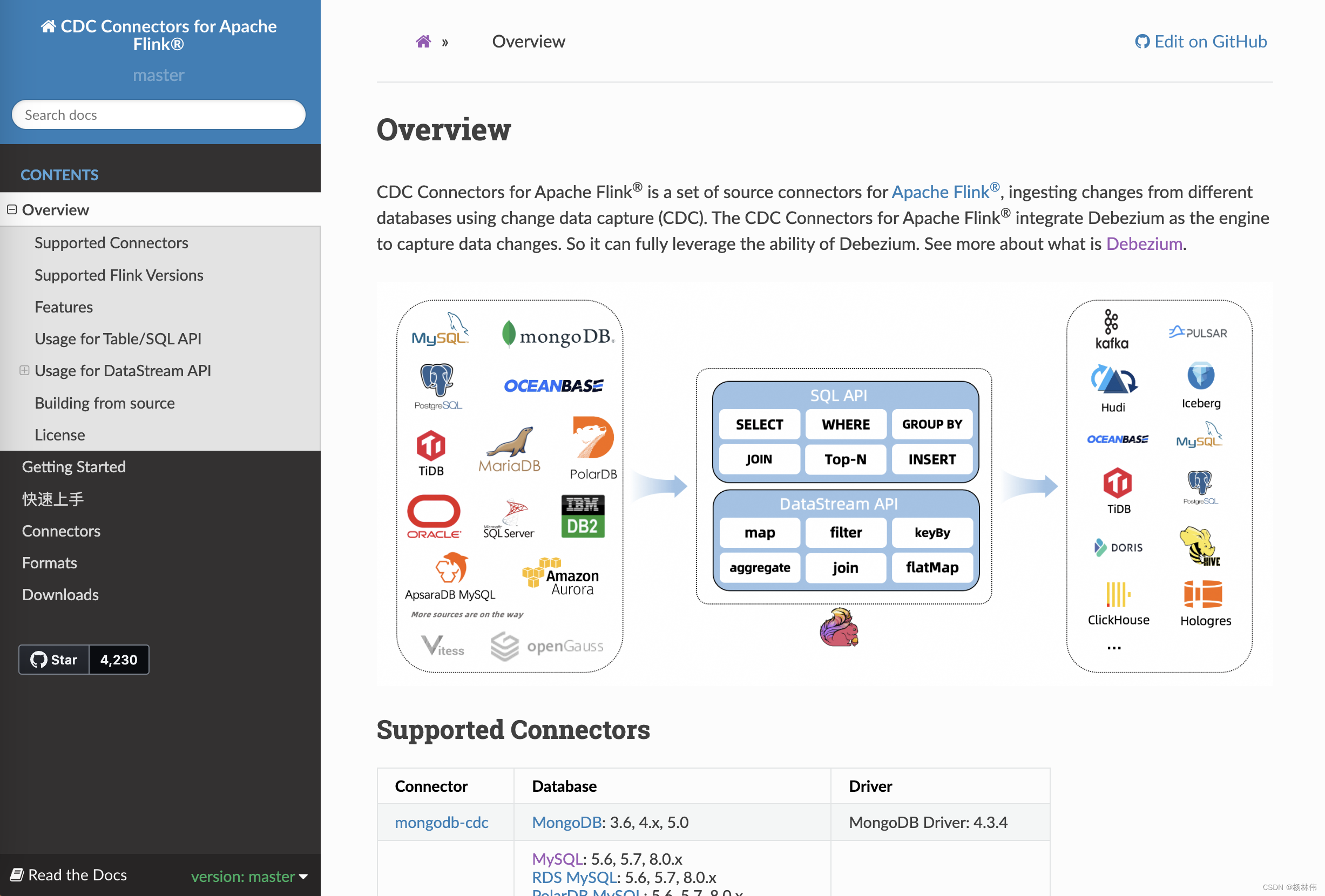
但是讲解的不是很详细,比如数据源怎么安装?怎么配置?都没有很详细的描述每一步骤,因此博主前面发布多篇文章以此来记录
flink cdc
相关数据源以及其配置相关的文章,有兴趣的同学可以参考下:
- 《docker下安装oracle11g(一次安装成功)》
- 《Docker下安装SqlServer2019》
- 《flink postgresql cdc实时同步(含pg安装配置等)》
- 《flink oracle cdc实时同步(超详细)》
- 《flink sqlserver cdc实时同步(含sqlserver安装配置等)》
本文主要就是记录在
docker
下安装和配置各种数据源,以实现
flink cdc
的功能,包含如下常见的数据源:
数据源版本MySQL8.0.25Postgresql10.6Oracle11gSqlServer2019
2. 数据源安装与配置
2.1 MySQL
版本:8.0.25
2.1.1 安装
Step1: 拉取mysql镜像:
docker pull mysql:8.0.25
Step2: 创建并运行 MySQL 容器
docker run -d-p30025:3306 --name mysql8.0.25 -eMYSQL_ROOT_PASSWORD=root mysql:8.0.25
2.1.2 CDC 配置
Step1:进入正在运行的mysql容器:
dockerexec-it mysql8.0.25 mysql -uroot-proot
Step2:配置 CDC
-- 启用二进制日志
mysql>SETGLOBAL log_bin =ON;-- 设置二进制日志格式为行级别
mysql>SETGLOBAL binlog_format ='ROW';
Step3(非必要):如果配置没生效,重启容器
docker restart mysql8.0.25
2.2 Postgresql
版本:PostgreSQL 10.6 (Debian 10.6-1.pgdg90+1)
2.2.1 安装
Step1: 拉取 PostgreSQL 10.6 版本的镜像:
docker pull postgres:10.6
Step2:创建并启动
PostgreSQL
容器,在这里,我们将把容器的端口 5432 映射到主机的端口 30028,账号密码设置为
postgres
,并将
pgoutput
插件加载到
PostgreSQL
实例中:
docker run -d-p30028:5432 --name postgres-10.6 -ePOSTGRES_PASSWORD=postgres postgres:10.6 -c'shared_preload_libraries=pgoutput'
Step3: 查看容器是否创建成功:
dockerps|grep postgres-10.6
2.2.2 CDC 配置
Step1:docker进去Postgresql数据的容器:
dockerexec-it postgres-10.6 bash
Step2:编辑
postgresql.conf
配置文件:
vi /var/lib/postgresql/data/postgresql.conf
配置内容如下:
# 更改wal日志方式为logical(方式有:minimal、replica 、logical )
wal_level = logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots =20# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders =20# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s,0表示禁用)
wal_sender_timeout = 180s
Step3:重启容器:
docker restart postgres-10.6
连接数据库,如果查询一下语句,返回
logical
表示修改成功:
SHOW wal_level;
Step4:新建用户并赋权。使用创建容器时的账号密码(
postgres/postgres
)登录Postgresql数据库。
-- 创建数据库 test_dbCREATEDATABASE test_db;-- 连接到新创建的数据库 test_db
\c test_db
-- 创建 t_user 表CREATETABLE"public"."t_user"("id" int8 NOTNULL,"name"varchar(255),"age" int2,PRIMARYKEY("id"));-- pg新建用户CREATEUSER test1 WITH PASSWORD 'test123';-- 给用户复制流权限ALTER ROLE test1 replication;-- 给用户登录数据库权限GRANTCONNECTONDATABASE test_db to test1;-- 把当前库public下所有表查询权限赋给用户GRANTALLPRIVILEGESONALLTABLESINSCHEMApublicTO test1;
Step4:发布表:
-- 设置发布为trueupdate pg_publication set puballtables=truewhere pubname isnotnull;-- 把所有表进行发布CREATE PUBLICATION dbz_publication FORALLTABLES;-- 查询哪些表已经发布select*from pg_publication_tables;-- 更改复制标识包含更新和删除之前值(目的是为了确保表 t_user 在实时同步过程中能够正确地捕获并同步更新和删除的数据变化。如果不执行这两条语句,那么 t_user 表的复制标识可能默认为 NOTHING,这可能导致实时同步时丢失更新和删除的数据行信息,从而影响同步的准确性)ALTERTABLE t_user REPLICA IDENTITYFULL;-- 查看复制标识(为f标识说明设置成功,f(表示 full),否则为 n(表示 nothing),即复制标识未设置)select relreplident from pg_class where relname='t_user';
2.3 Oracle
版本:Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
2.3.1 安装
Step1:拉取 oracle 11g 镜像(有6g,要等较长的时间)
docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
Step2:执行以下命令以创建并运行 Oracle 11g 容器
docker run -d-p30026:1521 -p8081:8080 \--name oracle_11g \-eORACLE_HOME=/home/oracle/app/oracle/product/11.2.0/dbhome_2 \-eORACLE_SID=helowin \
registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
Step3:查看容器是否启动
dockerps -a|grep oracle_11g
Step4:进入容器
dockerexec-it oracle_11g bash
Step5:设置账号密码
# 1. 切换至root用户(默认是oracle用户),密码为helowinsu root
# 2. 创建软链接ln-s$ORACLE_HOME/bin/sqlplus /usr/bin
# 3.切换回oracle用户su oracle
# 4. 登录sql plus
sqlplus /nolog
conn /as sysdba
## 4.1 修改system用户密码为system
alter user system identified by system;## 4.2 修改sys用户密码为system
alter user sys identified by system;## 4.3 新增一个测试用户(用户名:test,密码:test123);
create user test identified by test123;## 4.4 将dba权限给内部管理员账号和密码
grant connect,resource,dba to test;## 4.5 修改密码策略规则为:密码永不过期
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED;## 4.6 修改数据库最大连接数;
alter system setprocesses=1000scope=spfile;## 4.7 最后重启数据库;shutdown immediate;
startup;# 5.退出exit
2.3.2 CDC 配置
Step1:进入容器
dockerexec-it oracle_11g bash
Step2:以DBA的权限登录数据库
sqlplus /nolog
CONNECT sys/system AS SYSDBA
Step3:启用日志归档
-- 设置数据库恢复文件目标大小为10Galter system set db_recovery_file_dest_size =10G;-- 设置数据库恢复文件目标路径alter system set db_recovery_file_dest ='/home/oracle/app/oracle/product/11.2.0' scope=spfile;-- 立即关闭数据库shutdown immediate;-- 以mount模式启动数据库
startup mount;-- 启用数据库归档日志模式alterdatabase archivelog;-- 打开数据库,允许用户访问alterdatabaseopen;
Step4:查看日志归档是否启用(如果显示“Archive Mode”表示已经启用)
archive log list;
Step5:创建表空间
-- 以DBA的权限登录数据库
sqlplus /nolog
CONNECT sys/system AS SYSDBA
-- 创建一个名为"logminer_tbs"的表空间-- 指定表空间的数据文件路径为"/home/oracle/app/oracle/product/11.2.0/logminer_tbs.dbf",其中"/home/oracle/app/oracle/product/11.2.0"是数据文件存储的目录,"logminer_tbs.dbf"是数据文件的文件名-- 设置表空间的初始大小为25MB-- 如果数据文件已经存在且可重用,将其重用,否则创建一个新的数据文件-- 启用表空间的自动扩展功能,即当表空间空间不足时,自动增加数据文件的大小-- 设置表空间的最大允许大小为无限,即表空间可以无限制地自动扩展CREATETABLESPACE logminer_tbs DATAFILE '/home/oracle/app/oracle/product/11.2.0/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
Step6:创建用户并赋权
-- 创建一个名为"flinkuser"的用户,密码为"flinkpw",将其默认表空间设置为"LOGMINER_TBS",并在该表空间上设置无限配额。CREATEUSER flinkuser IDENTIFIED BY flinkpw DEFAULTTABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;-- 允许"flinkuser"用户创建会话,即允许该用户连接到数据库。GRANTCREATESESSIONTO flinkuser;-- (不支持Oracle 11g)允许"flinkuser"用户在多租户数据库(CDB)中设置容器。-- GRANT SET CONTAINER TO flinkuser;-- 允许"flinkuser"用户查询V_$DATABASE视图,该视图包含有关数据库实例的信息。GRANTSELECTON V_$DATABASETO flinkuser;-- 允许"flinkuser"用户执行任何表的闪回操作。GRANT FLASHBACK ANYTABLETO flinkuser;-- 允许"flinkuser"用户查询任何表的数据。GRANTSELECTANYTABLETO flinkuser;-- 允许"flinkuser"用户拥有SELECT_CATALOG_ROLE角色,该角色允许查询数据字典和元数据。GRANT SELECT_CATALOG_ROLE TO flinkuser;-- 允许"flinkuser"用户拥有EXECUTE_CATALOG_ROLE角色,该角色允许执行一些数据字典中的过程和函数。GRANT EXECUTE_CATALOG_ROLE TO flinkuser;-- 允许"flinkuser"用户查询任何事务。GRANTSELECTANYTRANSACTIONTO flinkuser;-- (不支持Oracle 11g)允许"flinkuser"用户进行数据变更追踪(LogMiner)。-- GRANT LOGMINING TO flinkuser;-- 允许"flinkuser"用户创建表。GRANTCREATETABLETO flinkuser;-- 允许"flinkuser"用户锁定任何表。GRANTLOCKANYTABLETO flinkuser;-- 允许"flinkuser"用户修改任何表。GRANTALTERANYTABLETO flinkuser;-- 允许"flinkuser"用户创建序列。GRANTCREATE SEQUENCE TO flinkuser;-- 允许"flinkuser"用户执行DBMS_LOGMNR包中的过程。GRANTEXECUTEON DBMS_LOGMNR TO flinkuser;-- 允许"flinkuser"用户执行DBMS_LOGMNR_D包中的过程。GRANTEXECUTEON DBMS_LOGMNR_D TO flinkuser;-- 允许"flinkuser"用户查询V_$LOG视图,该视图包含有关数据库日志文件的信息。GRANTSELECTON V_$LOG TO flinkuser;-- 允许"flinkuser"用户查询V_$LOG_HISTORY视图,该视图包含有关数据库历史日志文件的信息。GRANTSELECTON V_$LOG_HISTORY TO flinkuser;-- 允许"flinkuser"用户查询V_$LOGMNR_LOGS视图,该视图包含有关LogMiner日志文件的信息。GRANTSELECTON V_$LOGMNR_LOGS TO flinkuser;-- 允许"flinkuser"用户查询V_$LOGMNR_CONTENTS视图,该视图包含LogMiner日志文件的内容。GRANTSELECTON V_$LOGMNR_CONTENTS TO flinkuser;-- 允许"flinkuser"用户查询V_$LOGMNR_PARAMETERS视图,该视图包含有关LogMiner的参数信息。GRANTSELECTON V_$LOGMNR_PARAMETERS TO flinkuser;-- 允许"flinkuser"用户查询V_$LOGFILE视图,该视图包含有关数据库日志文件的信息。GRANTSELECTON V_$LOGFILE TO flinkuser;-- 允许"flinkuser"用户查询V_$ARCHIVED_LOG视图,该视图包含已归档的数据库日志文件的信息。GRANTSELECTON V_$ARCHIVED_LOG TO flinkuser;-- 允许"flinkuser"用户查询V_$ARCHIVE_DEST_STATUS视图,该视图包含有关归档目标状态的信息。GRANTSELECTON V_$ARCHIVE_DEST_STATUS TO flinkuser;
Step7:数据库和表启用增量日志
-- 切换至flinkuser用户
sqlplus /nolog
CONNECT flinkuser/flinkpw
-- 创建customers表CREATETABLE customers (
customer_id NUMBER PRIMARYKEY,
customer_name VARCHAR2(50),
email VARCHAR2(100),
phone VARCHAR2(20))TABLESPACE LOGMINER_TBS;-- 查看LOGMINER_TBS表空间下的所有表select tablespace_name, table_name from user_tables
where tablespace_name ='LOGMINER_TBS';-- 以DBA的权限登录数据库
sqlplus /nolog
CONNECT sys/system AS SYSDBA
-- 为LOGMINER_TBS表空间下的customers表启用增强日志记录ALTERTABLE FLINKUSER.CUSTOMERS ADD SUPPLEMENTAL LOG DATA(ALL)COLUMNS-- 为数据库启用增强日志记录:ALTERDATABASEADD SUPPLEMENTAL LOG DATA;
2.4 SQLServer
版本:Microsoft SQL Server 2019 (RTM-CU21) (KB5025808) - 15.0.4316.3 (X64)
2.4.1 安装
Step1:拉取SQL Server 2019 镜像
docker pull mcr.microsoft.com/mssql/server:2019-latest
Step2:运行 SQL Server 容器(密码必须是8个字符,并包含字母、数字和特殊字符,如:abc@123456 ,下面映射主机端口为30027)
docker run -e'ACCEPT_EULA=Y'-e'SA_PASSWORD=abc@123456'-p30027:1433 --name sql_server_2019 -d mcr.microsoft.com/mssql/server:2019-latest
Step3:验证 SQL Server 容器是否正在运行
docker ps -a|grep sql_server_2019
2.4.2 CDC 配置
Step1:开启SQLServer代理
## 使用root用户登录容器dockerexec-it--user root sql_server_2019 bash## 进入容器后,执行命令启用Agent
/opt/mssql/bin/mssql-conf set sqlagent.enabled true## 退出,重启容器exitdocker restart sql_server_2019
Step2:创建’cdc_test’测试数据库,并使用连接工具登录该数据库,使用以下 SQL 命令启用 CDC 功能
-- 创建数据库CREATEDATABASE cdc_test;-- 启用CDC功能EXEC sys.sp_cdc_enable_db;-- 判断当前数据库是否启用了CDC(如果返回1,表示已启用)SELECT is_cdc_enabled FROM sys.databasesWHERE name ='cdc_test';
Step3:选择要进行 CDC 跟踪的表(这里使用
orders表作为演示
)
-- 创建示例表(orders)CREATETABLE orders (
id int,
order_date date,
purchaser int,
quantity int,
product_id int,PRIMARYKEY([id]));-- schema_name 是表所属的架构(schema)的名称。-- table_name 是要启用 CDC 跟踪的表的名称。-- cdc_role 是 CDC 使用的角色的名称。如果没有指定角色名称,系统将创建一个默认角色。EXEC sys.sp_cdc_enable_table
@source_schema='dbo',@source_name='orders',@role_name='cdc_role';
3. 验证
如果要验证
flink cdc
的功能,需要先下载
flink
的安装包,然后下载相应的
cdc jar
包并依赖,最后使用安装包里面的
sql-client
写相关的
flink sql
即可验证。
3.1 Flink版本与CDC版本的对应关系
下载Flink安装包以及jar包前,必须确定Flink CDC与Flink版本关系:
Flink CDC 版本Flink 版本1.0.0
1.11.*
1.1.0
1.11.*
1.2.0
1.12.*
1.3.0
1.12.*
1.4.0
1.13.*
2.0.*
1.13.*
2.1.*
1.13.*
2.2.*
1.13.*
,
1.14.*
2.3.*
1.13.*
,
1.14.*
,
1.15.*
,
1.16.0
2.4.*
1.13.*
,
1.14.*
,
1.15.*
,
1.16.*
,
1.17.0
本文以 Flink1.13.6 + Flink CDC 2.2.0 版本为例子演示。
3.2 下载相关包
flink 安装包下载,下载地址:https://flink.apache.org/downloads/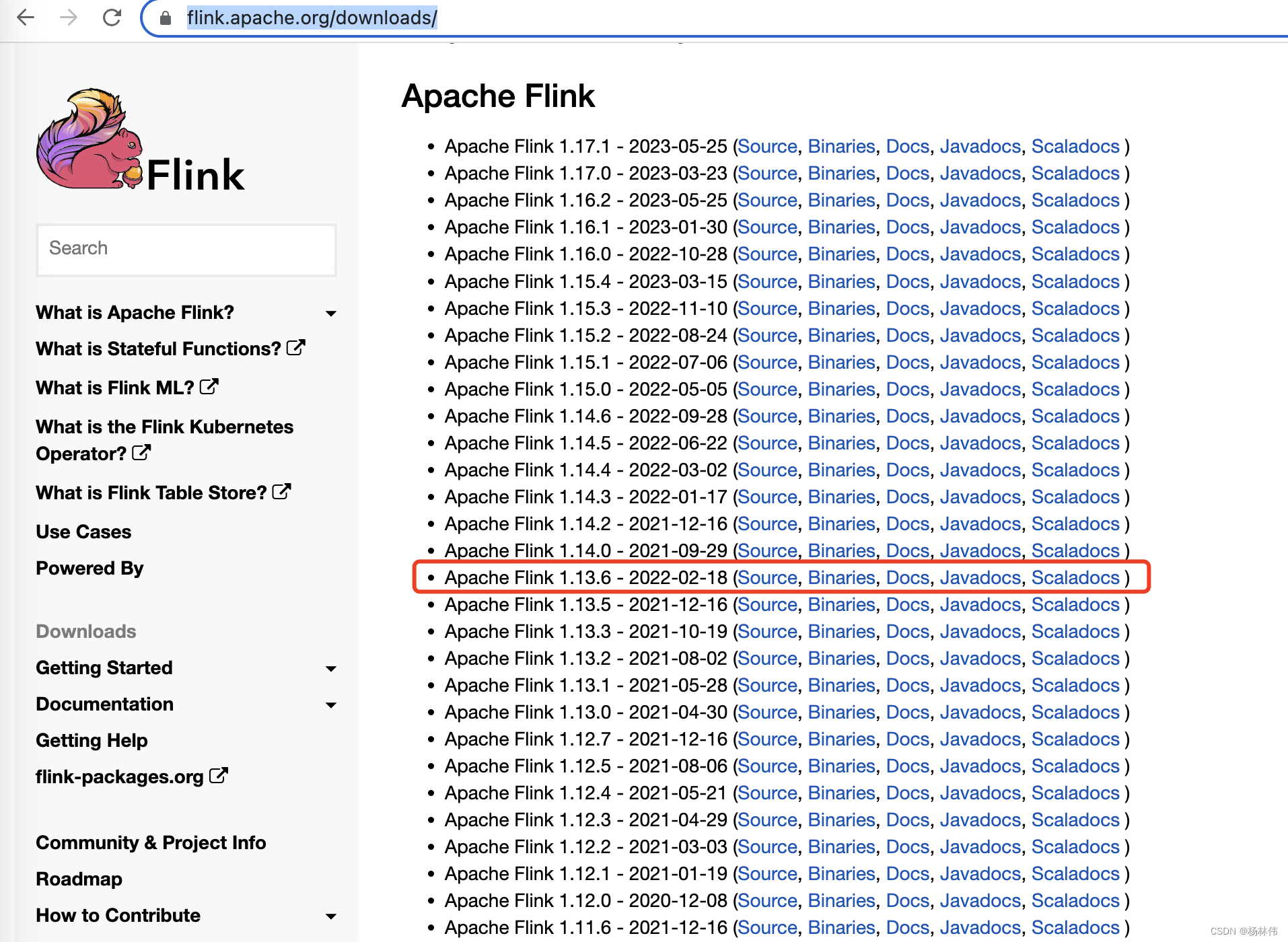
下载cdc相关的jar,根据自己的需求,下载相关的cdc jar:https://repo1.maven.org/maven2/com/ververica/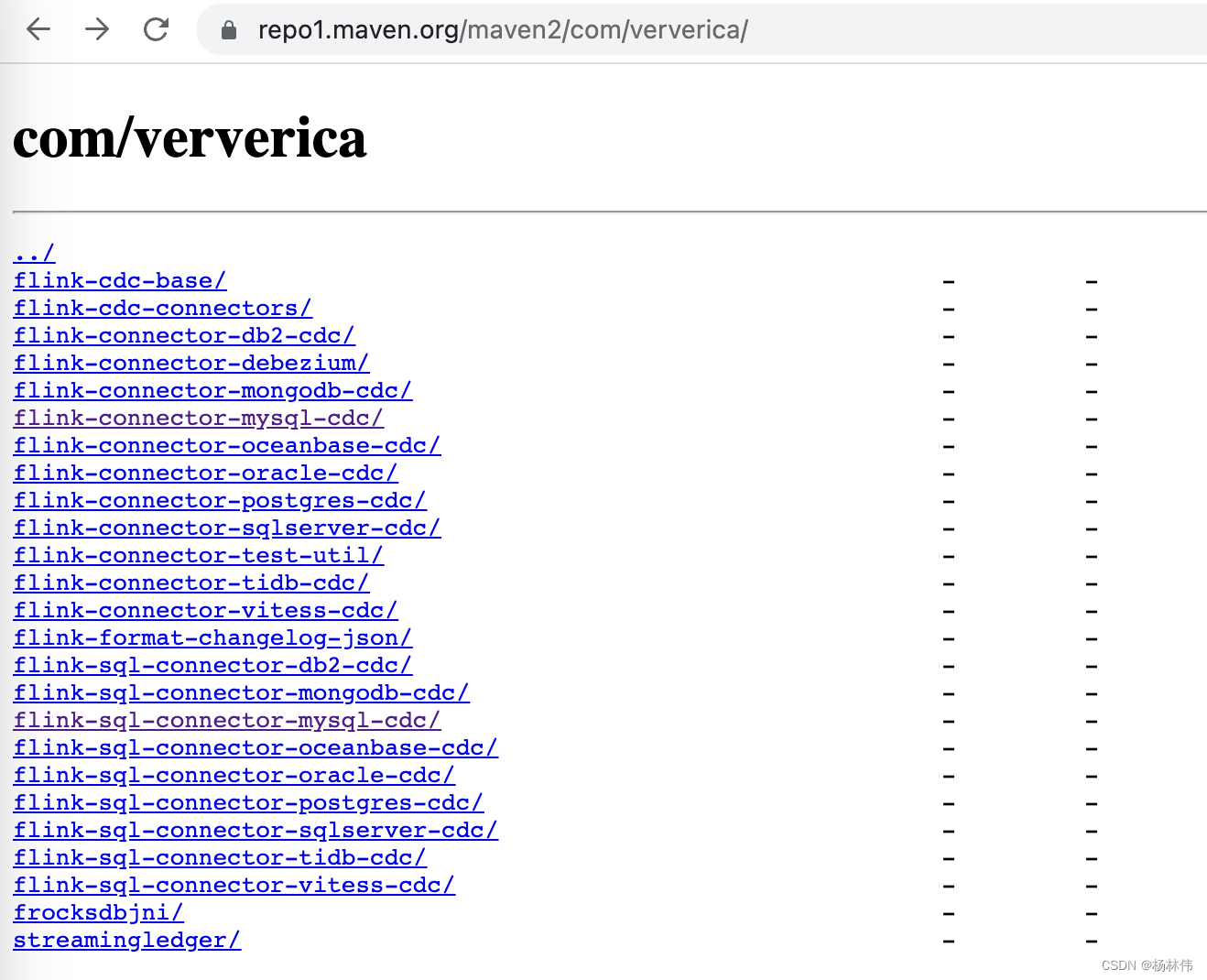
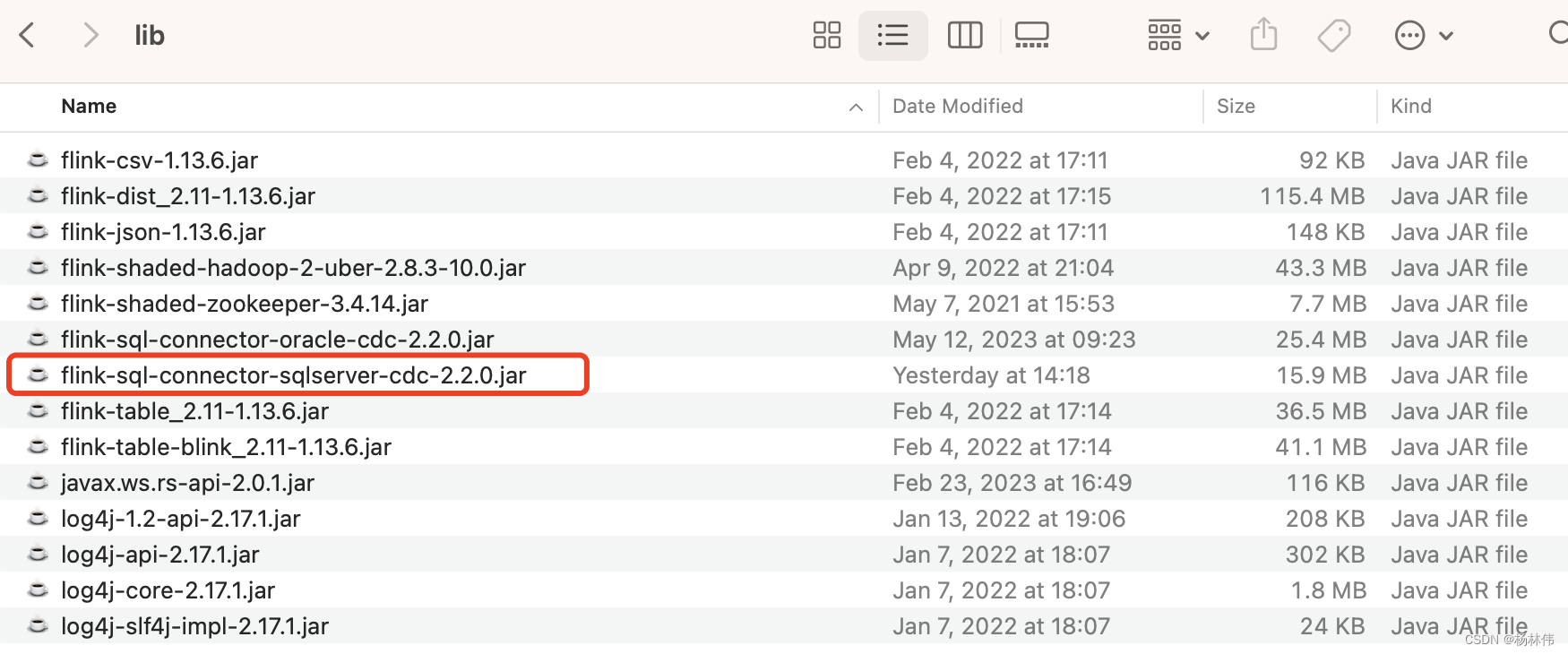
3.3 添加cdc jar 至lib目录
把需要验证的cdc jar放到flink安装包解压之后的lib目录(
<FLINK_HOME>/lib/
):
3.4 验证
使用下面的命令启动 Flink 集群:
./bin/start-cluster.sh
启动成功,可以访问 http://localhost:8081 访问到 Flink Web UI: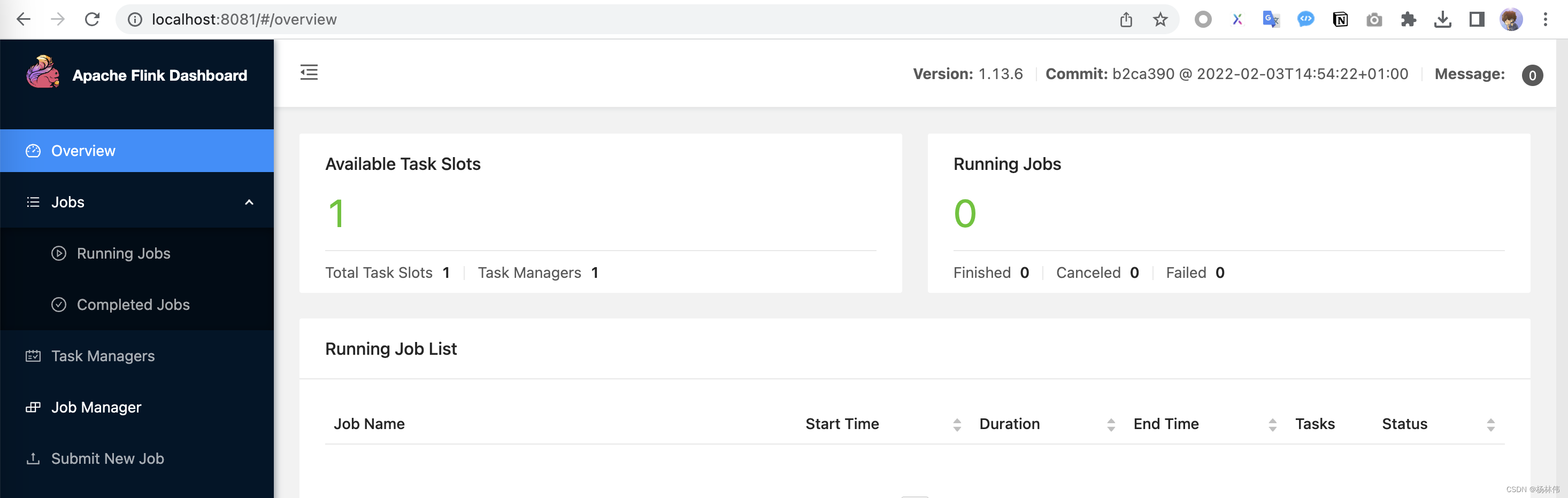
使用下面的命令启动 Flink SQL CLI :
./bin/sql-client.sh
展示如下页面,表示启动flink客户端成功:
执行如下FlinkSQL:
CREATETABLE t_source_sqlserver (
id INT,
order_date DATE,
purchaser INT,
quantity INT,
product_id INT,PRIMARYKEY(id)NOT ENFORCED
)WITH('connector'='sqlserver-cdc','hostname'='10.194.183.120','port'='30027','username'='sa','password'='abc@123456','database-name'='cdc_test','schema-name'='dbo','table-name'='orders');
可以看到执行成功了: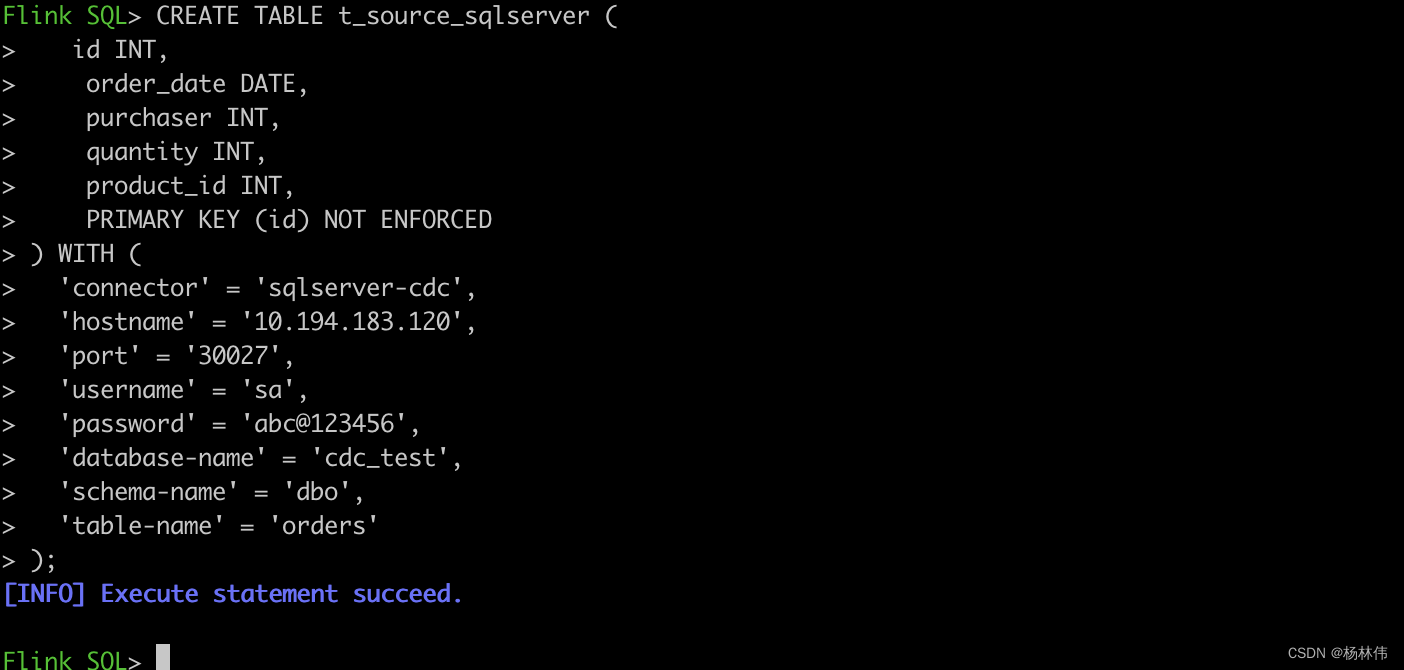
执行select 语句,以便实时查看该表的数据变动:
select*from t_source_sqlserver;
从下图,可以看出,只要修改左边的数据,会在控制台实时显示新增删除的数据。
同时,也能在Flink web页面看到任务正在运行: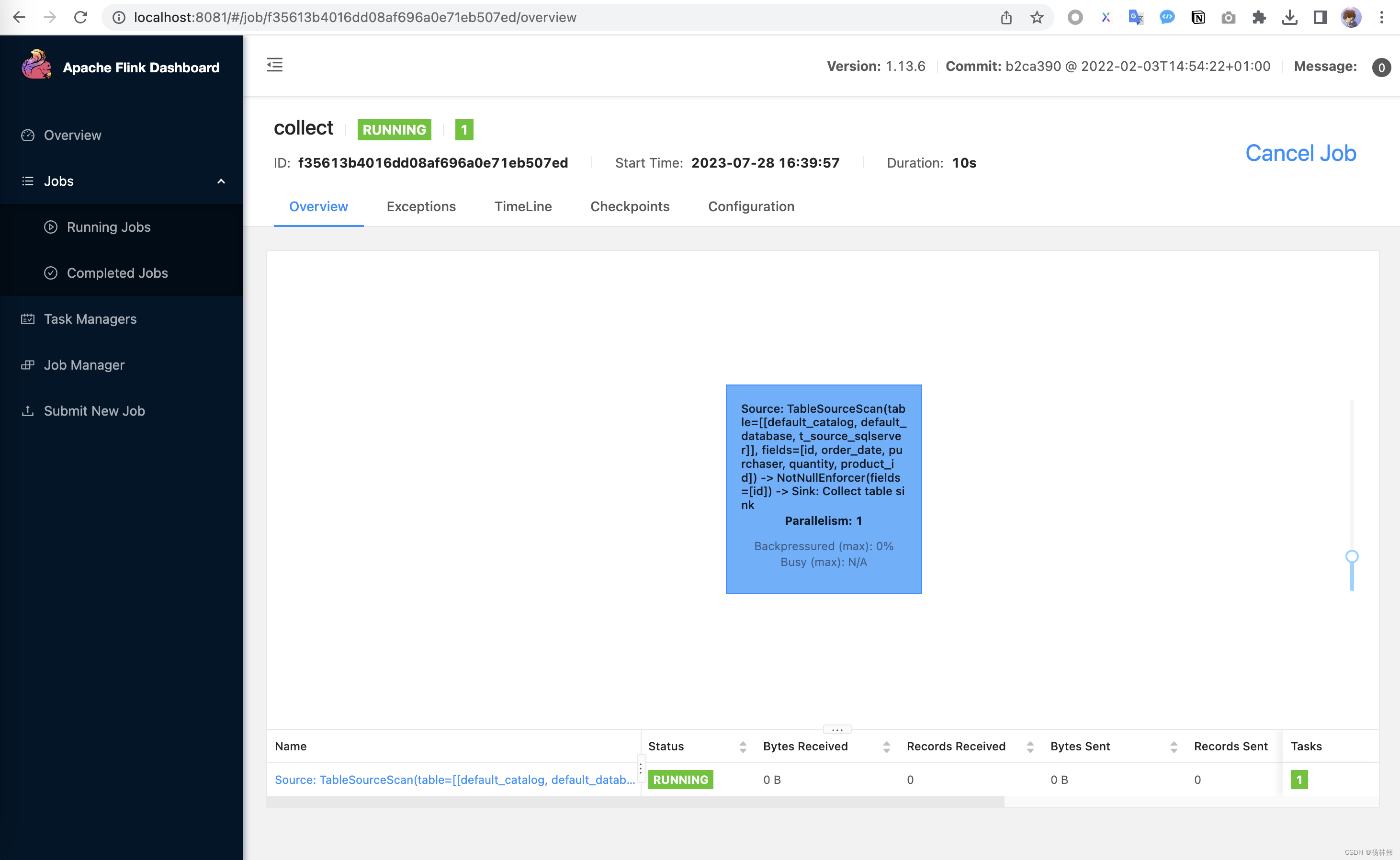
最后,可以通过如下命令关闭掉Flink启动的集群:
./stop-cluster.sh
版权归原作者 杨林伟 所有, 如有侵权,请联系我们删除。