
Flink ON YARN 模式就是使用客户端的方式,直接向Hadoop集群提交任务即可,不需要单独启动Flink进程
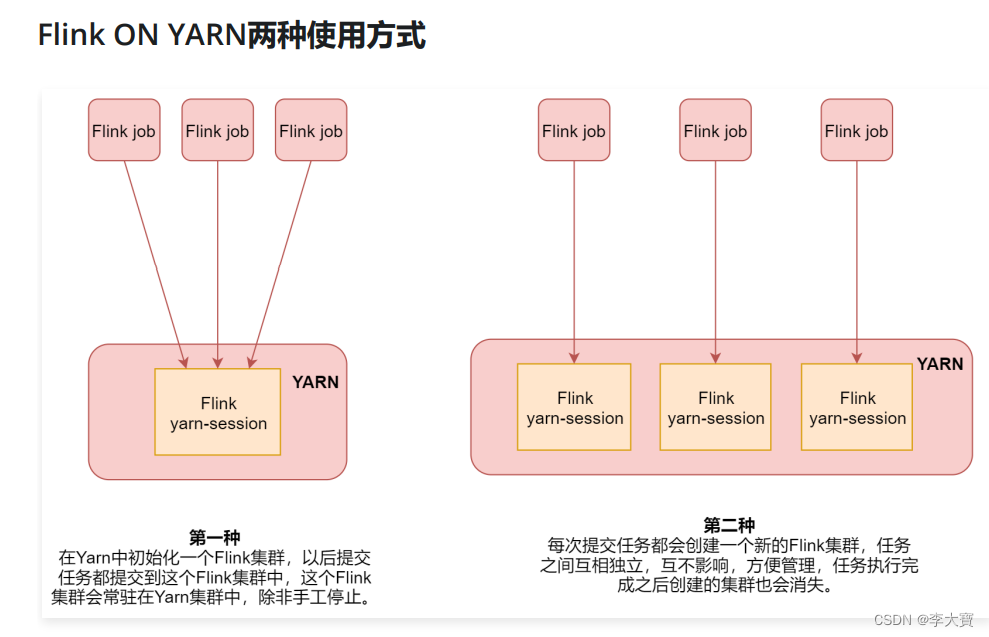
Flink ON YARN有两种使用方式:
- 在yarn中初始化一个flink集群,以后提交任务都提交到这个flink集群中,这个flink集群会常驻在yarn集群中,除非手工停止
- 每次提交任务都会创建一个新的flink集群,任务之间相互独立,互不影响,任务执行完成后创建的集群也会消失
一、Flink ON YARN第一种方式
1.1、把flink-1.11.1-bin-scala_2.12.tgz上传解压即可
tar -zxvf flink-1.11.1-bin-scala_2.12.tgz
1.2、在/etc/profile 中配置HADOOP_CLASSPATH
export HADOOP_CLASSPATH=${HADOOP_HOME}/bin/hadoop classpath
source /etc/profile

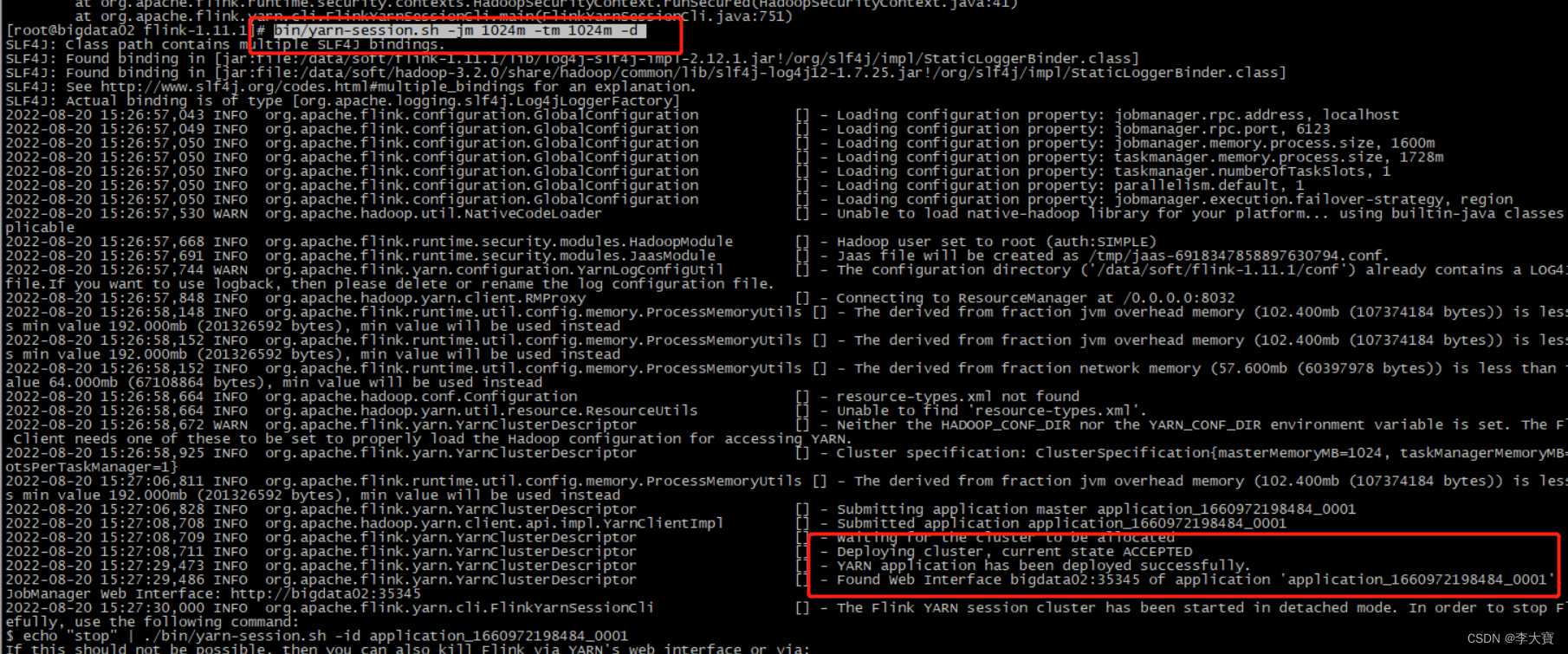
1.3、启动flink集群
bin/yarn-session.sh -jm 1024m -tm 1024m -d

1.4、向这个Flink集群中提交任务
bin/flink run ./examples/batch/WordCount.jar
运行结果:

1.5、关闭flink集群
yarn application -kill application_1660972198484_0001
二、 Flink ON YARN第二种方式
flink run -m yarn-cluster (创建Flink集群+提交任务)
使用flink run直接创建一个临时的Flink集群,并且提交任务 此时这里面的参数前面加上了一个 y 参数
提交上去之后,会先创建一个Flink集群,然后在这个Flink集群中执行任务。
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
输出结果: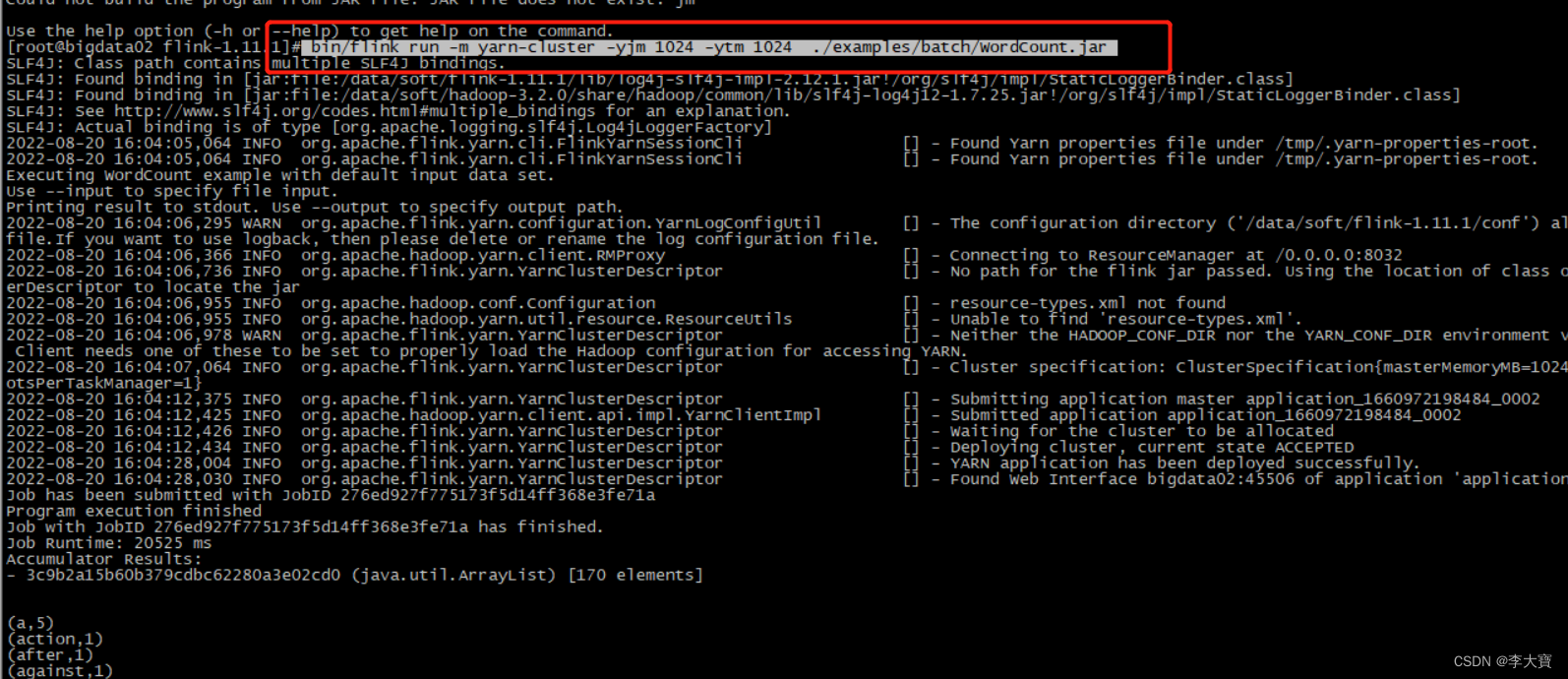
针对Flink命令的一些用法汇总
三、运行实际开发的项目
3.1、在pom中添加打包插件,把项目打包后上传到服务器上
<build>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- scala编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.6</version>
<configuration>
<scalaCompatVersion>2.11</scalaCompatVersion>
<scalaVersion>2.11.11</scalaVersion>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<id>compile-scala</id>
<phase>compile</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<phase>test-compile</phase>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打jar包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 可以设置jar包的入口类(可选) -->
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
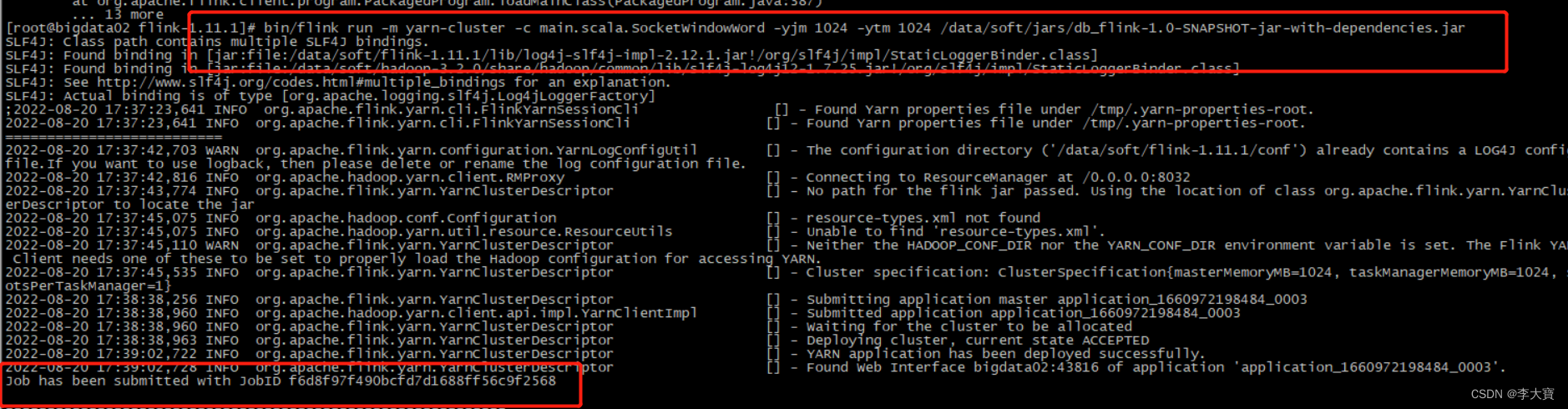
3.2、提交上去之后,会先创建一个Flink集群,然后在这个Flink集群中执行任务。
bin/flink run -m yarn-cluster -c main.scala.SocketWindowWord
-yjm 1024 -ytm 1024 /data/soft/jars/db_flink-1.0-SNAPSHOT-jar-with-dependencies.jar
结果:
本文转载自: https://blog.csdn.net/libaowen609/article/details/126440082
版权归原作者 李大寶 所有, 如有侵权,请联系我们删除。
版权归原作者 李大寶 所有, 如有侵权,请联系我们删除。