
在平常的工作与生活中,衡量服务器的性能是每一个程序员必备的技能,load作为必不可少的衡量性能的指标,它的理解和查看是非常重要的,本文主要介绍load(负载)的常用查看命令与定义和系统机器正常负载范围:
负载的概念
负载(load)是linux机器的一个重要指标,直观了反应了机器当前的状态。
简单解释一下:在LINUX系统中,系统负载是对当前CPU工作量的度量,被定义为特定时间间隔内运行队列中的平均线程数。load average 表示机器一段时间内的平均load。这个值越低越好。负载过高会导致机器无法处理其他请求及操作,甚至导致死机。
Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。
查看机器负载
在Linux机器上,有多个命令都可以查看机器的负载信息。其中包括uptime、top、w、iostat等。
uptime命令
uptime命令能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。

这行信息的后半部分,显示“load average”,它的意思是“系统的平均负荷”,里面有三个数字,我们可以从中判断系统负荷是大还是小。
0.40 0.36 0.41 这三个数字的意思分别是1分钟、5分钟、15分钟内系统的平均负荷。我们一般表示为load1、load5、load15。
w命令
w命令的主要功能其实是显示目前登入系统的用户信息。但是与who不同的是,w命令功能更加强大,w命令还可以显示:当前时间,系统启动到现在的时间,登录用户的数目,系统在最近1分钟、5分钟和15分钟的平均负载。然后是每个用户的各项数据,项目显示顺序如下:登录帐号、终端名称、远 程主机名、登录时间、空闲时间、JCPU、PCPU、当前正在运行进程的命令行。
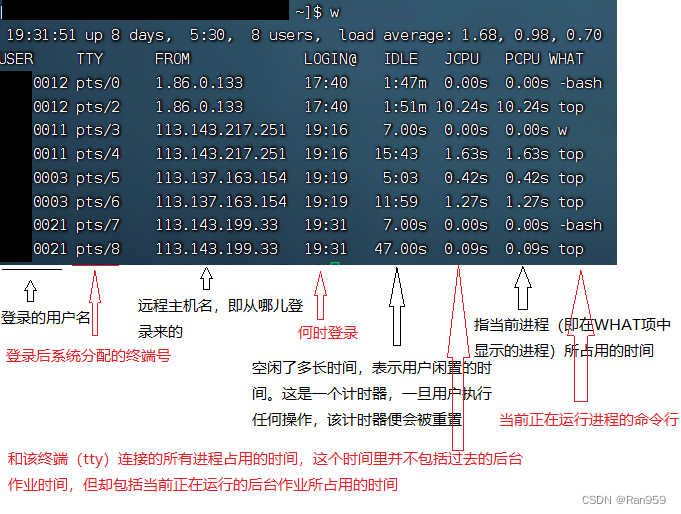
从上面的w命令的结果可以看到,当前系统时间是19:31,系统启动到现在经历了8天5个小时,共有8个用户登录。系统在近1分钟、5分钟和15分钟的平均负载分别是1.68 0.98 0.70。这和uptime得到的结果大致相同。 下面还打印了一些登录的用户的各项数据,不详细介绍了
Top命令
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
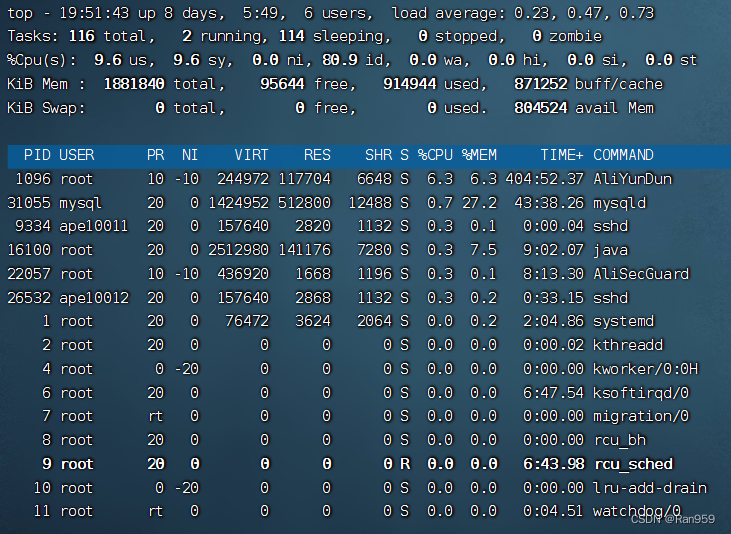
** 第一行**与就不解释了上文已经提到
第二行:Tasks: 116 total, 2 running, 107 sleeping, 0 stopped, 0 zombie
116 total:当前有116个任务
2 running:2个任务正在运行
114 sleeping:114个进程处于睡眠状态
0 stopped:停止的进程数
0 zombie:僵死的进程数
第三行:%Cpu(s): 9.6 us, 9.6 sy, 0.0 ni, 80.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
9.6%us:用户态进程占用CPU时间百分比
9.6%sy:内核占用CPU时间百分比
0.0%ni:renice值为负的任务的用户态进程的CPU时间百分比。nice是优先级的意思
80.9%id:空闲CPU时间百分比
0.0%wa:等待I/O的CPU时间百分比
0.0%hi:CPU硬中断时间百分比
0.0%si:CPU软中断时间百分比
第四行:KiB Mem : 1881840 total, 95644 free, 914944 used, 871252 buff/cache
1881840k total:物理内存总数
95644k used: 使用的物理内存
914944k free:空闲的物理内存
871252k cached:用作缓存的内存
第五行:KiB Swap: 0 total, 0 free, 0 used. 1871412 avail Mem
0k total:交换空间的总量
0k used: 使用的交换空间
0k free:空闲的交换空间
1871412k cached:缓存的交换空间
第六行:PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
PID:进程ID
USER:进程的所有者
PR:进程的优先级
NI:nice值
VIRT:占用的虚拟内存
RES:占用的物理内存
SHR:使用的共享内存
S:进行状态 S:休眠 R运行 Z僵尸进程 N nice值为负
%CPU:占用的CPU
%MEM:占用内存
TIME+: 占用CPU的时间的累加值
COMMAND:启动命令
机器正常负载范围
对于机器的Load到底多少算正常的问题,一直都是很有争议的,不同人有着不同的理解。对于单个CPU,有人认为如果Load超过0.7就算是超出正常范围了。也有人认为只要不超过1都没问题。也有人认为,单个CPU的负载在2以下都可以接受。
当系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
还有一点需要提一下,在Load Avg的指标中,有三个值,1分钟系统负荷、5分钟系统负荷,15分钟系统负荷。我们在排查问题的时候也是可以参考这三个值的。
一般情况下,1分钟系统负荷表示最近的暂时现象。15分钟系统负荷表示是持续现象,并非暂时问题。如果load15较高,而load1较低,可以认为情况有所好转。反之,情况可能在恶化。
版权归原作者 Ran959 所有, 如有侵权,请联系我们删除。