
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
** 🚀对毕设有任何疑问都可以问学长哦!**
** 大家好,这里是海浪学长计算机毕设专题,本次分享的课题是**
🎯基于聚类算法的网站内容安全检测系统
项目背景
随着互联网的快速发展,网站内容安全问题日益突出,如恶意软件、网络钓鱼、侵权内容等威胁用户的信息安全和网络环境的稳定性。为了解决这些问题,网站内容安全检测系统成为了迫切需要的技术。传统的基于规则和特征的检测方法往往面临着适应性差、易规避、效果有限等问题。因此,基于聚类算法的网站内容安全检测系统应运而生。该系统通过聚类算法对网站内容进行挖掘和分析,从而实现对恶意内容的自动检测和识别,具有更好的适应性、准确性和实时性。该课题旨在研究和开发基于聚类算法的网站内容安全检测系统,提高网络环境的安全性和用户的网络体验。
设计思路
2.1 支持向量机
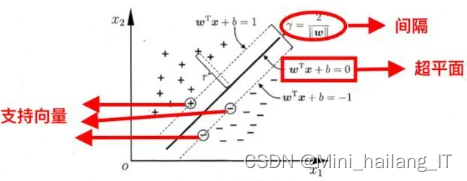
支持向量机是一种用于分类和回归分析的机器学习算法。它的主要思想是找到一个最优的超平面或者曲面,将不同类别的数据样本分隔开来,并尽可能地使分类边界与最近的数据点之间的间隔最大化。SVM的基本原理是将输入数据映射到高维特征空间中,使得数据在该空间中线性可分。在特征空间中,SVM试图找到一个超平面,可以将不同类别的样本分开,并且使得最靠近超平面的数据点到超平面的距离最大化,这些最靠近超平面的数据点被称为支持向量。
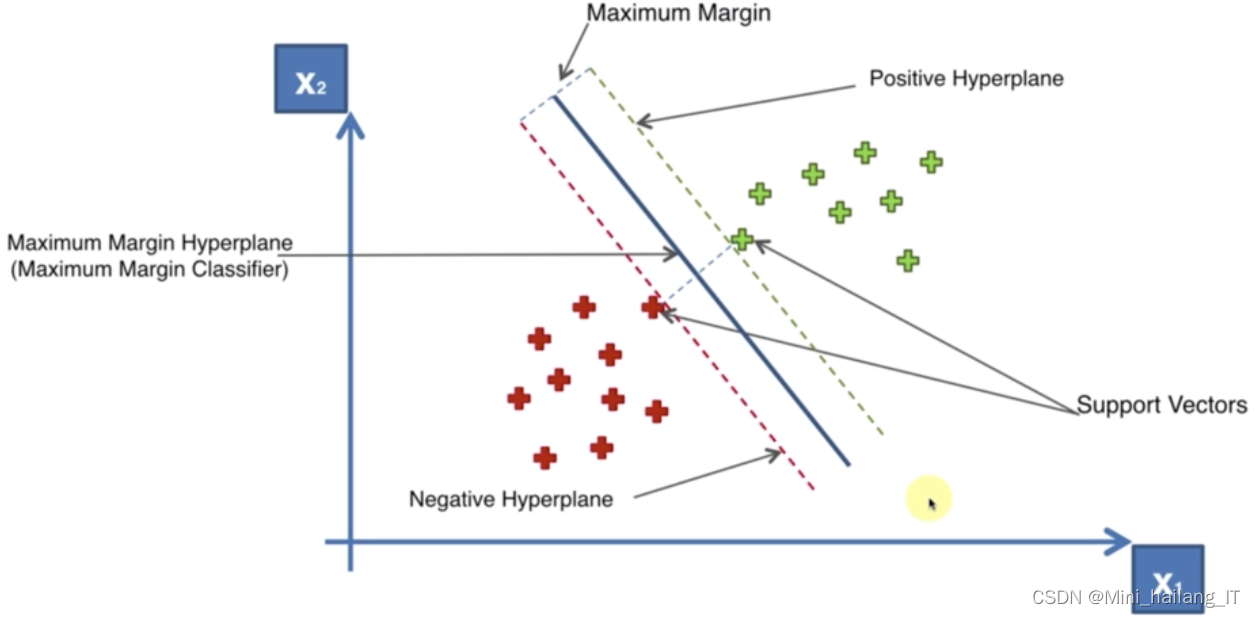
SVM的特点和优势有:
- 可用于线性和非线性分类:SVM可以通过使用不同的核函数来处理非线性分类问题,例如多项式核函数、高斯核函数等。
- 有效处理高维数据:由于SVM在特征空间中进行操作,它对高维数据的处理效果较好,可以避免维度灾难问题。
- 鲁棒性:SVM对于训练数据中的噪声和异常值具有一定的鲁棒性,可以避免过拟合的问题。
- 泛化能力强:通过最大化间隔,SVM在训练数据之外的新样本上具有较好的泛化能力。
- 支持向量的重要性:SVM仅依赖于支持向量,对于大规模数据集来说,只需保留支持向量即可,大大减少了存储和计算的开销。
基于SVM和VFS相关技术的智能网站内容监测系统能够有效识别和监测内容,解决了内容识别效率与网站内容生成速度差异大的性能瓶颈问题。SVM技术通过找到最优的超平面或曲面,将不同类别的数据样本分隔开来,实现内容分类和识别。VFS技术引入流式计算概念,提高了处理速度和效率。系统利用多处理能力,为内容恢复提供技术保障。综合运用SVM和VFS技术,实现了智能、高效的网站内容监测系统。
2.2 聚类算法
聚类算法是一种无监督学习方法,通过最大化簇内相似性和最小化簇间相似性,将数据样本划分为具有相似特征的组或簇。它能够帮助我们发现数据中的内在结构和模式,无需先验标签或目标变量。目标是将数据样本划分为具有相似特征的组或簇,而无需先验标签或目标变量。通过聚类,我们可以发现数据中的内在结构和模式,从而更好地理解数据。
聚类算法通过度量样本之间的相似性或距离来进行分类。通常,相似性度量使用欧氏距离、曼哈顿距离、余弦相似度等方法来衡量样本之间的距离或相似性。基本原理是最大化簇内相似性和最小化簇间相似性。簇内相似性较高,表示簇内的数据样本更加相似,具有较小的内部差异。簇间相似性较低,表示不同簇之间的数据样本差异较大,具有较大的外部差异。通过迭代过程,聚类算法将数据样本分配到最合适的簇中,使得簇内的相似性最大化,并且簇与簇之间的相似性最小化。这样,我们可以获得一组具有相似特征的簇,从而实现数据的自动分类。
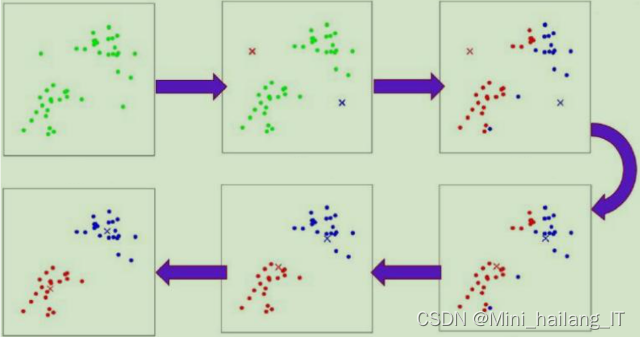
基于文本长度的聚类是一种利用文本样本的长度特征进行分类的方法。它通过度量文本的字符数、词数或句子数等长度度量来衡量文本的相似性和差异性,并将具有相似长度的文本样本放在同一簇中。这种方法在文本分类任务中可以帮助发现长度在类别区分中起重要作用的模式和差异。然而,仅仅依靠文本长度可能会忽略文本内容的语义信息,因此结合其他文本特征,如词频或词向量,可以提高聚类的准确性和解释性。

模型训练
整体系统的工作环境包括7台联想M4500型号电脑设备,每台设备配备了Intel酷睿i3-4170 3.7GHz双核处理器和4GB的内存空间。这些设备通过一定网速的交换机设备连接在一起。

设计了一种新方案,将K-means和支持向量机(SVM)整合在一起,以实现对样本集规模的控制,并在保证精度的基础上高效地控制整体的学习耗时。此外,方案还引入了增量学习的概念,使这两种技术能够高效地结合起来,在减少综合学习耗时的同时,通过增量学习活动持续提升整体学习精度。这样的整合方案在时间和精度两个方面都能够实现显著的提升。
该方案的核心思想是使用K-means算法对大规模样本集进行聚类,从而减少样本数目。K-means将样本集划分为较小的簇,每个簇代表一个样本子集。然后,对每个簇应用SVM进行分类,由于样本数目减少,SVM的训练和预测时间大大缩短,从而提高了学习的效率。
同时,方案中引入了增量学习的概念,即在已有模型的基础上,通过接收新样本并进行部分更新来持续提升学习精度。增量学习可以避免重新训练整个模型,只需对新样本进行增量训练,节省了时间和计算资源。
相关代码示例:
from sklearn.cluster import KMeans
# 假设有一个样本集 X
# 设置聚类簇的数量
k = 10
# 创建K-means模型并进行聚类
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
# 获取聚类结果,每个样本的类别标签
clusters = kmeans.labels_
from sklearn.svm import SVC
# 基于每个簇训练SVM模型
svm_models = []
for i in range(k):
# 获取属于当前簇的样本子集
cluster_samples = X[clusters == i]
# 创建SVM模型并进行训练
svm_model = SVC()
svm_model.fit(cluster_samples, y)
# 将训练好的模型添加到列表中
svm_models.append(svm_model)
# 针对每个新样本进行增量学习
for i in range(len(X_new)):
new_sample = X_new[i]
new_label = y_new[i]
# 找到最近的簇中心
nearest_cluster = kmeans.predict([new_sample])[0]
# 对应簇的SVM模型进行增量学习
svm_models[nearest_cluster].partial_fit([new_sample], [new_label])
更多帮助
本文转载自: https://blog.csdn.net/ASASASASASASAB/article/details/136141359
版权归原作者 Mini_hailang_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 Mini_hailang_IT 所有, 如有侵权,请联系我们删除。