
1. 打开浏览器
首先来到安装 chrome浏览器 的文件夹下,例:C:\Users\01\AppData\Local\Google\Chrome\Application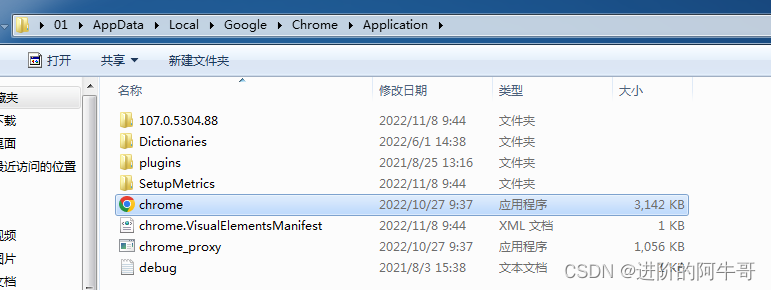
在此界面打开 cmd窗口,
然后输入:chrome.exe --remote-debugging-port=9527 --user-data-dir=“F:\selenium\AutomationProfile” ,并回车。
这句代码的意思是启动 chrome浏览器 的调试模式,
user-data-dirr=“F:\selenium\AutomationProfile” 是在单独的配置文件中启动 chrome浏览器,可以理解为 新的浏览器,记得创建对应文件夹哦;
其中 9527 为端口号,可自行指定。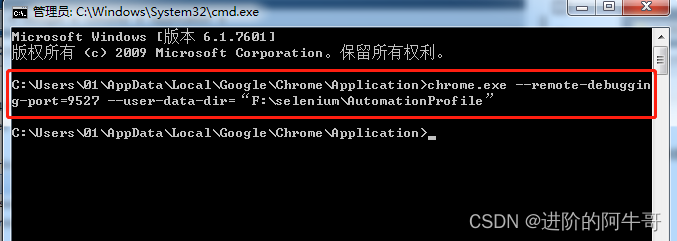
此时候,如果无误的话就可以看到桌面新打开了一个 chrome 浏览器了。
那接下来就是去控制这个 手动打开的 chrome浏览器 啦。
2. 编写 Python程序获取控制 浏览器
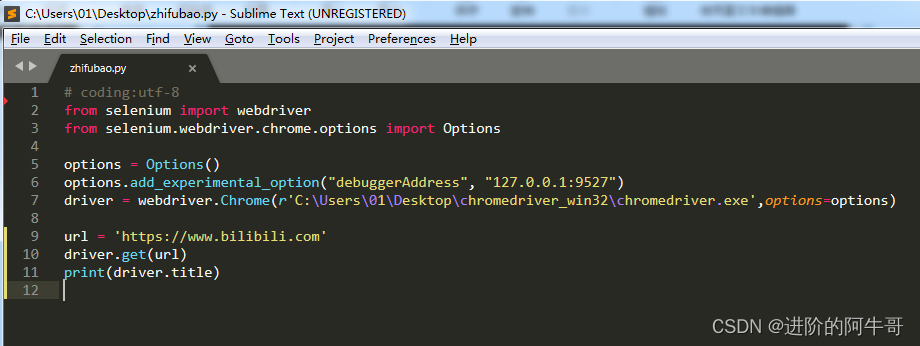
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
driver = webdriver.Chrome(r'C:\Users\01\Desktop\chromedriver_win32\chromedriver.exe',options=options)
url = 'https://www.bilibili.com'
driver.get(url)
print(driver.title)
代码运行后,可以看到如下:浏览器访问了哔哩哔哩,并获取 当前页面的 title 。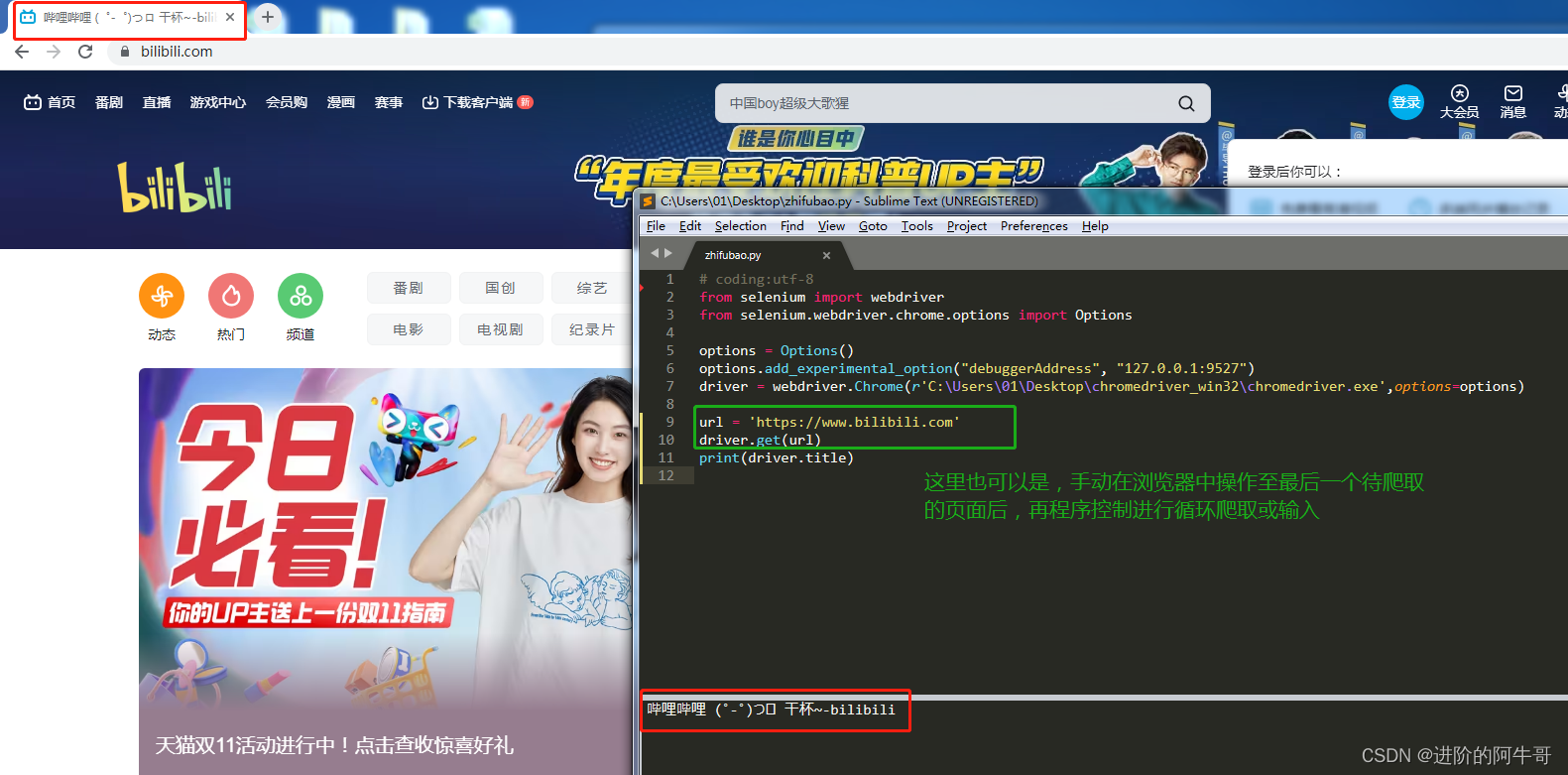
特别的:也可以是手动在浏览器中操作至我们待爬取的目标页面后,再程序控制进行循环爬取或输入。也就是省略掉用程序控制浏览器后一步一步点至目标页面。
备注:收藏中有参考文章。
本文转载自: https://blog.csdn.net/weixin_49167820/article/details/127747637
版权归原作者 进阶的阿牛哥 所有, 如有侵权,请联系我们删除。
版权归原作者 进阶的阿牛哥 所有, 如有侵权,请联系我们删除。