
Python3.6.9 Flink 1.15.2消费Kafaka Topic
PyFlink基础应用之kafka
通过PyFlink作业处理Kafka数据
1 环境准备
1.1 启动kafka
(1)启动zookeeper
zkServer.sh start
(2)启动kafka
cd /usr/local/kafka/
nohup ./bin/kafka-server-start.sh ./config/server.properties >> /tmp/kafkaoutput.log 2>&1&
或者
./bin/kafka-server-start.sh -daemon ./config/server0.properties
(3)查看进程如下
jps
10101 QuorumPeerMain
11047 Kafka
(4)kafka tools配置
C:\Windows\System32\drivers\etc\hosts
(5)查看日志文件
/tmp/kafkaoutput.log或者/usr/local/kafka/logs
(6)创建Topic主题
bin/kafka-topics.sh --create--zookeeper localhost:2181 -replication-factor 1--partitions1--topic flink_kafakasource
(7)查看当前创建的Topic
bin/kafka-topics.sh --list--zookeeper localhost:2181
(8)查看kafka版本
kafka_2.12-2.2.0.jar
可以看出scala的版本是2.12,kafka的版本是2.2.0
1.2 启动Flink
(1)启动flink
start-cluster.sh
(2)查看是否启用成功
jps
4704 TaskManagerRunner
4443 StandaloneSessionClusterEntrypoint
(3)关闭Flink
stop-cluster.sh
1.3 安装PyFlink
PyFlink需要特定的Python版本,Python 3.6, 3.7, 3.8 or 3.9。
1.3.1 python3和pip3的配置
一、系统中安装了多个版本的python3。
编译安装python时
其中–prefix选项是配置安装的路径,
若是不配置该选项,安装后可执行文件默认放在/usr/local/bin,
库文件默认放在/usr/local/lib,
配置文件默认放在/usr/local/etc,
其它的资源文件放在/usr /local/share,比较凌乱。
/usr/local/bin/python3.6m
/usr/local/bin/python3.6m-config
/usr/include/python3.6m
/usr/local/bin/python3.6
/usr/local/bin/python3.6-config
/usr/local/lib/python3.6
/usr/local/bin/python3.10
/usr/local/bin/python3.10-config
/usr/local/lib/python3.10
二、环境变量path作用顺序
#echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/jdk1.8.0_144/bin:/root/bin:/home/data/java/bin:/home/data/java/jre/bin
按照顺序进行显示
三、安装Pyflink
ln-s 源文件 目标文件
ln-s /usr/local/bin/python3.6 /usr/local/bin/python3
ln-s /usr/local/bin/pip3.6 /usr/local/bin/pip3
/usr/local/bin/python3.6 -m pip install--upgrade pip
pip3 install apache-flink==1.15.3 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
包文件安装后的位置
/usr/local/lib/python3.6/site-packages
1.3.2 配置Flink Kafka连接
(1)在https://mvnrepository.com/里输入flink kafka寻找对应版本的连接器。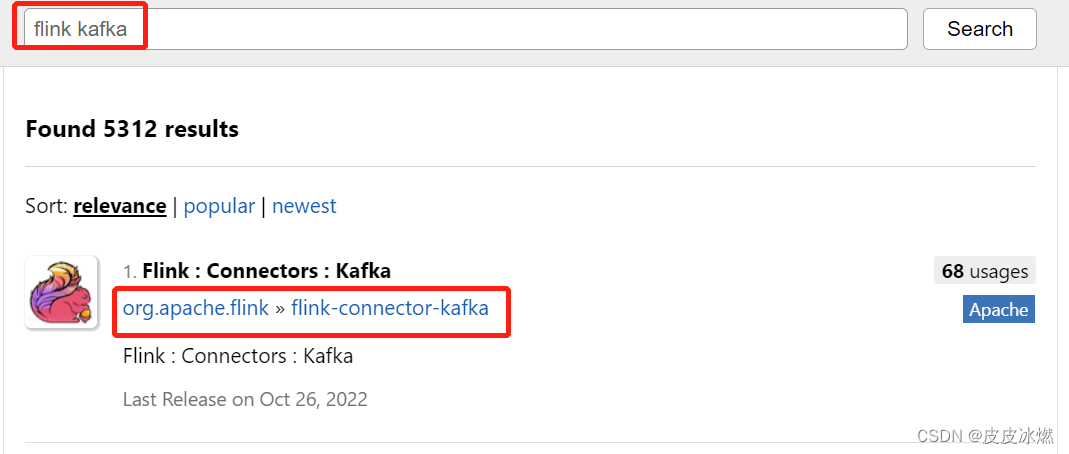
(2)选择Flink对应的版本1.15.3,点击jar。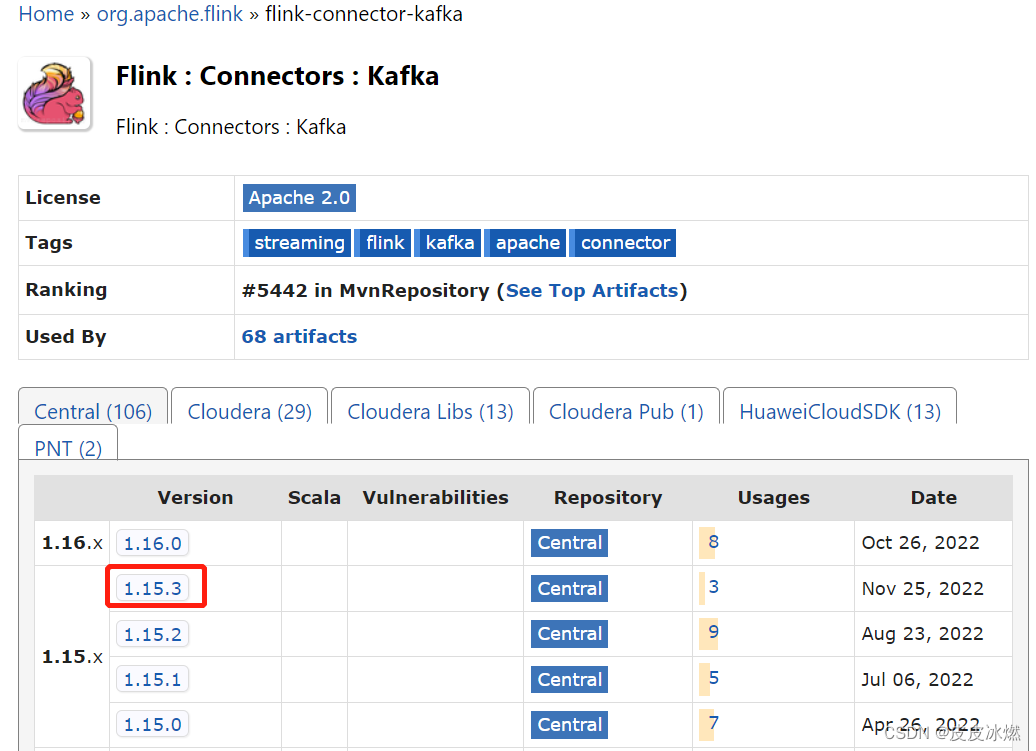
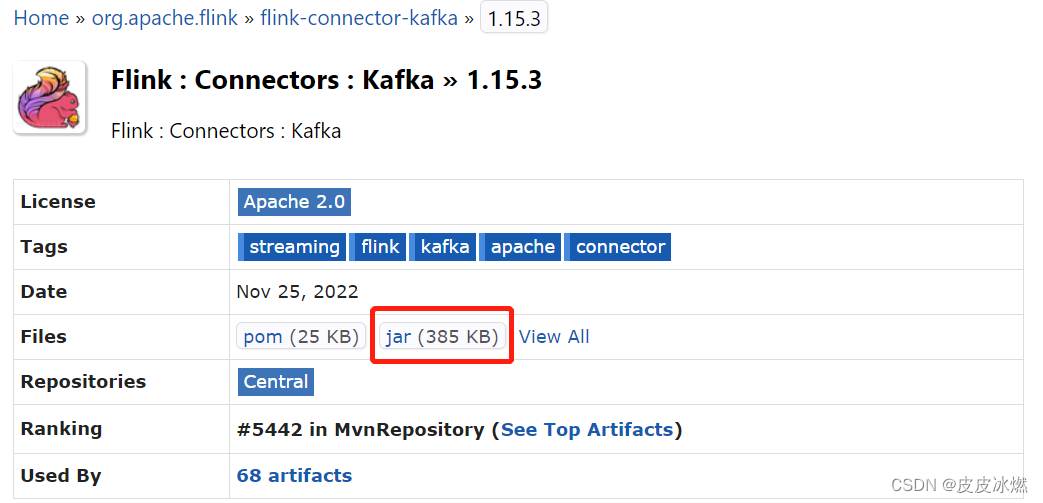
(3)分别下载flink-connector-base和kafka-clients对应的jar包。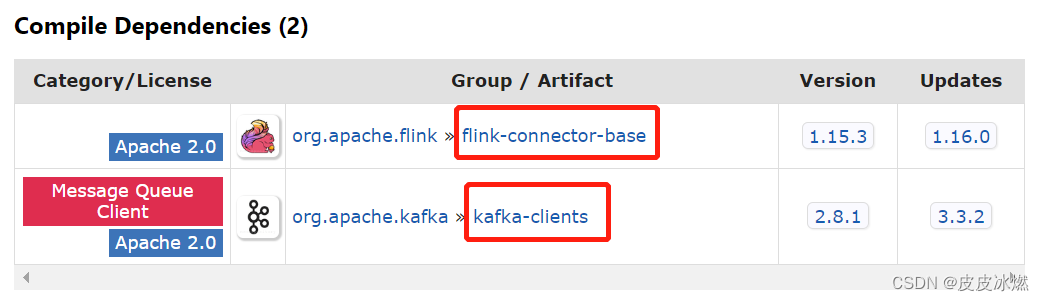
(4)将该jar包放置在python的lib目录下
/usr/local/lib/python3.6/dist-packages/pyflink/lib。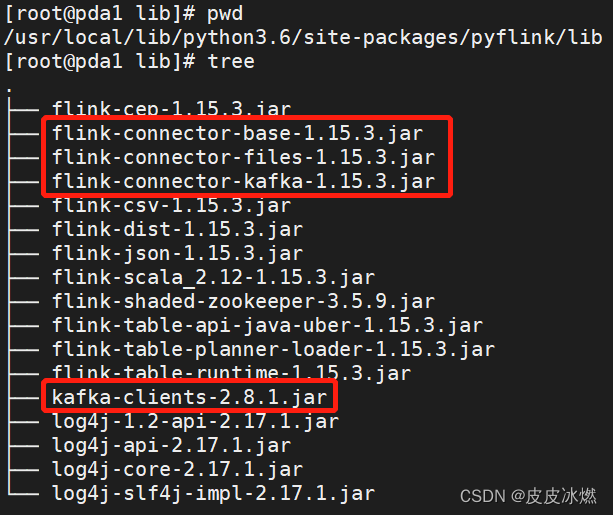
(5)将该jar包放置在Flink的lib目录下
拷贝三个jar包到FLINK_HOME/lib下。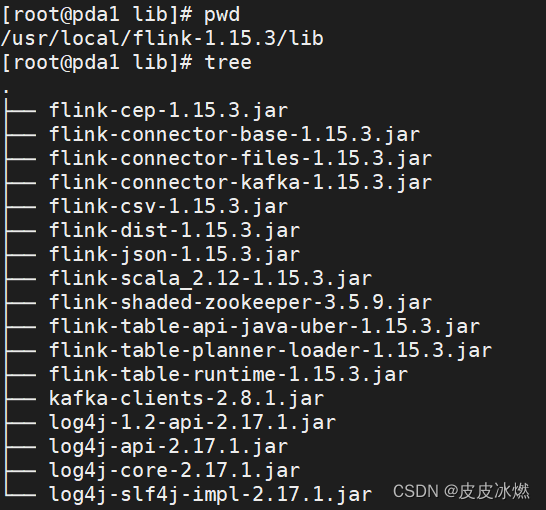
2 消费kafka写入本地文件
2.1 flinkDemo.py
本应用采用pyflink+sql方式编写代码。
# -*- coding: UTF-8 -*-
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment, TableConfig, DataTypes, CsvTableSink, WriteMode, SqlDialect
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(1)
s_env.enable_checkpointing(3000)
st_env = StreamTableEnvironment.create(s_env)# , TableConfig())
st_env.use_catalog("default_catalog")
st_env.use_database("default_database")
sourceKafkaDdl ="""
create table sourceKafka(id int,name varchar
)
with('connector'='kafka',
'topic'='flink_kafakasource',
'properties.bootstrap.servers'='192.168.43.48:9092',
'scan.startup.mode'='latest-offset',
'format'='json')"""
st_env.execute_sql(sourceKafkaDdl)
fieldNames =["id", "name"]
fieldTypes =[DataTypes.INT(), DataTypes.STRING()]
csvSink = CsvTableSink(fieldNames, fieldTypes, "/tmp/result.csv", ",", 1, WriteMode.OVERWRITE)
st_env.register_table_sink("csvTableSink", csvSink)
st_env.execute_sql("""
INSERT INTO csvTableSink
select * from sourceKafka
""").wait()
2.2 执行方式
2.2.1 方式一:直接IDEA中运行
无需安装flink。
(1)安装pyflink
pip3 install apache-flink==1.15.3
(2)配置pycharm的flink环境:
首先最重要的是版本问题,这里给出我的相关版本配置
kafka:2.2.0
jdk:1.8.0_201
apache-flink: 1.15.3
相应的jar包版本。
flink-connector-base-1.15.3.jar
flink-connector-kafka-1.15.3.jar
kafka-clients-2.8.1.jar
将jar包放入External Libraries下的site-packages下的pyflink下的lib中。
(3)运行
python3 flinkDemo.py
2.2.2 方式二:命令行提交到Flink
/usr/local/flink-1.15.3/bin/flink run -py flinkDemo.py
或
/usr/local/flink-1.15.3/bin/flink run --python flinkDemo.py
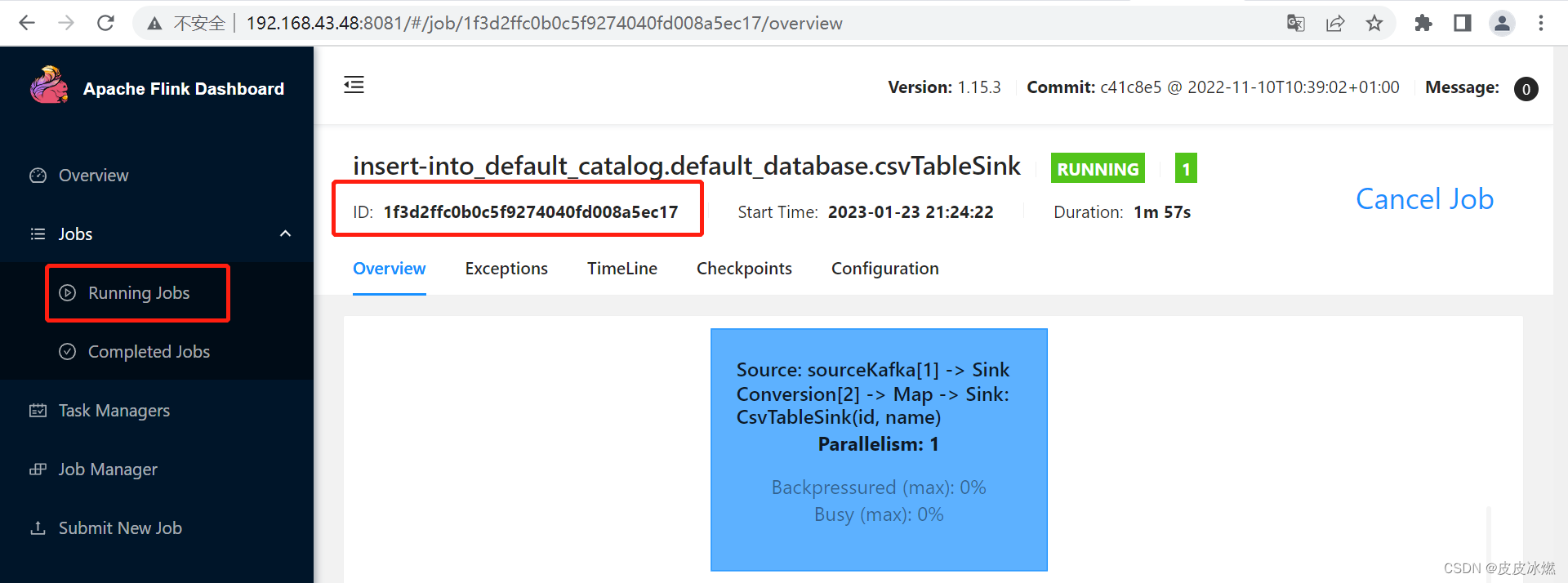
显示如下:
Job has been submitted with JobID 1f3d2ffc0b0c5f9274040fd008a5ec17
2.3 模拟数据
打开kafka生产者,通过客户端生产数据。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic flink_kafakasource
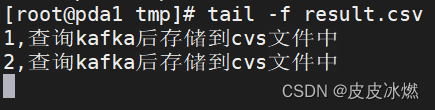
{"id":2,"name":"查询kafka后存储到cvs文件中"}
2.4 查看Flink侧结果
3 消费kafka写入kafka
直接本地IDEA中运行即可。
# -*- coding: UTF-8 -*-
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment, TableConfig, DataTypes, CsvTableSink, WriteMode, SqlDialect
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(1)
s_env.enable_checkpointing(3000)
st_env = StreamTableEnvironment.create(s_env)# , TableConfig())
st_env.use_catalog("default_catalog")
st_env.use_database("default_database")
sourceKafkaDdl ="""
create table sourceKafka(id int,name varchar
)
with('connector'='kafka',
'topic'='flink_kafakasource',
'properties.bootstrap.servers'='192.168.43.48:9092',
'scan.startup.mode'='latest-offset',
'format'='json')"""
sinkKafkaDdl ="""
create table sinkKafka(id int,name varchar
)
with('connector'='kafka',
'topic'='result',
'properties.bootstrap.servers'='192.168.43.48:9092',
'scan.startup.mode'='latest-offset',
'format'='json')"""
st_env.execute_sql(sourceKafkaDdl)
st_env.execute_sql(sinkKafkaDdl)
st_env.execute_sql("""
INSERT INTO sinkKafka
select * from sourceKafka
""").wait()
标签:
flink
本文转载自: https://blog.csdn.net/qq_20466211/article/details/128751674
版权归原作者 皮皮冰燃 所有, 如有侵权,请联系我们删除。
版权归原作者 皮皮冰燃 所有, 如有侵权,请联系我们删除。