
Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
8.1.🐶闭包引用的原理
1. 闭包引用的概念
- 算子函数中引用了一个算子外部的变量 , 这个变量就是闭包变量 ;
- 这些引用会随着任务的序列化而被发送到各个 Executor 上,并在 Executor 上被反序列化。
- 闭包变量定义在Driver端 ,使用在任务实例端 , 变量需要序列化
2. 闭包引用的副本
- 在 Executor 上执行的任务中的闭包对象是完全独立的。
- 修改任务中的闭包对象不会影响到 Driver 端的原对象,因为它们是独立的副本。
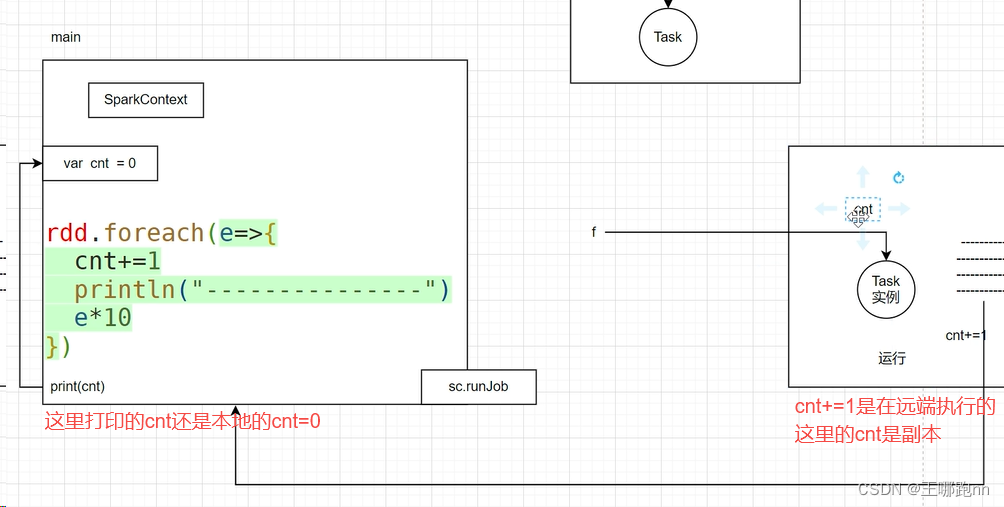
3. 🧀实例代码1
对于在 RDD 算子函数中引用的外部对象,其修改仅影响到任务执行所在的 Executor 上的局部副本,而不会影响到 Driver 端的原对象。
package com.doit.day0217
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/19
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test06 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 1)
var cnt=0 // cnt,在Driver端的jvm中
rdd.foreach(x=>{
cnt+=1 // 此处的cnt是在worker端反序列化出的Task中,与driver端已无联系
println(x)
})
println(cnt) // 此处打印的是driver端的cnt,依然是0
// 关闭SparkContext对象
sc.stop()
}
}
4. 🧀实例代码2
Spark 的转换操作是惰性求值的,只有在调用结果算子(如
foreach
、
count
、
collect
等)时才会触发实际的作业执行。
因此
cnt
的取值为调用结果算子之前的值
package com.doit.day0217
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/19
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test07 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 1)
var cnt=0 // cnt,在Driver端的jvm中
//算子中函数在远端执行
//函数中引用的遍历 闭包引用,将闭包变量复制一个副本发送到远端,你对闭包变量的所有操作操作的是副本
val rdd1 = rdd.map(x => {
cnt += 1 // 只有在调用结果算子时,才会runjob,所以这里取进来的cnt为10
println("-----" + cnt)
x*10
})
cnt=10
println(cnt) // 此处打印的是driver端的cnt,依然是0
rdd1.foreach(println)
// 关闭SparkContext对象
sc.stop()
}
}

8.2 闭包引用的应用场景
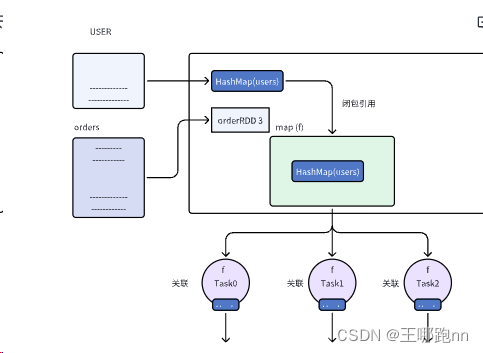
可以使用闭包引用避免****shuffle
在我们之前讲解join算子的案例中,需要将两个数据集进行连接,通常会触发 shuffle 操作,这会带来一定的性能开销。

我们可以将user数据集转换成hashmap,通过闭包引用传入进去,此时可以避免shuffle
package com.doit.day0217
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.io.Source
/**
* 示例代码:演示了如何使用闭包变量避免shuffle
*/
object Test08 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 加载用户数据,将其转换为Map
val user = Source.fromFile("data/join/user.txt")
val userMap: Map[String, String] = user.getLines().map(line => {
val arr = line.split(",")
(arr(0), arr(1))
}).toMap // 将用户数据转换为Map,存储在内存中 一般数据集控制大小为1G以内
// 加载订单数据
val orders = sc.textFile("data/join/orders.txt")
// 使用闭包变量userMap避免shuffle,将用户名直接关联到订单数据中
val rdd2 = orders.map(iter => {
val arr2 = iter.split(",")
val name = userMap.getOrElse(arr2(4), "unknown") // 使用闭包变量userMap关联订单数据中的用户ID
(arr2(0), arr2(1), arr2(2), arr2(3), arr2(4), name)
})
// 打印处理后的订单数据
rdd2.foreach(println)
// 关闭SparkContext对象
sc.stop()
}
}

如果需要让每个task都用有一份“只读”的“小量”数据,比如一个字典,则可以利用闭包引用;
如果共享的这分只读数据比较大,则应该使用“广播变量”效率更高!
🍠Source.fromFile
和
sc.textFile
的辨析
**1. 使用 ****
Source.fromFile
**** 读取数据:**
- 何时使用:- 当数据量较小,可以完全装载到内存中并进行处理时,适合使用
Source.fromFile方法读取数据。例如,对于文件大小在几十兆到几百兆之间的数据集,可以考虑使用该方法。- 特点:- 将文件内容一次性读取到内存中,适合对数据进行全量处理。- 读取的数据直接转换为内存中的集合类型(如Map),方便进行后续处理。- 注意事项:- 对于较大的数据集,可能会导致内存溢出,因此在处理大规模数据时需要谨慎使用。
**2. 使用 ****
sc.textFile
**** 读取数据:**
- 何时使用:- 当数据量较大,无法一次性装载到内存中进行处理时,应该使用 Spark 的
sc.textFile方法读取数据。例如,对于几百兆到几十亿的大型数据集,应该使用该方法。 - 特点:- Spark 的
sc.textFile方法将文件分布式地加载到集群中的各个节点上,并返回一个分布式数据集(RDD)。- 可以有效地处理大规模数据,具有良好的扩展性和性能。 - 使用方式:- 使用
sc.textFile方法加载文件后,可以使用各种 Spark 的转换操作对数据进行处理,如 map、filter、reduceByKey 等。 - 注意事项:- 使用
sc.textFile方法加载的数据集是分布式的,无法直接转换为集合类型,因此需要结合 Spark 的各种操作进行处理。
8.3 🐶闭包引用的注意事项
1.🥙序列化检查
闭包引用的对象,必须实现序列化接口,否则会导致task序列化失败,从而快速报错
class Per extends Serializable {
val id:Int = 0
}
val p = new Per()
val rd = sc.makeRDD(1 to 10, 2)
// 闭包引用的对象,必须实现序列化接口
rd.map((_,p)).foreach(println)
2. 🥙“副本”数量
如果闭包引用的是普通对象,则每个task中都有一份“copy”
如果闭包引用的是一个object对象(单例对象),则其实在整个executor中只有一份,如下
Yarn :resourcemanager nodemanager
Nodemanager 提供计算资源 : container对资源的隔离
object Per extends Serializable {
val id:Int = 0
}
val p = Per
val rd = sc.makeRDD(1 to 10, 2)
rd.map((_,p)).foreach(println)
如果使用闭包引用object对象,有可能产生线程安全问题(因为有多个task线程共享这个对象);
看似闭包,实非闭包
下面的代码,其实并不是“闭包引用”
当然,里面用到了自定义类型,也还是要注意序列化问题
class Phone(var brand: String, var price: Double)
val resRdd = rdd.map(tp => {
new Phone(tp._1, tp._2) // 这里并没有引用外部的对象,所以不存在f序列化检查失败的问题 })
//.map(phone => (phone.brand, phone.price))
//.reduceByKey(_ + _) // 这里有shuffle,但shuffle写出的是 2元组,它能序列化,所以不会报错
.groupBy(p=>p.brand) // 这里有shuffle,而且shuffle写出phone对象,它不能序列化,所以报错
.mapValues(_.size)
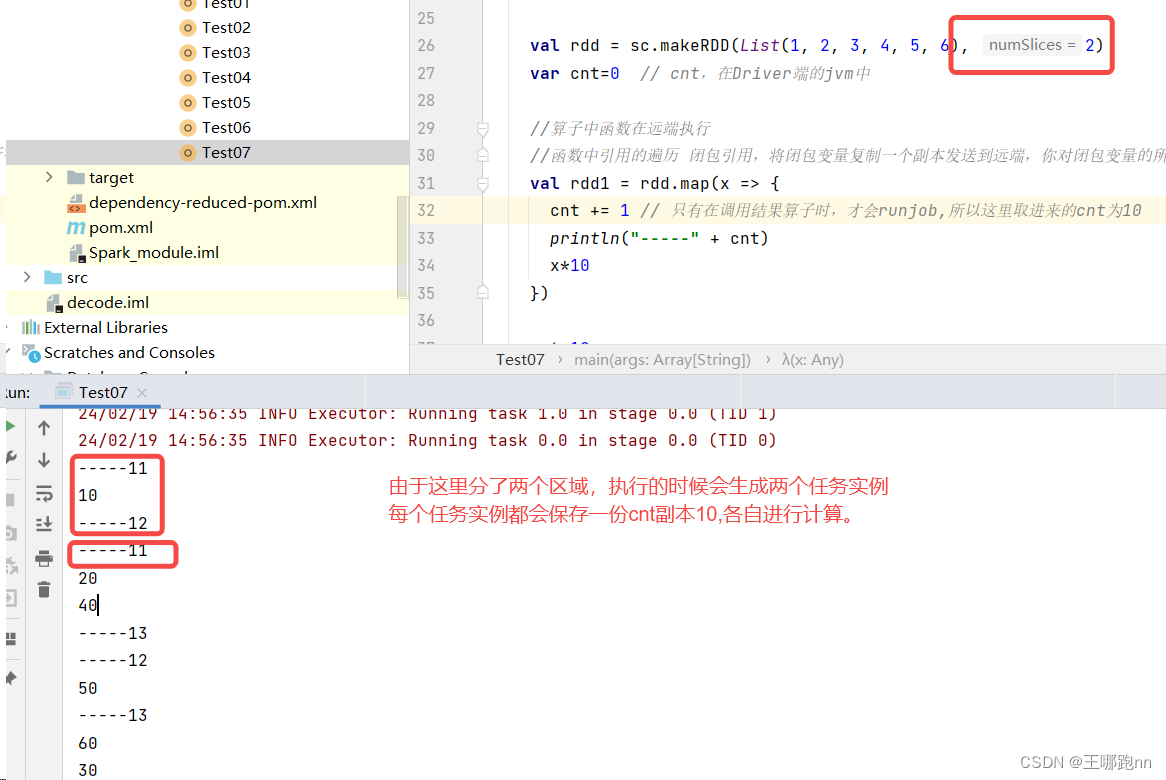
8.4 🐶闭包变量的问题
- 每个任务实例中都会保存一份完整的闭包变量
- 如果一条节点同时运行当前任务的多个任务实例 , 存储多份闭包变量数据
package com.doit.day0217
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/19
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test07 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
var cnt=0 // cnt,在Driver端的jvm中
//算子中函数在远端执行
//函数中引用的遍历 闭包引用,将闭包变量复制一个副本发送到远端,你对闭包变量的所有操作操作的是副本
val rdd1 = rdd.map(x => {
cnt += 1 // 只有在调用结果算子时,才会runjob,所以这里取进来的cnt为10
println("-----" + cnt)
x*10
})
cnt=10
println(cnt) // 此处打印的是driver端的cnt,依然是0
rdd1.foreach(println)
// 关闭SparkContext对象
sc.stop()
}
}
解决方案: 运行当前任务的节点只存一份数据

🥙BT传输协议:基本原理
BitTorrent(简称BT)是一种用于大规模文件分享的通信协议。它被广泛用于分发大型文件和数据集,例如软件、电影、音乐等。BitTorrent协议的主要原理是将文件分成小块,并且允许用户同时上传和下载这些文件块,从而实现高效的分发。
以下是BitTorrent协议的主要特点和工作原理:
- 分布式架构:1. BitTorrent是一种分布式协议,没有单一的中心服务器,所有参与者都可以直接交换文件块。2. 参与者之间通过Tracker服务器或者DHT网络(分布式哈希表)进行通信,用于发现其他参与者并交换文件块的信息。
- 分块下载:1. 将文件分成固定大小的块(一般为256KB或512KB)。2. 下载者可以选择下载文件的哪些块,而不是整个文件,从而实现灵活的下载策略。
- 种子文件:1. 种子文件(Torrent文件)包含了文件的元数据信息,包括文件名、大小、哈希值等。2. 种子文件可以通过文件共享网站或者其他方式进行传播,从而让其他用户获取文件的元数据信息并加入下载。
- 优化的上传下载策略:1. BitTorrent协议实现了一种基于位掩码的上传下载策略,优先下载缺失的文件块,并且优先上传稀缺的文件块,从而提高下载速度和整体的网络效率。
- 健壮性和自我修复:1. BitTorrent协议具有较强的健壮性,即使某些参与者离线或者退出下载,其他参与者仍然可以通过其他方式获取丢失的文件块。2. 通过校验和哈希校验值,BitTorrent协议可以检测到下载的文件块是否损坏或者被篡改,并且自动请求重新下载。
- Tracker服务器和DHT网络:1. Tracker服务器用于管理下载者和上传者的信息,帮助下载者找到可用的上传者。2. DHT网络是一种分布式哈希表,允许下载者通过哈希值查询其他下载者的IP地址和端口信息,从而实现去中心化的Peer发现。

版权归原作者 王哪跑nn 所有, 如有侵权,请联系我们删除。