
一.引言
Flink 使用 kafka 作为 Sink,大部分时间运行正常,偶发报错显示 Kafka Producer 发送消息超过 kafka 设置的最大请求即 max.request.size,下面分析排查并解决该问题:
org.apache.flink.streaming.connectors.kafka.FlinkKafkaException: Failed to send data to Kafka: The message is 1143824 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.

二.问题排查与分析
1.报错原因
报错原因很清晰,kafka produce 发送的消息超出了最大的请求大小,即下发大小超出了配置中 max.request.size 的大小,这里报错内记录大小 1143824 bytes = 1.09 mb

kafka 的默认 max.request.size 限制为 1m,故单条消息过大导致下发失败。


2.报错源码
2.1 FlinkKafkaProducer.invoke
Flink 使用类 org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer 完成 kafka produce,invoke 负责执行每条 record 的写入逻辑,其中最后调用 transaction.producer 调用 send 完成数据的发送:
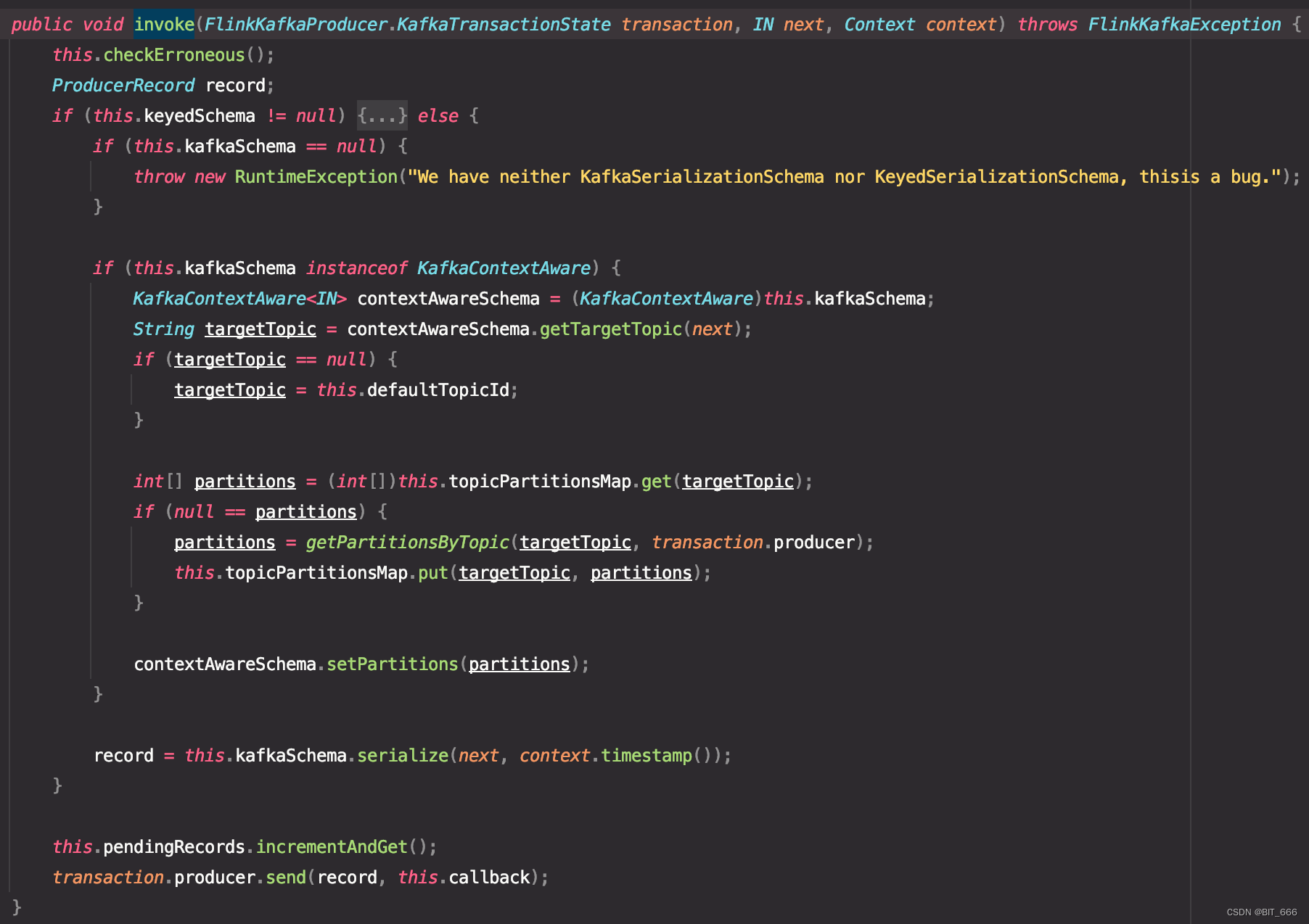
这里 transaction.producer 对应 FlinkKafkaInternalProducer 底层继承了 org.apache.kafka.clients.producer. KafkaProducer<K, V> 所以底层调用还是基于 kafkaClien:

2.2 KafkaProducer.send
由于调用了 Producer.send(record, callback),所以对应 KafkaProducer 内该函数:

其内部继续调用 doSend 执行下发逻辑,这里函数篇幅较大,我们主要关注 ensureValidRecordSize 方法,该方法负责检查 recode 的 Size 合法性:
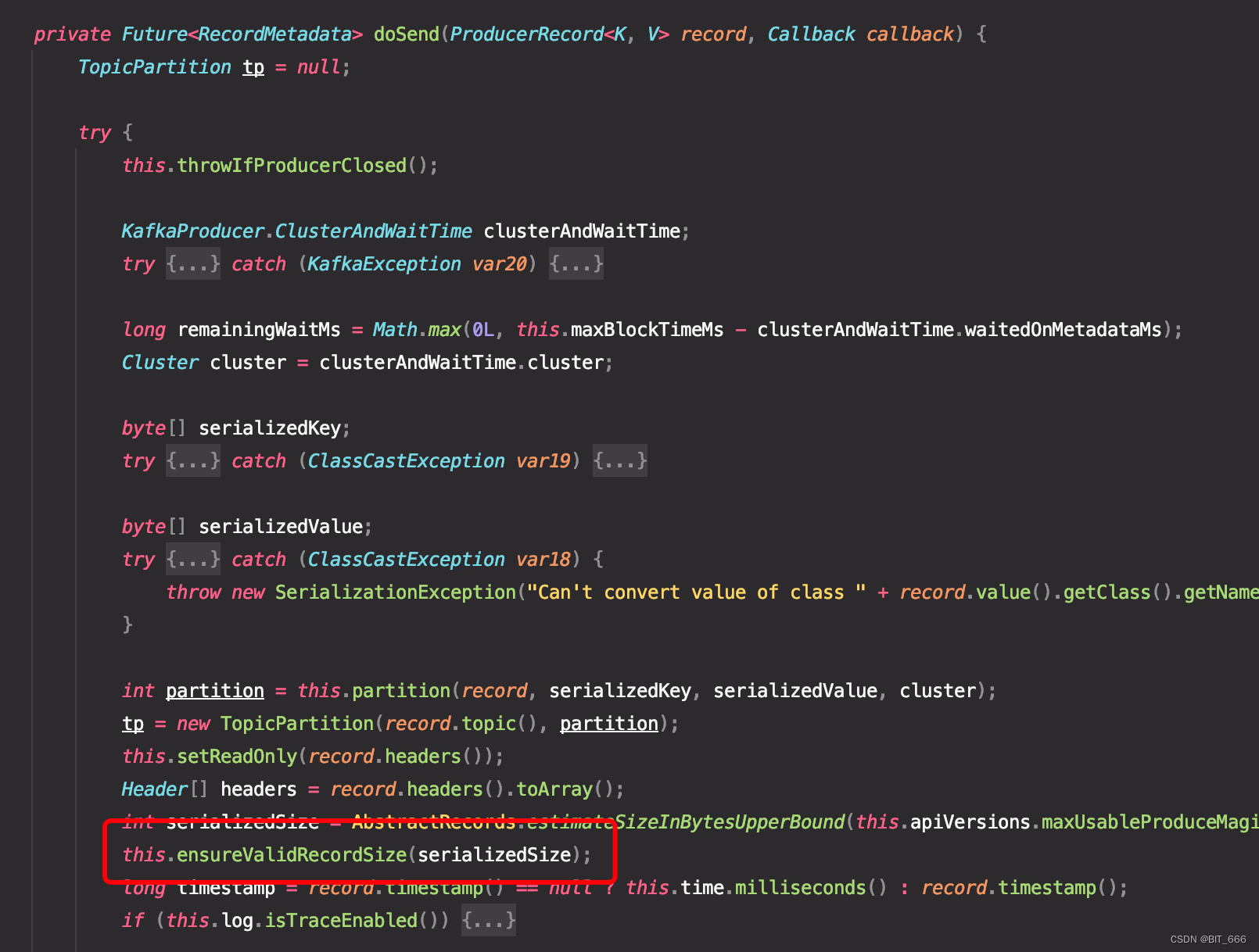
这里 Record Size 的估算采用如下算法:
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound
(this.apiVersions.maxUsableProduceMagic(), this.compressionType, serializedKey,
serializedValue, headers);
2.3 ensureValidRecordSize

该方法参数为 serializedSize,分别判断是否超过 max.request.size 和 buffer.memory:
- max.request.size 单次请求最大值
超过该值 Throw Exception larger than the maximum request size
- buffer.memory 缓冲池大小
超过该值 Throw Exception larger than the total memory buffer
所以我们调用 KafkaProducer 执行 doSend 时发送的数据大小需要小于 max.request.size 与 buffer.memory ,否则都会引起 Exception。
2.4 kafkaProducer 下发流程
这里简单分析下 KafkaProducer 的下发流程,首先明确常用的四个参数:
batch.size:每个Batch的大小,Batch 数值越高系统的吞吐量越大,但是延迟也会相应提高,默认 16384 bytes,即 16 KB
buffer.memory: buffer-memory 是生产者消息存放内存的大小,默认 33554432 bytes,即 32 MB
max.request.size:最大请求 size,默认 1048576 Bytes,即 1 MB
linger.ms:发送延迟,如果数据未达到 batch.size 但到达 linger.ms 也会发送,默认 0ms
buffer.memory 可以看作是客户端本地的内存缓存,负责存储 Batch,通过 Sender 线程发送,如果大小太小会导致 Sender 来不及把 Request 发送到 KafkaClient,会造成内存缓冲很快被写满,写满后会阻塞用户线程。假设一条数据到来:
A.首先判断是否超过 max.request.size 和 buffer.memory
B.满足条件进入 Batch 中继续处理,不满足条件抛出异常程序退出
C.Batch 达到 batch.size 或者达到 linger.ms 设置的延迟时间,唤醒 Sender 线程,开始发送

Tips:
batchIsFull 代表达到 batch,size,执行发送逻辑,newBatchCreated 代表新的 Batch 创建,则执行发送逻辑,不管上一个 Batch 是否已满,这里业务逻辑需要集合自己的写入压力和写入大小决定上面几个参数的配置,如果要发送大文件,建议提高 buffer.memory 和 batch.size,但是单条最好不要超过 max.request.size,因为单条数据过大对下游消费者的压力也比较大,其次性能与延迟的均衡来源于 linger.ms 参数,时效性要求高调低该参数,保证一定吞吐量,提高该参数。
3.报错分析
上面分析了报错相关的代码与参数,下面结合实际场景看一下为什么数据超出了 1 MB,正常情况下任务运行稳定,每条日志包含一个 Timewindow(5s) 的日志信息,序列化后大概几十 K,所以查看源头 Kafka 是否存在流量异常的情况:
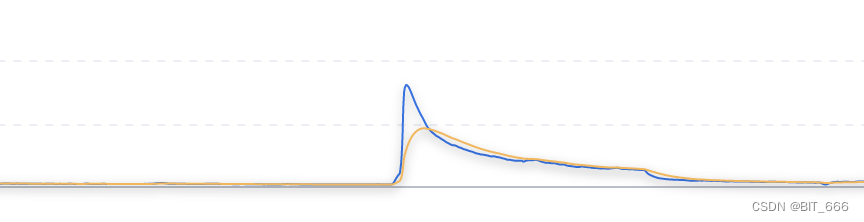
查看对应源头 kafka 的数据流量,果然在报错阶段流量异常,比平常翻了几百倍,导致日志过大超出限制。
三.问题解决
1.调整 max.request.size
the maximum request size you have configured with the max.request.size configuration
既然超出了 max.request.size,提高该 size 即可,这里将 kafka 配置的 max.request.size 提高一倍由 1M 增加至 2M:
// kafka下发限制由1m提升至2m
propertiesForSink.put("max.request.size","2097152");
但是一般该参数受 Kafka 集群客户端的配置影响,所以需要和负责客户端的同学确认集群下该参数的配置,如果代码内设置而集群默认仍未 1MB,则上述 2 MB 配置不生效,其次如果集群参数配置同步修改,还需重启客户端。
2.减少 Record Size
我们手机 TimeWindow 的日志,如上流量图,短期高流量日志导致 TimeWindow 内数据量激增从而导致 Record 大小过大,一种是减少 TimeWindow 的时间范围,但是治标不治本,如果还有更高峰值 QPS 写入日志还会超出 max.request.size,所以把日志进行拆分,参照 batch 的做法,将单条大数据 (> max.request.size) 拆分为多个小 batch(< max.request.size)。
版权归原作者 BIT_666 所有, 如有侵权,请联系我们删除。