
我的个人博客主页:如果’'真能转义1️⃣说1️⃣的博客主页
(1)关于Python基本语法学习---->可以参考我的这篇博客《我在VScode学Python》
(2)pip是必须的在我们学习python这门语言的过程中Python ---->> PiP 的重要性
Python urllib 库是用于操作网页 URL,并对网页的内容进行抓取处理。
利用 urllib 库获取网络资源
urllib是Python的一个模块,提供了一系列用于处理URL的模块。它可以用于发送HTTP请求
、处理cookie以及处理web sockets等任务。
url是什么
URL(外文名:Uniform Resource Locator,中文名:统一资源定位符),统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。它最初是由蒂姆·伯纳斯·李发明用来作为万维网的地址。
主要包含的模块:
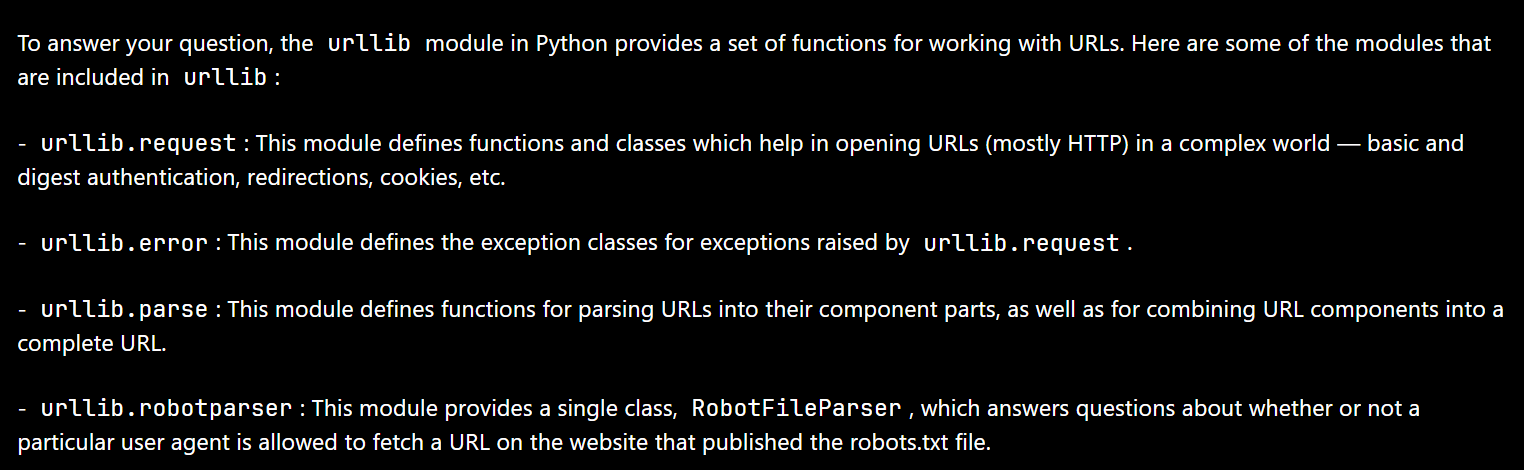
- urllib.request(请求模块):该模块定义了帮助在复杂世界中打开URL(主要是HTTP)的函数和类——基本和摘要身份验证、重定向、cookie等。
- urllib.error(异常处理模块):该模块定义了由urllib.request引发的异常类。
- urllib.parse(url解析模块):该模块定义了将URL解析为其组成部分的函数,以及将URL组件组合成完整URL的函数。
- urllib.robotparser(robots.txt解析模块):该模块提供了一个单一的类RobotFileParser,用于回答特定用户代理是否被允许在发布robots.txt文件的网站上获取URL。
【1】urllib.request(请求模块) —> 用于打开 URL 的可扩展库
(1)urllib.request.urlopen
urllib.request.urlopen()函数的主要工作是打开指定的URL并检索响应。
函数原型
urlopen() 方法不仅支持 HTTP 协议,还支持其他常见的协议,
- 如 FTP、SMTP 和 HTTPS。
- Telnet
- File / URL
urllib.request.urlopen(url, data=None,[timeout,]*, cafile=None, capath=None, cadefault=False, context=None)
- url:要打开的URL。
- data:这是一个可选参数,用于指定要发送到服务器的数据。
如果不提供此参数,则请求将是GET请求。如果提供了它,则请求将是POST请求。
- timeout:这是一个可选参数,用于指定请求的超时时间(以秒为单位)。
如果服务器在此时间内没有响应,则会引发timeout异常。
- cafile:这是一个可选参数,用于指定包含用于SSL验证的CA证书的文件的路径。
- capath:这是一个可选参数,用于指定包含用于SSL验证的CA证书的目录的路径。
- cadefault:这是一个可选参数,用于指定是否使用系统的默认CA证书进行SSL验证。
- context:这是一个可选参数,用于指定用于请求的SSL上下文。
例子:
import urllib.request
response = urllib.request.urlopen('**你的网站**')
html = response.read()print(html)
urllib.request.urlopen 函数用于打开 URL 你需要了解的网站。
然后,使用 read 方法将 URL 的内容读入变量 html 中。(方法获取的响应页面的返回值。打开的 URL 中读取内容并返回字节字符串(bytes)。)
最后,使用 print 函数将 html 的内容打印到控制台。
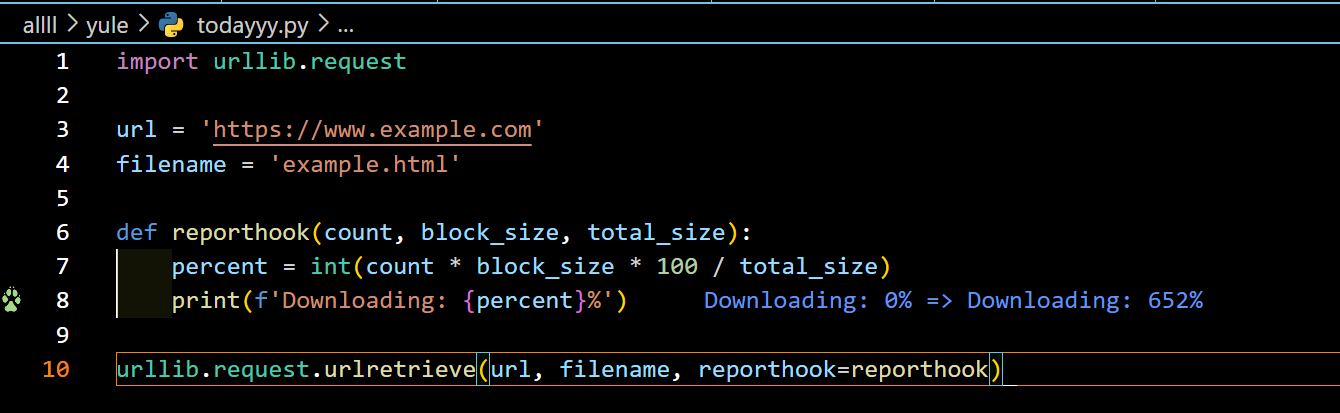
(2)urllib.request.urlretrieve —>该函数检索指定URL的内容并将其保存到本地文件中。
urllib.request.urlretrieve(url,[filename=None,]reporthook=None, data=None)
- url:要检索的URL。
- filename:要将内容保存到的本地文件名。如果未指定,则该函数将尝试从URL中猜测文件名并将其保存到当前工作目录中。
- reporthook:可选参数,用于指定一个回调函数,该函数将在检索过程中被调用以显示进度信息。
例子
如果传递了一个文件名参数,并且URL指向本地资源,则结果是从本地文件复制到新文件。
urllib.request.urlretrieve函数返回一个元组,其中包含新创建的数据文件的路径以及生成的HTTPMessage对象。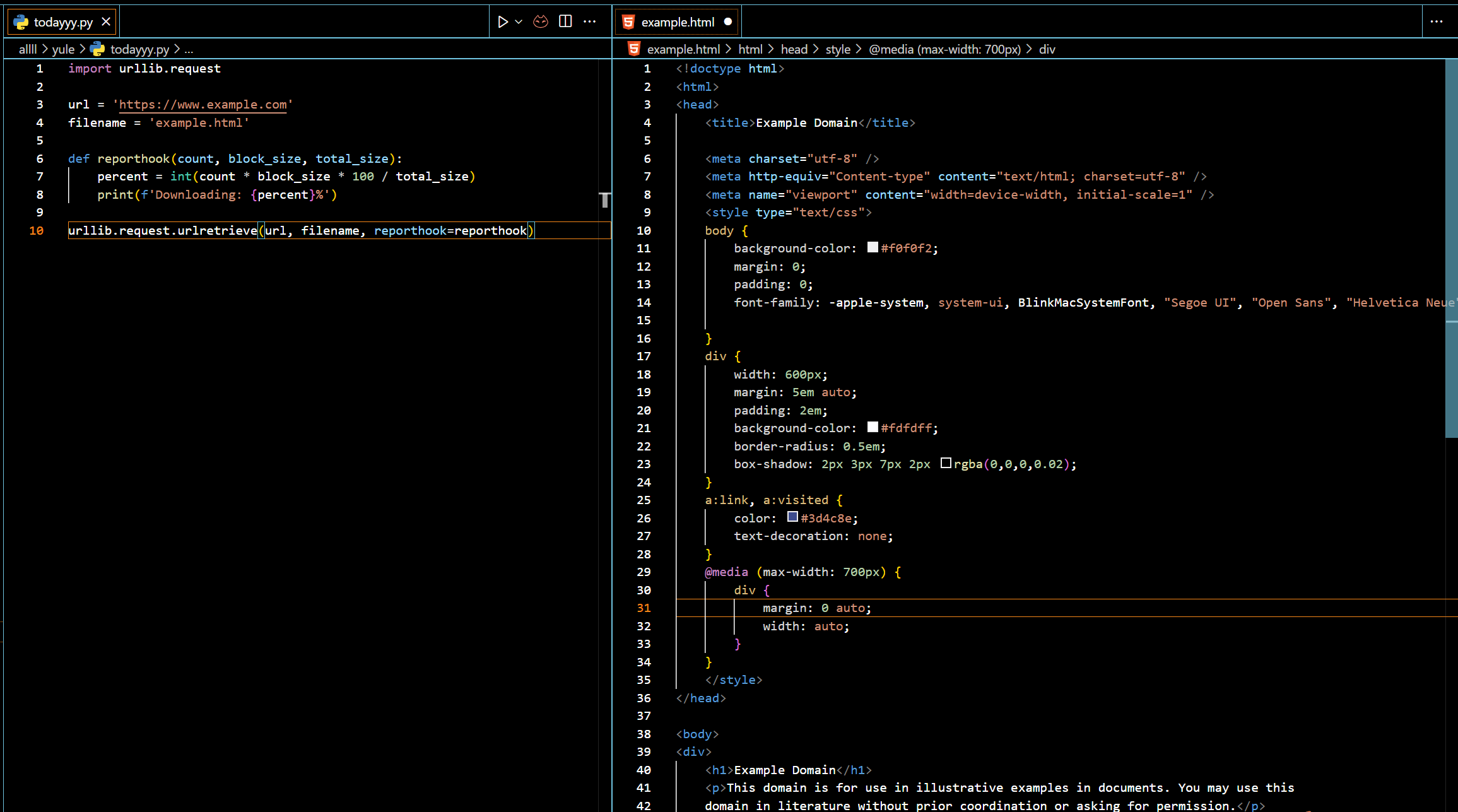
【2】- urllib.error(异常处理模块):该模块定义了由urllib.request引发的异常类。
urllib.error.URLError(reason, *args):
这是所有在URL处理期间发生的异常的基类。当无法打开或检索URL时,会引发此异常。reason参数是一个字符串,用于描述错误的原因。args参数是一个元组,包含其他与错误相关的信息。
urllib.error.HTTPError(url, code, msg, hdrs, fp):
这是URLError的子类,当发生HTTP错误时引发。它包含有关HTTP错误代码和原因的信息。url参数是引发错误的URL,code参数是HTTP错误代码,msg参数是HTTP错误原因短语,hdrs参数是HTTP响应头,fp参数是一个文件对象,用于读取错误响应的主体。
urllib.error.ContentTooShortError(msg, content)
: 这是URLError的子类,当下载的内容比预期的短时引发。msg参数是一个字符串,用于描述错误的原因。content参数是一个字节串,包含下载的内容。
# 导入urllib.error模块:import urllib.error
【3】urllib.parse(url解析模块):该模块定义了将URL解析为其组成部分的函数,以及将URL组件组合成完整URL的函数。
- urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
-> ParseResult: 将URL解析为其组件,并返回一个包含解析结果的ParseResult对象。
- urllib.parse.urlunparse(components)
-> str: 接受URL组件的元组并返回完整的URL字符串。
- urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
-> str: 接受查询参数的字典并返回URL编码的字符串。
- urllib.parse.parse_qs(qs, keep_blank_values=False, strict_parsing=False, encoding='utf-8', errors='replace', max_num_fields=None)
-> Dict[str, Union[str, List[str]]]: 接受URL编码的查询字符串并返回查询参数的字典。
【4】 urllib.robotparser(robots.txt解析模块):该模块提供了一个单一的类RobotFileParser,用于回答特定用户代理是否被允许在发布robots.txt文件的网站上获取URL。
- urllib.robotparser.RobotFileParser(url=''):
创建一个新的RobotFileParser对象,该对象可以解析指定URL的robots.txt文件。
- urllib.robotparser.set_url(url):
设置要解析的robots.txt文件的URL。
- urllib.robotparser.read():
从指定的URL读取robots.txt文件并解析其内容。
- urllib.robotparser.can_fetch(useragent, url):
检查指定的用户代理是否可以访问指定的URL。如果可以,返回True;否则返回False。
- urllib.robotparser.mtime():
返回上次读取robots.txt文件的时间戳。
- urllib.robotparser.modified():
返回robots.txt文件是否已被修改。
利用 urllib 库获取网络资源
当然获取想要的网络资源才是我们学习这篇文章的第一要义。
可以参考的的这篇博客:爬虫想要的HTML
版权归原作者 如果'\'真能转义1️⃣说1️⃣ 所有, 如有侵权,请联系我们删除。