
美团到店平台技术部/质量工程部与复旦大学周扬帆教授团队开展了科研合作,基于业务实际场景,自主研发了多模态UI交互意图识别模型以及配套的UI交互框架。
本文从大前端质量保障领域的痛点出发,介绍了UI交互意图识别的方法设计与实现。基于UI交互意图编写的测试用例在实际业务中展现出了可以跨端、跨App的泛化能力,希望可以为从事相关工作的同学带来一些启发或帮助。
- 背景
- UI交互介绍- 2.1 UI模块与交互意图- 2.2 当下痛点与启示- 2.3 研究目标- 2.4 效果预期
- 架构设计- 3.1 技术思路- 3.2 当前进展与效果Demo- 3.3 实现难点
- 4 实现方式探索- 4.1 交互意图识别需求- 4.2 模型的输入- 4.3 双阶段UI交互意图理解- 4.4 实验结论
- 5 实际落地探索
- 6 总结
- 7 展望
- 招聘信息
1. 背景
近年来,随着美团多种业务线的扩充和迭代,UI测试的任务愈发繁重。针对UI测试中人工成本过高的问题,美团到店测试团队开发了视觉自动化工具以进行UI界面的静态回归检查。然而,对于UI交互功能逻辑的检验仍强依赖于脚本测试,其无法满足对于进一步效率、覆盖面提升的强烈需求。主要难点体现在两方面:
- 前端技术栈多样,不同页面的实现方式各异,这导致不同页面中功能相似的UI模块的组件树差异很多,基于规则的测试脚本也就很难具备泛化能力,生产、维护的成本非常高。
- UI样式繁多,同样的功能模块可能在视觉上有很大差异,这为基于CV方法实现自动化驱动带来了困难。
考虑上述两个难点,美团到店平台技术部/质量工程部与复旦大学计算机科学技术学院周扬帆教授团队展开了“基于UI交互理解的智能化异常检测方法”的科研合作,利用多模态模型对用户可见文本、视觉图像内容和UI组件树中的属性进行融合,实现了对于UI交互意图[1]的准确识别。该工作对于大前端UI的质量保障等多个领域都具有可借鉴的意义,介绍该工作的论文[2]已被ESEC/FSE 2023(软件领域CCF A类推荐会议)接收,并将于12月6日在其工业届轨(Industry track)公开发布、推介。
2. UI交互介绍
| 2.1 UI模块与交互意图
移动应用由“页面”组成,不同页面中的不同“模块”为用户提供着不同的功能。用户在浏览页面时,根据以往使用经验以及当前页面中的图像、文字、页面结构等信息,可快速理解页面当中不同【模块】所想要提供的【功能】,以及通过该功能用户能够达到的【目的】。这些被用户认为能够提供特定功能并达到预期目的的页面模块,我们将其命名为一个【交互意图簇】。
以下图中的页面为例,不同模块通常对应不同的交互意图类型划分。比如商品详情区域,我们可以得知此模块主要是向我们展示当前商品最主要的信息,起展示作用;而顾客信息区域,需要用户进行点击或输入个人信息,用以补全整个订单所需要的信息;同时页面当中也会存在各类功能按钮,通过按钮的 位置 、文本信息、图标等信息,用户也可以大致推断出操作后会得到怎样的结果。由此,我们可以将UI交互意图定义为「用户通过当前UI展示推断出来的不同模块的概念及交互功能」。
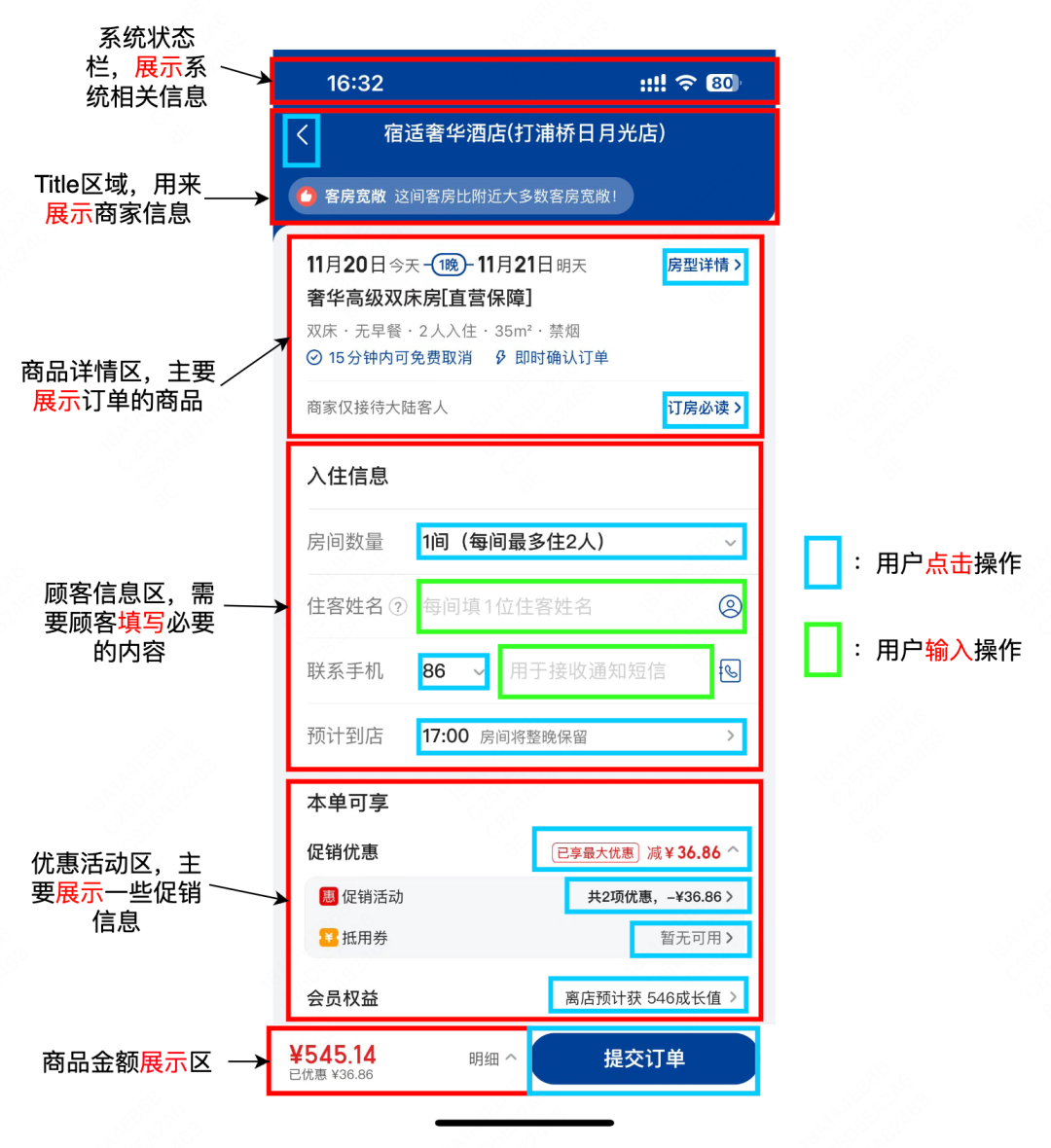
图1 模块的概念及交互功能样例
| 2.2 当下痛点与启示
对于复杂的UI交互场景,如提交订单页,测试人员需要对不同模块制定较复杂的测试流程、测试规则,同时编写及维护复杂的自动化测试逻辑。以美团内的App测试场景为例,许多不同的页面有着相似的功能模块,这些功能模块尽管表象不同,但对于一般用户来说,交互意图明确且相似,没有理解困难。如:

图2 相似的功能模块
| 2.3 研究目标
本课题期望结合多种机器学习方法,通过机器获取与人工认知一致的“交互意图”,从而利用该信息模拟测试人员对客户端产品进行“理解-操作-检查”的测试验证流程。如人工操作一般,我们希望该能力能够以一个与一般用户类似的逻辑来操作、检查相似的功能,同时兼容不同的技术栈、App、业务领域,无需特定适配。就像一个用户在美团上能够订酒店,在没有使用过的点评或者美团小程序上也同样能完成预订酒店的流程。
从能力目标视角来看,UI交互意图识别的定位是完成一般用户的交互概念到页面实体的映射。由人直接进该映射的准确率最高、泛化性最好,典型的场景就是手工测试,即人观测页面后操作、检查。人能在不同的设计、程序实现形式下实现下找到目标操作实体(例如各种各样的提交按钮、商品卡片)。当前的自动化脚本测试提高了效率,但由于映射的泛化性较差,往往需为每个页面做单独的适配。
此外,业内尝试了诸如CV页面目标检测等方法,但在鲁棒性、泛化性、使用成本等方面上仍不太令人满意。本研究旨在利用深度学习和多模态信息,通过少量标注数据,尽可能提升交互意图识别的映射能力,使其接近人的识别、认知水平。
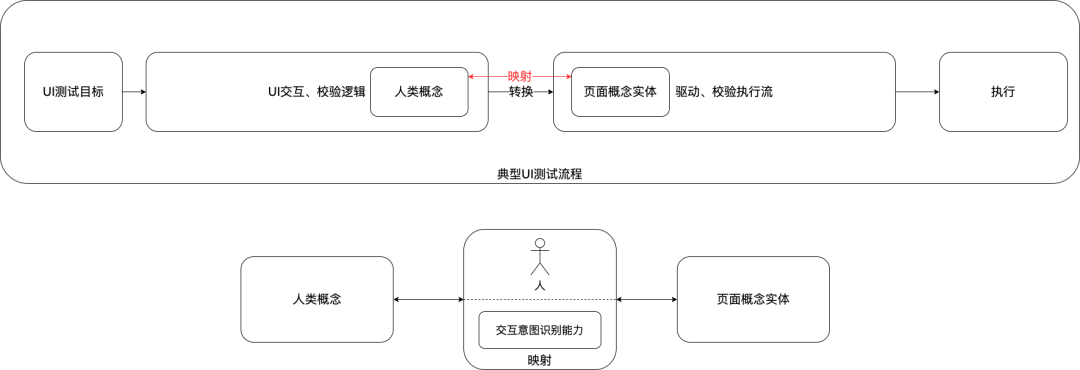
图3 UI交互意图理解的能力目标
| 2.4 效果预期
本研究提供一种UI交互意图理解的通用能力,能够在测试核心流程“理解-操作-检查”各个环节应用。
- 识别页面模块交互意图:通过页面UI交互意图识别来模拟测试人员的认知
- 测试行为的注入:利用UI交互意图识别结果信息,将操作逻辑程序化
- 测试结果检查:利用UI交互意图识别结果信息进行页面状态通用化校验
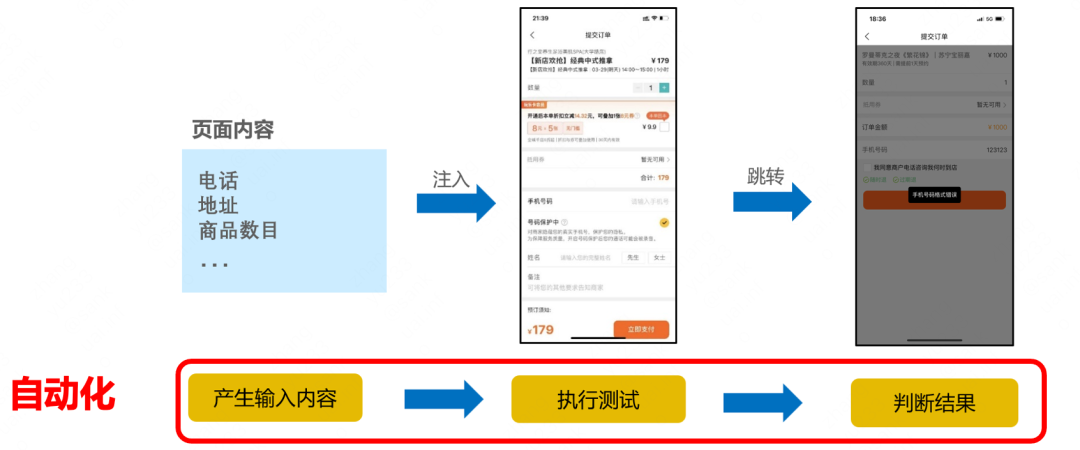
图4 核心流程“理解-操作-检查”
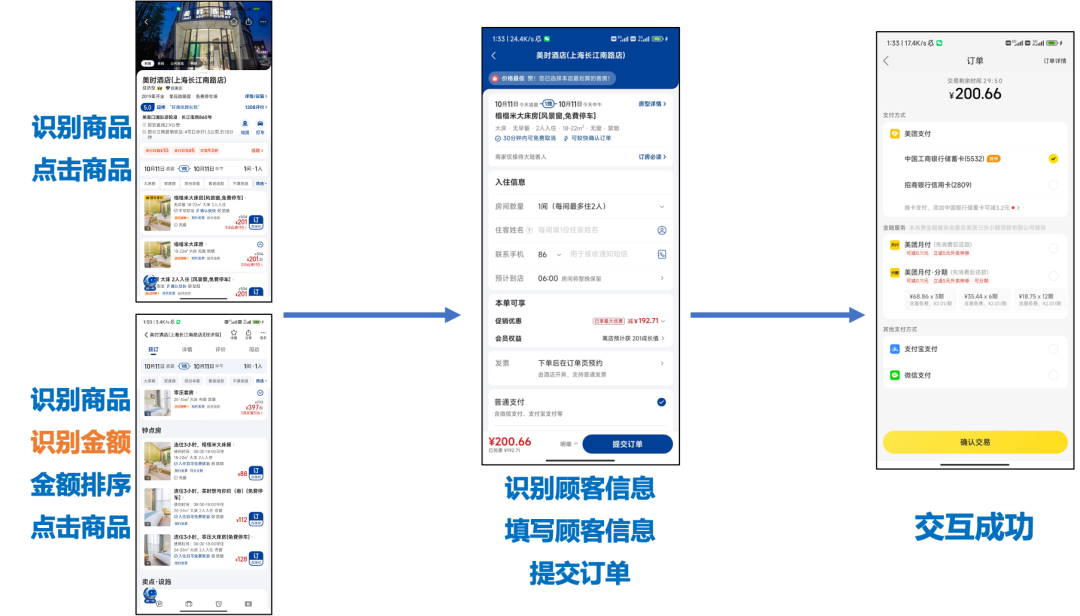
图5 预期效果示例
3. 架构设计
| 3.1 技术思路
考虑到UI交互意图理解是一种页面理解的通用能力,需要结合业务场景产生实际效果,我们决定首先将其应用于智能化UI交互,探索交互意图理解的能力范畴以及落地效果验证。后续会将该能力扩展到智能化测试逻辑检查、智能化遍历测试、测试知识标准化管理以及推荐等其它大前端测试领域应用。
为了验证技术方向的可行性,本课题先限定在某个垂直业务领域(订单/表单)进行探索,确认实际使用效果,再将方法推广泛化到其他领域。
具体来说,本项目的技术方案分为两个部分:
- UI交互意图理解:基于深度学习方法对交易流程中表单/订单场景进行目标UI交互意图簇识别划分。
- 智能化测试用例驱动:定义测试用例目标,基于表单/订单等场景中的UI交互意图簇编写交互逻辑,在跨App、跨技术栈、跨业务的场景下尝试复用执行。
| 3.2 当前进展与效果Demo
本项目目前已经实现了一套通用UI交互意图理解方法,利用UI交互意图在一些场景下编写的智能化测试用例可以在不同UI页面、不同技术栈,甚至不同App之间复用。下面是一个使用UI交互意图编写的“下单首个商品”测试用例的交互意图和其泛化能力的效果展示:
交互流程:识别第一个商品、点击购买进入提交订单页、填写顾客信息、提交订单。
App效果展示:
美团App下单购买列表内首个商品-视频
| 3.3 实现难点
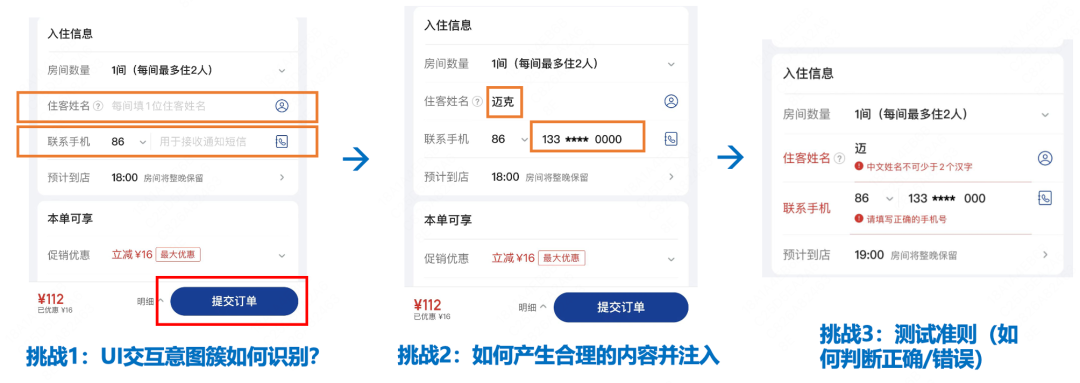
图6 测试过程中存在的挑战
如何让机器学习到一般用户的认知概念,自动分析获取到预先定义的UI交互意图是本课题中最大的难点。
4 实现方式探索
针对上述难点,本课题从真实的业务需求出发,首先梳理了需要识别的交互意图类别。随后,对交互意图类别进行了分析,先后进行了多种方法的尝试,通过定量实验对不同设计进行了效果比对,最终选取了先分类,再聚类的落地方案:先以渲染树元素为最小单位进行交互意图类型的分类,然后在不同的交互意图维度进行元素聚类,生成对应的交互意图簇。
| 4.1 交互意图识别需求
深入挖掘业务需求后,我们发现:UI交互意图并不是一维的,在不同场景、不同需求下会有不同的分类标准。具体来说,如果关注所属业务类别,可以将交互意图簇分为:商品信息、评价和发票等;当关注用户的操作方式时,又需要将可交互的组件分为:点击、键入、长按三类。例如,对于“点击进入第一个商品详情页”这样一个交互意图:模型需要从业务层找到“商品信息”,在商品信息簇中找到操作层的可“点击”的UI组件(“商品信息”和“点击”的交集),然后执行点击操作。
此外,由于本工作的初步实验场景为具有大量计算逻辑和信息输入的表单页,因此我们又增加了计算层和表单层两个特有的维度。例如,对于“购买最便宜的商品”这样的交互意图,其细分为“找出最便宜的商品”和“订单填写”两个串行子意图。具体来说,模型需要首先在商品列表页找出业务层“商品信息”和计算层“金额统计信息”的交集并排序,随后点击最便宜的商品进入提交订单页。在提交订单页中,模型需要在业务层的“顾客信息”和表单层的“信息输入”中找出共有的元素,并根据这些元素生成对应的文本输入信息,从而完成“订单填写”的子意图。
由此,我们利用上述四个维度将新的分类标准确定为16个不互斥的类别。

四个维度的预期分类结果分别如下图所示:

图7 多层次预期识别结果
| 4.2 模型的输入
为了实现UI交互意图理解这个目标,我们推测,与一般用户的理解方式类似,基于多种信息的综合考虑能够提升整体效果,因此选择了三种模态的页面信息:图像信息(来源于页面截图)、渲染树信息和文本信息。
例如,针对元素 【“普通支付”按钮】,可获得的关键信息有以下三种:
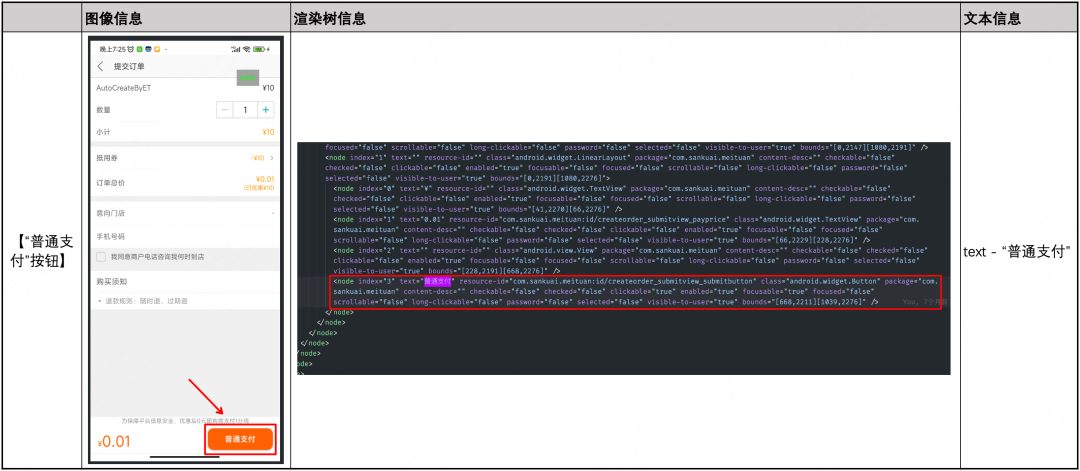
图8 多模态信息示例
| 4.3 双阶段UI交互意图理解
分析输入数据可知:三种信息输入中只有“渲染树”带有明确的边界,但其与“交互意图”概念在粒度上有显著差异。因此,本研究考虑采用先分类,再聚类的思路:先以渲染树元素为最小单位进行交互意图类型的分类,然后在不同的交互意图维度进行元素聚类,生成对应的交互意图簇。
具体来说:
- 在分类时,利用自注意力机制进行特征提取,实现在判断当前元素类别时会参考其它元素信息的目标。
- 在元素聚类的过程中,利用有监督的聚类方法将分类后的渲染树元素在不同交互意图维度进行聚合,得到簇划分结果。
4.3.1 UI组件分类模型
由于渲染树反映的是最细粒度的UI组件,因此对渲染树中组件进行分类的最大难点是信息缺失:订单页中的数字有可能是金额、商品数量、顾客人数,此类情况仅依据当前渲染树节点无法区分。因此,本研究借鉴了NLP领域的经验,利用自注意力机制进行特征提取,实现在判断当前元素类别时会参考其它元素的信息的目标。
分类模型结构如下图所示,我们利用Vision Transformer预训练模型提取图像特征,使用中文bert预训练模型提取文本特征,同时把渲染树元素属性进行特征提取后输入模型,综合判断元素类别:
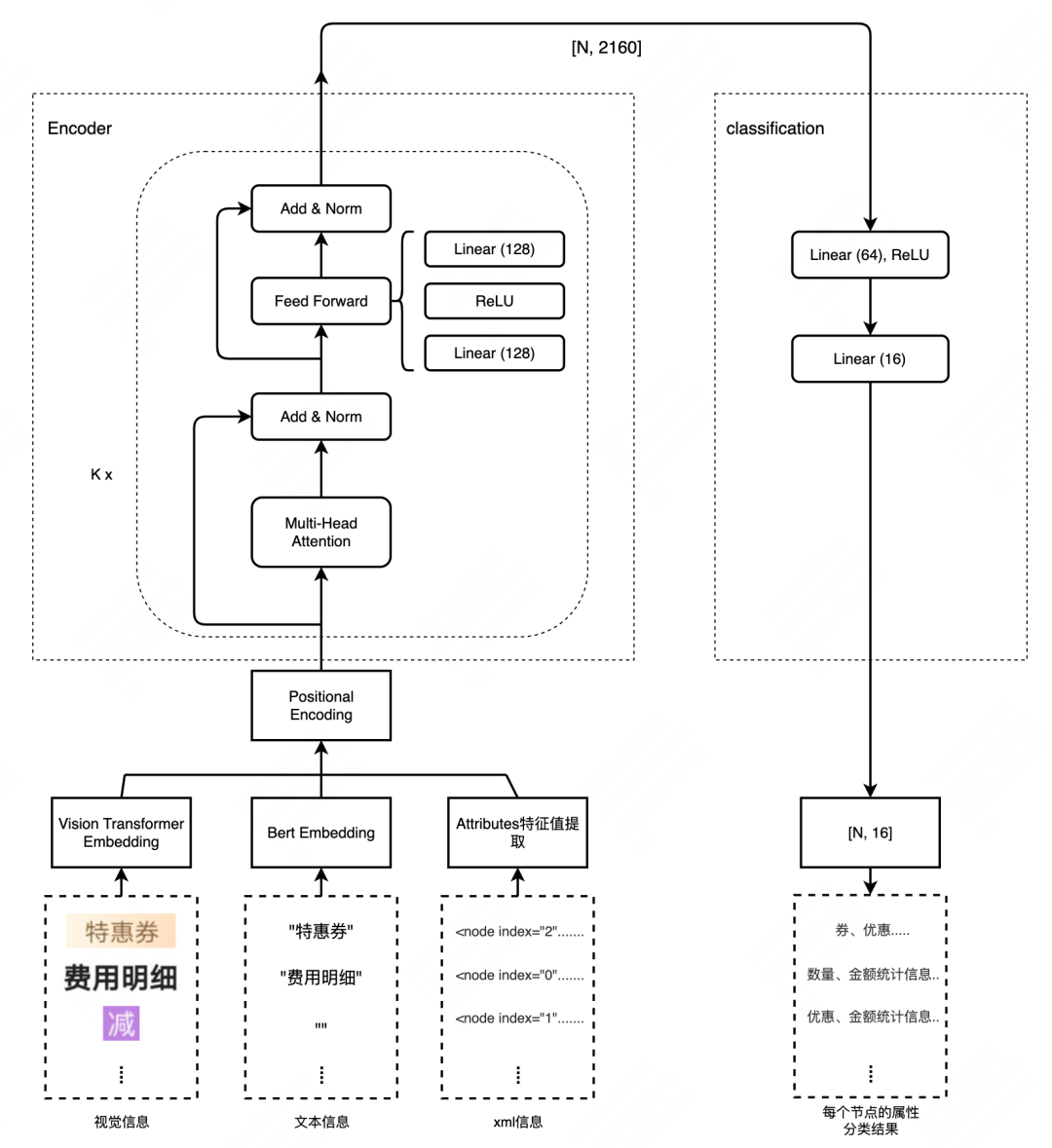
图9 模型结构
为了探究三种关键信息(渲染树、视觉图像信息、用户可见文本)的有效性以及三者之间的关系(是否相互补充),我们将不同关键信息作为模型的输入类型进行了消融实验,训练了7种不同的自注意力分类模型。此外,考虑到在UI领域很多实践使用CV目标检测能力实现类似工作,为了对比此类目标检测模型和自注意力模型在当前问题上的效果差异,本研究以YOLOv7模型为代表,定量评估了其在UI组件分类上的效果。
实验时,本研究从美团App上的四种业务线(酒店、KTV、密室、门票)中随机截取了158个提交订单页面,进行人工标注后,将其中的123个页面作为训练集,其余为测试集。在测试集上,各个维度的F1 Score[3]如下:
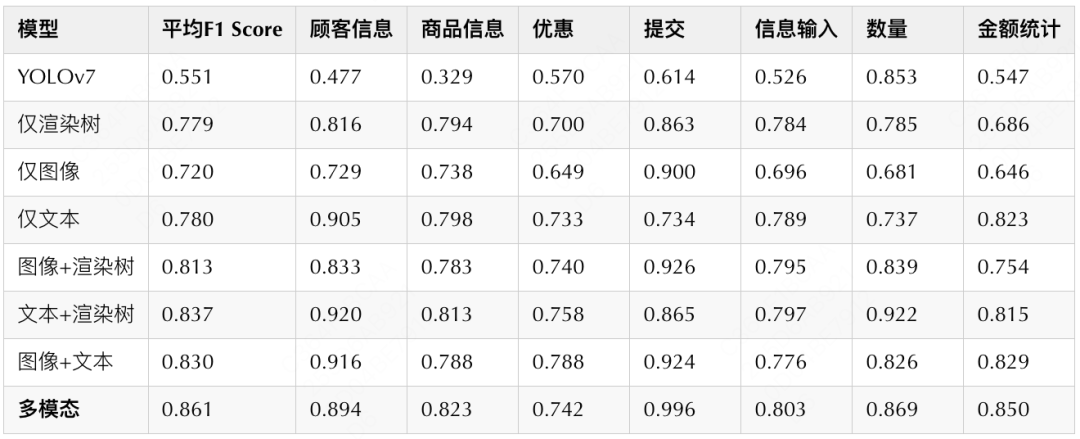
从上表可以看出,多模态自注意力深度学习的 UI 交互意图理解方案在相同数据集下具有最好的表现。分析原因主要有两个:首先,随着模态的增多模型的效果会变好,可见三种模态的信息互为补充,让模型能够通过多个维度更准确的进行拟合;此外,自注意力机制的引入使得节点的分类能够考虑到其周围的相关信息,提升了特征提取的效果,让UI组件分类更准确。因此,我们的后续研究基于此多模态自注意力模型展开。
该多模态模型的UI组件的多维度分类结果示例如下:

图10 不同页面下的分类效果(不同颜色框代表不同类别)
4.3.2 交互意图簇生成:UI组件聚类
当前多模态多分类模型针对的识别对象是一个个渲染树节点。一般来说多个渲染树节点才能组合成一个完整的交互意图簇,所以我们考虑将属于同一个意图的节点聚类在一起,这样就能够给下游任务提供更多可用信息。
我们首先尝试了基于规则的无监督聚类方式:将一个表单页上被分类模型判为同类型的连续节点聚为一个交互意图簇。但由于其在处理连续但独立的同类交互意图簇时效果很差,并不适用于当下复杂场景。
深入分析可知,聚类任务有两个难点:
- 情形1:如果渲染树节点不连续但是属于同一个簇,仍希望对其成功聚类。
- 情形2:连续的渲染树节点可能被分类模型判定为同一个交互意图类别,但希望对齐一般用户的理解将其聚类为多个独立交互意图簇。(如:连续的几个表单填写框我们希望能够将其分割开,如下图中出现的三个连续的【信息输入】交互意图簇)。
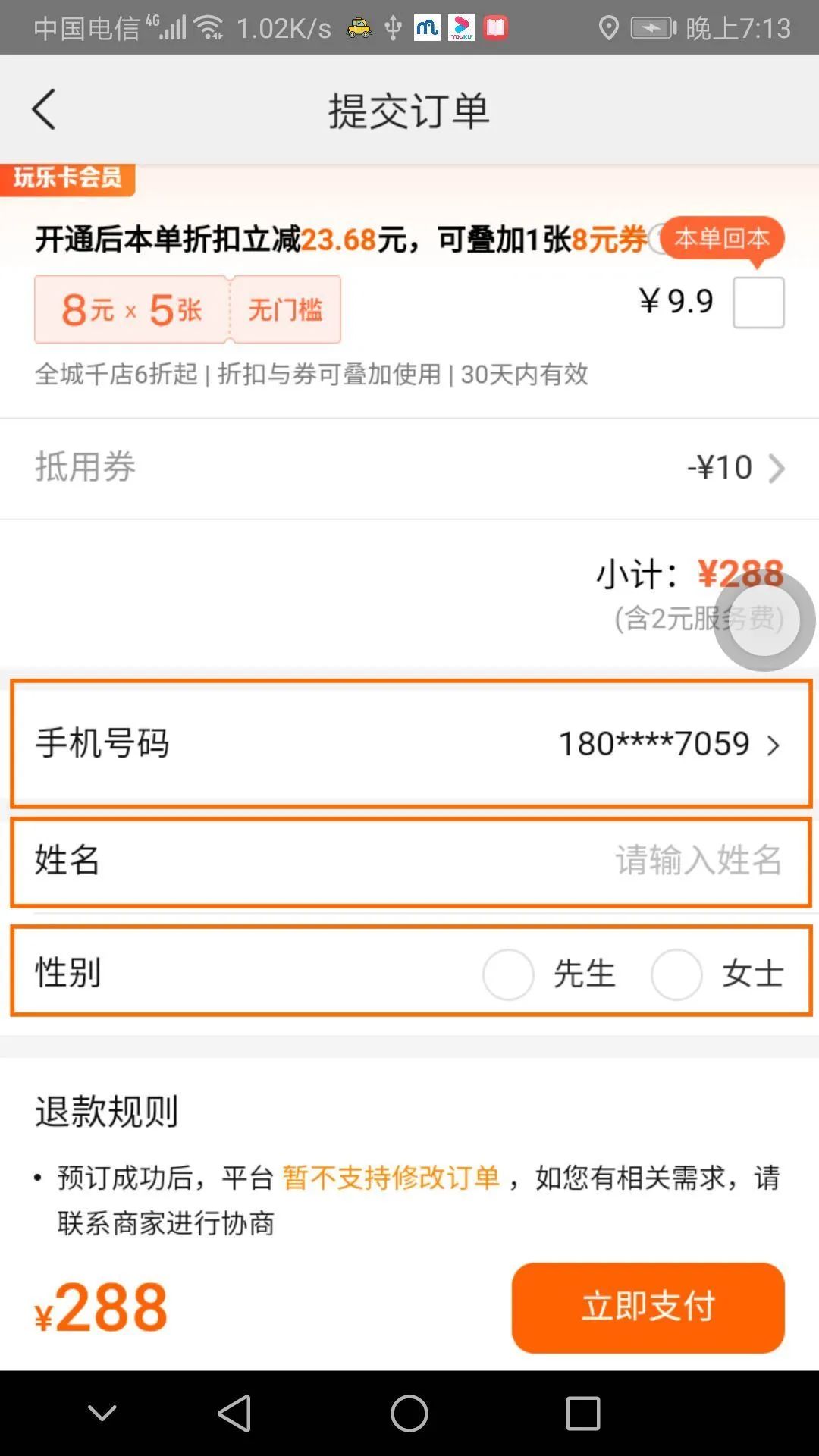
图11 三个连续的信息输入交互意图簇
在聚类的实现方式上,我们考察了多种常用聚类手段:
- 最简单的规则聚类(连续同标签的渲染树节点为同簇)并不能处理前述连续多个同类簇情形。
- 以k-means[4]为代表的无监督聚类方法在本研究所涉及的多维度聚类问题上也表现不佳,我们对其超参数进行了广范尝试也无法得到理想的聚类效果。
经过广泛尝试,我们最终选取了一种有监督聚类方案:每个节点依次与其它节点计算是否属于同一个簇,将被判断属于同一个簇的聚合起来。通过分类模型判断是否属于同一个簇,而模型的ground truth(真值)是我们人工标注出的每个类别页面中的所有渲染树元素簇。聚类模型结构与训练流程如下:
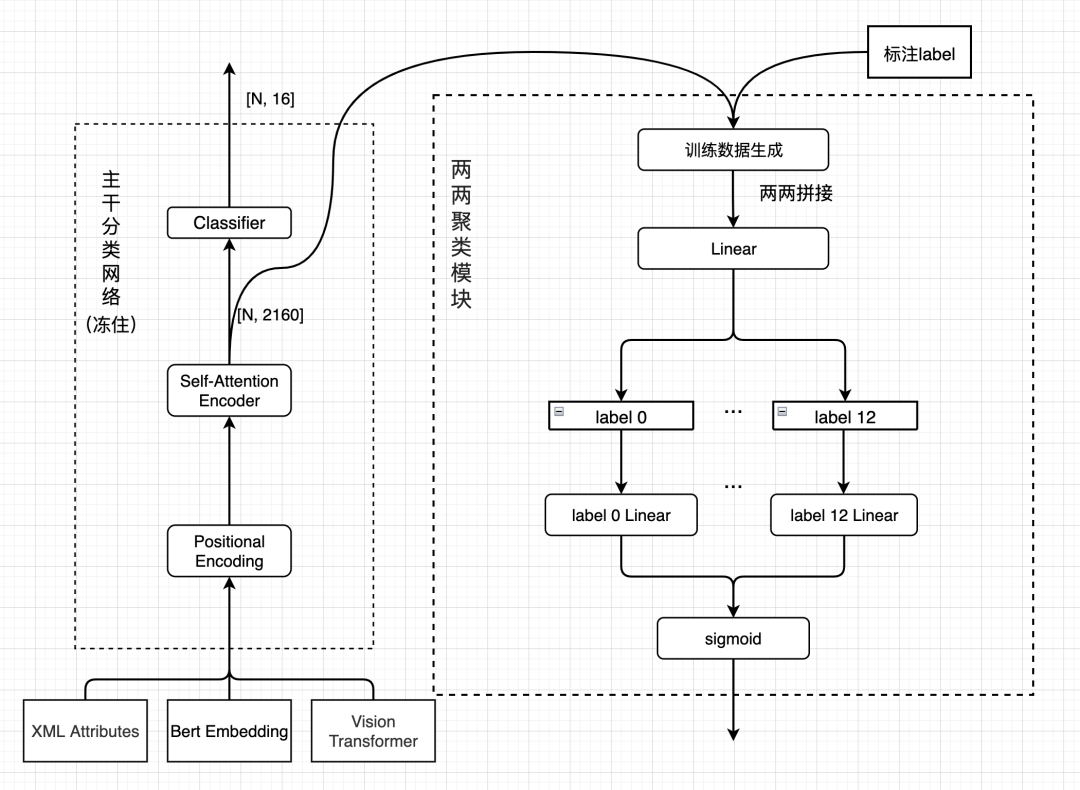
图12 聚类模型结构
我们采用与分类模型相同的页面标注数据生成训练集和测试集。训练时,我们首先为每个UI界面上生成所有可能的两两组合,其中在任意类别属于同一簇的组合是模型输入正例,其余为反例。预测时,我们将分类模型的结果送入聚类模型,由聚类模型输出最终的交互意图簇。
在UI组件聚类的评测指标上,我们采用标准聚类量化评估参数兰德系数[5]衡量聚类模型的效果。William M. Rand 通过将聚类问题转换为任意两个元素的组合(N(N-1) 个)是否在同一簇的决策问题,由此定义了在聚类问题上的混淆矩阵(TP,TN,FP,FN)。因此本研究用Precision来衡量聚类结果的准确性,用Recall表示聚类结果的全面性,而两者的F1 Score就是兰德系数。
由于本研究采用的是多层次平行聚类算法,所以兰德系数的数值整体偏低(如下表所示)。但从聚类效果图(图13)可知当前有监督聚类模型对交互簇有良好的聚类效果。


图13 选用的有监督聚类效果示例(不同颜色框代表不同类别)
| 4.4 实验结论
综上,我们得到了以下结论:
本研究提出的基于多模态自注意力深度学习的UI交互意图理解方案在准确性、泛化性上具有一定优势,且其对数据标注和训练轻量化的需求贴合业界的真实测试场景。
5 实际落地探索
基于UI交互意图理解的智能化测试用例驱动
UI交互意图识别模型在订单页领域已经具备了一定的交互意图簇识别能力,我们期望利用UI交互意图识别模型进行智能化测试用例驱动:在交互意图层面进行大前端测试用例的编写,希望测试用例在不需要任何适配的情况下实现跨端、跨App、跨技术栈的执行。我们在美团App的酒店详情页场景的安卓端利用交互意图簇识别能力完成以下测试用例的驱动编写:
- 下单首个产品
- 下单最便宜的产品
下面是测试用例伪代码以及部分输入集合定义:
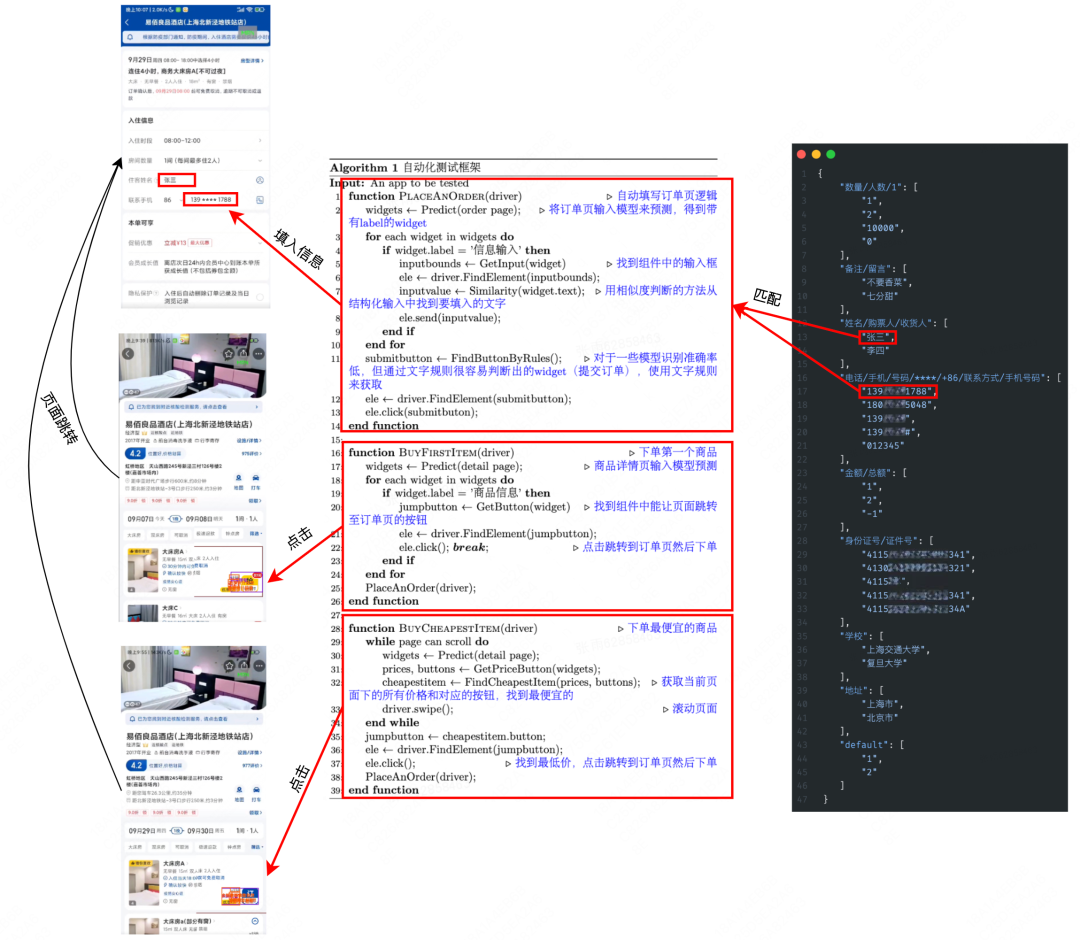
图14 测试用例伪代码与执行流程
图中显示了选择 “首个酒店” 与 “最便宜酒店” 的伪代码流程。
- 首先在酒店详情页,我们会在 BuyFirstItem 与 BuyCheapestItem 这两个函数中实现主要逻辑 。其中在 BuyFirstItem 会寻找到首个被模型识别为 “商品信息” 的交互意图,并从中找到在这个交互意图中的“购买按钮”意图,进行点击后跳转到填单页。在 BuyCheapestItem 中我们会获取页面上所有的 “商品信息” 的交互意图,并从每个商品信息意图中识别“价格信息” 交互意图,得到每个商品的价格进行比较,找到最便宜的商品后点击其“购买按钮”意图进入填单页。
- 进入填单页后,通过模型识别“信息填写” 交互意图。如图中所示,首先识别到两个“信息填写” 意图,通过其提示文字 【住客姓名、联系手机 】匹配输入集合中的 姓名、电话,从而选择出信息填写到对应的输入框中。在此之后,利用模型识别页面中的“提交订单”交互意图,点击进行订单提交从而完成整个下单流程。
美团App下单购买列表内首个商品-视频
美团App下单购买列表内最便宜的商品-视频
此外,我们在训练集以外的五种App上定量研究了智能化测试用例的可用性和泛化性。100个不同的页面中,基于UI交互意图理解的智能化测试用例在89个页面正确执行通过。该实验证明:基于UI交互意图理解的智能化测试用例具备良好的鲁棒性和泛化性。
目前,我们正在推进UI交互意图在实际自动化测试用例编写中的落地工作,即用UI交互意图代替基于规则的测试驱动脚本。由于业内的测试场景往往涉及不同技术栈、不同业务之间的大量相似的页面,这种泛化能力强的测试用例可以在相似页面复用,因此可以减少开发成本。此外,与现有的基于规则的测试脚本不同,该方法对UI页面的小规模变化不敏感,不会出现需要频繁维护Selector[6]的情况,可一定程度上减少自动化Case维护所耗费的精力。
未来,我们将通过收集更为广泛的UI数据来训练一个通用的UI交互意图理解模型以覆盖常见页面中的UI交互意图识别,业务质量保障人员可以直接利用这种通用的识别能力开发泛化性、鲁棒性更好的智能化测试用例。对于那些暂时处于模型能力范围之外的页面或者新上线的业务,我们将提供模型的微调接口,经少量的标注数据微调即可使其在相关页面展现出识别效果。
6 总结
本文介绍了利用页面多模态信息在UI测试领域的探索与实践经验。针对意图信息识别问题,我们利用图像+文本+渲染布局属性信息探索出了一种交互意图簇识别模型,验证了基于自注意力的多模态方向可行性。此模型可以识别出渲染树元素多维度的意图属性信息,同时利用聚类算法将节点聚成交互意图簇,可以为后续的任务提供结构化决策信息。在标注数据较少的情况下仍体现了较好的准确率以及泛化能力。后续计划通过扩大数据集、加强预训练等方式继续提升模型识别的精度。
回顾整个UI交互意图理解探索历程,先后经历了“无监督/无类别的区域划分”,“有监督针对UI节点分类”, “分类后聚类”, “利用识别结果进行测试用例编写、执行”四个阶段。目前在UI交互意图提取上我们已探索出了较为合适的方案,正进行实际业务落地,让UI交互意图识别能力融入当前大前端测试能力,在智能测试用例驱动、智能检查等方向上取得实际应用收益。
7 展望
下面是几个基于UI交互意图理解能力开展的业务落地工作。
1. 智能探索性测试
当前App功能复杂,有大量可以操作的组件,无意识的探索效率太低,期望利用意图识别结果,对当前测试场景的一些通用可操作组件执行有意义操作的自动化测试,并进行逻辑问题校验。
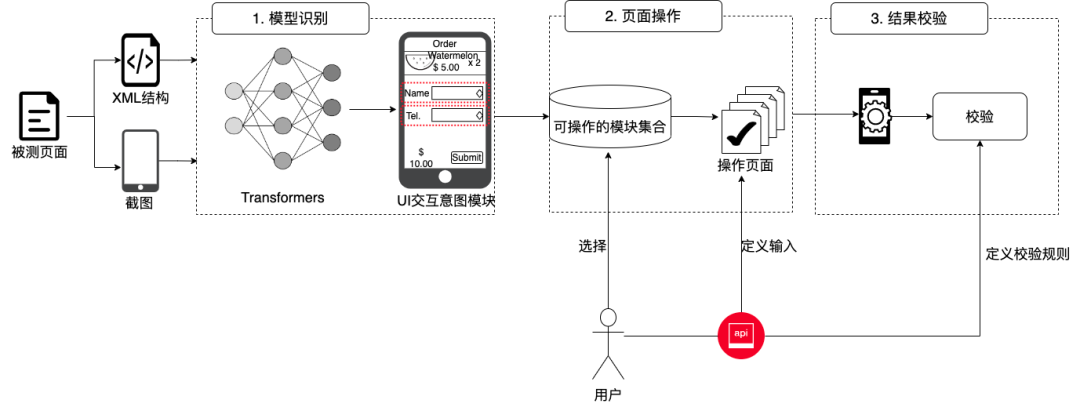
图15 探索性测试大体流程
2. 跨分辨率UI Diff及归因
不同分辨率/设备下布局存在差异,像素级比对无法识别不同分辨率下的UI Diff。使用交互意图簇Diff 可以大大削弱像素位置的差异造成的干扰,支持跨分辨率的比较,凸显Diff所需要关注的文本/图像变化,并可利用意图信息对结果进行结构化归因。
3. 节点匹配选择
利用意图识别预训练模型,支持节点匹配任务,实现泛化性较强的跨分辨率、跨技术栈、跨App的节点查找能力,与现有的基于XPath、Selector等的线性条件节点选择模式形成互补。
在中长期来看,我们期望将UI交互意图识别作为大前端结构化信息提取的通用能力,在不同的业务领域进行如智能测试bot、终端测试标准化知识组织与覆盖率评估、智能辅助测试用例编写与生成等方向上持续探索、落地。
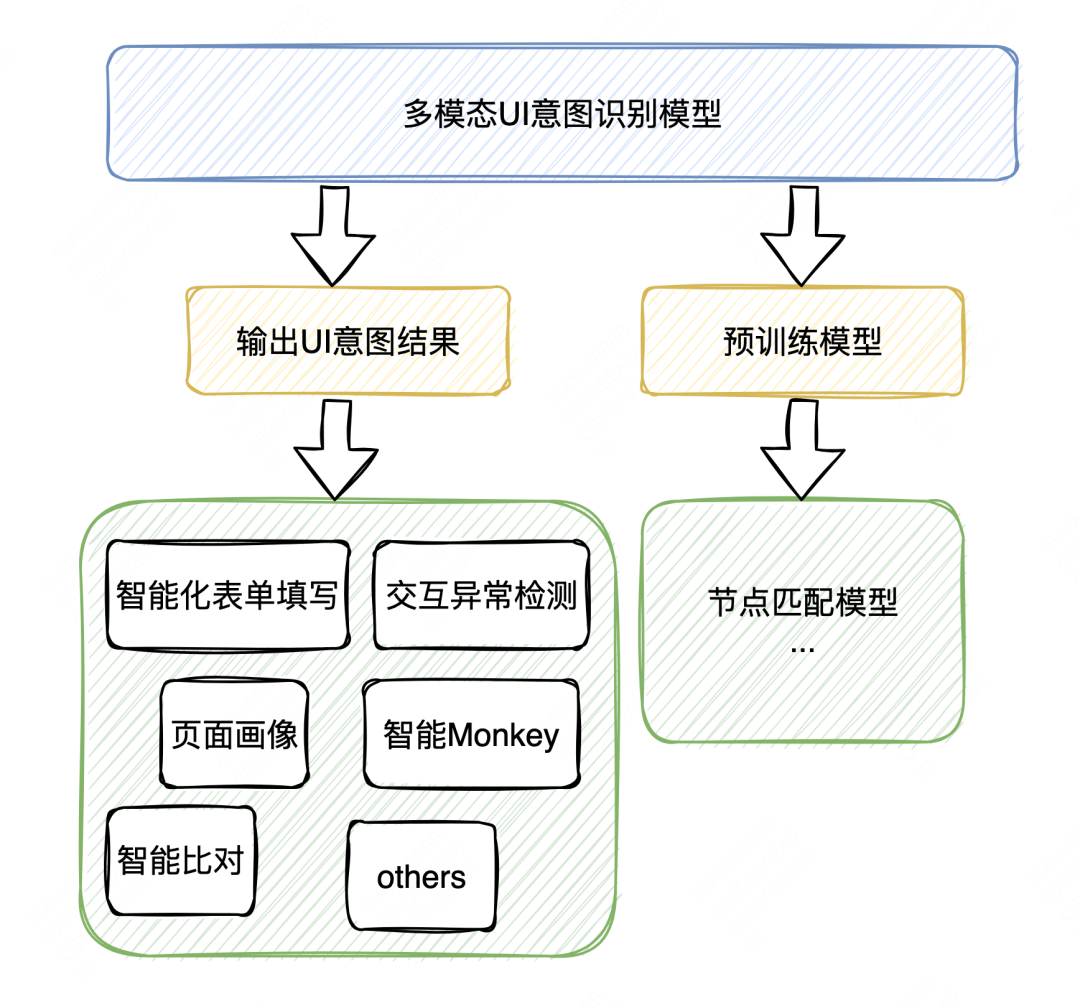
图16 相关下游任务
附录
大模型时代下UI交互意图理解能力的意义
目前业界内大模型主要存在两种类型:大语言模型[7](LLM:仅支持文本模态输入输出)以及多模态大语言模型[8](MLLM:可以同时处理多种模态信息)。目前大语言模型具备比较良好的通用化逻辑理解能力,而多模态大语言模型能够同时基于文本、图像等模态信息完成理解、判断,但整体的逻辑能力水平相比大语言模型有一定差距,在一些多模态任务上判断、分析的精度尚不够令人满意。
基于这两种大模型,在实际任务解决上有两种相对应的主要模式:【LLM as Controller】 与 【MLLM cognize Everything】,UI交互意图理解作为一种垂直领域能力,在两种模式中都具有相应的应用潜力。
LLM as Controller
该模式的核心思路是将垂直能力作为工具,LLM作为总控,利用其逻辑推理能力,通过自然语言理解目标,然后进行决策,编排、调用工具,完成任务。这种范式下的典型实例有HuggingGPT[9]等。在这种范式下,LLM能够与垂直能力优势互补,更好的完成多领域任务。
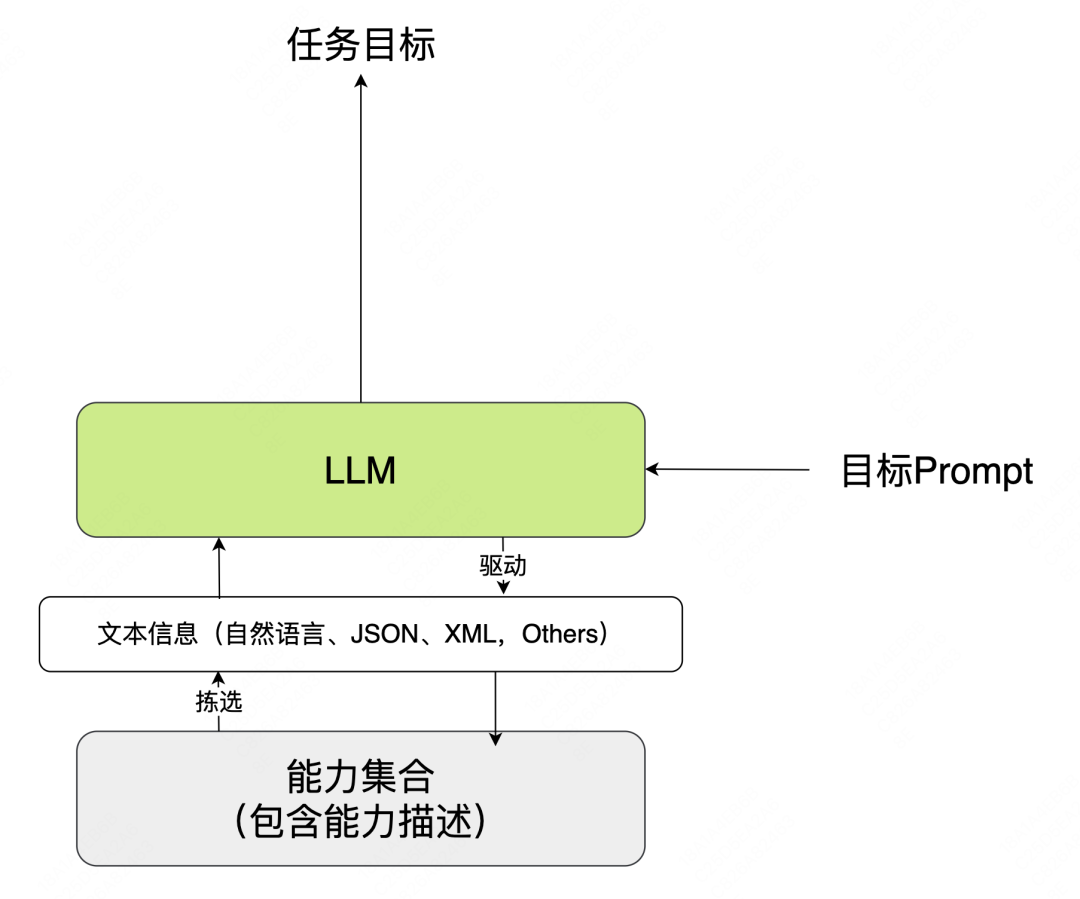
图17 相关下游任务
以HuggingGPT项目为例,其主要思想是将LLM作为总控,将HuggingFace平台上众多的垂直能力模型作为工具集,用户可提出需求,LLM根据需求调用垂直能力。最后LLM根据垂直能力返回的结果生成满足用户需求的多模态内容。

图18 HuggingGPT工作流程
可以看到在这个模式下,与其它的垂直工具能力类似,UI交互意图理解能力可以作为工具能力供LLM调用,更好的完成UI交互相关的任务。
MLLM cognize Everything
多模态大语言模型出现了之后,让我们看到了多模态任务通用化解决方案的曙光。具体到UI交互意图识别任务中,我们尝试使用多种MLLM直接进行UI交互意图识别,总体来看MLLM已经具备不错的识别能力,但是在具体的坐标、内容分析方面上仍有偏差。UI交互意图识别模型可以通过以下两种方式帮助MLLM在意图识别任务上进行性能提升:
- 将UI交互意图识别模型作为页面多模态信息Encoder,通过微调的方式提升意图识别任务中的准确率。
这里以MiniGPT为例,介绍Encoder模式。
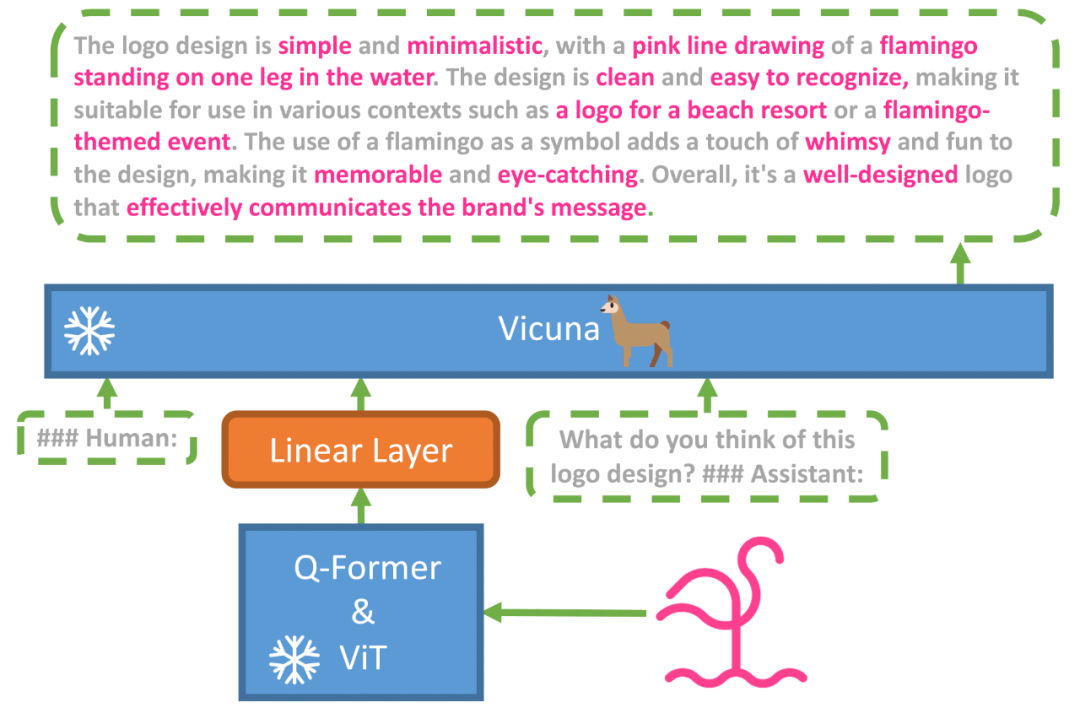
图19 MiniGPT模型结构
由上图可知,多模态大语言模型中一般由每个模态对应的模块来进行模态信息处理,如上图中VIT[10]&Q-Former[11]为图像模态处理部分,Vicuna[12]是一种开源的LLM。UI交互意图理解模型可以替换图中VIT&Q-Former的位置,作为交互意图信息的处理预训练Encoder与LLM结合进行多模态整合训练,产出页面分析来辅助多模态大语言模型在大前端质量保障中的应用。
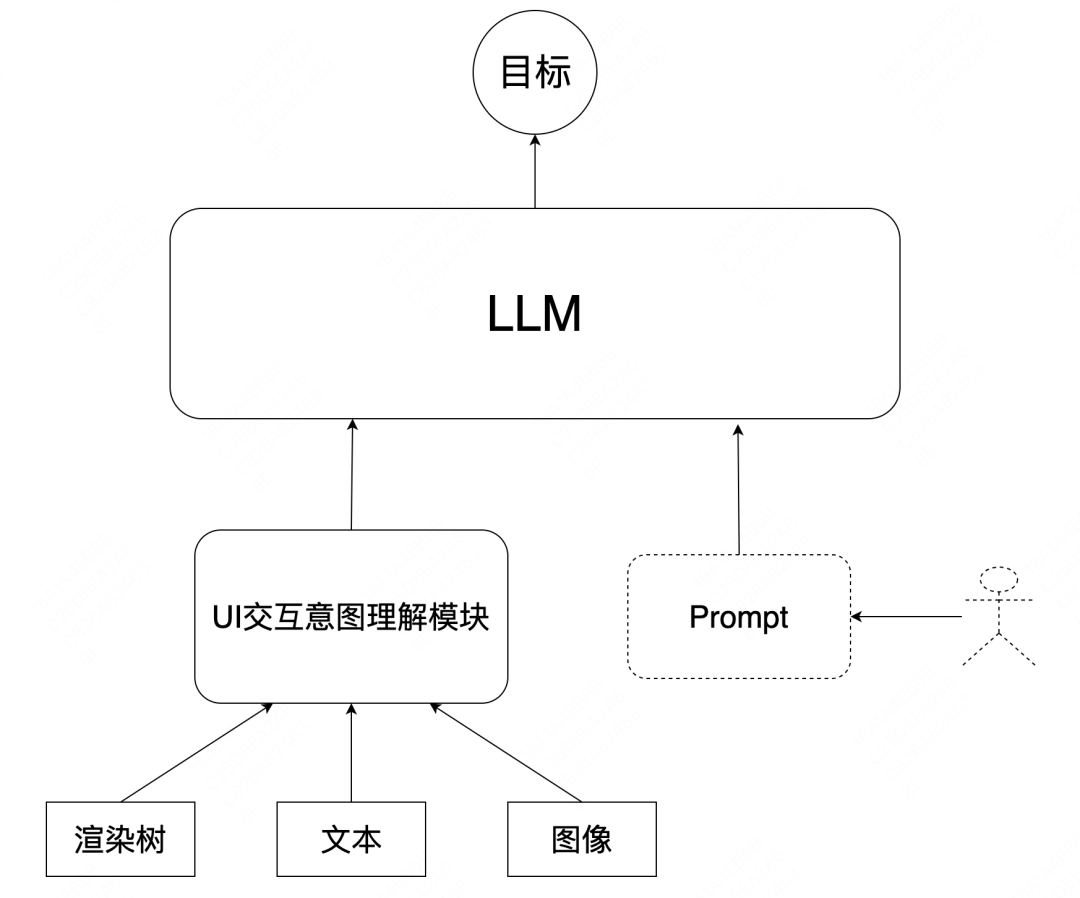
图20 基于UI意图理解能力的多模态大语言模型结构
- 将UI交互意图识别模型做为信息提取工具,将识别出的结构化信息加入Prompt中,帮助MLLM更精确的进行意图识别。
总体而言,UI交互意图识别是一种简单轻量但效果不错的垂直领域能力,只需简单少量的训练数据,即可实现在诸如跨App、跨技术栈、跨业务等复杂场景下准确识别多种交互意图的能力。大模型领域日新月异,我们也将持续探索UI交互意图识别能力与该领域技术的结合方式,发挥其最佳效果。
本文作者
诗雨,张雨,永祥等,均来自美团到店事业群/平台技术部/质量工程部。
参考文献
- [1] UI交互意图:用户通过当前UI展示推断出来的不同模块的概念及交互功能。
- [2] 学术产出:Appaction: Automatic GUI Interaction for Mobile Apps via Holistic Widget Perception
- [3] F1 Score:精确率(Precision)和召回率(Recall)的调和平均值。
- [4] k-means:一种最初来自信号处理的矢量量化方法,旨在通过最小化簇内方差将 n 个观测值划分为 k 个簇.
- [5] 兰德系数:Rand W M. Objective criteria for the evaluation of clustering methods[J]. Journal of the American Statistical association, 1971, 66(336): 846-850.
- [6] Selector:此处指在基于规则的测试脚本中选取/定位UI组件的工具。
- [7] 大语言模型(LLM):依据维基百科的定义,大语言模型是一种能够理解和生成自然语言的人工神经网络,它们利用了海量的文本数据和复杂的神经网络结构,可以通过预测下一个单词或使用提示工程来完成各种语言任务,但也可能存在不准确性和偏见。从定义中可知,狭义的大语言模型的输入和输出仅支持文本模态的信息。ChatGPT-3.5、Meta的LLaMa,以及BLOOM、Anthropic的Claude等都属于该类型。
- [8] 多模态大语言模型(MLLM):多模态大语言模型(英语:multimodal large language model,MLLM)是一种能够处理多种类型的数据,如文本、图像、音频、视频等,以实现通用的语言理解和生成的人工智能模型。MLLM利用了海量的多模态数据和复杂的神经网络结构,可以在不同的模态之间进行转换、融合和推理,以完成各种语言任务,如文本分类、问答、对话、图像描述、视频摘要等。从定义可知,多模态大语言模型可输入或输出多种模态的信息。GPT-4V、LLaVA、Minigpt-4等属于该类型。
- [9] HuggingGPT:microsoft/JARVIS: JARVIS, a system to connect LLMs with ML community. Paper: https://arxiv.org/pdf/2303.17580.pdf (github.com)
- [10] VIT(Vision Transformer):VIT是一种基于Transformer的模型,最初提出用于图像分类任务。与传统的卷积神经网络(CNN)不同,VIT将图像看作是一个序列(或一组图像块),并使用Transformer的注意力机制来学习图像的全局特征表示。VIT将输入图像划分为一系列的图像块(patches),然后将这些图像块转换为向量形式,并将其输入Transformer编码器中。通过自注意力机制和多层感知机,VIT能够学习到图像的全局特征表示,然后通过一个分类头进行分类。
- [11] Q-Former(Quasi-Recurrent Transformer):Q-Former是一种融合了CNN和Transformer的模型,用于处理序列建模任务,例如语言建模和机器翻译。Q-Former将CNN模块和Transformer模块结合在一起,以在序列中捕捉局部特征和全局依赖关系。在Q-Former中,CNN模块用于提取输入序列的局部特征表示,然后Transformer模块用于学习全局依赖关系和序列建模。相比于传统的Transformer模型,Q-Former在一些序列任务中可以获得更好的性能,并且具有更高的计算效率。
- [12] Vicuna:lm-sys/FastChat: An open platform for training, serving, and evaluating large language models. Release repo for Vicuna and FastChat-T5. (github.com),具体的多模态训练流程可以参考该项目论文。
---------- END ----------
** 美团科研合作 **
美团科研合作致力于搭建美团技术团队与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕机器人、人工智能、大数据、物联网、无人驾驶、运筹优化等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:meituan.oi@meituan.com。
** 招聘信息 **
美团到店平台技术部-质量工程部是到店事业群的技术质量保障团队,负责到店综合、到店餐饮、酒旅业务以及到店多个平台(业务平台、技术平台以及数据智能领域)的质量保障,通过建设基础工程能力,从研发全过程建设质量,保障到店业务与技术系统规模化快速迭代。我们注重技术创新,不断地探索技术边界,用技术驱动业务,团队技术氛围浓厚。目前正在招聘:
- 测试开发工程师-服务端/视频领域/数据智能/移动端
- 开发工程师-业务稳定性保障
欢迎感兴趣的同学发简历到:xuwen19@meituan.com,邮件标题格式:姓名-岗位名称-社招。
活动推荐

AI时代,数据、算法、算力是三大核心要素,而算法工程作为运作载体,提供AI能力的业务价值变现。
美团作为一家科技零售公司,很早就在搜索、推荐、广告方向践行用AI“帮大家吃得更好,生活更好”,持续打磨算法体系和算法工程系统,以追求极致的用户体验。
本次技术沙龙,我们将与大家分享稀疏场景下的算法工程内容,包括训练、特征、推理三个方向遇到的系统挑战与取得的阶段性成果。
11月25日(周六)下午,我们将分享以下4个议题,欢迎报名。

** 推荐阅读 **
** | **自动化测试在美团外卖的实践与落地
** |** Spock单元测试框架以及在美团优选的实践
** |** 基于模式挖掘的可靠性治理探索与实践
版权归原作者 美团技术团队 所有, 如有侵权,请联系我们删除。