
原论文链接->DCAM-Net: A Rapid Detection Network for Strip Steel Surface Defects Based on Deformable Convolution and Attention Mechanism | IEEE Journals & Magazine | IEEE Xplore
DCAM-Net: A Rapid Detection Network for Strip
Steel Surface Defects Based on Deformable
Convolution and Attention Mechanism(论文标题)
Abstract(摘要)
带钢(the strip steel)表面缺陷检测是带钢生产中的关键环节,是提高带钢生产质量的重要保证。然而,由于带钢表面缺陷图像的对比度差(poor contrast),缺陷类型(defect types)、尺度(scales)、纹理结构的多样性(texture structures)以及缺陷分布的不规则性(irregular distribution),使得现有方法难以实现带钢表面缺陷的快速、准确检测。本文提出了一种带钢快速检测网,基于可变形卷积和注意机制(deformable convolution and attention mechanism),即DCAM-Net。
首先,我们引入限制对比度自适应直方图均衡化 (传送门->CLAHE)作为数据增强方法(a data augmentation method),以提高缺陷图像的对比度,并突出(highlight)带钢表面图像上的缺陷特征。
其次,我们提出了一种新的(a novel)增强型变形特征提取模块(enhanced deformation-feature extraction block)(EDE-block),去解决复杂多样的以及不规则分布的带钢缺陷。通过融合变形卷积,扩展了缺陷特征提取网络的接收域,以捕获完整和全面的缺陷纹理特征。
最后,我们引入坐标注意力模块(coordination attention)(CA),以取代骨干网络(backbone)的空间金字塔池(SPP)结构,进一步分解池操作,有效地提高了网络的缺陷定位能力。在NEU-DET数据集上的实验结果表明所提出的算法的平均精度(the mean Average Precision)(mAP@loU=0.5)为82.6%,比基线网络提高了7.3%的检测速度,达到100.2帧(fps),有效提高了带钢表面缺陷的检测效率
Index Terms**— Attention mechanism, coordinate attention, ****deformable convolution, object detection, surface defect detection, ****YOLOX. **
索引词——注意力机制,坐标注意力,可变性卷积,目标检测,表面缺陷检测,YOLOX网络
I. INTRODUCTION(引入)
①由于带钢生产工艺、环境等问题质量导致带钢存在各自缺陷,本文指出缺陷检测技术是保证高质量带钢生产的关键步骤,能够自动化程度和生产效率,降低质检人员劳动强度、成本,提高钢铁企业的市场竞争力,所以具有广泛的应用前景。
②缺陷检测问题,通常采用传统的图像处理与机器学习相结合的方法,主要检测缺陷的边缘形状、纹理信息、灰度变换等特征。例如,对于具有单一背景的缺陷图像,一些边缘检测算子,如Sobel和Canny,可用于定位简单的缺陷。对于具有周期性纹理背景的缺陷,小波变换(wavelet transforms)和周期性的加伯变换(Gabor transforms)可用于将图像从空间域变换到频域进行检测。这种方法还可以表征图像的统计特性,如灰度差和灰度直方图。此外,缺陷可以通过传统的机器学习方法进行分类,如SVM和random forest。传统的方法通常需要通过手工设计(manual design)来描述缺陷特征。而且,基于人的主观性(subjectivity),手工设计的特征很难分辨出工业表面缺陷。而面对未知且多样的缺陷类型,这些检测方法的泛化能力往往较差(poor generalization ability)。因此,当面对更复杂和不规则的缺陷时,传统的方法难以在实际的工业应用场景中应用。
③接着论文介绍了目标检测的部分发展历程——
Girshick开发R-CNN,此后目标检测像滚雪球一样迅速发展(object detection has snowballed)-->提出SPPnet->提出fast R-CNN,结合R-CNN和SPPnet的优点提高检测效率-->提出faster R-CNN,即使用RPN代替fast R-CNN来生成区域建议,显著提高检测速率-->YOLOv1将目标检测问题统一为回归问题-->Redmon and Farhadi提出YOLO9000,提高YOLOv1的召回和定位能力-->两人又提出YOLOv3,利用ResNet残差思想进一步提高检测速度和准确性-->Bochkovskiy等人提出YOLOv4,在neck部分的特征金字塔网络(FPN)中添加了路径聚合网络(PAN),有效提高训练速率-->YOLOv5被提出,该模型对输入图像大小进行校正,并利用k-均值对锚框(anchor)进行聚类,在计算过程中自适应计算锚框,同时在FPN中应用跨阶段部分(CSP)模块,在保证检测精度的同时显著提高检测速度,相对降低模型参数-->基于YOLOv3的YOLOX被提出,YOLOX首先用CSPDarknet53取代了主干网络(backbone),以进一步增强特征提取。其次,将传统的头改进为解耦的头(decoupled head),提高了检测网络的收敛速度和表达能力。最后,采用anchor-free代替anchor-based生成锚框,大大减少了许多锚框造成的计算和耗时问题,提高了检测网络的泛化能力和检测速度(不需要预定义锚框,因此能够更加自适应地检测不同尺寸、不同比例的目标)。
④论文继续介绍历程——
2020年,一种多层次特征网络(a multilevel feature network)被提出,其思想是将多层次特征结合成一个特征,以此来获得带钢表面缺陷位置的更多细节。
2021年,Kou等人将YOLOv3算法应用于带钢表面缺陷图像的数据集NEU-DET,平均精度(mAP)效应达到72.2%,说明YOLOv3在带钢表面缺陷检测中的适用性。Cheng和Yu提出了结合注意机制和自适应空间特征融合模块的RetinaNet,有效地提高了对带钢表面缺陷的检测效果。Xing和Jia设计了一种新的损失函数XIOU,以更好地检测带钢表面缺陷。Gao等人提出了一个模块特征收集(a module for feature collection)和压缩网络(compression network)用来合并多尺度特征信息(multiscale feature information),并提供了一种新的高斯加权池方法取代ROI池,在NEU-DET数据集中达到了80.0%的mAP效应以及实现了64.0帧的检测速度,满足工业实时检测(industrial real-time detection)的应用要求。
2022年,Wang等人设计了一种噪声正则化(regularization)策略,可以更好地提高训练模型的鲁棒性,因为带钢表面不良图像的噪声会**导致模型崩溃(model collapse)**。Li等人提出了一种改进的YOLOv5网络模型,用于检测带钢表面的微小缺陷(minor defects)。在模型中嵌入了注意模块CBAM,并优化(be optimized)了检测网络结构和损失函数。在自构建的工业缺陷数据集(self-constructed industrial defect dataset)的mAP值达到91.0%。
⑤论文开始指出问题——
从以上综述中可以看出,近年来对带钢表面缺陷检测算法的研究,已经不同程度地提高了深度学习模型的检测精度(detection accuracy)和检测速度(detection speed),取得了良好的检测效果。然而,在带钢表面缺陷检测中,不同缺陷表面的缺陷类型、尺寸、形状和纹理特征的复杂性(complexity)仍然是一个常见的问题,使得缺陷难以准确检测,不规则的缺陷分布(irregular defect distribution)增加了检测的难度。此外,由于摄影设备和照明(illumination)的影响,带钢表面部分缺陷的图像存在对比度较低(low contrast)的问题。缺陷与背景对比度低,导致带钢表面成像后噪声较大,严重干扰(interferes)算法的缺陷检测,容易导致检测遗漏(missed detection)。
⑥因此,为了提高目标检测算法在钢板表面缺陷检测中的准确性和适用性,本文借鉴文献的方法,以YOLOX为目标检测模型的基础,构建了基于可变形卷积和注意力机制(deformable convolution and attention mechanism)的快速检测带钢表面缺陷DCAM-Net网络,如图Fig. 1所示。
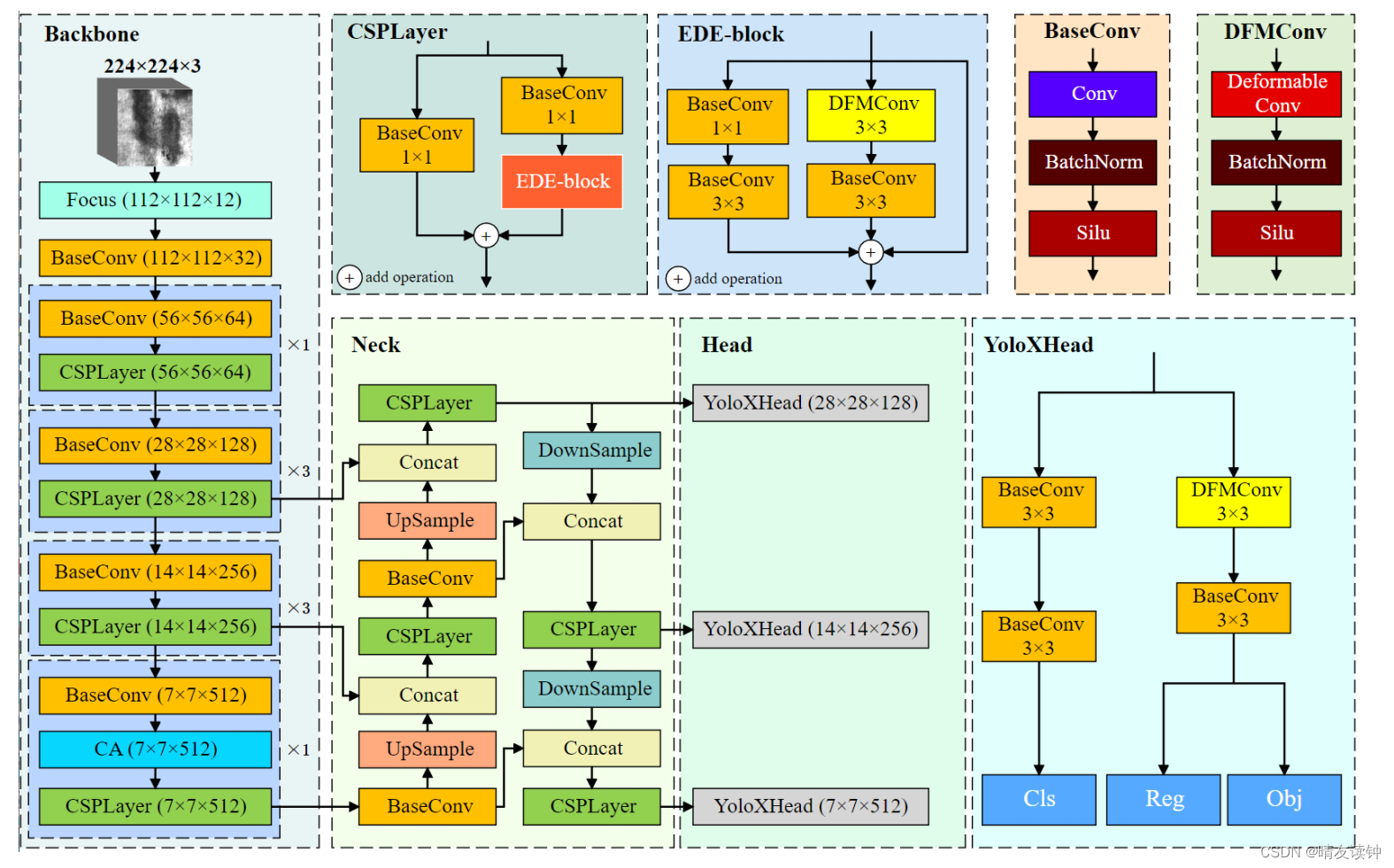 Fig. 1. Overall architecture of the DCAM-Net.
Fig. 1. Overall architecture of the DCAM-Net.
II. DCAM-NET
*A. Baseline Networks *
论文指出深度学习的锚框的生成模式尤为重要,评价YOLO系列的检测头采用的聚类生成锚框的模式会带来两个问题——
①聚类方法会导致模型在不同数据集上的泛化能力较差,训练后生成的锚框大多不能使用,导致大量的计算冗余,从而提高了计算成本和检测速度。
②在带钢的表面缺陷图像数据中,由于缺陷之间的显著差异,聚类得到的锚框的大小容易不稳定,会在一定程度上影响检测网络模型的检测效果。
对比YOLO系列网络——
①YOLOX检测头部分用无锚定(anchor-free)技术取代了基于锚定的技术。采用匈牙利算法作为参考,并设计了简化最优传输分配(SimOTA)匹配算法,以减少模型训练过程中的许多冗余锚框。
②YOLOX不需要手动调整锚框的大小,从而提高了模型对不同图像的泛化能力。YOLOX对YOLOv3上的一系列改进有效地提高了检测效果和速度,特别对不同图像上的泛化性(generalization ability to different images)。
因此,论文综合考虑了基于无锚框的YOLOX的优势,决定将其作为基线网络(baseline)。
论文又指出YOLOX也存在不足——
①由于残余结构的设计问题,YOLOX的骨干网络难以更好地改进带钢表面缺陷特征的提取。
②由于动态样本匹配(dynamic sample matching)的问题,YOLOX在检测不规则缺陷对象方面的性能较差。与YOLO系列中传统的anchor-based的方法相比,YOLOX对复杂纹理的缺陷对象的检测性能较差,精度较低。
因此,YOLOX仍有一定的改进空间。
论文顺势引出自己的改进——
为了提高YOLOX算法在带钢表面缺陷检测中的性能,我们设计了一种基于可变形卷积和注意力机制(deformable convolution and attention mechanism)的带钢表面缺陷检测网络,如图Fig. 1所示。
首先,我们引入限制对比度自适应直方图均衡化(the contrast limited adaptive histogram equalization)(CLAHE)作为一种数据增强方法来提高缺陷图像的对比度,并突出带钢表面图像上的缺陷特征。
其次,针对复杂、不规则的带钢缺陷设计了增强变形特征提取块(enhanced deformation-feature extraction block)(EDE-block)。通过融合(by fusing)可变形卷积(deformable convolution),扩展缺陷特征提取网络的感受野(receptive field),以捕获完整而全面(complete and comprehensive)的缺陷纹理特征(defect texture features)。
最后,引入坐标(coordinate)注意力模块(CA)来替代backbone部分的SPP结构,有效增强了网络定位缺陷(locate the defect feature)的能力。
B. CLAHE
由于摄像(image-capturing)设备、光变化、噪声和环境干扰的影响,带钢表面缺陷图像对比度较低。缺陷与背景之间的对比度较低,导致带钢表面成像后的噪声会干扰算法的缺陷检测,容易导致缺失检测(it is easy to cause the missing detection)。Reza提出利用CLAHE技术对照度较差的图像进行实时图像增强(real-time image enhancement),使图像获得了良好的对比度增强效果。因此,在数据增强方面(in terms of data augmentation),本文考虑增强带钢表面缺陷图像的对比度。目前,许多缺陷检测算法还没有使用对比度增强(contrast enhancement)的方法对带钢表面缺陷数据集进行增强。鉴于(given)CLAHE具有良好的对比度增强效果,本文将CLAHE应用于数据增强,以提高检测网络对带钢表面缺陷的捕获能力。
C. EDE-Block
在这个模块部分,论文先指出了传统卷积存在的问题,即网络的感受野被卷积大小所限制,故有人提出采用可变性卷积替代传统的标准卷积进行偏移学习——
在带钢表面缺陷检测过程中,缺陷的不同类型、尺寸、形状和纹理特征是导致检测难度和网络存在的普遍问题(general issues)。在深度学习模型中,由于卷积结构的固定性(the fixed structure of convolution),在特征提取(feature extraction)过程中,网络的感受野范围(the receptive field range of network)将被限制在卷积的大小上。然而,带钢表面缺陷的图像往往存在不规则特征,传统的卷积方法有限。为了提高卷积神经网络(convolution neural network)对带钢表面缺陷的检测性能(detection performance),必须扩大(expand)检测网络的感受野。大的感受野可以使检测网络更好地学习长程空间关系(long-range spatial relationship),建立隐式空间模型(implicit spatial model),Dai等人提出使用可变形卷积代替标准卷积通过可变形卷积进行偏移学习(offset learning),使检测网络能够动态地(dynamically)捕获完整的纹理缺陷特征。
主要(primary)的方法是通过在标准卷积上添加一个学习偏移量(learning offset)来扩展(extend)卷积核的采样范围(sampling range)。可变形卷积采样的偏移例子如图Fig.2所示。由于带钢表面缺陷的形状不同,标准卷积对非刚性带钢(nongrid strip steel)表面缺陷特征取样的影响是平均的。相反(on the contrary),可变形卷积可以在采样过程中(in the sampling process)拟合(fit)带钢缺陷对象的形状,以学习完整的对象特征。
可变形卷积的计算公式可定义为:
其中R定义了感受野的大小(size)和扩张(dilation),它的值为R={(−1,−1), (−1,0),…,(0,1),(1,1)}。p0为中心点位置,p**n为R范围内的9个位置,△p**n为学习偏移量,使得采样点扩散成非网格结构。

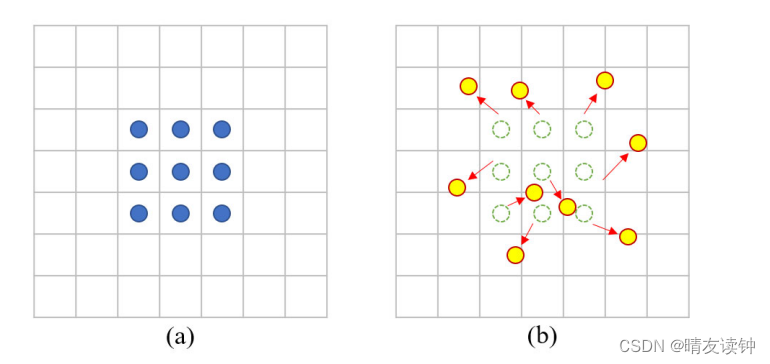 Fig. 2. Two different 3 × 3 sampling forms of the convolutional kernel.
Fig. 2. Two different 3 × 3 sampling forms of the convolutional kernel.
(a) Standard convolution. (b) Deformable convolution.
另外,如图Fig. 1所示,骨干提取网络的CSP残差模块通常(typically)使用1×1卷积模块进行通道调整,然后使用3×3卷积模块进行特征提取和残差连接(residual connection)。这种连接可以有效地减少参数和计算的数量,而且还有利于主干网络的特征提取。在带钢表面缺陷数据集中,缺陷特征对象不规则,其形状和尺寸差异很大(vary considerably)。一方面,锚框很难准确地反映出带钢表面的缺陷位置。另一方面,它会使检测网络判断错误,学习到太多的无关噪声,从而影响了带钢表面缺陷检测算法的性能。本文提出利用EDE-block对原CSP残差模块进行改进。原CSP残差块与新的(novel)EDE-block的比较如图Fig. 3所示。
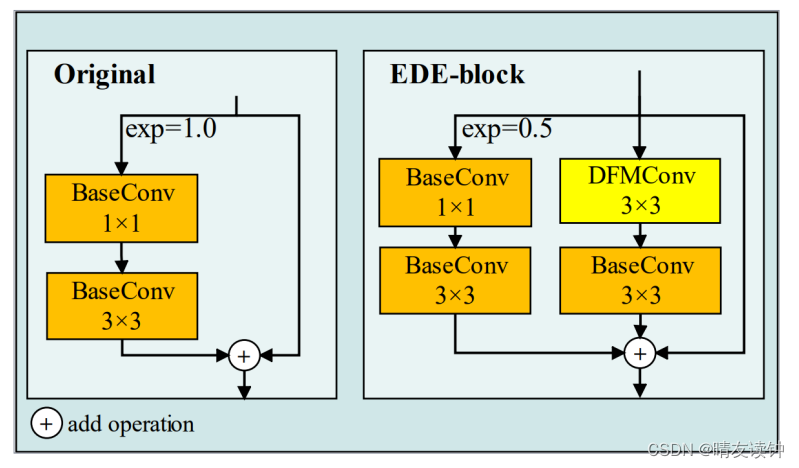
Fig.3.Comparison between the original CSP residual block and the EDE-block.
如图Fig.3所示,在EDE-block中,1×1基本卷积模块的通道扩展调整到0.5。利用3×3的基本卷积模块,我们实现了通道扩展,并完成了关键缺陷特征信息的提取。然后,添加一组连续(consecutive)的3×3卷积模块,提高检测网络的感受野,扩展检测网络对缺陷位置的捕获。其中,我们用一个可变形的卷积模块替换了第一个基本的卷积模块。
其偏移学习特征加强了(strengthens)不规则带钢缺陷对象特征之间的关系,使检测网络能够获得更完整的带钢缺陷特征信息,提高缺陷特征的特征提取能力。同样,检测头中Reg和Obj的分支结构被相同的连续卷积模块结构所取代,如图Fig.1所示。这不仅扩展了检测网络的接受域,而且增强了特征图的采样能力,提高了带钢表面缺陷特征的提取效果。
*D. Coordinate Attention *
在这个模块,论文指出现有的表面缺陷检测算法的检测能力有限,指出要增强特征的位置信息,提高网络对缺陷的关注。
面对带钢表面缺陷的复杂多样,现有的表面缺陷检测算法的检测能力有限。检测效果容易受到图像背景、无关噪声信息和缺陷特征的不规则分布的影响,导致检测网络对带钢表面缺陷特征的学习不足,使缺陷无法准确定位。因此,如何增强特征的位置信息,提高网络对缺陷的关注也是目前存在的问题之一。近年来,基于**即插即用(plug-and-play)**功能的注意力机制可以有效地提高网络性能,在计算机视觉中得到了广泛的应用。由于钢带钢缺陷位置信息的复杂性,我们在骨干网络中引入了CA模块来替代SPP结构。CA模块如图Fig.4所示。在带钢表面缺陷数据集中,缺陷的形状和位置表现出各种不规则状态。如果特征图直接汇集(pooling),其空间结构会被破坏,导致带钢缺陷位置信息的大量损失。为了不影响缺陷特征信息在FPN中的传输(transmission),本文用CA代替了SPP,它不仅保留(preserves)了缺陷的位置信息,而且进一步增强(further enhance)了缺陷特征的特征信息。CA在DCAM-Net模型中的位置如图Fig.1所示。CA模型的结构可以定义为
其中,zc为全局平均池化公式,x为输入卷积层,xc(i,j)为输入x在第c个通道道卷积层中的(i,j)位置的值。在注意力机制中,通常使用全局平均池化,将全局空间信息压缩到通道描述符中,因此位置信息具有保存难度。为了促进注意机制模块以精确的位置信息捕获长程(long-range)空间交互,文献将全局池分解(factorize)为一对一维(1-D)特征编码操作,其公式可定义为
其中,zhc(h)为zc池分解后高度为h的第c个通道的输出,zwc(w)为zc池分解后宽度为w的第c个通道的输出。然后,将(3)和(4)连接起来,并使用一个共享的1×1卷积F1来进行通道转换。最后,对F1使用非线性激活函数δ。得到了特征图f。
其中——
为了降低模型的复杂性,通常使用适当的衰减因子(ratio)r来减少f的通道数。
(下面这一部分涉及很多符号表示,不方便编写,我就直接上原图原内容了,其实这一块应该可以直接去找单独的CA模块讲解学习。)
大概意思是——然后,将特征图f分为两个不同的张量:fh和fw,使用1×1卷积将通道调整到与输入x相同数量的通道数,并使用sigmoid函数得到最终空间位置在垂直和水平上的注意力权重。同时,两个一维(1-D)全局池化操作沿着垂直(vertical)和水平(horizontal)方向将输入特征聚合(aggregate)成两个独立的(separate)方向感知(direction-aware)特征图,这有助于检测网络更准确地定位感兴趣的对象。gh和gw在空间位置的权值定义为(下面原文公式6和7)。
其中Fh和Fw为1×1卷积,σ为sigmoid函数。到目前为止,CA模块已经完成了垂直注意力和水平注意力。CA模型公式定义为(下面原图公式8)。
其中,yc(i,j)是第c个通道的卷积层乘以相应的垂直和水平权值的最终输出结果。
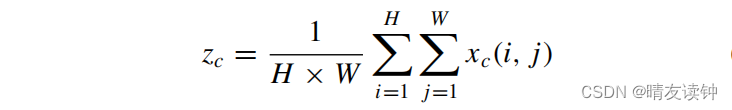
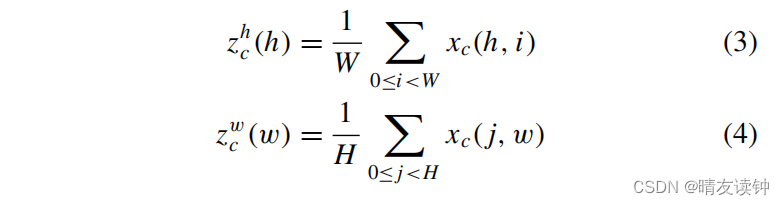
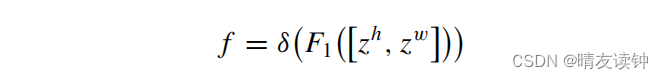


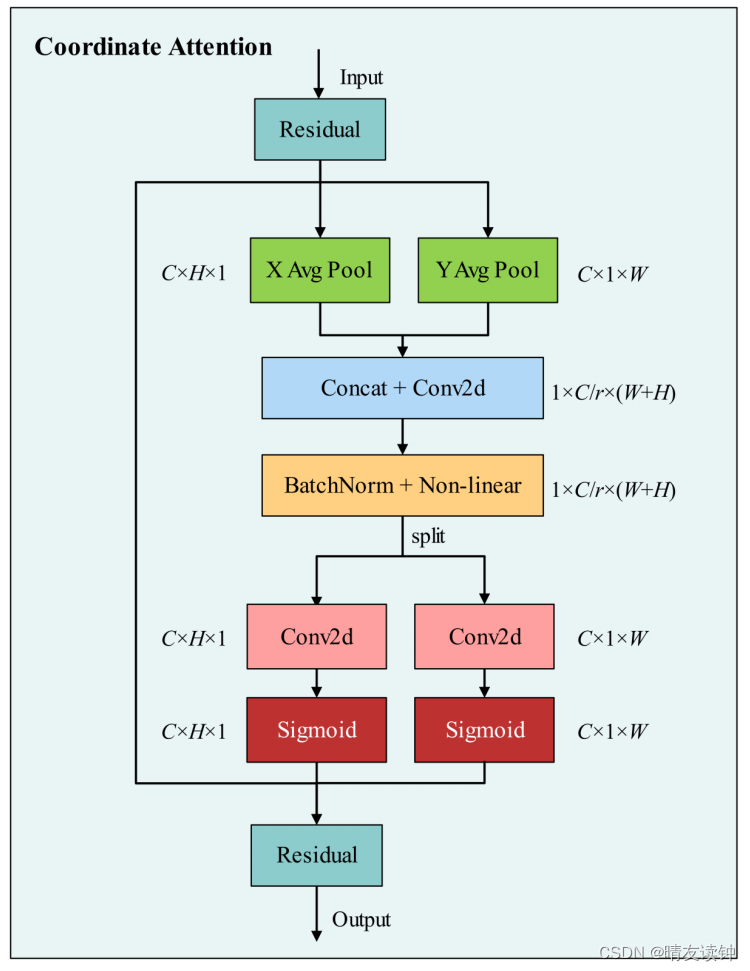
Fig. 4. CA module.
由于检测网络模型中的SPP属于池化操作,因此本文引入了用CA来代替SPP。它将全局池化分解为一对一维(1-D)特征编码操作。然后,两个一维全局池化操作沿着垂直和水平方向将输入特征聚合成两个独立的方向感知特征图,通过特征在空间中的转换,动态(dynamically)捕获特征图的长程依赖性(long-range dependency),将权重分配给缺陷特征的空间位置,增强检测网络对缺陷的关注,使检测网络更准确地定位感兴趣的对象。
E. EIoU Loss Function
近年来,在使用单阶段(one-stage)探测器检测带钢表面缺陷的算法中,一直忽略了IoU对检测网络整体检测效果的影响。为了弥补单阶段检测器在定位(positioning)上的不足(deficiency),本文用有效交叉联合(EIoU)损失函数代替IoU损失函数,不仅加快(accelerate)了检测网络在训练过程中的收敛速度(convergence rate),同时也提高了回归(regression)的准确性。EIoU损失函数公式定义为
接下来还是放原文方便对照公式解析,原文大意为:
其中,LIoU为IOU损失,Ldis为距离损失,Lasp为宽高比损失。IoU是交并比,ρ 2(b,b gt)/c 2是地面真实中心与锚框中心之间的欧氏距离,ρ 2(w,wgt)/c 2 w是地面真实宽度与锚框宽度之间的欧氏距离,ρ 2(h,h gt)/c 2 h是地面真实高度与锚框高度之间的欧氏距离。
EIoU损失函数可以提高网络对缺陷位置的回归能力,进一步提高检测网络的预测性能。


III. EXPERIMENTS AND RESULTS(实验结果)
本部分是实验结果与其它网络的对比,省略。
IV. CONCLUSION(总结)
针对带钢表面缺陷图像的一系列检测问题,提出了DCAM-Net。
首先,针对带钢表面缺陷图像的低对比度,引入了CLAHE作为数据增强方法。
其次,我们提出了一种新的EDE-block来捕获带钢表面缺陷的完整形态特征。
最后,引入了CA注意力模块来代替SPP结构,使网络能够更准确地定位带钢表面的缺陷特征。在NEU-DET数据集上的实验结果表明,该算法的检测速度为100.2fps,mAP为82.6%,证明了该方法在面对不规则缺陷特征时具有鲁棒性的特征提取能力。
虽然本文采用的方法可以取得很好的效果,但面对Cr缺陷(crazing,即开裂)等复杂的纹理缺陷特征,存在大量的噪声干扰仍会影响网络的学习,其特征提取能力有待进一步提高。
因此,未来的工作将从以下两个方面进行研究:
1)针对带钢表面缺陷的噪声问题,设计一种新的特征提取方法,通过减少噪声干扰来提高检测效果,增强缺陷特征;
2)改进标记方法,创建一种自我监督(self supervision)策略,以降低人工标记的成本。
到此本篇论文就完美收官了,下一篇博客将对该网络进行复现与细节讲解,敬请期待!
版权归原作者 晴友读钟 所有, 如有侵权,请联系我们删除。