
写在前面
1、本篇只列举一些特殊的查询方式,掌握这些查询语句的基本使用概念即可,实际用到的时候进行查询即可。
参考目录:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/dev/table/sql/queries/overview/
2、通过对这些例子的编写,感觉Flink相比hive中常见的查询方式,更多地从时间角度进行了更新迭代,需要注意Lookup Join和Temporal Joins区别
3、自定义函数,大致了解就行,后续用到直接套模板
1、Windowing table-valued functions (Windowing TVFs)
即:窗口表值函数
参考连接:https://nightlies.apache.org/flink/flink-docs-release-1.17/zh/docs/dev/table/sql/queries/window-tvf/
注:代码测试的时候使用的版本为1.14,这里不支持窗口函数的独立使用,具体使用见窗口聚合函数
以滑动窗口为例:
SELECT*FROMTABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime_ltz),INTERVAL'10' MINUTES));
error: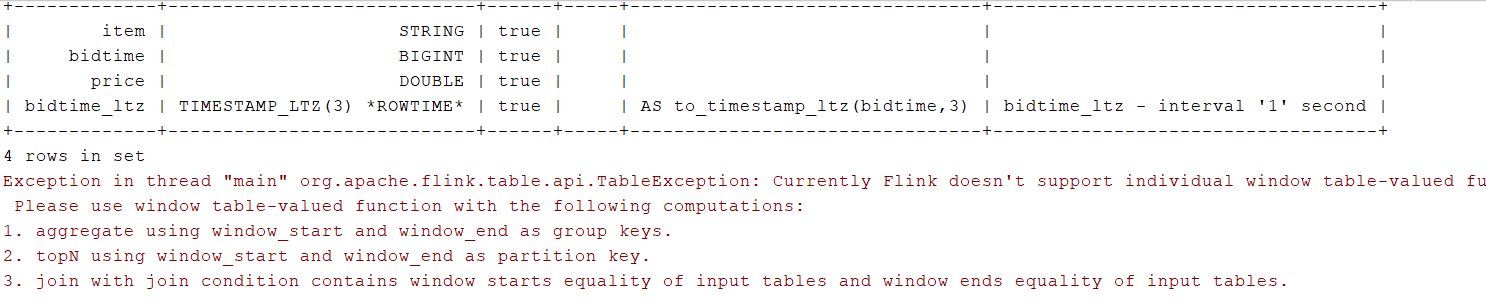
2、Window TVF Aggregation
即:窗口聚合
- 数据准备
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);StreamTableEnvironment tableEnvironment =StreamTableEnvironment.create(env,EnvironmentSettings.inStreamingMode());DataStreamSource<String> s1 = env.socketTextStream("123.56.100.37",9999);SingleOutputStreamOperator<Bid> s2 = s1.map(s ->{String[] split = s.split(",");DateTimeFormatter df =DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm");returnnewBid(LocalDateTime.parse(split[0],df),Double.valueOf(split[1]),split[2],split[3]);});//注:这里列声明的顺序和Bid一致,watermark才生效,测试过程中需注意
tableEnvironment.createTemporaryView("Bid",s2,Schema.newBuilder().column("item",DataTypes.STRING()).column("bidtime",DataTypes.TIMESTAMP(3)).column("price",DataTypes.DOUBLE()).column("supplier_id",DataTypes.STRING()).watermark("bidtime","bidtime - interval '1' second").build());
- hopping window aggregation 注:每分钟,计算最近5分钟的订单交易总额
SELECT window_start, window_end,SUM(price)AS sum_price
FROMTABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime),INTERVAL'1' MINUTES,INTERVAL'5' MINUTES))GROUPBY window_start, window_end;
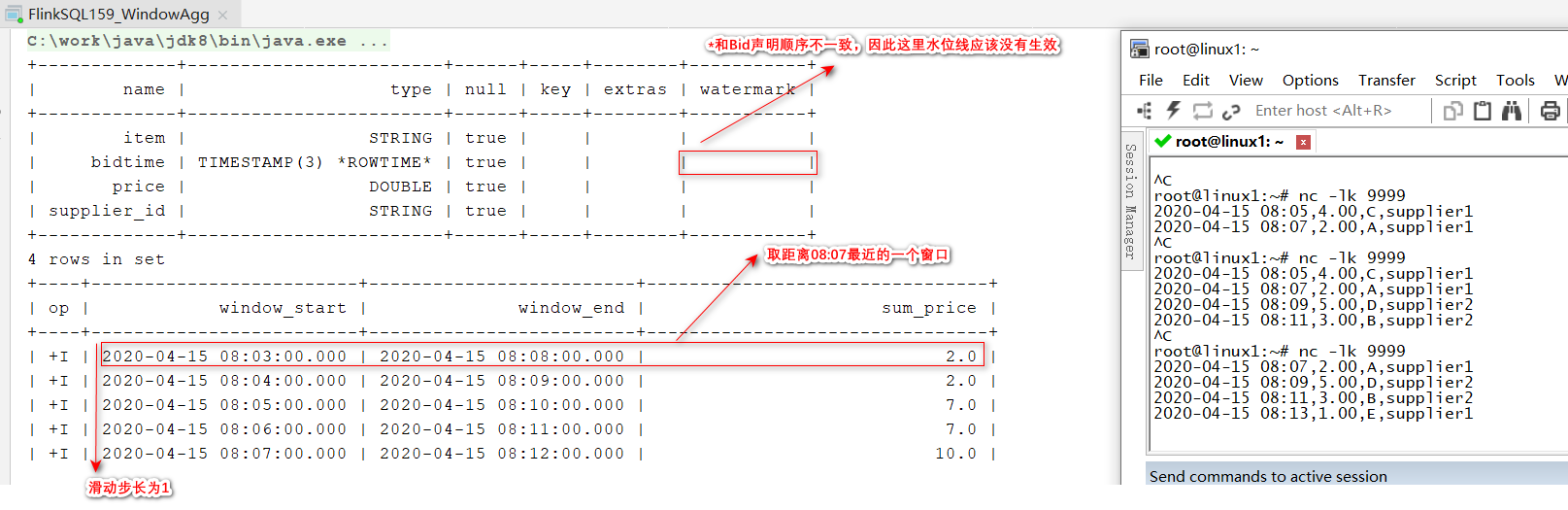
其他:
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
:每隔10分钟计算最近10分钟的price总和
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
:每隔10分钟,计算一个窗口里面每2分钟累积的price综合
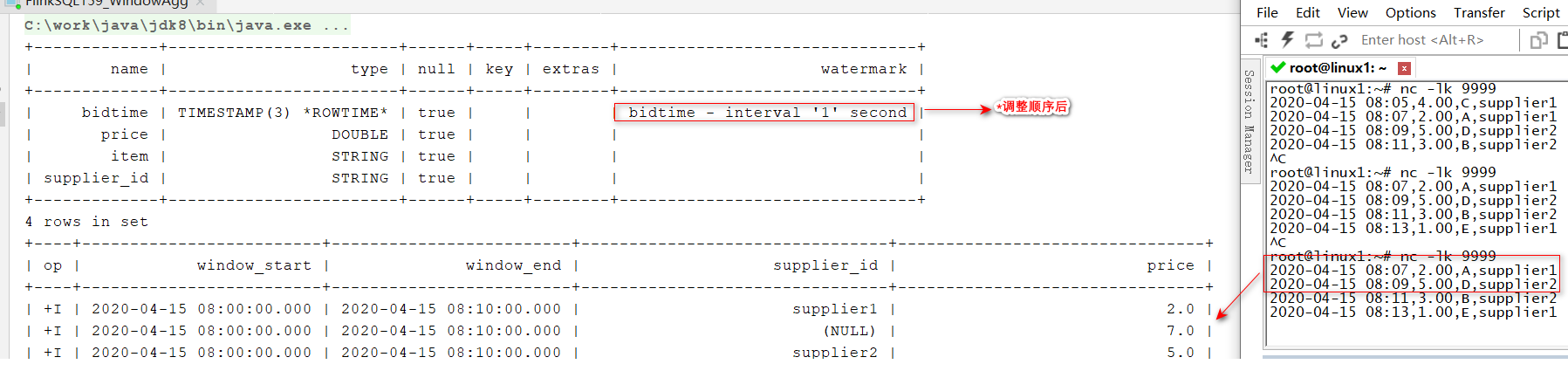
- GROUPING SETS
SELECT window_start, window_end, supplier_id,SUM(price)as price
FROMTABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime),INTERVAL'10' MINUTES))GROUPBY window_start, window_end, GROUPING SETS ((supplier_id),());
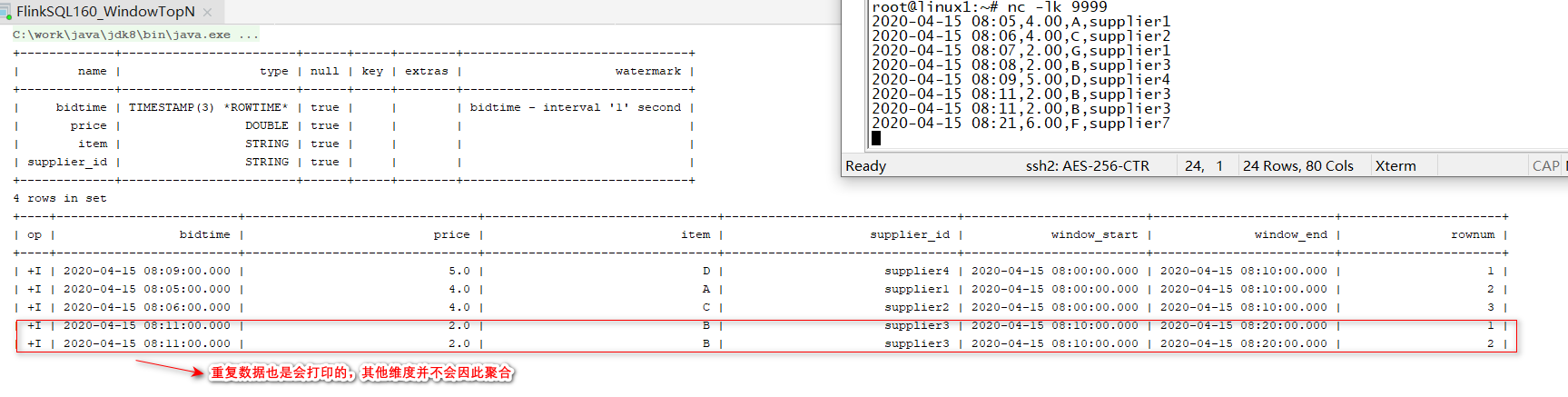
3、Window Top-N
语法要义:在 TVF上使用 row_number() over()
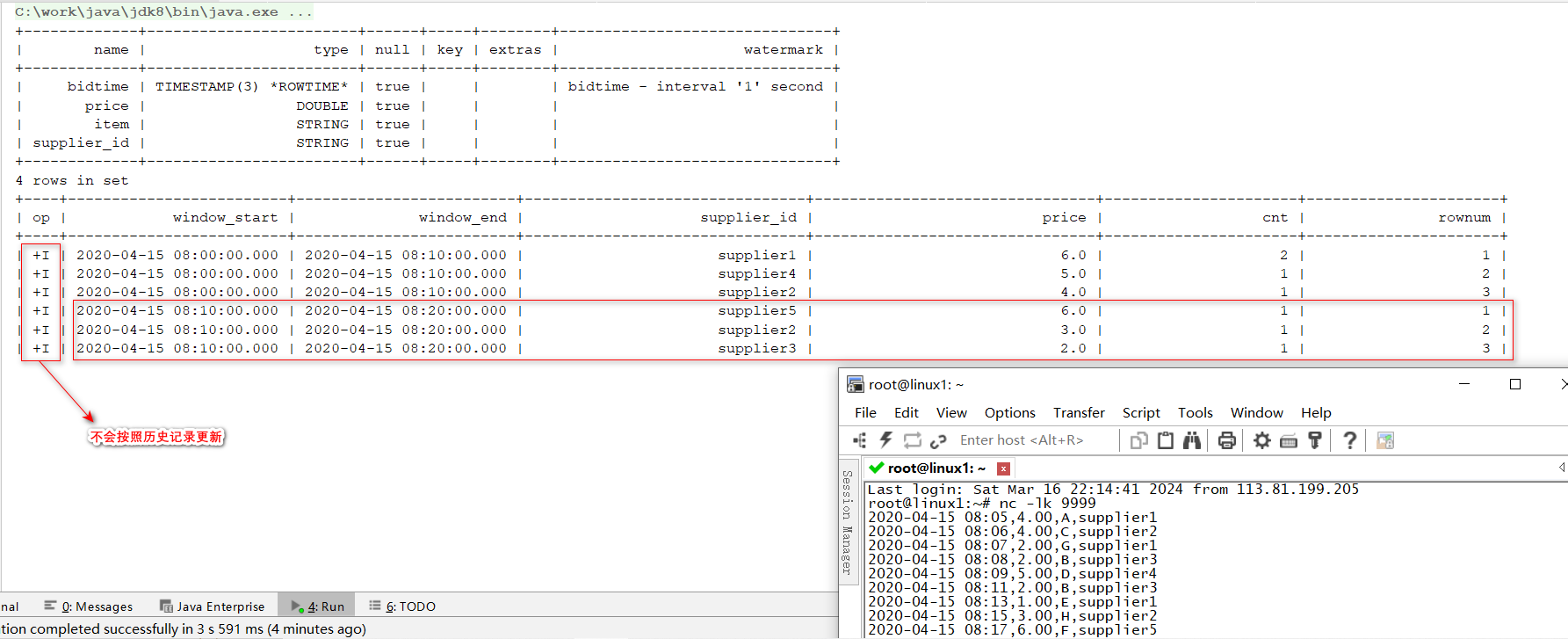
- Window Top-N follows after Window Aggregation 注:类似
分组TopN,不过这里【window_start、window_end】就充当了组的定义
SELECT*FROM(SELECT window_start,
window_end,
supplier_id,SUM(price)as price,COUNT(*)as cnt,
ROW_NUMBER()OVER(PARTITIONBY window_start, window_end ORDERBYSUM(price)DESC)as rownum
FROMTABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime),INTERVAL'10' MINUTES))GROUPBY window_start, window_end, supplier_id
)WHERE rownum <=3;
- Window Top-N follows after Windowing TVF 注:直接跟在TVF后面,详细查看TVF使用error的说明
SELECT*FROM(SELECT bidtime, price, item, supplier_id, window_start, window_end, ROW_NUMBER()OVER(PARTITIONBY window_start, window_end ORDERBY price DESC)as rownum
FROMTABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime),INTERVAL'10' MINUTES)))WHERE rownum <=3;
4、Window Join
参考连接:https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/dev/table/sql/queries/window-join/
- 测试环境构建核心环境
DataStreamSource<String> left1 = env.socketTextStream("123.56.100.37",9999);SingleOutputStreamOperator<DataTest> left2 = left1.map(s ->{String[] split = s.split(",");DateTimeFormatter df =DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm");returnnewDataTest(LocalDateTime.parse(split[0],df),Integer.valueOf(split[1]),split[2]);});DataStreamSource<String> right1 = env.socketTextStream("123.56.100.37",9998);SingleOutputStreamOperator<DataTest> right2 = right1.map(s ->{String[] split = s.split(",");DateTimeFormatter df =DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm");returnnewDataTest(LocalDateTime.parse(split[0],df),Integer.valueOf(split[1]),split[2]);});
- INNER/LEFT/RIGHT/FULL OUTER 测试代码:
SELECT L.num as L_Num,
L.id as L_Id,
R.num as R_Num,
R.id as R_Id,COALESCE(L.window_start, R.window_start)as window_start,COALESCE(L.window_end, R.window_end)as window_end
FROM(SELECT*FROMTABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time),INTERVAL'5' MINUTES))) L
FULLJOIN(SELECT*FROMTABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time),INTERVAL'5' MINUTES))) R
ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;
测试结果: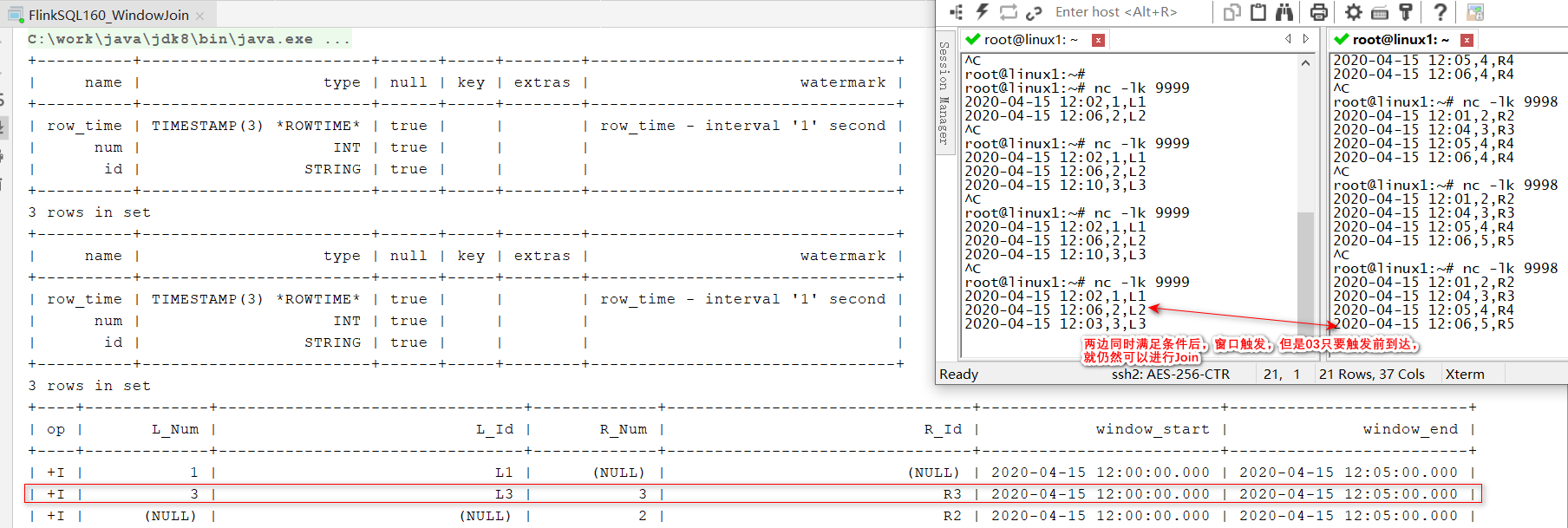
- SEMI JOIN 本质上是通过
select ... in (...sql...)实现的 测试代码:
SELECT num,id,row_time,window_start,window_end
FROM(SELECT*FROMTABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time),INTERVAL'5' MINUTES))) L
WHERE L.num IN(SELECT num FROM(SELECT*FROMTABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time),INTERVAL'5' MINUTES))) R
WHERE L.window_start = R.window_start AND L.window_end = R.window_end);
测试结果: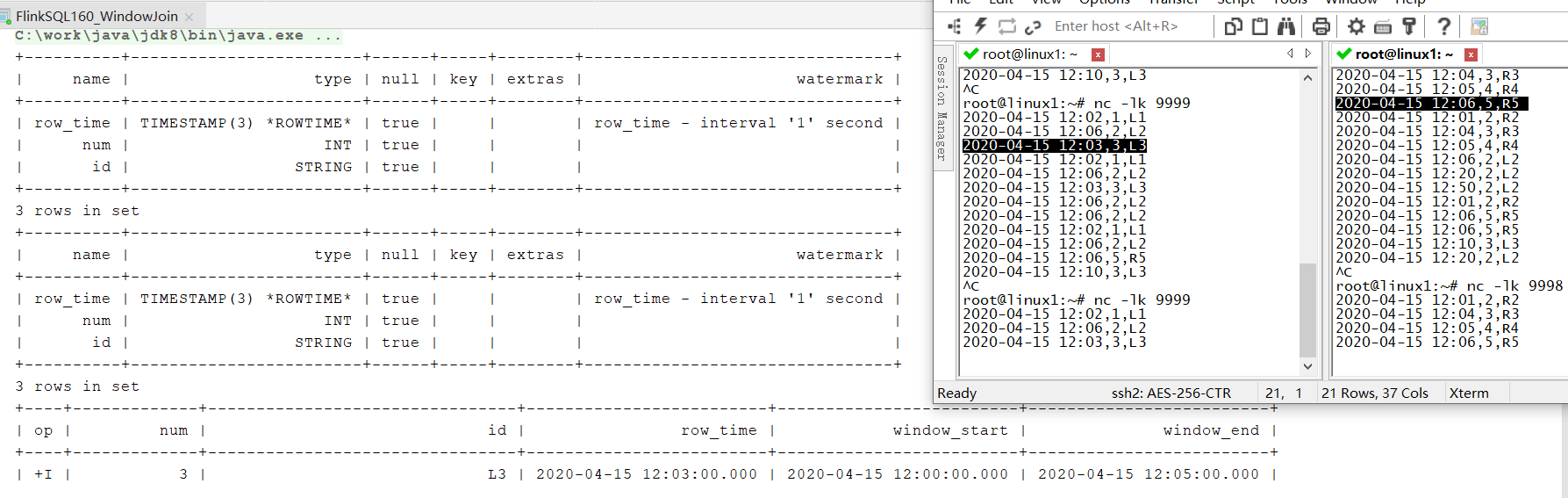
error:
参考连接:
- https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/table/sql/queries/window-tvf/
- https://issues.apache.org/jira/browse/FLINK-11220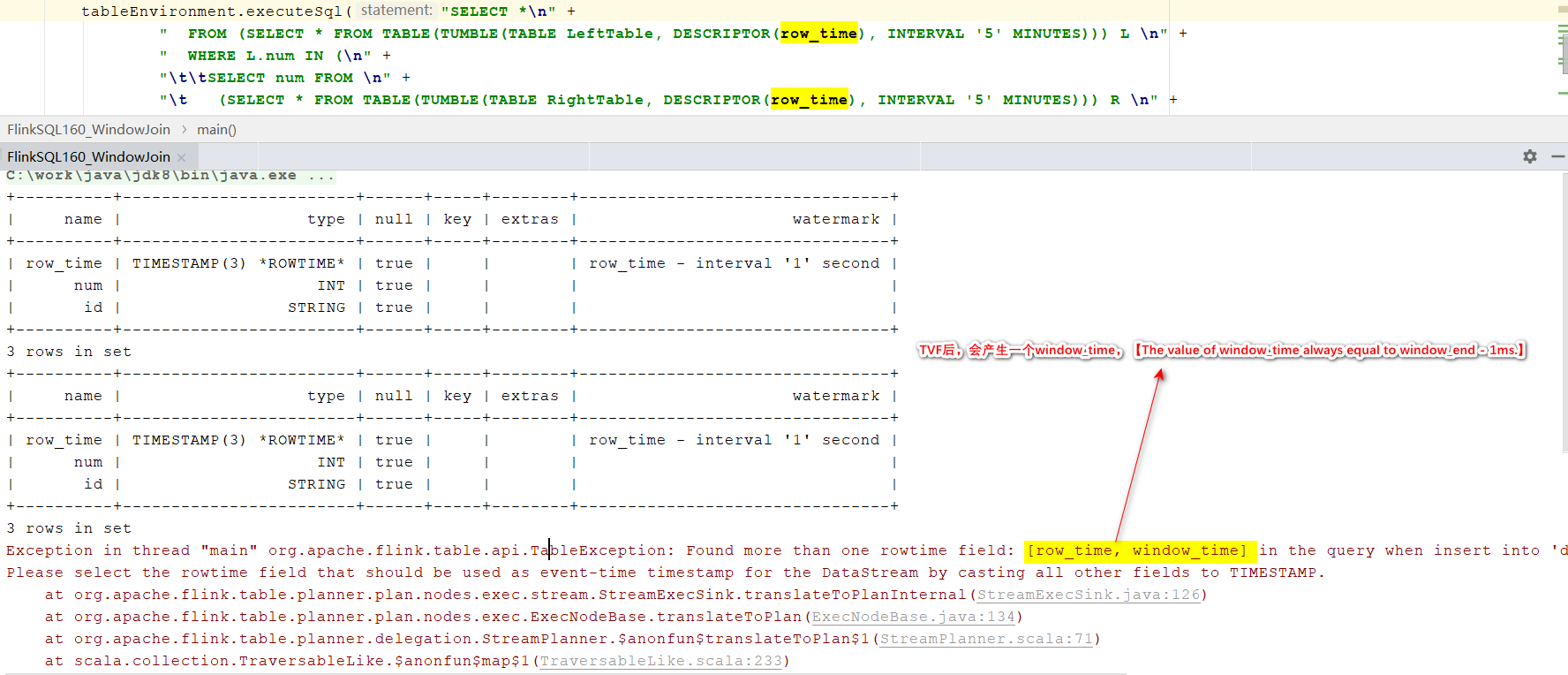
5、Join
常规 join的实现逻辑所在类:
org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator
常规 join,flink底层是会对两个参与 join的输入流中的数据进行状态存储的;所以,随着时间的推进,状态中的数据量会持续膨胀,可能会导致过于庞大,从而降低系统的整体效
率;
可以如何去缓解:自己根据自己业务系统数据特性(估算能产生关联的左表数据和右表数据到达的最
大时间差),根据这个最大时间差,去设置 ttl时长
配置参考链接:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/config/
5.1、Regular Joins
执行语句:
SELECT*FROM LeftTable LEFTJOIN RightTable ON LeftTable.id = RightTable.id;
执行结果: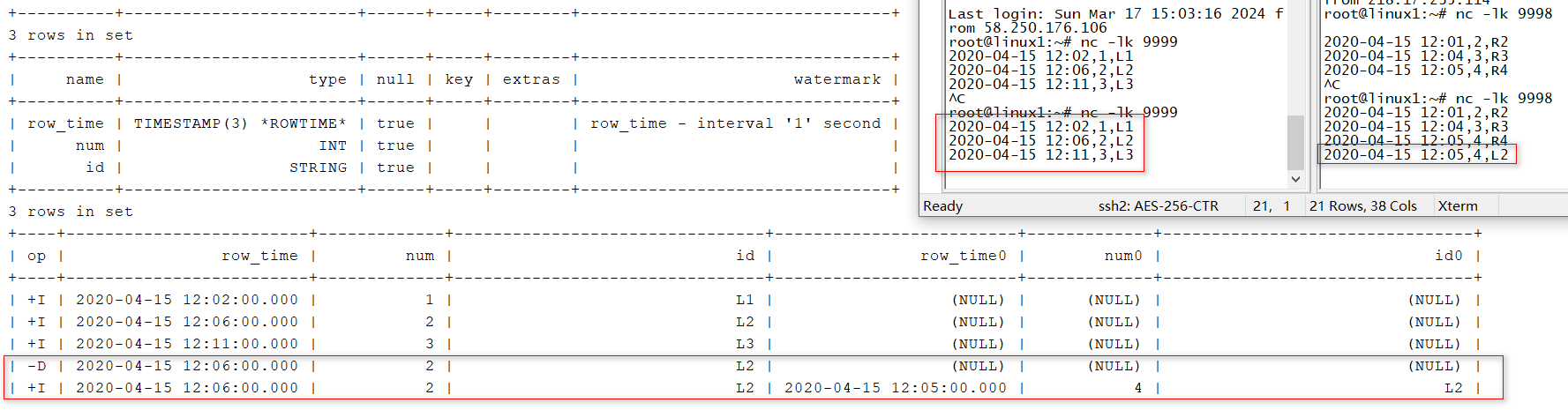
5.2、Lookup Join
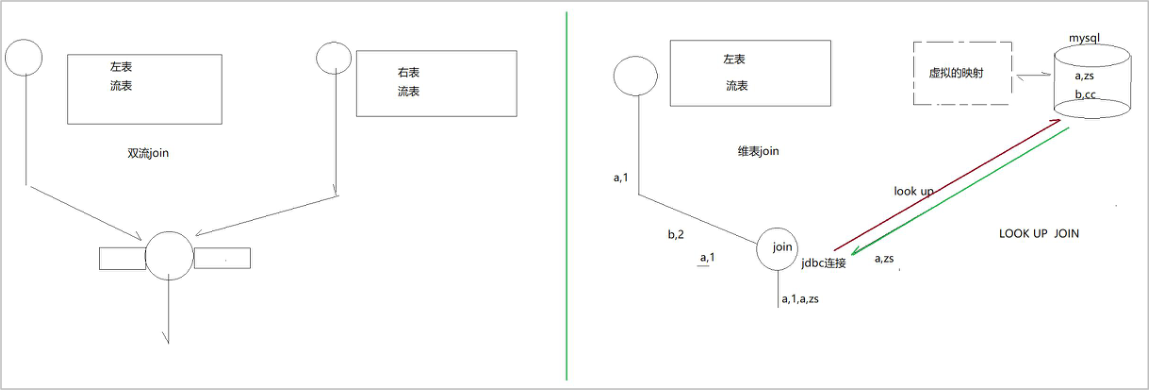
查找联接通常用于使用从外部系统查询的数据来扩充表。联接要求一个表具有处理时间属性,另一个表由查找源连接器提供支持。查找联接使用上述处理时临时联接语法,以及由查找源连接器支持的正确表。
lookup join
为了提高性能,lookup的连接器会将查询过的维表数据进行缓存(默认未开启此机制),可以通过参数开启,比如 jdbc-connector的 lookup模式下,有如下参数:
- lookup.cache.max-rows = (none) 未开启
- lookup.cache.ttl = (none) ttl缓存清除的时长
执行语句:
- 创建SQL表,
创建 lookup维表(jdbc connector表)
CREATETEMPORARYTABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
)WITH('connector'='jdbc','url'='jdbc:mysql://123.56.100.37:3306/flinktest','table-name'='customers','username'='root','password'='123456')
- 执行lookup join
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME ASOF o.proc_time AS c
ON o.customer_id = c.id
执行结果: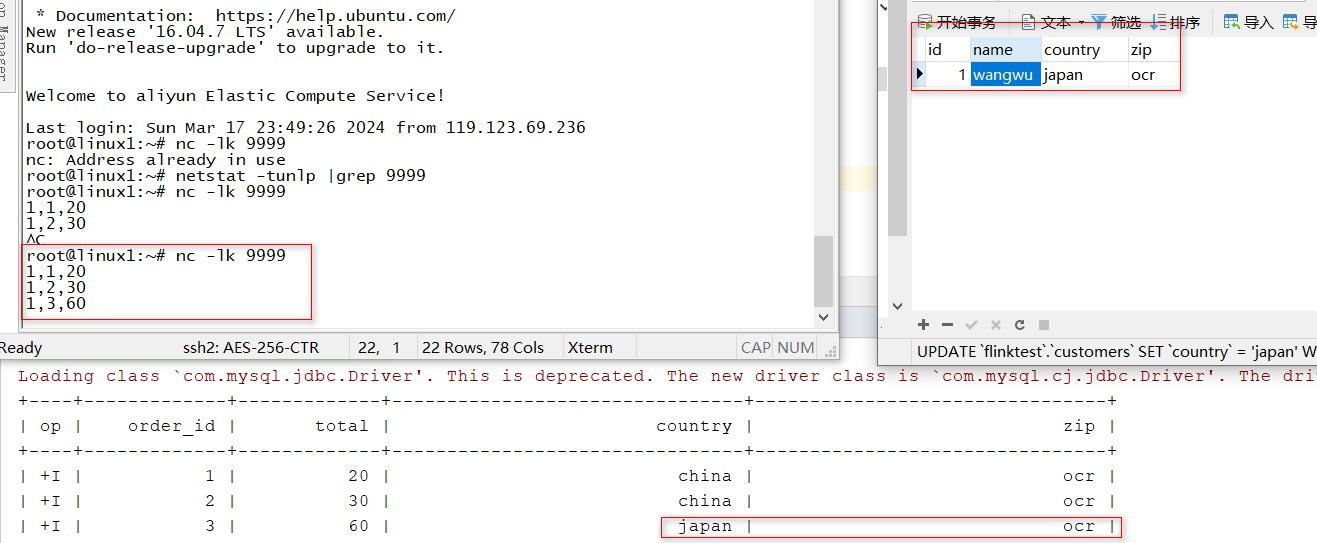
5.3、Interval Joins
举例说明:比如广告曝光流和广告观看事件流的 join
对于这种join,目前并没有实际遇到过,因此这里只给出相关限制条件,具体用到后可以参考官网。
- ltime = rtime
- ltime >= rtime AND ltime < rtime + INTERVAL ‘10’ MINUTE
- ltime BETWEEN rtime - INTERVAL ‘10’ SECOND AND rtime + INTERVAL ‘5’ SECOND
5.4、Temporal Joins
要义: 左表的数据永远去关联右表数据的对应时间上的版本
注:Flink会根据
版本表
的记录自动推测在对于位置上的时间,可以推测成功即关联上;这里以
Event Time Temporal Join
举例说明
- 创建order表
tableEnvironment.createTemporaryView("orders",s2,Schema.newBuilder().column("order_id",DataTypes.STRING()).column("price",DataTypes.DECIMAL(32,2)).column("currency",DataTypes.STRING()).column("order_time",DataTypes.TIMESTAMP(3)).watermark("order_time","order_time - INTERVAL '0' SECOND").build());
- 创建汇率表,即版本表
CREATETABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32,2),
update_time TIMESTAMP(3),
WATERMARK FOR update_time AS update_time -INTERVAL'0'SECOND,PRIMARYKEY(currency)NOT ENFORCED
)WITH('connector'='mysql-cdc','hostname'='123.56.100.37','port'='3306','username'='root','password'='123456','database-name'='flinktest','table-name'='currency_rates','server-time-zone'='Asia/Shanghai');
- join语句
SELECT order_id,
price,
orders.currency,
conversion_rate,
order_time,
update_time
FROM orders
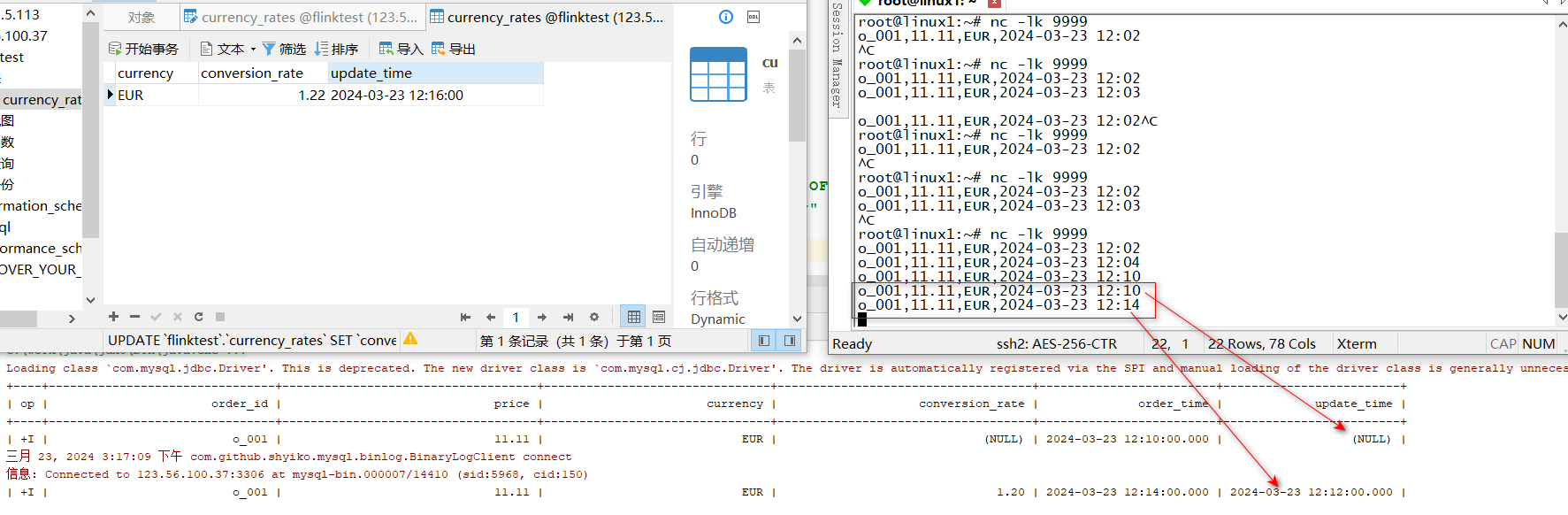
LEFTJOIN currency_rates FOR SYSTEM_TIME ASOF orders.order_time
ON orders.currency = currency_rates.currency
- 运行测试 12:10分的order来的时候,currency_rates的汇率为1.20,时间戳位12:12,因此order对于12:10的记录无法找到对应汇率值;12:14分的order来的时候,currency_rates汇率已经改为1.22,时间戳更新为12:16,因此推测,12:14分order的汇率应该还是1.20
5.5、Array Expansion(CROSS JOIN)
为给定数组中的每个元素返回一个新行
(数组的行转列)
- 测试数据
Tabletable= tableEnvironment.fromValues(DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.INT()),
DataTypes.FIELD("name", DataTypes.STRING()),
DataTypes.FIELD("phone_numbers", DataTypes.ARRAY(DataTypes.STRING()))),Row.of(1,"zs", Expressions.array("137","138","125")),Row.of(2,"ls", Expressions.array("159","126","199")));
tableEnvironment.createTemporaryView("phone_table",table);
- SQL语句
SELECT id,name,phone_numbers,phone_number
from phone_table
CROSSJOIN UNNEST(phone_numbers)AS t(phone_number)
测试结果: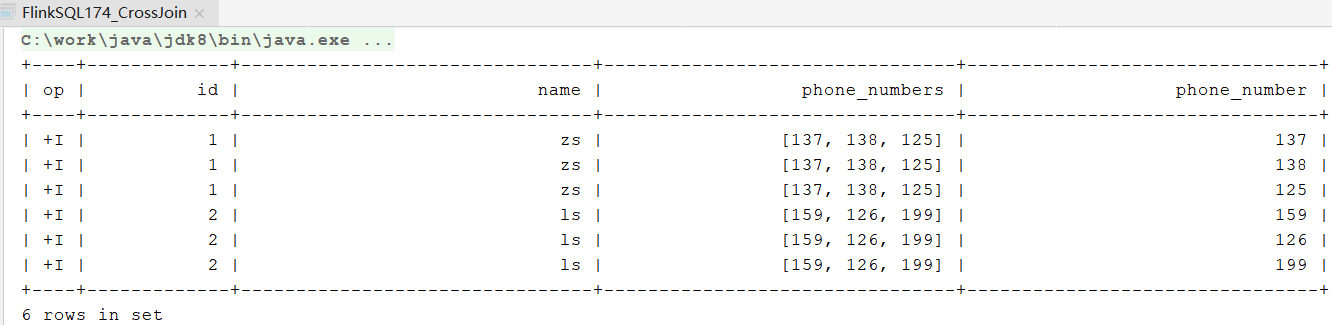
6、Over Aggregation
row_number( ) over ( )
flinksql中,over聚合时,指定聚合数据区间有两种方式
- 方式 1,带时间设定区间
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW - 方式 2,按行设定区间
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
over函数类似在hive中的使用,这里不列举了,给出一个简单的SQL语法格式,详细参考官网
SELECT
agg_func(agg_col)OVER([PARTITIONBY col1[, col2,...]]ORDERBY time_col
range_definition),...FROM...
7、User-defined Functions
7.1、Scalar Functions
标量函数,特点:每次只接收一行数据,输出结果也是1行1列
- 继承ScalarFunction,实现eval方法
publicstaticclassMyLowerextendsScalarFunction{publicStringeval(String input){return input.toLowerCase();}}
- 注册函数
tableEnvironment.createTemporaryFunction("myLower",MyLower.class);
- 执行SQL语句
select*,myLower(currency)as myLower from currency_rates
- 执行结果

7.2、Aggregate Functions
聚合函数,特点:对输入的数据行(一组)进行持续的聚合,最终对每组数据输出一行(多列)结果
- 自定义累加器
publicstaticclassMyAccumulator{publicint count;publicint sum;}
- 继承AggregateFunction,
至少实现下面三个方法
- createAccumulator()
- accumulate()
- getValue()
publicstaticclassMyAvgextendsAggregateFunction<Double,MyAccumulator>{// Creates and init the Accumulator for this (table)aggregate function.@OverridepublicMyAccumulatorcreateAccumulator(){MyAccumulatorMyAccumulator=newMyAccumulator();MyAccumulator.count =0;MyAccumulator.sum =0;returnMyAccumulator;}// rocesses the input values and update the provided accumulator instancepublicvoidaccumulate(MyAccumulator acc,Double rate){
acc.sum += rate;
acc.count +=1;}// Retracts the input values from the accumulator instance. publicvoidretract(MyAccumulator acc,Double rate){
acc.sum -= rate;
acc.count -=1;}//Called every time when an aggregation result should be materialized.@OverridepublicDoublegetValue(MyAccumulator accumulator){return accumulator.sum/accumulator.count;}}
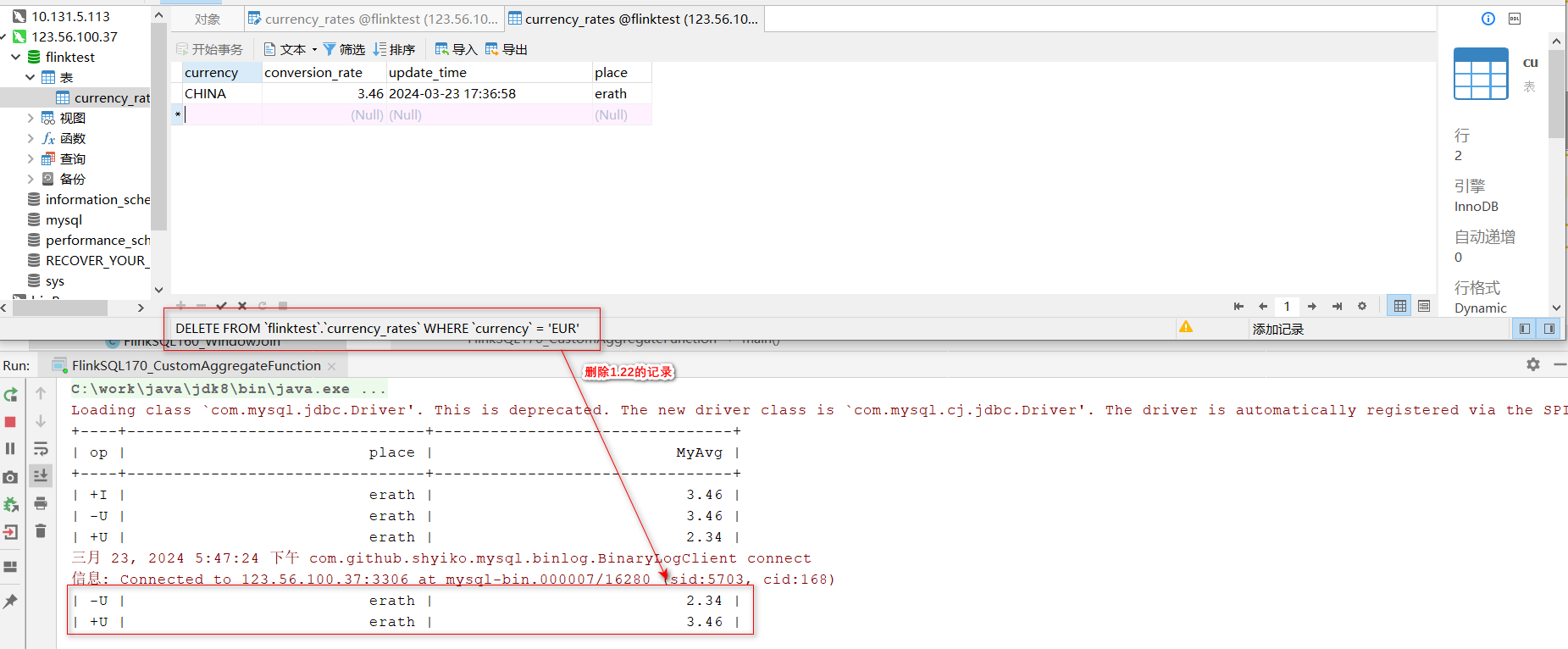
- 执行SQL语句 注:这里用Flink-CDC提示,必须实现retract函数,因此上面加上了;实际证明这个函数可以帮助我们记录group by结果的变化情况
select place,MyAvg(conversion_rate)as MyAvg from currency_rates groupby place
- 执行结果
7.3、Table Functions
表值函数,特点:运行时每接收一行数据(一个或多个字段),能产出多行、多列的结果;如:explode(), unnest()
注:其实这种方式就相当于产出一张表,Flink中对于数组类型的行转列可以参考
5.5、Array Expansion
- 自定义表值函数,分割字符串;
并注册函数
@FunctionHint(output =@DataTypeHint("ROW<phoneNumber STRING, phoneLength INT>"))public static class MySplitFunction extends TableFunction<Row> {
public void eval(String str) {
for(String phone : str.split(",")) {
// use collect(...) to emit a row
collect(Row.of(phone, phone.length()));
}
}
}
- 编写SQL语句
SELECT id,name,phone_numbers,phone_number,phone_length
FROM phone_table
LEFTJOIN LATERAL TABLE(MySplitFunction(phone_numbers))AS T(phone_number, phone_length)ONTRUE
运行结果:
7.4、Table Aggregate Functions
表值聚合函数,特点:对输入的数据行(一组)进行持续的聚合,最终对每组数据输出一行或多行(多列)结果,
目前不支持SQL语法,只能通过tableAPI实现
下面以
分组top2
为例说明实现过程,相比传统的分组Top2,这种方式可以带出更多的字段
- 创建测试数据
Tabletable= tableEnvironment.fromValues(DataTypes.ROW(
DataTypes.FIELD("id", DataTypes.INT()),
DataTypes.FIELD("gender", DataTypes.STRING()),
DataTypes.FIELD("score", DataTypes.DOUBLE())),Row.of(1,"male","98"),Row.of(2,"male","76"),Row.of(3,"male","99"),Row.of(4,"female","44"),Row.of(5,"female","76"),Row.of(6,"female","86"));
tableEnvironment.createTemporaryView("stu_score",table);
- 自定义Top2函数,即表值聚合函数
publicstaticclassTop2Accum{//emitValue()根据Top2Accum数据提交,因此如果要整行数据,Top2Accum需要定义为Row类型public@DataTypeHint("ROW<id INT, gender STRING, score DOUBLE>")Row first;public@DataTypeHint("ROW<id INT, gender STRING, score DOUBLE>")Row second;}//这里groupBy的gender会一直带出来,输出的时候也会检查字段是否重复,需要将和groupBy相关的字段重命名@FunctionHint(input =@DataTypeHint("ROW<id INT, gender STRING, score DOUBLE>"),output =@DataTypeHint("ROW<id INT, rgender STRING, score DOUBLE,rank INT>"))publicstaticclassTop2extendsTableAggregateFunction<Row,Top2Accum>{@OverridepublicTop2AccumcreateAccumulator(){Top2Accum top2Accum =newTop2Accum();
top2Accum.first =null;
top2Accum.second =null;return top2Accum;}//这些需要封装一整个Row给Top2Accum,因此传入Rowpublicvoidaccumulate(Top2Accum acc,Row row){Double score =(Double) row.getField(2);if(acc.first ==null||score >(double)acc.first.getField(2)){
acc.second = acc.first;
acc.first = row;}elseif(acc.second ==null|| score >(double)acc.second.getField(2)){
acc.second = row;}}publicvoidmerge(Top2Accum acc,Iterable<Top2Accum> iterable){for(Top2Accum otherAcc : iterable){accumulate(acc, otherAcc.first);accumulate(acc, otherAcc.second);}}publicvoidemitValue(Top2Accum acc,Collector<Row> out){// emit the value and rankif(acc.first !=null){
out.collect(Row.of(acc.first.getField(0),acc.first.getField(1),acc.first.getField(2),1));}if(acc.second !=null){
out.collect(Row.of(acc.second.getField(0),acc.second.getField(1),acc.second.getField(2),2));}}}
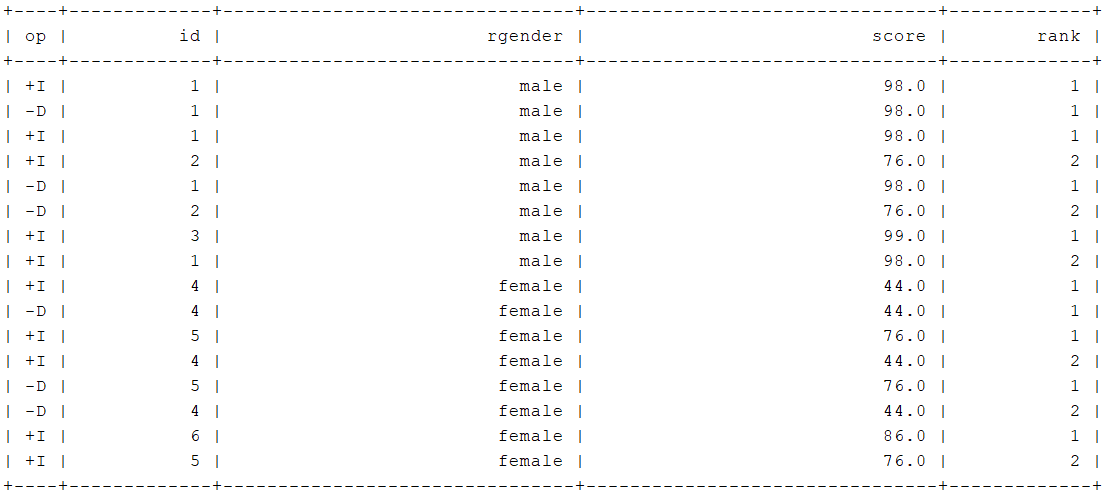
- 通过TableAPI编程
table.groupBy($("gender")).flatAggregate(call(Top2.class,row($("id"), $("gender"), $("score")))).select($("id"),$("rgender"), $("score"),$("rank")).execute().print();
- 测试结果
版权归原作者 星星点灯1966 所有, 如有侵权,请联系我们删除。