
文章目录
hive 查询语句
一、select 句式
查询员工表employess_table 包含了几个部门
输入命令: select * from employess_table 查看员工表的所有信息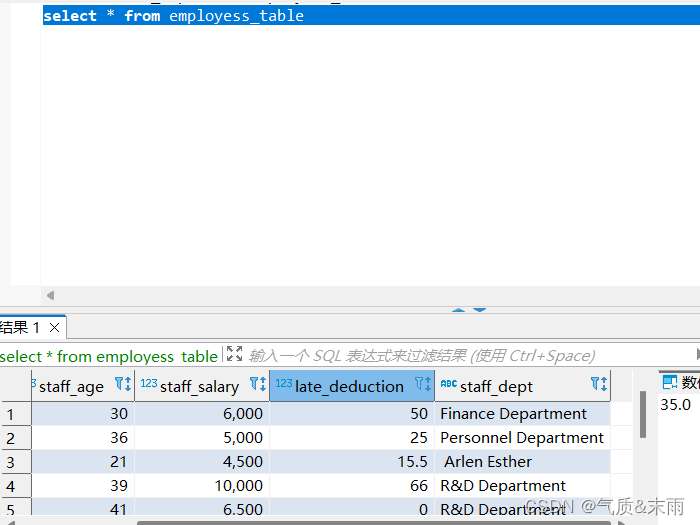
输入命令: select distinct staff_dept from employess 对员工信息表的部门字段进行查询,distinct 去重 查看出来了员工信息表有五个部门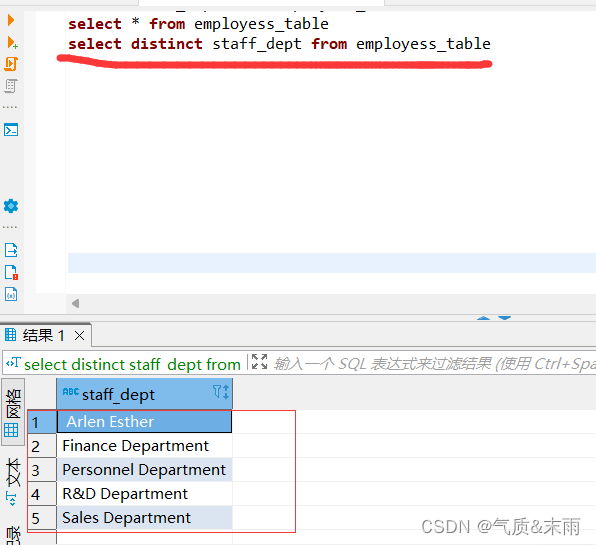
二、Having子句
HAVING子句的用法与WHERE子句的用法一致,都是在查询语句中指定查询条件,不同的是HAVING子句中可以使用聚合函数,并且HAVING子句必须配合GROUP BY子句一同使用,而WHERE子句中不能使用聚合函数,例如查询每个部门平均薪资大于5000的部门,具体命令如下
输入命令
查询员工信息表有平均薪资大于5000的部门
输入命令: select staff_dept from emplyess_table group by staff_table having AVG(staff_salary) > 5000 注意having 一定要 配聚合函数 group by 而where 不可以用聚合函数 gropy by 聚合的那个字段在前面的字段里面去找,要是只有一个那肯定就是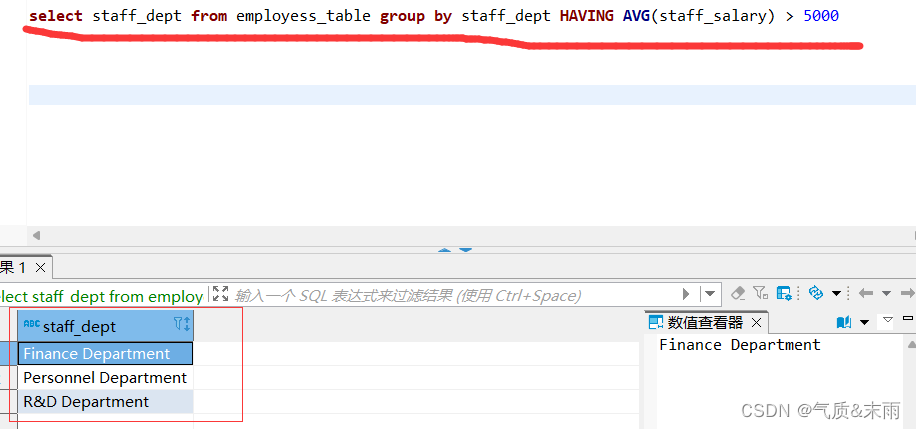
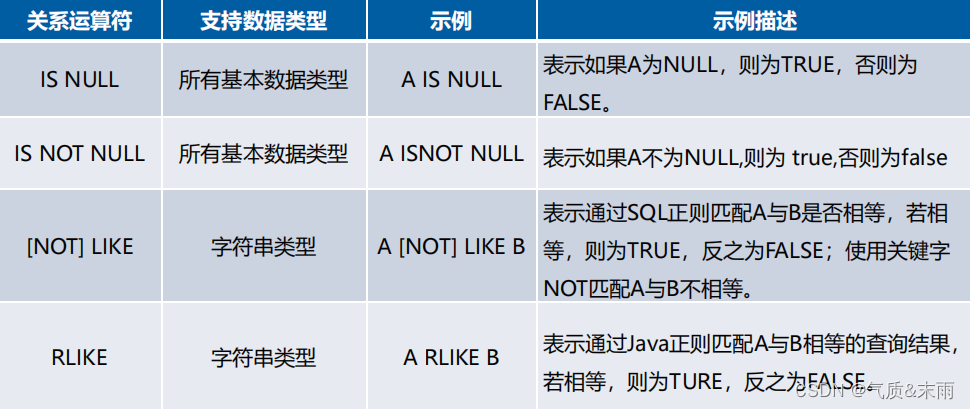
三、关系运算符
关系运算符通常在SELECT句式的WHERE子句中使用,用来比较两个操作数,下面通过一张表来介绍Hive内置的常用关系运算符。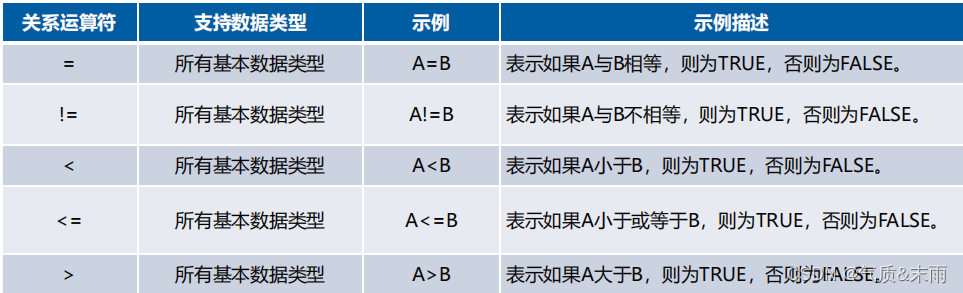

1、查询员工信息表中年龄信息为36岁的员工信息
输入命令: select * from employess_table where staff_table = 36 查询出年龄为36岁的员工信息,有两条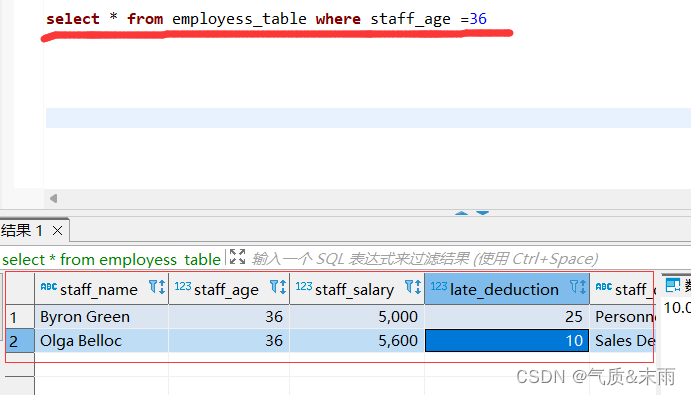
2、查询员工信息表中部门Personnel Department的所有员工信息
输入命令: select * from employess_table where staff_dept like “P%” %是通配符代表所有的,注意使用了模糊查询 like 就不能有=了,相当于是替代了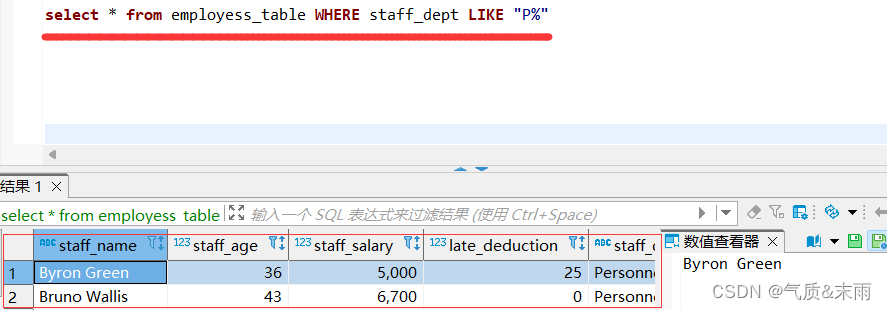
3、查询员工姓名首字母
输入命令: select * from employess_table where staff_name like “D% || A%”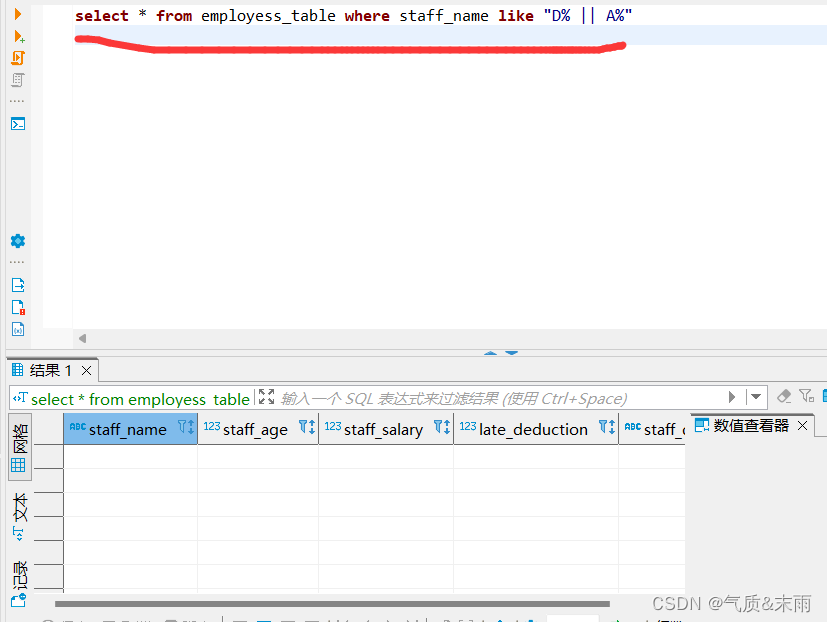
对这个表的所有员工姓名字段进行查询,发现根本没有A开头的名字,所以上面D||A会查询为空
四、算数运算符
算数运算符是用来计算两个数值的操作,下面通过一张表来介绍Hive内置的常用算数运算符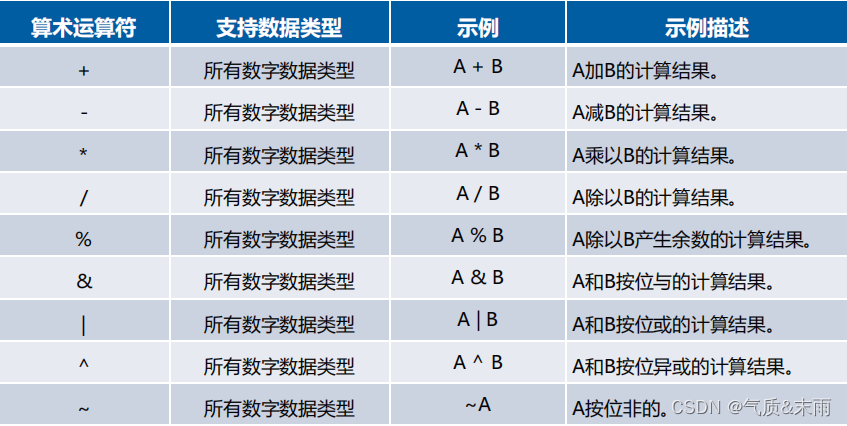
计算员工信息表employess_table中所有员工的实际工资
输入命令: select staff_name,staff_salary from employess_table 把员工的信息还有工资查询出来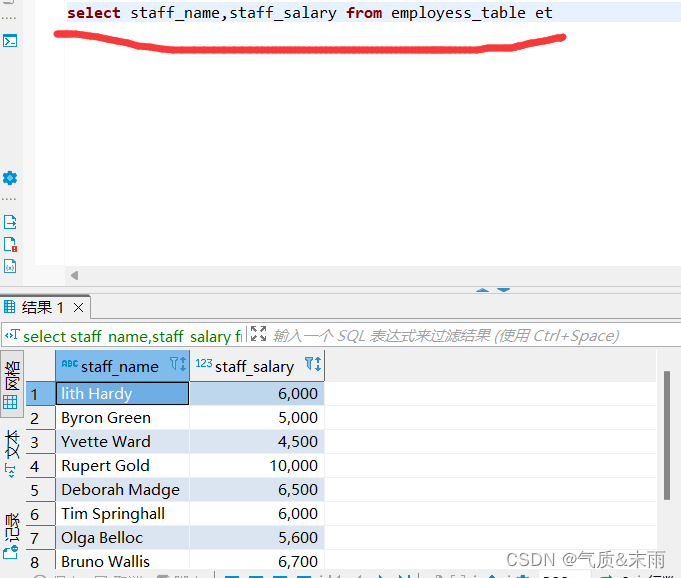
计算员工信息表每位员工每天的薪资,以单月工作日为20天计算
输入命令:select staff_name,staff_salary / 20 from employess_table 在前面工资字段直接除以20,直接就查询出来了每一天的工资,不用在后面用where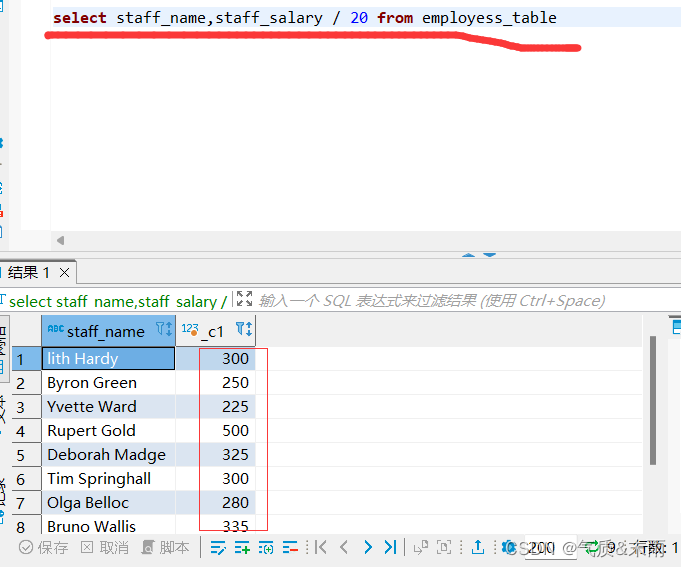
五、逻辑运算符
逻辑运算符可以将两个或者多个关系表达式合并为一个表达式或者反转表达式的逻辑。下面通过一张表来介绍Hive内置的常用逻辑运算符: and &&是与的意思,or || 是或的意思, ! not 是非的意思
查询员工信息表employess_table中薪资大于等于5000,并且薪资小于等于8000的员工信息
输入命令: select * from employess_table where staff_salary>=5000 and staff_salary <= 8000 查询出有六条信息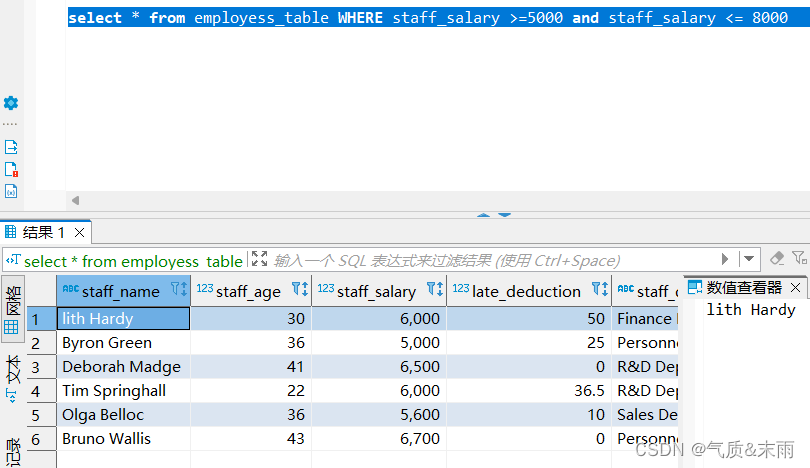
六、复杂运算符
复杂运算符用于操作Hive集合数据类型的列,集合数据类型包括array(数据),map,或struct 下面通过一张表来介绍Hive内置的复杂运算符
1、查询学生考级成绩表student_exam_table中所有学生的第一个意向大学
先输入命令: select * from student_exam_table 查看表里的志愿一共有多少个
可以看到intent_university 字段是用字典装的,一个学生有三个志愿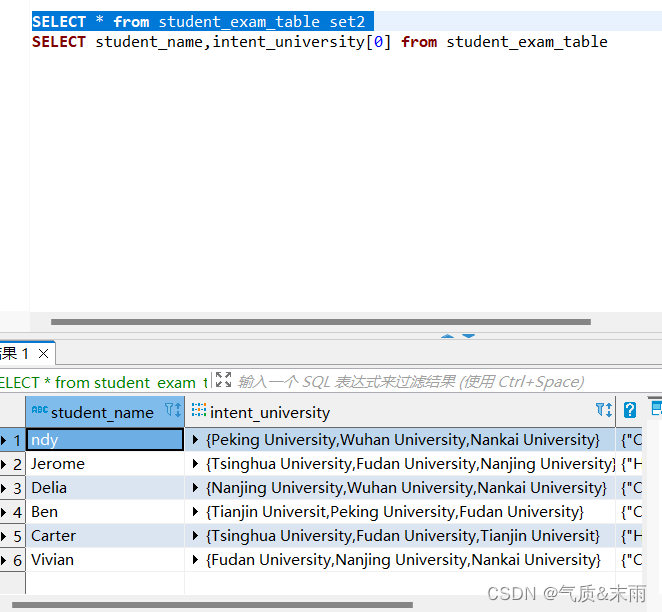
输入命令: select student_name,intent_university[0] from student_exam_table
取出intent_university 字段字典中的第一个元素,就是学生的第一个志愿 用到了复杂运算符中的复杂数据类型 array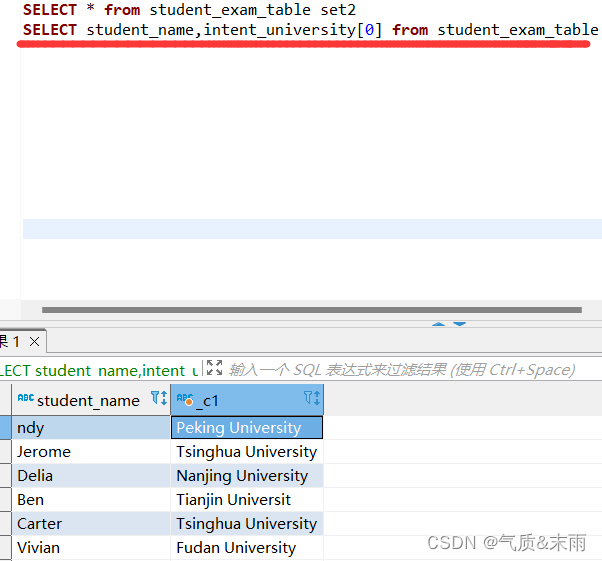
2、查询学生考试成绩表student_exam_table中学生的物理或历史成绩
输入命令:select student_name,humanities_or_sciences[‘History’],humanities_or_sciences[‘Physics’] from student_exam_table 这样就查询出了 物理和历史科目的成绩 用到了复杂运算符中的map M[key],返回括号里的key指定的value值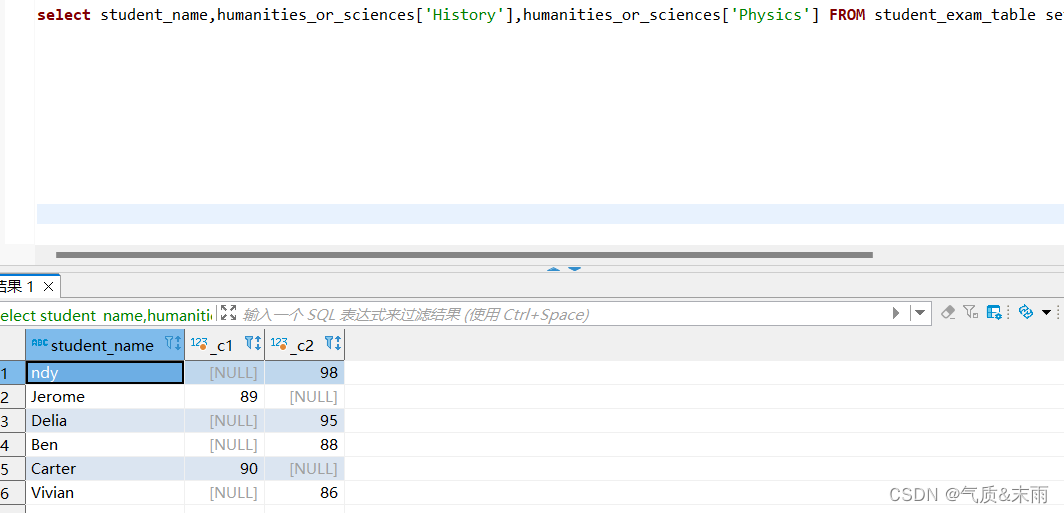
3、查询学生考试成绩表student_exam_table中所有学生的数学成绩
数学成绩是在comprehensive 这个字段里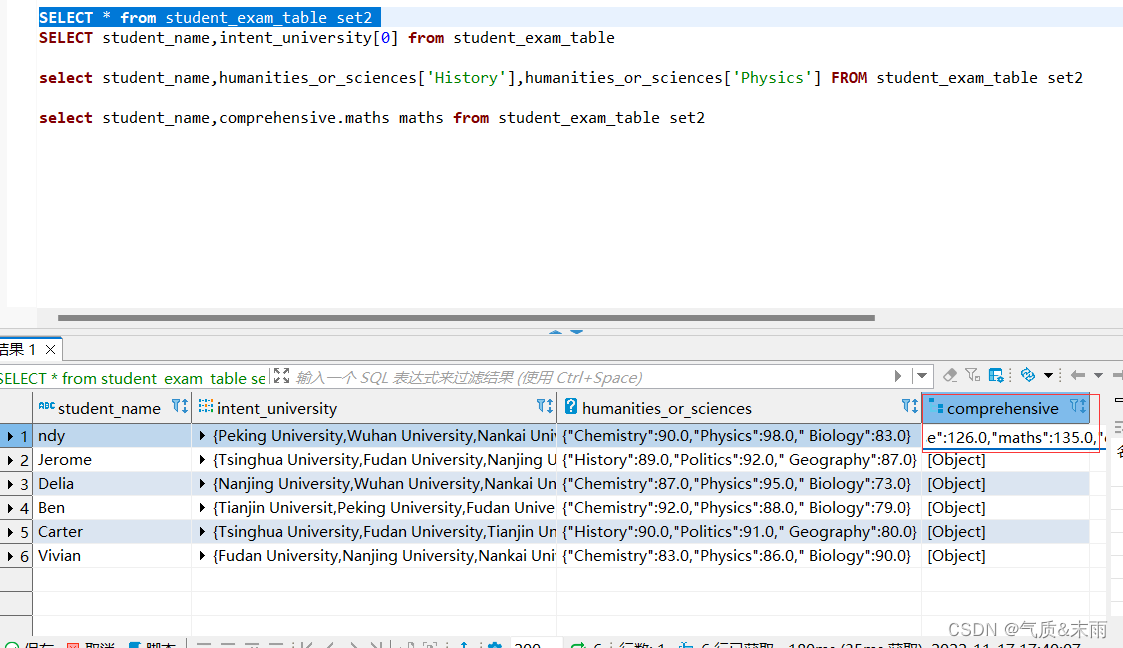
输入命令:select student_name,comprehensive.maths maths from student_exam_table comprehensive.maths 将这个字段下的maths取出,进行查询就查出来了所有的数学成绩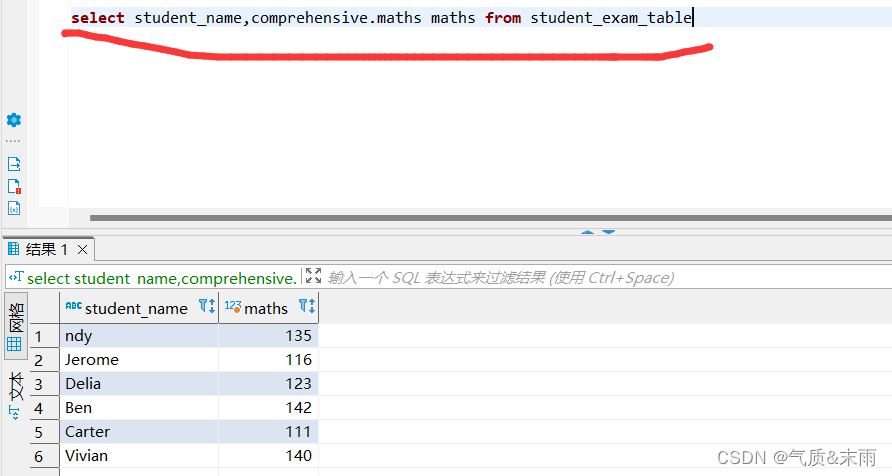
七、分组操作
分组操作是按照数据表某一列或多列的值进行分组,将相同的值放在一组,执行操作时触发MapReduce 任务进行处理,分组是通过select语句中的子句group by实现
分组查询员工信息表employess_table的部门
输入命令: select staff_dept from group by staff_dept 注意前面查询的字段一定要有后面分组的字段,不能直接*,后面没有条件判断的话也最好不要用where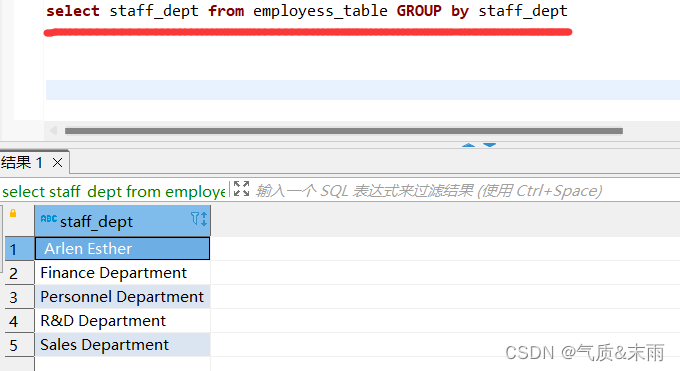
八、排序操作
1,order by(全局排序)
order by 用来对查询结果进行全局排序,查询的结果集只会交由一个Reducer处理,如果查询的结果集数据量较大,建议order by 和 limlt子句一同使用,目的是为了控制全局排序的显示条数。
2,sort by(局部排序)
sort by 用来对查询结果做局部排序,根据Mapreduce默认划分Reducer个数的规则,将查询结果集交由多个Reduce处理,sort by 会对每个Reducer进行排序,每个Reducer中的数据都是有序的。
3,查询商品销售表sales_table中销售额排名前十的省份以及城市
输入命令: select * from sales_table order by sales_amout desc limit 10 对销售表中的sales_amout字段进行全局排序,使用desc 进行倒序,使用limit方法只取前十条信息,注意后面要是没有条件的话就不要使用where,不然会报错。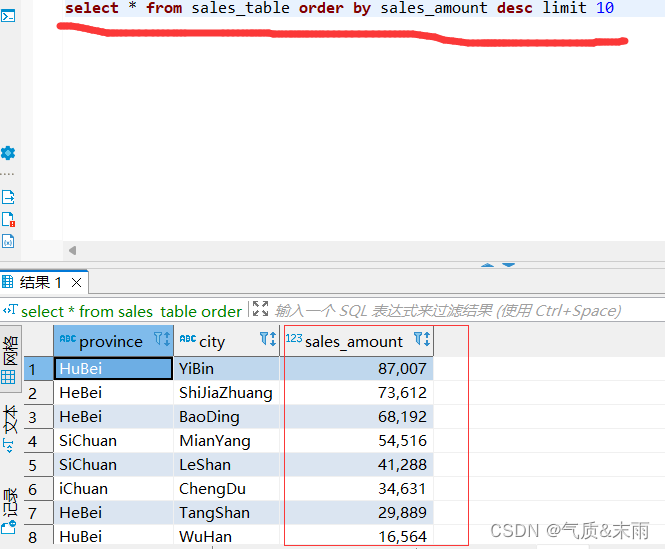
4,对商品销售表中不同省份内每个城市的销售额进行排序
1、使用order by 全局排序,对province省份和sales_amount销售额进行降序,注意要同时对两个字段进行排序。
输入命令: select * from sales_table order by province desc,sales_amount desc; 这个和下面的局部排序的效果是一样的。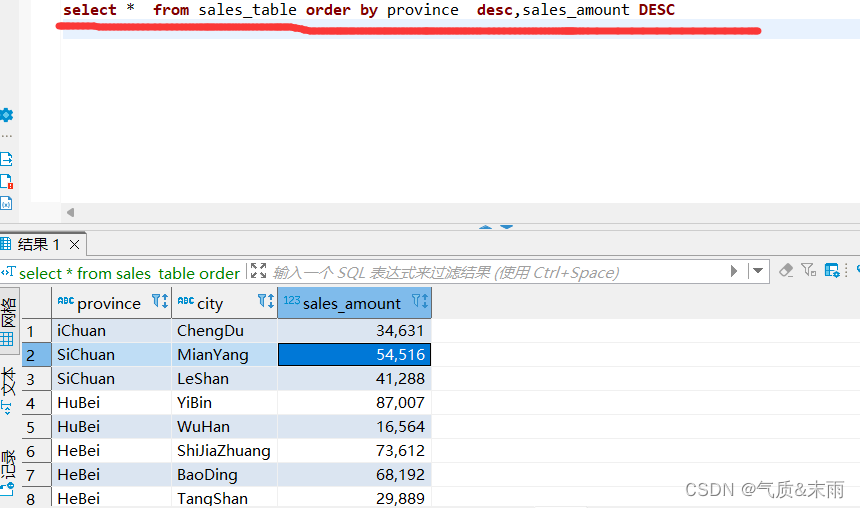
2、使用sort by 局部排序,对province省份和sales_amount销售额进行降序,注意要同时对两个字段进行排序。
输入命令: select * from sales_table sort by province desc,sales_amount desc;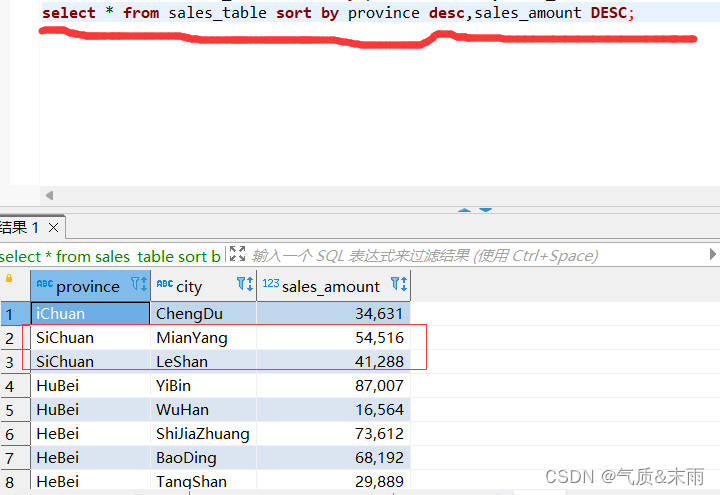
5、升序(ASC) 降序(DESC) 和 Cluster By
1、升序(ASC) 降序(DESC)
升序排列与降序排列的区别在于数据的排列方式不同,它们在数值类型数据,字符串数据类型和时间数据类型上的排列方式都有所不同。
- 数值类型:升序排列是把数据按照从小到大的顺序进行排列,降序排序则相反
- 字符串类型:升序排列是按照字符串首字母,从A到Z的顺序进行排列,降序排列则相反
- 日期类型:例如1月3日和1月6日,升序排列会把 1 月 3 日放在首位,降序拍了则相反
2、Cluster by
Cluster by可以看作是disribute by 和 sort by 的合集,若distribute by 和 sort by 指定的列名一致,则可以使cluster by 代替,不过cluster by默认只允许升序排列,不支持降序
九、union 语句
union语句 用于将多个select句式的结果合并为一个结果集,合并数据
将学生信息表中301的班级学生和教室信息表中301的班级老师合并在一起
输入命令:select class,student_name class301 from students_table where class = “301” union select class,teacher_name class301 from teacher_table where class = “301”
先把学生表中的数据 中的教室字段用where 查询出来301教室的信息,然后把教室的那个字段别名改为class301 然后教师表一样的操作,两个表的查询完成用 union 进行连接,就合并起来了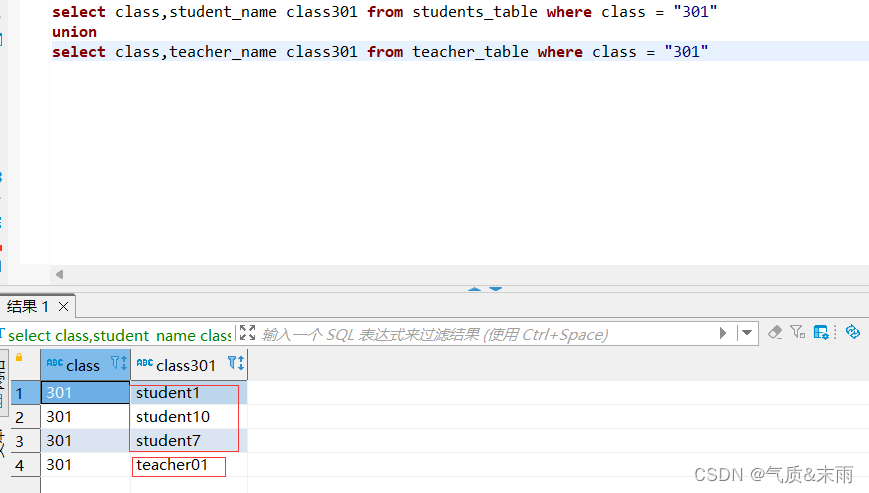
十、join 语句
join语句主要是基于两个或者多个表列之间的关系,将这些表进行连接
1、join语句的内连接,连接学生名单表和教师名单表
输入命令: select t1.class,t2.class,stdudent_name,teacher_name from students_table t1 inner join
teacher_table t2 on t1.class = t2.class
先进行查询学生表的class字段和教师表的class字段然后给两个表进行别名,学生表为t1,教师表为t2然后 使用 inner join 进行内连接 教师表 然后用 on 两个表相同的字段进行相等 t1.class=t2.class
注意使用join进行多表关联,一定要有相同的字段 内连接连接两个表都有的相同的字段,里面都有的数据,才会显示出来,比如学生表没有304这个教室,而教师表有那么连接两个表这个就不会显示,只会显示两个表都有的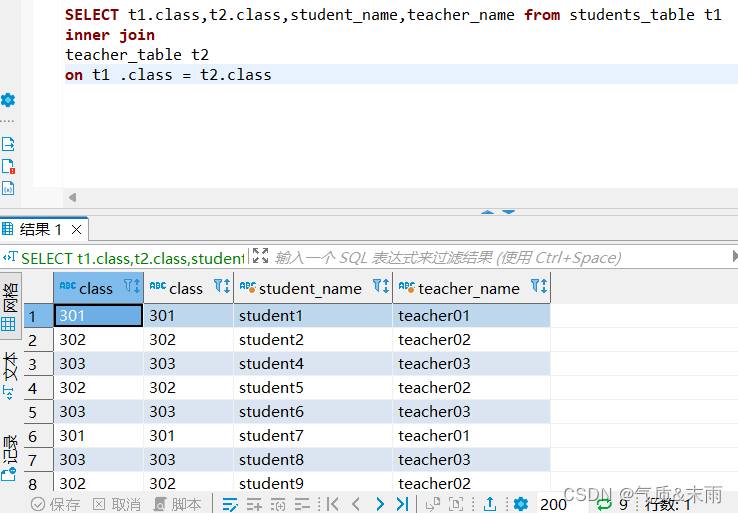
2、join 语句的左外连接
使用join语句的左外连接,连接学生名单表和教师名单表
输入命令:select t1.class,t2.class,student_name,teacher_name from students_table left outer join teacher_table on t1.class = t2.class
使用左外连接大致和内连接相似,但是连接的语句 使用 left outer join 左外连接 使用左连接就是以左边的那个表为基准,比如class那个字段两个表都有,但是只有学生表有305,但是教师表没有305这个教室,那么只会显示学生表的,教师表的305教室为显示为空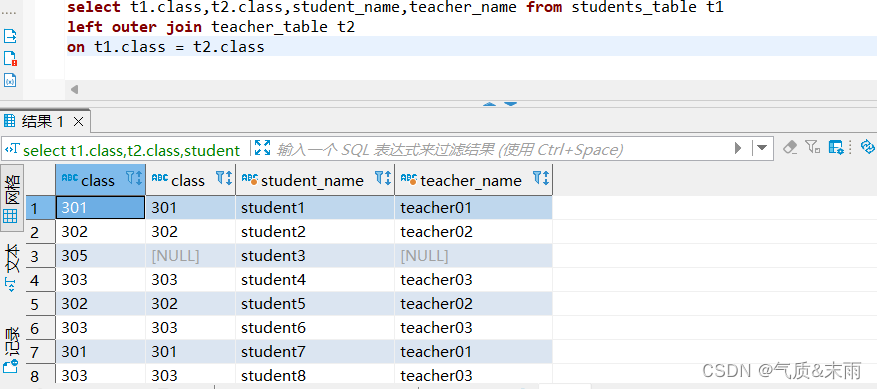
3、join 语句的右外连接
输入命令:select t1.class,t2.class,student_name,teacher_name from students_table t1 right outer
join teacher_table t2 on t1.class = t2.class
使用右外连接大致和内连接相似,但是连接的语句 使用 right outer join 右外连接 使用右连接就是以右边的那个表为基准,比如class那个字段两个表都有,但是学生表没有304,但是教师表有305这个教室,那么只会显示教师表的,学生表的305教室会显示为空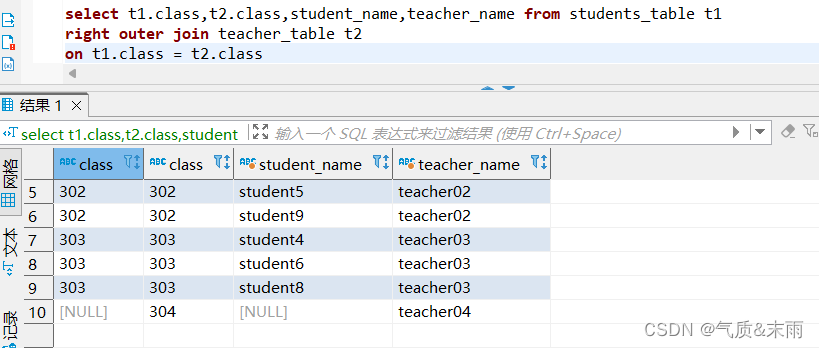
4、join 语句的全外连接
使用join语句的全外连接,连接学生名单表和教室名单表
输入命令:select t1.class,t2.class,student_name,teacher_name from students_table t1 full outer join teacher_table t2 on t1.class = t2.class
使用全外连接,连接的关键字是 full outer join 全外连接 ,使用全外连接会把两个表的数据都查出来,然后哪个表没有那个数据就会显示为空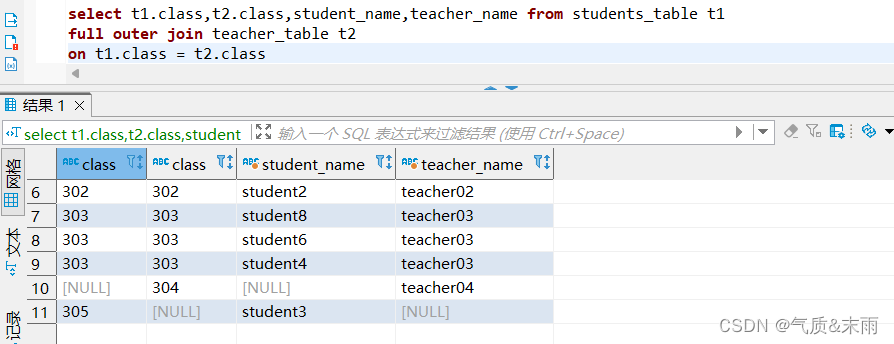
5、join语句的左半连接
使用join语句的左边连接,连接学生名单表和教室名单表
输入命令:select t1.class,student_name from students_table t1 left semi join teacher_table t2 on t1.class = t2.class
使用左边连接 要使用关键字 left semi join 左半连接 前面select 要查询的字段的时候只会有左边那个表的字段,不然会报错,查询也只会查出左边那个表有的信息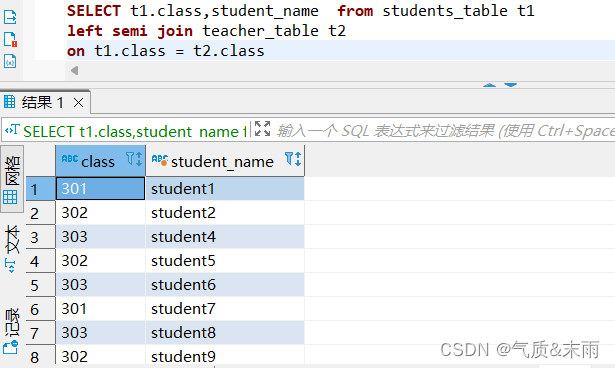
6、join 语句的笛卡尔积连接
使用join语句的笛卡尔积连接,连接学生名单表和教师名单表
输入命令:select t1.class,student_name from students_table t1 cross join teacher_table t2
使用笛卡尔积连接 使用关键字 cross join 笛卡尔积连接 只需要查询左表的字段然后 使用 cross join字段 连接右表就行了,连相同的字段相等都不用写 笛卡尔积连接会把两个表中相同字段的所有数据全部查询出来,而且两个表相同的数据他也会依次显示两遍出来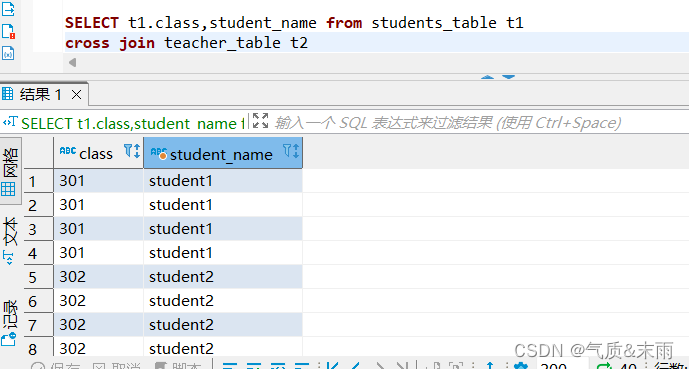
十一、抽样查询
对于非常大的数据集,有时候用户需要使用的是一个具有代表性的查询结果,而不是全部查询结果,此时可以用hive抽样查询实现这个需求。hive抽样查询分为随机抽样,分桶抽样和数据块抽样。
1、随机抽样 随机从学生名单表中抽取三名学生
输入命令:select student_name from students_table distribute by rand() sort by rand() limlt 3
随机抽样 先使用 distribute by 和 sort by 进行排序 然后使用 hive 中的 rand()随机函数 加上 limit 3
随机取出三条学生信息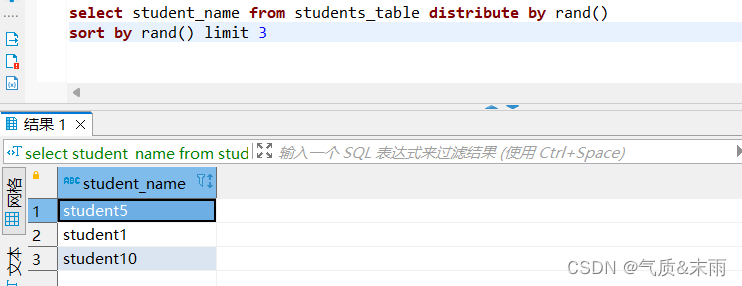
2、分桶抽样
将学生名单表的数据按照班级分为三个桶,查询第一个桶中的数据
输入命令:select * from students_table tablesample(bucket 1 out of 3 on class)
分桶查询 tablesample 函数 backet 是要抽哪一个桶的数据 out of 3 是要 分成三个桶 on 是要分桶的字段 bucket 1 查询出第一个桶里面的数据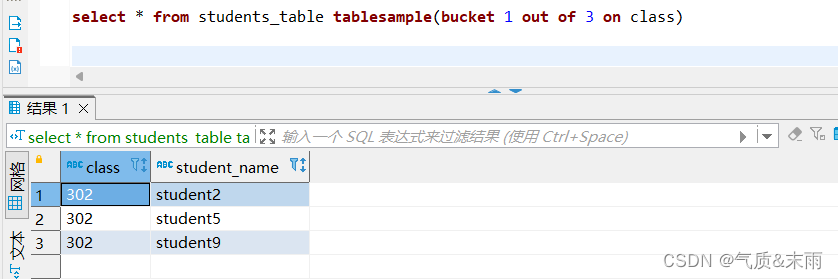
3、数据块抽样
数据库抽样可以根据比例,行数和数据大小抽取hive表中的数据,这里所指的比例和数据大小是跟据hive表的数据文件计算的。
抽取学生名单表 50% 的数据
输入命令: select * from students_table tablesample(50 percent)
数据块抽样使用hive的 tablesample 函数, 里面的参数 50 percent 抽取百分之50的数据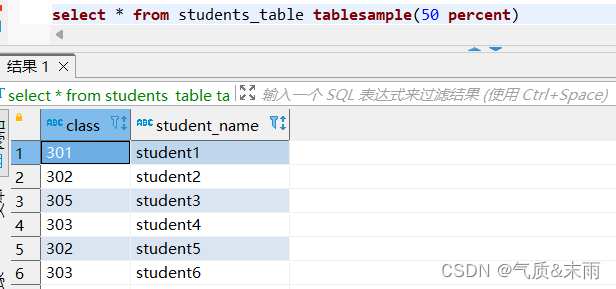
版权归原作者 气质&末雨 所有, 如有侵权,请联系我们删除。