
编者按:近年来,随着金融、制造、政务、交通、医疗等行业数字化转型深入,大量智慧应用涌现,使得构建强大的数据分析技术栈成为必须,也让“湖仓一体”成为热门词汇。但面对市场中各色各样的湖仓技术,众多行业用户既分辨不清,又无从选择。本文梳理了当前市场中主流数据分析技术栈的优劣,并对“湖仓一体”架构演进趋势进行了深度分析,值得广大用户一读。
随着信息时代的兴起,数据已成为推动业务决策和创新的核心要素;结构化、半结构化等多种类型的数据呈现爆炸式增长,如何高效处理和分析海量数据已经成为关键挑战。
当前业界构建数据分析的技术栈,有两条典型的路线:一条是数仓路线,另一条则是数据湖的路线。
数据仓库的路线,数据先通过 ETL 统一写入到数仓进行管理,然后构建数据集市来满足 BI 分析的各种需求;优势是数据质量高、查询性能高、具备实时分析的能力、数据治理功能完善等。
而数据湖的路线,通常是未经加工的数据先统一存储在数据湖,作为企业数据的 single sourth of truth,然后按需的使用数据,构建数据应用;优势是通开放生态、扩展性强,性价比高。
数据仓库

数据仓库是一种将来自不同源的数据聚合到单个集中式一致数据存储中的系统,以支持企业报表、数据分析、数据挖掘、人工智能和机器学习等应用。数据仓库技术经过几十年的发展,产品架构已经经过了多轮的迭代:
- 早期分析场景比较简单,业务采用 Oracle/MySQL 为代表的关系型数据库,在线处理与数据分析在一套系统里完成;但随着数据分析场景的越来越复杂多样化,这种方案的挑战非常大,一是两种负载会相互影响,同时数据分析的性能也不能满足需求。
- 以 Teradata 、Oracle EDW 为代表的商用数据仓库应运而生,专门针对大规模数据的管理与价值挖掘,这类数仓产品功能强大,但其商业成本太高,导致技术无法普及使用。
- 以 Hadoop( Hive) 为代表的开源数仓,基于开源组件构建大数据平台;Hadoop 生态让大数据变成普惠技术,企业能够低成本的基于开源 Hadoop 生态,构建企业级数仓平台。
- Hadoop 生态使用门槛低,但因为组件繁多,维护代价非常高,随着新技术的发展,Hadoop 生态各组件的技术竞争力也在持续下降,以 Snowflake、Redshift、Bigquery 为代表云原生数仓,帮助企业构建一体化的数据处理与分析平台。
数据湖

数据湖是以原始格式存储数据的存储库或系统,它按原样存储数据,无需事先对数据进行结构化处理。
- 数据湖通常采用 S3 对象存储或 HDFS 分布式文件系统作为底层统一存储,并作为 Single source of truth。
- 数据湖通常采用开放的数据格式,同时满足结构化、半结构化等数据等存储需求,并 ACID、Upsert、Time travle 等高级特性,满足企业数据管理方面的各种诉求。
- 业界常见的数据湖包括 Apache Iceberg、Apache Hudi、Delta、Apache Paimon 等,业务采用 Trino、Presto、Impala 等引擎按需分析数据湖上的数据。
企业未来数据架构应该建仓or建湖
其实,大家之所以有现在的纠结,是因为数据仓库和数据湖各有优劣,如果能将优势兼具,IT 架构工程师们也不必一定要选择是湖还是仓。目前在业界,很多企业正在不断探索湖仓融合的路径。
- 湖上建仓:企业的数据先进入到数据湖统一存储,湖上直接性能不足,此时可以采用湖上建仓的方案,将查询性能要求高的部分通过 ETL 导入到新的数据仓库提供服务。
- 仓外挂湖:部分数据仓库产品,例如 Redshift、Bigquery 等,开始扩展查询外部数据湖(Hive、Iceberg 等)的能力,实现计算层的统一。
不管是湖上建仓、还是仓外挂湖的方案,本质上数据都是分开存储,可能还会通过不同的引擎服务不同场景的查询,更好的方案是实现湖仓一体化,让数据分析的架构更加简单。那到底什么是湖仓一体?
湖仓一体
当互联网规模发展至一定程度后,企业数据的使用场景发生巨大变化,需求开始从离线转而要求实时的数据分析,同时随着企业数据规模极速增长,企业对于实时数据治理提出更高的要求,要求业务端数据能够实时处理,进一步满足基于数据的实时分析和决策。
湖仓一体是通过一套架构,满足所有的分析需求,抽象化的描述,要能实现 One Data、All Analytics 的业务价值。
- 统一数据存储:在湖仓一体架构下,数据要统一存储管理,一份数据作为 Single source of truth,避免导来导去,造成数据冗余,分析口径不一致等问题;存储层通常采用 S3/HDFS 作为数据存储底层,并采用开放数据湖或者私有的数据格式去管理数据。
- 极速查询引擎:基于统一的数据存储,湖仓一体架构要能满足所有的业务分析场景的诉求,包括 BI 报表、交互式分析、实时分析、ETL 数据加工等场景,这就要求必须要有一个足够强大的分析引擎,能同时满足这些场景的查询需求。
- 按需查询加速:对于部分业务场景特别复杂的查询,数据源数据组织未针对分析优化,直接分析不一定能满足查询延时的需求,湖仓一体架构要具备通用的数据查询加速的能力,并且不破坏 Single source of truth 的原则。

目前, StarRocks 3.x 推出了存算分离、湖仓分析、物化视图等重量级特性,能够很好的帮助企业构建湖仓一体平台,微信、携程、小红书等数十家大型企业进行实践后,收获极大的简化数据平台的技术栈,同时提升的服务性能。
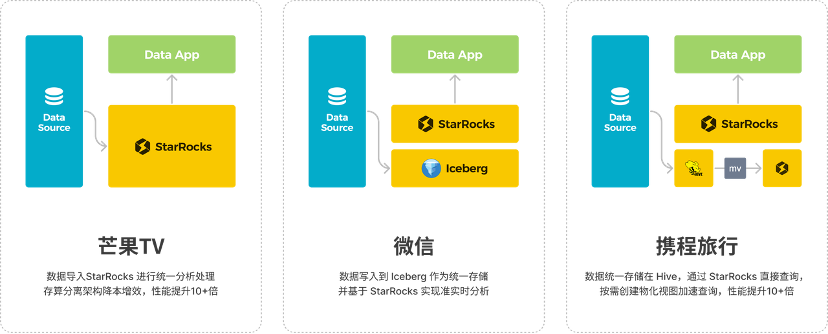
那么,如何构建湖仓一体平台?
用户可以将 StarRocks 当作一站式湖仓,数据统一导入到 StarRocks ,借助存算分离的架构,实现低成本的数据存储,然后利用 StarRocks 查询引擎来服务全场景的数据分析应用;
如果用户的数据已经在开放数据湖(Hive、Hudi、Iceberg、Paimon),就可以通过 StarRocks 直接分析数据湖,同样能获得极高的查询性能。
不管数据统一存储在开放数据湖里还是 StarRocks 里,当查询性能不足时,都可以利用物化视图加速查询性能。基于此,用户可以方便地构建湖仓一体平台,实现 One Data、All Analytics 的业务价值。
当然,对于有数据的安全、权限管理需要的企业,可以选择基于 StarRocks 开发的企业级产品镜舟湖仓分析引擎。
镜舟湖仓分析引擎能够兼容并加速企业已有的大数据架构如Hive、Iceberg、Hudi、Deltalake、MySQL 和 Oracle 等,有效帮助企业节省传统架构中数据搬运的时间与成本, 通过简化数据链路,实现数据分析性能指数级提升。同时,镜舟湖仓分析引擎部署简单、运维便捷,在为企业提速的同时降低系统及人力成本。
企业可以通过镜舟湖仓分析引擎,支撑不同团队和角色的数据使用诉求,在报表查询、用户画像与行为分析、自助指标分析、实时风控等业务场景实现加速,给业务团队带来极速查询、分析体验,快速响应市场变化,为解决企业数据治理需求和数据集成提供更优解。
作者介绍:张友东,镜舟科技CTO、StarRocks TSC member,资深数据库技术专家,曾担任阿里云、淘宝等多款数据库内核研发负责人,并拥有多项数据库领域技术专利。
版权归原作者 大数据在线 所有, 如有侵权,请联系我们删除。