
---合作同学:曾鑫 ID:zxhbnu2019
目录
一、爬虫介绍
在当今信息化爆炸的时代,我们想要获取某些网站中的某些数据信息(如淘宝的用户使用协议、猫眼电影排行榜、MOOC课网站的某一课程的评论等)都会有大量相关内容涌现在我们眼前,我们想要了解这些内容可能要一行一页的翻看记录收集(我们将此称为传统方法),按照传统方法完成一个项目可能80%~90%的时间用于获取和处理数据,为了提高我们的数据获取和处理的效率,帮助我们自动完成数据的翻看记录过程,爬虫技术随之而生。
1、什么是爬虫
爬虫,也称为网络爬虫或蜘蛛程序(spider),是一种自动获取网页内容的程序或脚本。(可以形象的理解为像蜘蛛一样在网络上爬行,找到自己想要的东西)
2、爬虫的功能
a.收集数据---最常用的功能
爬虫可以用来收集数据。通过在计算机上编程调试该程序,让爬虫程序代替人类重复查阅数据收集并存储的行为过程,实现自动化的数据收集和存储。
b.刷流量或秒杀活动
每次运行爬虫程序都会先点开一个需要获取数据的网站,就会随之增加了该网站的浏览量。除了刷流量以外,爬虫也可以用来参与各种商品的秒杀活动(如抢优惠券、抢某宝秒杀商品、抢机票、抢火车票)。
3、爬虫的挑战和问题(针对收集数据功能)
- 网站结构的变化:如果网站的结构发生变化,爬虫可能无法正确地提取数据。
- 动态内容:现代网页常常包含动态加载的内容,这需要特殊的处理来模拟用户交互。
- 访问限制:一些网站通过用户代理检测、登录限制、验证码等方式限制爬虫的访问。
- 隐私和法律问题:爬虫可能涉及到隐私和数据保护法律的问题,特别是在抓取个人信息时。
- 性能和可扩展性:随着抓取量的增加,爬虫需要有效地管理和分配资源,以处理大量的数据。
想要避免这些问题,需要我们不断提高我们的编程技术,对爬虫程序进行优化以适应我们的需求。
二、selenium介绍
1、什么是selenium
Selenium是一个开源的自动化测试工具,它主要用于Web应用的自动化测试。Selenium支持多种编程语言,包括Java、C#、Python、Ruby等,它允许测试人员编写测试脚本,模拟用户的行为,如点击链接、填写表单、键盘输入等,从而实现对Web应用的自动化测试。
2、selenium的主要组件
a.Selenium IDE:
一个用于录制和回放测试脚本的集成开发环境。它是一个Firefox插件,也可以用于Chrome。
b.Selenium WebDriver:(最重要的部分)
一个浏览器自动化工具,它提供了各种编程语言的API,允许测试脚本直接与浏览器交互。
c.Selenium Grid:
允许测试在不同的机器和不同的浏览器上并行运行,从而加快测试执行的速度。
Selenium不仅用于自动化测试,它也被广泛用于爬虫领域,特别是对于需要模拟用户交互才能获取数据的网站,如登录、滑动验证码、动态加载内容等。
三、调用的类和方法的功能介绍
·service类:
Service
类是用于管理WebDriver服务器的实例。当你想要启动一个本地或远程的WebDriver服务时,你会使用
Service
类。在Selenium WebDriver中,
Service
类通常与
ChromeDriver
、
GeckoDriver
(用于Firefox)、
EdgeDriver
等浏览器驱动程序一起使用。
·webdriver.Edge()
该代码调用Selenium库中的
webdriver
模块方法,用于声明浏览器对象,对浏览器对象进行初始化,webdriver.Edge()声明的是一个微软浏览器对象
Selenium 支持非常多的浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
·driver.get()
调用Selenium库中的
webdriver
模块方法,用来访问网站页面,参数传入我们需要爬取的网页链接URL即可
·time.sleep(5)
调用了标准库time中的sleep()方法。该方法的参数表示睡眠的时间,单位是秒。在这里,sleep()被调用为5秒,这意味着程序会暂停执行5秒钟,然后继续执行后续的代码块。
在爬虫中,有时需要让程序等待一定时间,以确保网站上的数据已经更新,或者为了避免因为请求过快而被认为是机器人行为,从而避免被封禁。通过使用sleep()方法,我们可以实现这样的等待功能。
·driver.find_element(By.ID, "review-tag-button")
这是Selenium库中webdriver模块中用来查找某个网页的某个节点的通用方法。
这里引入查找某个节点的所有方法
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
find_element()方法可以通过传入两个参数来应用上述所有方式,
其中第一个参数中的
By
是 Selenium 中用来指定定位策略的一个枚举类型,它支持多种定位方式,包括但不限于:
By.ID: 通过元素的 ID 属性定位。By.NAME: 通过元素的 name 属性定位。By.CLASS_NAME: 通过元素的 class 名称定位。By.TAG_NAME: 通过元素的标签名定位。By.LINK_TEXT: 通过链接的完整文本来定位。By.PARTIAL_LINK_TEXT: 通过链接的部分文本来定位。By.CSS_SELECTOR: 通过 CSS 选择器定位。By.XPATH: 通过 XPath 表达式定位。
第二个参数则是网页源代码中该节点对应的ID或NAME或CLASS_NAME等的值。
我们想要获取某个节点时,需要先调用webdriver里面的page_source属性获取网页源代码,在源代码根据节点名称找到对应的ID或NAME或CLASS_NAME等的值。
·element.click()
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys 方法,清空文字时用 clear 方法,点击按钮时用 click 方法。
·driver.page_source
在Selenium中,
page_source
是webdriver的一个属性,它返回当前加载页面的HTML源代码。这个属性允许你获取浏览器中当前可见页面的整个HTML内容,以字符串形式表示。
·PyQuery(next_source)
PyQuery
是一个 Python 库,它允许你使用 jQuery 的语法来操作 HTML 文档。如果你有一个 HTML 字符串,你可以使用
PyQuery
来解析这个字符串,并使用 jQuery 风格的选择器来选取和操作元素。
当你看到 PyQuery(next_source) 这样的代码时,它意味着 next_source 是一个字符串,其中包含 HTML 内容,并且这个字符串被传递给 PyQuery 来创建一个 PyQuery 对象。这个对象允许你使用 jQuery 风格的语法来操作 HTML 元素。
·time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime())
在Python中,time.strftime是一个用于格式化时间戳的函数,它将时间元组转换为字符串。这个函数接受两个参数:
- 格式字符串:指定了时间字符串的输出格式。
- 时间元组:一个包含时间信息的元组,通常由time.localtime()或其他类似函数返回。
time.localtime()函数获取当前时间的本地时间元组,它包含了年、月、日、小时、分钟、秒和星期几等信息。
格式字符串"%Y_%m_%d_%H_%M_%S"中的各个占位符代表如下含义:
- %Y:四位数的年份(例如,2023)
- %m:月份(01到12)
- %d:月份中的一天(01到31)
- %H:小时(00到23)
- %M:分钟(00到59)
- %S:秒(00到61,包括闰秒)
因此,time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime())这行代码的执行结果将是一个字符串,包含了当前时间的年、月、日、小时、分钟和秒,中间用下划线“_”连接。例如,如果当前时间是2023年11月8日16点30分22秒,那么返回的字符串将是"2023_11_08_16_30_22"。
·os.makedirs(os.path.dirname(filename))
在Python中,os.makedirs(os.path.dirname(filename))这行代码的作用是创建一个与给定文件名 filename相关联的目录。这里,os.makedirs是一个用于创建目录的函数,而 os.path.dirname(filename) 则用于获取文件名 filename` 中的目录路径。
具体来说,os.path.dirname(filename)会返回 filename 中除去文件名后的目录部分。然后,os.makedirs 会尝试创建这个目录。如果这个目录的上级目录不存在,os.makedirs会一并创建它们。
例如,如果 filename是 "path/to/directory/filename.txt",那么 os.path.dirname(filename) 会返回 "path/to/directory",接着 os.makedirs("path/to/directory") 会创建 "path"、"path/to" 和 "path/to/directory" 这三个目录,如果它们尚未存在的话。
这个操作通常用于确保在尝试写入文件之前,文件所在的目录已经存在,从而避免在尝试创建或写入文件时因为目录不存在而导致的错误。
·div_lists.items()
在Python中,
div_lists.items()
这行代码的用途取决于
div_lists
的具体类型。如果
div_lists
是一个字典(dict),那么
.items()
方法将返回一个视图对象,类似于列表,它包含了字典中的所有键值对,每个键值对都是一个元组(tuple)。
·div_list.find(".star-point")
在Python中,如果你看到div_list.find(".star-point")这样的代码,它通常意味着div_list是一个PyQuery对象,并且你正在使用PyQuery的find方法来查找具有类star-point的元素。
PyQuery是一个Python库,它允许你使用类似jQuery的语法来操作HTML文档。find方法用于在PyQuery对象表示的HTML元素内查找符合条件的子元素。
·driver.quit()
在Python的Selenium库中,driver.quit() 方法用于关闭浏览器窗口并结束浏览器驱动程序的进程。当你完成自动化测试或爬虫任务后,应该调用这个方法来清理资源,释放内存,并确保所有与浏览器相关的进程都被正确关闭。
四、准备工作及流程图
a.下载浏览器驱动
1)什么是浏览器驱动
浏览器驱动是一种特殊的软件,它允许Selenium WebDriver与特定的Web浏览器进行交互。每个主流浏览器都有自己的驱动程序,例如:
- ChromeDriver:用于控制Google Chrome浏览器。
- GeckoDriver:用于控制Mozilla Firefox浏览器。
- EdgeDriver:用于控制Microsoft Edge浏览器。
- SafariDriver:用于控制Apple Safari浏览器。
这些驱动程序实现了WebDriver协议,这是一种允许外部程序以编程方式控制Web浏览器的标准。当你使用Selenium WebDriver编写脚本时,你的脚本会发送命令到WebDriver服务(通常是驱动程序),然后服务会转发这些命令到浏览器,并执行相应的操作,如打开网页、点击按钮、填写表单等。
2)为什么要下载浏览器驱动程序?
·与特定浏览器版本兼容:
驱动程序通常与特定版本的浏览器绑定。为了确保Selenium能够正确地与你的浏览器版本交互,你需要下载与你的浏览器相匹配的驱动程序。
· 实现浏览器特定的功能:
不同的浏览器可能有不同的特性或渲染方式。驱动程序确保Selenium能够处理这些差异,并提供一致的操作接口。
· 执行JavaScript:
驱动程序能够在浏览器中执行JavaScript代码,这对于处理动态内容或与Ajax请求交互非常重要。
· 模拟用户行为:
驱动程序允许Selenium模拟用户的行为,如鼠标点击、键盘输入等,这对于自动化测试和爬虫非常有用。
· 支持多种编程语言:
Selenium WebDriver支持多种编程语言,驱动程序为这些语言提供了统一的接口,使得开发者可以使用他们熟悉的语言编写自动化脚本。
在开始使用Selenium WebDriver之前,你需要确保已经下载并配置了正确的浏览器驱动程序。你可以从各个浏览器的官方网站或Selenium项目的官方网站下载相应的驱动程序。
这里附上各个浏览器驱动程序的下载地址:
ChromeDriver (用于Google Chrome):
- 下载地址: https://sites.google.com/chromium.org/driver/
- 选择与你的Chrome浏览器版本相匹配的ChromeDriver版本。
GeckoDriver (用于Mozilla Firefox):
- 下载地址:https://github.com/mozilla/geckodriver/releases
- 选择与你的Firefox浏览器版本相匹配的GeckoDriver版本。
EdgeDriver (用于Microsoft Edge):
- 下载地址: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
- 选择与你的Edge浏览器版本相匹配的EdgeDriver版本。
SafariDriver (用于Apple Safari):
- SafariDriver通常随Safari浏览器一起提供,不需要单独下载。
- 注意:SafariDriver仅在MacOS上的Safari 10及更高版本中可用。
下载驱动程序时,请确保下载与你的浏览器版本兼容的驱动程序。如果你不确定应该下载哪个版本,可以查看浏览器的版本信息,并根据这些信息选择最接近的驱动程序版本。
b.下载selenium库
打开pycharm运行终端输入以下代码并按回车
pip install selenium
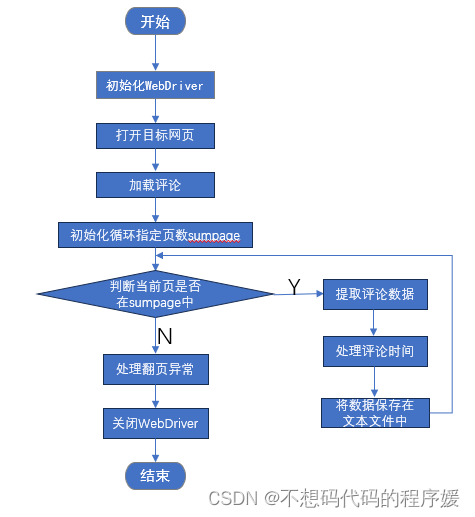
c.流程图
五、代码实现
1、导入所需的库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from pyquery import PyQuery
import time
import os
2、返回时间字符串
def extract_time(comment_time_str):
# 这里是一个示例函数,你需要根据时间字符串的格式写一个实际的解析函数
return comment_time_str
3、设置WebDriver
def auto_update_driver():
driver_path = 'C:\\Users\\59412\\Desktop\\edgedriver_win64\\msedgedriver.exe'
service = Service(executable_path=driver_path)
driver = webdriver.Edge(service=service)
return driver
注意:你需要将driver_path换成你实际下载在电脑上的浏览器驱动地址
4、模拟用户登录
def get_MOOC(browser, url, sum_page):
driver = auto_update_driver()
driver.get(url)
time.sleep(5) # Allow the page to load
5、抓取课程评论
element = driver.find_element(By.ID, "review-tag-button")
element.click()
time.sleep(2)
6、将评论保存到文本文件中
for page in range(sum_page):
next_source = driver.page_source
next_query = PyQuery(next_source)
div_lists = next_query(".ux-mooc-comment-course-comment_comment-list_item") # 评论列表项的容器
time_flag = time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime())
filename = f"result\\comment_{time_flag}.txt"
if not os.path.exists(os.path.dirname(filename)):
os.makedirs(os.path.dirname(filename))
with open(filename, "a", encoding="utf-8") as f:
for div_list in div_lists.items():
# 获取评论内容
comment_text = div_list.find(
".ux-mooc-comment-course-comment_comment-list_item_body_content span").text()
# 获取打分内容
star_point_div = div_list.find(".star-point")
star_icons = star_point_div("i")
comment_score = len(star_icons)
# 获取评论时间
comment_time = div_list.find(
".ux-mooc-comment-course-comment_comment-list_item_body_comment-info_time").text()
time_data = extract_time(comment_time)
# 写入文件
f.write(f"{comment_score} stars | {comment_text} | {time_data}\n")
try:
next_element = driver.find_element(By.CLASS_NAME, "ux-pager_btn__next")
next_element.click()
time.sleep(3) # Wait for the page to load
except Exception as e:
print("No more pages or error occurred:", e)
break
以上代码用于处理点击评论下一页的异常
driver.quit()
关闭浏览器驱动程序
7、运行爬虫
if __name__ == '__main__':
browser = "edge"
url = "https://www.icourse163.org/course/BIT-268001"
sum_page = 5
get_MOOC(browser, url, sum_page)
版权归原作者 不想码代码的程序媛 所有, 如有侵权,请联系我们删除。