
公司项目需要,对两个国产时序数据库 TDengine 与 DolphinDB 做了压缩比测试。
测试数据来源于 TDengine 官方的性能测试工具 Benchmark。
先上结果:DolphinDB 压缩比优于 TDengine 1.65 倍
TDengine
TDengine 是一款开源、云原生的时序数据库(Time Series Database),专为物联网、工业互联网、金融、IT 运维监控等场景设计并优化。它能对大量设备、数据采集器每天产生的高达 TB 甚至 PB 级的数据进行高效实时的处理;对业务的运行状态进行实时的监测、预警,从大数据中挖掘出商业价值。
DolphinDB
DolphinDB 是由浙江智臾科技有限公司研发的一款高性能分布式时序数据库,DB-Engines 时序库排行榜top 10。用户可在同一个系统内使用简洁高效的脚本语言快速开发大数据应用。适用于工业物联网及量化金融等领域。
测试环境:
Ubuntu20.04,内存32G,CPU i7x2.9 16核,硬盘256G SSD
TDengine社区版:3.0.1.4
DolphinDB社区版:2.00.8
部署方式:单服务器单节点
客户端:TDengine 使用命令行;DolphinDB 使用 v1.30.20.1 GUI 客户端
整个测试都是在相同环境下进行,TDengine 在测试中开启最大程度压缩的二级压缩。两个产品部署在同一台 Linux 服务器上,用了同一组数据记录集。
数据记录集:
使用 TDengine 的 taosBenchmark 命令产生记录集,包含1张超级表meters,1w张普通表,总共1亿条数据,保存在test数据库中。
meters表详情:
字段名
ts
current
voltage
phase
groupid
location
字段类型
TIMESTAMP
FLOAT
INT
FLOAT
INT
BINARY(64)
数据
样例
2017-07-14 10:40:00.000
9.80000
113
0.30278
4
California.Cupertino

测试结果:
项目
原始数据data.csv(M)
DolphinDB(M)
TDengine(M)
性能比DolphinDB/TDengine
Δ(M)
磁盘空间占用
6,656
294
486
1.65倍
192
结果表明:
(1)TDengine 为了实现性能的超常发挥,采用了大量的非常规(重复、排序)数据进行 Benchmark 测试。
(2)DolphinDB 对重复标签及排序数据的处理优于 TDengine 。
测试过程
linux 执行生成记录集,包含1亿条数据。TDengine 磁盘空间占用486m。
1taosBenchmark
导出数据:
1taos> select * from test.meters >> ~/tdengine/data.csv;
data.csv 数据大小为6.5G,TDengine 压缩比约为13.7。
data.csv 导入 DolphinDB:
1login("admin","123456") 2schema = table(1000:0,`ts`current`voltage`phase`location`groupId , `TIMESTAMP`DOUBLE`INT`DOUBLE`SYMBOL`SYMBOL) 3t = loadText('/home/yjfeng/tdengine/data.csv', , schema) 4db_date=database(,VALUE,[datetime(2022.01.01)]) 5db_hash=database(,HASH,[SYMBOL,5]) 6db=database("dfs://test",COMPO,[db_date,db_hash],compressMethods={ts:"delta", voltage:"delta"},`TSDB) 7pt=createPartitionedTable(db,t,`meters,`ts`location,,`location`ts) 8pt.append!(t) 9
DolphinDB 磁盘空间占用:294M。
1select sum(diskUsage)/1024/1024+"m" from pnodeRun(getTabletsMeta{chunkPath="/test/%",tableName="meters",diskUsage=true,top=0})
DolphinDB 压缩比约为22.6。
项目
DolphinDB
TDengine
性能比
Δ
压缩比
22.6
13.7
1.65倍
8.9
结果分析
1、为啥dolphindb压缩比高于tdengine
我猜测主要原因是 DolphinDB 使用了 SYMBOL 数据类型?
研究了下文档里对SYMBOL的介绍
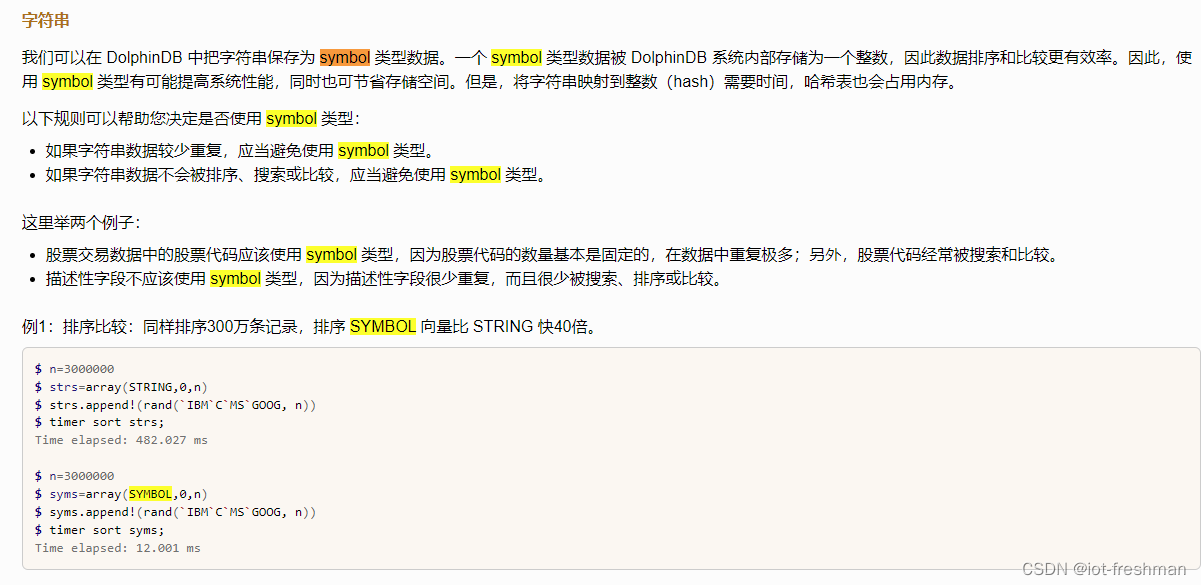
TDEngine 没有类似的数据类型,字符串类型必须事先制定最大长度。TDengine 磁盘空间占用包括时序数据以及库、表相关的元数据、标签数据等。采用超级表+子表的方式存储,标签数据单独存储可以提高压缩比,但是相比 DolphinDB 的 SYMBOL 类型并不占优。
2、压缩算法不一样
TDEngine默认采用二阶段的压缩算法,即在初次压缩的基础上,采用通用的压缩算法再次压缩,这提高了 TDEngine 的压缩率,牺牲了一定的计算资源。
DolphinDB 采用的默认压缩算法是LZ4,LZ4算法并不追求压缩率,其主要优势在于压缩与解压的效率高(压缩特别是解压非常快)对于 CPU 占用少。
目前市面上主流的压缩算法都是公开的,各家产品所采用的压缩算法之间并没有太大差距。压缩算法的选择,更多是根据产品定位不同而作出的取舍。压缩和解压本身是需要消耗资源的,并不存在对所有数据都表现优异的压缩算法。
数据的重复率、数据的排序等特征对于压缩比的影响非常大。对同个压缩算法来说,重复率高、排序的数据可拥有更高压缩比。
注:本文所讨论的压缩均为无损压缩,即在不损失数据精度的情况下,通过压缩算法减少数据的磁盘空间占用。有损压缩不在讨论范围之内,有损压缩可以通过算法或者是降采样的方式实现。比如,用年平均气温1个值来代替全年的365条记录,本质上也是一种有损压缩,而且压缩率达到 365 : 1,显然这样的压缩比在某些情况下是没有意义的。
版权归原作者 iot-freshman 所有, 如有侵权,请联系我们删除。