

想象你正在解决一个拼图游戏。你已经完成了大部分。假设您需要在一幅几乎完成的图片中间修复一块。你需要从盒子里选择一块,它既适合空间,又能完成整个画面。

我相信你很快就能做到。但是你的大脑是怎么做到的呢?
首先,它会分析空槽周围的图片(在这里你需要固定拼图的一块)。如果图片中有一棵树,你会寻找绿色的部分(这是显而易见的!)所以,简而言之,我们的大脑能够通过知道图像周围的环境来预测图像(它将适合放入槽中)。
在本教程中,我们的模型将执行类似的任务。它将学习图像的上下文,然后利用学习到的上下文预测图像的一部分(缺失的部分)。
在这篇文章之前,我们先看一下代码实现
我建议您在另一个选项卡中打开这个笔记本(TF实现),这样您就可以直观地了解发生了什么。
问题
我们希望我们的模型能预测图像的一部分。给定一个有部份缺失图像(只有0的图像阵列的一部分),我们的模型将预测原始图像是完整的。
因此,我们的模型将利用它在训练中学习到的上下文重建图像中缺失的部分。

数据
我们将为任务选择一个域。我们选择了一些山地图像,它们是Puneet Bansal在Kaggle上的 Intel Image Classification数据集的一部分。
为什么只有山脉的图像?
在这里,我们选择属于某个特定域的图像。如果我们选择的数据集中有更广泛图像,我们的模型将不能很好地执行。因此,我们将其限制在一个域内。
使用wget下载我在GitHub上托管的数据
!wget https://github.com/shubham0204/Dataset_Archives/blob/master/mountain_images.zip?raw=true -O images.zip
!unzip images.zip
为了生成训练数据,我们将遍历数据集中的每个图像,并对其执行以下任务,
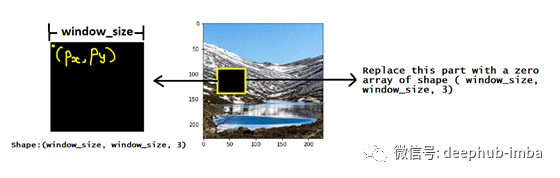
首先,我们将使用
PIL.Image.open()
读取图像文件。使用
np.asarray()
将这个图像对象转换为一个NumPy数组。
确定窗口大小。这是正方形的边长这是从原始图像中得到的。
在
[ 0 , image_dim — window_size ]
范围内生成2个随机数。image_dim是我们的方形输入图像的大小。
这两个数字(称为px和py)是从原始图像剪裁的位置。选择图像数组的一部分,并将其替换为零数组。
代码如下
x = []
y = []
input_size = ( 228 , 228 , 3 )
# Take out a square region of side 50 px.
window_size = 50
# Store the original images as target images.
for name in os.listdir( 'mountain_images/' ):
image = Image.open( 'mountain_images/{}'.format( name ) ).resize( input_size[0:2] )
image = np.asarray( image ).astype( np.uint8 )
y.append( image )
for name in os.listdir( 'mountain_images/' ):
image = Image.open( 'mountain_images/{}'.format( name ) ).resize( input_size[0:2] )
image = np.asarray( image ).astype( np.uint8 )
# Generate random X and Y coordinates within the image bounds.
px , py = random.randint( 0 , input_size[0] - window_size ) , random.randint( 0 , input_size[0] - window_size )
# Take that part of the image and replace it with a zero array. This makes the "missing" part of the image.
image[ px : px + window_size , py : py + window_size , 0:3 ] = np.zeros( ( window_size , window_size , 3 ) )
# Append it to an array
x.append( image )
# Normalize the images
x = np.array( x ) / 255
y = np.array( y ) / 255
# Train test split
x_train, x_test, y_train, y_test = train_test_split( x , y , test_size=0.2 )
自动编码器模型与跳连接
我们添加跳转连接到我们的自动编码器模型。这些跳过连接提供了更好的上采样。通过使用最大池层,许多空间信息会在编码过程中丢失。为了从它的潜在表示(由编码器产生)重建图像,我们添加了跳过连接,它将信息从编码器带到解码器。
alpha = 0.2
inputs = Input( shape=input_size )
conv1 = Conv2D( 32 , kernel_size=( 3 , 3 ) , strides=1 )( inputs )
relu1 = LeakyReLU( alpha )( conv1 )
conv2 = Conv2D( 32 , kernel_size=( 3 , 3 ) , strides=1 )( relu1 )
relu2 = LeakyReLU( alpha )( conv2 )
maxpool1 = MaxPooling2D()( relu2 )
conv3 = Conv2D( 64 , kernel_size=( 3 , 3 ) , strides=1 )( maxpool1 )
relu3 = LeakyReLU( alpha )( conv3 )
conv4 = Conv2D( 64 , kernel_size=( 3 , 3 ) , strides=1 )( relu3 )
relu4 = LeakyReLU( alpha )( conv4 )
maxpool2 = MaxPooling2D()( relu4 )
conv5 = Conv2D( 128 , kernel_size=( 3 , 3 ) , strides=1 )( maxpool2 )
relu5 = LeakyReLU( alpha )( conv5 )
conv6 = Conv2D( 128 , kernel_size=( 3 , 3 ) , strides=1 )( relu5 )
relu6 = LeakyReLU( alpha )( conv6 )
maxpool3 = MaxPooling2D()( relu6 )
conv7 = Conv2D( 256 , kernel_size=( 1 , 1 ) , strides=1 )( maxpool3 )
relu7 = LeakyReLU( alpha )( conv7 )
conv8 = Conv2D( 256 , kernel_size=( 1 , 1 ) , strides=1 )( relu7 )
relu8 = LeakyReLU( alpha )( conv8 )
upsample1 = UpSampling2D()( relu8 )
concat1 = Concatenate()([ upsample1 , conv6 ])
convtranspose1 = Conv2DTranspose( 128 , kernel_size=( 3 , 3 ) , strides=1)( concat1 )
relu9 = LeakyReLU( alpha )( convtranspose1 )
convtranspose2 = Conv2DTranspose( 128 , kernel_size=( 3 , 3 ) , strides=1 )( relu9 )
relu10 = LeakyReLU( alpha )( convtranspose2 )
upsample2 = UpSampling2D()( relu10 )
concat2 = Concatenate()([ upsample2 , conv4 ])
convtranspose3 = Conv2DTranspose( 64 , kernel_size=( 3 , 3 ) , strides=1)( concat2 )
relu11 = LeakyReLU( alpha )( convtranspose3 )
convtranspose4 = Conv2DTranspose( 64 , kernel_size=( 3 , 3 ) , strides=1 )( relu11 )
relu12 = LeakyReLU( alpha )( convtranspose4 )
upsample3 = UpSampling2D()( relu12 )
concat3 = Concatenate()([ upsample3 , conv2 ])
convtranspose5 = Conv2DTranspose( 32 , kernel_size=( 3 , 3 ) , strides=1)( concat3 )
relu13 = LeakyReLU( alpha )( convtranspose5 )
convtranspose6 = Conv2DTranspose( 3 , kernel_size=( 3 , 3 ) , strides=1 , activation='relu' )( relu13 )
model = tf.keras.models.Model( inputs , convtranspose6 )
model.compile( loss='mse' , optimizer='adam' , metrics=[ 'mse' ] )
最后,训练我们的自动编码器模型,
model.fit( x_train , y_train , epochs=150 , batch_size=25 , validation_data=( x_test , y_test ) )

结论
以上结果是在少数测试图像上得到的。我们观察到模型几乎已经学会了如何填充黑盒!但我们仍然可以分辨出盒子在原始图像中的位置。这样,我们就可以建立一个模型来预测图像缺失的部分。
这里我们只是用了一个简单的模型来作为样例,如果我们要推广到现实生活中,就需要使用更大的数据集和更深的网络,例如可以使用现有的sota模型,加上imagenet的图片进行训练。
作者 Shubham Panchal
deephub 翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********