
 9月7-8日,深圳国际会展中心18号馆
9月7-8日,深圳国际会展中心18号馆
来了,来了,腾讯面向产业互联网领域规格最高、规模最大、覆盖最广的年度科技盛会 -——- 腾讯全球数字生态大会。
9 月 7 日,我们将聚焦产业未来发展新趋势,针对云计算、大数据、人工智能、安全、SaaS 等核心数字化工具做关键进展发布,并联合生态伙伴推出最新行业场景解决方案。同时,携手全球权威商业杂志榜单,与中国最佳 CEO 探讨数实融合发展趋势,与中国 500 强企业解析产业焕新最佳实践。畅谈国产化、企业出海、行业大模型等应用实例,探讨如何构筑企业安全免疫力,以及如何通过 SaaS 产品组织协同缔造业务新增长等焦点议题。
由于本次大会的信息量太大,西红柿将聚焦“向量数据库”,为大家带来详细的介绍和评测。
一、什么是向量数据库?
向量数据库是一种专门用于存储和处理向量数据的数据库系统,它通过优化存储结构和查询算法,提供了高效的向量数据存储、相似度搜索、聚类和分类等功能。在图像、音频、文本等领域的应用中,向量数据库发挥着重要的作用。
向量数据库通常提供了丰富的查询接口和功能,如范围查询、k 近邻查询、相似性匹配等。同时,向量数据库还支持高并发和分布式部署,以应对大规模数据和高并发访问的需求。

向量数据库的工作流程包括以下步骤:
- 1、向量数据的存储:向量数据通常是高维的数值型数据,如图像特征向量、文本词向量等;向量数据库使用基于向量的存储结构,以便快速查询和处理;
- 2、向量索引:向量数据库使用 PQ、LSH 或 HNSW 等算法为向量编制索引,并将向量映射到数据结构,以便更快地进行搜索;
- 3、向量查询:向量数据库将查询向量与数据库中的向量进行比较,从而找到最近邻的向量;
- 4、查询结果的返回:向量数据库返回查询结果,通常包括与给定向量最相似的向量列表、向量之间的相似度得分等信息;该环节可以使用不同的相似性度量对最近邻重新排序。
二、腾讯云向量数据库** - **测试准备
准备工作概述:一台向量数据库 + 一个执行测试代码的客户端 + ann-benchamrk 官方的测试数据集和方法。
**2.1 **环境准备
- 1、登录腾讯云:https://console.cloud.tencent.com
- 2、创建向量数据库:从腾讯云控制台 一键创建 向量数据库实例。

ps.腾讯云向量数据库面向用户提供丰富的实例规格,可按需挑选。
- 操作系统选择: 版本建议使用‘TencentOS Server 3.1 (TK4)’, 此版本实测过程中安装 python3 相关的依赖 较顺利;
- 磁盘大小选择: 建议预留足够大的磁盘空间,200G 应该能满足实际测试需要,也可参考实际数据集的 大小创建;
- 内存大小选择: 因实际测试过程中,每一个进程都需要将被测试数据集全集加载进内存,可参考数据 集大小的 130% * 测试工具进程数 选择机器内存;
稍等几分钟,就建好啦,效果如下:
**2.2 **数据准备
2.1 上传测试工具及数据集到测试客户端
测试数据来源: ann-benchamrk 官方数据集测试工具可自动从外网官方站点下载。官网地址:https://ann-benchmarks.com/
2.2 安装测试工具依赖
软件依赖: python 版本大于 3.6.8, 使用建议的操作系统版本上的 python3 即可
2.2.1 安装操作系统依赖包
yum install python3-pillow-devel.x86_64
2.2.2 解决测试工具并安装 python 运行依赖
cd ann-benchmarks
pip3 install -r requirements.txt
2.2.3 需要的依赖包:
ansicolors==1.1.8
docker
h5py
matplotlib
numpy
pyyaml
psutil
scikit-learn
jinja2
pytest
dataclasses-json==0.5.7
dacite
urllib3
enum34
typing
tqdm
threadpool
三、性能测试
**3.1 测试 128 维数据在 HNSW **索引下的单核查询性能
从测试数据集说明中,找到 ann-benchamrk 已存在的名为 sift-128-euclidean 的数据集正好是 128 维度,可使用该数据集做测试。该数据集命令以 euclidean 结尾,表示使用 L2 相似算法。
执行测试后,看看数据库的资源表现吧。

- CPU 使用率接近 100%
- 内存和磁盘使用率较低
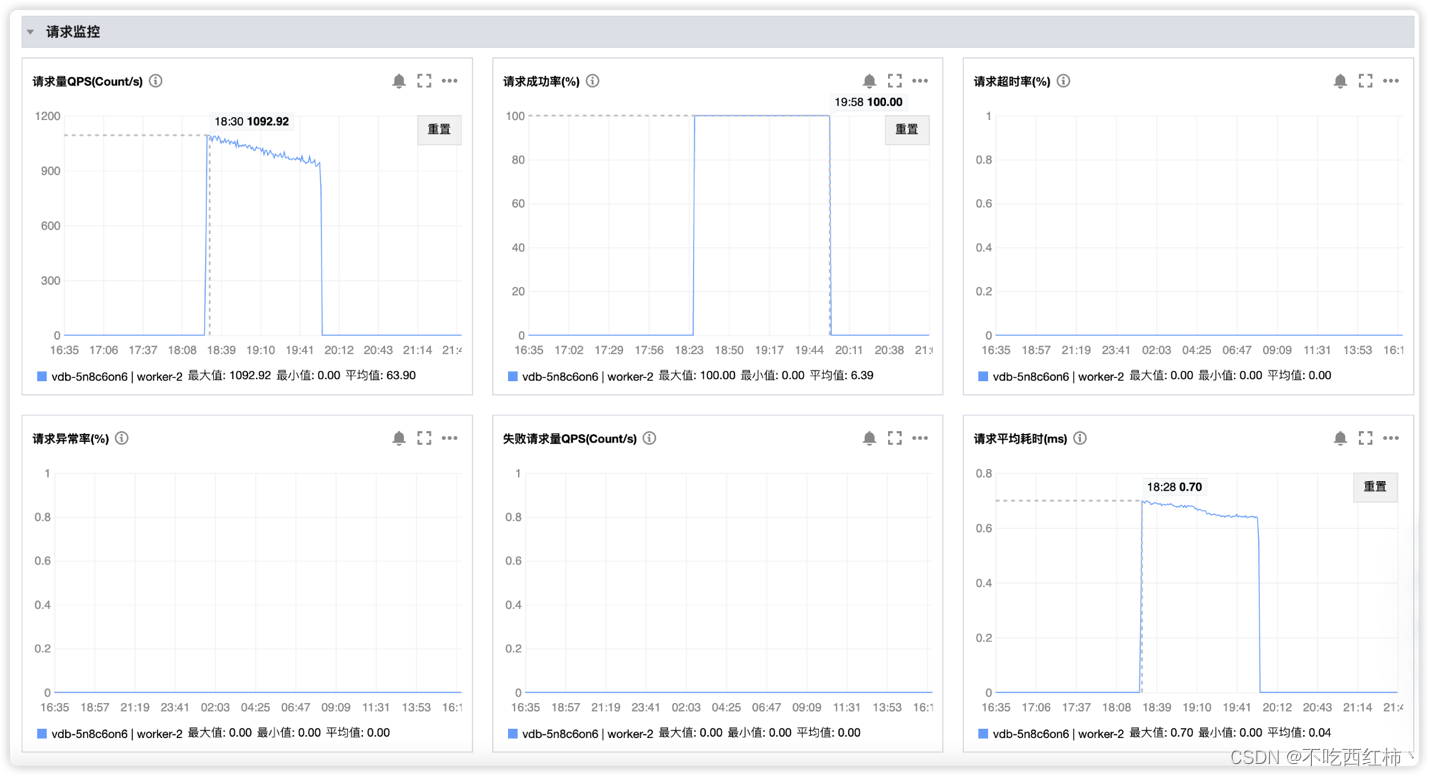
请求方面:
- 请求量 QPS(Count/s) 最大值: 1092.92 最小值: 0.00 平均值: 63.90
- 请求成功率(%) 最大值: 100.00 最小值: 0.00 平均值: 6.39
- 请求超时率(%) 最大值: 0.00 最小值: 0.00 平均值: 0.00
- 请求异常率(%) 最大值: 0.00 最小值: 0.00 平均值: 0.00
- 失败请求量 QPS(Count/s) 最大值: 0.00 最小值: 0.00 平均值: 0.00
- 请求平均耗时(ms) 最大值: 0.70 最小值: 0.00 平均值: 0.04
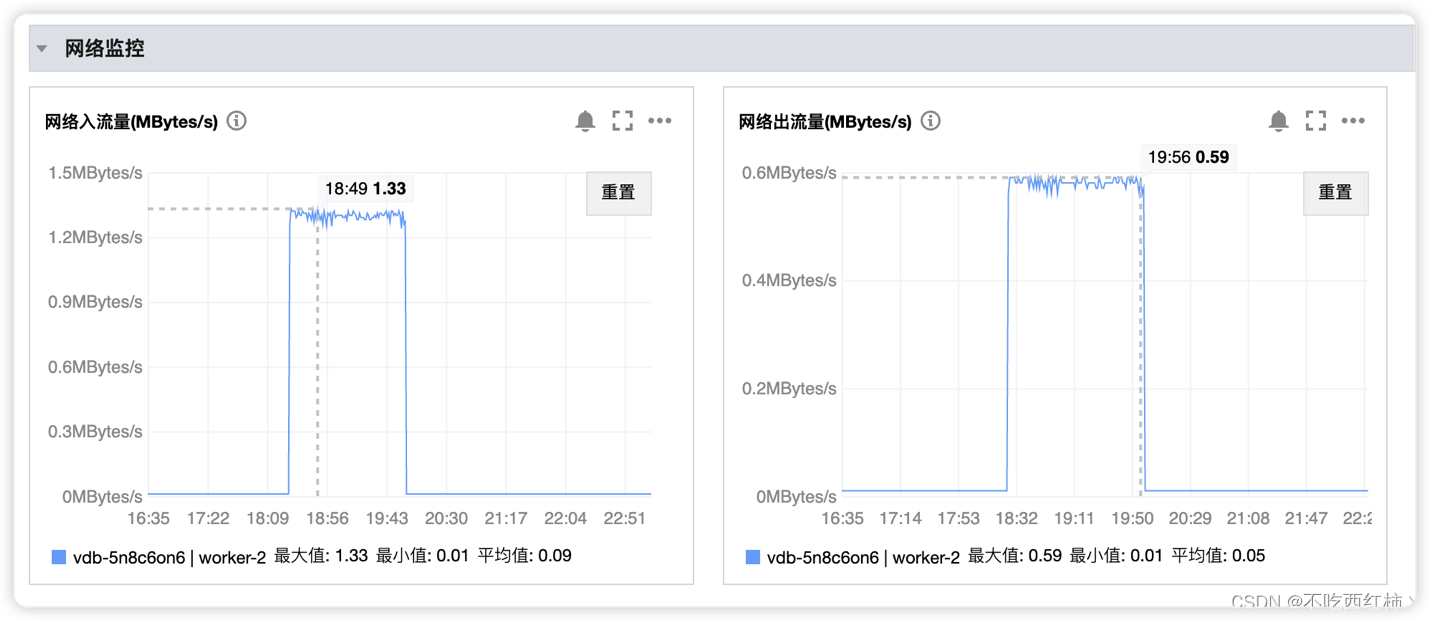
网络方面:在西红柿下载测试结果时,造成了一个峰值的。
向量数据库的单核性能表现令人赞叹。它展现出出色的处理能力和高效的计算速度。无论是在数据存储、索引构建还是查询处理方面,向量数据库都能够快速进行并行计算,并在单个核心上实现卓越的性能。
四、小结
腾讯云向量数据库专注于处理大规模的向量数据,并采用了高效的索引和查询算法,能够快速地进行相似度搜索和高维向量计算。使用户能够轻松地进行复杂的数据分析和机器学习任务。
腾讯云向量数据库还具备出色的可扩展性和稳定性。它支持自动水平扩展,能够根据数据规模和用户需求进行弹性扩容,保证了数据库的高可用性和性能稳定性。同时,腾讯云向量数据库提供了友好的管理界面和灵活的API接口,使得用户可以方便地进行数据操作和管理。
除此之外,腾讯云向量数据库还注重数据安全和隐私保护。它采用了多层次的安全措施,包括数据加密、访问控制和防火墙等,保证了用户数据的安全性和隐私保护。
总之,腾讯云向量数据库以其高性能、可扩展性和数据安全性而备受推崇,为用户提供了强大的数据处理和分析能力,是一项令人印象深刻的云端数据库解决方案。
更多精彩,请关注腾讯全球数字生态大会吧。
版权归原作者 不吃西红柿丶 所有, 如有侵权,请联系我们删除。