
😊😊😊欢迎来到本博客😊😊😊
本篇介绍的是Spark环境的准备🛠🛠🛠
预更新📑:体验第一个Spark程序

一.环境准备
配置环境:Hadoop、spark(本人是2.0.0)、JDK(1.8)、Linux(Centos6.7)
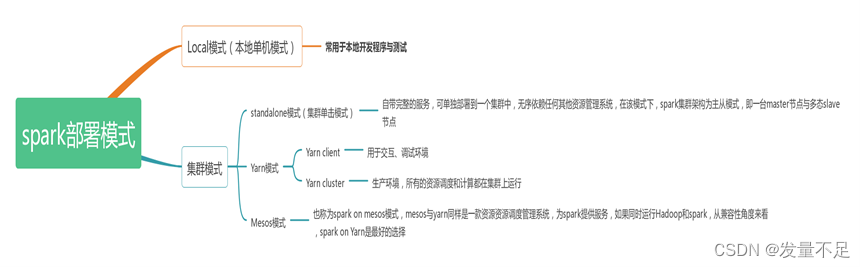
二·.spark的部署方式
spark部署模式分为Local模式和集群模式,在local模式,常用于本地开发与测试,集群模式又分为standalone模式(集群单机模式)、Yarn模式、mesos模式
三.spark集群安装部署
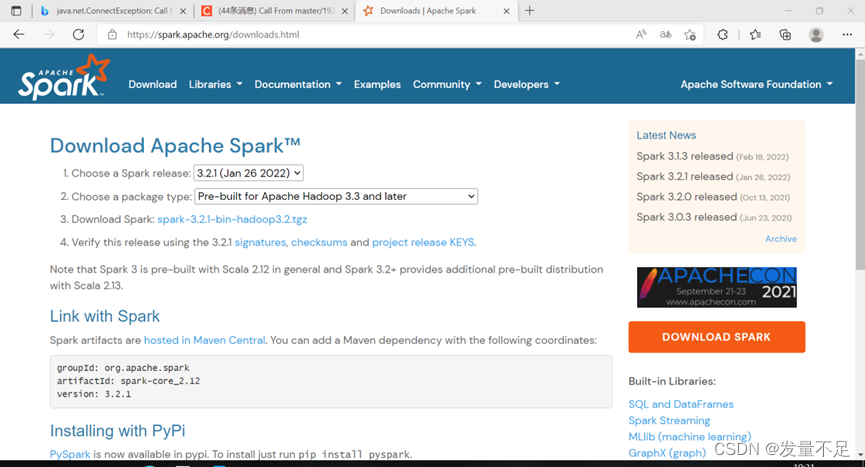
1下载spark安装包.
下载spark安装包 在Apache spark官网下载网址:Downloads | Apache Spark (最新且稳定的版本是3.2.1,本人安装版本为2.0.0)
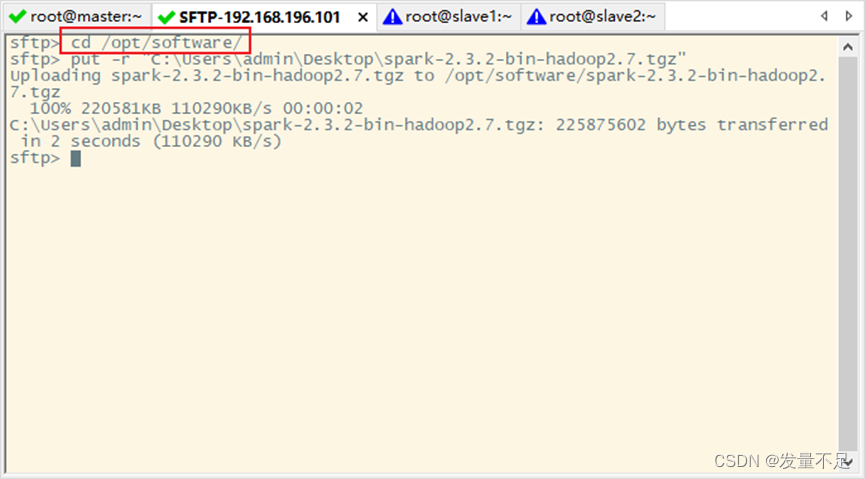
2.解压spark安装包
步骤1 先 alt+P,再拉spark-2.3.2-bin-hadoop2.7.tgz上传/opt/software目录下
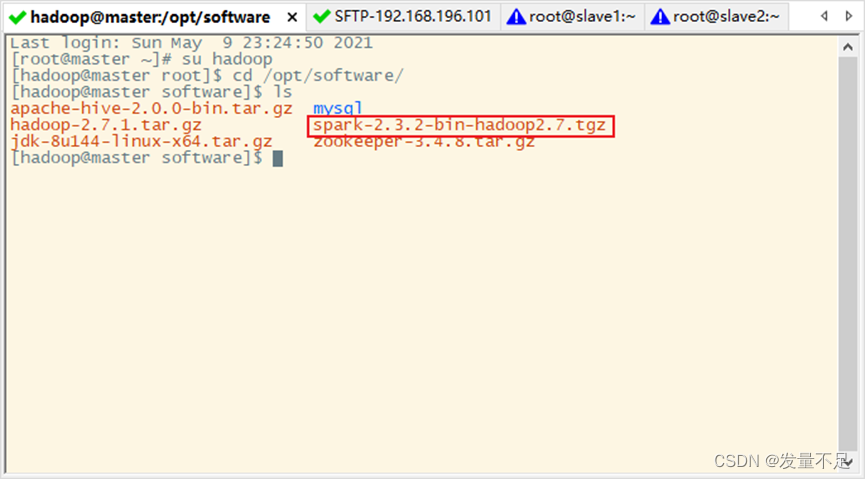
回到master切换hadoop用户
$su Hadoop
$ cd /opt/software
$ls
$ tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /opt/module/
3.修改配置文件
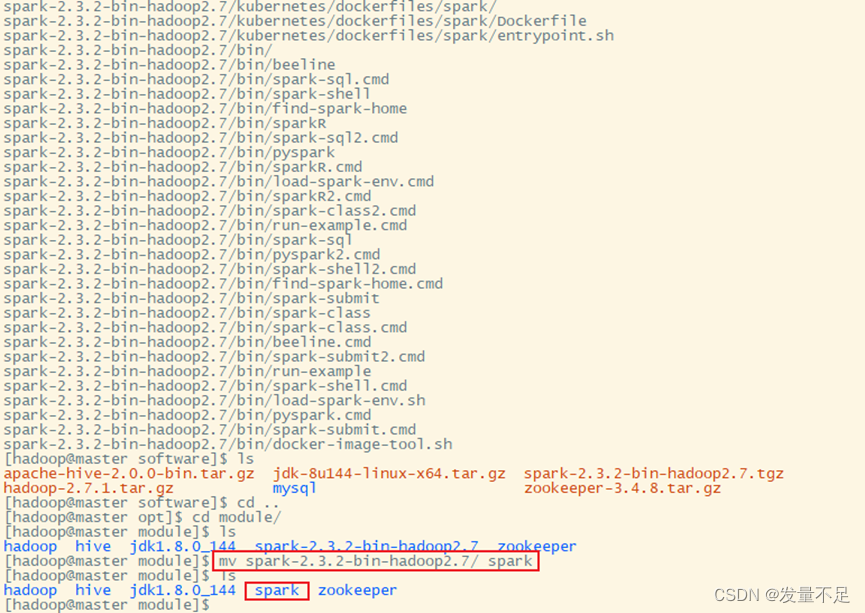
步骤1 使用mv命令将spark-2.3.2-bin-hadoop2.7重名为spark
$cd /opt/module
$ mv spark-2.3.2-bin-hadoop2.7/ spark
步骤2 先进入/opt/module/spark/conf/目录,将spark-env.sh.template复制给spark-env.sh
$ cd /spark/conf
$ ls
$ cp spark-env.sh.template spark-env.sh


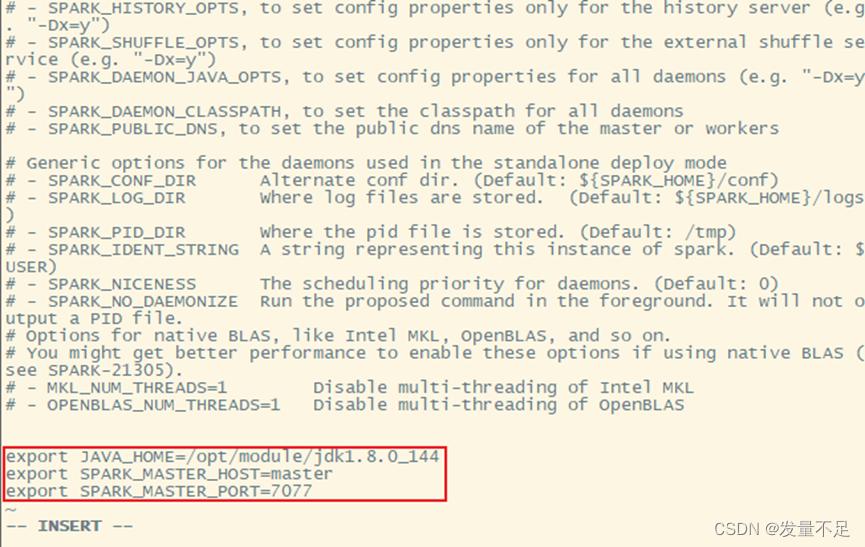
步骤3 修改spark-env.sh,配置内容:
$vi spark-env.sh

Java环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_144
**# **指定master的 IP
export SPARK_MASTER_HOST=master
**# **指定master的 端口
export SPARK_MASTER_PORT=7077
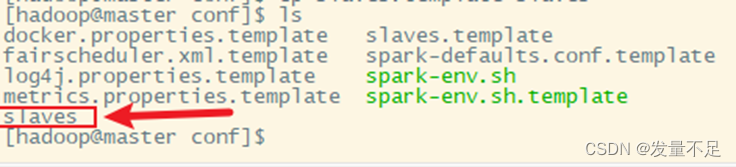
步骤4 复制slaves.template slaves 并重命名slaves
cp slaves.template slaves

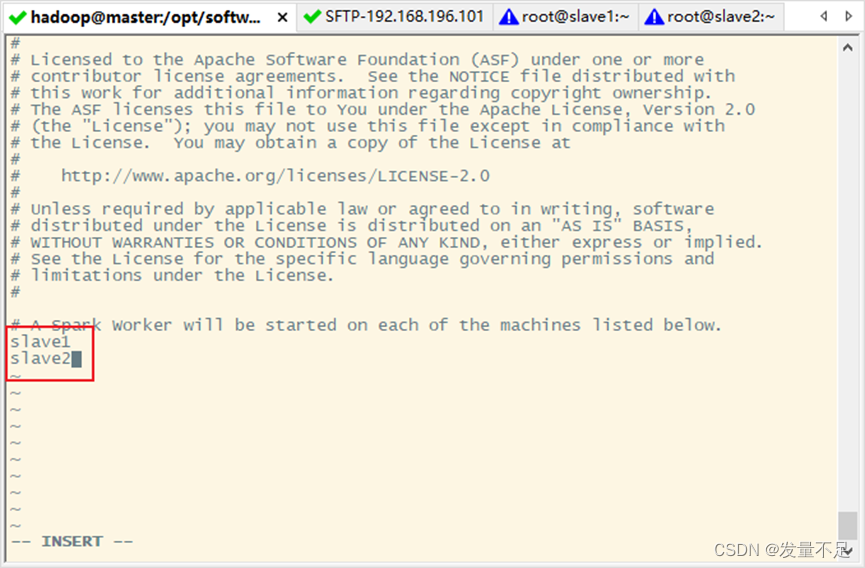
步骤5 使用vi slaves命令编辑slaves配置文件,指定从节点IP
$vi slaves
Slave1
Slave2
4.分发文件
步骤1 将spark目录分发slave1和slave2
$scp -r /opt/module/spark/ slave1:/opt/module/
$ scp -r /opt/module/spark/ slave2:/opt/module/


5 启动spark集群
**cd ..(**回到spark目录)
步骤1 $ sbin/start-all.sh

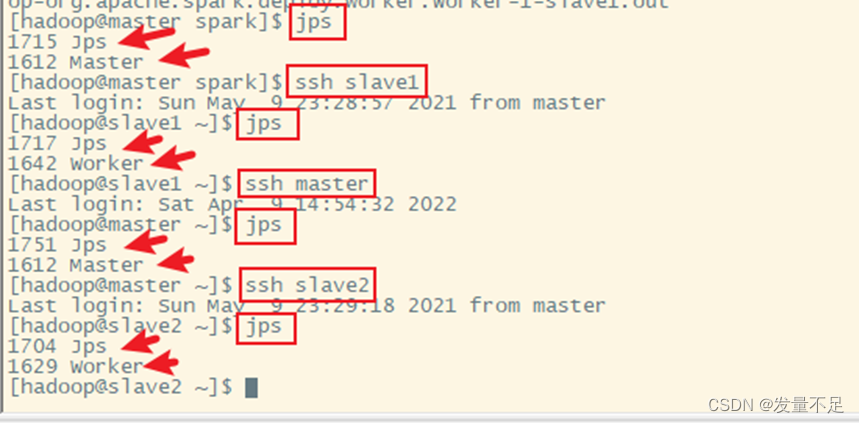
步骤2 先使用ssh命令切到slave1、slave2,使用jps查看各节点进程,主节点有master,从节点有worker
步骤3 访问spark管理界面(master) http://192.168.196.101:8080,如图:
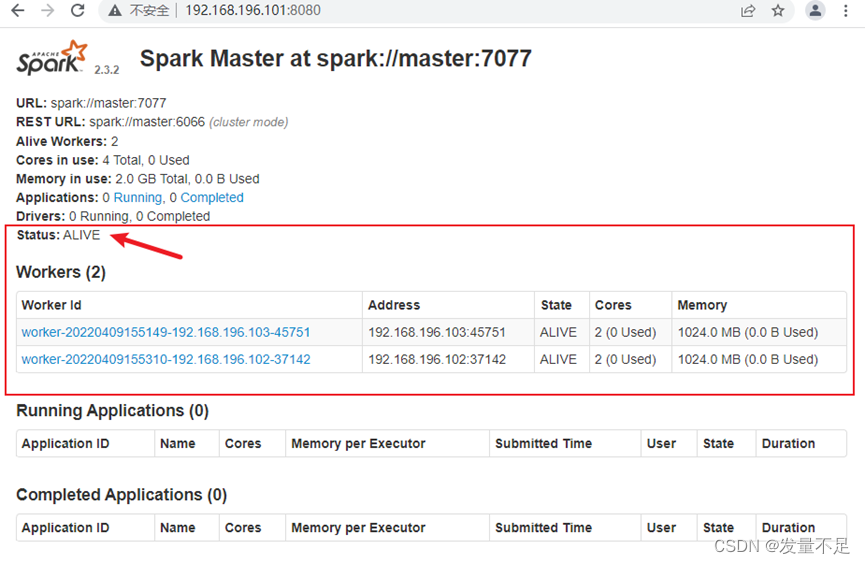 看到该状态
看到该状态
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。