
一、引言
Llama 2是Meta在LLaMA基础上升级的一系列从 7B到 70B 参数的大语言模型。Llama2 在各个榜单上精度全面超过 LLaMA1,Llama 2 作为开源界表现最好的模型之一,目前被广泛使用。
为了更深入地理解Llama 2的技术特点,特地在此整理了Llama 2模型架构、 预训练、SFT的内容详解,对于后续的RLHF和安全性分析,由于篇幅原因,笔者将写另一篇来介绍。
话不多说,直接上干货啦🥺
一、LLaMA 2简介
论文:https://arxiv.org/abs/2307.09288
Github:GitHub - facebookresearch/llama: Inference code for LLaMA models
Meta 在原本的LLaMA 1的基础上,增加了预训练使用的token数量;同时,修改了模型的架构,引入了Group Query Attention(GQA)。
并且,在Llama 2的基础上,Meta同时发布了 Llama 2-Chat。其通过应用监督微调来创建 Llama 2-Chat 的初始版本。随后,使用带有人类反馈 (RLHF) 方法的强化学习迭代地改进模型,过程中使用了拒绝采样和近端策略优化 (PPO)。
Llama 2-Chat的训练主要流程如下:

二、模型架构
2.1 主要架构
Llama 2采用LLaMA 1的大部分预训练设置和模型架构,包括:
- **Tokenzier: **和LLaMA 1一样的 tokenizer,使用 SentencePiece 实现的 BPE 算法。与LLaMA 1一样,将所有数字拆分为单个数字并使用字节来分解未知的 UTF-8 字符。总词汇量为 32k个 token。 (关于BPE,可参考BPE 算法原理及使用指南【深入浅出】 - 知乎)
- Pre-normalization:为了提高训练稳定性,LLaMa 对每个 Transformer 子层的输入进行归一化,而不是对输出进行归一化。LLaMa 使用了 RMSNorm 归一化函数。 (关于Pre-norm vs Post-norm,可参考为什么Pre Norm的效果不如Post Norm? - 科学空间|Scientific Spaces)
- SwiGLU 激活函数:LLaMa 使用 SwiGLU 激活函数替换 ReLU 以提高性能,维度从
变为
。SwiGLU是一种激活函数,它是GLU的一种变体, 它可以提高transformer模型的性能。SwiGLU的优点是它可以动态地调整信息流的门控程度,根据输入的不同而变化,而且SwiGLU比ReLU更
平滑,可以带来更好的优化和更快的收敛。 (关于SwiGLU激活函数,可参考激活函数总结(八):基于Gate mechanism机制的激活函数补充(GLU、SwiGLU、GTU、Bilinear、ReGLU、GEGLU)_glu激活-CSDN博客) - Rotary Embeddings:LLaMa 没有使用之前的绝对位置编码,而是使用了旋转位置编码(RoPE),可以提升模型的外推性。它的基本思想是通过一个旋转矩阵来调整每个单词或标记的嵌入向量,使得它们的内积只与它们的相对位置有关。旋转嵌入不需要预先定义或学习位置嵌入向量,而是在网络的每一层动态地添加位置信息。旋转嵌入有一些优点,比如可以处理任意长度的序列,可以提高模型的泛化能力,可以减少计算量,可以适用于线性Attention等。 (关于 RoPE 的具体细节,可参考十分钟读懂旋转编码(RoPE) - 知乎)
2.2 Group Query Attention (GQA)
Llama 2与 LLaMA 1 的主要架构差异包括上下文长度和分组查询注意力 (GQA) 的增加,如下图:

GQA:
自回归解码的标准做法是使用KV Cache,即缓存序列中先前token 的键 (K) 和值 (V) 对,以加快后续token的注意力计算。然而,随着上下文窗口或者批量大小的增加,多头注意力(MHA)模型中与KV Cache大小相关的内存成本会显著增加。对于大模型,KV Cache会成为推理时显存应用的一个瓶颈。
对于上述这种情况,有两种主流解决方案:
Multi Query Attention (MQA): 如下图所示,MQA在所有的query之间共享同一份键 (K) 和值 (V) 对
Group Query Attention (GQA): 如下图所示,GQA在不同的n (1<=n<=No. of heads)个query之间共享一份键 (K) 和值 (V) 对
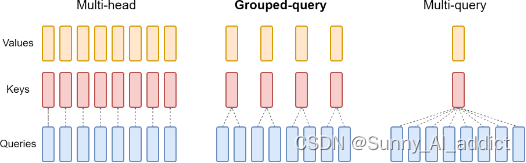
虽然仅使用单个键值头的多查询注意力 (MQA) 大大加快了解码器推理。然而,MQA 可能会导致质量下降。而查询注意力 (GQA),这是一种多查询注意力的泛化,它使用中间(多个,少于查询头的数量)键值头的数量。实验表明,经过预训练的 GQA 实现了接近多头注意力的质量,速度与 MQA 相当。
(关于MQA,可参考https://zhuanlan.zhihu.com/p/634236135;
关于GQA,可参考[LLM] Group query attention 加速推理 - 知乎;
关于KV Cache,可参考大模型推理加速:看图学KV Cache - 知乎)
三、预训练
3.1 预训练数据
- 训练语料库包括来自公开可用来源的新混合数据,不包括来自 Meta 产品或服务的数据。努力从已知包含大量关于私人的个人信息的某些站点中删除敏感数据。
- 在 2 万亿个数据上进行训练,因为这提供了良好的性能-成本权衡
- 对大多数事实源数据进行过采样,以增加知识和抑制幻觉
3.2 预训练过程及结果
3.2.1 预训练超参数
- 采用 Llama 1 的大部分预训练设置和模型架构
- 优化器:AdamW optimizer,
=0.9,
=0.95
- 学习率:余弦学习率,2000 step 的 warmup,最后 decay 到峰值学习率的 10%
- weight decay: 0.1
- gradient clipping:1.0
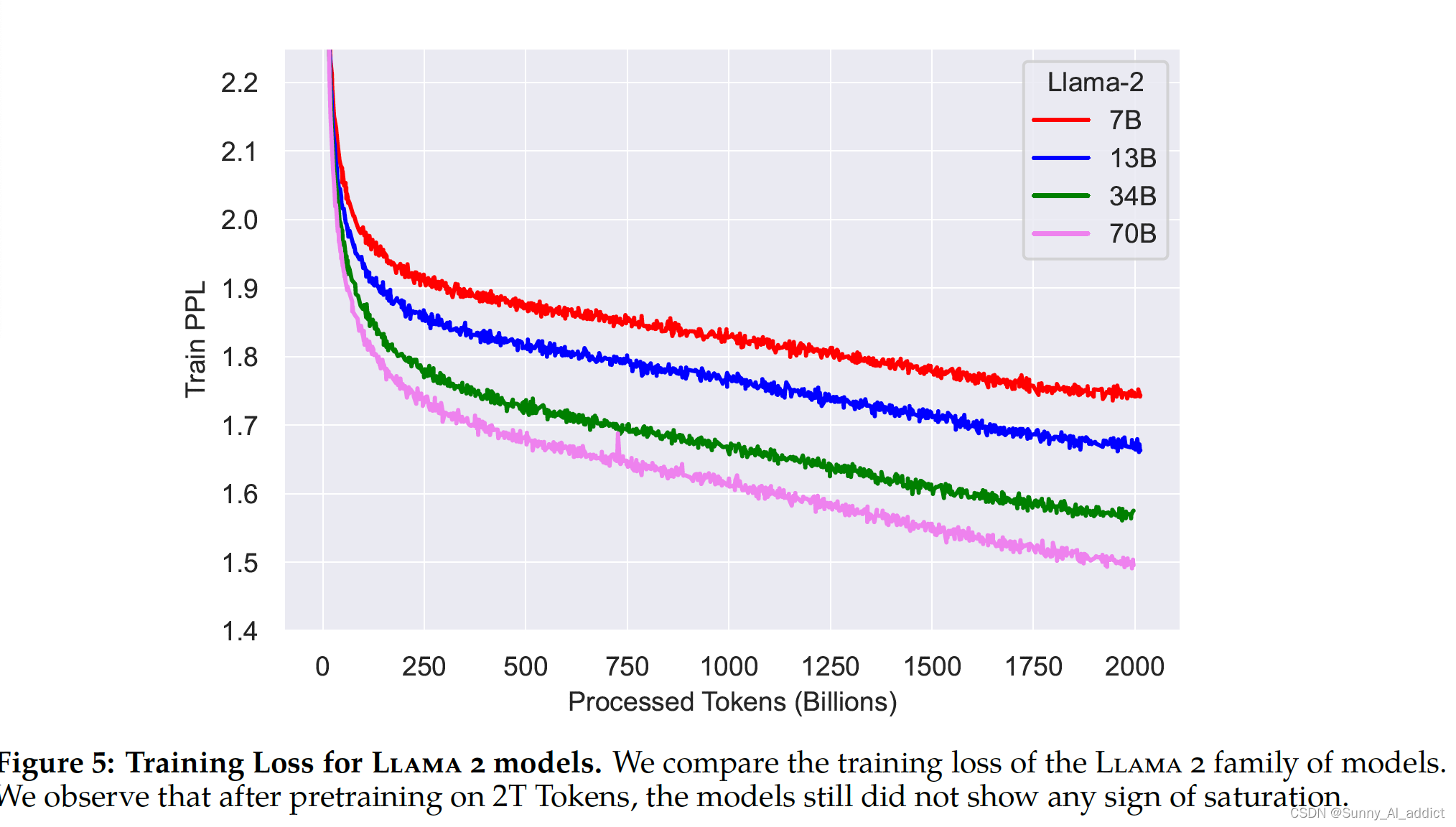
3.2.2 预训练的训练损失
训练 loss 曲线如下所示,即便训练了 2T 的 token 也暂时没有看到饱和现象:
3.2.3 Llama 2预训练模型评估
- 与开源模型在各个任务上的表现的比较:

除了代码基准测试之外,Llama 2 7B和30B模型在所有类别上都优于相应大小的MPT模型。Llama 2 7B和34B在所有类别的基准测试中都优于Falcon 7B和40B。此外,Llama 2 70B模型优于所有开源模型。
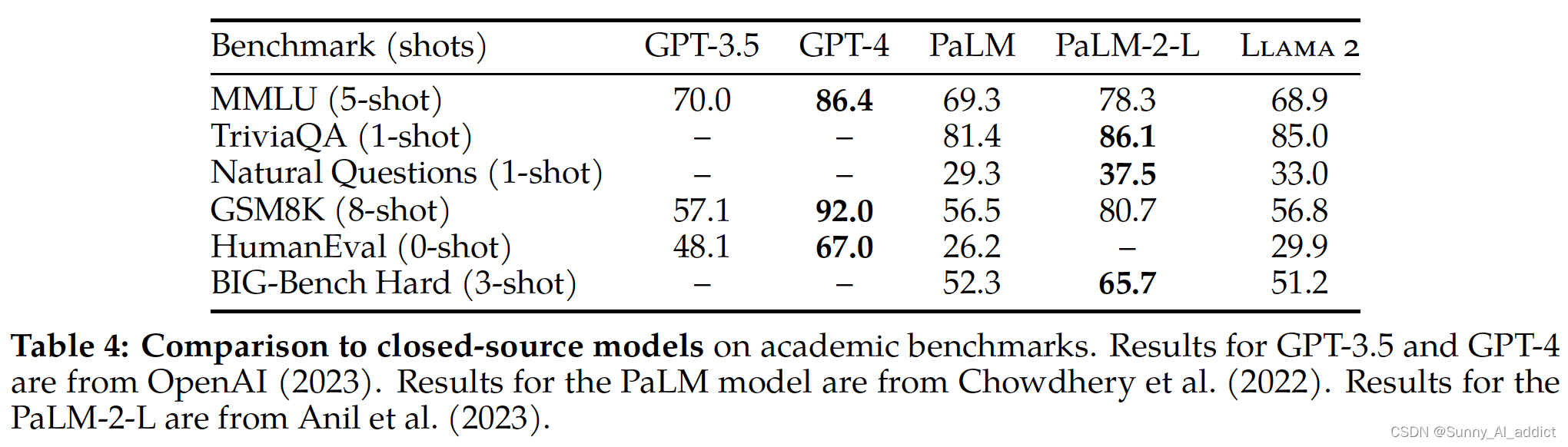
- 与闭源模型在各个任务上的表现的比较:
四、Supervized Fine-tuning (SFT)
4.1 SFT数据
为了引导,研究团队从公开可用的指令调优数据开始SFT阶段,但后来发现其中许多数据的多样性和质量都不够,特别是在将LLM与对话式指令结合起来方面。
- 高质量SFT数据收集:使用来自基于供应商的注释的更少但更高质量的示例,SFT的结果得到了显著改善。
- Quality> Quantity: 只通过几千个高质量的数据训练的模型效果就优于大规模开源 数据SFT 训练的模型,这与 Lima 的发现类似:有限的干净指令调优数据足以达到高水平的质量。在总共收集了 27,540 个注释后停止标注 SFT 数据。
- 标注偏置的引入:研究团队同时还观察到不同的注释平台和供应商可能导致明显不同的下游模型性能,这突显了即使使用供应商来获取注释时也需要进行数据检查的重要性。为了验证数据质量,研究团队仔细检查了一组180个样例,将人工提供的注释与模型生成的样本进行手工审查。令人惊讶的是,我们发现从结果SFT模型中采样的输出往往可以与人类标注者手写的SFT数据相竞争,这表明我们可以重新设置优先级,并将更多的注释工作投入到基于偏好的RLHF注释中。
4.2 SFT训练过程
4.2.1 SFT超参数
- 余弦学习率,初始学习率 2e-5,weight decay=0.1,batch_size=64,seq_len=4096
- 对于微调过程,每个样本由一个提示(prompt)和一个答案(answer)组成。为了确保模型的序列长度得到正确填充,将训练集中的所有提示和答案连接在一起。使用一个特殊的 token 将提示和答案分隔开。prompt <sep> answer <eos> prompt <sep> answer
- 采用自回归目标(autoregressive objective)并将用户提示(prompt)中的标记损失设为零,只用在答案(answer)标记上的loss进行反向传播。
- 对模型进行2个 epoch 的微调
版权归原作者 Sunny_AI_addict 所有, 如有侵权,请联系我们删除。