
以下是在VMware虚拟机中安装centos 7去配置hadoop。所以要准备的包
centos 7:Index of /apache/hadoop/common/hadoop-3.3.5
hadoop3.3.5:Index of /apache/hadoop/common/hadoop-3.3.5
#配置jdk环境
查看原本的jdk版本

其实原来的openjdk版本也是可用的,但是hadoop3.x不支持较低版本的jdk,所以这里卸载重新安装新版本jdk文件
执行yum remove openjdk 卸载原来的jdk


可以利用yum search openjdk命令查看源中有那些jdk版本,我这里选取的是java-11版本
执行 yum install -y “java版本”安装新的jdk

因为openjdk不配置jps包,所以得自行安装
再执行java -version查看java版本
 java环境配置成功
java环境配置成功
#配置ssh
运行rpm -qa|grep -E “openssh”查看是否安装ssh

如果未安装ssh,运行yum install openssh-server -y、yum install openssh-clients -y

配置ssh(没什么特殊需求默认就行)
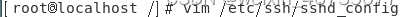

运行service sshd restart 重启ssh,

开放防火墙的22端口


用Xshell尝试连接
运行ip addr查看本机ip,
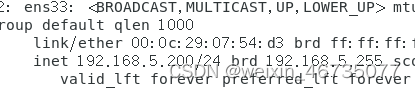
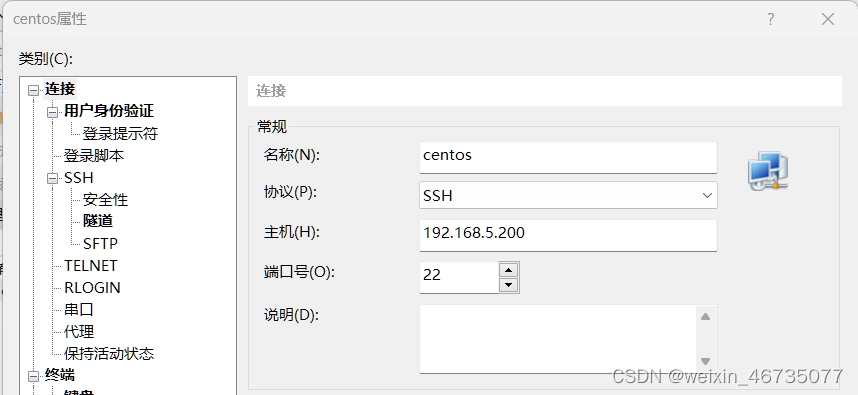
将信息填入新建的xshell中
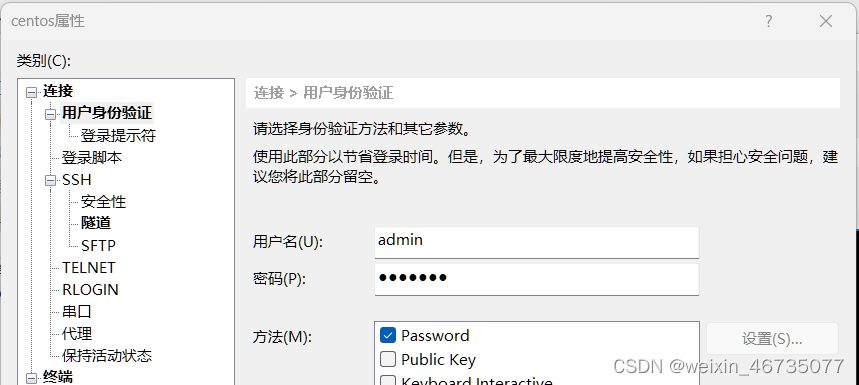
填入那台机子的登录账号和密码
点击连接,点击接受并保存

连接成功,这样接下来的命令操作基本上可以转到xshell里面操作

#下载安装hadoop
因为我们是要设置分布式的hadoop,首先我们要完成一些前序步骤,配置好单台主机
关闭防火墙

禁止防火墙开机启动

修改设备名称为hadoop00,重启计算机,配置结束后修改另外两个从节点计算机名为hadoop01,hadoop02。这里可以自行定义主机名称,但是要分清楚哪个是master哪些是slave

修改hosts文件,先把想要定义的另外两个从节点ip写入hosts

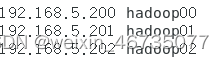
添加hadoop用户,添加完成后重新更改xshell的配置连接主机用户更换成hadoop
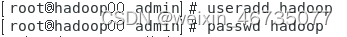
在根目录下新建一个hadoop文件夹,将此文件夹所有者设置为hadoop用户,方便以后存放hadoop相关文件

在刚才创建的hadoop文件中下载hadoop3.0,连接为顶上的连接

将下载的文件解压到当前文件夹中

运行vim /data/hadoop/hadoop-3.3.5/etc/hadoop/hadoop-env.sh 添加下面语句
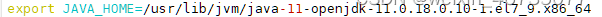
在/etc/profile里配置全局hadoop,source /etc/profile重新启动

单台主机配置完成,可以开始克隆出另外几台主机
关闭主机,开始克隆
点击管理里面的克隆,选择创建完整克隆,选择好克隆到的位置,设置好名称。克隆两台虚拟机
#搭建Hadoop集群
修改两台新建虚拟机名称


为三台虚拟机分别配置静态ip地址,配置到ens33网卡中
三台虚拟机分别进入修改ifcig-en33文件

Hadoop00和hadoop01
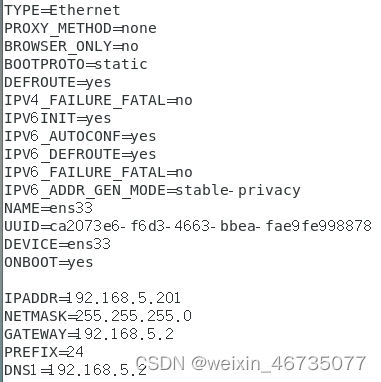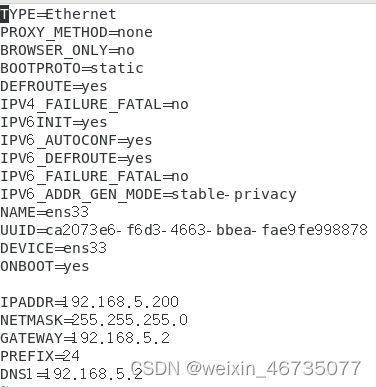
Hadoop02类似,IPADDR改为192.168.5.202,:wq保存退出,分别都运行systemctl restart network重启网卡
运行ping -c 3 hadoop01 / hadoop02测试是否连通


连通无误,网络配置结束
根据第二层的第5步的将三台主机配置到Xshell中,方便操作

为几台虚拟机配置免密登录
每台虚拟机都切换到/root文件夹中,运行 cd ~
 ** **
** **
接着运行: ssh-keygen -t rsa -P ‘’ 生成密钥 ,点击两次回车

查看密钥是否生成

在三台虚拟机的.ssh目录下创建新的文件 authorized_keys ,将三台虚拟机的ip_rsa.pub的密钥复制到authorized_keys里面
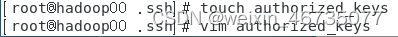
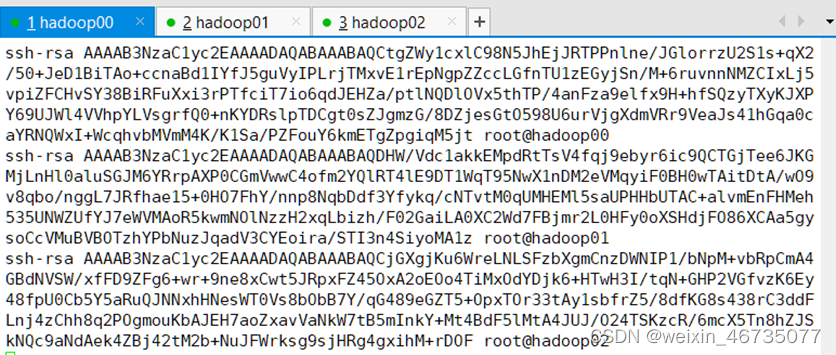
三台机子都要配置好authorized_keys文件,这样才能保证 每一台机子都能免密登录
在hadoop00中运行ssh hadoop01 / hadoop02测试无密码连通

输入命令exit退出该主机
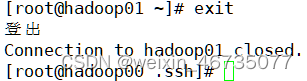
完成三台虚拟机的无密码登录
配置hadoop,先在hadoop00节点上操作
在root文件夹中新建hadoop文件夹
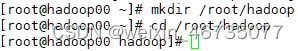
在hadoop文件夹中新建多个文件夹,这些文件夹复制存储hadoop的配置文件生成位置
用scp 命令将文件推送到hadoop01,hadoop02从节


修改/data/hadoop/hadoop-3.3.5/etc/hadoop下的文件配置
为hadoop-env.sh添加jdk环境在文件末尾添加


.xml文件配置都写在configuration标签当中,当中写入的内容可以去看一下别的文章解析,这里就不过多分析了。
在 core-site.xml写入
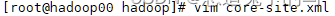
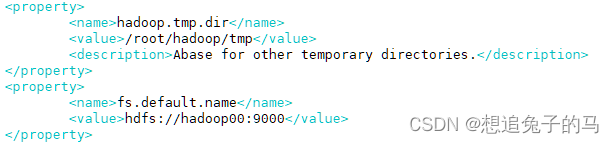
在hdfs-site.xml写入
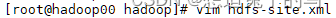
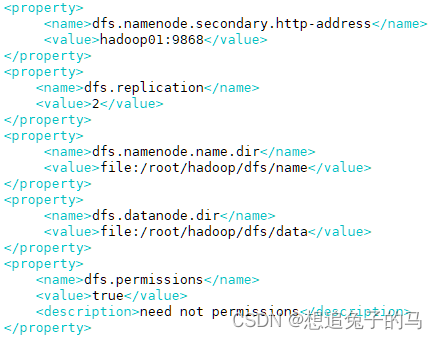
在mapred-site.xml写入


在workers写入从节点名称


在yarm-site.xml写入

回到上两层文件夹,切换到/sbin文件夹
在start-dfs.sh和stop-dfs.sh写入

在start-yarn.sh和stop-yarn.sh写入


运行vim /etc/selinux/config更改SELINUX值更改为 disabled

将上面配置的Hadoop文件推送到从节点主机上

#配置完成,可以开始尝试启动Hadoop
初始化hadoop
切换到hadoop所在文件夹文件夹中
输入命令 hdfs namende -format初始化hadoop,

运行sbin/start-all.sh启动hadoop

测试hadoop,打开浏览器输入 master主机ip+:9870

显示三台活跃主机

三台机子的datanode都正常显示

三台机子用jps查看都显示对应的程序启动了
hadoop00主节点

hadoop01主从节点

hadoop02从节点

浏览器打开 resourcemanager节点ip+:8088 访问
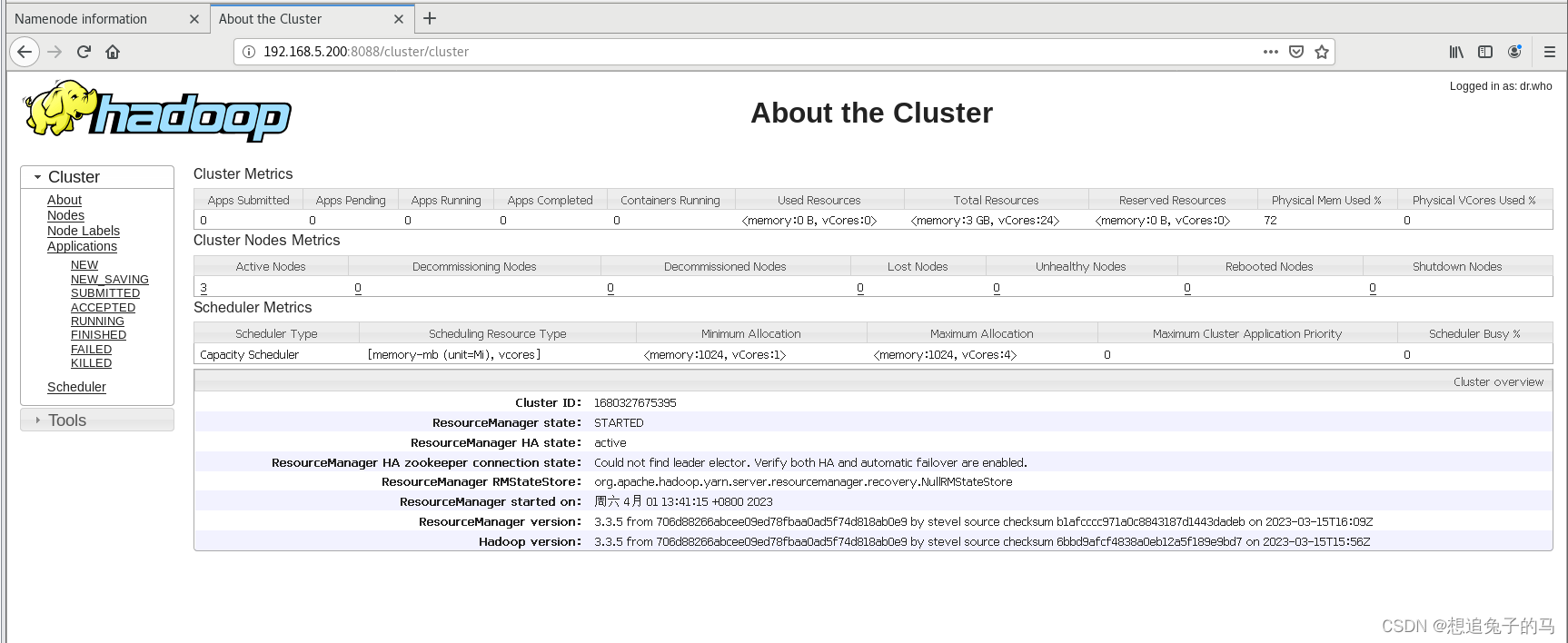
Hadoop分布式集群搭建完成
Hadoop00
Hadoop01
Hadoop02
HDFS
Namenode、Datanode
Secondarynamenode、Datanode
Datanode
YARN
Resourcemanager、Nodemanager
Nodemanager
Nodemanager
拓展
** **想要添加新的节点,只需要新配置好的从节点(直接克隆一台机子),更改好ip和主机名称。将主机配置入etc/hadoop/workers再启动hadoop就成功完成添加新节点了

版权归原作者 想追兔子的马 所有, 如有侵权,请联系我们删除。