
Spark内存迭代是每个task根据算子之间形成的DAG在内存中不断迭代计算的过程。
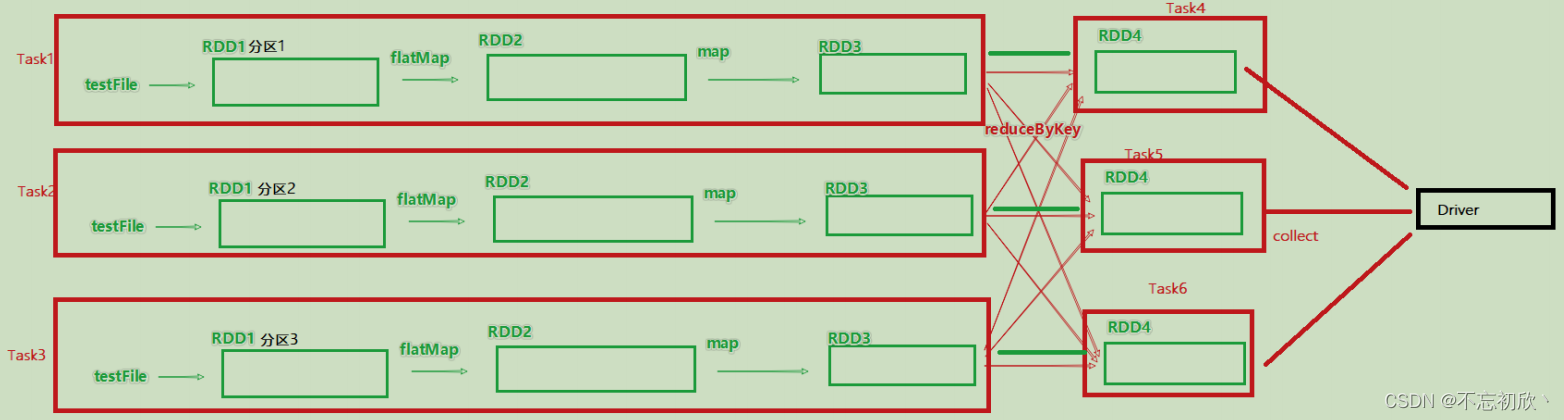
如图,带有分区的DAG以及阶段划分,可以从图中得到逻辑上最优的task分配。一个task是一个线程来具体执行。task1中的rdd1,rdd2,rdd3的迭代计算,都是由一个task(线程完成),这一阶段的这一条线,是纯内存计算。task1,task2,task3就形成了三个并行的内存计算管道。
Spark默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都遵循全局并行度的要求,来规划自己的分区数,如果全局并行度是3,其实大部分算子的分区都是3。Spark计算,我们一般推荐只设置全局并行度,不再算子上设置并行度,除了一些排序算子外,计算算子就采用默认的分区就可以了
Spark是怎么做内存计算的?DAG的作用是什么?Stage阶段划分的作用是什么?
- Spark会产生DAG图
- DAG图会基于分区和宽窄依赖关系划分阶段
- 一个阶段内部都是窄依赖,在窄依赖内,如果形成前后1:1的分区对应关系,就可以产生许多内存迭代计算的管道
- 这些内存迭代计算的管道,就是一个个具体执行的task
- 一个task是一个具体的线程,任务跑在一个线程内,就是走内存计算
Spark为什么比MapReduce快?
- Spark算子丰富,MapReduce算子匮乏,MapReduce这个编程模型,很难在一套MR中处理复杂的任务,很多的复杂任务,是需要写多个MapReduce进行串联,多个MR串联通过磁盘交互数据
- Spark可以执行内存迭代,算子之间形成DAG基于依赖划分阶段后,在阶段内形成内存迭代管理,在算子交互上,和计算上可以尽量多的内存计算而非磁盘迭代。但是MapReduce的Map和Reduce之间的交互依旧是通过磁盘来交互的。
本文转载自: https://blog.csdn.net/weixin_44639720/article/details/130031672
版权归原作者 不忘初欣丶 所有, 如有侵权,请联系我们删除。
版权归原作者 不忘初欣丶 所有, 如有侵权,请联系我们删除。