
一,什么是spark
Apache Spark 是一个快速的通用集群计算系统,它提供JAVA Scala Python R 的高级API,以及支持常规的执行图和优化引擎,并且还支持一组丰富的跟高级别的工具,包括Spark SQL 用于SQL和结构化数据的处理,MLlib机器学习,GraphX用于图形处理,Spark Streaming 流处理

二,spark特点
1、速度快
与Hadoop相比,Spark基于内存的运算效率要快100倍以上,基于硬盘的运算效率也要快10倍以上。Spark实现了高效的DAG执行引擎,能够通过内存计算高效地处理数据流。

2、易用性
Spark编程支持Java、Python、Scala及R语言,支持交互式的Shell操
3、通用性
Spark提供了统一的解决方案,适用于批处理、交互式查询、实时流处理、机器学和图计算,它们可以在同一个应用程序中无缝地结合使用
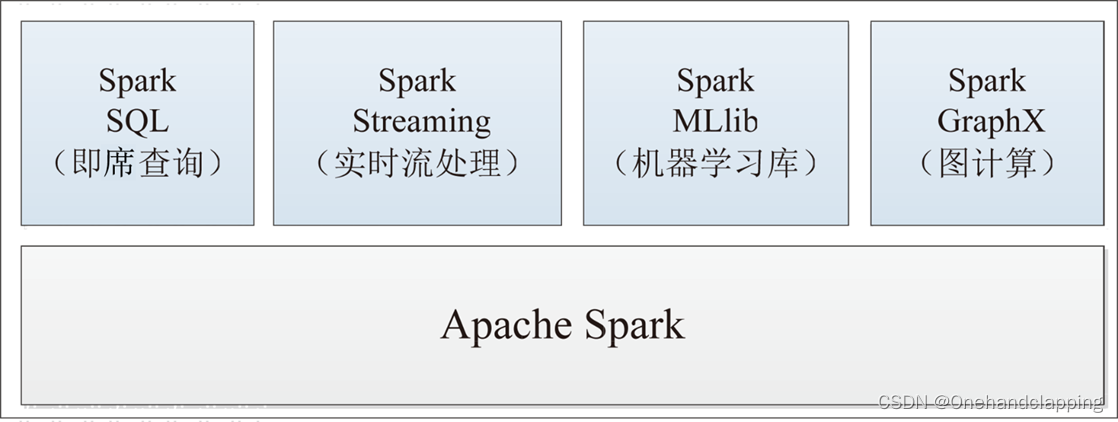
4、兼容性
Spark开发容pSpark可以运行在Hadoop模式、Mesos模式、Standalone独立模式或Cloud中,可以访问各种数据源,包括本地文件系统、HDFS、Cassandra、HBase和Hive等
三,spark生态圈
1,Spark Core:
Spark的核心,提供底层框架及核心支持。
2,BlinkDB:
一个用于在海量数据上进行交互式SQL查询的大规模并行查询引擎,允许用户通过权衡数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内
3,Spark SQL:
可以执行SQL查询,支持基本的SQL语法和HiveQL语法,可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
4,SparkStreaming:
可以进行实时数据流式计算
5,MLBase:
是Spark生态圈的一部分,专注于机器学习领域,学习门槛较低。
MLBase由4部分组成:MLlib、MLI、ML Optimizer和MLRuntime
6,Spark GraphX:
GraphX内置了许多与图相关的算法,如在移动社交关系分析中可使用图计算相关算法进行处理和分析。
7.SparkR:
AMPLab发布的一个R语言开发包,使得R语言编写的程序不只可以在单机运行,也可以作为Spark的作业运行在集群上,极大地提升了R语言的数据处理能力。

四,spark和 mapreduce的比较
1.spark和Mapreduce的简单介绍
MapReduce:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
spark:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
2.特点
mr:稳点,但是编程API不灵活、速度慢、只能做离线计算
spark:通用、编程API简洁、快,但是相较于mr没有mr更稳定
3.关于运行环境:
MR运行在YARN上,
spark:
local:本地运行
standalone:使用Spark自带的资源管理框架,运行spark的应用
yarn:将spark应用类似mr一样,提交到yarn上运行
mesos:类似yarn的一种资源管理框架
4.MapReduce和Spark的本质区别:
MR只能做离线计算,如果实现复杂计算逻辑,一个MR搞不定,就需要将多个MR按照先后顺序连成一串,一个MR计算完成后会将计算结果写入到HDFS中,下一个MR将上一个MR的输出作为输入,这样就要频繁读写HDFS,网络IO和磁盘IO会成为性能瓶颈。从而导致效率低下。
spark既可以做离线计算,有可以做实时计算,提供了抽象的数据集(RDD、Dataset、DataFrame、DStream)有高度封装的API,算子丰富,并且使用了更先进的DAG有向无环图调度思想,可以对执行计划优化后在执行,并且可以数据可以cache到内存中进行复用。
五,结构化,非结构化数据
1,结构化数据
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。
一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
如mysql数据库中的数据、csv文件
2,非结构化数据
非结构化数据是指信息没有一个预先定义好的数据模型或者没有以一个预先定义的方式来组织。非结构化数据一般指大家文字型数据,但是数据中有很多诸如时间,数字等的信息。相对于传统的在数据库中或者标记好的文件,由于他们的非特征性和歧义性,会更难理解。
文本、图片、音频/视频信息等等。
六,spark架构
1,ClusterManager
资源管理器,即在集群上获取资源的外部服务,目前主要有Standalone(Spark原生的资源管理器)和YARN(Hadoop集群的资源管理器)
2,SparkWorker
集群中任何可以运行应用程序的节点,运行一个或多个Executor进程
3,Executor
执行器,在Spark Worker上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
4,Task
被发送到某个Executor的具体任务。
七,spark运行流程
1,Standalone****模式运行流程

2,SparkonY****ARN
a.yarn-client运行流程
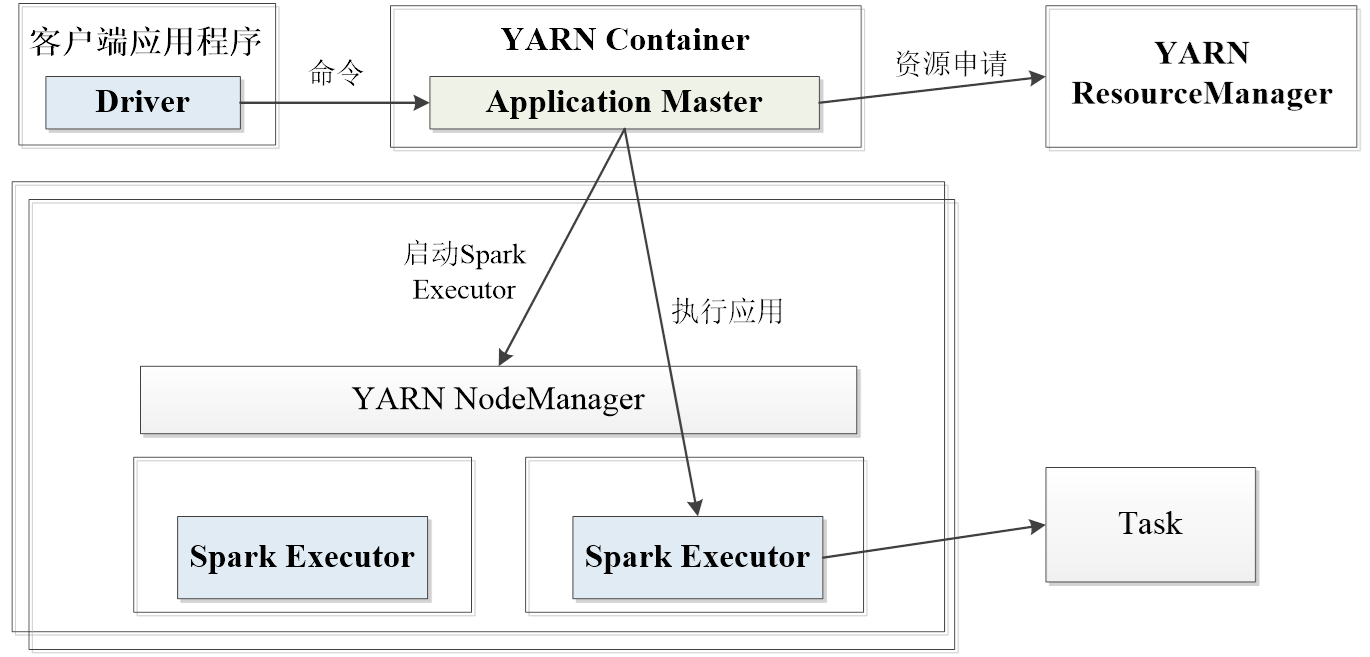
b.yarn-cluster运行流程
八,spark核心原理
1,窄依赖:
表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
2,宽依赖:
表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。

3,RDD Stage划分

版权归原作者 Onehandclapping 所有, 如有侵权,请联系我们删除。