
大数据挖掘与技术部分
基本概念:
数据预处理是指在进行数据分析和建模之前,对原始数据进行清洗、转换、集成和规约等操作的过程。数据预处理的目的是提高数据的质量,使数据更加适合进行分析和建模。
数据预处理包括以下几个方面:
数据清洗:去除重复数据、处理缺失值、去除异常值等。
数据转换:将数据从一种格式转换为另一种格式,例如将文本数据转换为数值型数据。
数据集成:将来自不同数据源的数据进行整合,例如将不同表格中的数据进行合并。
数据规约:对数据进行压缩、抽样等处理,以便于存储和处理。
数据预处理的重要性在于,原始数据往往存在各种问题,例如缺失值、异常值、重复值等,这些问题会影响到后续的分析和建模。因此,在进行数据分析和建模之前,需要对原始数据进行预处理,以提高数据质量和分析效果。
Apriori算法
Apriori算法是关联规则挖掘技术的最基本算法.目前关联规则的并行数据挖掘算法大都以Apriori算法为基础,它具有无可替代的独特地位。Apriori算法本质主要包含两个方面问题,第一个是找出事务数据库中所有的频繁数据项集。第二个是如何生成强关联规则。
Apriori 原理
Apriori算法的核心思想是基于频繁项集理论的递归方法,采用逐层搜索的迭代方法挖掘出在目标事务数据库中所有频繁项集,直至找到最高阶频繁项集即止,最后通过对获得的频繁项集进行计算得到强关联规则。
2.决策树的构建
2.1 基本原理
策略:自上而下分而治之
●.自根至叶的递归过程, 在每个中间结点寻找一 个“划分” 属性。
●1)开始:构建根节点;所有训练数据都放在根节点,选择-个最优特征,按着这一特征将训练数据集分割成子集,进入子节点。
●2)所有子集按内部节点的属性递归的进行分割。
●3)如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
●4)每个子集都被分到叶节点.上,即都有了明确的类,这样就生成了一颗决策树。
策略:分而治之”(divide- -and-conquer)
自根至叶的递归过程,在每个中间结点寻找一个“划分”(split or test)属性
三种停止条件:
(1)当前结点包含的样本全属于同一类别,无需划分;
(2)当前属性集为空,或是所有样本在所有属性.上取值相同,无法划分;
(3)当前结点包含的样本集合为空,不能划分.
1.朴素贝叶斯算法核心思想
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯(Naive Bayes)分类是贝叶斯分类中最简单,也是常见的一种分类方法。
朴素贝叶斯算法的核心思想是通过考虑特征概率来预测分类,即对于给出的待分类样本,求解在此样本出现的条件下各个类别出现的概率,哪个最大,就认为此待分类样本属于哪个类别。
举个例子:眼前有100个西瓜,好瓜和坏瓜个数差不多,现在要用这些西瓜来训练一个「坏瓜识别器」,我们要怎么办呢?
一般挑西瓜时通常要「敲一敲」,听听声音,是清脆声、浊响声、还是沉闷声。所以,我们先简单点考虑这个问题,只用敲击的声音来辨别西瓜的好坏。根据经验,敲击声「清脆」说明西瓜还不够熟,敲击声「沉闷」说明西瓜成熟度好,更甜更好吃。
所以,坏西瓜的敲击声是「清脆」的概率更大,好西瓜的敲击声是「沉闷」的概率更大。当然这并不绝对——我们千挑万选地「沉闷」瓜也可能并没熟,这就是噪声了。当然,在实际生活中,除了敲击声,我们还有其他可能特征来帮助判断,例如色泽、跟蒂、品类等。
朴素贝叶斯把类似「敲击声」这样的特征概率化,构成一个「西瓜的品质向量」以及对应的「好瓜/坏瓜标签」,训练出一个标准的「基于统计概率的好坏瓜模型」,这些模型都是各个特征概率构成的。
这样,在面对未知品质的西瓜时,我们迅速获取了特征,分别输入「好瓜模型」和「坏瓜模型」,得到两个概率值。如果「坏瓜模型」输出的概率值大一些,那这个瓜很有可能就是个坏瓜。

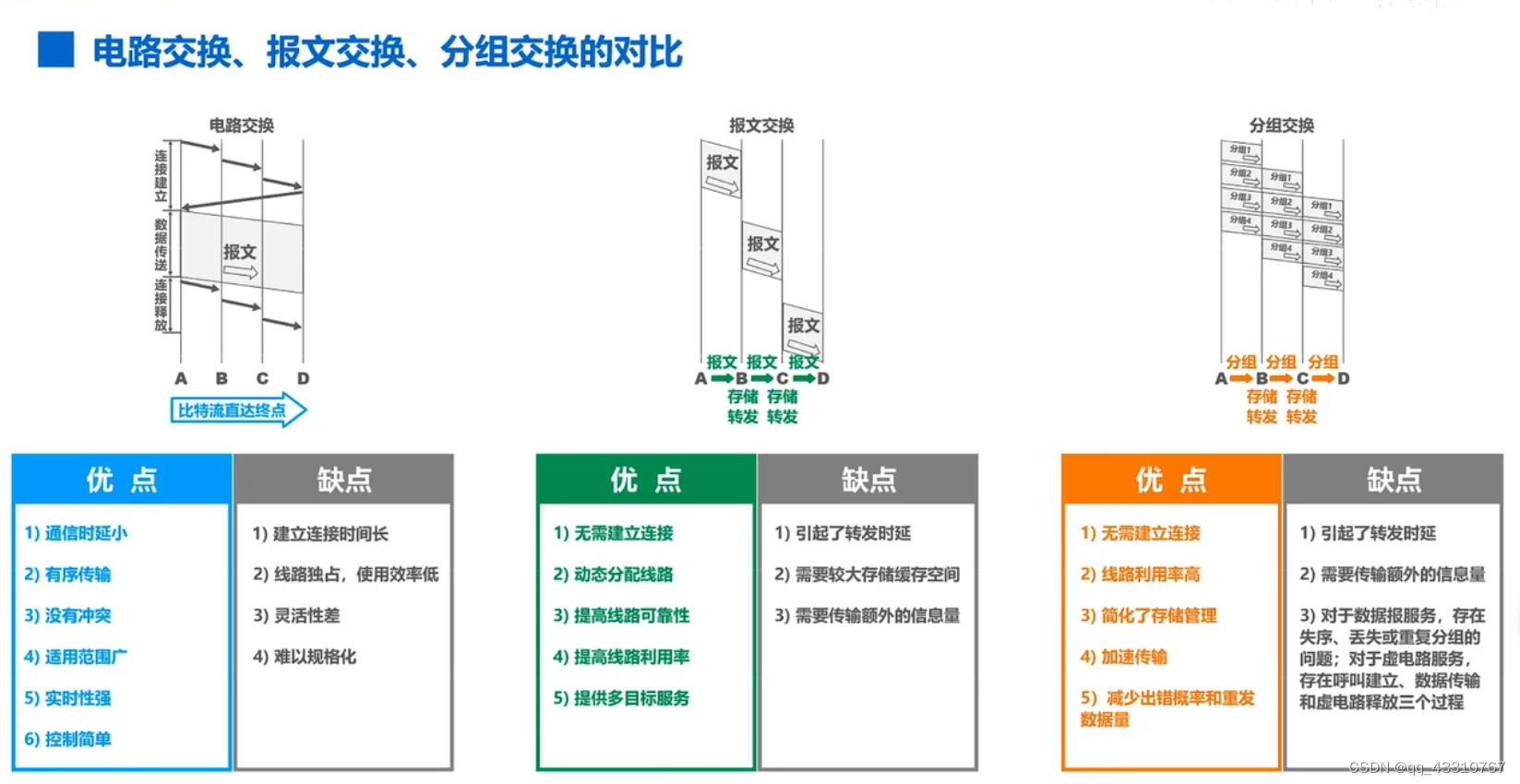



一个数据报分组交换网允许各结点在必要时将收到的分组丢弃。设结点丢弃一个分组的概率为p。现有一个主机经过两个网络结点与另一个主机以数据报方式通信,因此两个主机之间要经过3段链路。当传送数据报时,只要任何一个结点丢弃分组,则源点主机最终将重传此分组。试问:
(1)每一个分组在一次传输过程中平均经过几段链路?
(2)每一个分组平均要传送几次?
(3)目的主机每收到一个分组,连同该分组在传输时被丢弃的传输,平均需要经过几段链路?
答:(1)从源主机发送的每个分组可能走1段链路(主机-结点)、2段链路(主机-结点-结点)或3段链路(主机-结点-结点-主机)。
走1段链路的概率是p,
走2段链路的概率是p(1-p),
走3段链路的概率是(1-p)2
则,一个分组平均通路长度的期望值是这3个概率的加权和,即等于
L=1×p+2×p(1-p)+3×(1-p)2= p2-3 p+3
注意,当p=0时,平均经过3段链路,当p=1时,平均经过1段链路,当0
(2)一次传送成功的概率=(1-p)2,令α=(1-p)2,
两次传送成功的概率=(1-α)α,
三次传送成功的概率=(1-α)2α,
……
因此每个分组平均传送次数T=α+2α(1-α)+3α(1-α)2+
=[α/(1-α)][(1-α)+2(1-α)2+3(1-α)3+……]
因为 ∞
∑ kqk = q/(1-q)2
k=1
所以 T=[α/(1-α)]×(1-α)/[1-(1-α)]2 =1/α=1/(1-p)2
(3)每个接收到的分组平均经过的链路数H
H=L×T=(p2-3 p+3)/(1-p)2


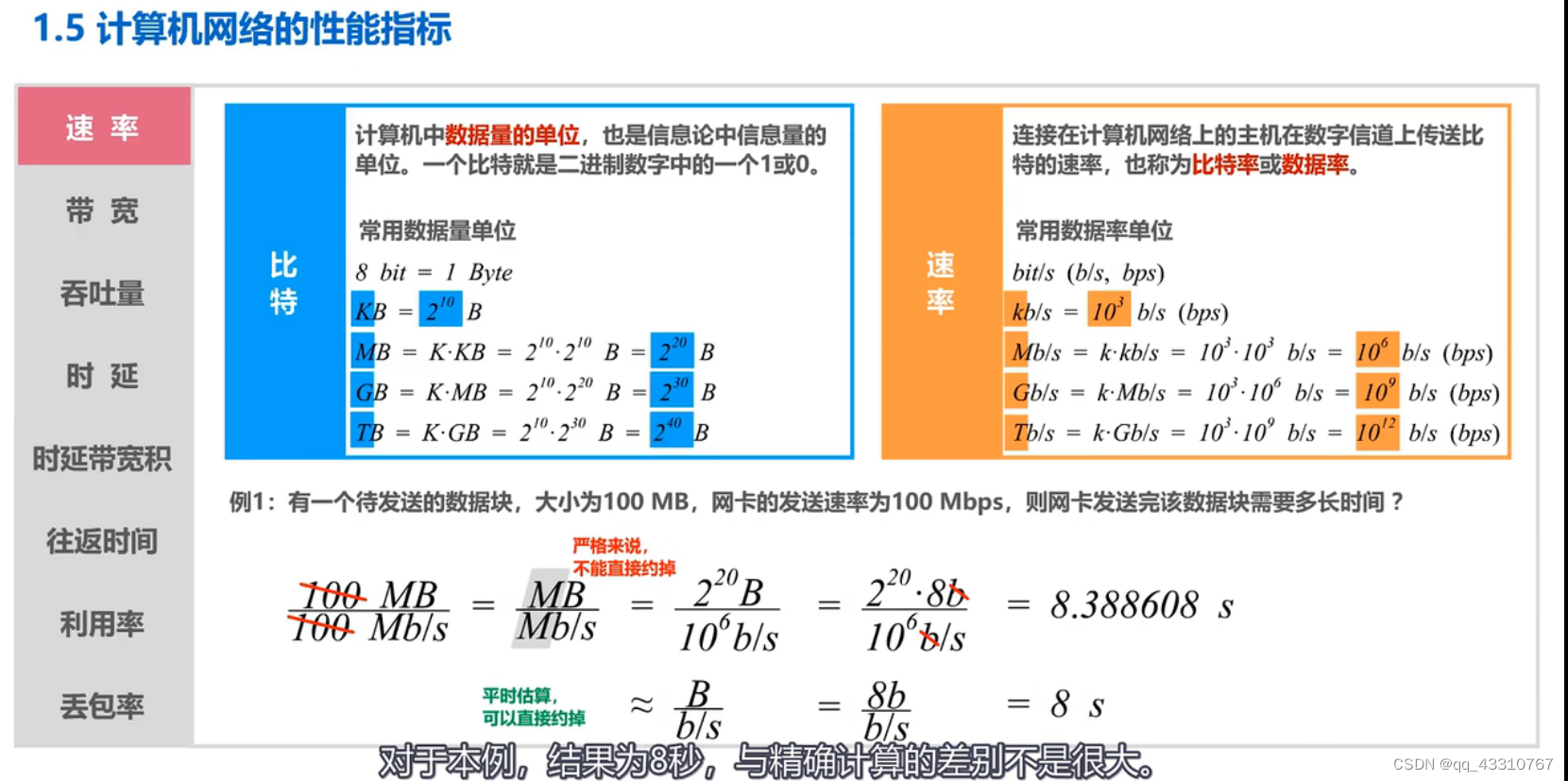
假设TCP在一个带宽无限的通道上使用窗口最大值(64KB)进行传输,其平均往返时延为20毫秒,求其最大吞吐量。如果其平均往返时延为40毫秒,最大吞吐量又为多少?
带宽无限说明发送时延忽略。
最大吞吐量=每秒发送数据次数×最大窗口。
平均往返时延20毫秒,每秒发送数据次数=1÷20×10⁻³=50次
最大窗口等于64KB,吞吐量单位为bit/s
所以最大吞吐量为50×64×1024×8=26214400bit/s
26214.4Kbit/s
26.2 Mbit/s
同理平均往返时延为40毫秒时,每秒发送数据次数=1÷40×10⁻³=25次
最大吞吐量为
25×64×1024×8=13.1Mbit/s





版权归原作者 qq_43310767 所有, 如有侵权,请联系我们删除。