
RBF神经网络
在学习RBF神经网络之前,最好先了解径向基函数的相关知识,参见径向基函数(RBF)插值。
RBF神经网络模型是1988年由Moody和Darken提出的一种神经网络结构,属于前向神经网络类型,能够以任意精度逼近任意连续函数,特别适合于解决分类问题。RBF网络是一种三层前向网络,第一层为由信号源节点组成的输入层,第二层为隐层,隐单元数视问题需要而定,隐单元的变换函数为非负非线性的函数RBF(径向基函数),第三层为输出层,输出层是对隐层神经元输出的线性组合
[
1
]
^{[1]}
[1]。网络结构大致如下图所示。
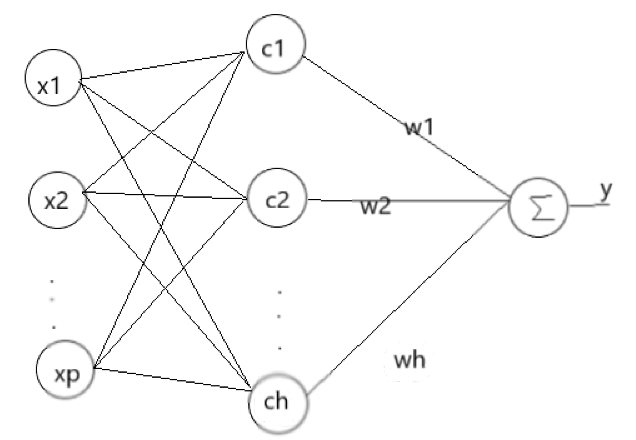
其中,输入向量
x
x
x 的维度为
p
p
p , 隐层大小为
h
h
h(神经元/中心点数量),
p
<
h
p<h
p<h 。**隐含层的作用是把向量从低维度p映射到高维度h,这样低维度线性不可分的情况到高维度就变得线性可分了,实际上是核函数的思想**。这样,网络由输入到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。网络的权就可由线性方程组直接解出,从而大大加快学习速度并避免局部极小问题。
径向基神经网络的激活函数可表示为:
R
(
x
p
−
c
i
)
=
exp
(
−
1
2
σ
2
∥
x
p
−
c
i
∥
2
)
R\left(x_p-c_i\right)=\exp \left(-\frac{1}{2 \sigma^2}\left\|x_p-c_i\right\|^2\right)
R(xp−ci)=exp(−2σ21∥xp−ci∥2)
根据径向基神经网络的结构,可得到网络的输出为:
y
j
=
∑
i
=
1
h
w
i
j
exp
(
−
1
2
σ
2
∥
x
p
−
c
i
∥
2
)
j
=
1
,
2
,
⋯
,
n
y_j=\sum_{i=1}^h w_{i j} \exp \left(-\frac{1}{2 \sigma^2}\left\|x_p-c_i\right\|^2\right) j=1,2, \cdots, n
yj=i=1∑hwijexp(−2σ21∥xp−ci∥2)j=1,2,⋯,n
采用最小二乘的损失函数表示
[
2
]
^{[2]}
[2] :
σ
=
1
P
∑
j
m
∥
d
j
−
y
j
c
i
∥
2
\sigma=\frac{1}{P} \sum_j^m\left\|d_j-y_j c_i\right\|^2
σ=P1j∑m∥dj−yjci∥2
网络学习方法
RBF神经网络求解的参数有3个:
- 基函数的中心;
- 方差;
- 隐含层到输出层的权值。
求解上述参数,目前有如下三种学习方法:
- 自组织选取中心学习法第一步:无监督学习过程,求解隐含层基函数的中心与方差第二步:有监督学习过程,求解隐含层到输出层之间的权值首先,选取h个中心做k-means聚类,对于高斯核函数的径向基,方差由公式求解:
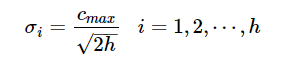 其中 c m a x cmax cmax 为所选取中心点之间的最大距离。隐含层至输出层之间的神经元的连接权值可以用最小二乘法直接计算得到,即对损失函数求解关于 w w w 的偏导数,使其等于0,可以化简得到计算公式为:
其中 c m a x cmax cmax 为所选取中心点之间的最大距离。隐含层至输出层之间的神经元的连接权值可以用最小二乘法直接计算得到,即对损失函数求解关于 w w w 的偏导数,使其等于0,可以化简得到计算公式为: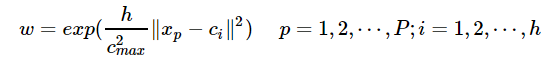
- 直接计算法
隐含层神经元的中心是随机地在输入样本中选取,且中心固定。一旦中心固定下来,隐含层神经元的输出便是已知的,这样的神经网络的连接权就可以通过求解线性方程组来确定。适用于样本数据的分布具有明显代表性。
- 有监督学习算法
通过训练样本集来获得满足监督要求的网络中心和其他权重参数,经历一个误差修正学习的过程,与BP网络的学习原理一样,同样采用梯度下降法。因此RBF同样可以被当作BP神经网络的一种
[
2
]
^{[2]}
[2]。
RBF神经网络特点
- 局部逼近RBF神经网络的隐神经元采用输入向量与中心向量的距离(如欧式距离)作为函数的自变量,并使用径向基函数(如Gaussian函数)作为激活函数。神经元的输入离径向基函数中心越远,神经元的激活程度就越低(高斯函数)。RBF网络的输出与部分调参数有关,譬如,一个 w i j w_{ij} wij值只影响一个 y i y_i yi的输出,RBF神经网络因此具有“局部逼近”特性。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xDQSMt2R-1667612060100)(https://gitee.com/mstifiy/img-load/raw/master/noteImg/OIP-C.GLdM4EpbPJngYMAZ_LAiGgHaFe)]所谓局部逼近是指目标函数的逼近仅仅根据查询点附近的数据。而事实上,对于径向基网络,通常使用的是高斯径向基函数,函数图像是两边衰减且径向对称的,当选取的中心与查询点(即输入数据)很接近的时候才对输入有真正的映射作用,若中心与查询点很远的时候,欧式距离太大的情况下,输出的结果趋于0,所以真正起作用的点还是与查询点很近的点,所以是局部逼近。
- 训练速度快使用RBF的训练速度快,一方面是因为隐含层较少,另一方面,局部逼近可以简化计算量。对于一个输入x,只有部分神经元会有响应,其他的都近似为0,对应的w就不用调参了。
完全内插法及其不足
之所以RBF能够拟合任意函数,可以从内插法的角度去理解。要拟合一个曲线,我们可以通过内插法获得这个曲线的表达函数,譬如:多项式插值、拉格朗日插值等。RBF 插值是一系列精确插值方法的组合;即表面必须通过每一个测得的采样值。

对于RBF插值,其特点即为,在输入数据集中,与中心点距离近的点对映射函数的贡献最大。
完全内插法即要求所有插值点都经过曲面,由于RBF内插对于每个x都有用到,所以是一种完全内插的形式,存在的问题就是当样本中包含噪声时,神经网络将拟合出一个错误的曲面,从而使泛化能力下降。另外,若样本x的数据远大于非线性函数φ,该求解变得不稳定,即为解超定方程。因此需要引入正则化方法,正则化的方法即通常加上正则化项。
两类径向基神经网络
正则化网络
性质:
• 正则化网络是一个通用逼近器,意味着,只要有足够多的隐含节点,它就可以以任意精度逼近任意多远连续函数。
• 给定一个未知的非线性函数f,总可以选择一组系数,使得网络对f 的逼近是最优的。
特点:
• 隐含节点的个数等于输入训练样本的个数,因此如果训练样本的个数N过大,网络的计算量将是惊人的,从而导致过低的效率甚至根本不可能实现。计算权值wij时,需要计算N×N矩阵的逆,其复杂度大约是O(N3),随着N的增长,计算的复杂度迅速增大。
• 矩阵过大,病态矩阵的可能性越高。矩阵A的病态是指,求解线性方程组Ax = b时,A中数据的微小扰动会对结果产生很大影响。病态成都往往用矩阵条件数来衡量,条件数等于矩阵最大特征值与最小特征值的比值。
广义网络
区别于正则化网络:正则化网络隐含节点数I等于输入训练样本的个数M,即是I=M。但广义网络隐含层I个节点个数小于M个输入节点,I<M
[
4
]
^{[4]}
[4]。
代码实现
下文代码中RBF神经网络采用直接计算法进行学习。代码框架参考文章
[
3
]
^{[3]}
[3]。
import time
from scipy.linalg import norm, pinv
from matplotlib import pyplot as plt
import numpy as np
classRBFN:def__init__(self, indim, numCenters, outdim):
self.indim = indim # 输入层维度
self.outdim = outdim # 输出层维度
self.numCenters = numCenters # 中心(隐层神经元)数量
self.centers =[np.random.uniform(-1,1, indim)for i inrange(numCenters)]# 初始化中心
self.beta =8# 方差初始化
self.W = np.random.random((self.numCenters, self.outdim))# 初始化权值def_basisfunc(self, c, d):# 激活函数定义assertlen(d)== self.indim
return np.exp(-(norm(c - d)**2)/(2* self.beta **2))def_calcAct(self, X):# 计算激活函数# calculate activations of RBFs
G = np.zeros((X.shape[0], self.numCenters),float)for ci, c inenumerate(self.centers):for xi, x inenumerate(X):
G[xi, ci]= self._basisfunc(c, x)return G
def_calcbeta(self):# 找到选取中心点最大值——及求解σ的值
bate_temp = np.zeros((self.numCenters, self.numCenters))# 定义一个矩阵 隐藏层中心值确定的for iindex, ivalue inenumerate(self.centers):for jindex, jvalue inenumerate(self.centers):
bate_temp[iindex, jindex]= norm(ivalue - jvalue)# 依次求解各中心层的值return np.max(bate_temp)/ np.sqrt(2* self.numCenters)deftrain(self, X, Y):"""
:param X: 样本数*输入变量数
:param Y:样本数*输出变量数
:return:无
"""# choose random center vectors from training set
rnd_idx = np.random.permutation(X.shape[0])[:self.numCenters]
self.centers =[X[i,:]for i in rnd_idx]# print("center", self.centers)
self.beta = self._calcbeta()# 根据样本中心计算σ值# print(self.beta)# calculate activations of RBFs
G = self._calcAct(X)# print(G)# calculate output weights (pseudoinverse)
self.W = np.dot(pinv(G), Y)# 伪逆法直接计算得到权值deftest(self, X):""" X: matrix of dimensions n x indim """
G = self._calcAct(X)
Y = np.dot(G, self.W)return Y
defgen_data(x1, x2):
y_all = np.sin(np.pi * x2 /2)+ np.cos(np.pi * x2 /3)
y_sample = np.sin(np.pi * x1 /2)+ np.cos(np.pi * x1 /3)# set y and add random noise# y_sample += np.random.normal(0, 0.1, y_sample.shape)return y_sample, y_all
if __name__ =='__main__':
num_sample =30# 数据生成
x1 = np.linspace(-10,10, num_sample).reshape(-1,1)
x2 = np.linspace(-10,10,(num_sample -1)*20+1).reshape(-1,1)
y_sample, y_all = gen_data(x1, x2)# Enable interactive mode.
plt.ion()# Create a figure and a set of subplots.
figure, ax = plt.subplots()# plot original data
plt.plot(x2, y_all,'r:')
plt.ylabel('y')
plt.xlabel('x')# plot input samplesfor i inrange(len(x1)):
plt.plot(x1[i], y_sample[i],'go', markerfacecolor ='none')# return AxesImage object for using.
pre_lines,= ax.plot([],[])
pre_lines.set_color('k')
center_points,= ax.plot([],[])
center_points.set_color('gray')
center_points.set_marker('s')
ax.set_autoscaley_on(True)# ax.set_xlim(min_x, max_x)
ax.grid()# plot learned model dynamicallyfor n_center inrange(2, num_sample):# RBF神经网络训练预测
rbf = RBFN(1, n_center,1)
rbf.train(x1, y_sample)
y_rec = rbf.test(x2)# update x, y data
pre_lines.set_xdata(x2)
pre_lines.set_ydata(y_rec)
plt.title('RBFN interpolation:$y=sin(\pi x/2)+cos(\pi x/3)$ with '+str(n_center)+' centers')# update centers
center_points.set_xdata(rbf.centers)
center_points.set_ydata(np.zeros(rbf.numCenters))# Need both of these in order to rescale
ax.relim()
ax.autoscale_view()# draw and flush the figure .
figure.canvas.draw()
figure.canvas.flush_events()
time.sleep(1)
plt.figure(1)
代码中,方差
σ
\sigma
σ 计算公式如下:
σ
=
d
max
2
n
\sigma=\frac{d_{\max }}{\sqrt{2 n}}
σ=2ndmax
这里
d
max
\mathrm{d}_{\max }
dmax 是选取中心的之间的最大距离。
n
\mathrm{n}
n 为隐函数节点的个数。防止径向基函数出现过尖或过平的情况。
对于隐层神经元的选取,代码中通过迭代寻找最优隐函数节点个数。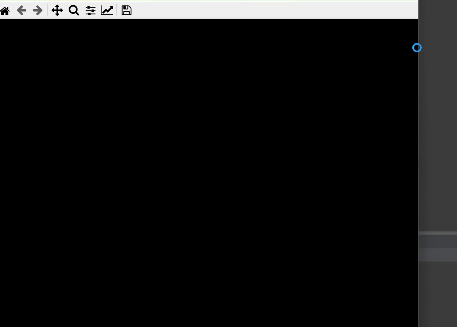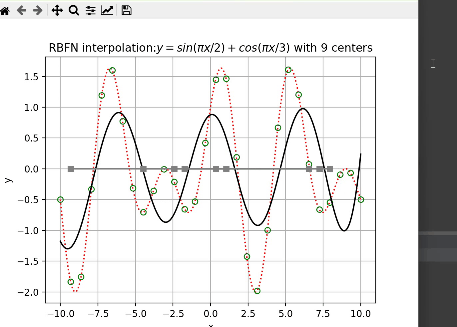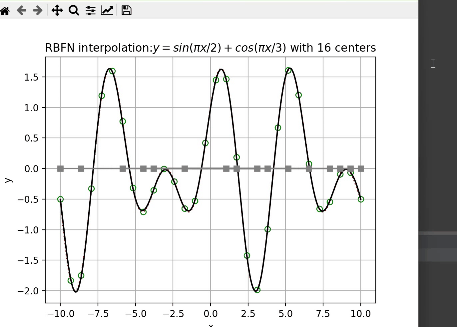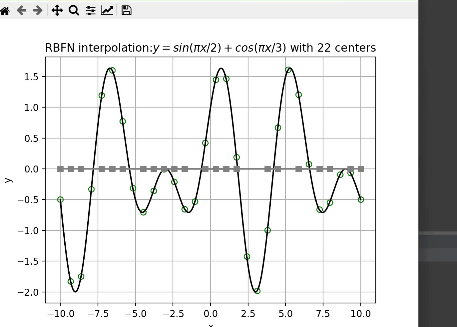
上图中,绿色空心圆点为输入的训练样本,红色虚线为实际值,黑色曲线为RBF神经网络预测结果,其中x轴上的灰色方点为中心点。
参考
[1] 一文带你了解RBF神经网络
[2] RBF(径向基)神经网络
[3] python编写自己的RBF径向基神经网络
[4] 所有神经网络的特点及优缺点分析总结
版权归原作者 MSTIFIY 所有, 如有侵权,请联系我们删除。