
一、selenium
1、为什么学习selenium?
requests获取ajax数据:优点:性能高,代码少;缺点:ajax接口有参数加密,需要学习js语法,门槛较高,当网站的js改动就需要重写代码
selenium获取ajax数据:优点:使用简单,直接模拟浏览器。缺点:性能低 代码量多
2、爬虫和反爬虫的斗争
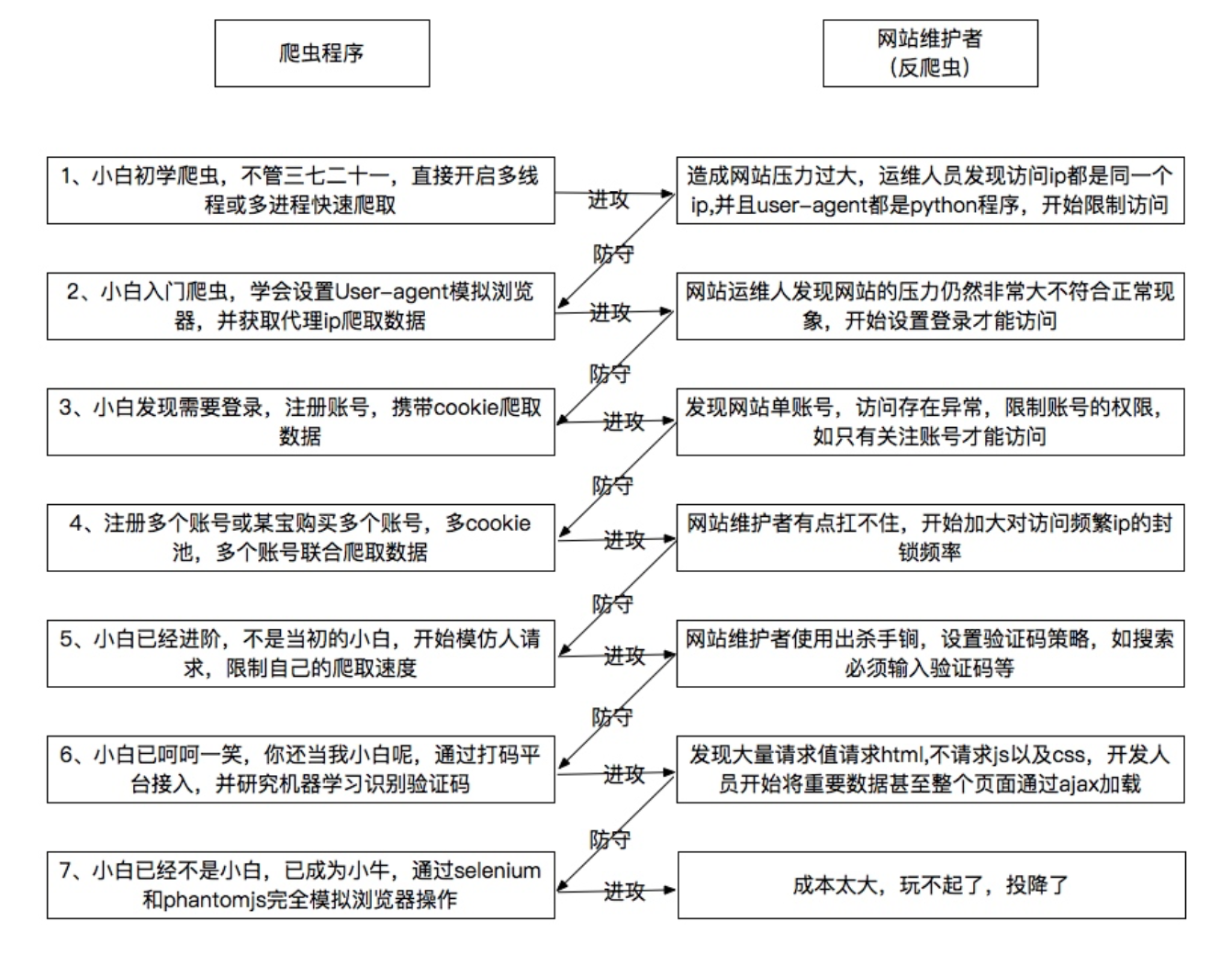
3、爬虫建议
尽量减少请求次数
保存获取到的HTML,供查错和重复使用 关注网站的所有类型的页面 H5页面 APP 多伪装代理IP
随机请求头利用多线程分布式
在不被发现的情况下我们尽可能的提高速度
4、获取ajax数据的方式
直接分析ajax调用的接口。然后通过代码请求这个接口。
使用Selenium+chromedriver模拟浏览器行为获取数据
方式
优点
缺点
分析接口
直接可以请求到数据。不需要做一些解析工作。代码量少,性能高
分析接口比较复杂,特别是一些通过js混淆的接口,要有一定的js功底。容易被发现是爬虫。
selenium
直接模拟浏览器的行为。浏览器能请求到的,使用selenium也能请求到。爬虫更稳定。
代码量多。性能低
5、介绍
selenium是一个web的自动化测试工具,最初是为网站自动化测试而开发的,selenium可以直接运行在浏览器上,它支持所有主流的浏览器,可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏
● chromedriver是一个驱动Chrome浏览器的驱动程序,使用他才可以驱动浏览器。当然针对不同的浏览器有不同的driver。以下列出了不同浏览器及其对应的driver:
○ Chrome:https://sites.google.com/a/chromium.org/chromedriver/downloads
○ Firefox:https://github.com/mozilla/geckodriver/releases
○ Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
○ Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
● 下载chromedriver
● 百度搜索:淘宝镜像(https://npm.taobao.org/)
● 安装总结:https://www.jianshu.com/p/a383e8970135
● 安装Selenium:pip install selenium
● 新的chromedriver 第地址 http://chromedriver.storage.googleapis.com/index.html
插件地址:CNPM Binaries Mirror
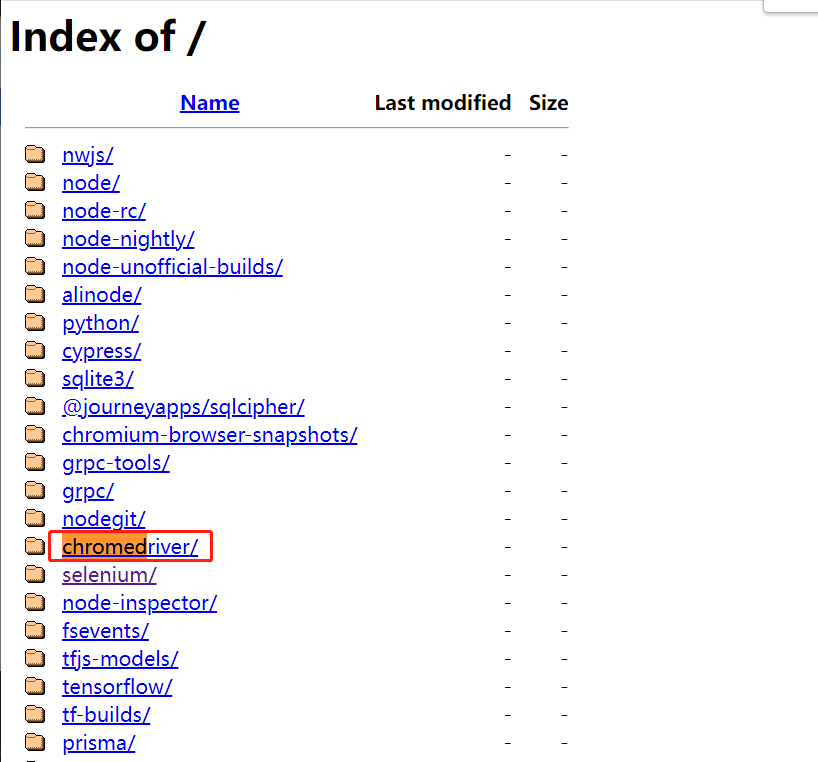
下载后的chromedriver插件放在python环境变量的目录下面。D:\soft\Anaconda3\Anaconda\Scripts
参考文献:
Python Selenium库的使用_凯耐的博客-CSDN博客_python selenium
二、Selenium提供了8种定位方式
- id
- name
- class name
- tag name
- link text
- partial link text
- xpath
- css selector
1、定位元素的8种方式
定位一个元素
定位多个元素
含义
find_element_by_id
find_elements_by_id
通过元素id定位
find_element_by_name
find_elements_by_name
通过元素name定位
find_element_by_xpath
find_elements_by_xpath
通过xpath表达式定位
find_element_by_link_text
find_elements_by_link_tex
通过完整超链接定位
find_element_by_partial_link_text
find_elements_by_partial_link_text
通过部分链接定位
find_element_by_tag_name
find_elements_by_tag_name
通过标签定位
find_element_by_class_name
find_elements_by_class_name
通过类名进行定位
find_elements_by_css_selector
find_elements_by_css_selector
通过css选择器进行定位
注意:
在学习爬虫中的selenium部分时,出现AttributeError: 'WebDriver' object has no attribute 'find_element_by_id'问题。新版的selenium已经不再使用find_element_by_id方法,将driver.find_element_by_id('kw')修改为如下语句driver.find_element(By.ID,'kw'),再在其代码页的最前端添加下列代码:from selenium.webdriver.common.by import By
例如:
from selenium import webdriver
from selenium.webdriver.common.by import By
from lxml import etree
# 实例化一个浏览器对象 Chrome代表google浏览器
driver = webdriver.Chrome()
# 请求地址
driver.get('https://www.baidu.com')
driver.find_element(By.ID,'kw').send_keys('新冠病毒')
by_class_name = driver.find_element(By.CLASS_NAME,'soutu-btn')
by_tag_name = driver.find_element(By.TAG_NAME,'input')
by_name = driver.find_element(By.NAME,'referrer')
print('by_name:',by_name)
2、****通过css定位,css定位有N种写法,这里列几个常用写法
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://baidu.com')
driver.find_element(By.CSS_SELECTOR,'#kw')
name = driver.find_element(By.CSS_SELECTOR,'[name=referrer]')
driver.find_element(By.CSS_SELECTOR,'.s-top-nav')
# driver.find_element(By.CSS_SELECTOR,'html > body > form > span > input')
#driver.find_element(By.CSS_SELECTOR,'span.soutu-btn > input#kw')
driver.find_element(By.CSS_SELECTOR,'form#form > span > input')
3、通过link_text定位
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://baidu.com')
driver.find_element(By.LINK_TEXT,'新闻').text
driver.find_element(By.LINK_TEXT,'hao123').text
4、通过partial_link_text定位
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://baidu.com')
driver.find_element(By.PARTIAL_LINK_TEXT,'新').text
driver.find_element(By.PARTIAL_LINK_TEXT,'hao').text
driver.find_element(By.PARTIAL_LINK_TEXT,'123').text
三、Selenium库下webdriver模块常用方法的使用
1、控制浏览器操作的一些方法
方法
说明
set_window_size()
设置浏览器的大小
back()
控制浏览器后退
forward()
控制浏览器前进
refresh()
刷新当前页面
clear()
清除文本
send_keys (value)
模拟按键输入
click()
单击元素
submit()
用于提交表单
get_attribute(name)
获取元素属性值
is_displayed()
设置该元素是否用户可见
size
返回元素的尺寸
text
获取元素的文本
from selenium import webdriver
from time import sleep
#1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口
driver = webdriver.Chrome()
#2.通过浏览器向服务器发送URL请求
driver.get("https://www.baidu.com/")
sleep(3)
#3.刷新浏览器
driver.refresh()
#4.设置浏览器的大小
driver.set_window_size(1400,800)
#5.设置链接内容
driver.find_element(By.ID,'kw').send_keys('新冠病毒')
sleep(3)
driver.find_element(By.ID,'su').click() # 点击百度
sleep(10)
2、鼠标事件
在 WebDriver 中,将这些关于鼠标操作的方法封装在 ActionChains 类提供
方法
说明
ActionChains(driver)
构造ActionChains对象
context_click()
执行鼠标悬停操作
move_to_element(above)
右击
double_click()
双击
drag_and_drop()
拖动
move_to_element(above)
执行鼠标悬停操作
context_click()
用于模拟鼠标右键操作, 在调用时需要指定元素定位
perform()
执行所有 ActionChains 中存储的行为,可以理解成是对整个操作的提交动作
说明:
首先需要了解ActionChains的执行原理,当你调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的时间会依次执行。
这种情况下我们可以有两种调用方法:链式写法
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
分步写法:
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
actions = ActionChains(driver)
actions.move_to_element(menu)
actions.click(hidden_submenu)
actions.perform()
鼠标事件对应的方法
•单击:click()
•右击:context_click()
•双击:double_click()
•鼠标悬停:move_to_element()
•鼠标拖动:drag_and_drop(source, target),source: 鼠标拖动的源元素,target: 鼠标释放的目标元素。
说明:
1.进行鼠标事件操作,需要导入相应的模块:from selenium.webdriver import ActionChains
2.调用 ActionChains()方法,在使用将浏览器驱动 driver 作为参数传入:ActionChains(driver)
3.模拟鼠标操作事件,在调用时需要传入定位到的元素:move_to_element(click)
4.执行所有 ActionChains 中存储的行为,要对整个操作事件进行提交动作:perform()
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.implicitly_wait(5) # 隐式等待
driver.maximize_window() # 最大化浏览器窗口
driver.get("http://www.baidu.com")
driver.find_element(By.ID,'kw').send_keys("selenium")
print("鼠标单击操作")
driver.find_element(By.ID,'su').click() # 鼠标单击“百度一下”
print("鼠标悬停操作")
click = driver.find_element(By.PARTIAL_LINK_TEXT,'百度翻译') # 定位到鼠标要操作的元素(Selenium_百度百科)
ActionChains(driver).move_to_element(click).perform()
time.sleep(3)
print("鼠标右击操作")
ActionChains(driver).context_click(click).perform()
time.sleep(3)
print("鼠标双击操作")
ActionChains(driver).double_click(click).perform()
print("鼠标拖动操作")
click1 = driver.find_element(By.PARTIAL_LINK_TEXT,'百度百科')
ActionChains(driver).drag_and_drop(click, click1).perform()
time.sleep(3)
driver.quit()
案例:
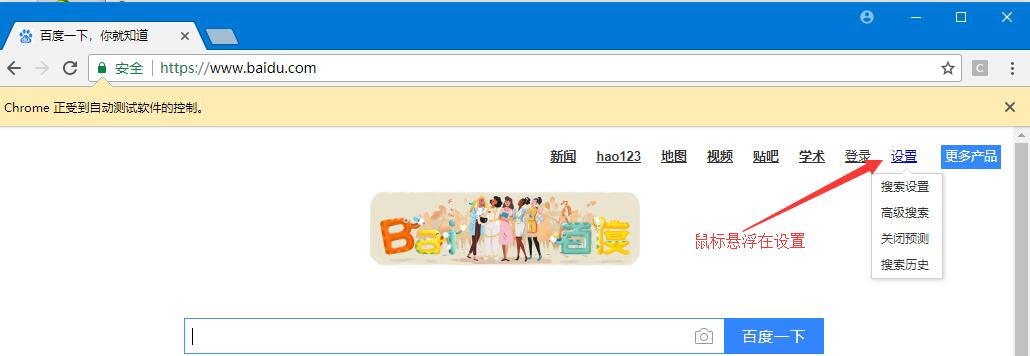
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://baidu.com')
# 定位到悬停的元素
set = driver.find_element(By.ID,'s-usersetting-top')
# 对定位的元素执行鼠标悬停操作
ActionChains(driver).move_to_element(set).perform()
# sleep(3)
# 找到链接 找到搜索设置
search_set = driver.find_element(By.PARTIAL_LINK_TEXT,'搜索设置')
search_set.click() # 点击搜索设置
sleep(1)
driver.find_element(By.ID,'SL_1').click()
sleep(2)
# 保存设置
driver.find_element(By.PARTIAL_LINK_TEXT,'保存设置').click()
sleep(2)
3、键盘事件
Selenium中的Key模块为我们提供了模拟键盘按键的方法,那就是send_keys()方法。它不仅可以模拟键盘输入,也可以模拟键盘的操作。
常用的键盘操作如下:
模拟键盘按键
说明
send_keys(Keys.BACK_SPACE)
删除键(BackSpace)
send_keys(Keys.SPACE)
空格键(Space)
send_keys(Keys.TAB)
制表键(Tab)
send_keys(Keys.ESCAPE)
回退键(Esc)
send_keys(Keys.ENTER)
回车键(Enter)
组合键的使用
模拟键盘按键
说明
send_keys(Keys.CONTROL,'a')
全选(Ctrl+A)
send_keys(Keys.CONTROL,'c')
复制(Ctrl+C)
send_keys(Keys.CONTROL,'x')
剪切(Ctrl+X)
send_keys(Keys.CONTROL,'v')
粘贴(Ctrl+V)
send_keys(Keys.F1…Fn)
键盘 F1…Fn
案例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://baidu.com')
driver.find_element(By.ID,'kw').send_keys('selenium') # 输入selenium
sleep(2)
driver.find_element(By.ID,'kw').send_keys(Keys.BACK_SPACE) # 删除一个文字
sleep(2)
# 输入空格键+'教程'
driver.find_element(By.ID,'kw').send_keys(Keys.SPACE)
sleep(1)
driver.find_element(By.ID,'kw').send_keys('教程')
sleep(1)
# ctrl+a 全选输入框内容
driver.find_element(By.ID,'kw').send_keys(Keys.CONTROL,'a')
sleep(2)
# 剪切输入款内容
driver.find_element(By.ID,'kw').send_keys(Keys.CONTROL,'x')
sleep(2)
# ctrl + v粘贴内容到如书框
driver.find_element(By.ID,'kw').send_keys(Keys.CONTROL,'v')
sleep(2)
# 通过回车键来代替单击操作
driver.find_element(By.ID,'kw').send_keys(Keys.ENTER)
sleep(3)
driver.quit()
4、获取断言信息
不管是在做功能测试还是自动化测试,最后一步需要拿实际结果与预期进行比较。这个比较的称之为断言。通过我们获取title 、URL和text等信息进行断言。
属性
说明
title
用于获得当前页面的标题
current_url
用户获得当前页面的URL
text
获取搜索条目的文本信息
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://www.baidu.com')
print('===========查询前==========')
title = driver.title
print('title:',title)
now_url = driver.current_url
print('当前页面URL:',now_url)
driver.find_element(By.ID,'kw').send_keys('selenium')
driver.find_element(By.ID,'su').click()
sleep(2)
print('===========查询后==========')
title = driver.title
print('title2:',title)
now_url = driver.current_url
print('now_url2:',now_url)
sleep(2)
# 关闭所有窗口
driver.quit()
四、使用selenium爬取动态加载的信息
1、安装selenium模块
在cmd中切换到anaconda目录下scripts,执行pip install selenium
下载浏览器驱动
selenium模块安装完成以后还需要选择一个浏览器,然后下载赌赢的浏览器驱动。此时才可以通过selenium模块来控制浏览器的操作。我选择Google浏览器。地址:https://chromedriver.storage.googleapis.com/index.html?path=80.0.3987.106.
这里要注意的是Google的版本。
查看Google的版本号的方法:
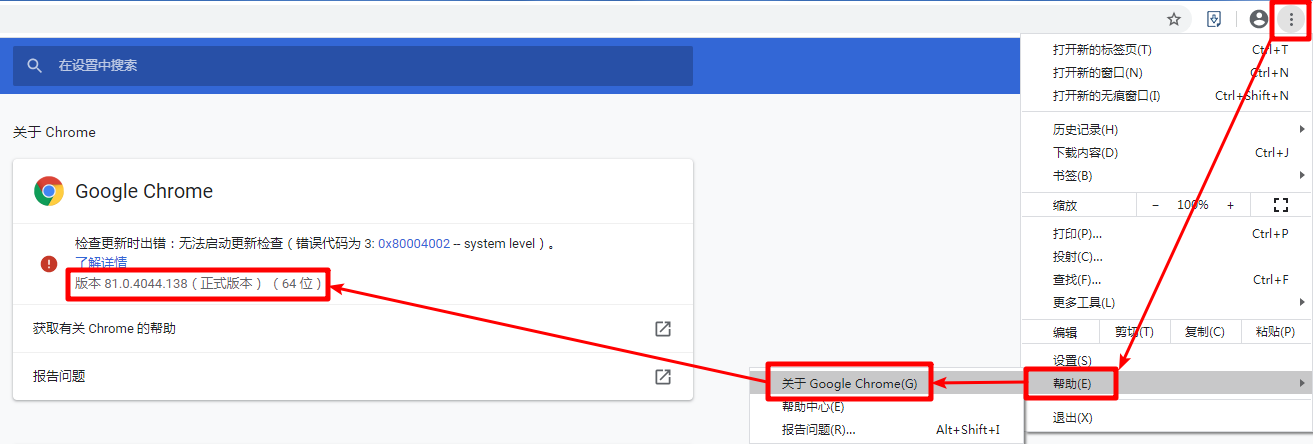
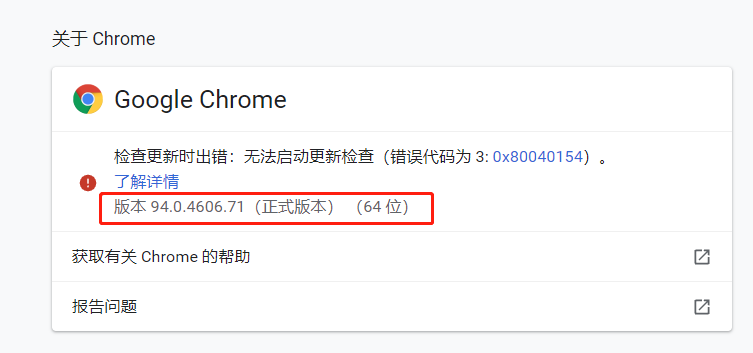
根据版本号搜谷歌浏览器驱动镜像

2、selenium模块的使用 :爬取京东商品
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
def get_good(driver):
try:
# 通过JS控制滚轮滑动获取所有商品信息
js_code = '''
window.scrollTo(0,5000);
'''
driver.execute_script(js_code) # 执行js代码
# 等待数据加载
time.sleep(2)
# 3、查找所有商品div
# good_div = driver.find_element_by_id('J_goodsList')
good_list = driver.find_elements(By.CLASS_NAME, "gl-item")
n = 1
for good in good_list:
# 根据属性选择器查找
# 商品链接
good_url = good.find_element(By.CSS_SELECTOR, '.p-img a').get_attribute('href')
# 商品名称
good_name = good.find_element(By.CSS_SELECTOR, '.p-name em').text.replace("\n", "--")
# 商品价格
good_price = good.find_element(By.CLASS_NAME, 'p-price').text.replace("\n", ":")
# 评价人数
good_commit = good.find_element(By.CLASS_NAME, 'p-commit').text.replace("\n", " ")
good_content = f'''
商品链接: {good_url}
商品名称: {good_name}
商品价格: {good_price}
评价人数: {good_commit}
\n
'''
print(good_content)
with open('jd.txt', 'a', encoding='utf-8') as f:
f.write(good_content)
next_tag = driver.find_element(By.CLASS_NAME, 'pn-next')
next_tag.click()
time.sleep(2)
# 递归调用函数
get_good(driver)
time.sleep(10)
finally:
driver.close()
if __name__ == '__main__':
good_name = input('请输入爬取商品信息:').strip()
driver = webdriver.Chrome()
driver.implicitly_wait(10)
# 1、往京东主页发送请求
driver.get('https://www.jd.com/')
# 2、输入商品名称,并回车搜索
# input_tag = driver.find_element_by_id('key') # 京东浏览器的搜索框的id值是key
input_tag = driver.find_element(By.ID, 'key')
input_tag.send_keys(good_name)
input_tag.send_keys(Keys.ENTER)
time.sleep(2)
get_good(driver)
版权归原作者 小马哥-码农 所有, 如有侵权,请联系我们删除。