

创作不易,感谢三连支持
一、非类型模版参数
模板参数分类为类型形参与非类型形参。
类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。
非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当成常量来使用。
注意:
非类型的模板参数必须在编译期就能确认结果。(分离编译会讲解)
我们来介绍一个c++11引入的array
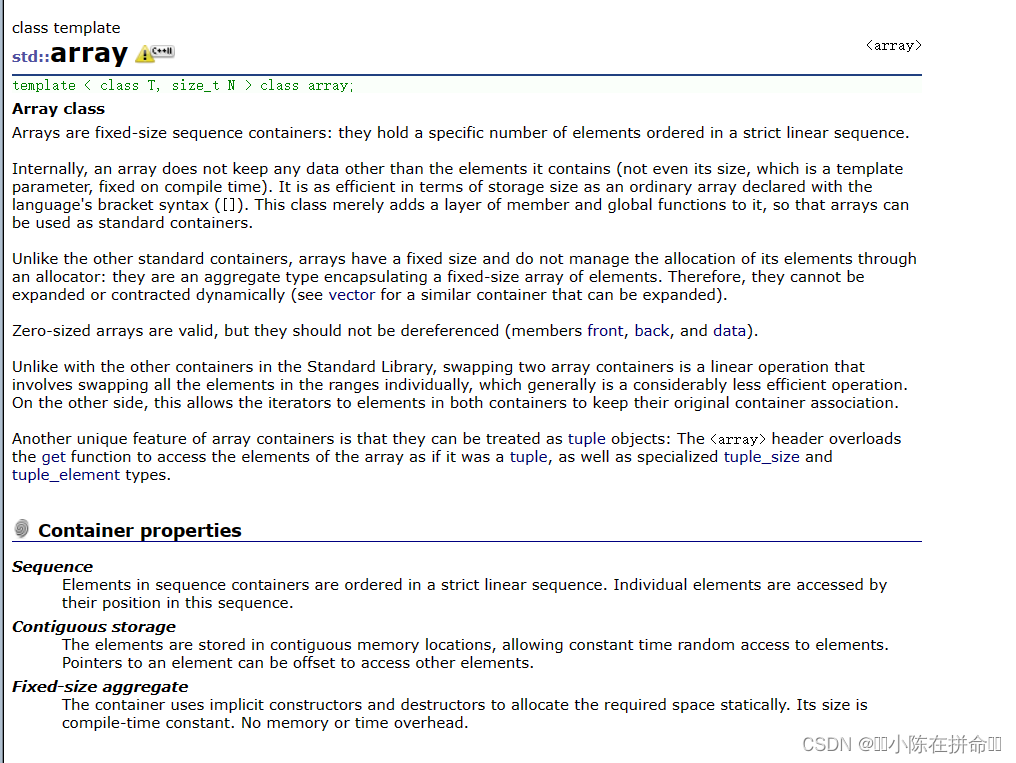
array的底层其实封装的是一个静态数组。并且用到了非类型形参,在这里指代的是底层静态数组的容量大小。
思考:
1、为什么要有这个非模版形参??define定义宏常量难道不香吗??
** **define定义宏常量有时也可以解决问题,但是宏常量的作用域是全局,比如我们想让一个数组是10的容量,一个数组是20的容量,显然是做不到的,但是模版是可以做到的!!我们不传的时候N就是缺省值,传的时候就是我们指定的容量。
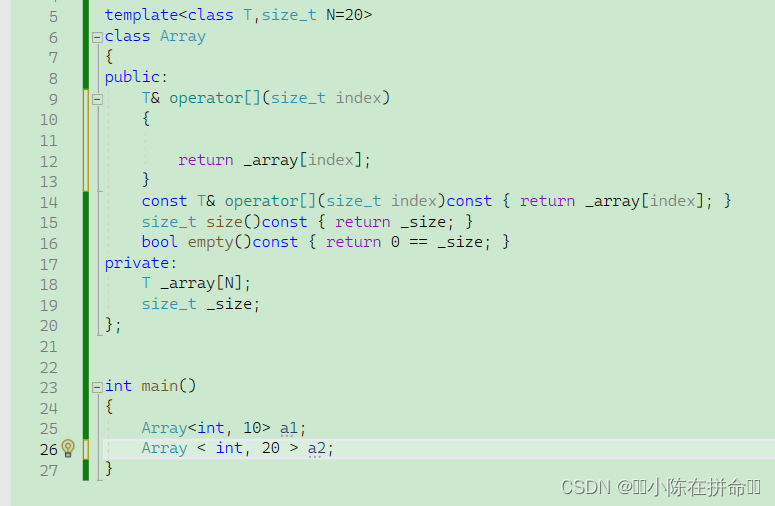
2、我直接用静态数组不行吗?为什么非得用类把他封起来??
(1)为了增加检查的功能,我们知道vs对于静态数组的越界功能是抽查行为,因此不是很安全,而我们把他封装在类里面,这样就可以去写个断言来防止数组越界
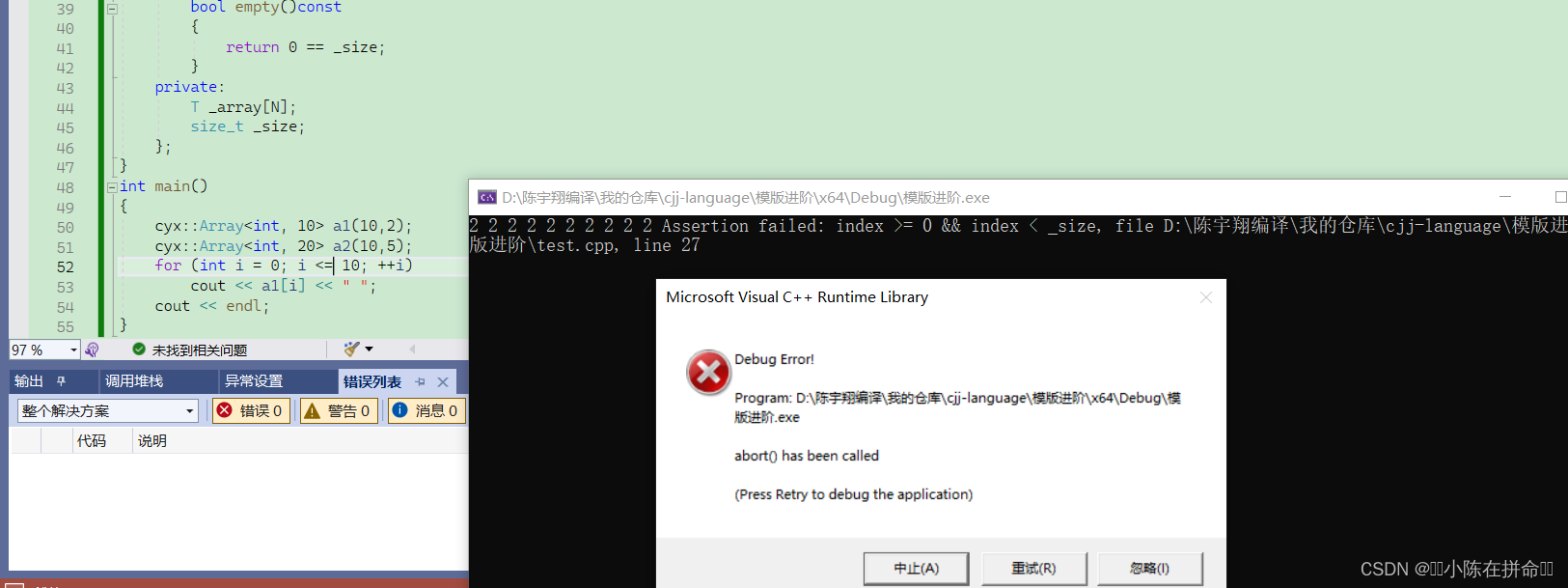
(2)[ ]的重载不仅可以增加检查功能,还可以去控制静态数组内容是否可以被写,同时还可以利用这个类去增加许多新的接口

3.能够作为非类型模版参数的有哪些类型??
只能是和int相似类型的才行,比如char、short、int、long int ……**浮点数类对象以及字符串是不允许作为非类型模板参数的。**
二、模版的特化
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板

可以看到,Less绝对多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然大于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指针的地址,这就无法达到预期而错误。
此时,就需要对模板进行特化。即:在原模板类的基础上,针对特殊类型所进行特殊化的实现方式。模板特化中分为**函数模板特化**与类**模板特化。**
2.1 函数模版特化
函数模板的特化步骤:
- 必须要先有一个基础的函数模板
- 关键字template后面接一对空的尖括号<>
- 函数名后跟一对尖括号,尖括号中指定需要特化的类型
- 函数形参表: 必须要和模板函数的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
我们展示一下用法:

相当于是我们特殊化了一个版本出来,这个版本可以去比较指针解引用的内容!
但是我们还有这样一个方法——利用函数匹配的规则,直接把这个特殊类型的函数给出来
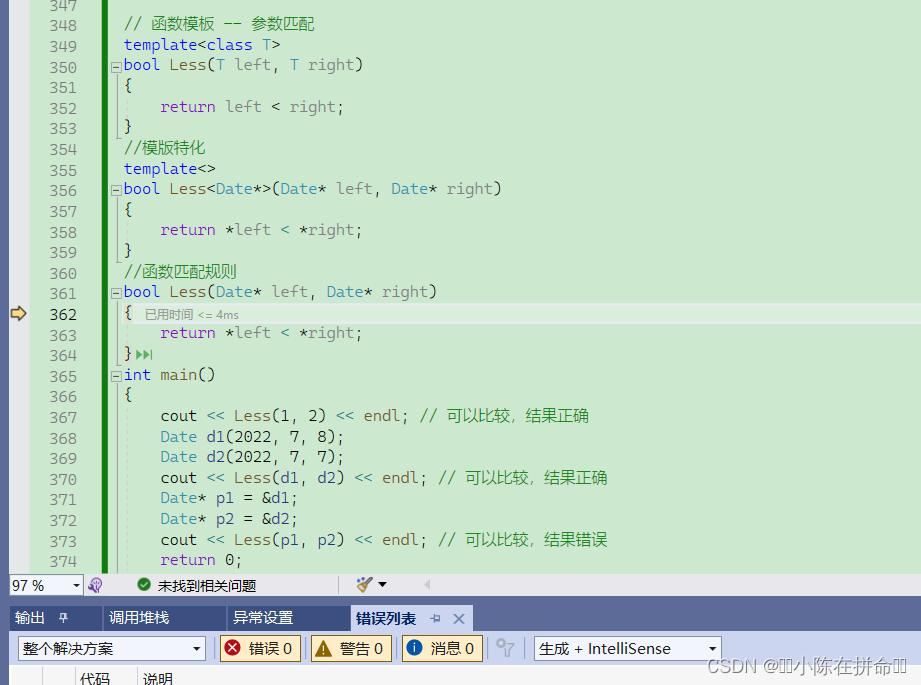
我们可以把函数模版当成是冰箱里的菜,模版特化的函数当成是预制菜,最后这个简单函数是现成菜。当我们有现成的吃的时候,就不会考虑去吃没做过的菜。**这其实就是函数匹配规则!**
并且这种函数实现简单明了,代码的可读性高,容易书写,因为对于一些参数类型复杂的函数模板,特化时特别给出,**因此函数模板不建议特化**。
2.2 类模版特化
函数有匹配规则,所以其实不怎么依赖特化,但是类并没有匹配规则啊!!所以特化最广泛的使用是在类中。类模版特化的步骤和函数模版特化的步骤是相似的。
2.2.1 全特化
全特化即是将模板参数列表中所有的参数都确定化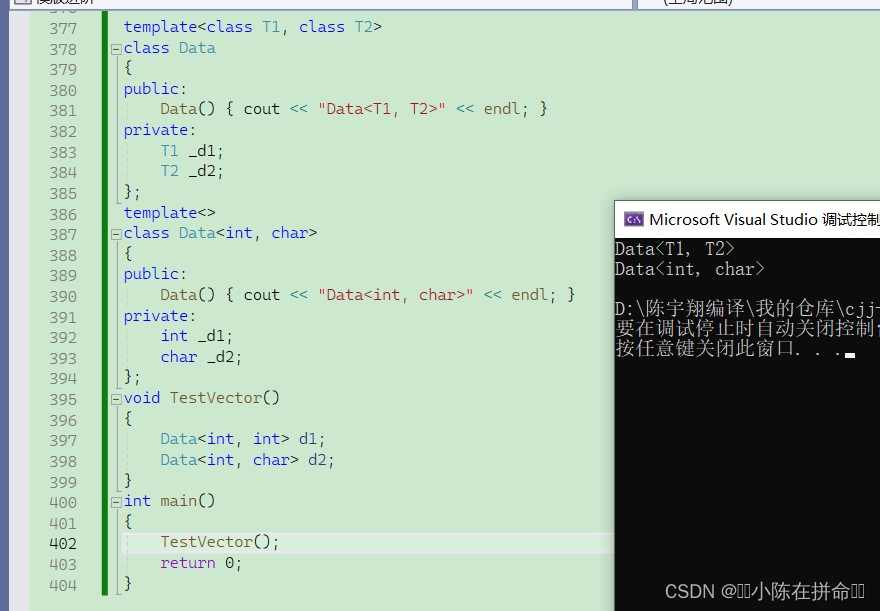
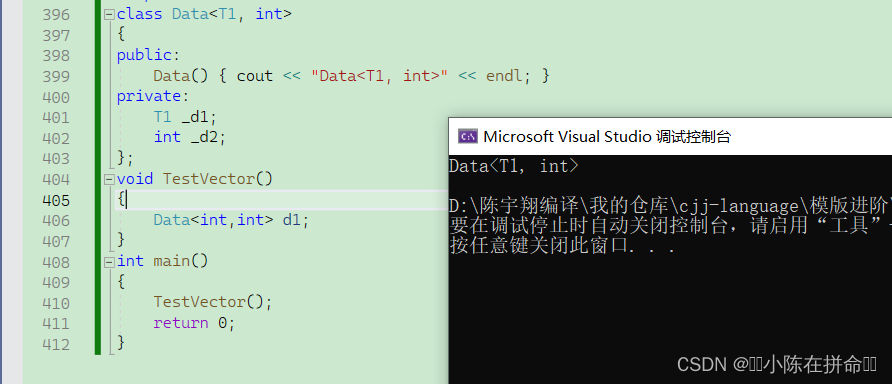
2.2.2 部分特化
部分特化的意思就是说,我们把其中一部分参数进行特化了。
2.2.3 偏特化(非常重要)
偏特化并不仅仅是指特化部分参数,而是**针对模板参数更进一步的条件限制所设计出来的一个特化版本。**
比如偏特化为指针类型(比较常见),或者是偏特化为引用类型(不常见)。
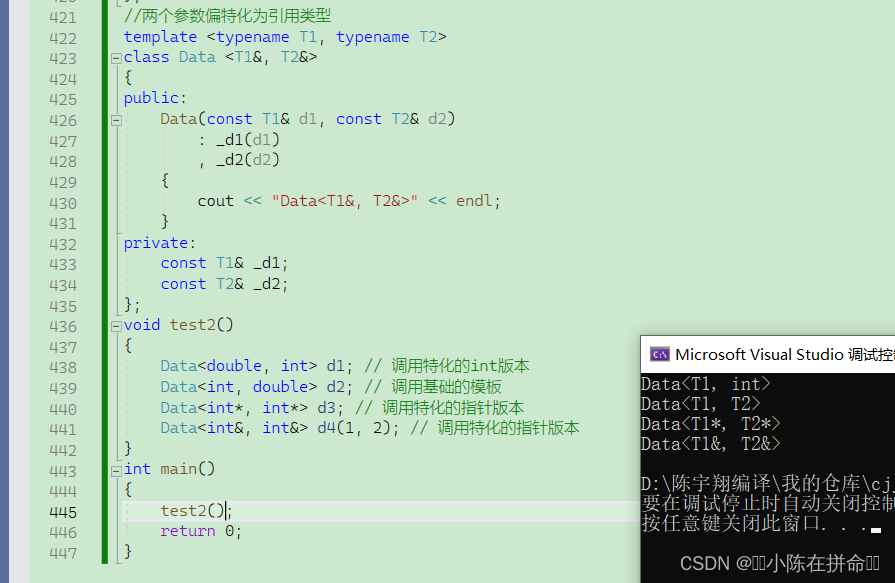
** 后面讲到仿函数的时候会做更进一步的介绍**
三、模版分离编译
** 一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件**的过程称为分离编译模式。
一般来说,在我们书写大项工程的时候,为了保证代码的简洁性,我们常常将函数声明放在一个头文件里,将函数定义放在一个源文件里,然后再用另外一个源文件去进行测试。但是在模版这个地方,分离编译成为了一个难题!
3.1 模版的分离编译
假如有以下场景,模板的声明与定义分离开,在头文件中进行声明,源文件中完成定义:
// flby.h
template<class T>
T Add(const T& left, const T& right);
// flby.cpp
#include"flby.h"
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
// test.cpp
#include"flby.h"
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}

为什么会这样呢??


3.2 解决方法
方法一:将声明和定义放到一个文件 "xxx.hpp" 里面或者xxx.h其实也是可以的。
因为最后都会在测试文件里面展开,这样编译的过程就可以进行实例化生成函数。一般比较推荐使用这种。
方法二:模板定义的位置显式实例化。这种方法不实用,不推荐使用。
显式实例化的意思就是,你不是推断不出来吗??那我就直接告诉你要生成什么样的函数!
四、模版的总结
优点:
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
- 增强了代码的灵活性
缺陷: - 模板会导致代码膨胀问题,也会导致编译时间变长(需要推导并生成实例化函数)
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误
五、priority_queue的介绍
priority_queue的文档介绍
优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大(小)的。
此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
empty():检测容器是否为空
size():返回容器中有效元素个数
front():返回容器中第一个元素的引用
push_back():在容器尾部插入元素
pop_back():删除容器尾部元素
标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用vector。
需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作。

其实优先级队列就是我们数据结构里的堆!!
DS:二叉树的顺序结构及堆的实现_顺序打印堆-CSDN博客
大家可以看看博主的这篇博客,堆主要的应用就是解决top-k问题,在这篇文章里有具体的分析。
六、priority_queue的模拟实现
//仿函数
template<class T>
struct less //冰箱里的菜
{
bool operator()(const T& x, const T& y) const
{
return x < y;
}
};
template<class T>
struct greater
{
bool operator()(const T& x, const T& y) const
{
return x > y;
}
};
template<class T, class Container = vector<T>, class Compare = less<T>>//默认是建大堆
class priority_queue
{
public:
void adjust_up(int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (Compare()(_con[parent], _con[child]))//_con[child] > _con[parent]
{
std::swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
break;
}
}
void adjust_down(int parent)
{
int child = parent * 2 + 1;//建大堆,找大,假设左孩子比右孩子大
while (child < _con.size())
{
if (child + 1 < _con.size() && (Compare()(_con[child], _con[child + 1])))//_con[child] < _con[child + 1]
++child;
if (Compare()(_con[parent], _con[child]))//_con[parent] < _con[child]
{
std::swap(_con[parent],_con[child]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
bool empty() const
{
return _con.empty();
}
size_t size() const
{
return _con.size();
}
const T& top() const
{
return _con[0];
}
void push(const T& val)
{
_con.push_back(val);
//插入后要向上调整
adjust_up(_con.size() - 1);//向上调整算法
}
void pop()
{
std::swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);//向下调整算法
}
void swap(priority_queue<T>& q)
{
_con.swap(q._con);
}
private:
Container _con;
};
**这边我们用到了两个仿函数,如果是建大堆的话,用less<T>,如果是建小堆的话,用greater<T>,仿函数就是通过重载()的行为,模拟出函数的效果,比函数指针会易用很多**
七、模版特化的深入分析
假设我们放了一个日期类进去,能进行比较吗??

答案是可以的,前提是我们需要在日期类重载出比较操作符
如果是以下这种情况呢??
虽然指针也可以比较大小,但是指针比较大小的方式显然不符合我们的预期,我们希望的是比较指针解引用的内容,这个时候应该怎么办呢?
第一个方法:再写一个专门用来比较指针解引用的仿函数
struct PDateless
{
bool operator()(const Date* p1, const Date* p2)
{
return *p1 < *p2;
}
};
struct PDateGreater
{
bool operator()(const Date* p1, const Date* p2)
{
return *p1 > *p2;
}
};

** 第二个方法:对原来的less和greater进行全特化出一个专门比较Date指针类型的仿函数**
//全特化版本(因为全特化了,只能针对Data*) (即食菜)
template<>
struct less<Date*>
{
bool operator()(const Date* x, const Date* y) const
{
return *x < *y;
}
};
//全特化版本(因为全特化了,只能针对Data*)
template<>
struct greater<Date*>
{
bool operator()(const Date* x, const Date* y) const
{
return *x > *y;
}
};
但是以上两种方法是不是都不太好,因为无论是全特化还是写一个全新的仿函数,我们都只是针对了Date类型,但是如果我们以后遇到int double*……难道也要再写一个吗??所以就有了一个更好的方法。
方法三:对原来的less和greater进行偏特化限制出一个专门比较任意指针类型的仿函数
//偏特化版本 具体类型,针对指针这个泛类 必须在原来的基础之上 (预制菜)
template<class T>
struct less<T*>
{
bool operator()(const T* x, const T* y) const
{
return *x < *y;
}
};
//偏特化版本 (针对所有类型的指针)
template<class T>
struct greater<T*>
{
bool operator()(const T* x, const T* y) const
{
return *x > *y;
}
};
我们这个时候发现,偏特化可以帮助我们更好地解决指针比较这样的问题。
** 给大家举个形象的比喻,模版就相当于是冰箱里的菜,全特化版本就相当于是即食菜,而偏特化就相当于是预制菜。重新写一个特定的仿函数就相当于是外卖**
** 外卖>即食菜>预制菜>冰箱里的菜。 **
1、 即食菜和预制菜理论上来说都是通过冰箱里的菜走出来的,所以必须要先有模版才能进行全特化和偏特化。
2、从前往后优先级变低。
版权归原作者 ✿༺小陈在拼命༻✿ 所有, 如有侵权,请联系我们删除。