
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。
安装顺序
1.安装es 7.17.12
2.安装kibana 7.17.12
3.安装x-pack
保证以上调试成功后开始下面的安装
4.安装kafka(1.1.0 版本,对应的是 kafka_2.11-1.1.0.tgz)5.安装logstash 7.17.12
6.安装filebeat 7.17.12
具体安装
1. es安装(单节点部署)
前提
1.环境准备
#设置Java环境#如果没有安装,yum -y install javajava-version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
安装
#1.下载es二进制包wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.12-linux-x86_64.tar.gz
#2.解压安装tar-xf elasticsearch-7.17.12-linux-x86_64.tar.gz
#3.修改elasticsearch主配置文件cp /elasticsearch-7.17.12/config/elasticsearch.yml /elasticsearch-7.17.12/configelasticsearch.yml.bak
########################################[root@master config]# grep -Ev '^#' elasticsearch.yml
cluster.name: my-application #--17--取消注释,指定集群名字
node.name: node-1 #--23--取消注释,指定节点名
path.data: /data/es/data #--33--取消注释,指定数据存放路径
path.logs: /data/es/logs #--37--取消注释,指定日志存放路径
bootstrap.memory_lock: false#--43--取消注释,避免es使用swap交换分区
network.host: 0.0.0.0 #--55--取消注释,设置监听地址,0.0.0.0代表所有地址
http.port: 9200#--59--取消注释,ES 服务的默认监听端口为9200
transport.tcp.port: 9300#指定es集群内部通信接口
cluster.initial_master_nodes: ["node-1"]# 设置master节点,单机情况设置和上面node-1 名称一致即可#------------------------------------------------#node.master: true #是否master节点,false为否#node.data: true #是否数据节点,false为否#######4.es 性能调优参数#优化最大内存大小和最大文件描述符的数量vim /etc/security/limits.conf
......
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* soft memlock unlimited
* hard memlock unlimited
vim /etc/systemd/system.conf
DefaultLimitNOFILE=65536DefaultLimitNPROC=32000DefaultLimitMEMLOCK=infinity
#5.#优化elasticsearch用户拥有的内存权限
由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。
lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问;
因此,我们很有必要将一半的物理内存留给lucene ; 另一半的物理内存留给ES(JVM heap )。
所以, 在ES内存设置方面,可以遵循以下原则:
1.当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给操作系统,供lucene使用
2.当机器内存大于64G时,遵循原则:建议分配给ES分配 4~32G 的内存即可,其它内存留给操作系统,供lucene使用
#6.修改一个进程可以拥有的虚拟内存区域的数量vim /etc/sysctl.conf
#一个进程可以拥有的最大内存映射区域数,参考数据(分配 2g/262144,4g/4194304,8g/8388608)vm.max_map_count=262144#使之生效sysctl-p#7.启动elasticsearch#前提:es需要非root用户启动useradd es
su es
#启动:
/elasticsearch-7.17.12/bin/elasticsearch
#注:1. es /config目录下jvm.options文件内可以调整jvm内存分配等其他参数
-Xms256m-Xmx256m2. 需要修改es目录为es用户权限
chown-R es.es /elasticsearch-7.17.12
chown-R es.es /data/es/
2.es web 查看
浏览器访问 http://esIP:9200 或者本地访问curl ‘http://localhost:9200/?pretty’
[root@localhost elasticsearch-7.17.12]# curl localhost:9200{"name":"node-1",
"cluster_name":"my-application",
"cluster_uuid":"23xYBSDTR9ahrLoNVYeBQw",
"version":{"number":"7.17.12",
"build_flavor":"default",
"build_type":"tar",
"build_hash":"a813d015ef1826148d9d389bd1c0d781c6e349f0",
"build_date":"2023-08-10T05:02:32.517455352Z",
"build_snapshot": false,
"lucene_version":"9.7.0",
"minimum_wire_compatibility_version":"7.17.0",
"minimum_index_compatibility_version":"7.0.0"},
"tagline":"You Know, for Search"}
2. kibana部署
安装
#1.下载kibana二进制包wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.12-linux-x86_64.tar.gz
#2.解压安装tar-xf kibana-7.17.12-linux-x86_64.tar.gz
#3.修改kibana主配置文件[root@master config]# grep -vE '^#|^$' kibana.yml
server.port: 5601#指定端口号
server.host: "172.18.22.38"#指定kibana监听地址
elasticsearch.hosts: ["http://172.18.22.38:9200"]#指定es地址
i18n.locale: "zh-CN"#,指定编码格式#4. 启动
./bin/kibana --allow-root &
kibana web 查看
浏览器访问:http://172.18.22.38:5601
3. X-Pack安装
X-Pack是Elastic Stack扩展功能,提供安全性,警报,监视,报告,机器学习和许多其他功能。 ES7.0+之后,默认情况下,当安装Elasticsearch时,会安装X-Pack,无需单独再安装。
X-pack 监控组件使您可以通过 Kibana 轻松地监控 ElasticSearch。您可以实时查看集群的健康和性能,以及分析过去的集群、索引和节点度量。此外,您可以监视 Kibana 本身性能。当你安装 X-pack 在群集上,监控代理运行在每个节点上收集和指数指标从 Elasticsearch。安装在 X-pack 在 Kibana 上,您可以查看通过一套专门的仪表板监控数据。
4. 安装kafka
5. 安装logstash
安装
#1.下载logstash二进制包wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.12-linux-x86_64.tar.gz
#2.解压安装tar-xf logstash-7.17.12-linux-x86_64.tar.gz
#3.修改logstash主配置文件[root@master config]#
Logstash 的启动命令位于安装路径的 bin 目录中,直接运行 logstash 不行, 需要按如下方式提供参数:
./logstash -e"input {stdin {}} output {stdout{}}"
启动时应注意: -e 参数后要使用双引号。
如果在命令行启动日志中看到 “Successfully started Logstash API end-point l:port=>9600”,就证明启动成功。
这个启动过程会非常慢,需要耐心等待。
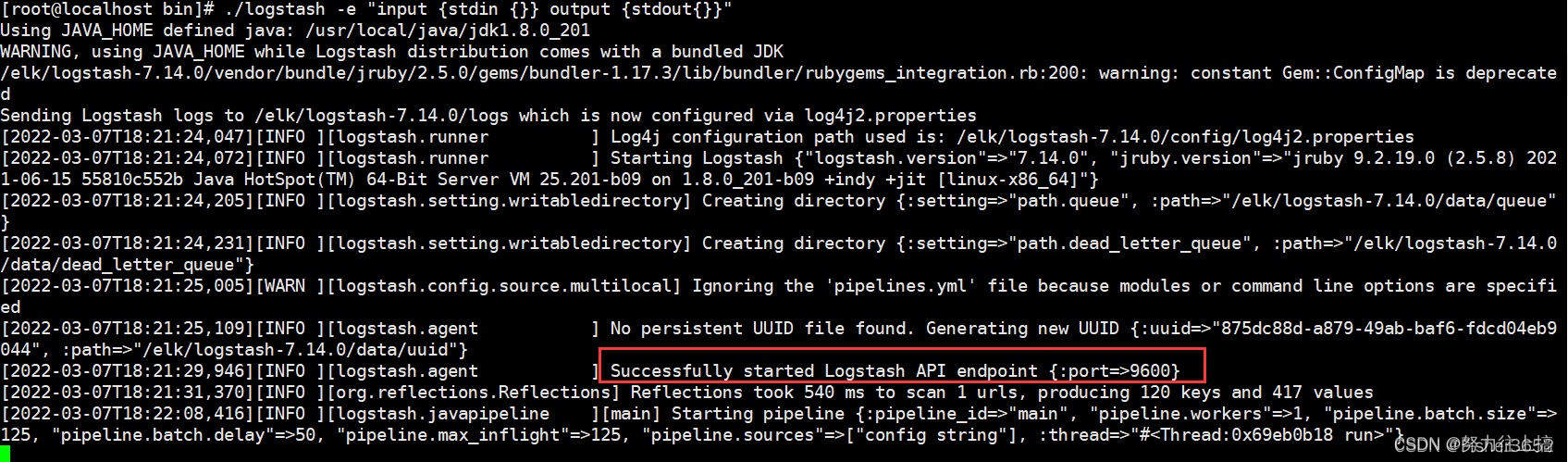
在上面的命令行中,-e 代表输入配置字符串,定义了一个标准输入插件( 即 stdin)
和一个标准输出插件( 即 stdout),意思就是从命令行提取输入,并在命令行直接将
提取的数据输出。如果想要更换输入或输出,只要将 input 或 output 中的插件
名称更改即可,这充分体现了 Logstash 管道配置的灵活性。按示例启动 Logstash,
命令行将会等待输入,输入“Hello world!"后会在命令行返回如下结果
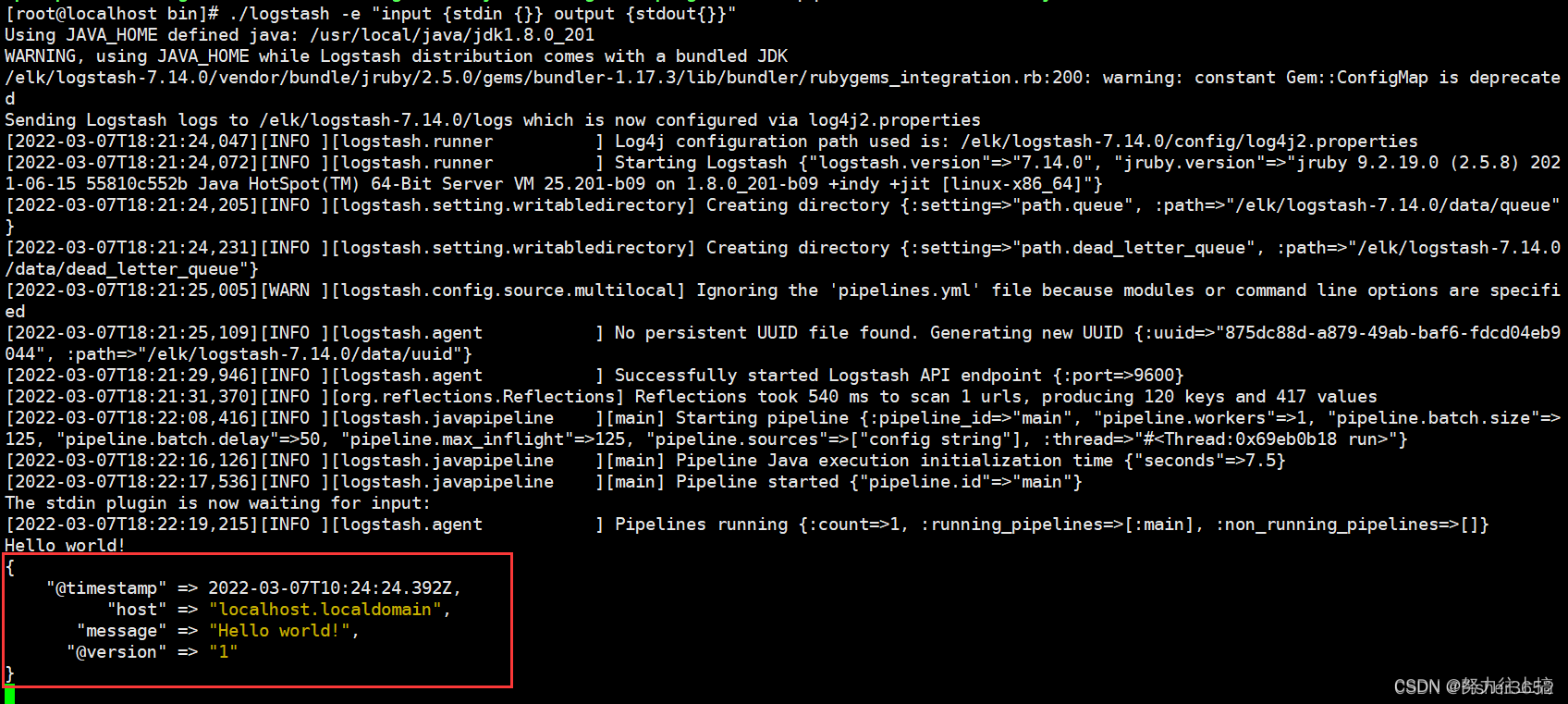
在默认情况下,stdout 输出插件的编解码器为 rubydebug,所以输出内容中
包含了版本、时间等信息,其中 message 属性包含的就是在命令行输入的内容。
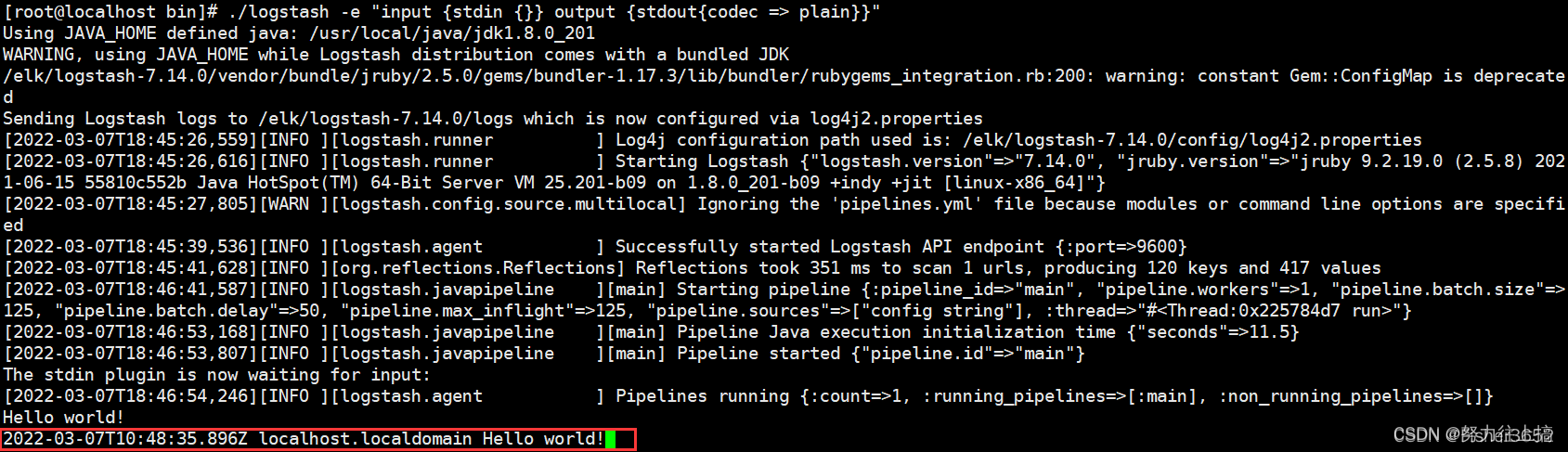
试着将输出插件的编码器更换为 plain 或 line,则输入的结果将会发生变化:
./logstash -e"input {stdin {}} output {stdout{codec => plain}}"
配置logstash连接 Elasticsearch(标准输入>es)
[root@master config]# cat std_es.conf
input {
stdin {#host => "XXXX"#port => 5044 #若要通过filebeat >> logstash 则需要设置端口和主机}}
output {
elasticsearch {
hosts =>["http://172.18.22.38:9200"]#hosts 指定了 es 地址和端口
index =>"mylogstash1"#index 指定存储的索引名mylogstash1#user => "elastic" #指定连接es的用户#password => "changeme" #指定连接es的密码}}
启动logstash
按如下方式启动 Logstash:
./logstash -f../config/std_es.conf #-f 指定配置文件的路径
Logstash 将把标准输入内容提取到指定的 Elastiesearch 服务中。通过 Kibana 开发工具输入 GET _cat/indices, 可以 看到 mylogstash1 这个索引已经创建出来了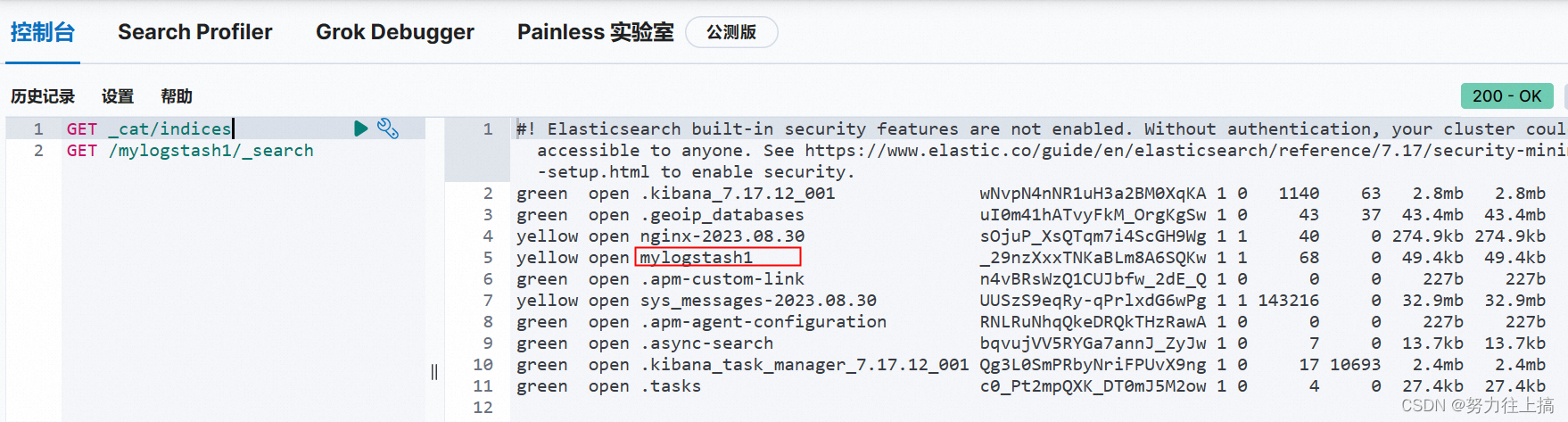
输入GET /mylogstash1/_search,则返回结果为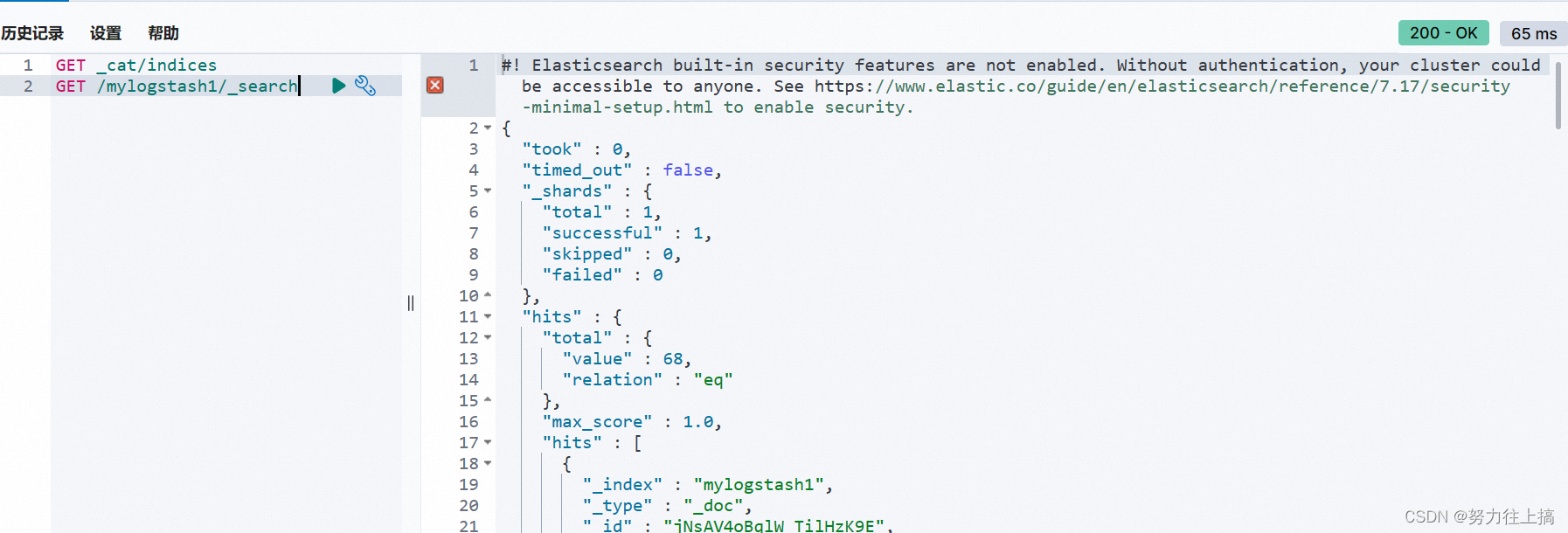
logstash-beats.conf
# Sample Logstash configuration for creating a simple# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port =>5044}}
filter {
grok {
match =>["message", "%{TIMESTAMP_ISO8601:timestamp_string}%{SPACE}%{GREEDYDATA:line}"]}date{
match =>["timestamp_string", "ISO8601"]}
mutate {
remove_field =>[message, timestamp_string]}}
output {
elasticsearch {
hosts =>["http://localhost:9200"]
user => elastic
password =>"your password"}
stdout {
codec => rubydebug
}}
- 这里的 input 使用了 beat,并监听端口5044。很多 Beats 都使用一个端口,并向这个端口发送数据。在接下来的 Filebeat,我们可以看到如何配置这个端口,并发送 log 数据到这个端口
- 在 filter 的这个部分,使用 grok,它的基本语法是 %{SYNTAX:SEMANTIC}。SYNTAX 是与你的文本匹配的模式的名称。这个有点类似于正则表达式。 例如,3.44 将与 NUMBER 模式匹配,55.3.244.1 将与 IP 模式匹配。SEMANTIC 是你为匹配的文本提供的标识符。针对我们的例子:
2019-09-09T13:00:00Z Whose woods these are I think I know.
2019-09-09T13:00:00Z:使用 TIMESTAMP_ISO8601 匹配,并形成一个叫做 timestamp_string 的字符串。SPACE 用来匹配时间后面的空格,而剩下的部分由 GREEDYDATA 进行匹配,并存于 line 这个字符串中。比如针对我们的例子 line 就是 “Whose woods these are I think I know.” 字符串
- date 这个 filter 可以帮我们把一个字符串变成一个 ISO8601 的时间,并最终存于一个叫做 @timestamp 的字段中。如果没有这个 filter,我们可以看到最终的 @timestamp 是采用当前的运行时间,而不是在 log 里的时间
- 我们使用 mutate 过滤器把之前的 message 和 timestamp_string 都删除掉
- 在 output 中,我们把数据输出到 Elasticsearch,并同时输出到 stdout,这样我们也可以在 terminal 的输出中看到输出的信息。这个也很方便我们做测试。
6.安装filebeat
安装
#1.下载filebeat二进制包wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.12-linux-x86_64.tar.gz
#2.解压安装tar-xf filebeat-7.17.12-linux-x86_64.tar.gz
#3.修改logstash主配置文件[root@master filebeat-7.17.12-linux-x86_64]# grep -vE '^#|^$|^*#' filebeat.yml
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /var/log/nginx/*.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
host: "172.18.22.40:5601"
output.logstash:
hosts: ["172.18.22.40:5044"]
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
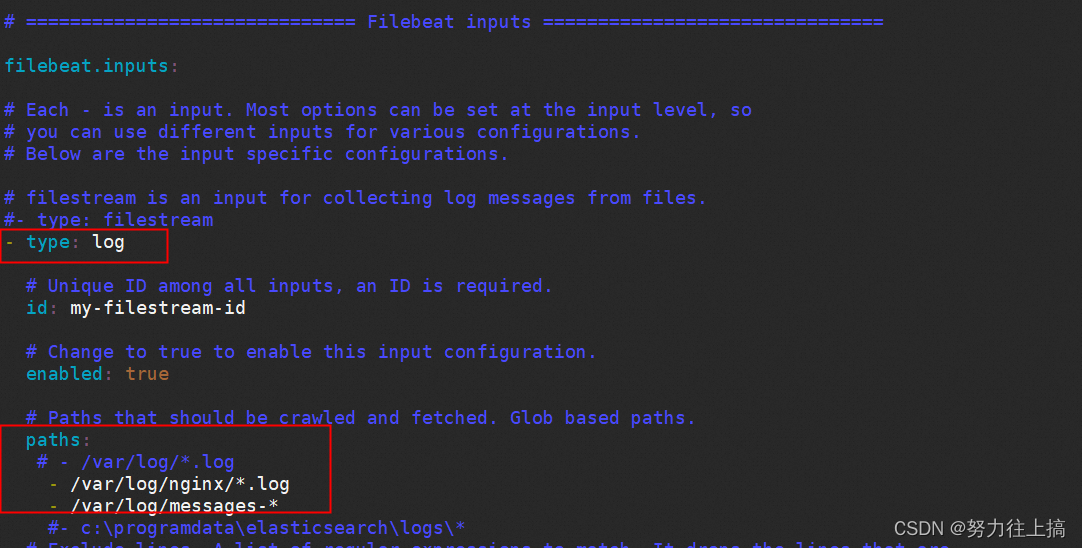
找到 Filebeat inputs位置,将type改为log,enabled改为true,
paths部分则是需要收集日志的目录位置,使用通配符*进行文件筛选
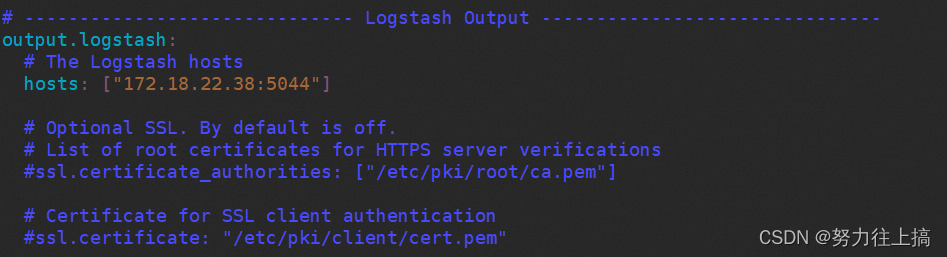
找到outputs部分,可以看到这里有多种不同的输出系统,这里选择输出到 Logstash,配置host之后记得将其他的输出配置给注释掉,配置后保存并退出
启动
启动 FileBeat
# 找到filebeat执行文件目录下
/filebeat/bin
# 指定配置文件来启动filebeat(日志文件在logs/下)
./filebeat -c filebeat.yml &# 检查是否启动成功ps-aux|grep filebeat
filebeat配置文件详解
#从input读取事件源,经过相应解析和处理之后,从output输出到目标存储库(elasticsearch或其他)。#输入可以从Log、Syslog、Stdin、Redis、UDP、Docker、TCP、NetFlow输入,然后可以输出到Elasticsearch、Logstash、Kafka、Redis、File、Console、Cloud。############################# Filebeat ######################################
filebeat:
prospectors:
-
# 指定要监控的日志,可以指定具体得文件或者目录
paths:
- /var/log/*.log (这是默认的)(自行可以修改)(比如我放在/home/hadoop/app.log里)
# 指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的#encoding: plain# 指定文件的输入类型log(默认)或者stdin
input_type: log
# 在输入中排除符合正则表达式列表的那些行。# exclude_lines: ["^DBG"]# 包含输入中符合正则表达式列表的那些行(默认包含所有行),include_lines执行完毕之后会执行exclude_lines# include_lines: ["^ERR", "^WARN"]# 忽略掉符合正则表达式列表的文件# exclude_files: [".gz$"]# 向输出的每一条日志添加额外的信息,比如“level:debug”,方便后续对日志进行分组统计。# 默认情况下,会在输出信息的fields子目录下以指定的新增fields建立子目录,例如fields.level# 这个得意思就是会在es中多添加一个字段,格式为 "filelds":{"level":"debug"}#fields:# level: debug# review: 1# 如果该选项设置为true,则新增fields成为顶级目录,而不是将其放在fields目录下。# 自定义的field会覆盖filebeat默认的field# 如果设置为true,则在es中新增的字段格式为:"level":"debug"#fields_under_root: false# 可以指定Filebeat忽略指定时间段以外修改的日志内容,比如2h(两个小时)或者5m(5分钟)。#ignore_older: 0# 如果一个文件在某个时间段内没有发生过更新,则关闭监控的文件handle。默认1h#close_older: 1h# 设定Elasticsearch输出时的document的type字段 可以用来给日志进行分类。Default: log#document_type: log# Filebeat以多快的频率去prospector指定的目录下面检测文件更新(比如是否有新增文件)# 如果设置为0s,则Filebeat会尽可能快地感知更新(占用的CPU会变高)。默认是10s#scan_frequency: 10s# 每个harvester监控文件时,使用的buffer的大小#harvester_buffer_size: 16384# 日志文件中增加一行算一个日志事件,max_bytes限制在一次日志事件中最多上传的字节数,多出的字节会被丢弃,default is 10MB.#max_bytes: 10485760# 适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈#multiline:# 多行日志开始的那一行匹配的pattern#pattern: ^\[# 是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。 【建议设置为true】#negate: false# 匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志#match: after# 合并的最多行数(包含匹配pattern的那一行)#max_lines: 500# 到了timeout之后,即使没有匹配一个新的pattern(发生一个新的事件),也把已经匹配的日志事件发送出去#timeout: 5s# 如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,# 而不是从文件开始处重新发送所有内容#tail_files: false# Filebeat检测到某个文件到了EOF(文件结尾)之后,每次等待多久再去检测文件是否有更新,默认为1s#backoff: 1s# Filebeat检测到某个文件到了EOF之后,等待检测文件更新的最大时间,默认是10秒#max_backoff: 10s# 定义到达max_backoff的速度,默认因子是2,到达max_backoff后,变成每次等待max_backoff那么长的时间才backoff一次,# 直到文件有更新才会重置为backoff# 根据现在的默认配置是这样的,每隔1s检测一下文件变化,如果连续检测两次之后文件还没有变化,下一次检测间隔时间变为10s#backoff_factor: 2# 这个选项关闭一个文件,当文件名称的变化。#该配置选项建议只在windows#force_close_files: false# spooler的大小,spooler中的事件数量超过这个阈值的时候会清空发送出去(不论是否到达超时时间)#spool_size: 2048# 是否采用异步发送模式(实验功能)#publish_async: false# spooler的超时时间,如果到了超时时间,spooler也会清空发送出去(不论是否到达容量的阈值)#idle_timeout: 5s# 记录filebeat处理日志文件的位置的文件,默认是在启动的根目录下#registry_file: .filebeat# 如果要在本配置文件中引入其他位置的配置文件,可以写在这里(需要写完整路径),但是只处理prospector的部分#config_dir:############################# Libbeat Config ################################### Base config file used by all other beats for using libbeat features############################# Output ##########################################
output:
elasticsearch: #(这是默认的,filebeat收集后放到es里)(自行可以修改,比如我有时候想filebeat收集后,然后到redis或者kafka,再到es,就可以注销这行)
hosts: ["localhost:9200"] (这是默认的,filebeat收集后放到es里)(自行可以修改,比如我有时候想filebeat收集后,然后到redis或者kafka,再到es,就可以注销这行)
版权归原作者 努力往上搞 所有, 如有侵权,请联系我们删除。