
✨作者主页:IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
一、前言
随着无线通信技术的快速发展和广泛应用,无线网络已经成为了现代社会信息交流的重要基础设施。为了满足日益增长的网络需求,提高无线网络的覆盖范围和服务质量变得尤为重要。然而,这需要解决许多技术挑战,其中之一就是如何规划、设计、维护和优化无线网络。
在当前的无线网络大数据平台中,存在一些问题和挑战。首先,网络规划数据不准确,无法满足实际需求。其次,网络设计数据不完整,无法了解在网分布系统和直放站现状。此外,缺乏无线网络大数据采集终端监控点,导致网络维护和优化数据不充分,无法准确评估网络性能和问题。
因此,本课题旨在研究一种新型的无线网络大数据平台,以解决上述问题。通过该平台,可以实现对无线网络数据的采集、分析和处理,从而为网络规划、设计、维护和优化提供强有力的支持。本课题的研究成果将有助于提高无线网络的覆盖范围和服务质量,具有重要的理论意义和实践价值。
目前,针对无线网络大数据平台的问题,虽然有一些现有的解决方案,但它们都存在一些问题。
首先,网络规划数据不准确。目前的网络规划方法主要依靠人工经验和一些简单的工具软件进行,无法考虑所有因素和情况,也无法实时更新数据。这导致规划结果往往与实际情况存在较大偏差,不能满足实际需求。
其次,网络设计数据不完整。在现有的系统中,对在网分布系统和直放站现状的记录往往不,无法准确反映实际情况。这使得网络设计存在盲区,可能导致一些潜在的问题无法被及时发现和处理。
此外,缺乏无线网络大数据采集终端监控点。现有的系统往往没有足够的数据采集点,无法收集网络维护和优化所需的数据。这使得网络维护和优化工作缺乏充分的数据支持,难以准确评估网络性能和问题。
本课题的研究目的是开发一种新型的无线网络大数据平台,以解决现有解决方案存在的问题。具体来说,该平台将实现以下功能:
实现对无线网络数据的采集和实时更新,包括网络规划数据、网络设计数据、无线网络大数据采集终端监控点数据等。
利用先进的数据分析和处理技术,对采集到的数据进行处理和分析,以发现潜在的问题和趋势,为网络规划、设计、维护和优化提供支持。
提供一个友好的用户界面,使用户可以方便地查看和分析数据,并生成相应的报告和建议。
本课题的研究成果将具有重要的理论意义和实践价值。首先,它将为无线网络规划、设计、维护和优化提供强有力的支持,有助于提高无线网络的覆盖范围和服务质量。其次,它将增进无线通信技术的发展和应用,推动信息社会的进步和发展。此外,本课题的研究还将为相关领域的研究提供新的思路和方法,推动相关领域的发展和创新。
二、开发环境
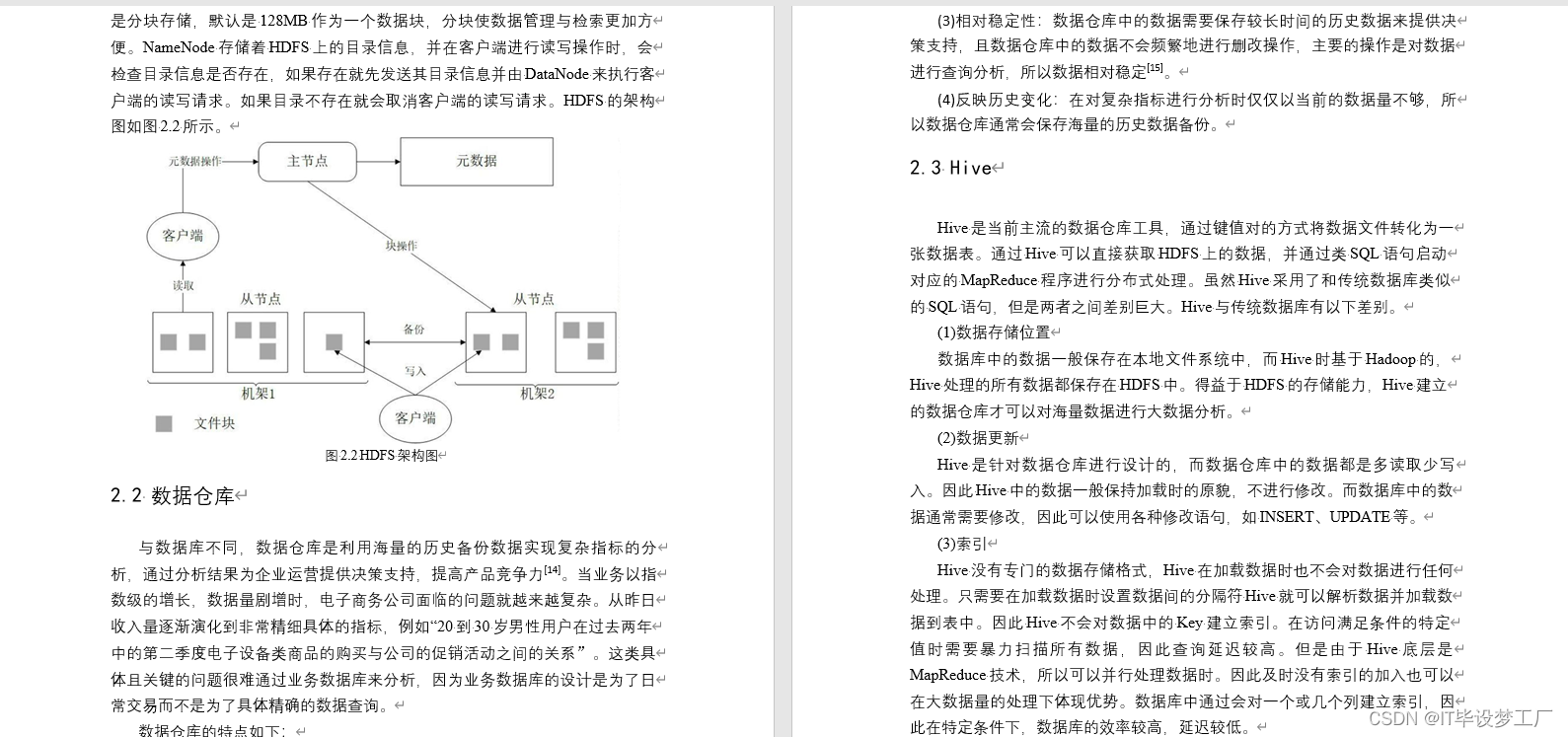
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
三、系统界面展示
- 无线网络大数据平台界面展示:






四、部分代码设计
- 无线网络大数据平台项目实战-代码参考:
class Scheduler(object):
def __init__(self, mongodb_server, mongodb_port, mongodb_db, persist, queue_key, queue_order):
self.mongodb_server = mongodb_server
self.mongodb_port = mongodb_port
self.mongodb_db = mongodb_db
self.queue_key = queue_key
self.persist = persist
self.queue_order = queue_order
def __len__(self):
return self.client.size()
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
mongodb_server = settings.get('MONGODB_QUEUE_SERVER', 'localhost')
mongodb_port = settings.get('MONGODB_QUEUE_PORT', 27017)
mongodb_db = settings.get('MONGODB_QUEUE_DB', 'scrapy')
persist = settings.get('MONGODB_QUEUE_PERSIST', True)
queue_key = settings.get('MONGODB_QUEUE_NAME', None)
queue_type = settings.get('MONGODB_QUEUE_TYPE', 'FIFO')
if queue_type not in ('FIFO', 'LIFO'):
raise Error('MONGODB_QUEUE_TYPE must be FIFO (default) or LIFO')
if queue_type == 'LIFO':
queue_order = -1
else:
queue_order = 1
return cls(mongodb_server, mongodb_port, mongodb_db, persist, queue_key, queue_order)
def open(self, spider):
self.spider = spider
if self.queue_key is None:
self.queue_key = "%s_queue"%spider.name
connection = pymongo.Connection(self.mongodb_server, self.mongodb_port)
self.db = connection[self.mongodb_db]
self.collection = self.db[self.queue_key]
# notice if there are requests already in the queue
size = self.collection.count()
if size > 0:
spider.log("Resuming crawl (%d requests scheduled)" % size)
def close(self, reason):
if not self.persist:
self.collection.drop()
def enqueue_request(self, request):
data = request_to_dict(request, self.spider)
self.collection.insert({
'data': data,
'created': datetime.datetime.utcnow()
})
def next_request(self):
entry = self.collection.find_and_modify(sort={"$natural":self.queue_order}, remove=True)
if entry:
request = request_from_dict(entry['data'], self.spider)
return request
return None
def has_pending_requests(self):
return self.collection.count() > 0
class DoubanPipeline(object):
def __init__(self):
self.server = settings['MONGODB_SERVER']
self.port = settings['MONGODB_PORT']
self.db = settings['MONGODB_DB']
self.col = settings['MONGODB_COLLECTION']
connection = pymongo.Connection(self.server, self.port)
db = connection[self.db]
self.collection = db[self.col]
def process_item(self, item, spider):
self.collection.insert(dict(item))
log.msg('Item written to MongoDB database %s/%s' % (self.db, self.col),level=log.DEBUG, spider=spider)
return item
五、论文参考
- 计算机毕业设计选题推荐-无线网络大数据平台-论文参考:
六、系统视频
无线网络大数据平台-项目视频:
大数据毕业设计选题推荐-无线网络大数据平台-Hadoop
结语
大数据毕业设计选题推荐-无线网络大数据平台-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
版权归原作者 IT毕设梦工厂 所有, 如有侵权,请联系我们删除。