
一、kafka架构
1.1Kafka基础知识
1.1.1 Kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多生产者、多订阅者,基于zookeeper协 调的分布式日志系统(也可以当做MQ系统),常见可以用于webynginx日志、访问日志,消息服务等等,Linkedin于 2010年贡献给了Apache基会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的⽅式提供消息持久化能⼒,即使对TB级以上数据也能保证常数时间的访问性能。
- ⾼吞吐率。即使在⾮常廉价的商⽤机器上也能做到单机⽀持每秒100K条消息的传输。
- ⽀持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时⽀持离线数据处理和实时数据处理。
- ⽀持在线⽔平扩展

kafka是一种发布-订阅模式, 对于消息中间件,消息分推拉两种模式。Kafka只有消息的拉取,没有推送,可以通过轮询实现消息的推送。
1.Kafka在一个或多个可以跨越多个数据中心的服务器上作为集群运行。
2.Kafka集群中按照主题分类管理,一个主题可以有多个分区,一个分区可以有多个副本分区。
3.每个记录由一个键,一个值和一个时间戳组成。
Kafka具有四个核心API:
1.ProducerAPI:允许应用程序将记录流发布到一个或多个Kafka主题。
2.ConsumerAPI:允许应用程序订阅一个或多个主题并处理为其生成的记录流。
3.StreamsAPI:允许应用程序充当流处理器,使用一个或多个主题的输入流,并生成一个或多个输出主题的输出流,从而有效地将输入流转换为输出流。
4.ConnectorAPI:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可重用生产者或使用者。例如,关系数据库的连接器可能会捕获对表的所有更改。
1.1.2 Kafka优势
- 高吞吐量:单机每秒处理几十上百万的消息量。即使存储了许多TB的消息,它也保持稳定的性能。
- 高性能:单节点支持上千个客户端,并保证零停机和零数据丢失。
- 持久化数据存储:将消息持久化到磁盘。通过将数据持久化到硬盘以及replication防止数据丢失。
- 分布式系统,无需停机就可扩展机器。
- 可靠性-kafka是分布式,分区,复制和容错的。
- 客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由server端维护。当失败时能自动平衡。
- 支持online和offline的场景。
- 支持多种客户端语言。Kafka支持Java、.NET、PHP、Python等多种语言。
1.1.3 Kafka应用场景
- 日志收集一个公司可以用Kafka可以收集各种服务的Log,通过Kafka以统一接口服务的方式开放给各种Consumer。
- 消息系统解耦生产者和消费者、缓存消息等。
- 用户活动跟踪用来记录web用户或者APP用户的各种活动,如网页搜索、搜索、点击,用户数据收集然后进行用户行为分析。
- 运营指标Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- 流式处理比如Spark Streaming和Storm。
1.1.4 Kafka核心概念
消息和批次
Kafka的数据单元称为消息。可以把消息看成是数据库里的一个“数据行”或一条“记录”,消息由字节数组组成。
消息有键,键也是⼀个字节数组。当消息以⼀种可控的⽅式写⼊不同的分区时,会⽤到键。
为了提⾼效率,消息被分批写⼊Kafka。批次就是⼀组消息,这些消息属于同⼀个主题和分区。
把消息分成批次可以减少⽹络开销。批次越⼤,单位时间内处理的消息就越多,单个消息的传输时间就越⻓。批次数据会被压缩,这样可以提升数据的传输和存储能⼒,但是需要更多的计算处理
模式
消息模式(schema)有许多可用的选项,以便于理解。如JSON和XML,但是它们缺乏强类型处理能力。Kafka的
许多开发者喜欢使用Apache Avro。Avro提供了一种紧凑的序列化格式,模式和消息体分开。当模式发生变化时,不需要重新生成代码,它还支持强类型和模式进化,其版本既向前兼容,也向后兼容。
topic
每条发布到Kafka集群的消息都有⼀个类别,这个类别被称为Topic。
物理上不同Topic的消息分开存储。
主题就好⽐数据库的表,尤其是分库分表之后的逻辑表。
主题可以被分为若干分区,一个主题通过分区分布于Kafka集群中,提供了横向扩展的能力。
Partition
- 主题可以被分为若干个分区,一个分区就是一个提交日志。
- 消息以追加的方式写入分区,然后以先入先出的顺序读取。
- 无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
- Kafka 通过分区来实现数据冗余和伸缩性。
- 在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
- 一个主题的不同partition,可以在一个broker上
Replicas
Kafka 使⽤主题来组织数据,每个主题被分为若⼲个分区,每个分区有多个副本。那些副本被保存在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。
同一个分区的副本分布在不同的broker上,所以副本数不能超过broker数
副本有以下两种类型:
- ⾸领副本每个分区都有⼀个⾸领副本。为了保证⼀致性,所有⽣产者请求和消费者请求都会经过这个副本。
- 跟随者副本⾸领以外的副本都是跟随者副本。跟随者副本不处理来⾃客户端的请求,它们唯⼀的任务就是从⾸领那⾥复制消息,保持与⾸领⼀致的状态。如果⾸领发⽣崩溃,其中的⼀个跟随者会被提升为新⾸领。跟随者副本包括同步副本和不同步副本,在发⽣⾸领副本切换的时候,只有同步副本可以切换为⾸领副本。
Broker和集群

一个独立的Kafka 服务器被称为broker,是集群的组成部分。
broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存
broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
broker 是集群的组成部分。每个集群都有⼀个broker 同时充当了集群控制器的⻆⾊(⾃动从集群的活跃成员中选举出来)。
如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的⼀个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的⼀个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数⽬少于N个,那么⼀个broker存储该topic的⼀个或多个partition。在实际⽣产环境中,尽量避免这种情况的发⽣,这种情况容易导致Kafka集群数据不均衡。
控制器负责管理⼯作:
- 将分区分配给broker
- 监控broker
在集群中,⼀个分区从属于⼀个broker,该broker 被称为分区的⾸领。一个分区在其他broker上可能还存在副本分区,分区的复制提供了消息冗余,⾼可⽤。副本分区不负责处理消息的读写。
Producer
生产者创建消息。

该⻆⾊将消息发布到Kafka的topic中。broker接收到⽣产者发送的消息后,将该消息追加到当前⽤于追加数据的 segment ⽂件中。
⼀般情况下,⼀个消息会被发布到⼀个特定的主题上。
- 默认情况下通过轮询把消息均衡地分布到主题的所有分区上。
- 在某些情况下,⽣产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为键⽣成⼀个散列值,并将其映射到指定的分区上。这样可以保证包含同⼀个键的消息会被写到同⼀个分区上。
- ⽣产者也可以使⽤⾃定义的分区器,根据不同的业务规则将消息映射到分区。
Consumer
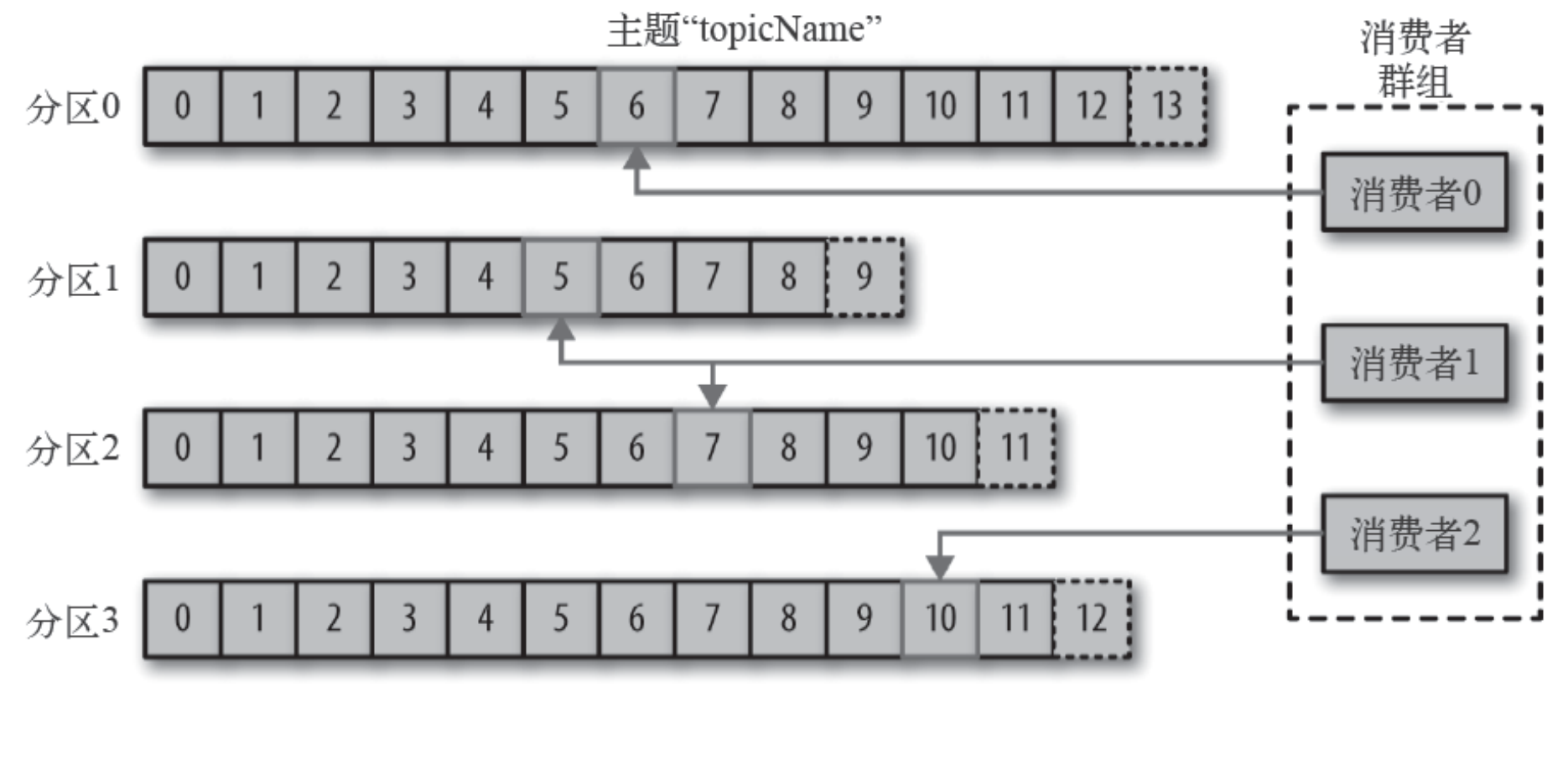
消费者读取消息
- 消费者订阅⼀个或多个主题,并按照消息⽣成的顺序读取它们。
- 消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是另⼀种元数据,它是⼀个不断递增的整数值,在创建消息时,Kafka 会把它添加到消息⾥。对于某个消费组,在给定的分区⾥,每个消息的偏移量都是唯⼀的。消费者把每个分区最后读取的消息偏移量保存在Zookeeper 或Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
- 消费者是消费组的⼀部分。群组保证每个分区只能被⼀个消费者使⽤。
- 如果⼀个消费者失效,消费组⾥的其他消费者可以接管失效消费者的⼯作,再平衡,分区重新分配。
Offset

生产者Offset:消息写入的时候,每一个分区都有一个offset,这个offset就是生产者的offset,同时也是这个分区的最新最大的offset。
消费者Offset:某个分区的offset情况,生产者写入的offset是最新最大的值是12,而当Consumer A进行消费时,从0开始消费,一直消费到了9,消费者的offset就记录在9,Consumer B就纪录在了11。等下⼀次他们再来消费时,他们可以选择接着上⼀次的位置消费,当然也可以选择从头消费,或者跳到最近的记录并从“现在”开始消费。
AR
分区中的所有副本统称为AR(Assigned Repllicas),AR=ISR+OSR。
ISR
所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。
消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进⾏同步,同步期间内follower副本相对于leader副本⽽⾔会有⼀定程度的滞后。对于这种滞后可以有“⼀定程度”忍受,这个忍受的范围可以通过参数进⾏配置
OSR
与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas)。
在正常情况下,所有的follower副本都应该与leader副本保持⼀定程度的同步,即AR=ISR,OSR集合为空
HW

HW是High Watermak的缩写, 俗称⾼⽔位,它表示了⼀个特定消息的偏移量(offset),是该分区的所有副本集中最小的LEO
LEO
LEO是Log End Offset的缩写,它表示了当前⽇志⽂件中下⼀条待写⼊消息的offset。
1.2 Kafka配置
1.2.1 生产者配置
KafkaProducer 的创建需要指定的参数和含义:
参数名称描述retry.backoff.ms在向⼀个指定的主题分区重发消息的时候,重试之间的等待时间。⽐如3次重试,每次重试之后等待该时间⻓度,再接着重试。在⼀些失败的场景,避免了密集循环的重新发送请求。long型值,默认100。可选值:[0,…]retriesretries重试次数当消息发送出现错误的时候,系统会重发消息。跟客户端收到错误时重发⼀样。如果设置了重试,还想保证消息的有序性,需要设置
MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1
否则在重试此失败消息的时候,其他的消息可能发送成功了request.timeout.ms客户端等待请求响应的最⼤时⻓。如果服务端响应超时,则会重发请求,除⾮达到重试次数。该设置应该⽐
replica.lag.time.max.ms (a broker configuration)
要⼤,以免在服务器延迟时间内重发消息。int类型值,默认:30000,可选值:[0,…]interceptor.classes在⽣产者接收到该消息,向Kafka集群传输之前,由序列化器处理之前,可以通过拦截器对消息进⾏处理。要求拦截器类必须实现
org.apache.kafka.clients.producer.ProducerInterceptor
接⼝。默认没有拦截器。
Map<String, Object> configs
中通过List集合配置多个拦截器类名。acks默认值:all。acks=0:⽣产者不等待broker对消息的确认,只要将消息放到缓冲区,就认为消息已经发送完成。该情形不能保证broker是否真的收到了消息,retries配置也不会⽣效。发送的消息的返回的消息偏移量永远是-1。 acks=1表示消息只需要写到主分区即可,然后就响应客户端,⽽不等待副本分区的确认。在该情形下,如果主分区收到消息确认之后就宕机了,⽽副本分区还没来得及同步该消息,则该消息丢失。 acks=all⾸领分区会等待所有的ISR副本分区确认记录。该处理保证了只要有⼀个ISR副本分区存活,消息就不会丢失。这是Kafka最强的可靠性保证,等效于acks=-1batch.size当多个消息发送到同⼀个分区的时候,⽣产者尝试将多个记录作为⼀个批来处理。批处理提⾼了客户端和服务器的处理效率。该配置项以字节为单位控制默认批的⼤⼩。所有的批⼩于等于该值。发送给broker的请求将包含多个批次,每个分区⼀个,并包含可发送的数据。如果该值设置的⽐较⼩,会限制吞吐量(设置为0会完全禁⽤批处理)。如果设置的很⼤,⼜有⼀点浪费内存,因为Kafka会永远分配这么⼤的内存来参与到消息的批整合中。client.id⽣产者发送请求的时候传递给broker的id字符串。⽤于在broker的请求⽇志中追踪什么应⽤发送了什么消息。⼀般该id是跟业务有关的字符串。compression.type⽣产者发送的所有数据的压缩⽅式。默认是none,也就是不压缩。⽀持的值:none、gzip、snappy和lz4。压缩是对于整个批来讲的,所以批处理的效率也会影响到压缩的⽐例。send.buffer.bytesTCP发送数据的时候使⽤的缓冲区(SO_SNDBUF)⼤⼩。如果设置为0,则使⽤操作系统默认的。buffer.memory⽣产者可以⽤来缓存等待发送到服务器的记录的总内存字节。如果记录的发送速度超过了将记录发送到服务器的速度,则⽣产者将阻塞
max.block.ms
的时间,此后它将引发异常。此设置应⼤致对应于⽣产者将使⽤的总内存,但并⾮⽣产者使⽤的所有内存都⽤于缓冲。⼀些额外的内存将⽤于压缩(如果启⽤了压缩)以及维护运⾏中的请求。long型数据。默认值:33554432,可选值:[0,…]connections.max.idle.ms当连接空闲时间达到这个值,就关闭连接。long型数据,默认:540000linger.ms⽣产者在发送请求传输间隔会对需要发送的消息进⾏累积,然后作为⼀个批次发送。⼀般情况是消息的发送的速度⽐消息累积的速度慢。有时客户端需要减少请求的次数,即使是在发送负载不⼤的情况下。该配置设置了⼀个延迟,⽣产者不会⽴即将消息发送到broker,⽽是等待这么⼀段时间以累积消息,然后将这段时间之内的消息作为⼀个批次发送。该设置是批处理的另⼀个上限:⼀旦批消息达到了
batch.size
指定的值,消息批会⽴即发送,如果积累的消息字节数达不到
batch.size
的值,可以设置该毫秒值,等待这么⻓时间之后,也会发送消息批。该属性默认值是0(没有延迟)。如果设置
linger.ms=5
,则在⼀个请求发送之前先等待5ms。long型值,默认:0,可选值:[0,…]max.block.ms控制
KafkaProducer.send()
和
KafkaProducer.partitionsFor()
阻塞的时⻓。当缓存满了或元数据不可⽤的时候,这些⽅法阻塞。在⽤户提供的序列化器和分区器的阻塞时间不计⼊。long型值,默认:60000,可选值:[0,…]max.request.size单个请求的最⼤字节数。该设置会限制单个请求中消息批的消息个数,以免单个请求发送太多的数据。服务器有⾃⼰的限制批⼤⼩的设置,与该配置可能不⼀样。int类型值,默认1048576,可选值:[0,…]partitioner.class实现了接⼝
org.apache.kafka.clients.producer.Partitioner
的分区器实现类。默认值为:
org.apache.kafka.clients.producer.internals.DefaultPartitioner
receive.buffer.bytesTCP接收缓存(SO_RCVBUF),如果设置为-1,则使⽤操作系统默认的值。int类型值,默认32768,可选值:[-1,…]security.protocol跟broker通信的协议:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.string类型值,默认:PLAINTEXTmax.in.flight.requests.per.connection单个连接上未确认请求的最⼤数量。达到这个数量,客户端阻塞。如果该值⼤于1,且存在失败的请求,在重试的时候消息顺序不能保证。int类型值,默认5。可选值:[1,…]reconnect.backoff.max.ms对于每个连续的连接失败,每台主机的退避将成倍增加,直⾄达到此最⼤值。在计算退避增量之后,添加20%的随机抖动以避免连接⻛暴。long型值,默认1000,可选值:[0,…]reconnect.backoff.ms尝试重连指定主机的基础等待时间。避免了到该主机的密集重连。该退避时间应⽤于该客户端到broker的所有连接。long型值,默认50。可选值:[0,…]key.serializer实现了接⼝org.apache.kafka.common.serialization.Serializer的key序列化类。value.serializer实现了接⼝org.apache.kafka.common.serialization.Serializer的value序列化类。
其他参数可以从
org.apache.kafka.clients.producer.ProducerConfig
中找到。
1.2.2 服务端参数配置
$KAFKA_HOME/config/server.properties⽂件中的配置
参数说明zookeeper.connect该参数⽤于配置Kafka要连接的Zookeeper/集群的地址。
它的值是⼀个字符串,使⽤逗号分隔Zookeeper的多个地址。Zookeeper的单个地址是host:port形式的,可以在最后添加Kafka在Zookeeper中的根节点路径
zookeeper.connect=192.168.0.102:2181,192.168.0.103:2181,192.168.0.104:2181/kafka
listeners⽤于配置broker监听的URI以及监听器名称列表,使⽤逗号隔开多个URI及监听器名称。如果监听器名称代表的不是安全协议,必须配置
listener.security.protocol.map
。每个监听器必须使⽤不同的⽹络端⼝。inter.broker.listener.name⽤于配置broker之间通信使⽤的监听器名称,该名称必须在advertised.listeners列表中。
inter.broker.listener.name=EXTERNAL
listener.security.protocol.map监听器名称和安全协议的映射配置。⽐如,可以将内外⽹隔离,即使它们都使⽤SSL。
listener.security.protocol.map=INTERNAL:SSL,EXTERNAL:SSL
每个监听器的名称只能在map中出现⼀次。advertised.listeners需要将该地址发布到zookeeper供客户端使⽤。
可以在zookeeper的
get /myKafka/brokers/ids/<broker.id>
中找到。
如果不设置此条⽬,就使⽤listeners的配置。
跟listeners不同,该条⽬不能使⽤0.0.0.0⽹络端⼝。
advertised.listeners的地址必须是listeners中配置的或配置的⼀部分。broker.id该属性⽤于唯⼀标记⼀个Kafka的Broker,它的值是⼀个任意integer值。
当Kafka以分布式集群运⾏的时候,尤为重要。
最好该值跟该Broker所在的物理主机有关的,如果主机名为
192.168.100.101
,则
broker.id=101
等等。log.dirs通过该属性的值,指定Kafka在磁盘上保存消息的⽇志⽚段的⽬录。
它是⼀组⽤逗号分隔的本地⽂件系统路径。如果指定了多个路径,那么broker 会根据“最少使⽤”原则,把同⼀个分区的⽇志⽚段保存到同⼀个路径下。
broker 会往拥有最少数⽬分区的路径新增分区,⽽不是往拥有最⼩磁盘空间的路径新增分区。
1.2.3 消费者参数配置
配置项说明bootstrap.servers建⽴到Kafka集群的初始连接⽤到的host/port列表。 客户端会使⽤这⾥指定的所有的host/port来建⽴初始连接。 这个配置仅会影响发现集群所有节点的初始连接。 形式:host1:port1,host2:port2… 这个配置中不需要包含集群中所有的节点信息。 最好不要配置⼀个,以免配置的这个节点宕机的时候连不上。group.id⽤于定义当前消费者所属的消费组的唯⼀字符串。 如果使⽤了消费组的功能
subscribe(topic)
,或使⽤了基于Kafka的偏移量管理机制,则应该配置group.id。auto.commit.interval.ms如果设置了
enable.auto.commit
的值为true,则该值定义了消费者偏移量向Kafka提交的频率。auto.offset.reset如果Kafka中没有初始偏移量或当前偏移量在服务器中不存在(⽐如数据被删掉了): earliest:⾃动重置偏移量到最早的偏移量。 latest:⾃动重置偏移量到最后⼀个 none:如果没有找到该消费组以前的偏移量没有找到,就抛异常。 其他值:向消费者抛异常。fetch.min.bytes服务器对每个拉取消息的请求返回的数据量最⼩值。 如果数据量达不到这个值,请求等待,以让更多的数据累积,达到这个值之后响应请求。 默认设置是1个字节,表示只要有⼀个字节的数据,就⽴即响应请求,或者在没有数据的时候请求超时。 将该值设置为⼤⼀点⼉的数字,会让服务器等待稍微⻓⼀点⼉的时间以累积数据。 如此则可以提⾼服务器的吞吐量,代价是额外的延迟时间。fetch.max.wait.ms如果服务器端的数据量达不到
fetch.min.bytes
的话,服务器端不能⽴即响应请求。该时间⽤于配置服务器端阻塞请求的最⼤时⻓。fetch.max.bytes服务器给单个拉取请求返回的最⼤数据量。 消费者批量拉取消息,如果第⼀个⾮空消息批次的值⽐该值⼤,消息批也会返回,以让消费者可以接着进⾏。 即该配置并不是绝对的最⼤值。 broker可以接收的消息批最⼤值通过
message.max.bytes
(broker配置)或
max.message.bytes
(主题配置)来指定。需要注意的是,消费者⼀般会并发拉取请求。enable.auto.commit如果设置为true,则消费者的偏移量会周期性地在后台提交。connections.max.idle.ms在这个时间之后关闭空闲的连接。check.crcs⾃动计算被消费的消息的CRC32校验值。 可以确保在传输过程中或磁盘存储过程中消息没有被破坏。 它会增加额外的负载,在追求极致性能的场合禁⽤。exclude.internal.topics是否内部主题应该暴露给消费者。如果该条⽬设置为true,则只能先订阅再拉取。isolation.level控制如何读取事务消息。 如果设置了
read_committed
,消费者的
poll()
⽅法只会返回已经提交的事务消息。如果设置了
read_uncommitted
(默认值),消费者的poll⽅法返回所有的消息,即使是已经取消的事务消息。⾮事务消息以上两种情况都返回。 消息总是以偏移量的顺序返回。
read_committed
只能返回到达LSO的消息。在LSO之后出现的消息只能等待相关的事务提交之后才能看到。结果,
read_committed
模式,如果有为提交的事务,消费者不能读取到直到HW的消息。
read_committed
的
seekToEnd
⽅法返回LSO。heartbeat.interval.ms当使⽤消费组的时候,该条⽬指定消费者向消费者协调器发送⼼跳的时间间隔。 ⼼跳是为了确保消费者会话的活跃状态,同时在消费者加⼊或离开消费组的时候⽅便进⾏再平衡。 该条⽬的值必须⼩于
session.timeout.ms
,也不应该⾼于
session.timeout.ms
的1/3。可以将其调整得更⼩,以控制正常重新平衡的预期时间。session.timeout.ms当使⽤Kafka的消费组的时候,消费者周期性地向broker发送⼼跳数据,表明⾃⼰的存在。 如果经过该超时时间还没有收到消费者的⼼跳,则broker将消费者从消费组移除,并启动再平衡。 该值必须在broker配置
group.min.session.timeout.ms
和
group.max.session.timeout.ms
之间。max.poll.records⼀次调⽤
poll()
⽅法返回的记录最⼤数量。max.poll.interval.ms使⽤消费组的时候调⽤poll()⽅法的时间间隔。 该条⽬指定了消费者调⽤poll()⽅法的最⼤时间间隔。 如果在此时间内消费者没有调⽤poll()⽅法,则broker认为消费者失败,触发再平衡,将分区分配给消费组中其他消费者。max.partition.fetch.bytes对每个分区,服务器返回的最⼤数量。消费者按批次拉取数据。 如果⾮空分区的第⼀个记录⼤于这个值,批处理依然可以返回,以保证消费者可以进⾏下去。 broker接收批的⼤⼩由
message.max.bytes
(broker参数)或
max.message.bytes
(主题参数)指定。
fetch.max.bytes
⽤于限制消费者单次请求的数据量。send.buffer.bytes⽤于TCP发送数据时使⽤的缓冲⼤⼩(SO_SNDBUF),-1表示使⽤OS默认的缓冲区⼤⼩。retry.backoff.ms在发⽣失败的时候如果需要重试,则该配置表示客户端等待多⻓时间再发起重试。 该时间的存在避免了密集循环。request.timeout.ms客户端等待服务端响应的最⼤时间。如果该时间超时,则客户端要么重新发起请求,要么如果重试耗尽,请求失败。reconnect.backoff.ms重新连接主机的等待时间。避免了重连的密集循环。 该等待时间应⽤于该客户端到broker的所有连接。reconnect.backoff.max.ms重新连接到反复连接失败的broker时要等待的最⻓时间(以毫秒为单位)。 如果提供此选项,则对于每个连续的连接失败,每台主机的退避将成倍增加,直⾄达到此最⼤值。 在计算退避增量之后,添加20%的随机抖动以避免连接⻛暴。receive.buffer.bytesTCP连接接收数据的缓存(SO_RCVBUF)。-1表示使⽤操作系统的默认值。partition.assignment.strategy当使⽤消费组的时候,分区分配策略的类名。metrics.sample.window.ms计算指标样本的时间窗⼝。metrics.recording.level指标的最⾼记录级别。metrics.num.samples⽤于计算指标⽽维护的样本数量interceptor.classes拦截器类的列表。默认没有拦截器拦截器是消费者的拦截器,该拦截器需要实现
org.apache.kafka.clients.consumer.ConsumerInterceptor
接⼝。拦截器可⽤于对消费者接收到的消息进⾏拦截处理。
1.2.4 主题配置

1.3 Kafka 使用
1.3.1 Kafka API 使用
⽣产者主要的对象有: KafkaProducer , ProducerRecord 。
其中 KafkaProducer 是⽤于发送消息的类, ProducerRecord 类⽤于封装Kafka的消息。
消费者⽣产消息后,需要broker端的确认,可以同步确认,也可以异步确认。
同步确认效率低,异步确认效率⾼,但是需要设置回调对象。
添加Maven依赖:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><!--高版本兼容低版本--><version>1.0.2</version></dependency>1.2.3.4.5.6.
生产者
同步等待消息确认:
public class MyProducer1 {
public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
Map<String, Object> configs = new HashMap<>();
// 设置连接Kafka的初始连接⽤到的服务器地址
// 如果是集群,则可以通过此初始连接发现集群中的其他broker
configs.put("bootstrap.servers", "192.168.0.102:9092");
// 设置key的序列化器
configs.put("key.serializer", IntegerSerializer.class);
// 设置value的序列化器
configs.put("value.serializer", StringSerializer.class);
configs.put("acks", "1");
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(configs);
// ⽤于封装Producer的消息
ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>(
"topic_1", // 主题名称
0, // 分区编号,现在只有⼀个分区,所以是0
0, // 数字作为key
"message 0" // 字符串作为value
);
// 发送消息,同步等待消息的确认
Future<RecordMetadata> future = producer.send(record);
RecordMetadata metadata = future.get(3000, TimeUnit.MILLISECONDS);
System.out.println("主题:" + metadata.topic()
+ "\n分区:" + metadata.partition()
+ "\n偏移量:" + metadata.offset()
+ "\n序列化的key字节:" + metadata.serializedKeySize()
+ "\n序列化的value字节:" + metadata.serializedValueSize()
+ "\n时间戳:" + metadata.timestamp());
// 关闭⽣产者
producer.close();
}
}
异步等待消息确认:
publicclassMyProducer2{publicstaticvoidmain(String[] args){Map<String,Object> configs =newHashMap<>();
configs.put("bootstrap.servers","192.168.0.102:9092");
configs.put("key.serializer",IntegerSerializer.class);
configs.put("value.serializer",StringSerializer.class);KafkaProducer<Integer,String> producer =newKafkaProducer<Integer,String>(configs);ProducerRecord<Integer,String> record =newProducerRecord<Integer,String>("topic_1",0,1,"message 2");// 使⽤回调异步等待消息的确认
producer.send(record,newCallback(){@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception exception){if(exception ==null){System.out.println("主题:"+ metadata.topic()+"\n分区:"+ metadata.partition()+"\n偏移量:"+ metadata.offset()+"\n序列化的key字节:"+ metadata.serializedKeySize()+"\n序列化的value字节:"+ metadata.serializedValueSize()+"\n时间戳:"+ metadata.timestamp());}else{System.out.println("有异常:"+ exception.getMessage());}}});// 关闭连接
producer.close();}}
消费者:
publicclassMyConsumer1{publicstaticvoidmain(String[] args){Map<String,Object> configs =newHashMap<>();// 指定bootstrap.servers属性作为初始化连接Kafka的服务器。// 如果是集群,则会基于此初始化连接发现集群中的其他服务器。
configs.put("bootstrap.servers","192.168.0.102:9092");// key的反序列化器
configs.put("key.deserializer",IntegerDeserializer.class);// value的反序列化器
configs.put("value.deserializer",StringDeserializer.class);// 设置消费组
configs.put("group.id","consumer.demo");// 创建消费者对象KafkaConsumer<Integer,String> consumer =newKafkaConsumer<Integer,String>(configs);// 可以使用正则表达式批量订阅主题// final Pattern pattern = Pattern.compile("topic_\\d")finalPattern pattern =Pattern.compile("topic_[0-9]");finalList<String> topics =Arrays.asList("topic_1");// 消费者订阅主题或分区// consumer.subscribe(pattern);// consumer.subscribe(pattern, new ConsumerRebalanceListener() {
consumer.subscribe(topics,newConsumerRebalanceListener(){@OverridepublicvoidonPartitionsRevoked(Collection<TopicPartition> partitions){
partitions.forEach(tp ->{System.out.println("剥夺的分区:"+ tp.partition());});}@OverridepublicvoidonPartitionsAssigned(Collection<TopicPartition> partitions){
partitions.forEach(tp ->{System.out.println(tp.partition());});}});// 拉取订阅主题的消息finalConsumerRecords<Integer,String> records = consumer.poll(3_000);// 获取topic_1主题的消息finalIterable<ConsumerRecord<Integer,String>> topic1Iterable = records.records("topic_1");// 遍历topic_1主题的消息
topic1Iterable.forEach(record ->{System.out.println("========================================");System.out.println("消息头字段:"+Arrays.toString(record.headers().toArray()));System.out.println("消息的key:"+ record.key());System.out.println("消息的偏移量:"+ record.offset());System.out.println("消息的分区号:"+ record.partition());System.out.println("消息的序列化key字节数:"+ record.serializedKeySize());System.out.println("消息的序列化value字节数:"+ record.serializedValueSize());System.out.println("消息的时间戳:"+ record.timestamp());System.out.println("消息的时间戳类型:"+ record.timestampType());System.out.println("消息的主题:"+ record.topic());System.out.println("消息的值:"+ record.value());});// 关闭消费者
consumer.close();}}
1.3.2 springboot Kafka 使用
pom.xml 依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.8.RELEASE</version><relativePath/><!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
application.properties
spring.application.name=demo-02-producer-consumer
server.port=8080
# ⽤于建⽴初始连接的broker地址
spring.kafka.bootstrap-servers=192.168.0.102:9092
# producer⽤到的key和value的序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.IntegerSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 默认的批处理记录数
spring.kafka.producer.batch-size=16384
# 32MB的总发送缓存
spring.kafka.producer.buffer-memory=33554432
# consumer⽤到的key和value的反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# consumer的消费组id
spring.kafka.consumer.group-id=spring-kafka-02-consumer
# 是否⾃动提交消费者偏移量
spring.kafka.consumer.enable-auto-commit=true
# 每隔100ms向broker提交⼀次偏移量
spring.kafka.consumer.auto-commit-interval=100
# 如果该消费者的偏移量不存在,则⾃动设置为最早的偏移量
spring.kafka.consumer.auto-offset-reset=earliest
Application.java 启动类
@SpringBootApplicationpublicclassApplication{publicstaticvoidmain(String[] args){SpringApplication.run(Application.class, args);}}
KafkaConfig.java 配置类,可以在应用启动时创建Topic,这里可以不用,因为主题不存在的时候Kafka可以自动创建
@Configuration
public class KafkaConfig {
@Bean
public NewTopic topic1() {
return new NewTopic("ntp-01", 5, (short) 1);
}
@Bean
public NewTopic topic2() {
return new NewTopic("ntp-02", 3, (short) 1);
}
}
生产者 KafkaSyncProducerController.java
@RestControllerpublicclassKafkaSyncProducerController{@AutowiredprivateKafkaTemplate template;// 同步等待消息发送@GetMapping("/sendSync/{message}")publicStringsendSync(@PathVariableString message)throwsExecutionException,InterruptedException{ProducerRecord<Integer,String> record =newProducerRecord<>("spring-topic-01",0,1, message
);ListenableFuture future = template.send(record);// 同步等待broker的响应Object o = future.get();SendResult<Integer,String> result =(SendResult<Integer,String>) o;System.out.println(result.getRecordMetadata().topic()+ result.getRecordMetadata().partition()+ result.getRecordMetadata().offset());return"success";}// 异步等待消息确认@GetMapping("/sendAsync/{message}")publicStringsendAsync(@PathVariableString message)throwsExecutionException,InterruptedException{ProducerRecord<Integer,String> record =newProducerRecord<>("spring-topic-01",0,1, message
);ListenableFuture<SendResult<Integer,String>> future = template.send(record);// 异步等待broker的响应
future.addCallback(newListenableFutureCallback<SendResult<Integer,String>>(){@OverridepublicvoidonFailure(Throwable throwable){System.out.println("发送失败: "+ throwable.getMessage());}@OverridepublicvoidonSuccess(SendResult<Integer,String> result){System.out.println("发送成功:"+ result.getRecordMetadata().topic()+"\t"+ result.getRecordMetadata().partition()+"\t"+ result.getRecordMetadata().offset());}});return"success";}}
消费者MyConsumer.java
@ComponentpublicclassMyConsumer{@KafkaListener(topics ="spring-topic-01")publicvoidonMessage(ConsumerRecord<Integer,String> record){Optional<ConsumerRecord<Integer,String>> optional =Optional.ofNullable(record);if(optional.isPresent()){System.out.println(record.topic()+"\t"+ record.partition()+"\t"+ record.offset()+"\t"+ record.key()+"\t"+ record.value());}}}
二、Kafka高级特性
2.1 生产者
2.1.1 消息发送
2.1.1.1 数据生产流程
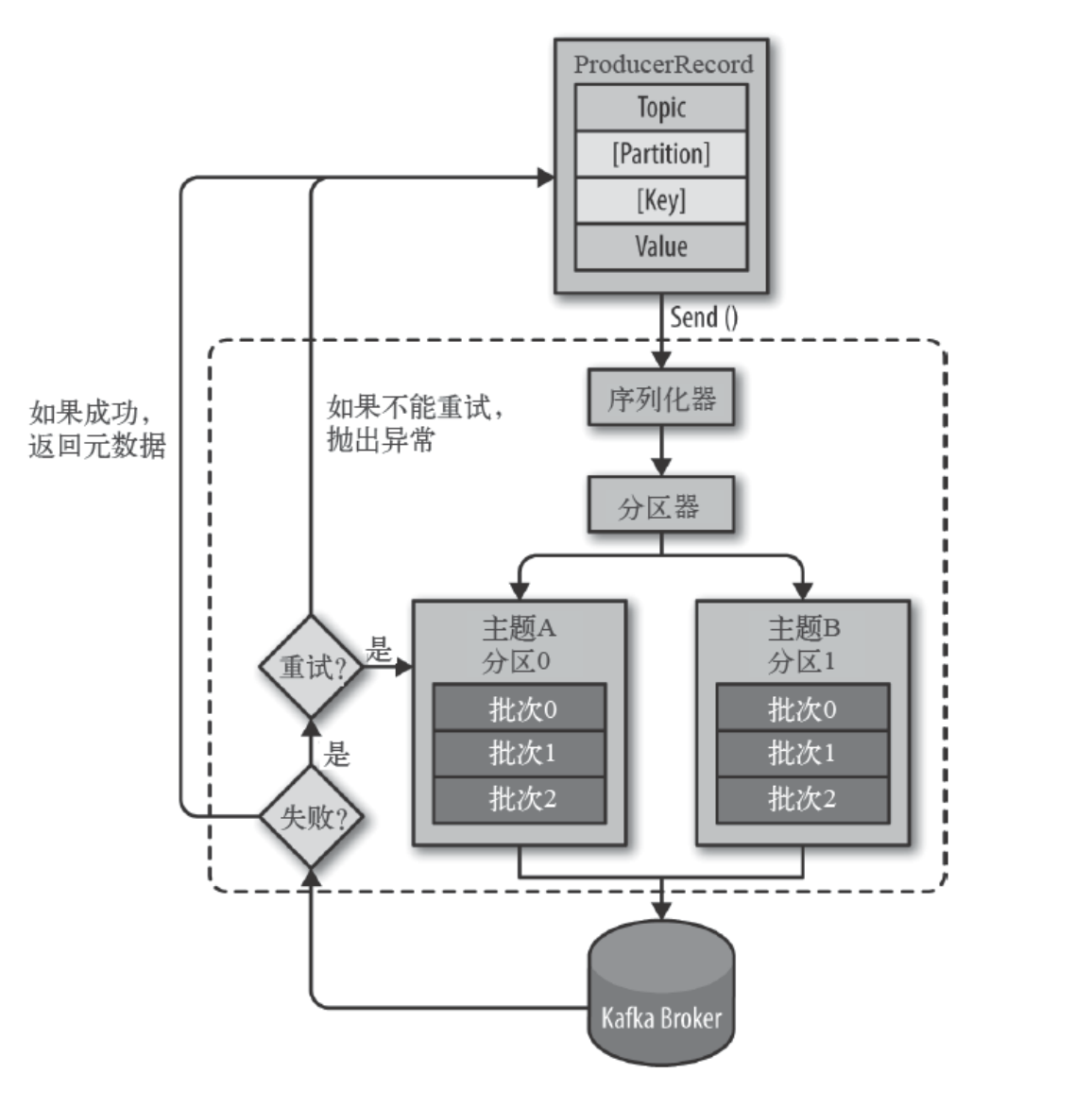
数据生产流程图解:

- Producer创建时,会创建⼀个Sender线程并设置为守护线程
- ⽣产消息时,内部其实是异步流程;⽣产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区(该缓冲区也是在Producer创建时创建)
- 批次发送的条件为:缓冲区数据⼤⼩达到
batch.size或者linger.ms达到上限,哪个先达到就算哪个 - 批次发送后,发往指定分区,然后落盘到 broker;如果⽣产者配置了
retrires参数⼤于0并且失败原因允许重试,那么客户端内部会对该消息进⾏重试 - 落盘到broker成功,返回⽣产元数据给⽣产者
- 元数据返回有两种⽅式:⼀种是通过阻塞直接返回,另⼀种是通过回调返回
2.1.1.2 拦截器

Producer 的拦截器(Interceptor)和 Consumer 的 Interceptor 主要⽤于实现Client端的定制化控制逻辑。
对于Producer⽽⾔,Interceptor使得⽤户在消息发送前以及Producer回调逻辑前有机会对消息做⼀些定制化需求,⽐如修改消息等。同时,Producer允许⽤户指定多个Interceptor按序作⽤于同⼀条消息从⽽形成⼀个拦截链(Interceptor Chain)。如果有多个拦截器1,2,3 那发送前的调用顺序是1->2->3,回调的时候顺序还是1->2->3而不是3->2->1,Intercetpor 的实现接⼝是
org.apache.kafka.clients.producer.ProducerInterceptor
,其定义的⽅法包括:
onSend(ProducerRecord):该⽅法封装进KafkaProducer.send⽅法中,即运⾏在⽤户主线程中。Producer确保在消息被序列化以及分区前调⽤该⽅法。⽤户可以在该⽅法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响⽬标分区的计算。onAcknowledgement(RecordMetadata, Exception):该⽅法会在消息被应答之前或消息发送失败时调⽤,并且通常都是在Producer回调逻辑触发之前。onAcknowledgement运⾏在Producer的IO线程中,因此不要在该⽅法中放⼊很重的逻辑,否则会拖慢Producer的消息发送效率。close:关闭Interceptor,主要⽤于执⾏⼀些资源清理⼯作。
如前所述,Interceptor可能被运⾏在多个线程中,因此在具体实现时⽤户需要⾃⾏确保线程安全。另外倘若指定了多个Interceptor,则Producer将按照指定顺序调⽤它们,并仅仅是捕获每个Interceptor可能抛出的异常记录到错误⽇志中⽽⾮在向上传递。这在使⽤过程中要特别留意。
自定义拦截器步骤:
- 实现ProducerInterceptor接⼝,自定义拦截器
- 在KafkaProducer的设置中设置⾃定义的拦截器
自定义拦截器:
public class InterceptorOne<Key, Value> implements ProducerInterceptor<Key, Value> {
private static final Logger LOGGER = LoggerFactory.getLogger(InterceptorOne.class);
/**
*发送前调用
*/
@Override
public ProducerRecord<Key, Value> onSend(ProducerRecord<Key, Value> record) {
System.out.println("拦截器---go");
// 此处可以根据业务需要对相关的数据作修改
String topic = record.topic();
Integer partition = record.partition();
Long timestamp = record.timestamp();
Key key = record.key();
Value value = record.value();
Headers headers = record.headers();
// 添加消息头
headers.add("interceptor", "自定义拦截器".getBytes());
ProducerRecord<Key, Value> newRecord = new ProducerRecord<Key, Value>(topic,
partition, timestamp, key, value, headers);
return newRecord;
}
//异常或者返回结果时调用
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.println("拦截器---back");
if (exception != null) {
// 如果发⽣异常,记录⽇志中
LOGGER.error(exception.getMessage());
}
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
生产者
public class MyProducer {
public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
Map<String, Object> configs = new HashMap<>();
// 设置连接Kafka的初始连接⽤到的服务器地址
// 如果是集群,则可以通过此初始连接发现集群中的其他broker
configs.put("bootstrap.servers", "192.168.0.102:9092");
// 设置key的序列化器
configs.put("key.serializer", IntegerSerializer.class);
// 设置value的序列化类
configs.put("value.serializer", StringSerializer.class);
// 设置自定义拦截器 如果有多个可以以,间隔
configs.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
"com.edu.interceptor.InterceptorOne");
KafkaProducer<Integer, User> producer = new KafkaProducer<>(configs);
// ⽤于封装Producer的消息
ProducerRecord<Integer, String> record = new ProducerRecord<>(
"topic_1", // 主题名称
0, // 分区编号
1, // 数字作为key
"自定义拦截器" // user 对象作为value
);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e == null) {
System.out.println("消息发送成功:" + metadata.topic() + "\t"
+ metadata.partition() + "\t"
+ metadata.offset());
} else {
System.out.println("消息发送异常");
}
}
});
// 关闭⽣产者
producer.close();
}
}
2.1.1.3 序列化器

Kafka使⽤
org.apache.kafka.common.serialization.Serializer
接⼝⽤于定义序列化器,将泛型指定类型的数据转换为字节数组。
package org.apache.kafka.common.serialization;
import java.io.Closeable;
import java.util.Map;
/**
将对象转换为byte数组的接⼝
该接⼝的实现类需要提供⽆参构造器
@param <T> 从哪个类型转换
*/
public interface Serializer<T> extends Closeable {
/*
类的配置信息
@param configs key/value pairs
@param isKey key的序列化还是value的序列化
*/
void configure(Map<String, ?> var1, boolean var2);
/*
将对象转换为字节数组
@param topic 主题名称
@param data 需要转换的对象
@return 序列化的字节数组
*/
byte[] serialize(String var1, T var2);
/*
关闭序列化器
该⽅法需要提供幂等性,因为可能调⽤多次。
*/
void close();
}
系统提供了该接⼝的⼦接⼝以及实现类:
org.apache.kafka.common.serialization.ByteArraySerializer
org.apache.kafka.common.serialization.ByteBufferSerializer
org.apache.kafka.common.serialization.BytesSerializer
org.apache.kafka.common.serialization.DoubleSerializer
org.apache.kafka.common.serialization.FloatSerializer
org.apache.kafka.common.serialization.IntegerSerializer
org.apache.kafka.common.serialization.StringSerializer
org.apache.kafka.common.serialization.LongSerializer
org.apache.kafka.common.serialization.ShortSerializer
自定义序列化器
数据的序列化⼀般⽣产中使⽤
avro
。
⾃定义序列化器需要实现
org.apache.kafka.common.serialization.Serializer<T>
接⼝,并实现其中的
serialize
⽅法。
实体类
public class User {
private Integer userId;
private String username;
// set、get方法省略
}
自定义序列化器
public class UserSerializer implements Serializer<User> {
@Override
public void configure(Map<String, ?> map, boolean b) {
// do Nothing
}
@Override
public byte[] serialize(String topic, User user) {
try {
// 如果数据是null,则返回null
if (user == null) return null;
Integer userId = user.getUserId();
String username = user.getUsername();
int length = 0;
byte[] bytes = null;
if (null != username) {
bytes = username.getBytes("utf-8");
length = bytes.length;
}
//userId+username的字节长度+username的字节
ByteBuffer buffer = ByteBuffer.allocate(4 + 4 + length);
buffer.putInt(userId);
buffer.putInt(length);
buffer.put(bytes);
return buffer.array();
} catch (UnsupportedEncodingException e) {
throw new SerializationException("序列化数据异常");
}
}
@Override
public void close() {
// do Nothing
}
}
生产者:
public class MyProducer1 {
public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
Map<String, Object> configs = new HashMap<>();
// 设置连接Kafka的初始连接⽤到的服务器地址
// 如果是集群,则可以通过此初始连接发现集群中的其他broker
configs.put("bootstrap.servers", "192.168.0.102:9092");
// 设置key的序列化器
configs.put("key.serializer", IntegerSerializer.class);
// 设置⾃定义的序列化类
configs.put("value.serializer", UserSerializer.class);
KafkaProducer<Integer, User> producer = new KafkaProducer<>(configs);
User user = new User();
user.setUserId(1);
user.setUsername("自定义序列化");
// ⽤于封装Producer的消息
ProducerRecord<Integer, User> record = new ProducerRecord<>(
"topic_1", // 主题名称
0, // 分区编号
user.getUserId(), // 数字作为key
user // user 对象作为value
);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e == null) {
System.out.println("消息发送成功:" + metadata.topic() + "\t"
+ metadata.partition() + "\t"
+ metadata.offset());
} else {
System.out.println("消息发送异常");
}
}
});
// 关闭⽣产者
producer.close();
}
}
2.1.1.4 分区器
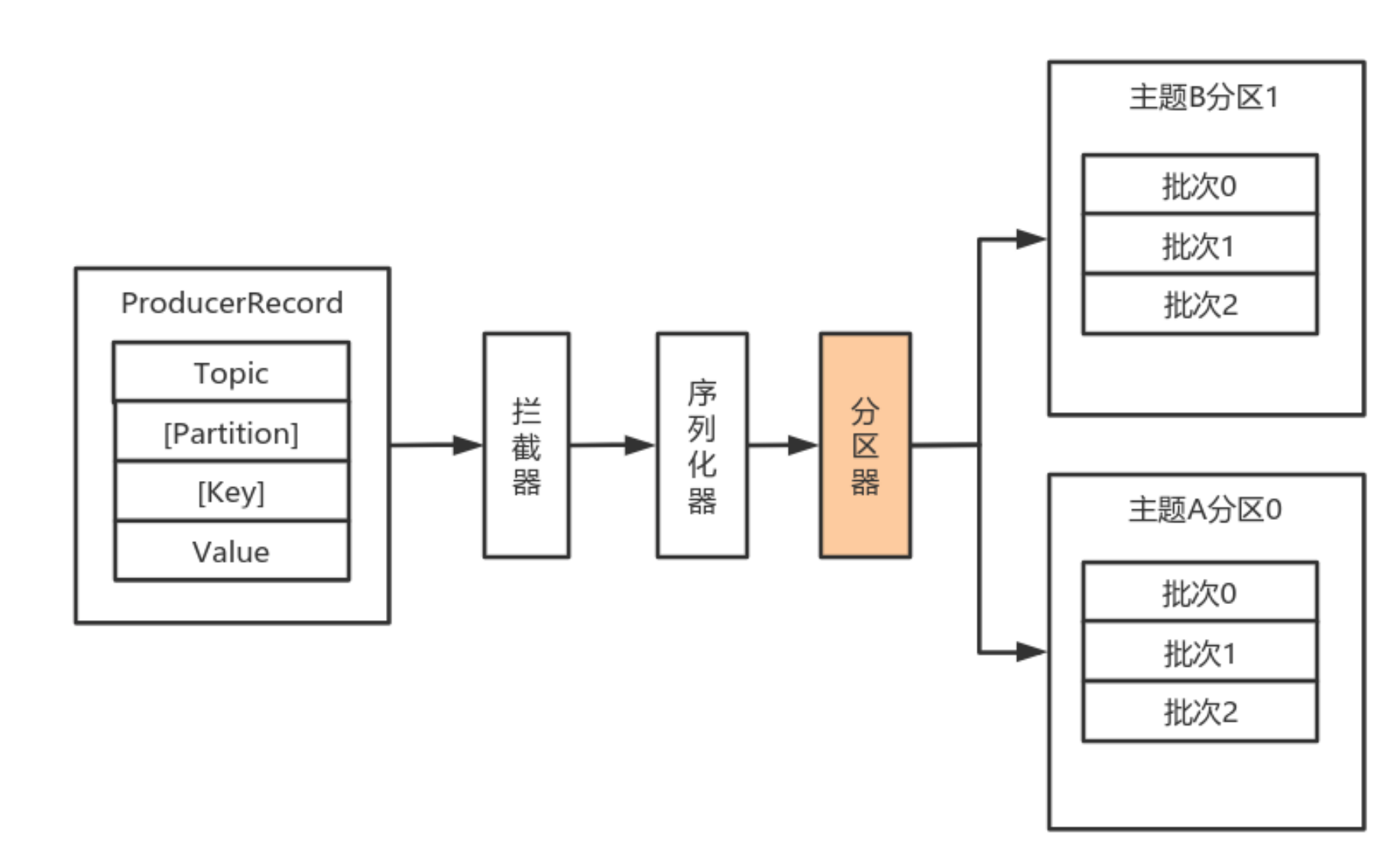
默认(
DefaultPartitioner
)分区计算:
- 如果record提供了分区号,则使⽤record提供的分区号
- 如果record没有提供分区号,则使⽤key的序列化后的值的hash值对分区数量取模
- 如果record没有提供分区号,也没有提供key,则使⽤轮询的⽅式分配分区号。 - 会⾸先在可⽤的分区中分配分区号- 如果没有可⽤的分区,则在该主题所有分区中分配分区号。
Kafka自带的默认分区器(
DefaultPartitioner
):

默认的分区器实现了
Partitioner
接口:
public interface Partitioner extends Configurable, Closeable {
/**
* 为指定的消息记录计算分区值
*
* @param topic 主题名称
* @param key 根据该key的值进⾏分区计算,如果没有则为null
* @param keyBytes key的序列化字节数组,根据该数组进⾏分区计算。如果没有key,则为null
* @param value 根据value值进⾏分区计算,如果没有,则为null
* @param valueBytes value的序列化字节数组,根据此值进⾏分区计算。如果没有,则为null
* @param cluster 当前集群的元数据
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* 关闭分区器的时候调⽤该⽅法
*/
public void close();
}
自定义分区器
- ⾸先开发Partitioner接⼝的实现类
- 在KafkaProducer中进⾏设置:
configs.put("partitioner.class", "xxx.xx.Xxx.class")
实现Partitioner接⼝⾃定义分区器:
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
然后在⽣产者中配置:
configs.put("partitioner.class", "com.edu.config.MyPartitioner");
2.1.2 消息发送原理
原理图解:

由上图可以看出:
KafkaProducer
有两个基本线程:
- 主线程:负责消息创建,拦截器,序列化器,分区器等操作,并将消息追加到消息收集器
RecoderAccumulator中; - 消息收集器RecoderAccumulator为每个分区都维护了⼀个Deque<ProducerBatch>类型的双端队列。-ProducerBatch可以理解为是ProducerRecord的集合,批量发送有利于提升吞吐量,降低⽹络影响;- 由于⽣产者客户端使⽤java.io.ByteBuffer在发送消息之前进⾏消息保存,并维护了⼀个BufferPool实现ByteBuffer的复⽤;该缓存池只针对特定⼤⼩(batch.size指定)的ByteBuffer进⾏管理,对于消息过⼤的缓存,不能做到重复利⽤。- 每次追加⼀条ProducerRecord消息,会寻找/新建对应的双端队列,从其尾部获取⼀个ProducerBatch,判断当前消息的⼤⼩是否可以写⼊该批次中。若可以写⼊则写⼊;若不可以写⼊,则新建⼀个ProducerBatch,判断该消息⼤⼩是否超过客户端参数配置batch.size的值,不超过,则以batch.size建⽴新的ProducerBatch,这样⽅便进⾏缓存重复利⽤;若超过,则以计算的消息⼤⼩建⽴对应的ProducerBatch,缺点就是该内存不能被复⽤了。 Sender线程:该线程从消息收集器获取缓存的消息,将其处理为<Node, List<ProducerBatch>的形式, Node 表示集群的broker节点。- 进⼀步将
<Node, List<ProducerBatch>转化为<Node, Request>形式,此时才可以向服务端发送数据。 - 在发送之前,
Sender线程将消息以Map<NodeId, Deque<Request>>的形式保存到InFlightRequests中进⾏缓存,可以通过其获取leastLoadedNode,即当前Node中负载压⼒最⼩的⼀个,以实现消息的尽快发出。
2.2 消费者
2.2.1 相关概念
2.2.1.1 消费组&消费者
消费者:
- 消费者从订阅的主题消费消息,消费消息的偏移量保存在Kafka的名字是
__consumer_offsets的主题中 - 消费者还可以将⾃⼰的偏移量存储到
Zookeeper,需要设置offset.storage=zookeeper - 推荐使⽤Kafka存储消费者的偏移量。因为Zookeeper不适合⾼并发。
消费组:
- 多个从同⼀个主题消费的消费者可以加⼊到⼀个消费组中
- 消费组中的消费者共享group_id。配置方法:
configs.put("group.id", "xxx"); - group_id⼀般设置为应⽤的逻辑名称。⽐如多个订单处理程序组成⼀个消费组,可以设置group_id为"order_process"
- 消费组均衡地给消费者分配分区,每个分区只由消费组中⼀个消费者消费
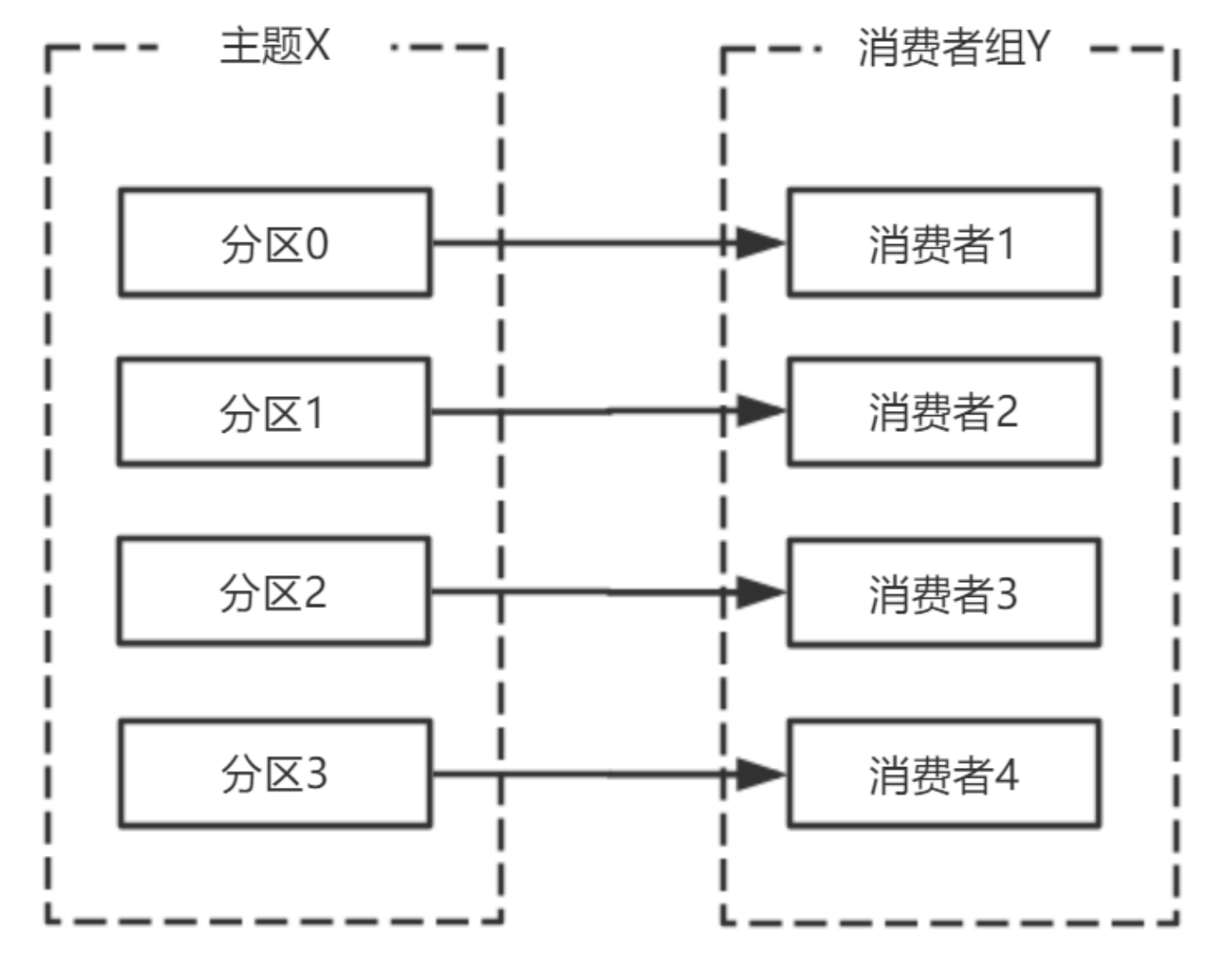
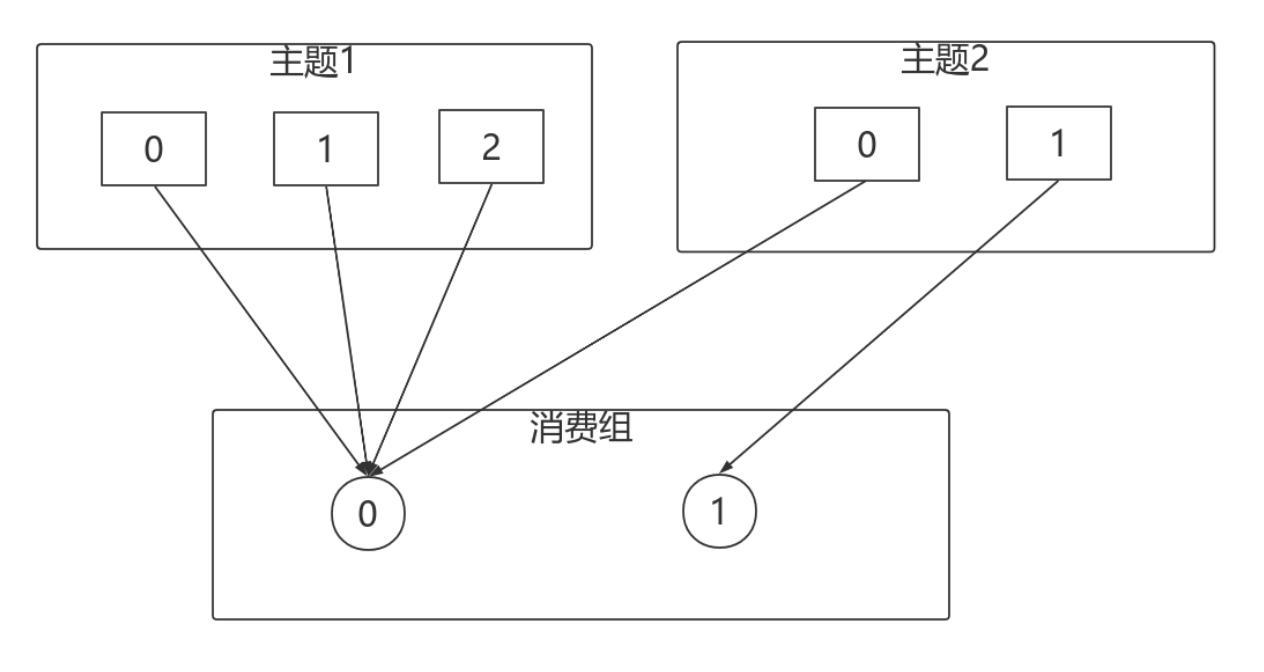
⼀个拥有四个分区的主题,包含⼀个消费者的消费组
此时,消费组中的消费者消费主题中的所有分区。并且没有重复的可能。

如果在消费组中添加⼀个消费者2,则每个消费者分别从两个分区接收消息
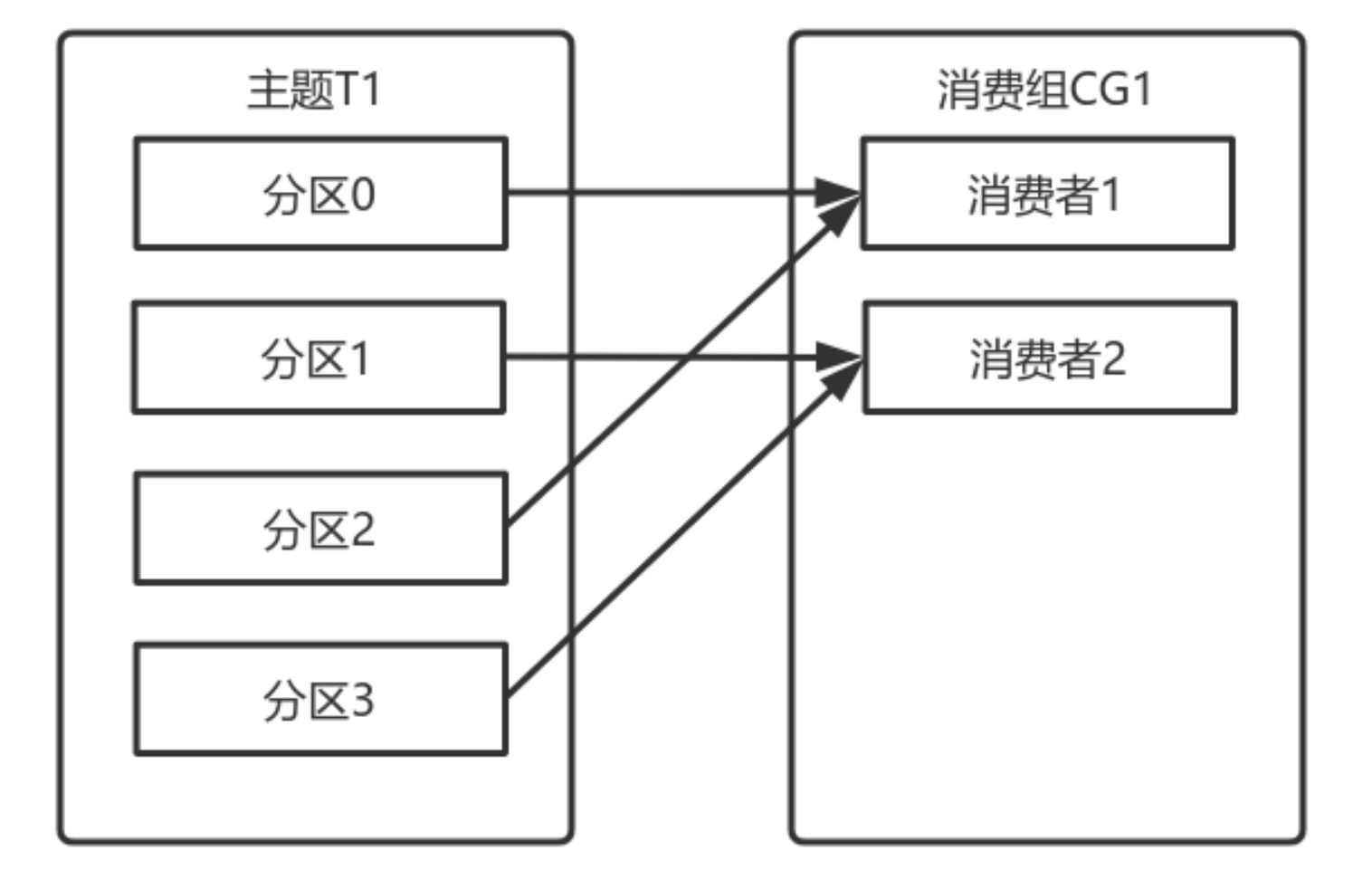
如果消费组有四个消费者,则每个消费者可以分配到⼀个分区

如果向消费组中添加更多的消费者,超过主题分区数量,则有⼀部分消费者就会闲置,不会接收任何消息

向消费组添加消费者是横向扩展消费能⼒的主要⽅式。
必要时,需要为主题创建⼤量分区,在负载增⻓时可以加⼊更多的消费者。但是不要让消费者的数量超过主题分区的数量。

除了通过增加消费者来横向扩展单个应⽤的消费能⼒之外,经常出现多个应⽤程序从同⼀个主题消费的情况。
此时,每个应⽤都可以获取到所有的消息。只要保证每个应⽤都有⾃⼰的消费组,就可以让它们获取到主题所有的消息。
横向扩展消费者和消费组不会对性能造成负⾯影响。
为每个需要获取⼀个或多个主题全部消息的应⽤创建⼀个消费组,然后向消费组添加消费者来横向扩展消费能⼒和应⽤的处理能⼒,则每个消费者只处理⼀部分消息。
2.2.1.2 ⼼跳机制
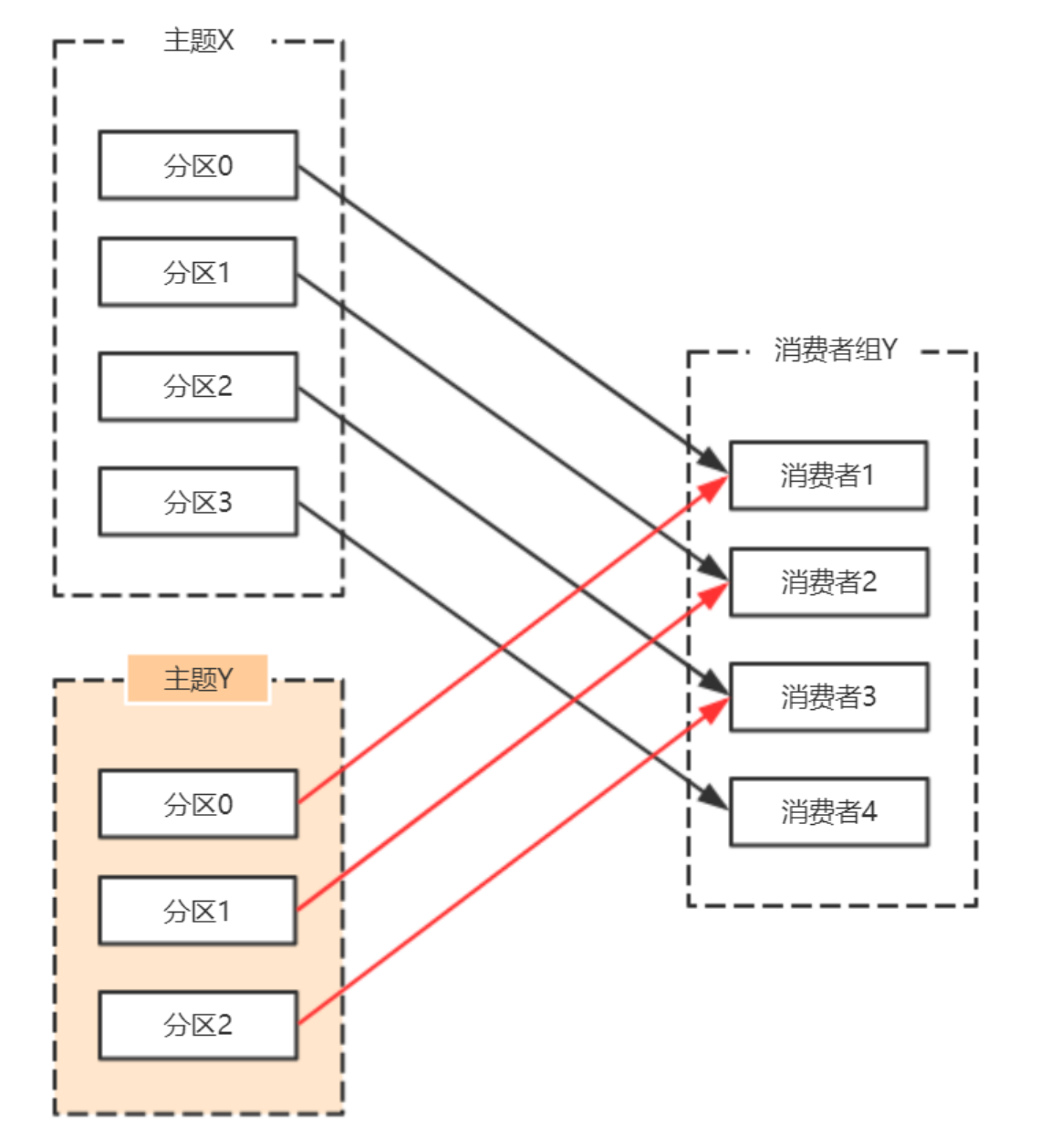
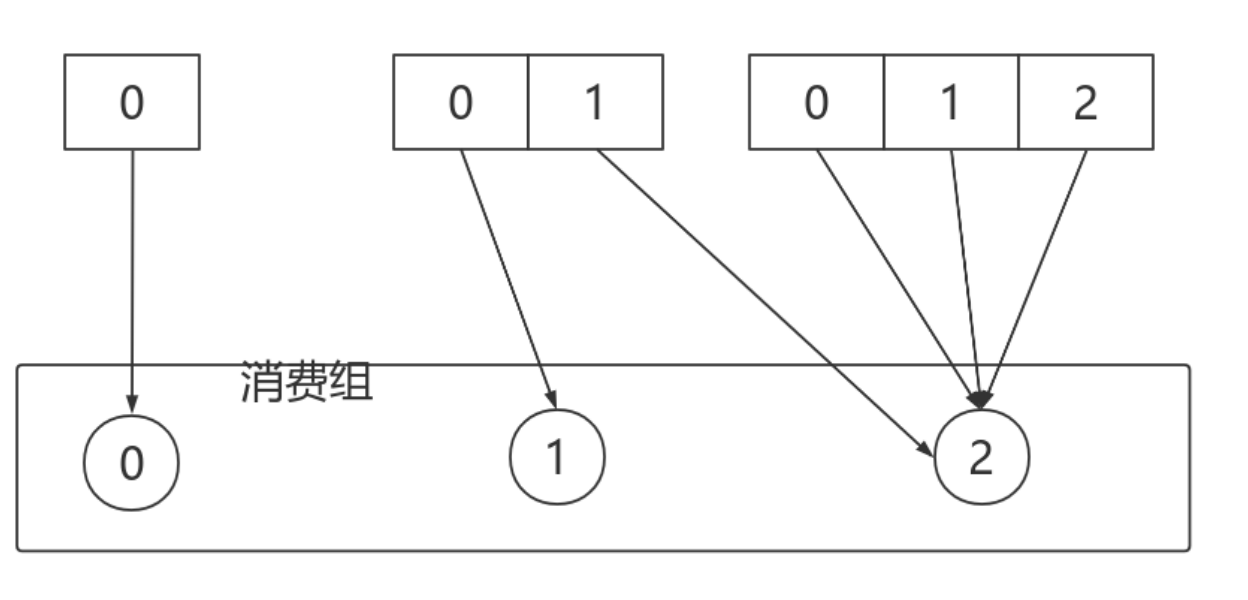
初始的消费者消费分区:
消费者宕机,退出消费组,触发再平衡,重新给消费组中的消费者分配分区

由于broker宕机,主题X的分区3宕机,此时分区3没有Leader副本,触发再平衡,消费者4没有对应的主题分区,则消费者4闲置

Kafka 的⼼跳是 Kafka Consumer 和 Broker 之间的健康检查,只有当 Broker Coordinator 正常时,Consumer 才会发送⼼跳。
Consumer 和 Rebalance 相关的 2 个配置参数:
参数字段session.timeout.msMemberMetadata.sessionTimeoutMsmax.poll.interval.msMemberMetadata.rebalanceTimeoutMs
broker 端,sessionTimeoutMs 参数
broker 处理⼼跳的逻辑在
GroupCoordinator
类中。如果⼼跳超期, broker coordinator 会把消费者从 group 中移除,并触发 rebalance。
可以看看源码的
kafka.coordinator.group.GroupCoordinator#completeAndScheduleNextHeartbeatExpiration
方法。
如果客户端发现⼼跳超期,客户端会标记 coordinator 为不可⽤,并阻塞⼼跳线程;如果超过了 poll 消息的间隔超过了 rebalanceTimeoutMs,则 consumer 告知 broker 主动离开消费组,也会触发 rebalance
可以看看源码的
org.apache.kafka.clients.consumer.internals.AbstractCoordinator.HeartbeatThread
内部类
2.2.2 消息接收
2.2.2.1 常用参数配置
参数说明bootstrap.servers向Kafka集群建⽴初始连接⽤到的host/port列表。 客户端会使⽤这⾥列出的所有服务器进⾏集群其他服务器的发现,⽽不管是否指定了哪个服务器⽤作引导。 这个列表仅影响⽤来发现集群所有服务器的初始主机。 字符串形式:host1:port1,host2:port2,… 由于这组服务器仅⽤于建⽴初始链接,然后发现集群中的所有服务器,因此没有必要将集群中的所有地址写在这⾥。 ⼀般最好两台,以防其中⼀台宕掉。key.deserializerkey的反序列化类,该类需要实现
org.apache.kafka.common.serialization.Deserializer
接⼝。value.deserializer实现了
org.apache.kafka.common.serialization.Deserializer
接⼝的反序列化器,⽤于对消息的value进⾏反序列化。client.id当从服务器消费消息的时候向服务器发送的id字符串。在ip/port基础上提供应⽤的逻辑名称,记录在服务端的请求⽇志中,⽤于追踪请求的源。group.id⽤于唯⼀标志当前消费者所属的消费组的字符串。 如果消费者使⽤组管理功能如subscribe(topic)或使⽤基于Kafka的偏移量管理策略,该项必须设置。auto.offset.reset当Kafka中没有初始偏移量或当前偏移量在服务器中不存在(如,数据被删除了),该如何处理? earliest:⾃动重置偏移量到最早的偏移量 latest:⾃动重置偏移量为最新的偏移量 none:如果消费组原来的(previous)偏移量不存在,则向消费者抛异常 anything:向消费者抛异常enable.auto.commit如果设置为true,消费者会⾃动周期性地向服务器提交偏移量。
2.2.2.2 订阅
Topic:Kafka⽤于分类管理消息的逻辑单元,类似与MySQL的数据库。
Partition:是Kafka下数据存储的基本单元,这个是物理上的概念。同⼀个topic的数据,会被分散的存储到多个partition中,这些partition可以在同⼀台机器上,也可以是在多台机器上。优势在于:有利于⽔平扩展,避免单台机器在磁盘空间和性能上的限制,同时可以通过复制来增加数据冗余性,提⾼容灾能⼒。为了做到均匀分布,通常partition的数量通常是Broker Server数量的整数倍。
Consumer Group:同样是逻辑上的概念,是Kafka实现单播和⼴播两种消息模型的⼿段。保证⼀个消费组获取到特定主题的全部的消息。在消费组内部,若⼲个消费者消费主题分区的消息,消费组可以保证⼀个主题的每个分区只被消费组中的⼀个消费者消费。

consumer 采⽤ pull 模式从 broker 中读取数据。
采⽤ pull 模式,consumer 可⾃主控制消费消息的速率, 可以⾃⼰控制消费⽅式(批量消费/逐条消费),还可以选择不同的提交⽅式从⽽实现不同的传输语义。
订阅主题:
consumer.subscribe(Arrays.asList("tp_demo_01,tp_demo_02"))
2.2.2.3 反序列化
自带反序列化器
Kafka的broker中所有的消息都是字节数组,消费者获取到消息之后,需要先对消息进⾏反序列化处理,然后才能交给⽤户程序消费处理。
常用的Kafka提供的,反序列化器包括key的和value的反序列化器:
- key.deserializer:IntegerDeserializer
- value.deserializer:StringDeserializer
消费者从订阅的主题拉取消息(
consumer.poll(3_000)
)后在Fetcher类中,对拉取到的消息⾸先进⾏反序列化处理:
privateConsumerRecord<K,V>parseRecord(TopicPartition partition,RecordBatch batch,Record record){try{long offset = record.offset();long timestamp = record.timestamp();Optional<Integer> leaderEpoch =this.maybeLeaderEpoch(batch.partitionLeaderEpoch());TimestampType timestampType = batch.timestampType();Headers headers =newRecordHeaders(record.headers());ByteBuffer keyBytes = record.key();byte[] keyByteArray = keyBytes ==null?null:Utils.toArray(keyBytes);K key = keyBytes ==null?null:this.keyDeserializer.deserialize(partition.topic(), headers, keyByteArray);ByteBuffer valueBytes = record.value();byte[] valueByteArray = valueBytes ==null?null:Utils.toArray(valueBytes);V value = valueBytes ==null?null:this.valueDeserializer.deserialize(partition.topic(), headers, valueByteArray);returnnewConsumerRecord(partition.topic(), partition.partition(), offset, timestamp, timestampType, record.checksumOrNull(), keyByteArray ==null?-1: keyByteArray.length, valueByteArray ==null?-1: valueByteArray.length, key, value, headers, leaderEpoch);}catch(RuntimeException var17){thrownewSerializationException("Error deserializing key/value for partition "+ partition +" at offset "+ record.offset()+". If needed, please seek past the record to continue consumption.", var17);}}
Kafka默认提供了⼏个反序列化的实现:
org.apache.kafka.common.serialization.ByteArrayDeserializer
org.apache.kafka.common.serialization.ByteBufferDeserializer
org.apache.kafka.common.serialization.BytesDeserializer
org.apache.kafka.common.serialization.DoubleDeserializer
org.apache.kafka.common.serialization.FloatDeserializer
org.apache.kafka.common.serialization.IntegerDeserializer
org.apache.kafka.common.serialization.LongDeserializer
org.apache.kafka.common.serialization.ShortDeserializer
org.apache.kafka.common.serialization.StringDeserializer
自定义反序列化器
反序列化器都需要实现
org.apache.kafka.common.serialization.Deserializer<T>
接⼝:
publicclassUserDeserializerimplementsDeserializer<User>{@Overridepublicvoidconfigure(Map<String,?> configs,boolean isKey){// do Nothing}@OverridepublicUserdeserialize(String topic,byte[] data){ByteBuffer allocate =ByteBuffer.allocate(data.length);
allocate.put(data);
allocate.flip();int userId = allocate.getInt();int length = allocate.getInt();String userName =newString(data,8, length);returnnewUser(userId, userName);}@Overridepublicvoidclose(){// do Nothing}}
消费者使用自定义反序列化器:
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,UserDeserializer.class);
2.2.2.4 拦截器
消费者在拉取了分区消息之后,要⾸先经过反序列化器对key和value进⾏反序列化处理。
处理完之后,如果消费端设置了拦截器,则需要经过拦截器的处理之后,才能返回给消费者应⽤程序进⾏处理。
消费端定义消息拦截器,需要实现
org.apache.kafka.clients.consumer.ConsumerInterceptor<K, V>
接⼝。
- ⼀个可插拔接⼝,允许拦截甚⾄更改消费者接收到的消息。⾸要的⽤例在于将第三⽅组件引⼊消费者应⽤程序,⽤于定制的监控、⽇志处理等.
- 该接⼝的实现类通过
configre⽅法获取消费者配置的属性,如果消费者配置中没有指定clientID,还可以获取KafkaConsumer⽣成的clientId。获取的这个配置是跟其他拦截器共享的,需要保证不会在各个拦截器之间产⽣冲突。 ConsumerInterceptor⽅法抛出的异常会被捕获、记录,但是不会向下传播。如果⽤户配置了错误的key或value类型参数,消费者不会抛出异常,⽽仅仅是记录下来。ConsumerInterceptor回调发⽣在org.apache.kafka.clients.consumer.KafkaConsumer#poll(long)⽅法同⼀个线程
该接⼝中有如下⽅法:
public interface ConsumerInterceptor<K, V> extends Configurable {
/**
* 该⽅法在poll⽅法返回之前调⽤。调⽤结束后poll⽅法就返回消息了。
*
* 该⽅法可以修改消费者消息,返回新的消息。拦截器可以过滤收到的消息或⽣成新的消息。
* 如果有多个拦截器,则该⽅法按照KafkaConsumer的configs中配置的顺序调⽤。
*
* @param records 由上个拦截器返回的由客户端消费的消息。
*/
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);
/**
* 当消费者提交偏移量时,调⽤该⽅法
* 该⽅法抛出的任何异常调⽤者都会忽略。
*/
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);
/**
* This is called when interceptor is closed
*/
public void close();
}
代码实现
自定义一个消费者拦截器:
public class OneInterceptor implements ConsumerInterceptor<String, String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {
// poll⽅法返回结果之前最后要调⽤的⽅法
System.out.println("自定义消费者拦截器,消息回来啦");
// 消息不做处理,直接返回
return records;
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {
// 消费者提交偏移量的时候,经过该⽅法
System.out.println("自定义消费者拦截器,要提交偏移量啦");
}
@Override
public void close() {
// ⽤于关闭该拦截器⽤到的资源,如打开的⽂件,连接的数据库等
}
@Override
public void configure(Map<String, ?> configs) {
// ⽤于获取消费者的设置参数
configs.forEach((k, v) -> {
System.out.println(k + "\t" + v);
});
}
}
按照
OneInterceptor
拦截器复制两个拦截器,更名为
TwoInterceptor
、
ThreeInterceptor
消费者使用自定义拦截器:
config.setProperty(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,com.edu.config.interceptor.OneInterceptor,com.edu.config.interceptor.TwoInterceptor,com.edu.config.interceptor.ThreeInterceptor);
2.2.2.5 位移提交
位移提交介绍:
- Consumer需要向Kafka记录⾃⼰的位移数据,这个汇报过程称为提交位移(
Committing Offsets) - Consumer 需要为分配给它的每个分区提交各⾃的位移数据
- 位移提交的由Consumer端负责的,Kafka只负责保管。
__consumer_offsets - 位移提交分为⾃动提交和⼿动提交
- 位移提交分为同步提交和异步提交
位移自动提交
Kafka Consumer 后台提交
- 开启⾃动提交:
enable.auto.commit=true - 配置⾃动提交间隔:Consumer端:
auto.commit.interval.ms,默认 5s
在消费者中设置自动提交和自动提交间隔:
Map<String,Object> configs =newHashMap<>();
configs.put("bootstrap.servers","192.168.0.102:9092");
configs.put("group.id","mygrp");// 设置偏移量⾃动提交。⾃动提交是默认值。这⾥做示例。
configs.put("enable.auto.commit","true");// 偏移量⾃动提交的时间间隔
configs.put("auto.commit.interval.ms","3000");
configs.put("key.deserializer",StringDeserializer.class);
configs.put("value.deserializer",StringDeserializer.class);KafkaConsumer<String,String> consumer =newKafkaConsumer<String,String>(configs);
Kafka会保证在开始调⽤poll⽅法时,提交上次poll返回的所有消息,因此⾃动提交不会出现消息丢失,但会重复消费
重复消费举例:
- Consumer 每 5s 提交 offset
- 假设提交 offset 后的 3s 发⽣了 Rebalance
- Rebalance 之后的所有 Consumer 从上⼀次提交的 offset 处继续消费
- 因此 Rebalance 发⽣前 3s 的消息会被重复消费
位移手动同步提交
- 使⽤
KafkaConsumer#commitSync():会提交KafkaConsumer#poll()返回的最新 offset - 该⽅法为同步操作,等待直到 offset 被成功提交才返回
- commitSync 在处理完所有消息之后
- ⼿动同步提交可以控制offset提交的时机和频率
while(true){ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1));process(records);// 处理消息 try{
consumer.commitSync();}catch(CommitFailedException e){handle(e);// 处理提交失败异常 }}
⼿动同步提交会:
- 调⽤ commitSync 时,Consumer 处于阻塞状态,直到 Broker 返回结果
- 会影响 TPS
- 可以选择拉⻓提交间隔,但有以下问题 - 会导致 Consumer 的提交频率下降- Consumer 重启后,会有更多的消息被消费
位移手动异步提交
KafkaConsumer#commitAsync()
while(true){ConsumerRecords<String,String> records = consumer.poll(3_000);process(records);// 处理消息
consumer.commitAsync((offsets, exception)->{if(exception !=null){handle(exception);}});}
- commitAsync出现问题不会⾃动重试
手动异步提交不会自动重试的解决方案:
try{while(true){ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1));process(records);// 处理消息 commitAysnc();// 使⽤异步提交规避阻塞 }}catch(Exception e){handle(e);// 处理异常}finally{try{
consumer.commitSync();// 最后⼀次提交使⽤同步阻塞式提交}finally{
consumer.close();}}
2.2.2.6 位移管理
Kafka中,消费者根据消息的位移顺序消费消息。
消费者的位移由消费者管理,可以存储于zookeeper中,也可以存储于Kafka主题
__consumer_offsets
中。
Kafka提供了消费者API,让消费者可以管理⾃⼰的位移。
KafkaConsumer<K, V>
的 API如下:
public void assign(Collection<TopicPartition> partitions): 给当前消费者⼿动分配⼀系列主题分区。 ⼿动分配分区不⽀持增量分配,如果先前有分配分区,则该操作会覆盖之前的分配。 如果给出的主题分区是空的,则等价于调⽤unsubscribe⽅法。 ⼿动分配主题分区的⽅法不使⽤消费组管理功能。当消费组成员变了,或者集群或主题的元数据改变了,不会触发分区分配的再平衡。 ⼿动分区分配assign(Collection)不能和⾃动分区分配subscribe(Collection,ConsumerRebalanceListener)⼀起使⽤。 如果启⽤了⾃动提交偏移量,则在新的分区分配替换旧的分区分配之前,会对旧的分区分配中的消费偏移量进⾏异步提交。public Set<TopicPartition> assignment(): 获取给当前消费者分配的分区集合。如果订阅是通过调⽤assign⽅法直接分配主题分区,则返回相同的集合。如果使⽤了主题订阅,该⽅法返回当前分配给该消费者的主题分区集合。如果分区订阅还没开始进⾏分区分配,或者正在重新分配分区,则会返回none。public Map<String, List<PartitionInfo>> listTopics(): 获取对⽤户授权的所有主题分区元数据。该⽅法会对服务器发起远程调⽤。public List<PartitionInfo> partitionsFor(String topic): 获取指定主题的分区元数据。如果当前消费者没有关于该主题的元数据,就会对服务器发起远程调⽤。public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions): 对于给定的主题分区,列出它们第⼀个消息的偏移量。 注意,如果指定的分区不存在,该⽅法可能会永远阻塞。 该⽅法不改变分区的当前消费者偏移量。public void seekToEnd(Collection<TopicPartition> partitions): 将偏移量移动到每个给定分区的最后⼀个。 该⽅法延迟执⾏,只有当调⽤过poll⽅法或position⽅法之后才可以使⽤。 如果没有指定分区,则将当前消费者分配的所有分区的消费者偏移量移动到最后。 如果设置了隔离级别为:isolation.level=read_committed,则会将分区的消费偏移量移动到最后⼀个稳定的偏移量,即下⼀个要消费的消息现在还是未提交状态的事务消息。public void seek(TopicPartition partition, long offset)说明: 将给定主题分区的消费偏移量移动到指定的偏移量,即当前消费者下⼀条要消费的消息偏移量。 若该⽅法多次调⽤,则最后⼀次的覆盖前⾯的。 如果在消费中间随意使⽤,可能会丢失数据。public long position(TopicPartition partition): 检查指定主题分区的消费偏移量public void seekToBeginning(Collection<TopicPartition> partitions): 将给定每个分区的消费者偏移量移动到它们的起始偏移量。该⽅法懒执⾏,只有当调⽤过poll⽅法或position⽅法之后才会执⾏。如果没有提供分区,则将所有分配给当前消费者的分区消费偏移量移动到起始偏移量。
API 实战:
/**
* 消费者位移管理
*/publicclassMyConsumer2{publicstaticvoidmain(String[] args){Map<String,Object> config =newHashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.0.102:9092");
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
config.put(ConsumerConfig.GROUP_ID_CONFIG,"myGroup");KafkaConsumer<String,String> consumer =newKafkaConsumer<String,String>(config);// 给当前消费者⼿动分配⼀系列主题分区
consumer.assign(Arrays.asList(newTopicPartition("tp_demo_01",1)));// 获取给当前消费者分配的分区集合Set<TopicPartition> assignment = consumer.assignment();
assignment.forEach(topicPartition ->System.out.println(topicPartition));// 获取对⽤户授权的所有主题分区元数据。该⽅法会对服务器发起远程调⽤Map<String,List<PartitionInfo>> stringListMap = consumer.listTopics();
stringListMap.forEach((k, v)->{System.out.println("主题:"+ k);
v.forEach(info ->System.out.println(info));});Set<String> strings = consumer.listTopics().keySet();
strings.forEach(topicName ->System.out.println(topicName));// 获取指定主题的分区元数据List<PartitionInfo> partitionInfos = consumer.partitionsFor("tp_demo_01");for(PartitionInfo partitionInfo : partitionInfos){Node leader = partitionInfo.leader();System.out.println(leader);System.out.println(partitionInfo);// 当前分区在线副本Node[] nodes = partitionInfo.inSyncReplicas();// 当前分区下线副本Node[] nodes1 = partitionInfo.offlineReplicas();}// 对于给定的主题分区,列出它们第⼀个消息的偏移量。// 注意,如果指定的分区不存在,该⽅法可能会永远阻塞。// 该⽅法不改变分区的当前消费者偏移量。Map<TopicPartition,Long> topicPartitionLongMap = consumer.beginningOffsets(consumer.assignment());
topicPartitionLongMap.forEach((k, v)->{System.out.println("主题:"+ k.topic()+"\t分区:"+ k.partition()+"偏移量\t"+ v);});// 将偏移量移动到每个给定分区的最后⼀个。
consumer.seekToEnd(consumer.assignment());//将给定主题分区的消费偏移量移动到指定的偏移量,即当前消费者下⼀条要消费的消息偏移量。
consumer.seek(newTopicPartition("tp_demo_01",1),10);// 检查指定主题分区的消费偏移量long position = consumer.position(newTopicPartition("tp_demo_01",1));System.out.println(position);// 将偏移量移动到每个给定分区的最后⼀个。
consumer.seekToEnd(Arrays.asList(newTopicPartition("tp_demo_01",1)));// 关闭⽣产者
consumer.close();}}
2.2.2.7 重平衡
重平衡介绍
重平衡可以说是kafka为⼈诟病最多的⼀个点了。
重平衡其实就是⼀个协议,它规定了如何让消费者组下的所有消费者来分配topic中的每⼀个分区。⽐如⼀个topic有100个分区,⼀个消费者组内有20个消费者,在协调者的控制下让组内每⼀个消费者分配到5个分区,这个分配的过程就是重平衡。
如何进行组内分区分配:
三种分配策略:
RangeAssignor
和
RoundRobinAssignor
以及
StickyAssignor
谁来执⾏重均衡和消费组管理:
Kafka提供了⼀个⻆⾊:Group Coordinator来执⾏对于消费组的管理。
Group Coordinator——每个消费组分配⼀个消费组协调器(是一个broker)⽤于组管理和位移管理。当消费组的第⼀个消费者启动的时候,它会去和Kafka Broker确定谁是它们组的组协调器。之后该消费组内所有消费者和该组协调器协调通信。
如何确定coordinator:
- 确定消费组位移信息写⼊
__consumers_offsets的哪个分区。具体计算公式: _consumers_offsets partition# = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount) 注意:groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,默认是50个分区。 - 该分区leader所在的broker就是组协调器。
重平衡的触发条件主要有三个:
- 消费者组内成员发⽣变更,这个变更包括了增加和减少消费者,⽐如消费者宕机退出消费组。
- 主题的分区数发⽣变更,kafka⽬前只⽀持增加分区,当增加的时候就会触发重平衡
- 订阅的主题发⽣变化,当消费者组使⽤正则表达式订阅主题,⽽恰好⼜新建了对应的主题,就会触发重平衡

消费者宕机,退出消费组,触发再平衡,重新给消费组中的消费者分配分区。

由于broker宕机,主题X的分区3宕机,此时分区3没有Leader副本,触发再平衡,消费者4没有对应的主题分区,则消费者4闲置

主题增加分区,需要主题分区和消费组进⾏再均衡。

由于使⽤正则表达式订阅主题,当增加的主题匹配正则表达式的时候,也要进⾏再均衡。
Rebalance Generation:
它表示Rebalance之后主题分区到消费组中消费者映射关系的⼀个版本,主要是⽤于保护消费组,隔离⽆效偏移量提交的。如上⼀个版本的消费者⽆法提交位移到新版本的消费组中,因为映射关系变了,你消费的或许已经不是原来的那个分区了。每次group进⾏Rebalance之后,Generation号都会加1,表示消费组和分区的映射关系到了⼀个新版本,如下图所示: Generation 1时group有3个成员,随后成员2退出组,消费组协调器触发Rebalance,消费组进⼊Generation 2,之后成员4加⼊,再次触发Rebalance,消费组进⼊Generation 3.

协议(protocol)
kafka提供了5个协议来处理与消费组协调相关的问题:
- Heartbeat请求:consumer需要定期给组协调器发送⼼跳来表明⾃⼰还活着
- LeaveGroup请求:主动告诉组协调器我要离开消费组
- SyncGroup请求:消费组Leader把分配⽅案告诉组内所有成员
- JoinGroup请求:成员请求加⼊组
- DescribeGroup请求:显示组的所有信息,包括成员信息,协议名称,分配⽅案,订阅信息等。通常该请求是给管理员使⽤
组协调器在再均衡的时候主要⽤到了前⾯4种请求。
liveness
消费者如何向消费组协调器证明⾃⼰还活着?
通过定时向消费组协调器发送Heartbeat请求。如果超过了设定的超时时间,那么协调器认为该消费者已经挂了。⼀旦协调器认为某个消费者挂了,那么它就会开启新⼀轮再均衡,并且在当前其他消费者的⼼跳响应中添加
“REBALANCE_IN_PROGRESS”
,告诉其他消费者:重新分配分区。
重平衡过程
重平衡分为2步:Join和Sync
- Join, 加⼊组。所有成员都向消费组协调器发送JoinGroup请求,请求加⼊消费组。⼀旦所有成员都发送了JoinGroup请求,协调器从中选择⼀个消费者担任Leader的⻆⾊,并把组成员信息以及订阅信息发给Leader。
- Sync,Leader开始分配消费⽅案,即哪个消费者负责消费哪些主题的哪些分区。⼀旦完成分配,Leader会将这个⽅案封装进SyncGroup请求中发给消费组协调器,⾮Leader也会发SyncGroup请求,只是内容为空。消费组协调器接收到分配⽅案之后会把⽅案塞进SyncGroup的response中发给各个消费者。

注意:在协调器收集到所有成员请求前,它会把已收到请求放⼊⼀个叫purgatory(炼狱)的地⽅。然后是分发分配⽅案的过程,即SyncGroup请求:

注意:消费组的分区分配⽅案在客户端执⾏。Kafka交给客户端可以有更好的灵活性。Kafka默认提供三种分配策略:range和round-robin和sticky。可以通过消费者的参数: partition.assignment.strategy 来实现⾃⼰分配策略。
消费组状态机
消费组组协调器根据状态机对消费组做不同的处理:
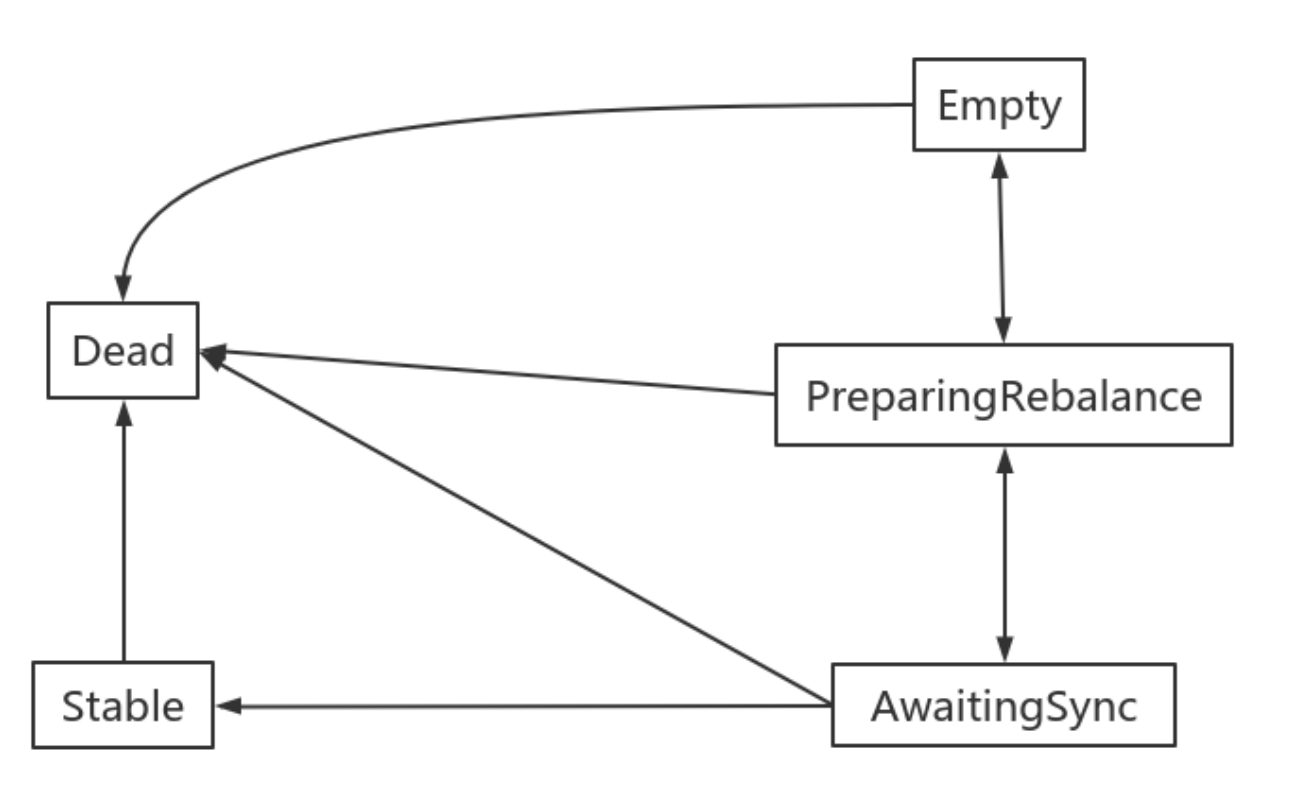
说明:
- Dead:组内已经没有任何成员的最终状态,组的元数据也已经被组协调器移除了。这种状态响应各种请求都是⼀个response: UNKNOWN_MEMBER_ID
- Empty:组内⽆成员,但是位移信息还没有过期。这种状态只能响应JoinGroup请求
- PreparingRebalance:组准备开启新的rebalance,等待成员加⼊
- AwaitingSync:正在等待leader consumer将分配⽅案传给各个成员
- Stable:再均衡完成,可以开始消费。
避免重平衡
为什么说重平衡为⼈诟病呢?因为重平衡过程中,消费者⽆法从kafka消费消息,这对kafka的TPS影响极⼤,⽽如果kafka集群内节点较多,⽐如数百个,那重平衡可能会耗时极多。数分钟到数⼩时都有可能,⽽这段时间kafka基本处于不可⽤状态。所以在实际环境中,应该尽量避免重平衡发⽣。
不可能完全避免重平衡,因为你⽆法完全保证消费者不会故障。⽽消费者故障其实也是最常⻅的引发重平衡的地⽅,所以我们需要保证尽⼒避免消费者故障。
⽽其他⼏种触发重平衡的⽅式,增加分区,或是增加订阅的主题,抑或是增加消费者,更多的是主动控制。
如果消费者真正挂掉了,就没办法了,但实际中,会有⼀些情况,kafka错误地认为⼀个正常的消费者已经挂掉了,我们要的就是避免这样的情况出现。
⾸先要知道哪些情况会出现错误判断挂掉的情况。
在分布式系统中,通常是通过⼼跳来维持分布式系统的,kafka也不例外。
在分布式系统中,由于⽹络问题你不清楚没接收到⼼跳,是因为对⽅真正挂了还是只是因为负载过重没来得及发⽣⼼跳或是⽹络堵塞。所以⼀般会约定⼀个时间,超时即判定对⽅挂了。**⽽在kafka消费者场景中,
session.timout.ms
参数就是规定这个超时时间是多少**。
还有⼀个参数,**
heartbeat.interval.ms
,这个参数控制发送⼼跳的频率**,频率越⾼越不容易被误判,但也会消耗更多资源。
此外,还有最后⼀个参数,
max.poll.interval.ms
,消费者poll数据后,需要⼀些处理,再进⾏拉取。如果两次拉取时间间隔超过这个参数设置的值,那么消费者就会被踢出消费者组。也就是说,拉取,然后处理,这个处理的时间不能超过
max.poll.interval.ms
这个参数的值。这个参数的默认值是5分钟,⽽如果消费者接收到数据后会执⾏耗时的操作,则应该将其设置得⼤⼀些。
总结:
session.timout.ms控制⼼跳超时时间。heartbeat.interval.ms控制⼼跳发送频率。max.poll.interval.ms控制poll的间隔。
这⾥给出⼀个相对较为合理的配置,如下:
session.timout.ms:设置为6sheartbeat.interval.ms:设置2smax.poll.interval.ms:推荐为消费者处理消息最⻓耗时再加1分钟
2.2.3 消费组管理
2.2.3.1 消费者组的概念
consumer group是kafka提供的可扩展且具有容错性的消费者机制。
三个特性:
- 消费组有⼀个或多个消费者,消费者可以是⼀个进程,也可以是⼀个线程
group.id是⼀个字符串,唯⼀标识⼀个消费组- 对于一个消费组,其订阅的主题的每个分区只能被消费组中的⼀个消费者消费。
- 不同的消费组的消费者可以消费同一个主题的分区
2.2.3.2 消费者位移(consumer position)
消费者在消费的过程中记录已消费的数据,即消费位移(offset)信息。
每个消费组保存⾃⼰的位移信息,那么只需要简单的⼀个整数表示位置就够了;同时可以引⼊checkpoint机制定期持久化。
2.2.3.3 位移管理(offset management)
⾃动VS⼿动
Kafka默认定期⾃动提交位移(
enable.auto.commit
= true),也⼿动提交位移。另外kafka会定期把group消费情况保存起来,做成⼀个offset map,如下图所示:

位移提交
位移是提交到Kafka中的
__consumer_offsets
主题。
__consumer_offsets
中的消息保存了每个消费组某⼀时刻提交的offset信息。
__consumers_offsets 主题配置了compact策略,使得它总是能够保存最新的位移信息,既控制了该topic总体的⽇志容量,也能实现保存最新offset的⽬的。
2.3 主题
使⽤
kafka-topics.sh
脚本时可用的配置:
选项说明–config <String: name=value>为创建的或修改的主题指定配置信息。⽀持下述配置条⽬:
cleanup.policy``compression.type``delete.retention.ms``file.delete.delay.ms``flush.messages``flush.ms``follower.replication.throttled.replicas``index.interval.bytes``leader.replication.throttled.replicas``max.message.bytes``message.format.version``message.timestamp.difference.max.ms``message.timestamp.type``min.cleanable.dirty.ratio``min.compaction.lag.ms``min.insync.replicas``preallocate``retention.bytes``retention.ms``segment.bytes``segment.index.bytes``segment.jitter.ms``segment.ms``unclean.leader.election.enable
–create创建⼀个新主题–delete删除⼀个主题–delete-config <String: name>删除现有主题的⼀个主题配置条⽬。这些条⽬就是在
--config
中给出的配置条⽬。–alter更改主题的分区数量,副本分配和/或配置条⽬。–describe列出给定主题的细节–disable-rack-aware禁⽤副本分配的机架感知。–force抑制控制台提示信息–help打印帮助信息–if-exists如果指定了该选项,则在修改或删除主题的时候,只有主题存在才可以执⾏。–if-not-exists在创建主题的时候,如果指定了该选项,则只有主题不存在的时候才可以执⾏命令。–list列出所有可⽤的主题。–partitions <Integer: # of partitions>要创建或修改主题的分区数。–replica-assignment <String:broker_id_for_part1_replica1 :broker_id_for_part1_replica2,broker_id_for_part2_replica1 :broker_id_for_part2_replica2 , …>当创建或修改主题的时候⼿动指定partition-to-broker的分配关系。–replication-factor <Integer:replication factor>要创建的主题分区副本数。1表示只有⼀个副本,也就是Leader副本。–topic <String: topic>要创建、修改或描述的主题名称。除了创建,修改和描述在这⾥还可以使⽤正则表达式。–topics-with-overridesif set when describing topics, only show topics that haveoverridden configs–unavailable-partitionsif set when describing topics, only show partitions whoseleader is not available–under-replicated-partitionsif set when describing topics, only show under replicatedpartitions–zookeeper <String: urls>必需的参数:连接zookeeper的字符串,逗号分隔的多个host:port列表。多个URL可以故障转移。
主题中可以使⽤的参数定义(也就是上面
--config <String: name=value>
的参数):
属性默认值服务器默认属性说明cleanup.policydeletelog.cleanup.policy要么是”delete“要么是”compact“; 这个字符串指明了针对旧⽇志部分的利⽤⽅式;默认⽅式(“delete”)将会丢弃旧的部分当他们的回收时间或者尺⼨限制到达时。”compact“将会进⾏⽇志压缩compression.typenoneproducer⽤于压缩数据的压缩类型。默认是⽆压缩。正确的选项值是none、gzip、snappy。压缩最好⽤于批量处理,批量处理消息越多,压缩性能越好。delete.retention.ms86400000(24hours)log.cleaner.delete.retention.ms对于压缩⽇志保留的最⻓时间,也是客户端消费消息的最⻓时间,通log.retention.minutes的区别在于⼀个控制未压缩数据,⼀个控制压缩后的数据。此项配置可以在topic创建时的置顶参数覆盖flush.msNonelog.flush.interval.ms此项配置⽤来置顶强制进⾏fsync⽇志到磁盘的时间间隔;例如,如果设置为1000,那么每1000ms就需要进⾏⼀次fsync。⼀般不建议使⽤这个选项flush.messagesNonelog.flush.interval.messages此项配置指定时间间隔:强制进⾏fsync⽇志。例如,如果这个选项设置为1,那么每条消息之后都需要进⾏fsync,如果设置为5,则每5条消息就需要进⾏⼀次fsync。⼀般来说,建议你不要设置这个值。此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡.如果此值过⼤,将会导致每次"fsync"的时间较⻓(IO阻塞),如果此值过⼩,将会导致"fsync"的次数较多,这也意味着整体的client请求有⼀定的延迟.物理server故障,将会导致没有fsync的消息丢失.index.interval.bytes4096log.index.interval.bytes默认设置保证了我们每4096个字节就对消息添加⼀个索引,更多的索引使得阅读的消息更加靠近,但是索引规模却会由此增⼤;⼀般不需要改变这个选项max.message.bytes1000000max.message.byteskafka追加消息的最⼤尺⼨。注意如果你增⼤这个尺⼨,你也必须增⼤你consumer的fetch 尺⼨,这样consumer才能fetch到这些最⼤尺⼨的消息。min.cleanable.dirty.ratio0.5min.cleanable.dirty.ratio此项配置控制log压缩器试图进⾏清除⽇志的频率。默认情况下,将避免清除压缩率超过50%的⽇志。这个⽐率避免了最⼤的空间浪费min.insync.replicas1min.insync.replicas当producer设置request.required.acks为-1时,min.insync.replicas指定replicas的最⼩数⽬(必须确认每⼀个repica的写数据都是成功的),如果这个数⽬没有达到,producer会产⽣异常。retention.bytesNonelog.retention.bytes如果使⽤“delete”的retention 策略,这项配置就是指在删除⽇志之前,⽇志所能达到的最⼤尺⼨。默认情况下,没有尺⼨限制⽽只有时间限制retention.ms7 dayslog.retention.minutes如果使⽤“delete”的retention策略,这项配置就是指删除⽇志前⽇志保存的时间。segment.bytes1Glog.segment.byteskafka中log⽇志是分成⼀块块存储的,此配置是指log⽇志划分成块的⼤⼩segment.index.bytes10MBlog.index.size.max.bytes此配置是有关offsets和⽂件位置之间映射的索引⽂件的⼤⼩;⼀般不需要修改这个配置segment.jitter.ms0log.roll.jitter.{ms,hours}The maximum jitter to subtract from logRollTimeMillis.segment.ms7 dayslog.roll.hours即使log的分块⽂件没有达到需要删除、压缩的⼤⼩,⼀旦log 的时间达到这个上限,就会强制新建⼀个log分块⽂件unclean.leader.election.enabletrue指明了是否能够使不在ISR中replicas设置⽤来作为leader
2.3.1 主题操作
创建主题
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_02 --partitions 2 --replication-factor 1
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_03 --partitions 3 --replication-factor 1 --config max.message.bytes=1048576 --config segment.bytes=10485760
查看主题
kafka-topics.sh --zookeeper localhost:2181/myKafka --list
kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic tp_demo_02
kafka-topics.sh --zookeeper localhost:2181/myKafka --topics-with-overrides --describe
修改主题
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_04 --partitions 4 --replication-factor 1
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic tp_demo_04 --config max.message.bytes=1048576
kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic tp_demo_04
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic tp_demo_04 --config segment.bytes=10485760
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --delete-config max.message.bytes --topic tp_demo_04
删除主题
kafka-topics.sh --zookeeper localhost:2181/myKafka --delete --topic tp_demo_01
2.3.2 添加分区
通过命令⾏⼯具操作,主题的分区只能增加,不能减少。否则报错
通过–alter修改主题的分区数,增加分区。
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic tp_demo_02 --partitions 3
2.3.3 KafkaAdminClient 应用
说明:
除了使⽤Kafka的bin⽬录下的脚本⼯具来管理Kafka,还可以使⽤管理Kafka的API将某些管理查看的功能集成到系统中。在Kafka0.11.0.0版本之前,可以通过kafka-core包(Kafka的服务端,采⽤Scala编写)中的AdminClient和AdminUtils来实现部分的集群管理操作。Kafka0.11.0.0之后,⼜多了⼀个AdminClient,在kafka-client包下,⼀个抽象类,具体的实现是
org.apache.kafka.clients.admin.KafkaAdminClient
。
功能与原理介绍
Kafka官⽹:The AdminClient API supports managing and inspecting topics, brokers, acls, and other Kafka objects
KafkaAdminClient包含了⼀下⼏种功能(以Kafka1.0.2版本为准):
- 创建主题
createTopics(final Collection<NewTopic> newTopics, final CreateTopicsOptions options) - 删除主题
deleteTopics(final Collection<String> topicNames, DeleteTopicsOptions options) - 列出所有主题
listTopics(final ListTopicsOptions options) - 查询主题
describeTopics(final Collection<String> topicNames, DescribeTopicsOptions options) - 查询集群信息
describeCluster(DescribeClusterOptions options) - 查询配置信息
describeConfigs(Collection<ConfigResource> configResources, final DescribeConfigsOptions options) - 修改配置信息
alterConfigs(Map<ConfigResource, Config> configs, final AlterConfigsOptions options) - 修改副本的日志记录
alterReplicaLogDirs(Map<TopicPartitionReplica, String> replicaAssignment, final AlterReplicaLogDirsOptions options) - 查询节点的⽇志⽬录信息
describeLogDirs(Collection<Integer> brokers, DescribeLogDirsOptions options) - 查询副本的⽇志⽬录信息
describeReplicaLogDirs(Collection<TopicPartitionReplica> replicas, DescribeReplicaLogDirsOptions options) - 增加分区
createPartitions(Map<String, NewPartitions> newPartitions, final CreatePartitionsOptions options)
其内部原理是使⽤Kafka⾃定义的⼀套⼆进制协议来实现,详细可以参⻅Kafka协议。
KafkaAdminClient
⽤到的参数:
属性说明重要性bootstrap.servers向Kafka集群建⽴初始连接⽤到的host/port列表。 客户端会使⽤这⾥列出的所有服务器进⾏集群其他服务器的发现,⽽不管是否指定了哪个服务器⽤作引导。 这个列表仅影响⽤来发现集群所有服务器的初始主机。 字符串形式:host1:port1,host2:port2,… 由于这组服务器仅⽤于建⽴初始链接,然后发现集群中的所有服务器,因此没有必要将集群中的所有地址写在这⾥。 ⼀般最好两台,以防其中⼀台宕掉。highclient.id⽣产者发送请求的时候传递给broker的id字符串。 ⽤于在broker的请求⽇志中追踪什么应⽤发送了什么消息。 ⼀般该id是跟业务有关的字符串。mediumconnections.max.idle.ms当连接空闲时间达到这个值,就关闭连接。long型数据,默认:300000mediumreceive.buffer.bytesTCP接收缓存(SO_RCVBUF),如果设置为-1,则使⽤操作系统默认的值。int类型值,默认65536,可选值:[-1,…]mediumrequest.timeout.ms客户端等待服务端响应的最⼤时间。如果该时间超时,则客户端要么重新发起请求,要么如果重试耗尽,请求失败。int类型值,默认:120000mediumsecurity.protocol跟broker通信的协议:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.string类型值,默认:PLAINTEXTmediumsend.buffer.bytes⽤于TCP发送数据时使⽤的缓冲⼤⼩(SO_SNDBUF),-1表示使⽤OS默认的缓冲区⼤⼩。 int类型值,默认值:131072mediumreconnect.backoff.max.ms对于每个连续的连接失败,每台主机的退避将成倍增加,直⾄达到此最⼤值。在计算退避增量之后,添加20%的随机抖动以避免连接⻛暴。 long型值,默认1000,可选值:[0,…]lowreconnect.backoff.ms重新连接主机的等待时间。避免了重连的密集循环。该等待时间应⽤于该客户端到broker的所有连接。 long型值,默认:50lowretriesThe maximum number of times to retry a call before failing it.重试的次数,达到此值,失败。 int类型值,默认5。lowretry.backoff.ms在发⽣失败的时候如果需要重试,则该配置表示客户端等待多⻓时间再发起重试。 该时间的存在避免了密集循环。 long型值,默认值:100。low
主要操作步骤:
客户端根据⽅法的调⽤创建相应的协议请求,⽐如创建Topic的createTopics⽅法,其内部就是发送CreateTopicRequest请求。
客户端发送请求⾄Kafka Broker。
Kafka Broker处理相应的请求并回执,⽐如与CreateTopicRequest对应的是CreateTopicResponse。客户端接收相应的回执并进⾏解析处理。
和协议有关的请求和回执的类基本都在org.apache.kafka.common.requests包中,AbstractRequest和AbstractResponse是这些请求和响应类的两个⽗类。
综上,如果要⾃定义实现⼀个功能,只需要三个步骤:
- ⾃定义XXXOptions;
- ⾃定义XXXResult返回值;
- ⾃定义Call,然后挑选合适的XXXRequest和XXXResponse来实现Call类中的3个抽象⽅法。
2.3.4 偏移量管理
Kafka 1.0.2,__consumer_offsets主题中保存各个消费组的偏移量。
早期由zookeeper管理消费组的偏移量。
查询⽅法:
通过原⽣ kafka 提供的⼯具脚本进⾏查询。
⼯具脚本的位置与名称为bin/kafka-consumer-groups.sh
⾸先运⾏脚本,查看帮助:
参数说明–all-topics将所有关联到指定消费组的主题都划归到reset-offsets操作范围。–bootstrap-server<String:server to connectto>必须:(基于消费组的新的消费者): 要连接的服务器地址。–by-duration<String: duration>距离当前时间戳的⼀个时间段。格式:‘PnDTnHnMnS’–commandconfig<String:command configproperty file>指定配置⽂件,该⽂件内容传递给Admin Client和消费者。–delete传值消费组名称,删除整个消费组与所有主题的各个分区偏移量和所有者关系。 如:–group g1 --group g2。 传值消费组名称和单个主题,仅删除该消费组到指定主题的分区偏移量和所属关系。 如:–group g1 --group g2 --topic t1。 传值⼀个主题名称,仅删除指定主题与所有消费组分区偏移量以及所属关系。 如:–topic t1 注意:消费组的删除仅对基于ZK保存偏移量的消费组有效,并且要⼩⼼使⽤,仅删除不活跃的消费组。–describe描述给定消费组的偏移量差距(有多少消息还没有消费)。–execute执⾏操作。⽀持的操作:reset-offsets。–export导出操作的结果到CSV⽂件。⽀持的操作:reset-offsets。–from-file<String: path toCSV file>重置偏移量到CSV⽂件中定义的值。–group <String:consumer group>⽬标消费组–list列出所有消费组。–new-consumer使⽤新的消费者实现。这是默认值。随后的发⾏版中会删除这⼀操作。–reset-offsets重置消费组的偏移量。当前⼀次操作只⽀持⼀个消费组,并且该消费组应该是不活跃的。 有三个操作选项 1.(默认)plan:要重置哪个偏移量。 2. execute:执⾏reset-offsets操作。 3. process:配合–export将操作结果导出到CSV格式。 可以使⽤如下选项: --to-datetime --by-period --to-earliest --to-latest --shift-by --from-file --to-current 必须选择⼀个选项使⽤。 要定义操作的范围,使⽤: --all-topics --topic。 必须选择⼀个,除⾮使⽤–from-file选项。–shift-by<Long: number-of-offsets>重置偏移量n个。n可以是正值,也可以是负值。–timeout<Long: timeout(ms)>对某些操作设置超时时间。 如:对于描述指定消费组信息,指定毫秒值的最⼤等待时间,以获取正常数据(如刚创建的消费组,或者消费组做了⼀些更改操作)。默认时间:5000。–to-current重置到当前的偏移量。–to-datetime<String: datetime>重置偏移量到指定的时间戳。格式:‘YYYY-MM-DDTHH:mm:SS.sss’–to-earliest重置为最早的偏移量–to-latest重置为最新的偏移量–to-offset<Long: offset>重置到指定的偏移量。
--topic<String:topic>
指定哪个主题的消费组需要删除,或者指定哪个主题的消费组需要包含到resetoffsets操作中。对于reset-offsets操作,还可以指定分区:topic1:0,1,2。其中0,1,2表示要包含到操作中的分区号。重置偏移量的操作⽀持多个主题⼀起操作。–zookeeper<String: urls>必须,它的值,你懂的。–zookeeper localhost:2181/myKafka。
由于kafka 消费者记录group的消费偏移量有两种⽅式 :
- kafka ⾃维护 (新)
- zookpeer 维护 (旧) ,已经逐渐被废弃
所以 ,脚本只查看由broker维护的,由zookeeper维护的可以将–bootstrap-server换成–zookeeper即可。
查看有那些 group ID 正在进⾏消费
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
注意:
- 这⾥⾯是没有指定 topic,查看的是所有topic消费者的 group.id 的列表。
- 注意: 重名的 group.id 只会显示⼀次
**查看指定group.id 的消费者消费情况 **
kafka-consumer-groups.sh --bootstrap-server node1:9092 --describe --group group
2.4 分区
2.4.1 副本机制

Kafka在⼀定数量的服务器上对主题分区进⾏复制。
当集群中的⼀个broker宕机后系统可以⾃动故障转移到其他可⽤的副本上,不会造成数据丢失。
创建主题:
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_02 --partitions 2 --replication-factor 31.
上面创建主题中的
--replication-factor 3
表示有3个副本,1个Leader + 2个 Follower
- 将复制因⼦为1的未复制主题称为复制主题。
- 主题的分区是复制的最⼩单元。
- 在⾮故障情况下,Kafka中的每个分区都有⼀个Leader副本和零个或多个Follower副本。
- 包括Leader副本在内的副本总数构成复制因⼦。
- 所有读取和写⼊都由Leader副本负责。
- 通常,分区⽐broker多,并且Leader分区在broker之间平均分配
Follower分区像普通的Kafka消费者⼀样,消费来⾃Leader分区的消息,并将其持久化到⾃⼰的⽇志中。
允许Follower对⽇志条⽬拉取进⾏批处理。
同步节点定义:
- 节点必须能够维持与ZooKeeper的会话(通过ZooKeeper的⼼跳机制)
- 对于Follower副本分区,它复制在Leader分区上的写⼊,并且不要延迟太多
Kafka提供的保证是,只要有⾄少⼀个同步副本处于活动状态,提交的消息就不会丢失。
宕机如何恢复:
- 少部分副本宕机 当leader宕机了,会从follower选择⼀个作为leader。当宕机的重新恢复时,会把之前commit的数据清空,重新从leader⾥pull数据。
- 全部副本宕机 当全部副本宕机了有两种恢复⽅式 - 等待ISR中的⼀个恢复后,并选它作为leader。(等待时间较⻓,降低可⽤性)- 选择第⼀个恢复的副本作为新的leader,⽆论是否在ISR中。(并未包含之前leader commit的数据,因此造成数据丢失)
2.4.2 Leader 选举
如下图,在这张图片中:
- 分区P1的Leader是0,ISR是0和1
- 分区P2的Leader是2,ISR是1和2
- 分区P3的Leader是1,ISR是0,1,2。

⽣产者和消费者的请求都由Leader副本来处理。Follower副本只负责消费Leader副本的数据和Leader保持同步。
对于P1,如果0宕机会发⽣什么?
Leader副本和Follower副本之间的关系并不是固定不变的,在Leader所在的broker发⽣故障的时候,就需要进⾏分区的Leader副本和Follower副本之间的切换,需要选举Leader副本。
如何选举?
如果某个分区所在的服务器除了问题,不可⽤,kafka会从该分区的其他的副本中选择⼀个作为新的Leader。之后所有的读写就会转移到这个新的Leader上。现在的问题是应当选择哪个作为新的Leader。
只有那些跟Leader保持同步的Follower才应该被选作新的Leader。
Kafka会在Zookeeper上针对每个Topic维护⼀个称为ISR(in-sync replica,已同步的副本)的集合,该集合中是⼀些分区的副本。
只有当这些副本都跟Leader中的副本同步了之后,kafka才会认为消息已提交,并反馈给消息的⽣产者。
如果这个集合有增减,kafka会更新zookeeper上的记录。
如果某个分区的Leader不可⽤,Kafka就会从ISR集合中选择⼀个副本作为新的Leader。
显然通过ISR,kafka需要的冗余度较低,可以容忍的失败数⽐较⾼。
假设某个分区有N+1个副本,kafka可以容忍N个服务器不可⽤。
为什么不⽤少数服从多数的⽅法
少数服从多数是⼀种⽐较常⻅的⼀致性算发和Leader选举法。
它的含义是只有超过半数的副本同步了,系统才会认为数据已同步;
选择Leader时也是从超过半数的同步的副本中选择。
这种算法需要较⾼的冗余度,跟Kafka⽐起来,浪费资源。
譬如只允许⼀台机器失败,需要有三个副本;⽽如果只容忍两台机器失败,则需要五个副本。
⽽kafka的ISR集合⽅法,分别只需要两个和三个副本。
如果所有的ISR副本都失败了怎么办?
此时有两种⽅法可选:
- 等待ISR集合中的副本复活,
- 选择任何⼀个⽴即可⽤的副本,⽽这个副本不⼀定是在ISR集合中。
- 需要设置
unclean.leader.election.enable=true
这两种⽅法各有利弊,实际⽣产中按需选择。
如果要等待ISR副本复活,虽然可以保证⼀致性,但可能需要很⻓时间。⽽如果选择⽴即可⽤的副本,则很可能该副本并不⼀致。
总结:
Kafka中Leader分区选举,通过维护⼀个动态变化的ISR集合来实现,⼀旦Leader分区丢掉,则从ISR中随机挑选⼀个副本做新的Leader分区。
如果ISR中的副本都丢失了,则:
- 可以等待ISR中的副本任何⼀个恢复,接着对外提供服务,需要时间等待。
- 从OSR中选出⼀个副本做Leader副本,此时会造成数据丢失
2.4.3 分区重新分配
向已经部署好的Kafka集群⾥⾯添加机器,我们需要从已经部署好的Kafka节点中复制相应的配置⽂件,然后把⾥⾯的broker id修改成全局唯⼀的,最后启动这个节点即可将它加⼊到现有Kafka集群中(同一个集群中所有节点的ClusterId相同)。
问题:新添加的Kafka节点并不会⾃动地分配数据,⽆法分担集群的负载,除⾮我们新建⼀个topic。
需要⼿动将部分分区移到新添加的Kafka节点上,Kafka内部提供了相关的⼯具来重新分布某个topic的分区。
**使⽤Kafka⾃带的
kafka-reassign-partitions.sh
⼯具来重新分布分区。该⼯具有三种使⽤模式:**
- generate模式,给定需要重新分配的Topic,⾃动⽣成reassign plan(并不执⾏)
- execute模式,根据指定的reassign plan重新分配Partition
- verify模式,验证重新分配Partition是否成功
借助kafka-reassign-partitions.sh⼯具⽣成reassign plan,需要先定义⼀个⽂件,⾥⾯说明哪些topic需要重新分区,⽂件内容如下
[root@node1 ~]# cat topics-to-move.json
{
"topics": [
{ "topic":"tp_re_01" }
],
"version":1
}
然后使⽤kafka-reassign-partitions.sh⼯具⽣成reassign plan
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --topicsto-move-json-file topics-to-move.json --broker-list "0,1" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas":[1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas":[1],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Proposed partition reassignment configuration下⾯⽣成的就是将分区重新分布的结果。
将这些内容保存到名为result.json⽂件⾥⾯(⽂件名不重要,⽂件格式也不⼀定要以json为结尾,只要保证内容是json即可),replicas就是对应分区的brokerId,如果不符合要求可以自己修改
然后执⾏这些reassign plan:
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file topics-to-execute.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"tp_re_01","partition":4,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":1,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":2,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":3,"replicas":[0],"log_dirs":["any"]},{"topic":"tp_re_01","partition":0,"replicas":[0],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
2.4.4 自动再平衡
可以在新建主题的时候,⼿动指定主题各个Leader分区以及Follower分区的分配情况,即什么分区副本在哪个broker节点上
执⾏脚本:
[root@node11 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --create --topic tp_demo_03 --replica-assignment "0:1,1:0,0:1"
上述脚本执⾏的结果是:创建了主题tp_demo_03,有三个分区,每个分区两个副本,Leader副本在列表中第⼀个指定的brokerId上,Follower副本在随后指定的brokerId上。
但是当0号机宕机后,所有Leader分区都会在1号上,当0号机重启后,Leader分区还是都会在1号上
随着系统的运⾏,broker的宕机重启,会引发Leader分区和Follower分区的⻆⾊转换,最后可能Leader⼤部分都集中在少数⼏台broker上,由于Leader负责客户端的读写操作,此时集中Leader分区的少数⼏台服务器的⽹络I/O,CPU,以及内存都会很紧张。
Kafka提供的⾃动再均衡脚本:
kafka-preferred-replica-election.sh
可以让Kafka⾃动帮我们让集群恢复到初始的副本分配
该⼯具会让每个分区的Leader副本分配在合适的位置,让Leader分区和Follower分区在服务器之间均衡分配。
如果该脚本仅指定zookeeper地址,则会对集群中所有的主题进⾏操作,⾃动再平衡。
具体操作:
- 创建preferred-replica.json,内容如下:
{
"partitions": [
{
"topic":"tp_demo_03",
"partition":0
},
{
"topic":"tp_demo_03",
"partition":1
},
{
"topic":"tp_demo_03",
"partition":2
}
]
}
- 执⾏操作:
[root@node1 ~]# kafka-preferred-replica-election.sh --zookeeper node1:2181/myKafka --path-to-json-file preferred-replicas.json
- 查看操作的结果
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_demo_03
Topic:tp_demo_03 PartitionCount:3 ReplicationFactor:2 Configs:
Topic: tp_demo_03 Partition: 0 Leader: 0 Replicas: 0,1 Isr: 1,0
Topic: tp_demo_03 Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: tp_demo_03 Partition: 2 Leader: 0 Replicas: 0,1 Isr: 1,0
[root@node1 ~]#1.2.3.4.5.6.
恢复到最初的分配情况。
2.4.5 修改分区副本
实际项⽬中,我们可能由于主题的副本因⼦设置的问题,需要重新设置副本因⼦
或者由于集群的扩展,需要重新设置副本因⼦。
topic⼀旦使⽤⼜不能轻易删除重建,因此动态增加副本因⼦就成为最终的选择。
说明:kafka 1.0版本配置⽂件默认没有default.replication.factor=x, 因此如果创建topic时,不指定-replication-factor 默认副本因⼦为1. 我们可以在⾃⼰的server.properties中配置上常⽤的副本因⼦,省去⼿动调整。例如设置default.replication.factor=3, 详细内容可参考官⽅⽂档https://kafka.apache.org/documentation/#replication
原因分析:
假设我们有2个kafka broker分别broker0,broker1。
- 当我们创建的topic有2个分区partition时并且replication-factor为1,基本上⼀个broker上⼀个分区。当⼀个broker宕机了,该topic就⽆法使⽤了,因为两个分区只有⼀个能⽤。
- 当我们创建的topic有3个分区partition时并且replication-factor为2时,可能分区数据分布情况是 broker0, partiton0,partiton1,partiton2, broker1, partiton1,partiton0,partiton2, 每个分区有⼀个副本,当其中⼀个broker宕机了,kafka集群还能完整凑出该topic的两个分区,例如当broker0宕机了,可以通过broker1组合出topic的两个分区。
- 创建主题
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --create --topic tp_re_02 --partitions 3 --replication-factor 1
- 查看主题细节
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_re_02
Topic:tp_re_02 PartitionCount:3 ReplicationFactor:1 Configs:
Topic: tp_re_02 Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: tp_re_02 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: tp_re_02 Partition: 2 Leader: 1 Replicas: 1 Isr: 1
使⽤
kafka-reassign-partitions.sh
修改副本因⼦:
- 创建increment-replication-factor.json
{
"version":1,
"partitions":[
{"topic":"tp_re_02","partition":0,"replicas":[0,1]},
{"topic":"tp_re_02","partition":1,"replicas":[0,1]},
{"topic":"tp_re_02","partition":2,"replicas":[1,0]}
]
}
- 执⾏分配
[root@node1 ~]# kafka-reassign-partitions.sh --zookeeper node1:2181/myKafka --reassignment-json-file increase-replication-factor.json --execute
- 查看主题细节
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --describe --topic tp_re_02
Topic:tp_re_02 PartitionCount:3 ReplicationFactor:2 Configs:
Topic: tp_re_02 Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1,0
Topic: tp_re_02 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: tp_re_02 Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
2.4.6 分区分配策略
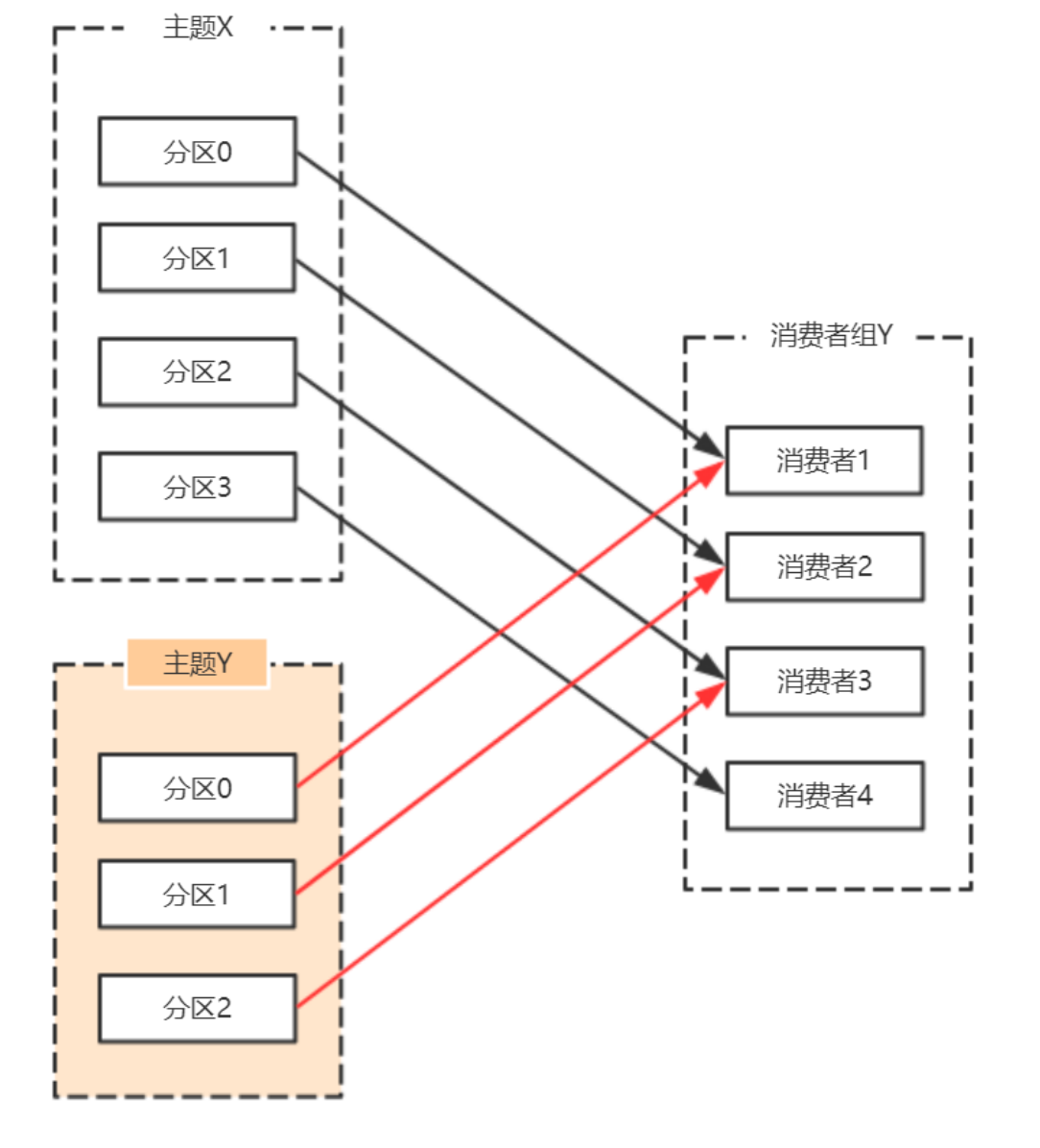
在Kafka中,每个Topic会包含多个分区,默认情况下⼀个分区只能被⼀个消费组下⾯的⼀个消费者消费,这⾥就产⽣了分区分配的问题。Kafka中提供了多重分区分配算法(PartitionAssignor)的实现:RangeAssignor、RoundRobinAssignor、StickyAssignor。
消费组的成员订阅它们感兴趣的Topic并将这种订阅关系传递给作为订阅组协调者的Broker。协调者选择其中的⼀个消费者来执⾏这个消费组的分区分配并将分配结果转发给消费组内所有的消费者。Kafka默认采⽤RangeAssignor的分配算法。
2.4.6.1 RangeAssignor
RangeAssignor对每个Topic进⾏独⽴的分区分配。对于每⼀个Topic,⾸先对分区按照分区ID进⾏数值排序,然后订阅这个Topic的消费组的消费者再进⾏字典排序,之后尽量均衡的将分区分配给消费者。这⾥只能是尽量均衡,因为分区数可能⽆法被消费者数量整除,那么有⼀些消费者就会多分配到⼀些分区。

⼤致算法如下:
assign(topic, consumers) {
// 对分区和Consumer进⾏排序
List<Partition> partitions = topic.getPartitions();
sort(partitions);
sort(consumers);
// 计算每个Consumer分配的分区数
int numPartitionsPerConsumer = partition.size() / consumers.size();
// 额外有⼀些Consumer会多分配到分区
int consumersWithExtraPartition = partition.size() % consumers.size();
// 计算分配结果
for (int i = 0, n = consumers.size(); i < n; i++) {
// 第i个Consumer分配到的分区的index
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
// 第i个Consumer分配到的分区数
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
// 分装分配结果
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
RangeAssignor策略的原理是按照消费者总数和分区总数进⾏整除运算来获得⼀个跨度,然后将分区按照跨度进⾏平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每⼀个Topic,RangeAssignor策略会将消费组内所有订阅这个Topic的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配⼀个分区。
这种分配⽅式明显的⼀个问题是随着消费者订阅的Topic的数量的增加,不均衡的问题会越来越严重,⽐如上图中4个分区3个消费者的场景,C0会多分配⼀个分区。如果此时再订阅⼀个分区数为4的Topic,那么C0⼜会⽐C1、C2多分配⼀个分区,这样C0总共就⽐C1、C2多分配两个分区了,⽽且随着Topic的增加,这个情况会越来越严重。
字典序靠前的消费组中的消费者⽐较“贪婪”。

2.4.6.2 RoundRobinAssignor
RoundRobinAssignor的分配策略是将消费组内订阅的所有Topic的分区及所有消费者进⾏排序后尽量均衡的分配(RangeAssignor是针对单个Topic的分区进⾏排序分配的)。如果消费组内,消费者订阅的Topic列表是相同的(每个消费者都订阅了相同的Topic),那么分配结果是尽量均衡的(消费者之间分配到的分区数的差值不会超过1)。如果订阅的Topic列表是不同的,那么分配结果是不保证“尽量均衡”的,因为某些消费者不参与⼀些Topic的分配。

相对于RangeAssignor,在订阅多个Topic的情况下,RoundRobinAssignor的⽅式能消费者之间尽量均衡的分配到分区(分配到的分区数的差值不会超过1——RangeAssignor的分配策略可能随着订阅的Topic越来越多,差值越来越⼤)。
对于消费组内消费者订阅Topic不⼀致的情况:假设有两个个消费者分别为C0和C1,有2个Topic T1、T2,分别拥有3和2个分区,并且C0订阅T1和T2,C1订阅T2,那么RoundRobinAssignor的分配结果如下:
看上去分配已经尽量的保证均衡了,不过可以发现C0承担了4个分区的消费⽽C1订阅了T2⼀个分区,是不是把T2P0交给C1消费能更加的均衡呢?
2.4.6.3 StickyAssignor
动机
尽管RoundRobinAssignor已经在RangeAssignor上做了⼀些优化来更均衡的分配分区,但是在⼀些情况下依旧会产⽣严重的分配偏差,⽐如消费组中订阅的Topic列表不相同的情况下。
更核⼼的问题是⽆论是RangeAssignor,还是RoundRobinAssignor,当前的分区分配算法都没有考虑上⼀次的分配结果。显然,在执⾏⼀次新的分配之前,如果能考虑到上⼀次分配的结果,尽量少的调整分区分配的变动,显然是能节省很多开销的。
目标
从字⾯意义上看,Sticky是“粘性的”,可以理解为分配结果是带“粘性的”:
- 分区的分配尽量的均衡
- 每⼀次重分配的结果尽量与上⼀次分配结果保持⼀致
当这两个⽬标发⽣冲突时,优先保证第⼀个⽬标。第⼀个⽬标是每个分配算法都尽量尝试去完成的,⽽第⼆个⽬标才真正体现出StickyAssignor特性的。
我们先来看预期分配的结构,后续再具体分析StickyAssignor的算法实现。
例如:
- 有3个Consumer:C0、C1、C2
- 有4个Topic:T0、T1、T2、T3,每个Topic有2个分区
- 所有Consumer都订阅了这4个主题
StickyAssignor的分配结果如下图所示(增加RoundRobinAssignor分配作为对⽐):

如果消费者1宕机,则按照RoundRobin的⽅式分配结果如下。打乱从新来过,轮询分配:

按照Sticky的⽅式。仅对消费者1分配的分区进⾏重分配,红线部分。最终达到均衡的⽬的:

再举⼀个例⼦:
- 有3个Consumer:C0、C1、C2
- 3个Topic:T0、T1、T2,它们分别有1、2、3个分区
- C0订阅T0;C1订阅T0、T1;C2订阅T0、T1、T2
分配结果如下图所示
消费者0下线,则按照轮询的⽅式分配:

按照Sticky⽅式分配分区,仅仅需要动的就是红线部分,其他部分不动

StickyAssignor分配⽅式的实现稍微复杂点⼉,我们可以先理解图示部分即可。感兴趣的同学可以研究⼀下。
2.4.6.4 自定义分区策略
PartitionAssignor接⼝⽤于⽤户定义实现分区分配算法,以实现Consumer之间的分区分配。
⾃定义的分配策略必须要实现org.apache.kafka.clients.consumer.internals.PartitionAssignor接⼝。PartitionAssignor接⼝的定义如下:
Subscriptionsubscription(Set<String> topics);Stringname();Map<String,Assignment>assign(Cluster metadata,Map<String,Subscription> subscriptions);voidonAssignment(Assignment assignment);classSubscription{privatefinalList<String> topics;privatefinalByteBuffer userData;}classAssignment{privatefinalList<TopicPartition> partitions;privatefinalByteBuffer userData;}
PartitionAssignor接⼝中定义了两个内部类:Subscription和Assignment。
Subscription类⽤来表示消费者的订阅信息,类中有两个属性:topics和userData,分别表示消费者所订阅topic列表和⽤户⾃定义信息。PartitionAssignor接⼝通过subscription()⽅法来设置消费者⾃身相关的Subscription信息,注意到此⽅法中只有⼀个参数topics,与Subscription类中的topics的相互呼应,但是并没有有关userData的参数体现。为了增强⽤户对分配结果的控制,可以在subscription()⽅法内部添加⼀些影响分配的⽤户⾃定义信息赋予userData,⽐如:权重、ip地址、host或者机架(rack)等等。
Assignment类,它是⽤来表示分配结果信息的,类中也有两个属性:partitions和userData,分别表示所分配到的分区集合和⽤户⾃定义的数据。可以通过PartitionAssignor接⼝中的onAssignment()⽅法是在每个消费者收到消费组leader分配结果时的回调函数,例如在StickyAssignor策略中就是通过这个⽅法保存当前的分配⽅案,以备在下次消费组重平衡(rebalance)时可以提供分配参考依据。
接⼝中的name()⽅法⽤来提供分配策略的名称,对于Kafka提供的3种分配策略⽽⾔,RangeAssignor对应的protocol_name为“range”,RoundRobinAssignor对应的protocol_name为“roundrobin”,StickyAssignor对应的protocol_name为“sticky”,所以⾃定义的分配策略中要注意命名的时候不要与已存在的分配策略发⽣冲突。这个命名⽤来标识分配策略的名称。
真正的分区分配⽅案的实现是在assign()⽅法中,⽅法中的参数metadata表示集群的元数据信息,⽽subscriptions表示消费组内各个消费者成员的订阅信息,最终⽅法返回各个消费者的分配信息。
Kafka中还提供了⼀个抽象类org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor,它可以简化PartitionAssignor接⼝的实现,对assign()⽅法进⾏了实现,其中会将Subscription中的userData信息去掉后,在进⾏分配。Kafka提供的3种分配策略都是继承⾃这个抽象类。如果开发⼈员在⾃定义分区分配策略时需要使⽤userData信息来控制分区分配的结果,那么就不能直接继承AbstractPartitionAssignor这个抽象类,⽽需要直接实现PartitionAssignor接⼝。
自定义分区策略
packageorg.apache.kafka.clients.consumer;importorg.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor;importorg.apache.kafka.common.TopicPartition;importjava.util.*;publicclassMyAssignorextendsAbstractPartitionAssignor{}
在使⽤时,消费者客户端需要添加相应的Properties参数,示例如下:
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,MyAssignor.class.getName());
2.5 存储
2.5.1 日志存储
2.5.1.1 日志概念
Kafka 消息是以主题为单位进⾏归类,各个主题之间是彼此独⽴的,互不影响;每个主题⼜可以分为⼀个或多个分区;每个分区各⾃存在⼀个记录消息数据的⽇志⽂件。
如果创建了⼀个 demo_01 主题,其存在6个 Parition,对应到物理文件在日志路径下就有demo_01-0、demo_01-1、demo_01-2、demo_01-3、demo_01-4、demo_01-5 六个分区文件
在理想情况下,数据流量分摊到各个 Parition 中,实现了负载均衡的效果。在分区⽇志⽂件中,你会发现很多类型的⽂件,⽐如: .index、.timestamp、.log、.snapshot 等。
⽂件名⼀致的⽂件集合称为 LogSement
LogSegment
- 分区⽇志⽂件中包含很多的 LogSegment
- Kafka ⽇志追加是顺序写⼊的
- LogSegment 可以减⼩⽇志⽂件的⼤⼩
- 进⾏⽇志删除的时候和数据查找的时候可以快速定位。
- ActiveLogSegment 是活跃的⽇志分段,拥有⽂件拥有写⼊权限,其余的 LogSegment 只有只读的权限。
⽇志⽂件存在多种后缀⽂件,重点需要关注 .index、.timestamp、.log 三种类型。
类别作⽤
后缀名****说明.index偏移量索引⽂件.timestamp时间戳索引⽂件.log⽇志⽂件.snapshot快照⽂件.deleted要删除的文件.cleaned⽇志清理时临时⽂件.swap⽇志压缩之后的临时⽂件leader-epoch-checkpoint
⽇志与索引⽂件
配置条⽬默认值说明log.index.interval.bytes4096(4K)增加索引项字节间隔密度,会影响索引⽂件中的区间密度和查询效率log.segment.bytes1073741824(1G)⽇志⽂件最⼤值log.roll.ms当前⽇志分段中消息的最⼤时间戳与当前系统的时间戳的差值允许的最⼤范围,单位毫秒log.roll.hours168(7天)当前⽇志分段中消息的最⼤时间戳与当前系统的时间戳的差值允许的最⼤范围,单位⼩时log.index.size.max.bytes10485760(10MB)触发偏移量索引⽂件或时间戳索引⽂件分段字节限额
配置项默认值说明
- 偏移量索引⽂件⽤于记录消息偏移量与物理地址之间的映射关系。
- 时间戳索引⽂件则根据时间戳查找对应的偏移量。
- Kafka 中的索引⽂件是以稀疏索引的⽅式构造消息的索引,并不保证每⼀个消息在索引⽂件中都有对应的索引项。
- 每当写⼊⼀定量的消息时,偏移量索引⽂件和时间戳索引⽂件分别增加⼀个偏移量索引项和时间戳索引项。
- 通过修改 log.index.interval.bytes 的值,改变索引项的密度。
2.5.1.2 .index文件
偏移量索引⽂件⽤于记录消息偏移量与物理地址之间的映射关系。
- log⽇志默认每写⼊4K(log.index.interval.bytes设定的),会写⼊⼀条索引信息到index⽂件中,因此索引⽂件是稀疏索引,它不会为每条⽇志都建⽴索引信息。
- 索引⽂件的数据结构则是由相对offset(4byte)+position(4byte)组成,由于保存的是相对第⼀个消息的相对offset,只需要4byte就可以了,可以节省空间,在实际查找后还需要计算回实际的offset,这对⽤户是透明的。
- 稀疏索引,索引密度不⾼,但是offset有序,⼆分查找的时间复杂度为O(lgN),如果从头遍历时间复杂度是O(N)
- 可以通过
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index -- print-data-log | head来查看索引文件 - offset 与 position 没有直接关系,因为会删除数据和清理⽇志
- 在偏移量索引⽂件中,索引数据都是顺序记录 offset

2.5.1.3 .timestamp文件
时间戳索引⽂件则根据时间戳查找对应的偏移量。
它的作⽤是可以让⽤户查询某个时间段内的消息,它⼀条数据的结构是时间戳(8byte)+相对offset(4byte),如果要使⽤这个索引⽂件,⾸先需要通过时间范围,找到对应的相对offset,然后再去对应的
index⽂件找到position信息,然后才能遍历log⽂件,它也是需要使⽤上⾯说的index⽂件的。
但是由于producer⽣产消息可以指定消息的时间戳,这可能将导致消息的时间戳不⼀定有先后顺序,因此量不要⽣产消息时指定时间戳。
时间戳索引⽂件中每个追加的索引时间戳必须⼤于之前追加的索引项,否则不予追加。在 Kafka 0.11.0.0 以后,消息元数据中存在若⼲的时间戳信息。如果 broker 端参数 log.message.timestamp.type 设置为 LogAppendTIme ,那么时间戳必定能保持单调增⻓。反之如果是CreateTime 则⽆法保证顺序。
timestamp⽂件中的 offset 与 index ⽂件中的 offset 不是⼀⼀对应的。因为数据的写⼊是各⾃追加

2.5.1.4 .log文件
- 消息内容保存在log⽇志⽂件中。
- 消息封装为Record,追加到log⽇志⽂件末尾,采⽤的是顺序写模式,由message+实际offset+position组成。
- ⼀个topic的不同分区,可认为是queue,顺序写⼊接收到的消息。

查看日志命令
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log | head
#打印如下
Dumping 00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 716 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 0
CreateTime: 1596513421661 isvalid: true size: 16380 magic: 2 compresscodec: NONE crc:
2973274901
baseOffset: 717 lastOffset: 1410 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 16380
CreateTime: 1596513421715 isvalid: true size: 16371 magic: 2 compresscodec: NONE crc:
1439993110
baseOffset: 1411 lastOffset: 2092 baseSequence: -1 lastSequence: -1 producerId: -1
producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false position: 32751
CreateTime: 1596513421747 isvalid: true size: 16365 magic: 2 compresscodec: NONE crc:
3528903590
- offset是逐渐增加的整数,每个offset对应⼀个消息的偏移量。
- position:消息批字节数,⽤于计算物理地址。
- CreateTime:时间戳。
- magic:2代表这个消息类型是V2,如果是0则代表是V0类型,1代表V1类型。
- compresscodec:None说明没有指定压缩类型,kafka⽬前提供了4种可选择,0-None、1-GZIP、2-snappy、3-lz4。
- crc:对所有字段进⾏校验后的crc值。
每个 LogSegment 都有⼀个基准偏移量,表示当前 LogSegment 中第⼀条消息的****offset。
偏移量是⼀个 64 位的⻓整形数,固定是20位数字,⻓度未达到,⽤ 0 进⾏填补,索引⽂件和⽇志⽂件都由该作为⽂件名命名规则(00000000000000000000.index、00000000000000000000.timestamp、00000000000000000000.log)。
如果⽇志⽂件名为 00000000000000000121.log ,则当前⽇志⽂件的⼀条数据偏移量就是 121(偏移量从 0 开始)。
2.5.2 切分⽂件
当满⾜如下⼏个条件中的其中之⼀,就会触发⽂件的切分:
- 当前⽇志分段⽂件的⼤⼩超过了 broker 端参数 log.segment.bytes 配置的值。 log.segment.bytes 参数的默认值为 1073741824,即 1GB。
- 当前⽇志分段中消息的最⼤时间戳与当前系统的时间戳的差值⼤于 log.roll.ms 或 log.roll.hours 参数配置的值。如果同时配置了 log.roll.ms 和 log.roll.hours 参数,那么 log.roll.ms 的优先级⾼。默认情况下,只配置了 log.roll.hours 参数,其值为168,即 7 天。
- 偏移量索引⽂件或时间戳索引⽂件的⼤⼩达到 broker 端参数 log.index.size.max.bytes 配置的值。 log.index.size.max.bytes 的默认值为 10485760,即 10MB。
- 追加的消息的偏移量与当前⽇志分段的偏移量之间的差值⼤于 Integer.MAX_VALUE ,即要追加的消息的偏移量不能转变为相对偏移量。
为什么是Integer.MAX_VALUE?
1024 * 1024 * 1024=1073741824
在偏移量索引⽂件中,每个索引项共占⽤ 8 个字节,并分为两部分。相对偏移量和物理地址。
- 相对偏移量:表示消息相对与基准偏移量的偏移量,占 4 个字节
- 物理地址:消息在⽇志分段⽂件中对应的物理位置,也占 4 个字节
4 个字节刚好对应 Integer.MAX_VALUE ,如果⼤于 Integer.MAX_VALUE ,则不能⽤ 4 个字节进⾏表示了。
索引⽂件切分过程
索引⽂件会根据 log.index.size.max.bytes 值进⾏预先分配空间,即⽂件创建的时候就是最⼤值
当真正的进⾏索引⽂件切分的时候,才会将其裁剪到实际数据⼤⼩的⽂件。
这⼀点是跟⽇志⽂件有所区别的地⽅。其意义降低了代码逻辑的复杂性。
2.5.3 消息查找
2.5.3.1 offset 查询

如何查找偏移量为 23 的消息?
- 定位index文件Kafka 中存在一个 ConcurrentSkipListMap 来保存在每个日志分段,通过跳跃表方式定位到在 00000000000000000000.index 文件中
- 查找offset通过二分法在偏移量索引文件中找到不大于 23 的最大索引项,即 offset 20 那栏
- 查找消息从日志分段文件中的物理位置为320 开始顺序查找偏移量为 23 的消息。
2.5.3.2 时间戳查询

查找时间戳为 1557554753430 开始的消息
将 1557554753430 和每个日志分段中最大时间戳 largestTimeStamp 逐一对比,直到找到不小于 1557554753430 所对应的日志分段。(日志分段中的 largestTimeStamp 的计算是先查询该日志分段所对应时间戳索引文件,找到最后一条索引项,若最后一条索引项的时间戳字段值大于 0 ,则取该值,否则去该日志分段的最近修改时间)。
找到相应日志分段之后,在对应的时间戳索引文件中使用二分法进行定位,与偏移量索引方式类似,找到不大于 1557554753430 最大索引项,也就是 [1557554753420 430]。
拿着偏移量为 430 到偏移量索引文件中使用二分法找到不大于 430 最大索引项,即 [20,320] 。
日志文件中从 320 的物理位置开始查找不小于 1557554753430 数据。
2.5.4 日志清理
Kafka 提供两种日志清理策略:
- 日志删除:按照一定的删除策略,将不满足条件的数据进行数据删除
- 日志压缩:针对每个消息的 Key 进行整合,对于有相同 Key 的不同 Value 值,只保留最后一个版本。
Kafka 提供 log.cleanup.policy 参数进行相应配置,默认值:delete,还可以选择 compact。主题级别的配置项是 cleanup.policy 。
配置默认值说明log.retention.check.interval.ms300000 (5分钟)检测频率log.retention.hours168 (7天)日志保留时间小时log.retention.minutes日志保留时间分钟log.retention.ms日志保留时间毫秒file.delete.delay.ms60000 (1分钟)延迟执行删除时间log.retention.bytes-1 无穷大 运行保留日志文件最大值log.retention.bytes1073741824 (1G)日志文件最大值
2.5.4.1 日志删除
Kafka 会周期性根据相应规则进行日志数据删除,保留策略有 3 种:基于时间的保留策略、基于日志大小的保留策略和基于日志其实偏移量的保留策略。
基于时间
日志删除任务会根据 log.retention.hours/log.retention.minutes/log.retention.ms 设定日志保留的时间节点。如果超过该设定值,就需要进行删除。默认是 7 天,log.retention.ms 优先级最高。
如何查找日志分段文件中已经过去的数据呢?
Kafka 依据日志分段中最大的时间戳进行定位,首先要查询该日志分段所对应的时间戳索引文件,查找时间戳索引文件中最后一条索引项,若最后一条索引项的时间戳字段值大于 0,则取该值,否则取最近修改时间。
为什么不直接选最近修改时间呢?
因为日志文件可以有意无意的被修改,并不能真实的反应日志分段的最大时间信息。
删除过程
- 从日志对象中所维护日志分段的跳跃表中移除待删除的日志分段,保证没有线程对这些日志分段进行读取操作。
- 这些日志分段所有文件添加 上 .delete 后缀。
- 交由一个以 “delete-file” 命名的延迟任务来删除这些 .delete 为后缀的文件。延迟执行时间可以通过 file.delete.delay.ms 进行设置
如果活跃的日志分段中也存在需要删除的数据时,Kafka 会先切分出一个新的日志分段作为活跃日志分段,然后执行删除操作。
基于日志大小
日志删除任务会检查当前日志的大小是否超过设定值。设定项为 log.retention.bytes ,单个日志分段的大小由 log.regment.bytes 进行设定。
删除过程
- 计算需要被删除的日志总大小 (当前日志文件大小-retention值)。
- 从日志文件第一个 LogSegment 开始查找可删除的日志分段的文件集合。
- 执行删除。
基于日志起始偏移量
基于日志起始偏移量的保留策略的判断依据是某日志分段的下一个日志分段的起始偏移量是否小于等于日志文件的起始偏移量,若是,则可以删除此日志分段。
注意:日志文件的起始偏移量并不一定等于第一个日志分段的基准偏移量,存在数据删除,可能与之相等的那条数据已经被删除了。
删除过程
- 从头开始变了每一个日志分段,日志分段 1 的下一个日志分段的起始偏移量为 11,小于 logStartOffset,将 日志分段 1 加入到删除队列中
- 日志分段 2 的下一个日志分段的起始偏移量为 23,小于 logStartOffset,将 日志分段 2 加入到删除队列中
- 日志分段 3 的下一个日志分段的起始偏移量为 30,大于 logStartOffset,则不进行删除。
2.5.4.2 日志压缩
⽇志压缩是Kafka的⼀种机制,可以提供较为细粒度的记录保留,⽽不是基于粗粒度的基于时间的保留。
对于具有相同的Key,⽽数据不同,只保留最后⼀条数据,前⾯的数据在合适的情况下删除
⽇志压缩特性,就实时计算来说,可以在异常容灾⽅⾯有很好的应⽤途径。⽐如,我们在Spark、Flink中做实时计算时,需要⻓期在内存⾥⾯维护⼀些数据,这些数据可能是通过聚合了⼀天或者⼀周的⽇志得到的,这些数据⼀旦由于异常因素(内存、⽹络、磁盘等)崩溃了,从头开始计算需要很⻓的时间。⼀个⽐较有效可⾏的⽅式就是定时将内存⾥的数据备份到外部存储介质中,当崩溃出现时,再从外部存储介质中恢复并继续计算。
使⽤⽇志压缩来替代这些外部存储的优势
- Kafka即是数据源⼜是存储⼯具,可以简化技术栈,降低维护成本
- 使⽤外部存储介质的话,需要将存储的Key记录下来,恢复的时候再使⽤这些Key将数据取回,实现起来有⼀定的⼯程难度和复杂度。使⽤Kafka的⽇志压缩特性,只需要把数据写进Kafka,等异常出现恢复任务时再读回到内存就可以了
- Kafka对于磁盘的读写做了⼤量的优化⼯作,⽐如磁盘顺序读写。相对于外部存储介质没有索引查询等⼯作量的负担,可以实现⾼性能。同时,Kafka的⽇志压缩机制可以充分利⽤廉价的磁盘,不⽤依赖昂贵的内存来处理,在性能相似的情况下,实现⾮常⾼的性价⽐(这个观点仅仅针对于异常处理和容灾的场景来说)
实现方式
主题的 cleanup.policy 需要设置为compact。
Kafka的后台线程会定时将Topic遍历两次:
- 记录每个key的hash值最后⼀次出现的偏移量
- 第⼆次检查每个offset对应的Key是否在后⾯的⽇志中出现过,如果出现了就删除对应的⽇志。
⽇志压缩允许删除,除最后⼀个key之外,删除先前出现的所有该key对应的记录。在⼀段时间后从⽇志中清理,以释放空间。
注意:⽇志压缩与key有关,确保每个消息的key不为null。
压缩是在Kafka后台通过定时重新打开Segment来完成的,Segment的压缩细节如下图所示:

⽇志压缩可以确保:
- 任何保持在⽇志头部以内的使⽤者都将看到所写的每条消息,这些消息将具有顺序偏移量。可以使⽤Topic的min.compaction.lag.ms属性来保证消息在被压缩之前必须经过的最短时间。也就是说,它为每个消息在(未压缩)头部停留的时间提供了⼀个下限。可以使⽤Topic的max.compaction.lag.ms属性来保证从收到消息到消息符合压缩条件之间的最⼤延时
- 消息始终保持顺序,压缩永远不会重新排序消息(按照最后一次写入顺序排),只是删除⼀些⽽已
- 消息的偏移量永远不会改变,它是⽇志中位置的永久标识符
- 从⽇志开始的任何使⽤者将⾄少看到所有记录的最终状态,按记录的顺序写⼊。另外,如果使⽤者在⽐Topic的log.cleaner.delete.retention.ms短的时间内到达⽇志的头部,则会看到已删除记录的所有delete标记。保留时间默认是24⼩时。
默认情况下,启动⽇志清理器,若需要启动特定Topic的⽇志清理,请添加特定的属性。配置⽇志清理器,这⾥为
⼤家总结了以下⼏点:
- log.cleanup.policy 设置为 compact ,Broker的配置,影响集群中所有的Topic。
- log.cleaner.min.compaction.lag.ms ,⽤于防⽌对更新超过最⼩消息进⾏压缩,如果没有设置,除最后⼀个Segment之外,所有Segment都有资格进⾏压缩
- log.cleaner.max.compaction.lag.ms ,⽤于防⽌低⽣产速率的⽇志在⽆限制的时间内不压缩。
Kafka的⽇志压缩原理并不复杂,就是定时把所有的⽇志读取两遍,写⼀遍,⽽CPU的速度超过磁盘完全不是问题,只要⽇志的量对应的读取两遍和写⼊⼀遍的时间在可接受的范围内,那么它的性能就是可以接受的。
2.5.5磁盘存储
2.5.5.1 零拷贝
Kafka性能非常高,但是他却把数据存储在磁盘中,需要对数据进行落盘,因此kafka是多方面协同的结果,包括宏观架构、分布式partition存储,ISR数据同步、以及各种高效利用磁盘的特性。零拷贝不是不需要拷贝,而且减少不必要的拷贝次数,nginx高性能中也有零拷贝应用。
传统IO:先读取,再发送,经过1-4次复制,第一次将磁盘文件读取到操作系统内核缓存区,第二次copy到application应用程序的缓存,第三次再copy到socket网络发送到缓冲区,最后copy到网络协议栈,由网卡进行网络传输。

零拷贝就是并不需要第⼆个和第三个数据副本。数据可以直接从读缓冲区传输到套接字缓冲区
2.5.5.2 接收数据( product到Broker)
页缓存:操作系统实现的一种主要磁盘缓存,用来减少对磁盘的IO操作,也就是把磁盘中的数据缓存在内存中,把对磁盘的访问变成对内存的访问,提高效率。
Kafka接收来⾃socket buffer的⽹络数据,应⽤进程不需要中间处理、直接进⾏持久化时可以使⽤mmap内存⽂件映射。
Memory Mapped Files:简称mmap,简单描述其作⽤就是将磁盘⽂件映射到内存, ⽤户通过修改内存就能修改磁盘⽂件。
它的⼯作原理是直接利⽤操作系统的Page来实现磁盘⽂件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)
通过mmap,进程像读写硬盘⼀样读写内存(当然是虚拟机内存)。使⽤这种⽅式可以获取很⼤的I/O提升,省去了⽤户空间到内核空间复制的开销。
mmap也有⼀个很明显的缺陷:不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调⽤flush的时候才把数据真正的写到硬盘。
Kafka提供了⼀个参数 producer.type 来控制是不是主动flush;如果Kafka写⼊到mmap之后就⽴即flush然后再返回Producer叫同步(sync);写⼊mmap之后⽴即返回Producer不调⽤flush叫异步(async)。
在mmap中
- 当⼀个进程准备读取磁盘上的⽂件内容时- 操作系统会先查看待读取的数据所在的⻚ (page)是否在⻚缓存(pagecache)中,如果存在(命中)则直接返回数据,从⽽避免了对物理磁盘的 I/O 操作;- 如果没有命中,则操作系统会向磁盘发起读取请求并将读取的数据⻚存⼊⻚缓存,之后再将数据返回给进程。
- 如果⼀个进程需要将数据写⼊磁盘- 操作系统也会检测数据对应的⻚是否在⻚缓存中,如果不存在,则会先在⻚缓存中添加相应的⻚,最后将数据写⼊对应的⻚。- 被修改过后的⻚也就变成了脏⻚,操作系统会在合适的时间把脏⻚中的数据写⼊磁盘,以保持数据的⼀致性。
对⼀个进程⽽⾔,它会在进程内部缓存处理所需的数据,然⽽这些数据有可能还缓存在操作系统的⻚缓存中,因此同⼀份数据有可能被缓存了两次。并且,除⾮使⽤Direct I/O的⽅式, 否则⻚缓存很难被禁⽌。
当使⽤⻚缓存的时候,即使Kafka服务重启, ⻚缓存还是会保持有效,然⽽进程内的缓存却需要重建。这样也极⼤地简化了代码逻辑,因为维护⻚缓存和⽂件之间的⼀致性交由操作系统来负责,这样会⽐进程内维护更加安全有效。
Kafka中⼤量使⽤了⻚缓存,这是 Kafka 实现⾼吞吐的重要因素之⼀。
消息先被写⼊⻚缓存,由操作系统负责刷盘任务。
顺序写⼊操作系统可以针对线性读写做深层次的优化,⽐如预读(read-ahead,提前将⼀个⽐较⼤的磁盘块读⼊内存) 和后写(write-behind,将很多⼩的逻辑写操作合并起来组成⼀个⼤的物理写操作)技术。
Kafka 在设计时采⽤了⽂件追加的⽅式来写⼊消息,即只能在⽇志⽂件的尾部追加新的消 息,并且也不允许修改已写⼊的消息,这种⽅式属于典型的顺序写盘的操作,所以就算 Kafka 使⽤磁盘作为存储介质,也能承载⾮常⼤的吞吐量。
mmap和senfile
- linux内核提供实现零拷贝的api
- sendfile是将读到内核空间的数据,转到socket buffer,进行网络发送。
- mmap将磁盘文件映射到内存,支持读和写,对内存的操作会反应在磁盘文件上。
- rocketmq在消费消息使用了mmap,kafka使用了sendfile。
2.5.5.3 磁盘⽂件通过⽹络发送(Broker 到 Consumer)
消费时,kafka磁盘文件通过网络发送,不需要先copy到application应用程序的缓存,在copy到socket网络发送到缓冲区。
除了减少数据拷⻉外,整个读⽂件 ==> ⽹络发送由⼀个 sendfile 调⽤完成,整个过程只有两次上下⽂切换,因此
⼤⼤提⾼了性能。
Java NIO对sendfile的⽀持就是FileChannel.transferTo()/transferFrom()。
fileChannel.transferTo( position, count, socketChannel);
把磁盘⽂件读取OS内核缓冲区后的fileChannel,直接转给socketChannel发送;底层就是sendfile。消费者从broker读取数据,就是由此实现。
具体来看,Kafka 的数据传输通过 TransportLayer 来完成,其⼦类 PlaintextTransportLayer 通过Java NIO 的FileChannel 的 transferTo 和 transferFrom ⽅法实现零拷⻉。
2.5.5.3 总结
Kafka速度快的原因:
- partition顺序读写,充分利用磁盘特性。
- producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入。
- customer从broker读取消息,采用sendfile,将磁盘文件读到OS内核缓存区,然后直接转到socket buffer进行网络发送。
2.6 稳定性
2.6.1 事务
2.6.1.1 事务简介
事务场景
- producer发的多条消息组成⼀个事务这些消息需要对consumer同时可⻅或者同时不可⻅
- producer可能会给多个topic,多个partition发消息,这些消息也需要能放在⼀个事务⾥⾯,这就形成了⼀个典型的分布式事务
- kafka的应⽤场景经常是应⽤先消费⼀个topic,然后做处理再发到另⼀个topic,这个consume-transform-produce过程需要放到⼀个事务⾥⾯,⽐如在消息处理或者发送的过程中如果失败了,消费偏移量也不能提交
- producer或者producer所在的应⽤可能会挂掉,新的producer启动以后需要知道怎么处理之前未完成的事务
关键概念和推导
- 因为producer发送消息可能是分布式事务,所以引⼊了常⽤的2PC,所以有事务协调者(Transaction Coordinator)。Transaction Coordinator和之前为了解决脑裂和惊群问题引⼊的Group Coordinator在选举和failover上⾯类似
- 事务管理中事务⽇志是必不可少的,kafka使⽤⼀个内部topic来保存事务⽇志,这个设计和之前使⽤内部topic保存偏移量的设计保持⼀致。事务⽇志使Transaction Coordinator管理的状态的持久化,因为不需要回溯事务的历史状态,所以事务⽇志只⽤保存最近的事务状态
- 因为事务存在commit和abort两种操作,⽽客户端⼜有read committed和read uncommitted两种隔离级别,所以消息队列必须能标识事务状态,这个被称作Control Message
- producer挂掉重启或者漂移到其它机器,需要能关联到之前的未完成事务,所以需要有⼀个唯⼀标识符来进⾏关联,这个就是TransactionalId,⼀个producer挂了,另⼀个有相同TransactionalId的producer能够接着处理这个事务未完成的状态。kafka⽬前没有引⼊全局序,所以也没有transaction id,这个TransactionalId是⽤户提前配置的
- TransactionalId能关联producer,也需要避免两个使⽤相同TransactionalId的producer同时存在,所以引⼊了producer epoch来保证对应⼀个TransactionalId只有⼀个活跃的producer epoch
- 事务组在处理事务性消息时,Kafka 引入了事务组的概念。事务组中的消费者协作处理从事务性生产者发送的事务性消息。这样可以确保消息被原子地处理,即在消息的生产和消费之间保持一致性
- ⽣产者ID和事务组状态事务⽣产者需要两个新参数:事务ID和⽣产组。需要将⽣产者的输⼊状态与上⼀个已提交的事务相关联。这使事务⽣产者能够重试事务(通过为该事务重新创建输⼊状态;在我们的⽤例中通常是偏移量的向量)。可以使⽤消费者偏移量管理机制来管理这些状态。消费者偏移量管理器将每个键( consumergroup-topic partition )与该分区的最后⼀个检查点偏移量和元数据相关联。在事务⽣产者中,我们保存消费者的偏移量,该偏移量与事务的提交点关联。此偏移提交记录(在 consumer_offsets 主题中)应作为事务的⼀部分写⼊。即存储消费组偏移量的 __consumer_offsets 主题分区将需要参与事务。因此,假定⽣产者在事务中间失败(事务协调器随后到期);当⽣产者恢复时,它可以发出偏移量获取请求,以恢复与最后提交的事务相关联的输⼊偏移量,并从该点恢复事务处理。为了⽀持此功能,我们需要对偏移量管理器和压缩的 __consumer_offsets 主题进⾏⼀些增强。⾸先,压缩的主题现在还将包含事务控制记录。我们将需要为这些控制记录提出剔除策略。其次,偏移量管理器需要具有事务意识;特别是,如果组与待处理的事务相关联,则偏移量提取请求应返回错误。
- 事务协调器和事务⽇志事务协调器是每个Kafka内部运⾏的⼀个模块。事务⽇志是⼀个内部的主题。每个协调器拥有事务⽇志所在分区的⼦集,即这些 borker 中的分区都是Leader。事务协调器在内存管理如下的状态- 对应正在处理的事务的第⼀个消息的HW。事务协调器周期性地将HW写到ZK。- 事务控制⽇志中存储对应于⽇志HW的所有正在处理的事务:- 事务消息主题分区的列表。- 事务的超时时间。- 与事务关联的Producer ID每个
transactional.id都通过⼀个简单的哈希函数映射到事务⽇志的特定分区,这个分区的Leader就是事务协调器。 通过这种⽅式,我们利⽤Kafka可靠的复制协议和Leader选举流程来确保事务协调器始终可⽤,并且所有事务状态都能够持久化。 值得注意的是,事务⽇志只保存事务的最新状态⽽不是事务中的实际消息。消息只存储在实际的Topic的分区中。事务可以处于诸如“Ongoing”,“prepare commit”和“Completed”之类的各种状态中。正是这种状态和关联的元数据存储在事务⽇志中。 - 事务数据流数据流在抽象层⾯上有四种不同的类型- producer和事务coordinator的交互 执⾏事务时,Producer向事务协调员发出如下请求: -
initTransactions API向coordinator注册⼀个transactional.id。 此时,coordinator使⽤该transactional.id关闭所有待处理的事务,并且会避免遇到僵⼫实例,由具有相同的transactional.id的Producer的另⼀个实例启动的任何事务将被关闭和隔离。每个Producer会话只发⽣⼀次。- 当Producer在事务中第⼀次将数据发送到分区时,⾸先向coordinator注册分区- 当应⽤程序调⽤commitTransaction或abortTransaction时,会向coordinator发送⼀个请求以开始两阶段提交协议。- Coordinator和事务⽇志交互 随着事务的进⾏,Producer发送上⾯的请求来更新Coordinator上事务的状态。事务Coordinator会在内存中保存每个事务的状态,并且把这个状态写到事务⽇志中(这是以三种⽅式复制的,因此是持久保存的)。 事务Coordinator是读写事务⽇志的唯⼀组件。如果⼀个给定的Borker故障了,⼀个新的Coordinator会被选为新的事务⽇志的Leader,这个事务⽇志分割了这个失效的代理,它从传⼊的分区中读取消息并在内存中重建状态。- Producer将数据写⼊⽬标Topic所在分区 在Coordinator的事务中注册新的分区后,Producer将数据正常地发送到真实数据所在分区。这与producer.send流程完全相同,但有⼀些额外的验证,以确保Producer不被隔离。- Topic分区和Coordinator的交互 - 在Producer发起提交(或中⽌)之后,协调器开始两阶段提交协议。- 在第⼀阶段,Coordinator将其内部状态更新为“prepare_commit”并在事务⽇志中更新此状态。⼀旦完成了这个事务,⽆论发⽣什么事,都能保证事务完成。- Coordinator然后开始阶段2,在那⾥它将事务提交标记写⼊作为事务⼀部分的Topic分区。- 这些事务标记不会暴露给应⽤程序,但是在read_committed模式下被Consumer使⽤来过滤掉被中⽌事务的消息,并且不返回属于开放事务的消息(即那些在⽇志中但没有事务标记与他们相关联)- ⼀旦标记被写⼊,事务协调器将事务标记为“完成”,并且Producer可以开始下⼀个事务。
事务语义
多分区原子写入:
事务能够保证Kafka topic下每个分区的原⼦写⼊。事务中所有的消息都将被成功写⼊或者丢弃。
⾸先,我们来考虑⼀下原⼦读取-处理-写⼊周期是什么意思。简⽽⾔之,这意味着如果某个应⽤程序在某个topic tp0的偏移量X处读取到了消息A,并且在对消息A进⾏了⼀些处理(如B = F(A)),之后将消息B写⼊topic tp1,则只有当消息A和B被认为被成功地消费并⼀起发布,或者完全不发布时,整个读取过程写⼊操作是原⼦的。
现在,只有当消息A的偏移量X被标记为已消费,消息A才从topic tp0消费,消费到的数据偏移量(record offset)将被标记为提交偏移量(Committing offset)。在Kafka中,我们通过写⼊⼀个名为offsets topic的内部Kafka topic来记录offset commit。消息仅在其offset被提交给offsets topic时才被认为成功消费。
由于offset commit只是对Kafka topic的另⼀次写⼊,并且由于消息仅在提交偏移量时被视为成功消费,所以跨多个主题和分区的原⼦写⼊也启⽤原⼦读取-处理-写⼊循环:提交偏移量X到offset topic和消息B到tp1的写⼊将是单个事务的⼀部分,所以整个步骤都是原⼦的。
粉碎“僵尸实例”:
我们通过为每个事务Producer分配⼀个称为
transactional.id
的唯⼀标识符来解决僵⼫实例的问题。在进程重新启动时能够识别相同的Producer实例。
API要求事务性Producer的第⼀个操作应该是在Kafka集群中显示注册
transactional.id
。 当注册的时候,Kafka broker⽤给定的
transactional.id
检查打开的事务并且完成处理。 Kafka也增加了⼀个与
transactional.id
相关的epoch。Epoch存储每个
transactional.id
内部元数据。
⼀旦epoch被触发,任何具有相同的
transactional.id
和旧的epoch的⽣产者被视为僵⼫,Kafka拒绝来⾃这些⽣产者的后续事务性写⼊。
简⽽⾔之:Kafka可以保证Consumer最终只能消费⾮事务性消息或已提交事务性消息。它将保留来⾃未完成事务的消息,并过滤掉已中⽌事务的消息。
事务的使用场景
在⼀个原⼦操作中,根据包含的操作类型,可以分为三种情况,前两种情况是事务引⼊的场景,最后⼀种没⽤:
- 只有Producer⽣产消息;
- 消费消息和⽣产消息并存,这个是事务场景中最常⽤的情况,就是我们常说的
consume-transform-produce模式 - 只有consumer消费消息,这种操作其实没有什么意义,跟使⽤⼿动提交效果⼀样,⽽且也不是事务属性引⼊的⽬的,所以⼀般不会使⽤这种情况
事务定义
⽣产者可以显式地发起事务会话,在这些会话中发送(事务)消息,并提交或中⽌事务。有如下要求:
- 原⼦性:消费者的应⽤程序不应暴露于未提交事务的消息中。
- 持久性:Broker不能丢失任何已提交的事务。
- 排序:事务消费者应在每个分区中以原始顺序查看事务消息。
- 交织:每个分区都应该能够接收来⾃事务性⽣产者和⾮事务⽣产者的消息
- 事务中不应有重复的消息。
如果允许事务性和⾮事务性消息的交织,则⾮事务性和事务性消息的相对顺序将基于附加(对于⾮事务性消息)和最终提交(对于事务性消息)的相对顺序。

在上图中,分区p0和p1接收事务X1和X2的消息,以及⾮事务性消息。时间线是消息到达Broker的时间。由于⾸先提交了X2,所以每个分区都将在X1之前公开来⾃X2的消息。由于⾮事务性消息在X1和X2的提交之前到达,因此这些消息将在来⾃任⼀事务的消息之前公开。
事务配置
创建消费者代码,需要:
- 将配置中的⾃动提交属性(
auto.commit)进⾏关闭 - ⽽且在代码⾥⾯也不能使⽤⼿动提交
commitSync()或者commitAsync() - 设置
isolation.level
创建生产者,代码如下,需要:
- 配置
transactional.id属性 - 配置
enable.idempotence属性
事务相关配置
Broker configs:
配置项说明transactional.id.timeout.ms在ms中,事务协调器在⽣产者TransactionalId提前过期之前等待的最⻓时间,并且没有从该⽣产者TransactionalId接收到任何事务状态更新。默认是604800000(7天)。这允许每周⼀次的⽣产者作业维护它们的idmax.transaction.timeout.ms事务允许的最⼤超时。如果客户端请求的事务时间超过此时间,broke将在InitPidRequest中返回InvalidTransactionTimeout错误。这可以防⽌客户机超时过⼤,从⽽导致⽤户⽆法从事务中包含的主题读取内容。 默认值为900000(15分钟)。这是消息事务需要发送的时间的保守上限。transaction.state.log.replication.factor事务状态topic的副本数量。默认值:3transaction.state.log.num.partitions事务状态主题的分区数。默认值:50transaction.state.log.min.isr事务状态主题的每个分区ISR最⼩数量。默认值:2transaction.state.log.segment.bytes事务状态主题的segment⼤⼩。默认值:104857600字节
Producer configs:
配置项说明enable.idempotence开启幂等transaction.timeout.ms事务超时时间 事务协调器在主动中⽌正在进⾏的事务之前等待⽣产者更新事务状态的最⻓时间。这个配置值将与InitPidRequest⼀起发送到事务协调器。如果该值⼤于max.transaction.timeout。在broke中设置ms时,请求将失败,并出现InvalidTransactionTimeout错误。 默认是60000。这使得交易不会阻塞下游消费超过⼀分钟,这在实时应⽤程序中通常是允许的。transactional.id⽤于事务性交付的TransactionalId。这⽀持跨多个⽣产者会话的可靠性语义,因为它允许客户端确保使⽤相同TransactionalId的事务在启动任何新事务之前已经完成。如果没有提供TransactionalId,则⽣产者仅限于幂等交付。
Consumer configs:
配置项说明isolation.level- read_uncommitted:读未提交,以偏移顺序使⽤已提交和未提交的消息。 - read_committed:读已提交,仅以偏移量顺序使⽤⾮事务性消息或已提交事务性消息。为了维护偏移排序,这个设置意味着我们必须在使⽤者中缓冲消息,直到看到给定事务中的所有消息。
事务流程
- 初始阶段- Producer:计算哪个Broker作为事务协调器。- Producer:向事务协调器发送BeginTransaction(producerId, generation, partitions… )请求,当然也可以发送另⼀个包含事务过期时间的。如果⽣产者需要将消费者状态作为事务的⼀部分提交事务,则需要在BeginTransaction中包含对应的 __consumer_offsets 主题分区信息。- Broker:⽣成事务ID- Coordinator:向事务协调主题追加BEGIN(TxId, producerId, generation, partitions…)消息,然后发送响应给⽣产者。- Producer:读取响应(包含了事务ID:TxId)- Coordinator (and followers):在内存更新当前事务的待确认事务状态和数据分区信息。
- 发送阶段- Producer:发送事务消息给主题Leader分区所在的Broker。每个消息需要包含TxId和TxCtl字段。TxCtl仅⽤于标记事务的最终状态(提交还是中⽌)。⽣产者请求也封装了⽣产者ID,但是不追加到⽇志中。
- 结束阶段 (⽣产者准备提交事务)- Producer:发送OffsetCommitRequest请求提交与事务结束状态关联的输⼊状态(如下⼀个事务输⼊从哪⼉开始)- Producer:发送CommitTransaction(TxId, producerId, generation)请求给事务协调器并等待响应。(如果响应中没有错误信息,表示将提交事务)- Coordinator:向事务控制主题追加PREPARE_COMMIT(TxId)请求并向⽣产者发送响应。- Coordinator:向事务涉及到的每个Leader分区(事务的业务数据的⽬标主题)的Broker发送⼀个CommitTransaction(TxId, partitions…)请求。- 事务业务数据的⽬标主题相关Leader分区Broker: - 如果是⾮ __consumer_offsets 主题的Leader分区:⼀收到CommitTransaction(TxId,partition1, partition2, …)请求就会向对应的分区Broker发送空(null)消息(没有key/value)并给该消息设置TxId和TxCtl(设置为COMMITTED)字段。Leader分区的Broker给协调器发送响应。- 如果是 __consumer_offsets 主题的Leader分区:追加消息,该消息的key是 G-LAST-COMMIT ,value就是 TxId 的值。同时也应该给该消息设置TxId和TxCtl字段。Broker向协调器发送响应。- Coordinator:向事务控制主题发送COMMITTED(TxId)请求。 __transaction_state- Coordinator (and followers):尝试更新HW。
事务中止
当事务⽣产者发送业务消息的时候如果发⽣异常,可以中⽌该事务。如果事务提交超时,事务协调器也会中⽌当前事务。
- Producer:向事务协调器发送AbortTransaction(TxId)请求并等待响应。(⼀个没有异常的响应表示事务将会中⽌)
- Coordinator:向事务控制主题追加PREPARE_ABORT(TxId)消息,然后向⽣产者发送响应。
- Coordinator:向事务业务数据的⽬标主题的每个涉及到的Leader分区Broker发送AbortTransaction(TxId,partitions…)请求。
- 收到Leader分区Broker响应后,事务协调器中⽌动作跟上⾯的提交类似。
基本事务流程的失败
- ⽣产者发送BeginTransaction(TxId):的时候超时或响应中包含异常,⽣产者使⽤相同的TxId重试。
- ⽣产者发送数据时的Broker错误:⽣产者应中⽌(然后重做)事务(使⽤新的TxId)。如果⽣产者没有中⽌事务,则协调器将在事务超时后中⽌事务。仅在可能已将请求数据附加并复制到Follower的错误的情况下才需要重做事务。例如,⽣产者请求超时将需要重做,⽽NotLeaderForPartitionException不需要重做。
- ⽣产者发送CommitTransaction(TxId)请求超时或响应中包含异常,⽣产者使⽤相同的TxId重试事务。此时需要幂等性。
2.6.1.2 幂等性
Kafka在引⼊幂等性之前,Producer向Broker发送消息,然后Broker将消息追加到消息流中后给Producer返回Ack信号值。实现流程如下:

⽣产中,会出现各种不确定的因素,⽐如在Producer在发送给Broker的时候出现⽹络异常。⽐如以下这种异常情况的出现:

上图这种情况,当Producer第⼀次发送消息给Broker时,Broker将消息(x2,y2)追加到了消息流中,但是在返回Ack信号给Producer时失败了(⽐如⽹络异常) 。此时,Producer端触发重试机制,将消息(x2,y2)重新发送给Broker,Broker接收到消息后,再次将该消息追加到消息流中,然后成功返回Ack信号给Producer。这样下来,消息流中就被重复追加了两条相同的(x2,y2)的消息。
幂等性
保证在消息重发的时候,消费者不会重复处理。即使在消费者收到重复消息的时候,重复处理,也要保证最终结果的⼀致性。
所谓幂等性,数学概念就是:
f(f(x)) = f(x)
。f函数表示对消息的处理。
⽐如,银⾏转账,如果失败,需要重试。不管重试多少次,都要保证最终结果⼀定是⼀致的。
幂等性实现
添加唯⼀ID,类似于数据库的主键,⽤于唯⼀标记⼀个消息。
Kafka为了实现幂等性,它在底层设计架构中引⼊了
ProducerID
和
SequenceNumber
。
- ProducerID:在每个新的Producer初始化时,会被分配⼀个唯⼀的ProducerID,这个ProducerID对客户端使⽤者是不可⻅的。
- SequenceNumber:对于每个ProducerID,Producer发送数据的每个Topic和Partition都对应⼀个从0开始单调递增的SequenceNumber值。

同样,这是⼀种理想状态下的发送流程。实际情况下,会有很多不确定的因素,⽐如Broker在发送Ack信号给Producer时出现⽹络异常,导致发送失败。异常情况如下图所示:

当Producer发送消息(x2,y2)给Broker时,Broker接收到消息并将其追加到消息流中。此时,Broker返回Ack信号给Producer时,发⽣异常导致Producer接收Ack信号失败。对于Producer来说,会触发重试机制,将消息(x2,y2)再次发送,但是,由于引⼊了幂等性,在每条消息中附带了PID(ProducerID)和SequenceNumber。相同的PID和SequenceNumber发送给Broker,⽽之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有⼀条(x2,y2),不会出现重复发送的情况。
客户端在⽣成Producer时,会实例化如下代码:
// 实例化⼀个Producer对象
Producer<String, String> producer = new KafkaProducer<>(props);
在
org.apache.kafka.clients.producer.internals.Sender
类中,在run()中有⼀个
maybeWaitForPid()
⽅法,⽤来⽣成⼀个ProducerID,实现代码如下:
privatevoidmaybeWaitForPid(){if(transactionState ==null)return;while(!transactionState.hasPid()){try{Node node =awaitLeastLoadedNodeReady(requestTimeout);if(node !=null){ClientResponse response =sendAndAwaitInitPidRequest(node);if(response.hasResponse()&&(response.responseBody()instanceofInitPidResponse)){InitPidResponse initPidResponse =(InitPidResponse) response.responseBody();
transactionState.setPidAndEpoch(initPidResponse.producerId(), initPidResponse.epoch());}else{
log.error("Received an unexpected response type for an InitPidRequest from {}. "+"We will back off and try again.", node);}}else{
log.debug("Could not find an available broker to send InitPidRequest to. "+"We will back off and try again.");}}catch(Exception e){
log.warn("Received an exception while trying to get a pid. Will back off and retry.", e);}
log.trace("Retry InitPidRequest in {}ms.", retryBackoffMs);
time.sleep(retryBackoffMs);
metadata.requestUpdate();}}
2.6.1.3 事务操作
在Kafka事务中,⼀个原⼦性操作,根据操作类型可以分为3种情况。情况如下:
- 只有Producer⽣产消息,这种场景需要事务的介⼊;
- 消费消息和⽣产消息并存,⽐如Consumer&Producer模式,这种场景是⼀般Kafka项⽬中⽐较常⻅的模式,需要事务介⼊;
- 只有Consumer消费消息,这种操作在实际项⽬中意义不⼤,和⼿动Commit Offsets的结果⼀样,⽽且这种场景不是事务的引⼊⽬的。
// 初始化事务,需要注意确保transation.id属性被分配voidinitTransactions();// 开启事务voidbeginTransaction()throwsProducerFencedException;// 为Consumer提供的在事务内Commit Offsets的操作voidsendOffsetsToTransaction(Map<TopicPartition,OffsetAndMetadata> offsets,String consumerGroupId)throwsProducerFencedException;// 提交事务voidcommitTransaction()throwsProducerFencedException;// 放弃事务,类似于回滚事务的操作voidabortTransaction()throwsProducerFencedException;
案例1:单个Producer,使⽤事务保证消息的仅⼀次发送:
packagecom.edu.kafka.demo.producer;importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.clients.producer.ProducerRecord;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.HashMap;importjava.util.Map;publicclassMyTransactionalProducer{publicstaticvoidmain(String[] args){Map<String,Object> configs =newHashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092");
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);// 提供客户端ID
configs.put(ProducerConfig.CLIENT_ID_CONFIG,"tx_producer");// 事务ID
configs.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"my_tx_id");// 要求ISR都确认
configs.put(ProducerConfig.ACKS_CONFIG,"all");KafkaProducer<String,String> producer =newKafkaProducer<String,String>(configs);// 初始化事务
producer.initTransactions();// 开启事务
producer.beginTransaction();try{// producer.send(new ProducerRecord<>("tp_tx_01", "tx_msg_01"));
producer.send(newProducerRecord<>("tp_tx_01","tx_msg_02"));// int i = 1 / 0;// 提交事务
producer.commitTransaction();}catch(Exception ex){// 中⽌事务
producer.abortTransaction();}finally{// 关闭⽣产者
producer.close();}}}
案例2:在消费-转换-⽣产模式,使⽤事务保证仅⼀次发送。
packagecom.edu.kafka.demo;importorg.apache.kafka.clients.consumer.*;importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerConfig;importorg.apache.kafka.clients.producer.ProducerRecord;importorg.apache.kafka.common.TopicPartition;importorg.apache.kafka.common.serialization.StringDeserializer;importorg.apache.kafka.common.serialization.StringSerializer;importjava.util.Collections;importjava.util.HashMap;importjava.util.Map;publicclassMyTransactional{publicstaticKafkaProducer<String,String>getProducer(){Map<String,Object> configs =newHashMap<>();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092");
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);// 设置client.id
configs.put(ProducerConfig.CLIENT_ID_CONFIG,"tx_producer_01");// 设置事务id
configs.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"tx_id_02");// 需要所有的ISR副本确认
configs.put(ProducerConfig.ACKS_CONFIG,"all");// 启⽤幂等性
configs.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);KafkaProducer<String,String> producer =newKafkaProducer<String,String>(configs);return producer;}publicstaticKafkaConsumer<String,String>getConsumer(String consumerGroupId){Map<String,Object> configs =newHashMap<>();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node1:9092");
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class);// 设置消费组ID
configs.put(ConsumerConfig.GROUP_ID_CONFIG,"consumer_grp_02");// 不启⽤消费者偏移量的⾃动确认,也不要⼿动确认
configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
configs.put(ConsumerConfig.CLIENT_ID_CONFIG,"consumer_client_02");
configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");// 只读取已提交的消息// configs.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");KafkaConsumer<String,String> consumer =newKafkaConsumer<String,String>(configs);return consumer;}publicstaticvoidmain(String[] args){String consumerGroupId ="consumer_grp_id_101";KafkaProducer<String,String> producer =getProducer();KafkaConsumer<String,String> consumer =getConsumer(consumerGroupId);// 事务的初始化
producer.initTransactions();//订阅主题
consumer.subscribe(Collections.singleton("tp_tx_01"));finalConsumerRecords<String,String> records = consumer.poll(1_000);// 开启事务
producer.beginTransaction();try{Map<TopicPartition,OffsetAndMetadata> offsets =newHashMap<>();for(ConsumerRecord<String,String> record : records){System.out.println(record);
producer.send(newProducerRecord<String,String>("tp_tx_out_01", record.key(), record.value()));
offsets.put(newTopicPartition(record.topic(), record.partition()),newOffsetAndMetadata(record.offset()+1));// 偏移量表示下⼀条要消费的消息}// 将该消息的偏移量提交作为事务的⼀部分,随事务提交和回滚(不提交消费偏移量)
producer.sendOffsetsToTransaction(offsets, consumerGroupId);// int i = 1 / 0;// 提交事务
producer.commitTransaction();}catch(Exception e){
e.printStackTrace();// 回滚事务
producer.abortTransaction();}finally{// 关闭资源
producer.close();
consumer.close();}}}
2.6.2 控制器
Kafka集群包含若⼲个broker,
broker.id
指定broker的编号,编号不要重复。
Kafka集群上创建的主题,包含若⼲个分区。
每个分区包含若⼲个副本,副本因⼦包括了Follower副本和Leader副本。
副本⼜分为ISR(同步副本分区)和OSR(⾮同步副本分区)。
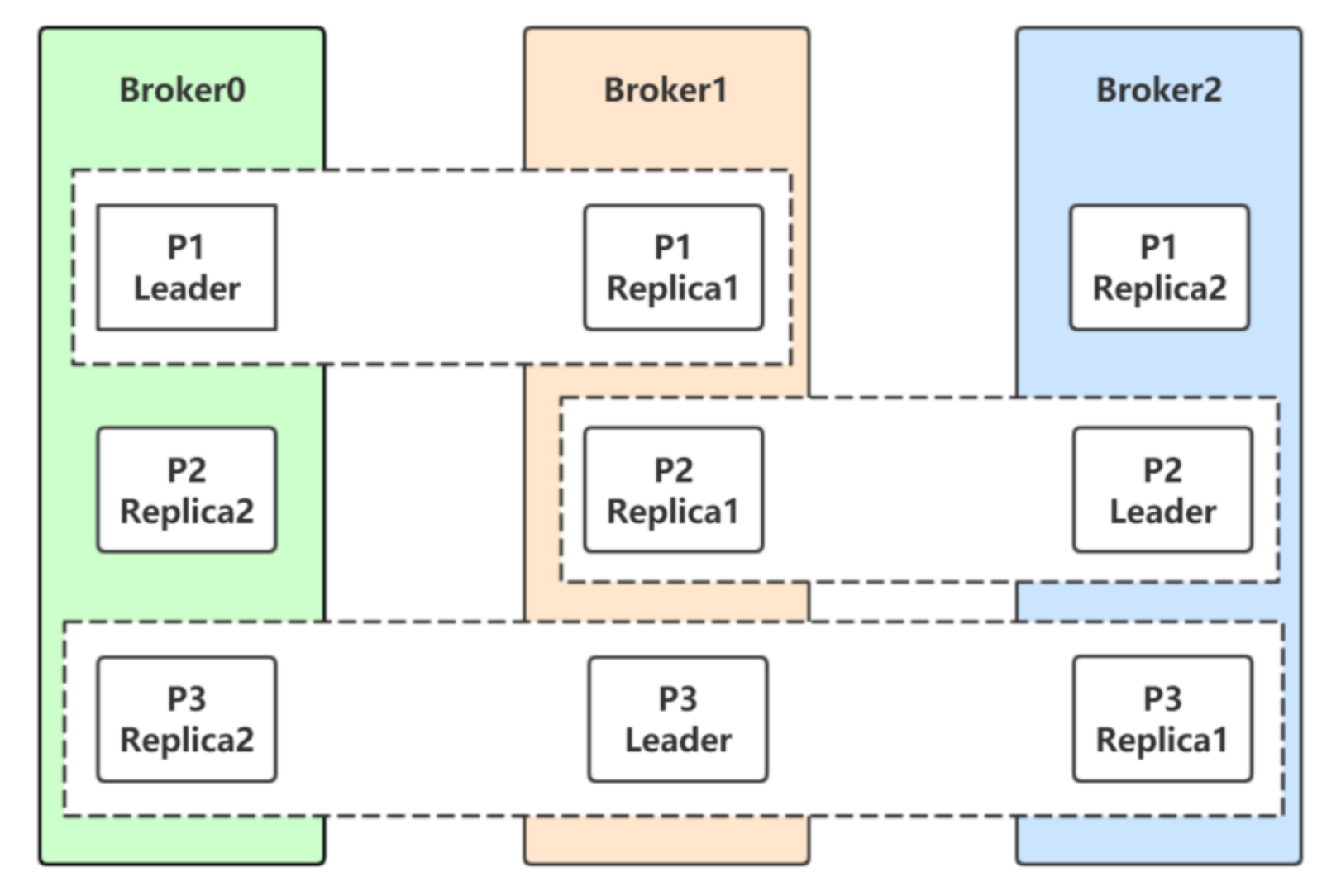
控制器就是⼀个broker。
控制器除了⼀般broker的功能,还负责Leader分区的选举。
集群控制器选举
集群⾥第⼀个启动的broker在Zookeeper中创建临时节点
<KafkaZkChroot>/controller
。
其他broker在该控制器节点创建Zookeeper watch对象,使⽤Zookeeper的监听机制接收该节点的变更。
即:Kafka通过Zookeeper的分布式锁特性选举集群控制器。
节点
<KafkaZkChroot>/controller
是⼀个zookeeper临时节点,其中"brokerid":0,表示当前控制器是
broker.id
为 0 的broker。
{"version":1, "brokerid":0, "timestamp": "1596122550321"}
每个新选出的控制器通过 Zookeeper 的条件递增操作获得⼀个全新的、数值更⼤的 controller epoch。其他 broker 在知道当前 controller epoch 后,如果收到由控制器发出的包含较旧epoch 的消息,就会忽略它们,以防⽌“脑裂”。
⽐如当⼀个Leader副本分区所在的broker宕机,需要选举新的Leader副本分区,有可能两个具有不同纪元数字的控制器都选举了新的Leader副本分区,如果选举出来的Leader副本分区不⼀样,听谁的?脑裂了。有了纪元数字,直接使⽤纪元数字最新的控制器结果。
纪元数字在节点
<KafkaZkChroot>/controller_epoch
节点中
结论:
- Kafka 使⽤ Zookeeper 的分布式锁选举控制器
- 其他节点监听zk的相关节点,当控制器宕机时可以重新选举控制器
- 控制器使⽤epoch 来避免“脑裂”。“脑裂”是指两个节点同时认为⾃⼰是当前的控制器。
2.6.3 可靠性保证
概念
- 创建Topic的时候可以指定
--replication-factor 3,表示分区的副本数,不要超过broker的数量。 - Leader是负责读写的节点,⽽其他副本则是Follower。Producer只把消息发送到Leader,Follower定期地到Leader上Pull数据。
- ISR是Leader负责维护的与其保持同步的Replica列表,即当前活跃的副本列表。如果⼀个Follow落后太多,Leader会将它从ISR中移除。落后太多意思是该Follow⻓时间没有向Leader发送fetch请求(参数:
replica.lag.time.max.ms默认值:10000)。 - 为了保证可靠性,可以设置
acks=all。Follower收到消息后,会像Leader发送ACK。⼀旦Leader收到了ISR中所有Replica的ACK,Leader就commit,那么Leader就向Producer发送ACK。
副本分配
当某个topic的
--replication-factor
为N(N>1)时,每个Partition都有N个副本,称作replica。原则上是将replica均匀的分配到整个集群上。不仅如此,partition的分配也同样需要均匀分配。为了更好的负载均衡。
副本分配的三个⽬标:
- 均衡地将副本分散于各个broker上
- 对于某个broker上分配的分区,它的其他副本在其他broker上
- 如果所有的broker都有机架信息,尽量将分区的各个副本分配到不同机架上的broker。
在不考虑机架信息的情况下:
- 第⼀个副本分区通过轮询的⽅式挑选⼀个broker,进⾏分配。该轮询从broker列表的随机位置进⾏轮询。
- 其余副本通过增加偏移进⾏分配。
分区Leader的选举
如果Leader宕机在Follower中重新选举⼀个Leader,但是选举哪个作为leader呢?Follower可能已经落后许多了,因此我们要选择的是”最新”的Follow:新的Leader必须拥有与原来Leader commit过的所有信息。
kafka动态维护⼀组同步leader数据的副本(ISR),只有这个组的成员才有资格当选leader,kafka副本写⼊不被认为是已提交(ack=all),直到所有的同步副本已经接收才认为。这组ISR保存在zookeeper,正因为如此,在ISR中的任何副本都有资格当选leader。
基于Zookeeper的选举⽅式:
⼤数据很多组件都有Leader选举的概念,如HBASE等。它们⼤都基于ZK进⾏选举,所有Follow都在ZK上⾯注册⼀个Watch,⼀旦Leader宕机,Leader对应的Znode会⾃动删除,那些Follow由于在Leader节点上注册了Watcher,故可以得到通知,就去参与下⼀轮选举,尝试去创建该节点,ZK会保证只有⼀个Follow创建成功,成为新的Leader。
但是这种⽅式有⼏个缺点:
- split-brain。这是由ZooKeeper的特性引起的,虽然ZooKeeper能保证所有Watch按顺序触发,但并不能保证同⼀时刻所有Replica“看”到的状态是⼀样的,这就可能造成不同Replica的响应不⼀致
- herd effect。如果宕机的那个Broker上的Partition⽐较多,会造成多个Watch被触发,造成集群内⼤量的调整
- ZooKeeper负载过重。每个Replica都要为此在ZooKeeper上注册⼀个Watch,当集群规模增加到⼏千个Partition时ZooKeeper负载会过重。
基于Controller的选举⽅式:
Kafka 0.8后的Leader Election⽅案解决了上述问题,它在所有broker中选出⼀个controller,所有Partition的Leader选举都由controller决定。controller会将Leader的改变直接通过RPC的⽅式(⽐ZooKeeper Queue的⽅式更⾼效)通知需为为此作为响应的Broker。同时controller也负责增删Topic以及Replica的重新分配。
- 优点:极⼤缓解了Herd Effect问题、减轻了ZK的负载,Controller与Leader/Follower之间通过RPC通信,⾼效且实时。
- 缺点:引⼊Controller增加了复杂度,且需要考虑Controller的Failover
当控制器发现⼀个 broker 已经离开集群,那些失去Leader副本分区的Follower分区需要⼀个新Leader(这些分区的⾸领刚好是在这个 broker 上)。
- 控制器需要知道哪个broker宕机了?
- 控制器需要知道宕机的broker上负责的时候是哪些分区Leader?
<KafkaChroot>/brokers/ids/0
保存该broker的信息,此节点为临时节点,如果broker节点宕机,该节点丢失。
集群控制器负责监听
ids
节点,⼀旦节点⼦节点发送变化,集群控制器得到通知。
控制器遍历这些Follower副本分区,并确定谁应该成为新Leader分区,然后向所有包含新Leader分区和现有Follower的 broker 发送请求。该请求消息包含了谁是新Leader副本分区以及谁是Follower副本分区的信息。随后,新Leader分区开始处理来⾃⽣产者和消费者的请求,⽽跟随者开始从新Leader副本分区消费消息。
当控制器发现⼀个 broker 加⼊集群时,它会使⽤ broker ID 来检查新加⼊的 broker 是否包含现有分区的副本。如果有,控制器就把变更通知发送给新加⼊的 broker 和其他 broker,新 broker上的副本分区开始从Leader分区那⾥消费消息,与Leader分区保持同步。
宕机恢复
处理Replica的恢复

- 只有当ISR列表中所有列表都确认接收数据后,该消息才会被commit(HW对应的消息)。因此只有m1被commit了。即使leader上有m1,m2,m3,consumer此时只能读到m1。
- 此时A宕机了。B变成了新的leader了,A从ISR列表中移除。B有m2,B会发给C,C收到m2后,m2被commit。
- B继续commit消息4和5
- A回来了。注意A并不能⻢上在isr列表中存在,因为它落后了很多,A会发生日志截断,把commit之后的数据删除,然后重新同步新leader数据,⽐如m2 m4 m5,它不落后太多的时候,才会回到ISR列表中。 思考:m3怎么办呢? 两种情况:A重试,重试成功了,m3就恢复了,但是乱序了。A重试不成功,此时数据就可能丢失了。
如果Replica都死了怎么办?
只要⾄少有⼀个replica,就能保证数据不丢失,可是如果某个partition的所有replica都死了怎么办?有两种⽅案:
- 等待在ISR中的副本恢复,并选择该副本作为Leader
- 选择第⼀个活过来的副本(不⼀定在 ISR中),作为Leader 可⽤性和⼀致性的⽭盾:如果⼀定要等待副本恢复,等待的时间可能⽐较⻓,甚⾄可能永远不可⽤。如果是第⼆种,不能保证所有已经commit的消息不丢失,但有可⽤性。 Kafka默认选⽤第⼆种⽅式,⽀持选择不能保证⼀致的副本。 可以通过参数
unclean.leader.election.enable禁⽤它。
Broker宕机怎么办?
Controller在Zookeeper的/brokers/ids节点上注册Watch。⼀旦有Broker宕机,其在Zookeeper对应的Znode会⾃动被删除,Zookeeper会fire Controller注册的Watch,Controller即可获取最新的幸存的Broker列表。
Controller决定set_p,该集合包含了宕机的所有Broker上的所有Partition。
对set_p中的每⼀个Partition:
- 从
/brokers/topics/[topic]/partitions/[partition]/state读取该Partition当前的ISR。 - 分区Leader的选举。如果该Partition的所有Replica都宕机了,则将新的Leader设置为-1。
- 将新的Leader,ISR和新的leader_epoch及controller_epoch写⼊
/brokers/topics/[topic]/partitions/[partition]/state。
[zk: localhost:2181(CONNECTED) 13] get /brokers/topics/topics_01/partitions/0/state
{"controller_epoch":1272,"leader":0,"version":1,"leader_epoch":4,"isr":[0,2]}
直接通过RPC向set_p相关的Broker发送LeaderAndISRRequest命令。Controller可以在⼀个RPC操作中发送多个命令从⽽提⾼效率。
Controller宕机怎么办?
同控制器选举
失效副本
系统维护⼀个ISR副本集合,即所有与Leader副本保持同步的副本列表。
replica.lag.time.max.ms 默认⼤⼩为10000。
当ISR中的⼀个Follower副本滞后Leader副本的时间超过参数 replica.lag.time.max.ms 指定的值时即判定为副本失效,需要将此Follower副本剔出除ISR。
具体实现原理:当Follower副本将Leader副本的LEO之前的⽇志全部同步时,则认为该Follower副本已经追赶上Leader副本,此时更新该副本的lastCaughtUpTimeMs标识。
分区Leader的broker会启动一个Kafka的副本管理器(ReplicaManager),ReplicaManager启动时会启动⼀个副本过期检测的定时任务,⽽这个定时任务会定时检查当前时间与副本的lastCaughtUpTimeMs差值是否⼤于参数 replica.lag.time.max.ms 指定的值。
Kafka源码注释中说明了⼀般有两种情况会导致副本失效:
- Follower副本进程卡住,在⼀段时间内没有向Leader副本发起同步请求,⽐如频繁的Full GC。
- Follower副本进程同步过慢,在⼀段时间内都⽆法追赶上Leader副本,⽐如IO开销过⼤。
如果通过⼯具增加了副本因⼦,那么新增加的副本在赶上Leader副本之前也都是处于失效状态的。
如果⼀个Follower副本由于某些原因(⽐如宕机)⽽下线,之后⼜上线,在追赶上Leader副本之前也是出于失效状态。
失效副本的分区个数是⽤于衡量Kafka性能指标的重要部分。Kafka本身提供了⼀个相关的指标,即UnderReplicatedPartitions,这个可以通过JMX访问:
kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions
取值范围是⼤于等于0的整数。注意:如果Kafka集群正在做分区迁移(kafka-reassign-partitions.sh)的时候,这个值也会⼤于0。
replica.lag.time.max.ms的误区
是不是可以理解为只要在 replica.lag.time.max.ms 时间内 follower 有同步消息,即认为该 follower 处于 ISR 中?
其实不是的。千万不要这么认为,因为这里还涉及一个 速率问题(你理解为蓄水池一个放水一个注水的问题)。
如果leader副本的消息流入速度大于follower副本的拉取速度时,你follower就是实时同步有什么用?
replica.lag.time.max.ms的正确理解是:
follower在过去的replica.lag.time.max.ms时间内,已经追赶上leader一次了就可以认为是ISR。
2.6.4 一致性
2.6.4.1 概念
水位标记:⽔位或⽔印(watermark)⼀词,表示位置信息,即位移(offset)。Kafka源码中使⽤的名字是⾼⽔位,HW(high watermark)。
副本⻆⾊:Kafka分区使⽤多个副本(replica)提供⾼可⽤。
每个分区副本对象都有两个重要的属性:LEO和HW。
- LEO:即⽇志末端位移(log end offset),记录了该副本⽇志中下⼀条消息的位移值。如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。另外,Leader LEO和Follower LEO的更新是有区别的。
- HW:表示在分区中的消息日志中,已经被成功复制到所有ISR(In-Sync Replicas,同步副本)的消息的位置。对于同⼀个副本对象⽽⾔,其HW值不会⼤于LEO值。⼩于等于HW值的所有消息都被认为是“已备份”的(replicated)。Leader副本和Follower副本的HW更新不同。

上图中,HW值是7,表示位移是07的所有消息都已经处于“已提交状态”(committed),⽽LEO值是14,8-13的消息就是未完全备份(fully replicated)——为什么没有14?LEO指向的是下⼀条消息到来时的位移。
消费者⽆法消费分区下Leader副本中位移⼤于分区HW的消息。
2.6.4.2 Follower副本何时更新LEO
Follower副本不停地向Leader副本所在的broker发送FETCH请求,⼀旦获取消息后写⼊⾃⼰的⽇志中进⾏备份。那么Follower副本的LEO是何时更新的呢?Kafka有两套Follower副本LEO:
- ⼀套LEO保存在Follower副本所在Broker的副本管理机中;
- 另⼀套LEO保存在Leader副本所在Broker的副本管理机中。Leader副本机器上保存了所有的follower副本的LEO。
Kafka使⽤前者帮助Follower副本更新其HW值;利⽤后者帮助Leader副本更新其HW。
- Follower副本的本地LEO何时更新? Follower副本的LEO值就是⽇志的LEO值,每当新写⼊⼀条消息,LEO值就会被更新。当Follower发送FETCH请求后,Leader将数据返回给Follower,此时Follower开始Log写数据,从⽽⾃动更新LEO值。
- Leader端Follower的LEO何时更新? Leader端的Follower的LEO更新发⽣在Leader在处理Follower FETCH请求时。⼀旦Leader接收到Follower发送的FETCH请求,它先从Log中读取相应的数据,给Follower返回数据前,先更新Follower的LEO。
2.6.4.3 Follower副本何时更新HW
Follower更新HW发⽣在其更新LEO之后,⼀旦Follower向Log写完数据,尝试更新⾃⼰的HW值。
⽐较当前LEO值与FETCH响应中Leader的HW值,取两者的⼩者作为新的HW值。
即:如果Follower的LEO⼤于Leader的HW,Follower HW值不会⼤于Leader的HW值。

2.6.4.4 Leader副本何时更新LEO
和Follower更新LEO相同,Leader写Log时⾃动更新⾃⼰的LEO值。
2.6.4.5 Leader副本何时更新HW值
Leader的HW值就是分区HW值,直接影响分区数据对消费者的可⻅性 。
Leader会尝试去更新分区HW的四种情况:
- Follower副本成为Leader副本时:Kafka会尝试去更新分区HW。
- Broker崩溃导致副本被踢出ISR时:检查下分区HW值是否需要更新是有必要的。
- ⽣产者向Leader副本写消息时:因为写⼊消息会更新Leader的LEO,有必要检查HW值是否需要更新
- Leader处理Follower FETCH请求时:⾸先从Log读取数据,之后尝试更新分区HW值
结论:
当Kafka broker都正常⼯作时,分区HW值的更新时机有两个:
- Leader处理PRODUCE请求时
- Leader处理FETCH请求时。
Leader如何更新⾃⼰的HW值?Leader broker上保存了⼀套Follower副本的LEO以及⾃⼰的LEO。当尝试确定分区HW时,它会选出所有满⾜条件的副本,⽐较它们的LEO(包括Leader的LEO),并选择最⼩的LEO值作为HW值。
需要满⾜的条件,(⼆选⼀):
- 处于ISR中
- 副本LEO落后于Leader LEO的时⻓不⼤于
replica.lag.time.max.ms参数值(默认是10s)
如果Kafka只判断第⼀个条件的话,确定分区HW值时就不会考虑这些未在ISR中的副本,但这些副本已经具备了“⽴刻进⼊ISR”的资格,因此就可能出现分区HW值越过ISR中副本LEO的情况——不允许。因为分区HW定义就是ISR中所有副本LEO的最⼩值。
2.6.4.6 HW和LEO正常更新案例
我们假设有⼀个topic,单分区,副本因⼦是2,即⼀个Leader副本和⼀个Follower副本。我们看下当producer发送⼀条消息时,broker端的副本到底会发⽣什么事情以及分区HW是如何被更新的。
初始状态
初始时Leader和Follower的HW和LEO都是0(严格来说源代码会初始化LEO为-1,不过这不影响之后的讨论)。Leader中的Remote LEO指的就是Leader端保存的Follower LEO,也被初始化成0。此时,⽣产者没有发送任何消息给Leader,⽽Follower已经开始不断地给Leader发送FETCH请求了,但因为没有数据因此什么都不会发⽣。值得⼀提的是,Follower发送过来的FETCH请求因为⽆数据⽽暂时会被寄存到Leader端的purgatory中,待500ms (
replica.fetch.wait.max.ms
参数)超时后会强制完成。倘若在寄存期间⽣产者发来数据,则Kafka会⾃动唤醒该FETCH请求,让Leader继续处理。
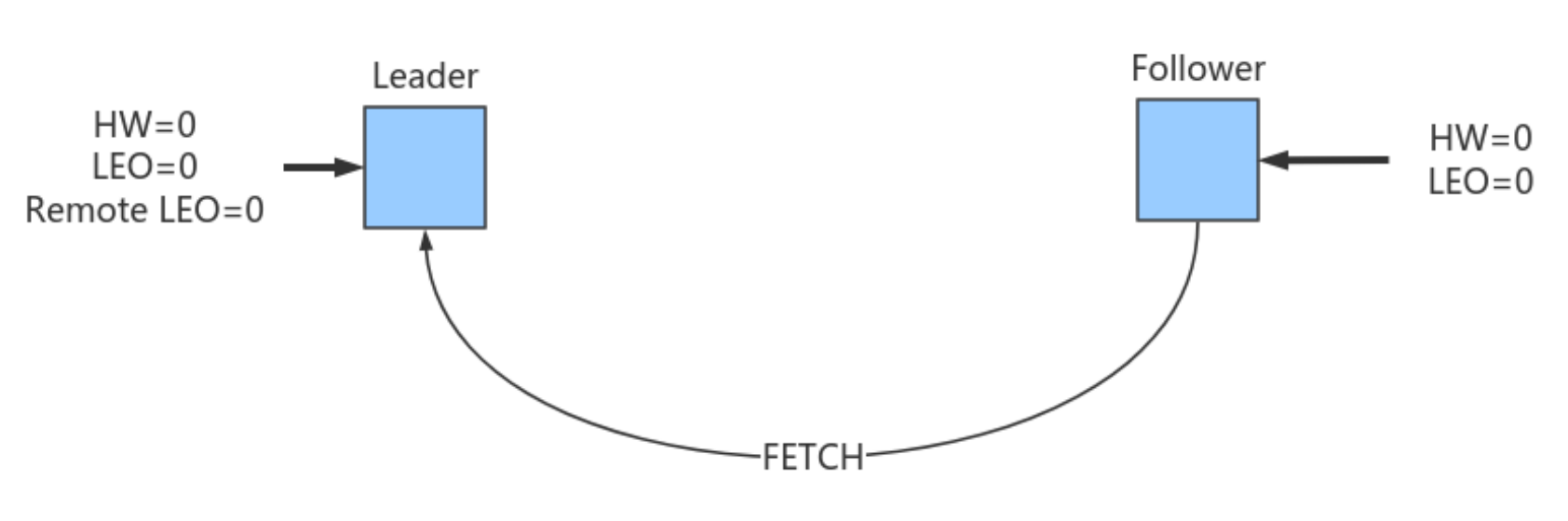
Follower发送FETCH请求在Leader处理完PRODUCE请求之后
producer给该topic分区发送了⼀条消息
此时的状态如下图所示:

如上图所示,Leader接收到PRODUCE请求主要做两件事情:
- 把消息写⼊Log,同时⾃动更新Leader⾃⼰的LEO
- 尝试更新Leader HW值。假设此时Follower尚未发送FETCH请求,Leader端保存的Remote LEO依然是0,因此Leader会⽐较它⾃⼰的LEO值和Remote LEO值,发现最⼩值是0,与当前HW值相同,故不会更新分区HW值(仍为0)
PRODUCE请求处理完成后各值如下,Leader端的HW值依然是0,⽽LEO是1,Remote LEO也是0。
属性阶段旧值新值备注Leader LEOPRODUCE处理完成01写⼊了⼀条数据Remote LEOPRODUCE处理完成00还未FetchLeader HWPRODUCE处理完成00min(LeaderLEO=1, RemoteLEO=0)=0Follower LEOPRODUCE处理完成00还未FetchFollower HWPRODUCE处理完成00min(LeaderHW=0, FollowerLEO=0)=0
假设此时follower发送了FETCH请求,则状态变更如下:

本例中当follower发送FETCH请求时,Leader端的处理依次是:
- 读取Log数据
- 更新remote LEO = 0(为什么是0? 因为此时Follower还没有写⼊这条消息。Leader如何确认Follower还未写⼊呢?这是通过Follower发来的FETCH请求中的Fetch offset来确定的)
- 尝试更新分区HW:此时Leader LEO = 1,Remote LEO = 0,故分区HW值= min(Leader LEO, Follower Remote LEO) = 0
- 把数据和当前分区HW值(依然是0)发送给Follower副本
⽽Follower副本接收到FETCH Response后依次执⾏下列操作:
- 写⼊本地Log,同时更新Follower⾃⼰管理的 LEO为1
- 更新Follower HW:⽐较本地LEO和 FETCH Response 中的当前Leader HW值,取较⼩者,Follower HW = 0
此时,第⼀轮FETCH RPC结束,我们会发现虽然Leader和Follower都已经在Log中保存了这条消息,但分区HW值尚未被更新,仍为0。
属性阶段旧值新值备注Leader LEOPRODUCE和Follower FETCH处理完成01写⼊了⼀条数据Remote LEOPRODUCE和Follower FETCH处理完成00第⼀次fetch中offset为0Leader HWPRODUCE和Follower FETCH处理完成00min(LeaderLEO=1,RemoteLEO=0)=0Follower LEOPRODUCE和Follower FETCH处理完成01同步了⼀条数据Follower HWPRODUCE和Follower FETCH处理完成00min(LeaderHW=0,FollowerLEO=1)=0
Follower第⼆轮FETCH
分区HW是在第⼆轮FETCH RPC中被更新的,如下图所示:

Follower发来了第⼆轮FETCH请求,Leader端接收到后仍然会依次执⾏下列操作:
- 读取Log数据
- 更新Remote LEO = 1(这次为什么是1了? 因为这轮FETCH RPC携带的fetch offset是1,那么为什么这轮携带的就是1了呢,因为上⼀轮结束后Follower LEO被更新为1了)
- 尝试更新分区HW:此时leader LEO = 1,Remote LEO = 1,故分区HW值= min(Leader LEO, Follower Remote LEO) = 1。
- 把数据(实际上没有数据)和当前分区HW值(已更新为1)发送给Follower副本作为Response
同样地,Follower副本接收到FETCH response后依次执⾏下列操作:
- 写⼊本地Log,当然没东⻄可写,Follower LEO也不会变化,依然是1。
- 更新Follower HW:⽐较本地LEO和当前Leader LEO取⼩者。由于都是1,故更新follower HW = 1 。
属性阶段旧值新值备注Leader LEO第⼆次Follower FETCH处理完成11未写⼊新数据Remote LEO第⼆次Follower FETCH处理完成01第2次fetch中offset为1Leader HW第⼆次Follower FETCH处理完成01min(RemoteLEO,LeaderLEO)=1Follower LEO第⼆次Follower FETCH处理完成11未写⼊新数据Follower HW第⼆次Follower FETCH处理完成01第2次fetch resp中的LeaderHW和本地FollowerLEO都是1
此时消息已经成功地被复制到Leader和Follower的Log中且分区HW是1,表明消费者能够消费offset = 0的消息。
FETCH请求保存在purgatory中,PRODUCE请求到来
当Leader⽆法⽴即满⾜FECTH返回要求的时候(⽐如没有数据),那么该FETCH请求被暂存到Leader端的purgatory中(炼狱),待时机成熟尝试再次处理。Kafka不会⽆限期缓存,默认有个超时时间(500ms),⼀旦超时时间已过,则这个请求会被强制完成。当寄存期间还没超时,⽣产者发送PRODUCE请求从⽽使之满⾜了条件以致被唤醒。此时,Leader端处理流程如下:
- Leader写Log(⾃动更新Leader LEO)
- 尝试唤醒在purgatory中寄存的FETCH请求
- 尝试更新分区HW
2.6.4.7 HW和LEO异常案例
Kafka使⽤HW值来决定副本备份的进度,⽽HW值的更新通常需要额外⼀轮FETCH RPC才能完成。但这种设计是有问题的,可能引起的问题包括:
- 备份数据丢失
- 备份数据不⼀致
数据丢失
使⽤HW值来确定备份进度时其值的更新是在下⼀轮RPC中完成的。如果Follower副本在标记上⽅的的第⼀步与第⼆步之间发⽣崩溃,那么就有可能造成数据的丢失。
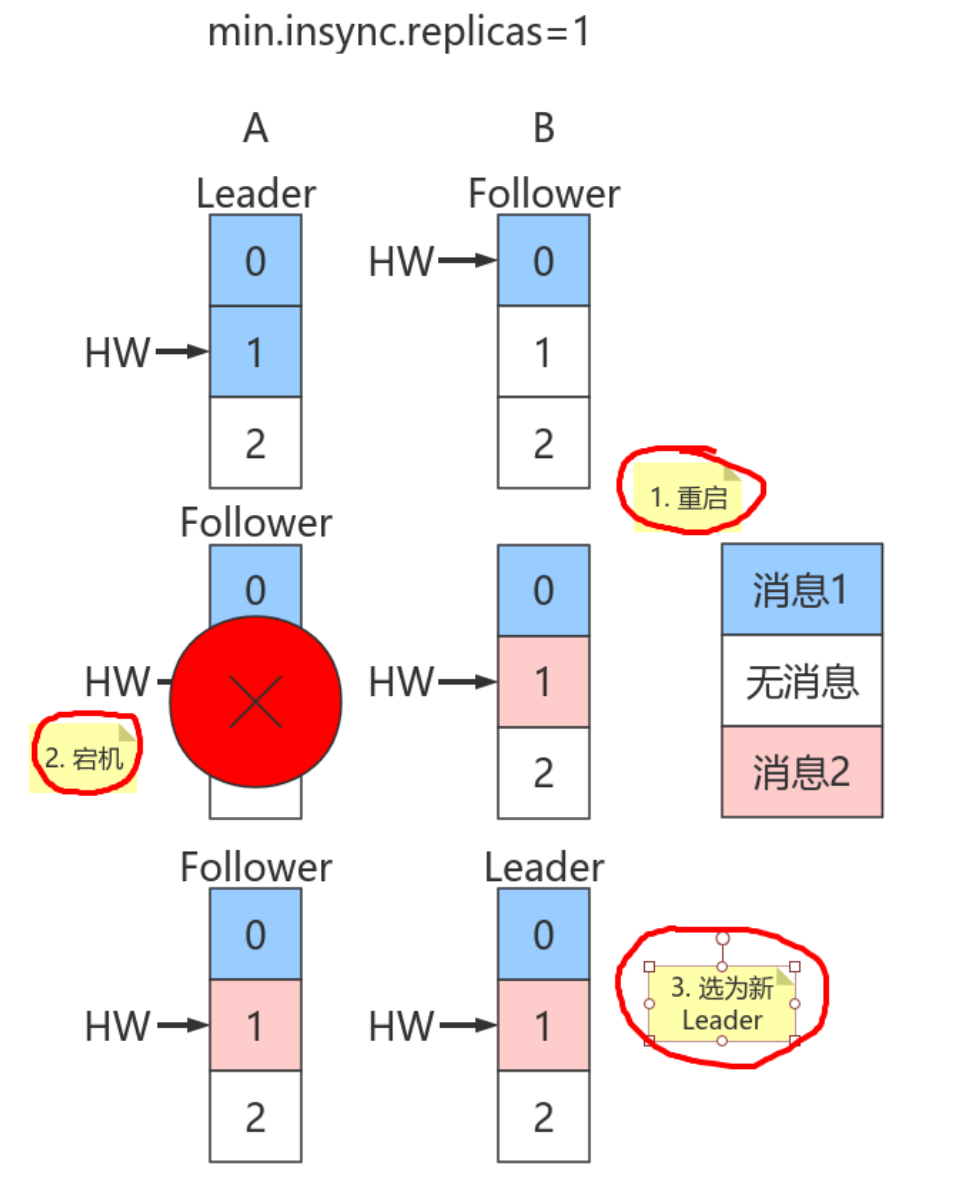
上图中有两个副本:A和B。开始状态是A是Leader。
假设⽣产者
min.insync.replicas
为1,那么当⽣产者发送两条消息给A后,A写⼊Log,此时Kafka会通知⽣产者这两条消息写⼊成功。
代属性阶段旧值新值备注1Leader LEOPRODUCE和Follower FETCH处理完成01写⼊了⼀条数据1Remote LEOPRODUCE和Follower FETCH处理完成00第⼀次fetch中offset为01Leader HWPRODUCE和Follower FETCH处理完成00min(LeaderLEO=1,FollowerLEO=0)=01Follower LEOPRODUCE和Follower FETCH处理完成01同步了⼀条数据1Follower HWPRODUCE和Follower FETCH处理完成00min(LeaderHW=0, FollowerLEO=1)=02Leader LEO第⼆次Follower FETCH处理完成12写⼊了第⼆条数据2Remote LEO第⼆次Follower FETCH处理完成01第2次fetch中offset为12Leader HW第⼆次Follower FETCH处理完成01min(RemoteLEO=1,LeaderLEO=2)=12Follower LEO第⼆次Follower FETCH处理完成12写⼊了第⼆条数据2Follower HW第⼆次Follower FETCH处理完成01min(LeaderHW=1,FollowerLEO=2)=13Leader LEO第三次Follower FETCH处理完成22未写⼊新数据3Remote LEO第三次Follower FETCH处理完成12第3次fetch中offset为23Leader HW第三次Follower FETCH处理完成12min(RemoteLEO=2,LeaderLEO)=23Follower LEO第三次Follower FETCH处理完成22未写⼊新数据3Follower HW第三次Follower FETCH处理完成12第3次fetch resp中的LeaderHW和本地FollowerLEO都是2
但是在broker端,Leader和Follower的Log虽都写⼊了2条消息且Leader的HW已经被更新到2,但Follower HW尚未被更新还是1,表中最后⼀条未执⾏。
倘若此时副本B所在的broker宕机,那么重启后B会发生日志截断(log truncation),⾃动把LEO调整到之前的HW值1,将offset = 1的那条消息从log中删除,并调整LEO = 1。此时follower副本底层log中就只有⼀条消息,即offset = 0的消息!
B重启之后需要给A发FETCH请求,但若A所在broker机器在此时宕机,那么Kafka会令B成为新的Leader,⽽当A重启回来后和B进行同步时也会执⾏⽇志截断,将HW调整回1。这样,offset=1的消息就从两个副本的log中被删除,也就是说这条已经被⽣产者认为发送成功的数据丢失。
丢失数据的前提是
min.insync.replicas=1
时,⼀旦消息被写⼊Leader端Log即被认为是committed。延迟⼀轮FETCH RPC更新HW值的设计使follower HW值是异步延迟更新,若在这个过程中Leader发⽣变更,那么成为新Leader的Follower的HW值就有可能是过期的,导致⽣产者本是成功提交的消息被删除。
Leader和Follower数据离散
除了可能造成的数据丢失以外,该设计还会造成Leader的Log和Follower的Log数据不⼀致。
如Leader端记录序列:m1,m2,m3,m4,m5,…;Follower端序列可能是m1,m3,m4,m5,…。
看图:

假设:A是Leader,A的Log写⼊了2条消息,但B的Log只写了1条消息。Leader分区HW更新到2,但B的HW还是1(osr),同时⽣产者
min.insync.replicas
仍然为1。
假设A和B所在Broker同时宕机,B先重启回来,因此B成为Leader,分区HW = 1。假设此时⽣产者发送了第3条消息(红⾊表示)给B,于是B的log中offset = 1的消息变成了红框表示的消息,同时分区HW更新到2(A还没有回来,就B⼀个副本,故可以直接更新HW⽽不⽤理会A)之后A重启回来,需要执⾏⽇志截断,但发现此时分区HW=2⽽A之前的HW值也是2,故不做任何调整。此后A和B将以这种状态继续正常⼯作。
显然,这种场景下,A和B的Log中保存在offset = 1的消息是不同的记录,从⽽引发不⼀致的情形出现。
2.6.4.8 Leader Epoch使⽤
Kafka 解决方案
造成上述两个问题的根本原因在于
- HW值被⽤于衡量副本备份的成功与否。
- 在出现失败重启时作为⽇志截断的依据。
但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,故这中间发⽣的任何崩溃都可能导致HW值的过期。
Kafka从0.11引⼊了
leader epoch
来取代HW值。Leader端使⽤内存保存Leader的epoch信息,即使出现上⾯的两个场景也能规避这些问题。
所谓Leader epoch实际上是⼀对值:<epoch, offset>:
- epoch表示Leader的版本号,从0开始,Leader变更过1次,epoch+1
- offset对应于该epoch版本的Leader写⼊第⼀条消息的offset。因此假设有两对值:
<0, 0>
<1, 120>
则表示第⼀个Leader从位移0开始写⼊消息;共写了120条[0, 119];⽽第⼆个Leader版本号是1,从位移120处开始写⼊消息。
- Leader broker中会保存这样的⼀个缓存,并定期地写⼊到⼀个checkpoint⽂件中。
- 当Leader写Log时它会尝试更新整个缓存:如果这个Leader⾸次写消息,则会在缓存中增加⼀个条⽬;否则就不做更新。
- 每次副本变为Leader时会查询这部分缓存,获取出对应Leader版本的位移,则不会发⽣数据不⼀致和丢失的情况.
规避数据丢失

场景和之前大致是类似的,只不过引用 Leader Epoch 机制后,Follower 副本 B 重启回来后,需要向 A 发送一个特殊的请求去获取 Leader 的 LEO 值。在这个例子中,该值为 2。当获知到 Leader LEO=2 后,B 发现该 LEO 值不比它自己的 LEO 值小,而且缓存中也没有保存任何起始位移值大于2 的 Epoch 条目(<1,2>里的start offset为2),因此 B 无需执行任何日志截断操作。这是对高水位机制的一个明显改进,即副本是否执行日志截断不再依赖于高水位进行判断。
现在,副本 A 宕机了,B 成为 Leader。同样地,当 A 重启回来后,执行与 B 相同的逻辑判断,发现也不用执行日志截断,至此位移值为 1 的那条消息在两个副本中均得到保留。后面当生产者程序向 B 写入新消息时,副本 B 所在的 Broker 缓存中,会生成新的 Leader Epoch 条目:[Epoch=1, Offset=2]。之后,副本 B 会使用这个条目帮助判断后续是否执行日志截断操作。这样,通过 Leader Epoch 机制,Kafka 完美地规避了这种数据丢失场景。
规避数据不一致

B 第一个恢复过来并成为新的 leader。
之后 B 写入消息 m3(红色的1),并将 LEO 和 HW 更新至2,此时的 LeaderEpoch 已经从 LE0 增至 LE1 了
紧接着 A 也恢复过来成为 Follower 并向 B 发送 OffsetsForLeaderEpochRequest 请求,此时 A 的 LeaderEpoch 为 LE0。B 根据 LE0 查询到LE0+1=LE1,LE1对应的 offset 为1并返回给 A,A 就截断日志并删除了消息 m2(蓝色的1)。之后 A 发送 FetchRequest 至 B 请求来同步数据,最终A和B中都有两条消息 m1 和 m3,HW 和 LEO都为2,并且 LeaderEpoch 都为 LE1,如此便解决了数据不一致的问题。
2.6.5 消息重复
消息重复主要发⽣在以下三个阶段:
- 生产者阶段
- broker阶段
- 消费者阶段
2.6.5.1 生产者阶段重复场景
根本原因
⽣产发送的消息没有收到正确的broke响应,导致producer重试。
producer发出⼀条消息,broke落盘以后因为⽹络等种种原因发送端得到⼀个发送失败的响应或者⽹络中断,然后producer收到⼀个可恢复的Exception重试消息导致消息重复。
重试过程

说明:
new KafkaProducer()后创建一个线程KafkaThread扫描RecordAccumulator中是否有消息- 调用
KafkaProducer.send()发送消息,实际上只是把消息保存到RecordAccumulator中 - 后台线程
KafkaThread扫描到RecordAccumulator中有消息后,将消息发送到Kafka集群 - 如果发送成功,那么返回成功
- 如果发送失败,那么判断是否允许重试。如果不允许重试,那么返回失败结果;如果允许重试,把消息再保存到
RecordAccumulator中,等待后台线程KafkaThread扫描再次发送
可恢复异常说明
异常是
RetriableException
类型或者
TransactionManager
允许重试;
RetriableException
类继承关系如下:

记录顺序问题
如果设置
max.in.flight.requests.per.connection
大于1 (默认5, 单个连接.上发送的未确认请求的最大数量,表示上一个发出的请求没有确认下一个请求又发出了)。大于1可能会改变记录的顺序,因为如果将两个batch发送到单个分区,第一个batch处理失败并重试, 但是第二个batch处理成功,那么第二个batch处理中的记录可能先出现被消费。
设置
max.in.flight.requests.per.connection
为1,可能会影响吞吐量,可以解决单个生产者发送顺序问题。如果多个生产者,生产者1先发送一一个请求, 生产者2后发送请求,此时生产者1返回可恢复异常,重试一定次数成功了。虽然生产者1先发送消息,但生产者2发送的消息会被先消费。
解决方案
启动Kafka的幂等性
要启动Kafka的幂等性,设置
enable.idempotence=true
,以及
ack=all
和
retries>1
ack=0,不重试
可能会丢失消息,适用于吞吐量指标重要性高于数据丢失,如:日志收集
2.6.5.2 生产者和broker阶段消息丢失场景
根本原因
ack=0,不重试
生产者发送消息完毕,不管结果,如果发送失败也就丢失了
ack=1,Leader crash
生产者发送消息完毕,只等待Leader写入成功就返回了,Leader 分区丢失了,此时Follower没来得及同步,消息丢失
**
unclean.leader.election.enable
配置true**
允许选举ISR以外的副本作为leader,会导致数据丢失,默认为false。 生产者发送异步消息,只等待Lead写入成功就返回,Leader分区丢失,此时ISR中没有Follower, Leader从OSR中选举,因为OSR中本来落后于Leader造成消息丢失。
解决方案
禁用unclean选举,ack=all
ack=all / -1,tries > 1,unclean.leader.election.enable:false
生产者发完消息,等待Follower同步完再返回, 如果异常则重试。副本的数量可能影响吞吐量,不超过5个,一般三个。
不允许unclean Leader选举。
**配置:
min.insync.replicas>1
**
当生产者将
acks
设置为all (或-1 )时,
min.insync.replicas>1
。指定确认消息写成功需要的最小副本数量。达不到这个最小值,生产者将引发一个异常(要么是
NotEnoughReplicas
, 要么是
NotEnoughReplicasAfterAppend
)。
当一起使用时,
min.insync.replicas
和
ack
允许执行更大的持久性保证。一个典型的场景 是创建一个复制因子为3的主题,设置
min.insync
复制到2个, 用 all 配置发送。将确保如果大多数副本没有收到写操作,则生产者将引发异常。
失败的 offset 单独记录
生产者发送消息,会自动重试,遇到不可恢复异常会抛出,这时可以捕获异常记录到数据库或缓存,进行单独处理。
2.6.5.3 消费者数据重复场景及解决方案
根本原因
数据消费完没及时提交 offset 到 broker
场景
消息消费端在消费过程中挂掉没有及时提交offset到broke,另一个消费端启动拿之前记录的offset开始消费,由于offset的滞后性可能会导致新启动的客户端有少量重复消费。
解决方案
取消自动提交
每次消费完或者程序退出时手动提交。这可能也没法保证一条不重复
下游做幂等
一般是让 下游做幂等或者尽量每消费-条消息都记录offset, 对于少数严格的场景可能需要把offset或唯一ID (例如订单ID)和下游状态更新放在同一个数据库里面做事务来保证精确的一次更新或者在下游数据表里面同时记录消费offset,然后更新下游数据的时候用消费位移做乐观锁拒绝旧位移的数据更新。
2.6.6__consumer_offsets
Zookeeper不适合⼤批量的频繁写⼊操作。
Kafka 1.0.2将consumer的位移信息保存在Kafka内部的topic中,即
__consumer_offsets
主题,并且默认提供了
kafka_consumer_groups.sh
脚本供⽤户查看consumer信息。
创建topic “tp_test_01”
[root@node1 ~]# kafka-topics.sh --zookeeper node1:2181/myKafka --create --topic tp_test_01 --partitions 5 --replication-factor 1
使⽤kafka-console-producer.sh脚本⽣产消息
[root@node1 ~]# for i in `seq 100`; do echo "hello kafka $i" >> messages.txt; done
[root@node1 ~]# kafka-console-producer.sh --broker-list node1:9092 --topic tp_test_01 < messages.txt
由于默认没有指定key,所以根据round-robin⽅式,消息分布到不同的分区上。 (本例中⽣产了100条消息)
验证消息⽣产成功
[root@node1 ~]# kafka-console-producer.sh --broker-list node1:9092 --topic tp_test_01 < messages.txt
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
[root@node1 ~]# kafka-run-class.sh kafka.tools.GetOffsetShell --brokerlist node1:9092 --topic tp_test_01 --time -1
tp_test_01:2:20
tp_test_01:4:20
tp_test_01:1:20
tp_test_01:3:20
tp_test_01:0:20
结果输出表明100条消息全部⽣产成功!
创建⼀个console consumer group
[root@node1 ~]#kafka-console-consumer.sh --bootstrap-server node1:9092 --topic tp_test_01 --from-beginning
获取该consumer group的group id(后⾯需要根据该id查询它的位移信息)
[root@node1 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092 --list
查询__consumer_offsets topic所有内容
注意:运⾏下⾯命令前先要在
consumer.properties
中设置
exclude.internal.topics=false
[root@node1 ~]# kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server node1:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
默认情况下
__consumer_offsets
有50个分区,如果你的系统中
consumer group
也很多的话,那么这个命令的输出结果会很多。
计算指定consumer group在__consumer_offsets topic中分区信息
这时候就⽤到了第5步获取的
group.id
(本例中是
console-consumer-49366
)。Kafka会使⽤下⾯公式计算该group位移保存在
__consumer_offsets
的哪个分区上:
Math.abs(groupID.hashCode()) % numPartitions
对应的分区=Math.abs("console-consumer-49366".hashCode()) % 50 = 19
,即
__consumer_offsets
的分区19保存了这个
consumer group
的位移信息。
获取指定consumer group的位移信息
[root@node1 ~]# kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 19 --broker-list node1:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"
下⾯是输出结果:
...
[console-consumer-49366,tp_test_01,3]::[OffsetMetadata[20,NO_METADATA],CommitTime 1596424702212,ExpirationTime 1596511102212]
[console-consumer-49366,tp_test_01,4]::[OffsetMetadata[20,NO_METADATA],CommitTime 1596424702212,ExpirationTime 1596511102212]
[console-consumer-49366,tp_test_01,0]::[OffsetMetadata[20,NO_METADATA],CommitTime 1596424702212,ExpirationTime 1596511102212]
上图可⻅,该
consumer group
果然保存在分区11上,且位移信息都是对的(这⾥的位移信息是已消费的位移,严格来说不是第3步中的位移。由于我的consumer已经消费完了所有的消息,所以这⾥的位移与第3步中的位移相同)。另外,可以看到
__consumer_offsets topic
的每⼀⽇志项的格式都是:
[Group, Topic, Partition]::[OffsetMetadata[Offset, Metadata], CommitTime, ExpirationTime]
。
2.7 延迟队列
2.7.1 简介
TimingWheel是kafka时间轮的实现,时间轮的⼀格都包含了⼀个TimerTaskList数组,数组的元素是TimerTaskEntry事件,这⼀格的时间跨度为tickMs,同⼀个TimerTaskList中的事件都是相差在⼀个tickMs跨度内的,整个时间轮的时间跨度为interval = tickMs * wheelSize,该时间轮能处理的时间范围在cuurentTime到currentTime + interval之间的事件。
当添加⼀个事件他的超时时间⼤于整个时间轮的跨度时, expiration >= currentTime + interval,则会将该事件向上级传递,传递直到某⼀个时间轮满⾜expiration < currentTime + interval,
然后计算对应位于哪⼀格,然后将事件放进去,重新设置超时时间,然后放进jdk延迟队列
else if (expiration < currentTime + interval) {
// Put in its own bucket
val virtualId = expiration / tickMs
val bucket = buckets((virtualId % wheelSize.toLong).toInt)
bucket.add(timerTaskEntry)
// Set the bucket expiration time
if (bucket.setExpiration(virtualId * tickMs)) {
// The bucket needs to be enqueued because it was an expired bucket
// We only need to enqueue the bucket when its expiration time has changed, i.e. the wheel has advanced
// and the previous buckets gets reused; further calls to set the expiration within the same wheel cycle
// will pass in the same value and hence return false, thus the bucket with the same expiration will not
// be enqueued multiple times.
queue.offer(bucket)
}
SystemTimer会取出queue中的TimerTaskList,根据expiration将currentTime往前推进,然后把⾥⾯所有的事件重新放进时间轮中,因为ct推进了,所以有些事件会在第0格,表示到期了,然后将任务提交到java线程池中处理。
服务端在处理客户端的请求,针对不同的请求,可能不会⽴即返回响应结果给客户端。在处理这类请求时,服务端会为这类请求创建延迟操作对象放⼊延迟缓存队列中。延迟缓存的数据结构类似MAP,延迟操作对象从延迟缓存队列中完成并移除有两种⽅式:
- 延迟操作对应的外部事件发⽣时,外部事件会尝试完成延迟缓存中的延迟操作 。
- 如果外部事件仍然没有完成延迟操作,超时时间达到后,会强制完成延迟的操作 。
2.7.2 延时操作接口
DelayedOperation
接⼝表示延迟的操作对象。此接⼝的实现类包括延迟加⼊,延迟⼼跳,延迟⽣产,延迟拉取。延迟接⼝相关的⽅法:
tryComplete:尝试完成,外部事件发⽣时会尝试完成延迟的操作。该⽅法返回值为true,表示可以完成延迟操作,会调⽤强制完成的⽅法(forceComplete)。返回值为false,表示不可以完成延迟操作。forceComplete:强制完成,两个地⽅调⽤,尝试完成⽅法(tryComplete)返回true时;延迟操作超时时。run:线程运⾏,延迟操作超时后,会调⽤线程的运⾏⽅法,只会调⽤⼀次,因为超时就会发⽣⼀次。超时后会调⽤强制完成⽅法(forceComplete),如果返回true,会调⽤超时的回调⽅法。onComplete:完成的回调⽅法。onExpiration:超时的回调⽅法。
外部事件触发完成和超时完成都会调⽤
forceComplete()
,并调⽤
onComplete()
。
forceComplete
和
onComplete
只会调⽤⼀次。多线程下⽤原⼦变量来控制只有⼀个线程会调⽤
onComplete
和
forceComplete
。
延迟⽣产和延迟拉取完成时的回调⽅法,尝试完成的延迟操作
副本管理器在创建延迟操作时,会把回调⽅法传给延迟操作对象。当延迟操作完成时,在
onComplete
⽅法中会调⽤回调⽅法,返回响应结果给客户端。
创建延迟操作对象需要提供请求对应的元数据。延迟⽣产元数据是分区的⽣产结果;延迟拉取元数据是分区的拉取信息。
创建延迟的⽣产对象之前,将消息集写⼊分区的主副本中,每个分区的⽣产结果会作为延迟⽣产的元数据。
创建延迟的拉取对象之前,从分区的主副本中读取消息集,但并不会使⽤分区的拉取结果作为延迟拉取的元数据
延迟⽣产返回给客户端的响应结果可以直接从分区的⽣产结果中获取,⽽延迟的拉取返回给客户端的响应结果不能直接从分区的拉取结果中获取。
元数据包含返回结果的条件是:从创建延迟操作对象到完成延迟操作对象,元数据的含义不变。
对于延迟的⽣产,服务端写⼊消息集到主副本返回的结果是确定的。是因为ISR中的备份副本还没有全部发送应答给主副本,才会需要创建延迟的⽣产。服务端在处理备份副本的拉取请求时,不会改变分区的⽣产结果。最后在完成延迟⽣产的操作对象时,服务端就可以把 “创建延迟操作对象” 时传递给它的分区⽣产结果直接返回给⽣产者 。
对于延迟的拉取,读取了主副本的本地⽇志,但是因为消息数量不够,才会需要创建延迟的拉取,⽽不⽤分区的拉取结果⽽是⽤分区的拉取信息作为延迟拉取的元数据,是因为在尝试完成延迟拉取操作对象时,会再次读取主副本的本地⽇志,这次的读取有可能会让消息数量达到⾜够或者超时,从⽽完成延迟拉取操作对象。这样创建前和完成时延迟拉取操作对象的返回结果是不同的。但是拉取信息不管读取多少次都是⼀样的。
延迟的⽣产的外部事件是:一定数量的ISR副本发送了拉取请求;
备份副本的延迟拉取的外部事件是:追加消息集到主副本;
消费者的延迟拉取的外部事件是:增加主副本的最⾼⽔位。
2.7.3 尝试完成延迟的生产
服务端处理⽣产者客户端的⽣产请求,将消息集追加到对应主副本的本地⽇志后,会等待ISR中所有的备份刚本都向主副本发送应答 。⽣产请求包括多个分区的消息集,每个分区都有对应的ISR集合。当所有分区的ISR副本都向对应分区的主副本发送了应答,⽣产请求才能算完成。⽣产请求中虽然有多个分区,但是延迟的⽣产操作对象只会创建⼀个。
判断分区的ISR副本是否都已经向主副本发送了应答,需要检查ISR中所有备份副本的偏移量是否到了延迟⽣产元数据的指定偏移量(延迟⽣产的元数据是分区的⽣产结果中包含有追加消息集到本地⽇志返回下⼀个偏移量)。所以ISR所有副本的偏移量只要等于元数据的偏移量,就表示备份副本向主副本发送了应答。由于当备份副本向主副本发送拉取请求,服务端读取⽇志后,会更新对应备份副本的偏移量数据。所以在具体的实现上,备份副本并不需要真正发送应答给主副本,因为主副本所在消息代理节点的分区对象已经记录了所有副本的信息,所以尝试完成延迟的⽣产时,根据副本的偏移量就可以判断备份副本是否发送了应答。进⽽检查分区是否有⾜够的副本赶上指定偏移量,只需要判断主副本的最⾼⽔位是否等于指定偏移量(最⾼⽔位的值会选择ISR中所有备份副本中最⼩的偏移量来设置,最⼩的值都等于了指定偏移量,那么就代表所有的ISR都发送了应答)。
总结:
总结:服务端创建的延迟⽣产操作对象,在尝试完成时根据主副本的最⾼⽔位是否等于延迟⽣产操作对象中元数据的指定偏移量来判断。具体步骤:
- 服务端处理⽣产者的⽣产请求,写⼊消息集到Leader副本的本地⽇志。
- 服务端返回追加消息集的下⼀个偏移量,并且创建⼀个延迟⽣产操作对象。元数据为分区的⽣产结果(其中就包含下⼀个偏移量的值)
- 服务端处理备份副本的拉取请求,⾸先读取主副本的本地⽇志。
- 服务端返回给备份副本读取消息集,并更新备份副本的偏移量。
- 选择ISR备份副本中最⼩的偏移量更新主副本的最⾼⽔位。
- 如果主副本的最⾼⽔位等于指定的下⼀个偏移量的值,就完成延迟的⽣产。
2.7.4 尝试完成延迟的拉取
服务端处理消费者或备份副本的拉取请求,如果创建了延迟的拉取操作对象,⼀般都是客户端的消费进度能够⼀直赶上主副本。⽐如备份副本同步主副本的数据,备份副本如果⼀直能赶上主副本,那么主副本有新消息写⼊,备份副本就会⻢上同步。但是针对备份副本已经消费到主副本的最新位置,⽽主副本并没有新消息写⼊时:服务端没有⽴即返回空的拉取结果给备份副本,这时会创建⼀个延迟的拉取操作对象,如果有新的消息写⼊,服务端会等到收集⾜够的消息集后,才返回拉取结果给备份副本,有新的消息写⼊,但是还没有收集到⾜够的消息集,等到延迟操作对象超时后,服务端会读取新写⼊主副本的消息后,返回拉取结果给备份副本(完成延迟的拉取时,服务端还会再读取⼀次主副本的本地⽇志,返回新读取出来的消息集)。
客户端的拉取请求包含多个分区,服务端判断拉取的消息⼤⼩时,会收集拉取请求涉及的所有分区。只要消息的总⼤⼩超过拉取请求设置的最少字节数,就会调⽤forceComplete()⽅法完成延迟的拉取。
外部事件尝试完成延迟的⽣产和拉取操作时的判断条件:
操作参数完成条件延迟的生产指定的偏移量Leader分区HW超过指定偏移量延迟的拉取最少的字节数Leader结束偏移量-拉取偏移量>最少的字节数
Leader结束偏移量-拉取偏移量=拉取到消息⼤⼩。对于备份副本的延迟拉取,主副本的结束偏移量是它的最新偏移量(LEO)。对于消费者的拉取延迟,主副本的结束偏移量是它的最⾼⽔位(HW)。备份副本要时刻与主副本同步,消费者只能消费到主副本的最⾼⽔位。
2.7.5 ⽣产请求和拉取请求的延迟缓存
客户端的⼀个请求包括多个分区,服务端为每个请求都会创建⼀个延迟操作对象。⽽不是为每个分区创建⼀个延迟操作对象。服务端的“延迟操作缓存”管理了所有的“延迟操作对象”,缓存的键是每⼀个分区,缓存的值是分区对应的延迟操作列表。
⼀个客户端请求对应⼀个延迟操作,⼀个延迟操作对应多个分区。在延迟缓存中,⼀个分区对应多个延迟操作。延迟缓存中保存了分区到延迟操作的映射关系。
根据分区尝试完成延迟的操作,因为⽣产者和消费者是以分区为最⼩单位来追加消息和消费消息。虽然延迟操作的创建是针对⼀个请求,但是⼀个请求中会有多个分区,在⽣产者追加消息时,⼀个⽣产请求中不同分区包含的消息是不⼀样的。这样追加到分区对应的主副本的本地⽇志中,有的分区就可以去完成延迟的拉取,但是有的分区有可能还达不到完成延迟拉取操作的条件。同样完成延迟的⽣产也⼀样。所以在延迟缓存中要以分区为键来存储各个延迟操作。
由于⼀个请求创建⼀个延迟操作,⼀个请求⼜会包含多个分区,所以不同的延迟操作可能会有相同的分区。在加⼊到延迟缓存时,每个分区都对应相同的延迟操作。外部事件发⽣时,服务端会以分区为粒度,尝试完成这个分区中的所有延迟操作 。 如果指定分区对应的某个延迟操作可以被完成,那么延迟操作会从这个分区的延迟操作列表中移除。但这个延迟操作还有其他分区,其他分区中已经被完成的延迟操作也需要从延迟缓存中删除。但是不会⽴即被删除,因为分区作为延迟缓存的键,在服务端的数量会很多。只要分区对应的延迟操作完成了⼀个,就要⽴即检查所有分区,对服务端的性能影响⽐较⼤。所以采⽤⼀个清理器,会负责定时地清理所有分区中已经完成的延迟操作。
副本管理器针对⽣产请求和拉取请求都分别有⼀个全局的延迟缓存。⽣产请求对应延迟缓存中存储了延迟的⽣产。拉取请求对应延迟缓存中存储了延迟的拉取。
延迟缓存提供了两个⽅法:
- tryCompleteElseWatch():尝试完成延迟的操作,如果不能完成,将延迟操作加⼊延迟缓存中。⼀旦将延迟操作加⼊延迟缓存的监控,延迟操作的每个分区都会监视该延迟操作。换句话说就是每个分区发⽣了外部事件后,都会去尝试完成延迟操作。
- checkAndComplete():参数是延迟缓存的键,外部事件调⽤该⽅法,根据指定的键尝试完成延迟缓存中的延迟操作。
延迟缓存在调⽤tryCompleteElseWatch⽅法将延迟操作加⼊延迟缓存之前,会先尝试⼀次完成延迟的操作,如果不能完成,会调⽤⽅法将延迟操作加⼊到分区对应的监视器,之后还会尝试完成⼀次延迟操作,如果还不能完成,会将延迟操作加⼊定时器。如果前⾯的加⼊过程中,可以完成延迟操作后,那么就可以不⽤加⼊到其他分区的延迟缓存了。
延迟操作不仅存在于延迟缓存中,还会被定时器监控。定时器的⽬的是在延迟操作超时后,服务端可以强制完成延迟操作返回结果给客户端。延迟缓存的⽬的是让外部事件去尝试完成延迟操作。
2.7.6 监视器
延迟缓存的每个键都有⼀个监视器(类似每个分区有⼀个监视器),以链表结构来管理延迟操作。当外部事件发⽣时,会根据给定的键,调⽤这个键的对应监视器的tryCompleteWatch()⽅法,尝试完成监视器中所有的延迟操作。监视器尝试完成所有延迟操作的过程中,会调⽤每个延迟操作的tryComplete()⽅法,判断能否完成延迟的操作。如果能够完成,就从链表中删除对应的延迟操作。
2.7.7 清理线程
清理线程的作⽤是清理所有监视器中已经完成的延迟操作。
2.7.8 定时器
服务端创建的延迟操作会作为⼀个定时任务,加⼊定时器的延迟队列中。当延迟操作超时后,定时器会将延迟操作从延迟队列中弹出,并调⽤延迟操作的运⾏⽅法,强制完成延迟的操作。
定时器使⽤延迟队列管理服务端创建的所有延迟操作,延迟队列是定时器中保存定时任务列表的全局数据结构
延迟队列的每个元素是定时任务列表(TimerTaskList数组),⼀个定时任务列表可以存放多个定时任务条⽬(TimerTaskEntry)。
服务端创建的延迟操作对象,会先包装成定时任务条⽬,加⼊时间轮,延迟队列中保存的是时间轮的槽表(TimerTaskList数组)。
时间轮和延迟队列的关系:
- 定时器拥有⼀个全局的延迟队列和时间轮,所有时间轮公⽤⼀个计数器。
- 时间轮持有延迟队列的引⽤。
- 定时任务条⽬添加到时间轮对应的时间格(槽)中,并且把该槽表也会加⼊到延迟队列中。
- ⼀个线程会将超时的定时任务列表会从延迟队列的poll⽅法弹出。定时任务列表超时并不⼀定代表定时任务超时,将定时任务重新加⼊时间轮,如果加⼊失败,说明定时任务确实超时,提交给线程池执⾏。
- 延迟队列的poll⽅法只会弹出超时的定时任务列表,队列中的每个元素(定时任务条目)按照超时时间排序,如果第⼀个定时任务列表都没有过期,那么其他定时任务列表也⼀定不会超时。
延迟操作本身的失效时间是客户端请求设置的,延迟队列的元素(每个定时任务列表)也有失效时间,当定时任务列表中的getDelay()⽅法返回值⼩于等于0,就表示定时任务列表已经过期,需要⽴即执⾏。
如果当前的时间轮放不下加⼊的时间时,就会创建⼀个更⾼层的时间轮。定时器只持有第⼀层的时间轮的引⽤,并不会持有更⾼层的时间轮。因为第⼀层的时间轮会持有第⼆层的时间轮的引⽤,第⼆层会持有第三层的时间轮的引⽤。定时器将定时任务加⼊到当前时间轮,要判断定时任务的失效时间⾸是否在当前时间轮的范围内,如果不在当前时间轮的范围内,则要将定时任务上升到更⾼⼀层的时间轮中。时间轮包含了定时器全局的延迟队列。
时间轮中的变量:tickMs=1:表示⼀格的⻓度是1毫秒;wheelSize=20表示⼀共20格,时间轮的范围就是20毫秒,定时任务的失效时间⼩于等于20毫秒的都会加⼊到这⼀层的时间轮中;interval=tickMs*wheelSize=20,如果需要创建更⾼⼀层的时间轮,那么低⼀层的时间轮的interval的值作为⾼⼀层数据轮的tickMs值;currentTime当前时间轮的当前时间,往前移动时间轮,主要就是更新当前时间轮的当前时间,更新后重新加⼊定时任务条⽬。
2.7.9 一道面试题
⾯试题⼤致上是这样的:消费者去Kafka⾥拉去消息,但是⽬前Kafka中⼜没有新的消息可以提供,那么Kafka会如何处理?
如下图所示,两个follower副本都已经拉取到了leader副本的最新位置,此时⼜向leader副本发送拉取请求,⽽leader副本并没有新的消息写⼊,那么此时leader副本该如何处理呢?可以直接返回空的拉取结果给follower副本,不过在leader副本⼀直没有新消息写⼊的情况下,follower副本会⼀直发送拉取请求,并且总收到空的拉取结果,这样徒耗资源,显然不太合理。

这⾥就涉及到了Kafka延迟操作的概念。Kafka在处理拉取请求时,会先读取⼀次⽇志⽂件,如果收集不到⾜够多(
fetchMinBytes
,由参数
fetch.min.bytes
配置,默认值为1)的消息,那么就会创建⼀个延时拉取操作(
DelayedFetch
)以等待拉取到⾜够数量的消息。当延时拉取操作执⾏时,会再读取⼀次⽇志⽂件,然后将拉取结果返回给follower副本。
延迟操作不只是拉取消息时的特有操作,在Kafka中有多种延时操作,⽐如延时数据删除、延时⽣产等。
对于延时⽣产(消息)⽽⾔,如果在使⽤⽣产者客户端发送消息的时候将acks参数设置为-1,那么就意味着需要等待ISR集合中的所有副本都确认收到消息之后才能正确地收到响应的结果,或者捕获超时异常。

假设某个分区有3个副本:leader、follower1和follower2,它们都在分区的ISR集合中。为了简化说明,这⾥我们不考虑ISR集合伸缩的情况。Kafka在收到客户端的⽣产请求后,将消息3和消息4写⼊leader副本的本地⽇志⽂件,如上图所示。
由于客户端设置了acks为-1,那么需要等到follower1和follower2两个副本都收到消息3和消息4后才能告知客户端正确地接收了所发送的消息。如果在⼀定的时间内,follower1副本或follower2副本没能够完全拉取到消息3和消息4,那么就需要返回超时异常给客户端。⽣产请求的超时时间由参数request.timeout.ms配置,默认值为30000,即30s。


那么这⾥等待消息3和消息4写⼊follower1副本和follower2副本,并返回相应的响应结果给客户端的动作是由谁来执⾏的呢?在将消息写⼊leader副本的本地⽇志⽂件之后,Kafka会创建⼀个延时的⽣产操作(DelayedProduce),⽤来处理消息正常写⼊所有副本或超时的情况,以返回相应的响应结果给客户端。
延时操作需要延时返回响应的结果,⾸先它必须有⼀个超时时间(delayMs),如果在这个超时时间内没有完成既定的任务,那么就需要强制完成以返回响应结果给客户端。其次,延时操作不同于定时操作,定时操作是指在特定时间之后执⾏的操作,⽽延时操作可以在所设定的超时时间之前完成,所以延时操作能够⽀持外部事件的触发。
就延时⽣产操作⽽⾔,它的外部事件是所要写⼊消息的某个分区的HW(⾼⽔位)发⽣增⻓。也就是说,随着follower副本不断地与leader副本进⾏消息同步,进⽽促使HW进⼀步增⻓,HW每增⻓⼀次都会检测是否能够完成此次延时⽣产操作,如果可以就执⾏以此返回响应结果给客户端;如果在超时时间内始终⽆法完成,则强制执⾏。
延时拉取操作,它也同样如此,也是由超时触发或外部事件触发⽽被执⾏的。超时触发很好理解,就是等到超时时间之后触发第⼆次读取⽇志⽂件的操作。外部事件触发就稍复杂了⼀些,因为拉取请求不单单由follower副本发起,也可以由消费者客户端发起,两种情况所对应的外部事件也是不同的。如果是follower副本的延时拉取,它的外部事件就是消息追加到了leader副本的本地⽇志⽂件中;如果是消费者客户端的延时拉取,它的外部事件可以简单地理解为HW的增⻓
2.8 重试队列
kafka没有重试机制不⽀持消息重试,也没有死信队列,因此使⽤kafka做消息队列时,需要⾃⼰实现消息重试的功能。
自己实现(创建新的kafka主题作为重试队列):
- 创建⼀个topic作为重试topic,⽤于接收等待重试的消息。
- 普通topic消费者设置待重试消息的下⼀个重试topic。
- 从重试topic获取待重试消息储存到redis的zset中,并以下⼀次消费时间排序
- 定时任务从redis获取到达消费事件的消息,并把消息发送到对应的topic
- 同⼀个消息重试次数过多则不再重试
版权归原作者 一瓶橄榄菜 所有, 如有侵权,请联系我们删除。