
一.什么是Spark
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群.
二.Spark的特点
1.快速
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中。
2.易用
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法。
3.通用
Spark提供了统一的解决方案。Spark可以用于,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。

4.随处运行
用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

5.代码简洁
spark支持使用scala,python等语言编写代码。
三.spark与mapreduce的区别?
1、Spark的速度比MapReduce快,Spark把运算的中间数据存放基于内存,迭代计算效率更高;mapreduce的中间结果需要落地,基于磁盘,比较影响性能;
2、spark容错性高,它通过弹性分布式数据集RDD来实现高效容错;mapreduce容错可能只能重新计算了,成本较高;
3、spark更加通用,spark提供了transformation和action这两大类的多个功能API,另外还有流式处理sparkstreaming模块、图计算GraphX等;mapreduce只提供了map和reduce两种操作,流计算以及其他模块的支持比较缺乏,计算框架(API)比较局限;
4、spark框架和生态更为复杂,很多时候spark作业都需要根据不同业务场景的需要进行调优已达到性能要求;mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,但是运行较为稳定,适合长期后台运行;
四.spark的运行架构与原理及作业流程
Spark的运行架构主要包括以下几个组件:
- Driver:驱动器是Spark应用程序的主要控制器,负责定义应用程序的逻辑和执行流程。它将应用程序划分为一系列任务,并将这些任务分发给集群中的执行器进行执行。
- Cluster Manager:集群管理器负责在集群中启动和管理Spark应用程序的执行。常见的集群管理器有Standalone、YARN和Mesos等。
- Executors:执行器是在集群中运行Spark任务的工作进程。每个执行器负责在其所在节点上执行任务,并将结果返回给驱动器。
- Spark Context:Spark上下文是与集群通信的主要接口,它负责与集群管理器通信、分配资源、调度任务等。
Spark的原理主要包括以下几个方面:
- 弹性分布式数据集(RDD):RDD是Spark的核心抽象,它代表了一个可并行操作的分布式数据集合。RDD可以在内存中缓存,以便快速访问和重用。
- DAG调度器:Spark将应用程序的操作转化为有向无环图(DAG),并通过DAG调度器将任务划分为不同的阶段,以便并行执行。
- 内存计算:Spark利用内存计算技术将数据存储在内存中,以加快数据处理速度。通过减少磁盘IO,Spark可以显著提高性能。
- 数据分区:Spark将数据划分为多个分区,每个分区可以在不同的节点上并行处理。这种数据分区的方式可以提高并行度和性能。
- 任务调度:Spark使用任务调度器将任务分发给集群中的执行器,并根据数据位置和资源可用性进行优化调度。
spark的三种运行模式:
1.Standalone 模式:standalone模式也叫作独立模式,自带完整的服务,可单独部署到一个集群中,无序依赖任何其他资源管理系统。
2.YARN运行模式:Spark使用Hadoop的YARN组件进行资源与任务调度,真正意义上spark与外部对接协作。
3.Local模式:在本地部署单个Spark服务,比较适合简单了解spark目录结构,熟悉配置文件,简单跑一下demo示例等调试场景。
五.spark核心数据集RDD
RDD是什么?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD是spark core的底层核心。
RDD的特点:
容错的弹性:数据丢失可以自动恢复;
存储的弹性:内存与磁盘的自动切换;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
分布式:数据存储在集群不同节点上/计算分布式。
数据集: RDD封装了计算逻辑,并不保存数据。
数据抽象: RDD是一个抽象类,需要子类具体实现。
不可变: RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑。
可分区、并行计算。
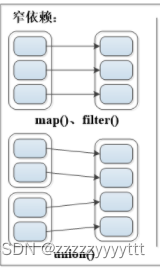
宽依赖与窄依赖
RDD之间有一系列的依赖关系,依赖关系又分为宽依赖和在窄依赖。
宽依赖(Shuffle Dependency) :表现为存在一个父RDD 的一个分区对应一个子 RDD 的多个分区。
窄依赖 (Narrow Dependency) :表现为一个父RDD 的分区对应于一个子 RDD 的分区或者多个父 RDD 的分区对应于一个子 RDD 的分区。

六.了解scala的特性
(1)面向对象
Scala是一-种纯粹的面向对象语言。一个对象的类型和行为是由类和特征描述的。类通过子类化和灵活的混合类进行扩展,成为多重继承的可靠解决方案。
(2)函数式编程
Scala提供了轻量级语法来定义匿名函数,支持高阶函数,允许函数嵌套,并支持函数柯里化。Scala 的样例类与模式匹配支持函数式编程语言中的代数类型。Scala 的单例对象提供了方便的方法来组合不属于类的函数。用户还可以使用Scala 的模式匹配,编写类似正则表达式的代码处理可扩展标记语言( Extensible Markup Language, XML )格式的数据。
(3)静态类型
Scala配备了表现型的系统,以静态的方式进行抽象,以安全和连贯的方式进行使用,系统支持将通用类、内部类、抽象类和复合类作为对象成员,也支持隐式参数、转换和多态方法等,这为抽象编程的安全重用和软件类型的安全扩展提供了强大的支持。
(4)可扩展
在实践中,专用领域的应用程序开发往往需要特定的语言扩展。Scala 提供了许多独特的语言机制,可以以库的形式无缝添加新的语言结构。
七.Scala部署安装步骤
(1)上传并解压安装scala安装包
tar -zxvf scala-2.2.12.12.tgz
(2)设置环境变量
vim /etc/profile
#SCALA
export SCALA_HOME=/usr/local/soft/scala-2.12.12
export PATH=$PATH:${SCALA_HOME}/bin
source /etc/profile
使环境变量生效
(3)验证scala 启动成功
scala -version
scala启动成功
scala
八.spark部署与安装
(1)上传并解压安装spark安装包
tar -zxvf / export/ software/ spark-3.0.3-bin-hadoop2.7.tgz
(2)设置环境变量
vim /etc/profile
#SPARK
export SPARK_HOME=/usr/local/soft/spark-3.0.3
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
source /etc/profile
使环境变量生效
(3)修改配置文件.
cd spark/ conf/
先备份文件
cp spark env.sh.template spark env.sh
cp slaves. template slaves
vim spark-env.sh
加一些环境变量:
修改spark- env.sh文件,加以下内容:
export SCALA_HOME=/usr/local/soft/scala-2.12.12
export JAVA_HOME=/usr/local/soft/jdk1.8.0_202
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.3/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
修改从节点ip
vi slaves 修改内容为slave1 slave2(我的子机分别为是slave1 slave2)
(4)分发文件
scp -r /usr/local/soft/spark-3.0.3/ slave1:/usr/local/soft/
scp -r /usr/local/soft/spark-3.0.3/ slave2:/usr/local/soft/
(5)分别在slave1 slave2上设置环境变量
vim /etc/profile
#SPARK
export SPARK_HOME=/usr/local/soft/spark-3.0.3
export PATH=$PATH:${SPARK_HOME}/binexport
export PATH=$PATH:${SPARK_HOME}/sbin
source /etc/profile
使环境变量生效
(6)启动集群:spark目录下:
./start-all.sh
查看节点:
Master:

Slave1:
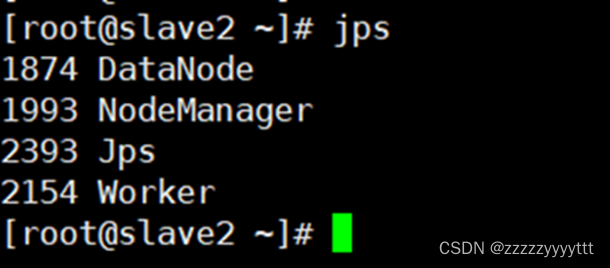
Scala2:
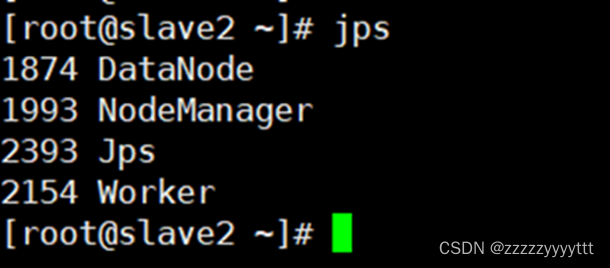
在主节点master上出现Master 在s1上出现Worker在s2上出现Worker
Spark-shell

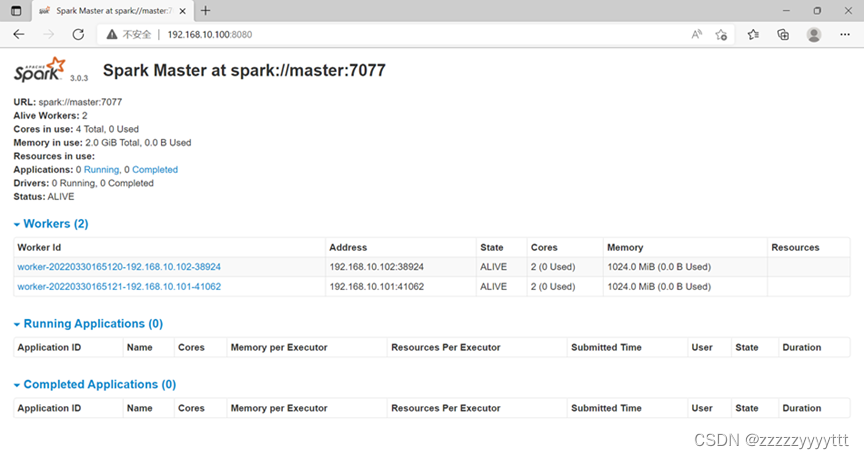
浏览器查看192.168.10.100:8080
版权归原作者 zzzzzyyyyttt 所有, 如有侵权,请联系我们删除。