
问题描述:
曾经碰到了一道抄答案都没抄明白的题目(#_<-),卡在了不懂大佬是怎么绕过preg_match()的,所以在此总结~
博文内容:(1)官方手册介绍与留言;(2)博主们的思路实践整理~
官方介绍:
链接在此:PHP: preg_match - Manual

作为匹配检查的大函数,可以带五个小参数:pattern、subject、matches、flags、offset,其中前两个:pattern、subject是必须要填写的后三个不填写的话会有自动的默认值
pattern:需要被检查的字符串(通常就是我们传到网页的字符串)~
subject:需要被比较的字符串(通常就是被WAF拉黑的字符串)~
matches:搜索结果,$matches[0]将包含完整模式匹配到的文本, $matches[1] 将包含第一个捕获子组匹配到的文本,以此类推默认为null
flags:有以下几种返回值可选——preg_offset_capture(匹配成功时返回字符串的起始位置)、preg_offset_capture(不设置时,匹配失败无返回值;设置时,匹配失败会返回Null)默认为0
offset:指定检查字符串时的开始位置默认为0
preg_match()这个函数,如果pattern匹配到指定subject,则返回 1;如果没有匹配到则返回 0, 或者在失败时返回false~(也可能返回等同于false的非布尔值)
官方介绍中还有一些范例说明,值得摘要一下~
(1)模式分隔符后写i,表示这是一个大小写不敏感的搜索,例**"/php/i"**可匹配PHP~
(2)模式中的\b标记单词边界,表示只会完全匹配,而不会匹配某单词的部分内容,例**"/\bweb\b/i"**只会匹配web的大小写形式,而不能匹配cobweb(单词中含有web)~
(3)捕获截断功能,例如:
** preg_match('@^(?:http://)?([^/]+)@i',"http://www.php.net/index.html", $matches);**这句话的输出结果是www.php.net,是捕获了http://之后,/之前的内容~
^ 表示匹配输入字符串的开始位置~
(?:) 表示匹配但是不记住项,例如(?http://)捕获不含http://本身的字符串开始的位置~
[^/] 表示不匹配/以及之后的内容~
+ 表示多次匹配,否则只会输入单个字符w~
i 表示匹配不区分大小写~
** preg_match('/[^.]+.[^.]+$/', "www.php.net", $matches);**这句话的输出结果是php.net是截取了第一个.的所有内容,同时保留了第二个.后到行尾的内容
$ 表示匹配输入字符串的结尾位置~
————————————————————————————————————
对于正则表达式有兴趣可以参考下面的三个网页,反正我自己看到那些鬼画符真的很头大~
参考1:php正则表达式中preg_match函数的详解-PHP中文网
参考2:正则表达式 – 语法 | 菜鸟教程 (runoob.com)
参考3:正则表达式 - JavaScript | MDN (mozilla.org)
如果想做到简单的截断功能,**strstr()**也真的可以考虑一下~
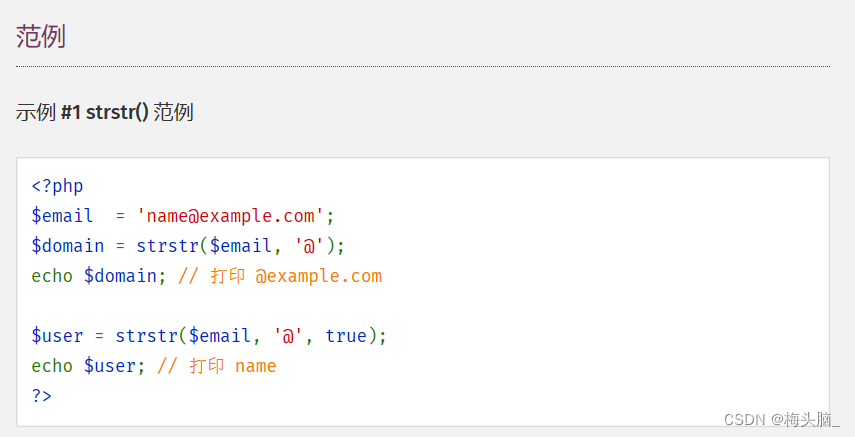
↑图片内容摘自:PHP: strstr - Manual
————————————————————————————————————
(4)命名子组,这个貌似是把数组的值赋予属性吧~在ctf中我还暂时没有看到过这种用法...

↑图片内容摘自:PHP: preg_match - Manual
————————————————————————————————————
类似的功能,数组在创建的过程中,用**array()**函数本身就可以实现命名...
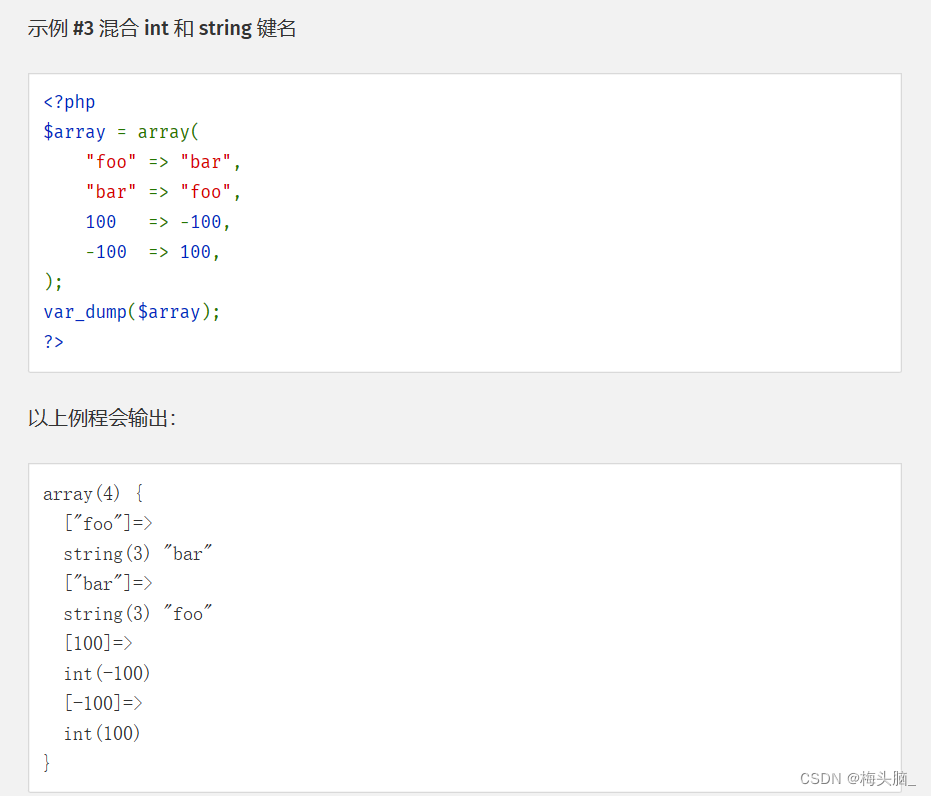
↑图片内容摘自:PHP: Array 数组 - Manual
以上就是官方的介绍内容,下面整理一下大佬们的绕过方式~
绕过整理:
参考1:preg_match()绕过的问题总结 - 无据 - 博客园 (cnblogs.com)
参考2:preg_match函数绕过 | 码农网 (codercto.com)
推荐preg_match()的绕过:PHP preg_系列漏洞小结 | 国光 (sqlsec.com)
以下绕过我都是直接贴到编辑器里运行的,菜鸟教程在线编辑器 (runoob.com)~
首先我们贴一个最最简单的代码,要求输入flag.php,黑名单是flag~
<?php
$a='flag.php'; //目标是输入flag.php
if(!preg_match("/flag/",$a)==false){ //如果匹配中出现了flag
die('这样子是不行的~'); //绕过失败,输出:这样子是不行的~
}
echo '成功啦~'; //绕过成功
?>
运行一下试试结果,可以看出来直接被判定失败了~

1 数组绕过
代码的第二行更换参数,把传入的代码从字符串形式改为数组形式,通常是以下三种形式~
$a[]='flag.php';
$a=array('flag.php');
$a=['flag.php'];
(注意以下第三行$a=['flag.php'];,粗心的小白不要像我一样写成$a='[flag.php]';这样,会被判定成字符串的,导致绕过失败的...)
执行结果如下图所示,绕过成功啦~

2 回溯次数绕过(我失败啦)
preg_match()的回溯次数可以设定,默认是1000000次(中英文次数不同,实测回溯为100w次,5.3.7版本以前是10w次),这个可以在php.ini中查询~


↑图片内容摘自:PHP: 运行时配置 - Manual
↓如果对php.ini的其他内容感兴趣,可以参考这个:PHP: php.ini 配置选项列表 - Manual,虽然与本博文的关系不大,不过对于其他的ctf题目会很有帮助的~

所以我们这里可以采用函数str_repeat(),强行输入一个字符串好多好多次~~
首先,我们把1输入100w次,看看分别有什么效果~
$a=str_repeat('1',1000000);
可以看到,这个运行结果是一片白茫茫,没有输出失败判定,说明成功啦~不过准确来说,以上内容只能使preg_match()挂掉,严格来说不算绕过...

我还没想到什么其他的利用方法...比如说后面加一个flag.php,就被当场抓包了...以下是我的失败案例一览...而且从运行速度上推断,我怀疑他只是检查了’1‘和'flag.php'两个变量,没有执行回溯,这个小机灵鬼~
$a=str_repeat('1',1000000).'flag.php';//失败示范1,flag被抓包~
$a=str_repeat('flag.php',1000000);//失败示范2,flag被抓包~
$a='flag.php'*1000000;//不知道是不是失败,echo该变量的结果是0,也就是php不认识这个东西...相当于输入一个0~



3 换行符绕过(我失败啦)
怀疑这是一种存在于传说中的匹配方法...我这边怎么测试都是不好使...
$a="\nflag.php\n";//失败范例1~
$a="%0aflag.php%0a";//失败范例2~


emm...暂时写到这里,后续我再想想...一定会有其他绕过方法的,遇到题目我会再补充的~
4 preg_match_all()绕过
**preg_match() 函数在第一次匹配后将会停止搜索,但preg_match_all() **函数会一直匹配到结尾,就很适合多行命令的执行~
针对正则表达式,看看通过没有被禁掉的字符,有希望达到多行命令执行的效果~
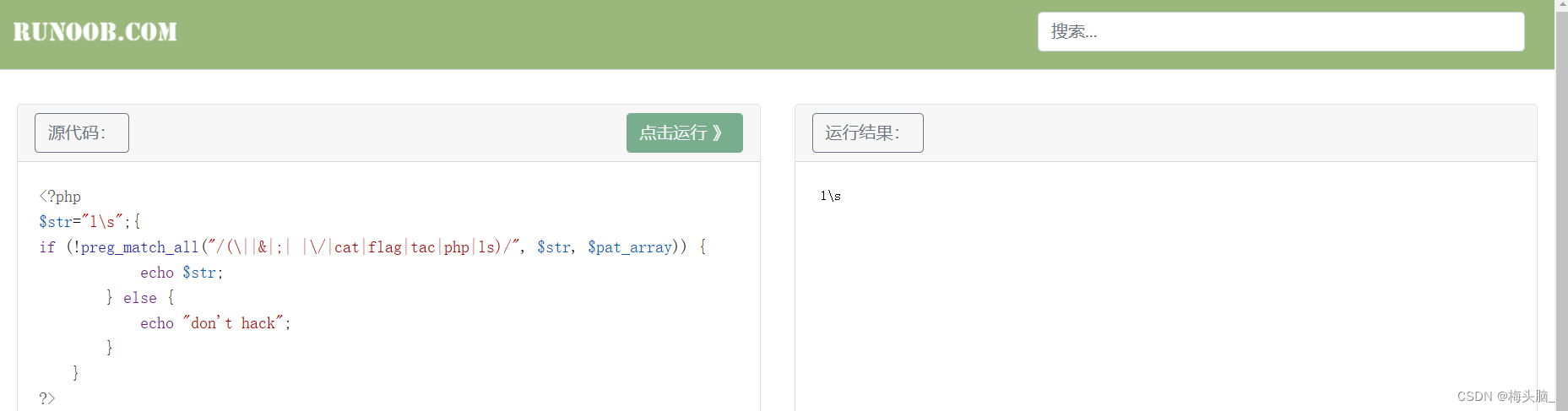
** 相关题目:**Web安全攻防世界04 unseping(江苏工匠杯)
暂时就想到这些,话说这篇已经是修正一次的结果了,以后还是会根据做题经历有所增补的~
博文写得模糊或者有误之处,欢迎留言讨论与批评~
码字不易,若有所帮助,可以点赞支持一下博主嘛?感谢~(●'◡'●)
版权归原作者 梅头脑_ 所有, 如有侵权,请联系我们删除。