
15.说说循环依赖?
什么是循环依赖?
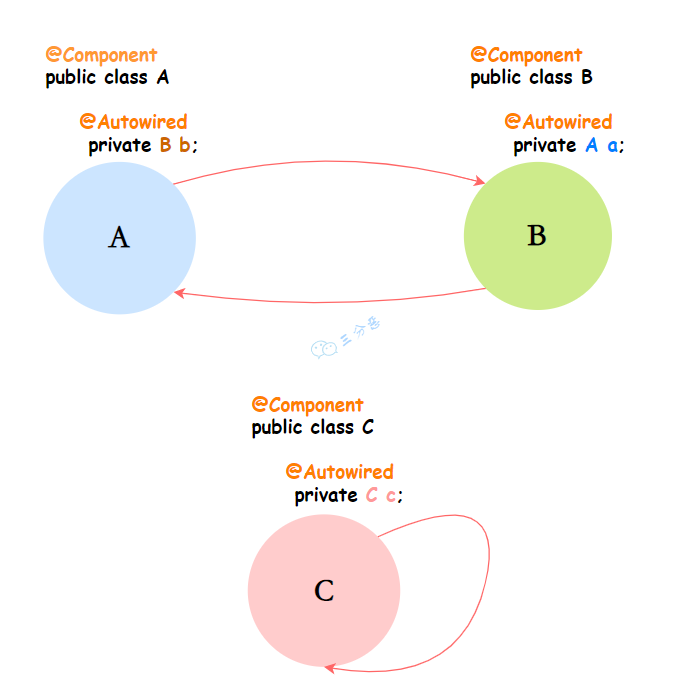
Spring循环依赖
Spring 循环依赖:简单说就是自己依赖自己,或者和别的Bean相互依赖。
鸡和蛋
只有单例的Bean才存在循环依赖的情况,原型(Prototype)情况下,Spring会直接抛出异常。原因很简单,AB循环依赖,A实例化的时候,发现依赖B,创建B实例,创建B的时候发现需要A,创建A1实例……无限套娃,直接把系统干垮。
Spring可以解决哪些情况的循环依赖?
Spring不支持基于构造器注入的循环依赖,但是假如AB循环依赖,如果一个是构造器注入,一个是setter注入呢?
看看几种情形:

循环依赖的几种情形
第四种可以而第五种不可以的原因是 Spring 在创建 Bean 时默认会根据自然排序进行创建,所以 A 会先于 B 进行创建。
所以简单总结,当循环依赖的实例都采用setter方法注入的时候,Spring可以支持,都采用构造器注入的时候,不支持,构造器注入和setter注入同时存在的时候,看天。
16.那Spring怎么解决循环依赖的呢?
PS:其实正确答案是开发人员做好设计,别让Bean循环依赖,但是没办法,面试官不想听这个。
我们都知道,单例Bean初始化完成,要经历三步:
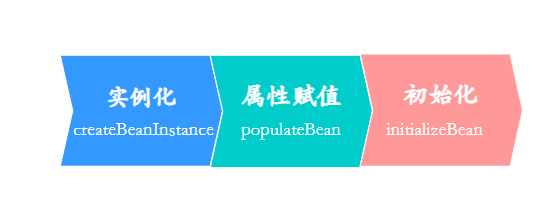
Bean初始化步骤
注入就发生在第二步,属性赋值,结合这个过程,Spring 通过三级缓存解决了循环依赖:
- 一级缓存 : Map<String,Object> singletonObjects,单例池,用于保存实例化、属性赋值(注入)、初始化完成的 bean 实例
- 二级缓存 : Map<String,Object> earlySingletonObjects,早期曝光对象,用于保存实例化完成的 bean 实例
- 三级缓存 : Map<String,ObjectFactory<?>> singletonFactories,早期曝光对象工厂,用于保存 bean 创建工厂,以便于后面扩展有机会创建代理对象。

三级缓存
我们来看一下三级缓存解决循环依赖的过程:
当 A、B 两个类发生循环依赖时:
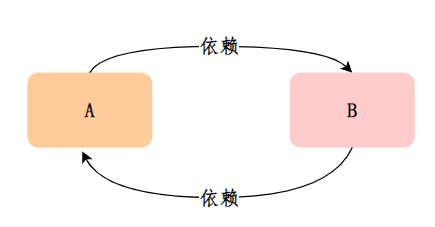
A实例的初始化过程:
- 创建A实例,实例化的时候把A对象⼯⼚放⼊三级缓存,表示A开始实例化了,虽然我这个对象还不完整,但是先曝光出来让大家知道
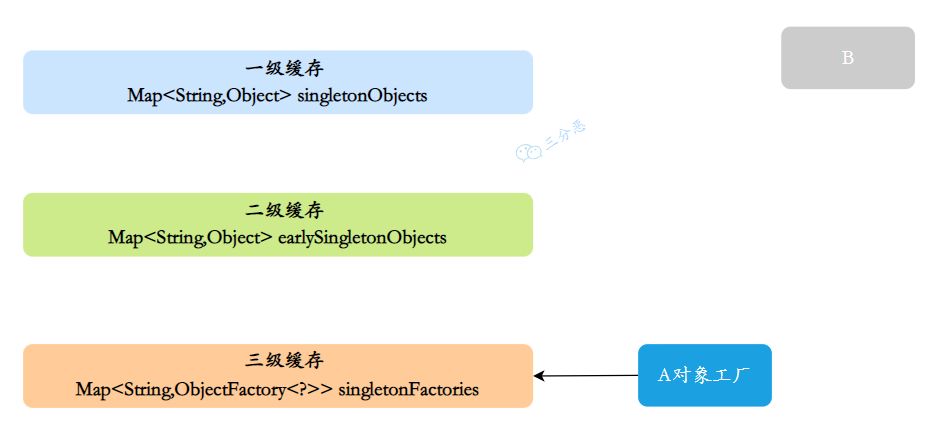 1
1 - A注⼊属性时,发现依赖B,此时B还没有被创建出来,所以去实例化B
- 同样,B注⼊属性时发现依赖A,它就会从缓存里找A对象。依次从⼀级到三级缓存查询A,从三级缓存通过对象⼯⼚拿到A,发现A虽然不太完善,但是存在,把A放⼊⼆级缓存,同时删除三级缓存中的A,此时,B已经实例化并且初始化完成,把B放入⼀级缓存。
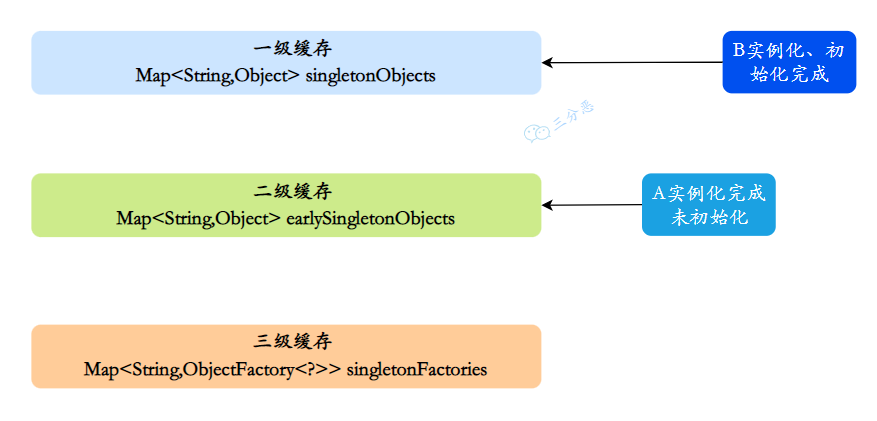 2
2 - 接着A继续属性赋值,顺利从⼀级缓存拿到实例化且初始化完成的B对象,A对象创建也完成,删除⼆级缓存中的A,同时把A放⼊⼀级缓存
- 最后,⼀级缓存中保存着实例化、初始化都完成的A、B对象
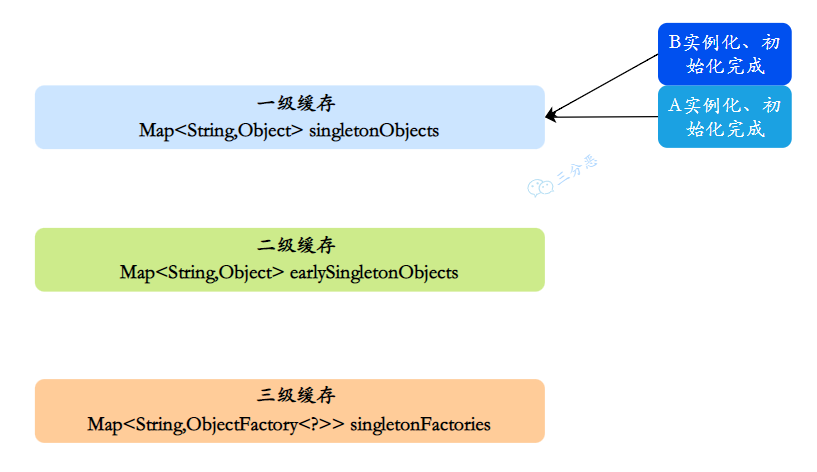
5
所以,我们就知道为什么Spring能解决setter注入的循环依赖了,因为实例化和属性赋值是分开的,所以里面有操作的空间。如果都是构造器注入的化,那么都得在实例化这一步完成注入,所以自然是无法支持了。
17.为什么要三级缓存?⼆级不⾏吗?
不行,主要是为了⽣成代理对象。如果是没有代理的情况下,使用二级缓存解决循环依赖也是OK的。但是如果存在代理,三级没有问题,二级就不行了。
因为三级缓存中放的是⽣成具体对象的匿名内部类,获取Object的时候,它可以⽣成代理对象,也可以返回普通对象。使⽤三级缓存主要是为了保证不管什么时候使⽤的都是⼀个对象。
假设只有⼆级缓存的情况,往⼆级缓存中放的显示⼀个普通的Bean对象,Bean初始化过程中,通过 BeanPostProcessor 去⽣成代理对象之后,覆盖掉⼆级缓存中的普通Bean对象,那么可能就导致取到的Bean对象不一致了。

二级缓存不行的原因
18.@Autowired的实现原理?
实现@Autowired的关键是:AutowiredAnnotationBeanPostProcessor
在Bean的初始化阶段,会通过Bean后置处理器来进行一些前置和后置的处理。
实现@Autowired的功能,也是通过后置处理器来完成的。这个后置处理器就是AutowiredAnnotationBeanPostProcessor。
- Spring在创建bean的过程中,最终会调用到doCreateBean()方法,在doCreateBean()方法中会调用populateBean()方法,来为bean进行属性填充,完成自动装配等工作。
- 在populateBean()方法中一共调用了两次后置处理器,第一次是为了判断是否需要属性填充,如果不需要进行属性填充,那么就会直接进行return,如果需要进行属性填充,那么方法就会继续向下执行,后面会进行第二次后置处理器的调用,这个时候,就会调用到AutowiredAnnotationBeanPostProcessor的postProcessPropertyValues()方法,在该方法中就会进行@Autowired注解的解析,然后实现自动装配。
/*** 属性赋值**/protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) { //………… if (hasInstAwareBpps) { if (pvs == null) { pvs = mbd.getPropertyValues(); } PropertyValues pvsToUse; for(Iterator var9 = this.getBeanPostProcessorCache().instantiationAware.iterator(); var9.hasNext(); pvs = pvsToUse) { InstantiationAwareBeanPostProcessor bp = (InstantiationAwareBeanPostProcessor)var9.next(); pvsToUse = bp.postProcessProperties((PropertyValues)pvs, bw.getWrappedInstance(), beanName); if (pvsToUse == null) { if (filteredPds == null) { filteredPds = this.filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching); } //执行后处理器,填充属性,完成自动装配 //调用InstantiationAwareBeanPostProcessor的postProcessPropertyValues()方法 pvsToUse = bp.postProcessPropertyValues((PropertyValues)pvs, filteredPds, bw.getWrappedInstance(), beanName); if (pvsToUse == null) { return; } } } } //………… } - postProcessorPropertyValues()方法的源码如下,在该方法中,会先调用findAutowiringMetadata()方法解析出bean中带有@Autowired注解、@Inject和@Value注解的属性和方法。然后调用metadata.inject()方法,进行属性填充。
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) { //@Autowired注解、@Inject和@Value注解的属性和方法 InjectionMetadata metadata = this.findAutowiringMetadata(beanName, bean.getClass(), pvs); try { //属性填充 metadata.inject(bean, beanName, pvs); return pvs; } catch (BeanCreationException var6) { throw var6; } catch (Throwable var7) { throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", var7); } }
版权归原作者 叶秋学长 所有, 如有侵权,请联系我们删除。